用于人體動作識別的多尺度時空圖卷積算法
2023-03-10 00:11:14趙登閣智敏
計算機與生活 2023年3期
趙登閣,智敏
內蒙古師范大學 計算機科學技術學院,呼和浩特010000
基于骨骼數據的人體動作識別是計算機視覺領域的熱點之一,它從人體骨骼序列中獲取特征信息,能夠避免視頻數據的許多不利因素。視頻數據會受到復雜的背景、變幻的色彩和明暗度、目標大小縮放以及動作軌跡速度變化的影響,基于視頻數據的人體動作識別算法[1-3]在3D 空間獲取準確特征表達的難度相對更大。骨骼數據規避了以上視頻數據中的限制,因此,骨骼數據動作識別算法的抗干擾性和魯棒性更強,也更適于解決動作識別任務中遇到的難題。
早期基于骨骼數據的算法[4-6]通常使用手工提取特征,但此類方法工作量較大且在特征表達上有很大的限制,也無法同時捕捉時空特征。隨著深度學習的發展,卷積神經網絡(convolution neural networks,CNN)[7]及循環神經網絡(recurrent neural network,RNN)[8]提升了基于骨骼數據動作識別算法的性能,能夠從骨骼序列中提取關節點特征,然而由于骨骼數據都是非歐幾里德結構數據,此類算法忽略了至關重要的節點間關聯信息,整體提升有限。圖神經網絡(graph neural networks,GNN)[9]的出現化解了以往算法難以處理非歐數據的困境,圖神經網絡能夠提取節點間的關聯特征,適用于任何拓撲結構,相較于其他方法,GNN 更能勝任以骨骼數據為基礎的動作識別任務。將CNN 的概念推廣到GNN 中,于是形成了圖卷積神經網絡[10],此類算法大幅提升了特征提取和表達能力。基于GCN(graph convolutional neural network),Yan 等提出了時空圖卷積網絡(spatialtemporal graph convolutional neural network,ST-GCN)[11],能夠從空間和時間維度提取空間結構特征和時間軌跡特征,形成高級時空特征,大幅提升動作識別精度。在ST-GCN 基礎上衍生出了許多時空圖卷積算法:Thakkar等[12]將骨骼序列根據人體結構分為多個部分(如頭、軀干、四肢)分別獨立輸入時空圖卷積網絡中,最終融合為整體結果;Zhang等[13]分別將骨骼序列圖中關節點和骨架作為獨立輸入,同時對關節頂點和肢體骨架進行卷積操作,構造了以不同輸入為基礎的雙流時空圖卷積網絡;Cheng等[14]利用輕量級位移圖操作代替卷積操作,通過空間位移圖和時間位移圖獲取時空特征;Liu等[15]構造了統一時空圖卷積模塊,直接對跨時空關節依賴關系建模,同時消除冗余依賴關系,提高了模型性能;Zhang等[16]通過點積、線性函數、可學習參數等計算方法,減少了卷積層的堆疊,降低了動作識別算法的計算量;Ma等[17]設計了區域關聯自適應圖卷積網絡,強化了模型的靈活性和對非物理連接相關性的捕捉。雖然基于ST-GCN 的算法改進都提升了人體動作識別精度,但仍然存在問題。此類時空圖卷積算法的時間卷積往往是固定結構,單一且尺度固定的卷積核難以提取每個動作序列中的全部重要軌跡特征,限制了時空圖卷積網絡的能力。
為解決以上問題,本文在ST-GCN 的基礎上,提出了多尺度時間卷積結構,利用不同尺度的圖卷積從時間維度提取各尺度軌跡特征,并融合為全面的時空特征,提高了基于骨骼數據的動作識別精度。
1 相關工作
基于骨骼數據的人體動作識別時空圖卷積網絡(ST-GCN),能夠從時間和空間兩個維度共同提取時空特征。主要流程是:給定一個動作視頻的骨骼序列,首先構造表達該序列的圖結構數據,并以此作為ST-GCN 的輸入;然后經過一系列的時空圖卷積操作提取高層時空特征;最后利用Softmax 分類器得到分類結果。ST-GCN 實現了端對端的訓練,其整體結構及卷積單元結構如圖1 所示。
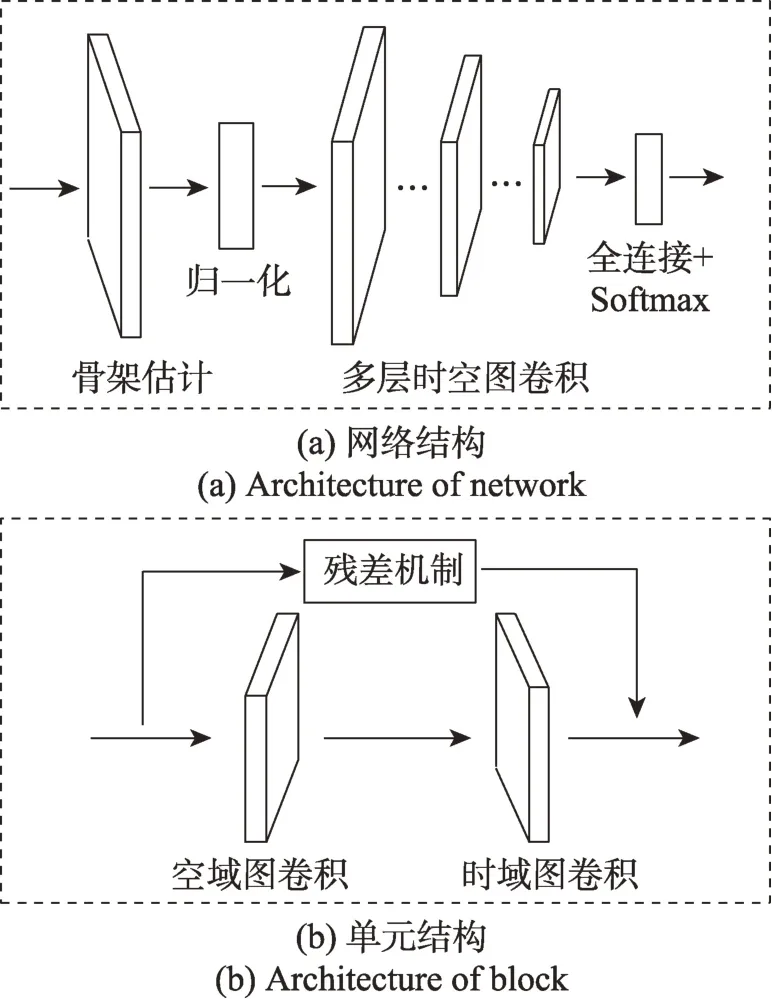
圖1 ST-GCN 網絡及單元結構Fig.1 ST-GCN network and architecture of block
