基于深度學習的容器化Flink上下游負載均衡策略研究
2023-03-15 03:50:44艾力卡木再比布拉段曉東
大連民族大學學報 2023年1期
艾力卡木·再比布拉,甄 妞,黃 山,段曉東
(大連民族大學 a.計算機科學與工程學院;b.大數據應用技術國家民委重點實驗室;c.大連市民族文化數字技術重點實驗室,遼寧 大連 116650)
在現今的社會,大數據處理廣泛應用于電子商務、O2O、物流配送等領域,協助企業不斷地發展新業務,創新運營模式。Flink[1]作為新一代的大數據計算引擎,能夠以數據并行和流水線的方式執行批處理和流處理任務,相較于上一代大數據處理框架Spark,具有低延遲、高吞吐、高性能等優勢。隨著Docker[2]容器技術的發展,Flink等大數據應用都逐漸走向容器化。并且利用Kubernetes[3]等編排工具去管理容器化應用。
由于Flink集群有異構性并且Flink本身沒有均衡負載的能力,很多學者利用RNN、LSTM[4]等機器學習技術去提前預測負載并進行調度。文獻[5]通過區域劃分和基于人工螢火蟲優化的算法實現負載均衡。文獻[6]設計了雙向的LSTM來對云計算資源的動態變化的復雜特性進行預測。文獻[7]將ARIMA與自回歸神經網絡相結合,對云服務器上的實時資源情況進行預測,實驗證明,該模型與其他單一模型相比,預測結果更加精確。文獻[8]提出了Flink環境下基于負載預測的彈性資源調(LPERS-Flink)策略。文獻[9]通過將超載節點上的容器遷移到低負載節點,降低系統通信開銷,提升集群的吞吐量與計算效率。文獻[10]通過優化支持向量機構建負載預測模型,對單步與多步云計算資源負載進行預測分析。文獻[11]使用遞歸神經網絡RNN來實現對云工作負荷的預測,通過Google Cloud Trace數據集上的實驗驗證了該方法的準確性。文獻[12]首先使用ARIMA模型進行預測,再使用ENN模型對ARIMA誤差進行預測,最終得到修正后的預測值。該文獻提出的組合預測模型有效提升了云環境中工作負載預測的精度。文獻[13]提出了一種基于自回歸移動平均模型ARIMA與長短期記憶網絡LSTM的組合預測模型,預測精度相比其他預測模型有明顯的提升,降低了云環境中對資源負載的實時預測誤差。
容器化部署Flink時,由于下游算子所在容器無法預知上游算子傳輸的數據量,導致上下游算子的容器內存分配不均衡問題。針對此問題,本文提出基于深度學習的容器化Flink上下游負載均衡框架,提出C-BiLSTM預測模型,使用CEEMDAN分解方法和BiLSTM相結合的預測方法預測Flink下游所需內存利用率,并依據預測結果對下游容器的伸縮操作。
1 負載均衡系統
1.1 問題描述
Flink中TaskManager結構如圖1。Flink中每一個TaskManager是一個JVM進程,它可以啟動多個獨立的線程,來并行執行多個子任務(subtask)。TaskManager的計算資源是有限的,并不是所有任務都可以放在一個TaskManager上并行執行。并行的任務越多,每個線程的資源就會越少。為了控制并發量,Flink需要在TaskManager上對每個任務運行所占用的資源做出明確的劃分。由于下游算子所在容器無法預知上游算子傳輸的數據量,導致上下游算子的容器內存分配不均衡問題。

圖1 Flink中TaskManager結構
1.2 架構概述
系統架構如圖2。Flink提交作業到伸縮模塊和Kubernetes集群上,監控模塊獲取節點數據并傳給預測模塊進行數據處理和預測任務。預測結果傳回到伸縮模塊進行伸縮,最后傳給Flink進行容器的初始化操作。

圖2 系統架構圖
本文提出的負載均衡策略由監控模塊、預測模塊和容器伸縮模塊構成。監控模塊獲取到容器資源負載數據,傳送給預測模塊,預測模塊對時序列數據進行數據的預處理并預測下游容器所需要的內存利用率,并把預測結果傳給容器伸縮模塊,最后伸縮模塊根據預測的結果提前對下游的容器數量進行伸縮操作來避免上下游之間的負載不均衡。模塊之間的交互流程如圖3。