每個圖卷積單元包含一個空間卷積層、一個時間卷積層和殘差結構。在時空圖卷積單元內,存在一個可學習的邊權重參數,用于學習節點之間的邊重要程度。該邊權重的優勢是可以作為ST-GCN 內部的注意力機制,起到強化關聯信息的作用;但不足之處在于,對關鍵節點和結構化特征并未有效加強。ST-GCN 的時間卷積層采用具有固定結構的卷積操作,卷積核大小為單一定值。骨骼序列圖,首先通過空間卷積層獲取空間結構特征,再經過時間卷積獲取時間流方向上的時間特征,最后利用殘差機制融合原始輸入和高層時空特征,形成每個時空圖卷積單元的輸出。每個ST-GCN 時空卷積單元中,空間圖卷積和時間圖卷積可以有類似的表達:
時空圖卷積獲取時空關聯信息的流程如圖2 所示,輸入的骨骼數據包含空間和時間兩個序列,其中空間序列即單幀內的關節點序列,時間序列即時間流序列。首先,通過空間卷積層從空間序列中提取出每個單幀的結構特征,這些特征不僅包含節點特征和幀內節點間的關聯信息,還保留原始時間序列;之后,通過時間卷積層從時間流的方向上提取幀間特征,幀間特征包含了節點的軌跡特征,即時間關聯信息;經上述兩步,時空卷積既獲取了單幀內結構化的空間關聯信息,又獲取了連續幀之間節點軌跡的時間關聯信息,由此構成了包含大量時空關聯信息的特征圖。
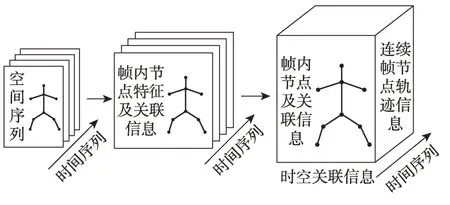
圖2 時空卷積流程圖Fig.2 Flow of spatial-temporal convolution
2 本文算法
2.1 多尺度時間卷積
人體動作識別所需的特征是多變的,不同動作的判別關鍵也有所區別。如圖3 所示(前4 幅圖為“起立”,后4 幅圖為“坐下”),“起立”和“坐下”兩個動作相似,二者的空間特征差異不大,但在時間特征上,兩者有明顯的不同;“坐下”在時序上是一個由“高”到“低”的過程,而“起立”則相反,在時序上是一個由“低”到“高”的過程;因此,二者的時間特征在時序上存在很大差異。另外,不同動作的持續時間也不相同,例如,“擊打”只需要2 s 左右的時間,而“穿夾克”則需要5 s 左右的時間,二者的時間特征存在長短期差異。由此,基于骨骼信息的人體動作識別需要從時間維度上全面地提取并融合不同距離或尺度的特征,才能準確表達對應不同動作序列的重要特征部分,更加精確地完成動作分類。
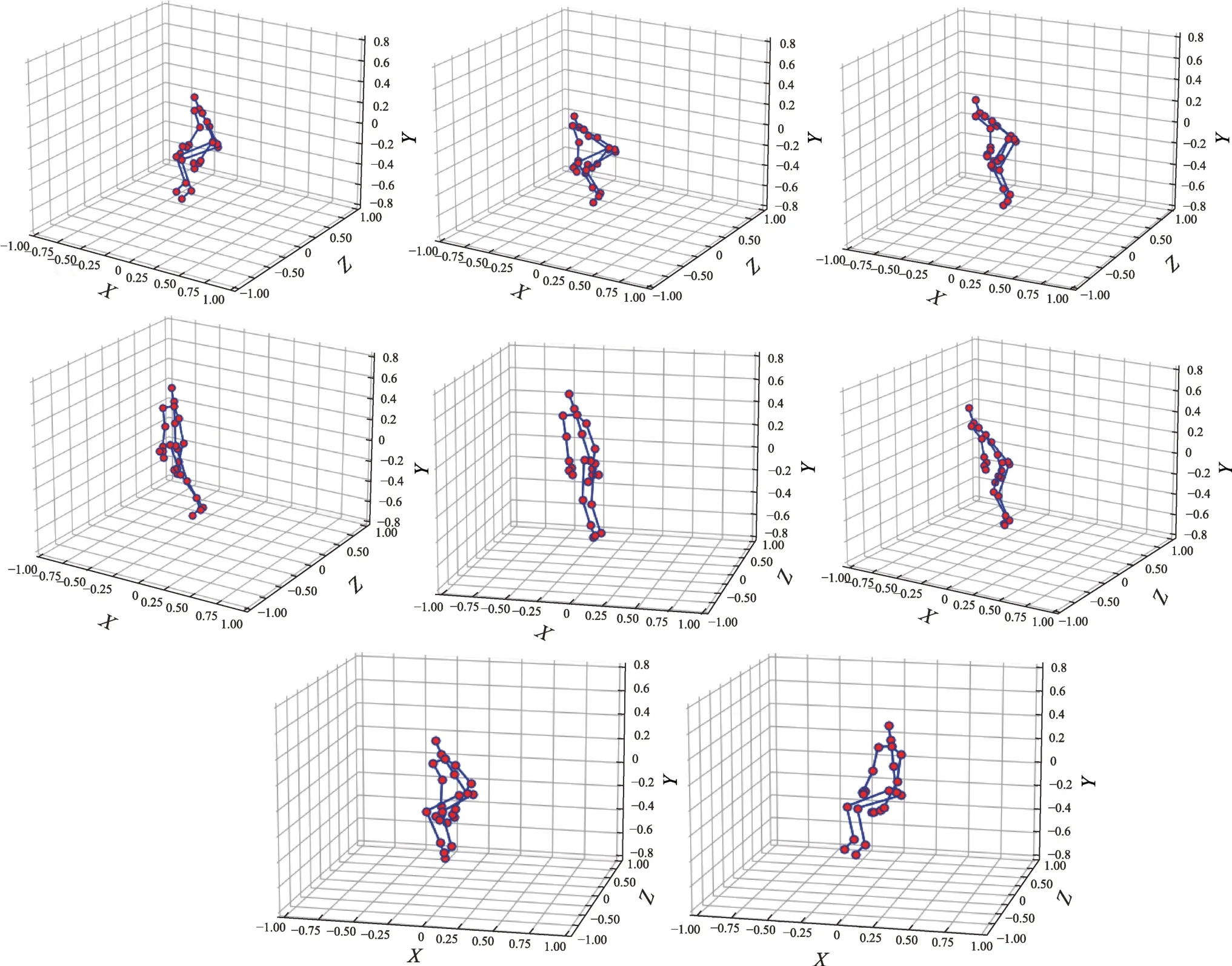
圖3 “起立”和“坐下”軌跡特征Fig.3 Motion features of“stand up”and“sit down”
多尺度特征融合可以增強不同分辨率和距離特征的表達能力,而多尺度特征的提取可以通過設計多個不同尺寸的卷積核實現,如經典的Inception 系列網絡[18]是 在VGG網絡(visual geometry group network)[19]多個固定3×3 卷積的基礎上,通過設置多尺度卷積核,獲得了更好的特征提取效果,提升了實驗效果;Li[20]在尺寸為t的單一時間卷積核基礎上,通過額外增加一個2t尺寸的卷積核,提高了動作識別精度。大尺寸的卷積核具有相對更大的感受野,獲取特征分辨率更低,能夠捕捉更豐富的長距離高層語義信息,同時計算量相對較大;小尺寸的卷積核具有相對較小的感受野,局部性更強,獲取特征分辨率更高,能夠捕捉更豐富的短距離低層內含信息,計算量相對較小;二者兼具優點,對不同任務需求的適應程度各有不同。對于基于骨骼信息的人體動作識別,全面的時間特征提取包含對長、短距離依賴的提取;本文采用多尺度時間卷積核進行時間特征提取,利用小尺寸卷積進行短程時序特征建模,提取豐富的節點局部內含信息;利用大尺寸卷積進行長距離時序依賴建模,提取豐富的長時語義信息;利用中間尺度卷積提取同時包含語義和內含信息的特征,使模型對時間特征的提取更加全面。另外,有效的特征融合策略可以強化多尺度特征提取效果,合理的網絡結構可以優化特征融合策略;因此設計并選擇性能更優的模型架構也是全面提取多尺度時間特征的關鍵。反觀時空圖卷積網絡(ST-GCN),存在時間卷積層結構單一、卷積核尺寸固定、難以全面提取對應每個動作序列重要特征部分的問題;為此,本文以多尺度特征提取和融合為基礎,設計了多尺度時間圖卷積層,包括不同數量和尺寸的卷積核以及構造的特征融合架構。
本文設計的多尺度時間卷積層(multiple-temporal graph convolution,MT-GC)結構如圖4 所示。
圖4(a)將多個不同尺度圖卷積操作單元并行處理,構造了多尺度并行時間圖卷積(multiple-temporal parallel graph convolution,MPT-GC),可以有如下表示:
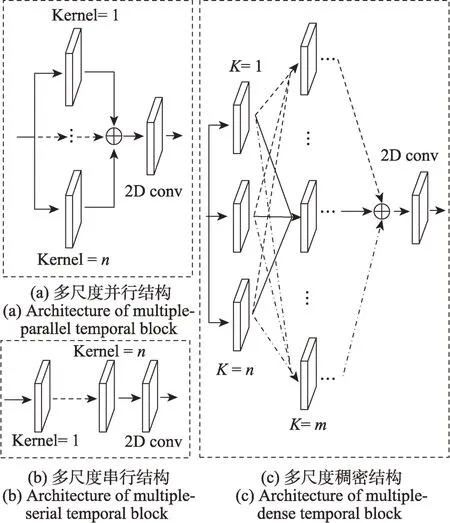
圖4 多尺度時間圖卷積(MT-GC)結構Fig.4 Architecture of multiple-temporal graph convolution(MT-GC)
其中,x為輸入,y代表輸出,conv()表示2D 卷積,表示MPT-GC 子單元,卷積核大小從1至n,BN() 表示批歸一化,gt() 表示時間圖卷積,ReLU() 表示激活函數,Drop() 為隨機丟棄機制。式(4)代表MPT-GC 子單元,每個子單元采用BN歸一化-ReLU 激活-圖卷積g-BN 歸一化的結構,并且在單元末尾與原輸入融合;其中兩個BN 歸一化使模型可以在更大的學習率下進行訓練和測試,防止梯度爆炸和過擬合現象的發生,保證模型的收斂性能;ReLU 激活函數使模型參數在前后向的循環學習中得到優化;圖卷積是進行特征提取的核心操作,且每個子單元圖卷積核大小不同;隨機丟棄操作Drop在每個子循環中隨機丟棄部分算子,既能夠降低計算量,又進一步防止過擬合的發生,提升模型收斂性;每個子單元的輸出在末位與原輸入的融合是本文算法對殘差結構的改進,作用是保持原始特征信息的作用,防止原始信息過度流失,并且保持模型在深層中的魯棒性。從式(3)可以看到,MPT-GC 以不同尺度卷積并行提取多尺度時間特征,通過直接加權求和策略進行多尺度特征融合,將長、中、短距離時序特征組合為時間特征圖,再通過一個2D 卷積進一步強化特征提取;在特征融合過程中,此結構卷積不對提取到的時序特征作額外處理,而是直接統一到同一時間特征圖中,簡單地融合就使時序特征表達更加全面,并且在計算量上的增加要少于設計的其他卷積單元結構。
圖4(b)將多個不同尺度圖卷積單元串行處理,構造多尺度串行時間圖卷積(multiple-temporal serial graph convolution,MST-GC),如式(5):
MST-GC 的卷積子單元與上文MPT-GC 和后面將介紹的MDT-GC 子單元具有同樣的結構和式(4)表達,都采用BN-ReLU-g-BN 結構。在MST-GC 中,子單元的卷積核按照由前到后的結構順序被設置為由小到大的尺寸,由小尺寸卷積獲取相對短程的特征,再逐層利用相對較大尺寸的卷積獲取長距離的語義依賴關系,使獲取的語義信息既能夠以節點內含信息為基礎,又能夠捕捉更高級的關聯信息。MST-GC 采用順序融合的策略,強化了內含和語義關聯信息的提取,其計算量的增加高于MPT-GC,低于MDT-GC。
圖4(c)借鑒了經典的稠密網絡(densely connected convolutional network,Dense-Net)[21]結 構,并融合MPT-GC 和MST-GC 的特點,構造了多尺度稠密時間圖卷積(multiple-temporal dense graph convolution,MDT-GC),如式(6):
2.2 變換殘差機制Tran-Res
視覺變換網絡(vision transformer network,ViT)[22]具有強大的長距離依賴關系建模能力,而長距離關聯信息是基于骨骼信息動作識別的重點和難點之一。為了進一步強化骨骼序列中人體關聯信息,本文結合Transformer 的優勢,對殘差機制進行改進,構造了變換殘差機制(Transformer-Resnet,Tran-Res),強化了模型對長距離關聯依賴的關注度,并提升了人體動作識別精度。如圖5 所示,Tran-Res 由變換(Transformer branch,Tran)分支和恒等分支(skipconnection branch,Skip)組成,其中Tran 分支對原始輸入進行多頭自注意力計算,得到全部節點的關聯信息;恒等分支不對原始輸入做額外處理,保持原始信息的完整性;最后通過求和的方式對二者進行融合,作為完整的Tran-Res殘差機制輸出結果。
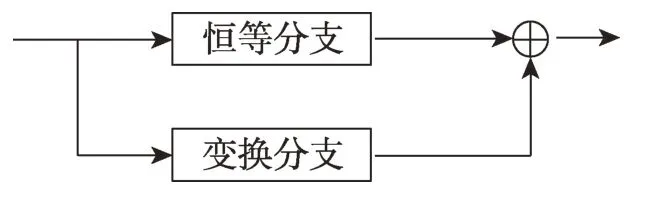
圖5 變換殘差機制結構Fig.5 Architecture of Transformer-Resnet
Tran 分支以Transformer 網絡Q、K、V 機制為基礎,其結構如圖6 所示。形如Cin×T×V的原始輸入首先經過BN 層歸一化處理,并重塑為T×Cin×V的形式,再分別通過兩組線性變換得到相應的Q、K、V矩陣,在Q和轉置K相乘后,再與V相乘,最后通過重塑得到與原輸入形式一致的輸出Cout×T×V。圖6 中,wq、wk、wv分別為取得Q、K、V矩陣的對應參數權重,Q、K矩陣分別具有T×N×dq×V和T×N×dk×V的形式,V矩陣具有T×N×dv×V的形式。本文中,空間維度和時間維度下Tran-Res 的Tran 分支基本相似,但有所不同。空間維度下,Tran 分支處理的是單幀下的所有關節點,然后整合為最終的輸出;時間維度下,Tran 分支處理的是連續幀下的相同關節點,并整合為時間維度Tran分支的最終輸出。總體來說,Tran 分支可以有如下表示:其中,式(7)代表空間維度下的Tran 分支,式(8)代表時間維度下的Tran 分支,其中表示相同幀下每個節點間的關聯強度,并作為節點值v的權重參數,上標t代表第t幀,i、j分別代表目標節點和鄰居節點;代表連續幀下每個相同節點的關聯強度,并作為時間維度下節點值v的權重參數,上標n代表相同節點,t、u代表不同連續幀;softmax()代表激活函數,dk代表通道維數。
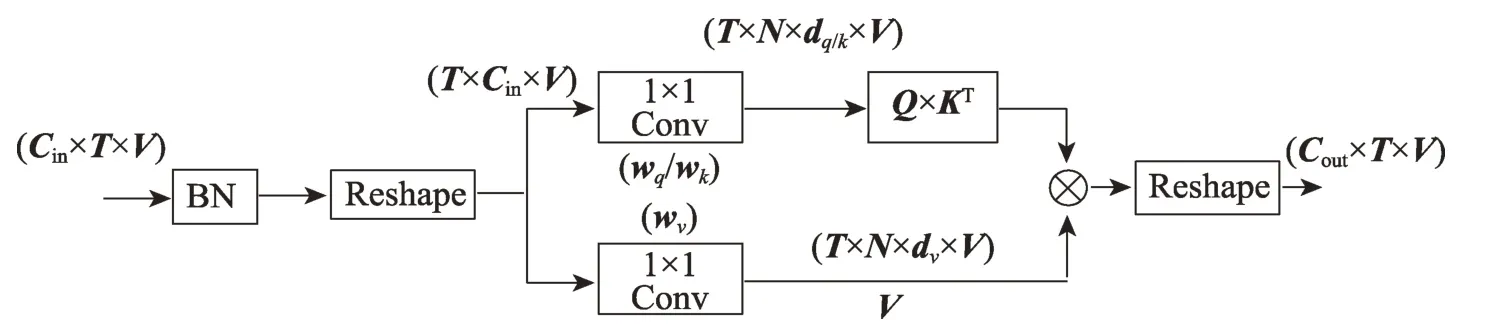
圖6 Tran 分支結構Fig.6 Architecture of Tran stream
如圖7 所示,Tran-Res 作為空間和時間圖卷積子單元的殘差機制,分別融合于空間圖卷積模塊和時間圖卷積模塊中,強化了骨骼序列長距離關聯信息,提升了模型性能。
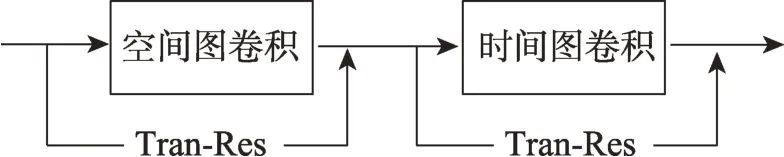
圖7 Tran-Res融合于時空圖卷積模型Fig.7 Tran-Res fused in spatial-temporal graph convolution network
2.3 融合輕量級注意力模塊
類別相差較大的人體動作識別,不僅需要在時間維度全面地提取時序上的差異特征,同時也需要從空間維度上提取具有明顯差別的結構化特征。如圖8所示,“喝水”和“起跳”兩個動作(前4幅圖為“喝水”,后4幅圖為“起跳”),每幀內的動作特征都存在顯著的差異,因此,強化幀內空間特征的提取和表達可以提升人體動作識別的精度;另外,對空間特征的強化,也可以減少對類別相近動作的識別混淆度。ST-GCN 內部本身存在一定的注意力機制,但該注意力機制僅對關聯信息進行了強化,缺少對關鍵節點及特征的強化。為提升基于骨骼的人體動作識別精度,本文引入通道空間注意力(convolutional block attention module,CBAM)[23]模塊,強化了空間特征的表達。
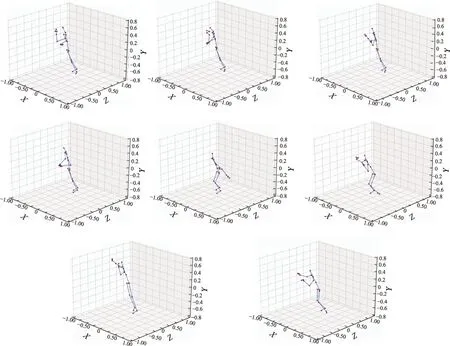
圖8 “喝水”和“起跳”軌跡特征Fig.8 Motion features of“drink water”and“jump up”
Woo等[23]構建的輕量級通道-空間注意力模塊(CBAM),在強化通道信息的同時,也加強了對空間特征的表達。CBAM 結構如圖9 所示,該模塊可以融入各類基礎網絡模型中,均得到了一定的性能提升。
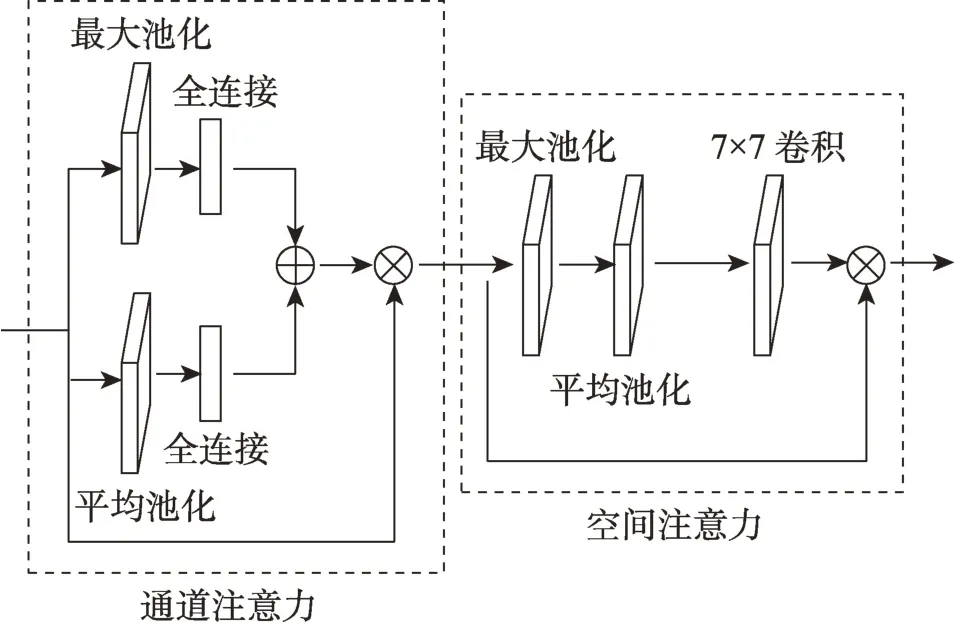
圖9 CBAM 結構Fig.9 Architecture of CBAM
CBAM 模塊由通道注意力子模塊和空間注意力子模塊組成。通道注意力模塊包含并行的最大池化和平均池化操作以及對應的兩組線性全連接層,輸入通過最大池化和平均池化后,強化了通道信息,再與原始輸出融合得到強化通道特征的輸出;空間注意力模塊包含串行的最大池化和平均池化操作以及一組尺度為7×7 的2D 卷積操作,強化了通道特征的輸入通過最大池化和平均池化后,再由2D 卷積操作得出強化的空間特征,最后與原始輸入加權融合得出最后的輸出。由于缺少激活函數,在融合原始特征和強化特征時,原始特征和強化特征在深層時會減少差異性;因此本文對CBAM 特征融合階段做了微小調整,為了加強非線性并強化注意力模塊與模型的融合程度,加入了激活函數。將激活函數設置為Sigmoid,可以強化殘差結構的性能,防止原始特征作用被過度弱化,增加強化特征和原始特征間的差異性。嵌入改進的CBAM 模塊后,構造的強化時空圖卷積層結構如圖10 所示。改進的時空圖卷積層能夠強化關鍵節點和結構特征,提高基于骨骼的人體動作識別精度。
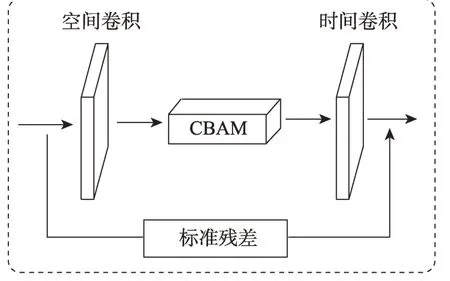
圖10 強化的時空圖卷積層結構Fig.10 Architecture of enhanced spatial-temporal graph convolution layer
2.4 本文結構
為解決ST-GCN 時間卷積層結構固定、單一的問題,并提升空間特征表達能力,本文改進了ST-GCN時間圖卷積層,構造了多尺度時空圖卷積網絡(spatial multiple-temporal graph convolutional neural network,SMT-GCN);在此基礎上還通過融合通道空間注意力(CBAM)模塊,構造了多尺度時空圖注意卷積網絡(spatial-attentive multiple-temporal graph convolutional neural network,SAMT-GCN)。多尺度時空圖注意卷積單元具體結構如圖11 所示。
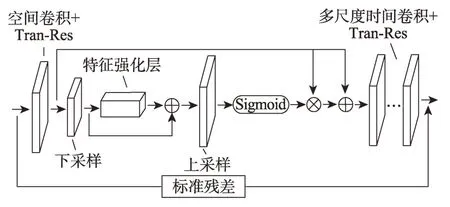
圖11 SAMT-GCN 網絡單元結構Fig.11 Architecture of SAMT-GCN block
每個多尺度時空圖卷積單元由空間圖卷積層、特征強化層、下采樣和上采樣層及多尺度時間圖卷積層組成,空間圖卷積和多尺度時間圖卷積層中都融合了構造的變換殘差模塊,并且整體網絡單元內依然應用標準殘差機制,不對原始輸入做額外處理,用于融合原始輸入和時空特征。這里不使用構造的變換殘差模塊的原因在于,防止原始信息過度流失的可能性,并減少對模型計算負擔的增加。整個網絡由骨架估計模塊、多尺度時空圖卷積模塊以及全連接層和Softmax 分類器組成,多尺度時空圖卷積模塊由1 個歸一化層和9 層多尺度時空圖卷積層堆疊組成,每個圖卷積層具有相同的結構。整個網絡的算法流程如下:
(1)原始視頻通過骨架估計算法得到對應的骨骼序列,并構造骨骼序列圖x,作為多尺度時空圖卷積模塊的輸入;
(2)輸入x由歸一化層進行規范化處理,再通過9 層多尺度時空圖卷積層獲取高級時空特征x′;
(3)x′經過全連接層融合全局信息,并由Softmax分類器獲取最終的動作分類結果。
另外,對于基于骨骼信息的人體動作識別,肢體骨架所包含的關聯信息與關節頂點包含的坐標信息同樣重要;單獨以關節頂點或肢體骨架作為輸入,都會使模型對關聯信息或節點坐標的利用不足。因此本文融合兩類輸入的優勢,采用雙流網絡架構,如圖12,模型由處理關節點的分支和處理骨架的分支組成,兩個分支具有相同的網絡線構架,均由多個多尺度時空圖卷積層堆疊而成。關節點分支的輸入為人體關節點序列,由各幀的人體關節點坐標構成。骨架分支的輸入為肢體序列,由每一個幀的肢體序列構成,肢體序列由該部位的大小和方向表示,根據肢體兩端的關節點坐標計算;例如給定一根肢體骨架,其靠近人體重心的關節點為v1=(x1,y1,z1),遠離人體重心的關節點為v2=(x2,y2,z2),則該肢體骨架可以表示為ev1v2=(x2-x1,y2-y1,z2-z1)。在兩個分支分別得到對應的Softmax 分數后,通過帶權相加融合為最終的分數并預測動作標簽;與雙流多關系圖卷積網絡(two-stream multi-relational graph convolutional network,2S-MRGCN)[24]相似,本文設置兩個分支的識別分數具有相同的融合權重,此時取得的融合效果最佳。
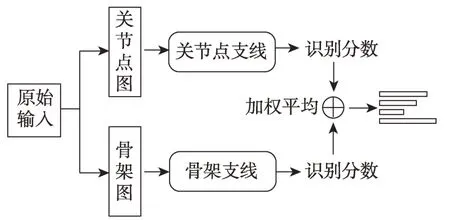
圖12 雙流網絡結構Fig.12 Architecture of two-stream network
3 實驗
3.1 數據集
本文分別在NTU RGB+D 和HDM05 兩個常用人體動作識別數據集上對提出的模型進行了實驗。與大型數據集NTU RGB+D 相比,HDM05 的數據規模相對較小,實驗在大規模數據和小規模數據兩種訓練狀態下進行,驗證了算法的性能。
NTU RGB+D(60)數據集[25]是近期主流的大規模人體動作識別數據集,包含56 000 個視頻和60 種動作類別。60 類動作中,50 類為單人動作,10 類為多人交互動作;每位演員捕捉了25 個關節點;每個動作片段由3 臺Kinetics 攝像機分別從3 個不同角度-45°、0°、45° 捕捉完成。該數據集包含兩種分割方式,Cross Subject 和Cross View:Cross Subject 分割方式根據動作類別排序,訓練集包含40 320 個視頻片段,測試集包含16 560 個視頻片段,兩個集合中的表演者不同;Cross View 分割方式根據設備標號排序,訓練集包含37 920 個視頻片段,測試集包含18 960 個視頻片段,訓練集由2 號和3 號攝像機從0°和45°的角度捕捉完成,測試集由1 號攝像機從-45°的角度捕捉完成。
HDM05 數據集[26],包含2 337 個骨骼序列,130 種動作類別,共由5 位表演者完成動作捕捉。該數據集總共包含184 046 幀視頻片段,每個人捕捉了31 個關節點。與NTU RGB+D 數據集相比,該數據集的規模相對較小,實驗利用該數據集說明了本文網絡在相對較小訓練量下的性能提升。
3.2 訓練參數設置
本實驗使用的硬件為Nvidia Tesla T4 GPU,操作系統為Linux Centos。以Pytorch 為基礎框架,保障實驗的順利進行。
在實驗中,為防止過擬合現象的發生,采用隨機丟棄的機制,并將隨機丟棄率Dropout 參數設置為0.5。堆疊的9 層多尺度時空圖卷積層中,第4 層和第7 層的卷積步長被設置為2,以此作為池化層;其中,1到3 層的通道數設置為64,5 到6 層的通道數設置為128,8 到9 層的通道數設置為256。同時,經反復實驗對比發現,將每層的學習率設置為0.1 時,可以確保實驗的最優結果。批處理量被設置為64,每個樣本的最大幀數設置為300 幀,不足300 幀的片段則會反復循環直到300 幀幀數上限;訓練回合數被設置為80 輪批次。訓練采用隨機梯度下降法更新參數,優化模型,保證模型的收斂性。模型使用交叉熵函數作為訓練損失,如下所示:
其中,x為預測值,class為真實值,該損失是凸優化函數,適合隨機梯度下降法尋找最優解,能夠衡量類間的細微差異。
另外,本文分析了雙流網絡架構的合理性。表1列出了在相同實驗參數設置下(k=1,5,9;稠密結構時間圖卷積),本文算法在不同融合權重雙流架構下的精度提升。與單獨以關節頂點(joint-stream,jstream)和肢體骨架(bone-stream,b-stream)為輸入的模型架構相比,雙流架構(two-stream,2s-stream)的模型精度有明顯的提升。表1 還列出了在不同融合權重下雙流模型的識別精度,結果顯示,當融合權重值設置為0.5 時,模型精度最高。因此,采用以關節頂點和肢體骨架為基礎的雙流網絡架構,能夠有效提升模型性能。

表1 不同融合權重下雙流模型在NTU-CS 上的精度Table 1 Accuracy of 2s-stream network on NTU-CS with different fusion weights
3.3 模型參數量及收斂性分析
本文分析了設計的多尺度時空圖卷積網絡(SMT-GCN)在有無注意力機制嵌入下的參數量規模,如表2 所示。可以看出隨著設計的多尺度卷積核尺寸和數量的增加,模型的參數量和復雜程度也隨之增加;當存在4 個尺度的時間卷積核時,無注意力機制模型參數量達到9.70 MB,嵌入注意力模塊的模型參數量達到9.92 MB,是ST-GCN 的3 倍。另外,圖13 為ST-GCN 與本文設計的多尺度稠密時空圖卷積模型SMDT-GCN,在相同參數設置和訓練設置情況下的損失收斂對比圖,顯示了在50 輪訓練下的損失變換。從圖中可以看出在相同訓練輪次下,多尺度時空圖卷積模型的收斂速度要比ST-GCN 更快,效果更好。

表2 參數量對比Table 2 Comparison of parameters 單位:MB
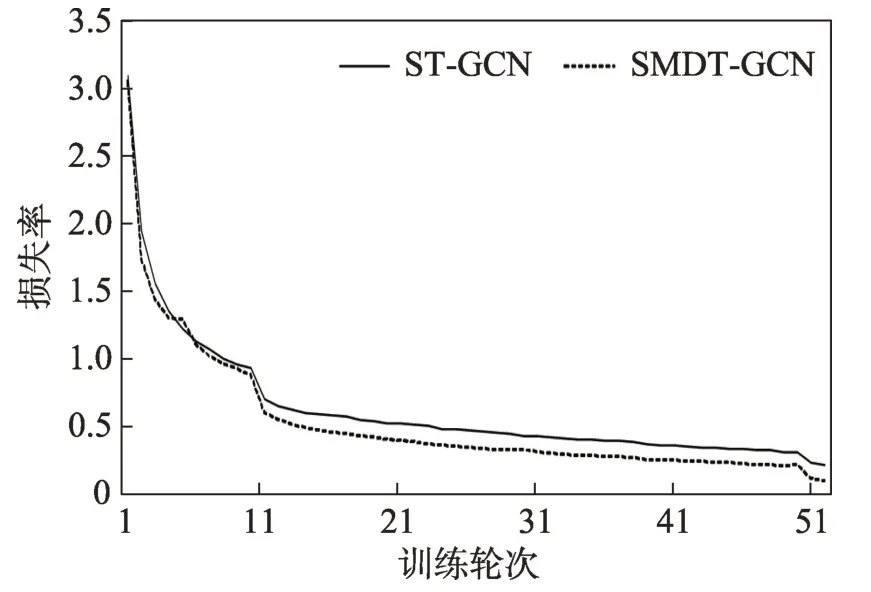
圖13 損失函數收斂曲線Fig.13 Convergence curve of loss function
3.4 實驗結果
本文比較了提出的多尺度時空圖卷積網絡與ST-GCN 在兩個主流動作識別數據集上的實驗結果對比,如表3 和表4 所示。
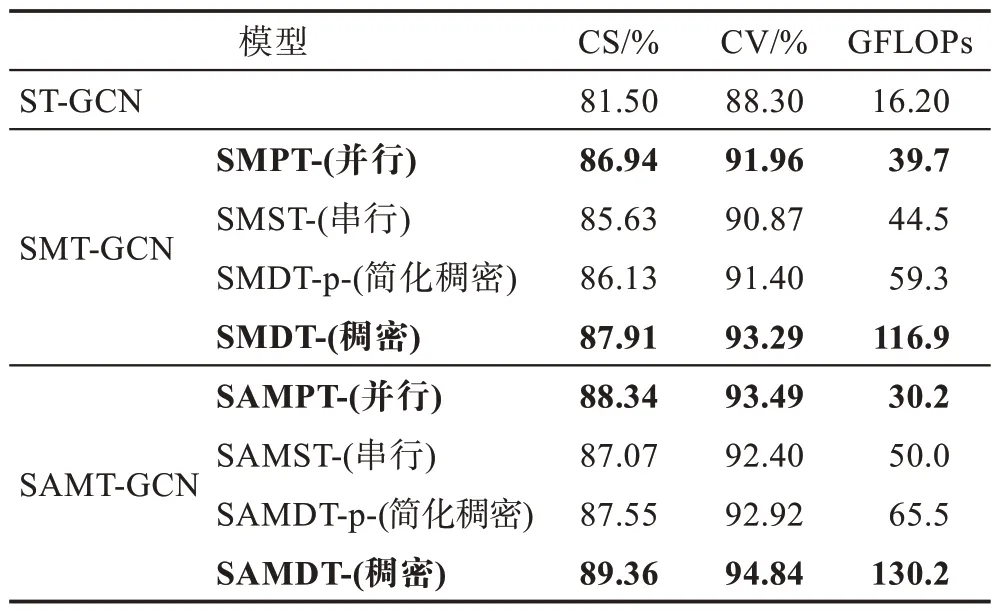
表3 NTU RGB+D 識別精度及浮點運算數Table 3 Accuracies and FLOPs on NTU RGB+D
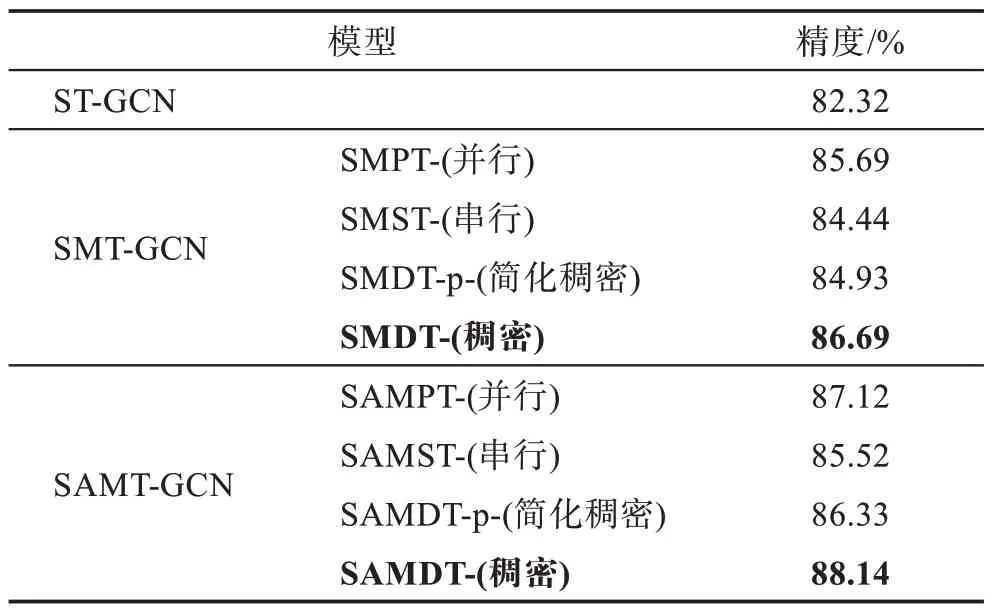
表4 各方法在HDM05 數據集的識別精度Table 4 Accuracies of algorithms on HDM05
表3 列出了各方法在NTU RGB+D 數據集上的精度和浮點計算量。其中SMT-GCN 并未在多尺度時空圖卷積網絡中嵌入通道空間注意力(CBAM)模塊,SAMT-GCN 在構造的多尺度時空圖卷積網絡中融合了通道空間注意力(CBAM)模塊;另外,表中SMPT-、SMST-、SMDT-、SMDT-p-分別表示具有并行、串行、稠密、簡化稠密結構多尺度時間圖卷積的時空模型。在4 種多尺度時間圖卷積單元中,圖卷積操作單元卷積核大小分別設置為1、5、9,經消融實驗對比發現,如此設置的多尺度時間圖卷積層參數可以使模型的性能最優,消融實驗的結果和細節將在下節中敘述。
表4 列出了各類方法在HDM05 數據集上的識別精度。在相對較小規模的數據集上,本文算法的精度提升相對少于在大規模數據集上的精度提升,這表明該算法仍需要大規模數據作為訓練基礎。
從表3 和表4 可以看出,具有稠密結構的SMDT-獲得了最優的實驗效果,這是因為SMDT-相較于SMPT-能夠獲取更加豐富的高層語義信息,相較于SMST-,SMDT-獲取的語義和內含信息更加全面,SMDT-有效融合了并、串行結構的優點;SMST-雖然能夠更好地對長距離依賴建模,但相較于其他結構,其時間特征仍然不夠全面,因此獲取的精度提升最小;簡化版的SMDT-p-雖然看似融合了并行、串行的設計思想,但實際上其結構仍可以視為強化版的串行結構時間卷積模型;雖然第n層的輸入包含前n-1層所有輸出和,但經過第n層相對大尺寸卷積計算后,所捕獲的依然是長距離的語義依賴,對短程信息的利用依然沒有并行結構和稠密結構全面,因此簡化版SMDT-p-的實驗精度要低于SMDT-和SMPT-。從表2 和表3 中可以看到,不同結構的多尺度時空模型對計算復雜度FLOPs 有不同程度的增加,其中并行結構SMPT-GCN 的浮點計算量較ST-GCN 增加了23.5 GFLOPs,增加得最少;而稠密結構的SMDTGCN 增加得最多,較ST-GCN 增加了100.7 GFLOPs,較SMPT-GCN 增加了77.2 GFLOPs。雖然SMDTGCN 的精度比SMPT-GCN 高出1 個百分點,但計算復雜度卻增加了近3 倍,因此如果綜合復雜度的增加和精度的提升,本文認為SMPT-GCN 的整體效果最佳。從表2 還可以看到,改進CBAM 注意力的嵌入并未顯著增加復雜度,但平均增加了1.34 個百分點的精確度。
另外,本文設計的多尺度時間圖卷積可以作為結構策略模塊,應用于各類具有相似構架的圖卷積動作識別模型中,并提升效果。為了驗證多尺度時間圖卷積的有效性,本文以2S-AGCN(two-steam adaptive graph convolutional neural network)[27]、AS-GCN(actionalstructural graph convolutional network)[28]模型為基礎基線,進行了融合實驗,在NTU RGB+D-CS 上的實驗結果如表5 所示。
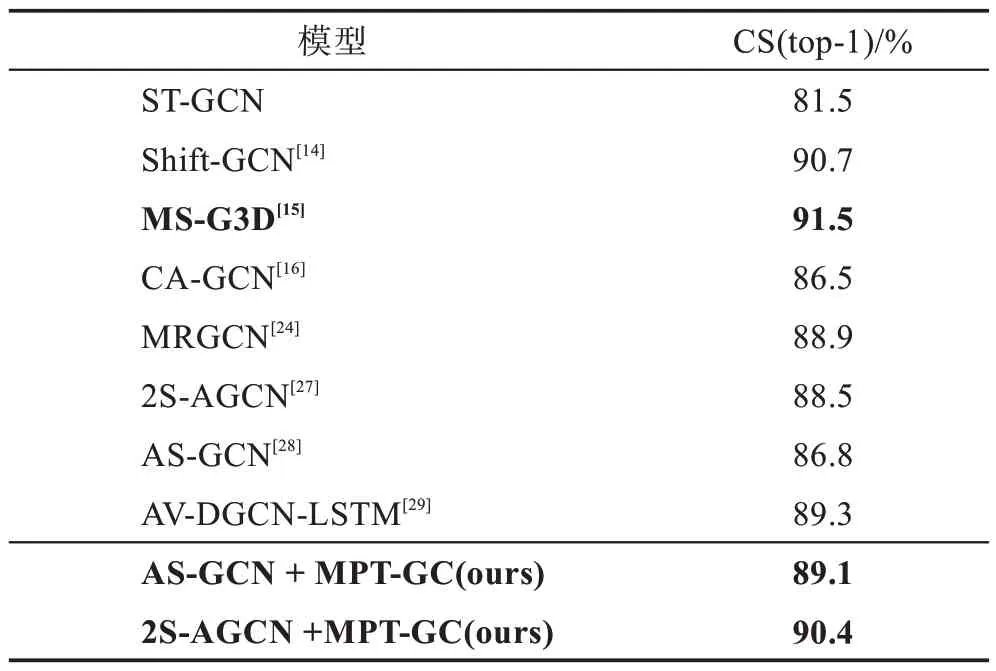
表5 不同基線融合MPT-GC 實驗效果Table 5 Performance of MPT-GC with other baselines
可以看出,本文設計的方法以不同的基線為基礎,均獲得了優秀的實驗效果,其中以2S-AGCN 為基線的多尺度模型將識別準確率達到90.4%,證明了多尺度時間圖卷積是提升動作識別精度的有效方法。
綜上所述,本文設計的多尺度時間卷積模塊可以有效地提升基于骨骼信息的人體動作識別精度,同時也可以作為策略模塊,遷移到其他基線中并提高性能;改進CBAM 注意力的嵌入也提升了模型性能。另外,本文提出的模型需要以大規模訓練為基礎,在大規模數據集上的表現優于在小規模數據集上的表現。
3.5 消融實驗
為了探究設計的多尺度時間圖卷積層中,卷積核尺寸以及圖卷積層結構對性能的影響,本文設計了相應的消融實驗。實驗對不同的卷積核大小及卷積層結構進行了比較,其中時間卷積子單元層數分別從1 層延伸至4 層,卷積核尺寸分別設置有1、5、9、13、17、21,消融實驗在NTU RGB+D 數據集上進行,采用Cross Subject 分割方式訓練和測試。消融實驗結果如表6 所示。
表6 中SMT-GCN 表示未嵌入注意力模塊的多尺度時空圖卷積模型,SAMT-GCN 代表嵌入注意力模塊的多尺度時空圖注意卷積模型,兩類模型都融合了構造的變換殘差機制Tran-Res,模型一欄中字母-P-、-S-、-D-p-、-D-分別代表具有并行、串行、簡化稠密和稠密時間圖卷積結構的模型。從消融實驗結果中可以看出,當時間圖卷積子單元卷積核尺寸設置為1、5、9時,多尺度圖卷積模型性能最優;具有稠密和并行時間圖卷積結構模型的實驗效果優于具有其他兩種時間卷積結構的模型;注意力機制的嵌入對模型性能也有一定提升。因此,本文在與其他動作識別算法的對比過程中,均使用卷積核為1、5、9 的參數設置。
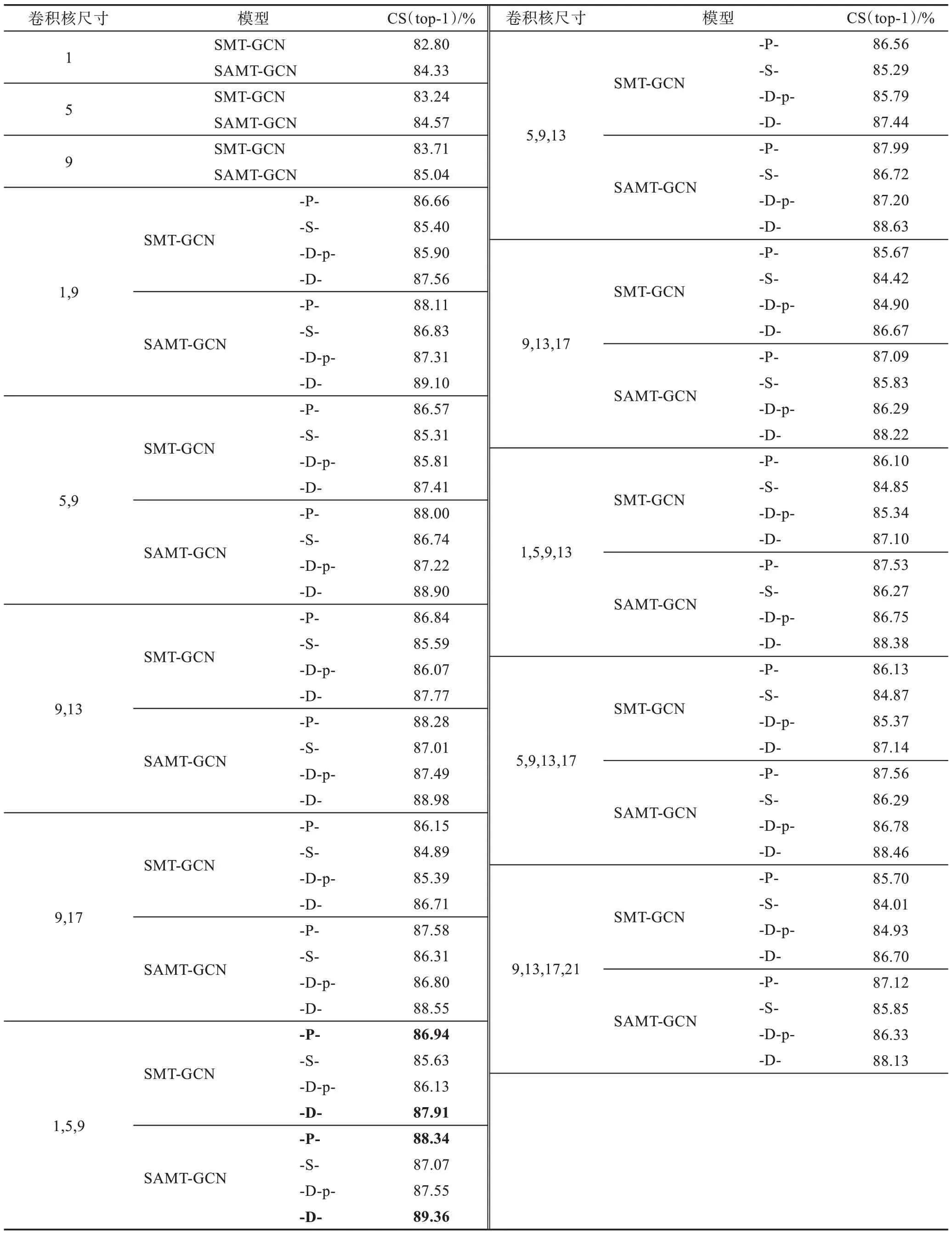
表6 消融實驗結果Table 6 Results of ablation study
4 結束語
為了提高基于骨骼數據的人體動作識別精度,本文設計提出了多尺度時空圖卷積,增強了時間特征提取;基于Transformer 構造了變換殘差機制Tran-Res,并分別融合于空間和時間圖卷積中,強化了人體長距離關聯依賴信息;另外,模型還融合了通道空間注意力(CBAM)模塊。多尺度時空圖卷積模型既全面地提取了時間特征,又強化了人體關聯信息以及關鍵節點和空間結構化特征,提高了基于骨骼數據的人體動作識別模型性能。在實驗過程中,對不同的卷積核尺寸以及不同的多尺度時間卷積層結構進行了消融對比實驗。結果表明,具有稠密和并行結構且卷積核大小為1、5、9 的時間圖卷積模型性能最優;設計的多尺度時間卷積結構可以作為策略模塊融合于其他基線中,并有效提升基線性能。另外,實驗結果表明,本文網絡在進行大規模數據訓練后的結果要好于在小規模數據集上的訓練結果。多尺度時空圖卷積模型提升了人體動作識別精度,但在上下文關系的利用上,仍有欠缺,對關聯特征相距較遠的特殊動作(如“拍手”)的識別仍有待加強。今后的工作,將在本文的基礎上,從全局上下文關系的角度對算法進行改進,以進一步提升基于骨骼數據的人體動作識別精度。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