圖3 模塊之間的交互流程
監控模塊本文采用Prometheus監控組件監測集群負載信息,框架圖如圖4所示。在容器中部署Prometheus目標,收集部署Flink的容器的CPU負載信息,這些信息由Pushgateway收集匯總。利用Prometheus的服務發現組件,連接Kubernetes收集容器的內存負載信息。Prometheus服務器部署在集群的主節點上,分別從Pushgateway和服務發現組件中拉取CPU及內存負載信息,并將這些信息保存到TSDB數據庫中。收集的信息由Grafana導出到預測模塊處理。

圖4 Prometheus體系架構圖
1.3 資源負載預測模塊
資源負載預測模塊主要作用是對容器的監控數據進行預測分析,預測容器資源未來負載情況,然后將預測結果發送給資源伸縮模塊,為資源伸縮工作提供決策支持。
(1)數據預處理。數據預處理首先獲取監控數據中的時間序列數據后,對此進行重采樣,并刪掉數據不合法的值。在對數據進行填充缺失值操作。數據預處理過程的偽代碼見表1。

表1 容器資源負載時間序列預處理過程
(2)負載預測。本文提出一種組合預測模型C-BiLSTM模型,將CEEMDAN方法和BiLSTM模型結合,使得分析時間序列變得更加精確。CEEMDAN方法可以有效分析時間序列中的信息,將時間序列分解為不同的頻率、趨勢特征的分量,彼此之間相互獨立。因此使用CEEMDAN方法進行時間序列特征分析可以減少預測誤差,增大預測精度。BiLSTM模型具有強大的學習能力,可以有效地針對容器中的資源負載時間序列進行預測,獲得精準的預測結果。C-BiLSTM模型的預測流程,其主要步驟如圖5。

圖5 C-BiLSTM模型流程圖
基于CEEMDAN方法將原始時間序列分解為一系列的IMF分量和res殘差序列,其中IMF分量就是原始時間序列中不同趨勢特征的分量,而res殘差序列就是原始時間序列的長期的,整體的變化趨勢;將IMF分量和res殘差序列分別作為BiLSTM模型的輸入,進行訓練和接收預測值,最后得出預測結果;LSTM結構如圖6。LSTM用內部自循環結構來控制信息流,通過輸入門、遺忘門、輸出門三個非線性門控單元和一個記憶單元來控制信息的流通和損失。遺忘門由一個sigmod神經網絡層和一個按位乘操作構成,用來遺忘一些不必要的信息,遺忘門決定了上一時刻細胞狀態中的哪些信息將被遺忘。記憶門由輸入門與tanh神經網絡層和一個按位乘操作構成,與遺忘門相反,記憶門決定輸入信息x(t)和上一時刻輸出信息h(t-1)中的哪些信息被保留。輸出門與tanh函數以及按位乘操作共同作用將細胞狀態和輸入信號傳遞到輸出端。LSTM無法編碼從后向到前向的信息,因此本文使用由前向與后向LSTM組成的BiLSTM模型。BiLSTM網絡就是在LSTM網絡中使用兩套連接權重分別沿前向時序和后向時序對同一序列進行建模。BiLSTM網絡結構圖如圖7。x(t)表示序列中第t幀的特征向量,其中t=1~T,T是樣本序列中的總幀數。在BiLSTM網絡中x(t)被LSTM網絡分別沿前向時序和后向時序處理并輸出信息h(t)。對得到的各個IMF分量和res殘差序列預測結果進行合并,合并計算過程如公式(1)。
(1)

圖6 C-BiLSTM模型流程圖

圖7 BiLSTM網絡結構圖
容器資源負載模型訓練偽代碼見表2。讀取監控獲取的容器資源負載數據,經過對此數據預處理后進行CEEMDAN分解,得到IMF分量和res殘差序列并進行檢查有無異常,將分量后的數據交給BiLSTM網絡進行訓練,最終得出預測結果。

表2 容器資源負載模型訓練流程
1.4 容器伸縮模塊
本文的伸縮模塊是基于預測模塊的輸出并提前進行調整下游容器數量來達到上下游負載均衡的目的。從預測模塊獲取到預測結果,計算下游容器數量是否需要進行伸縮操作。并按照判斷結果,提前對下游容器數量進行伸縮操作。本文容器伸縮模塊的流程如圖8。
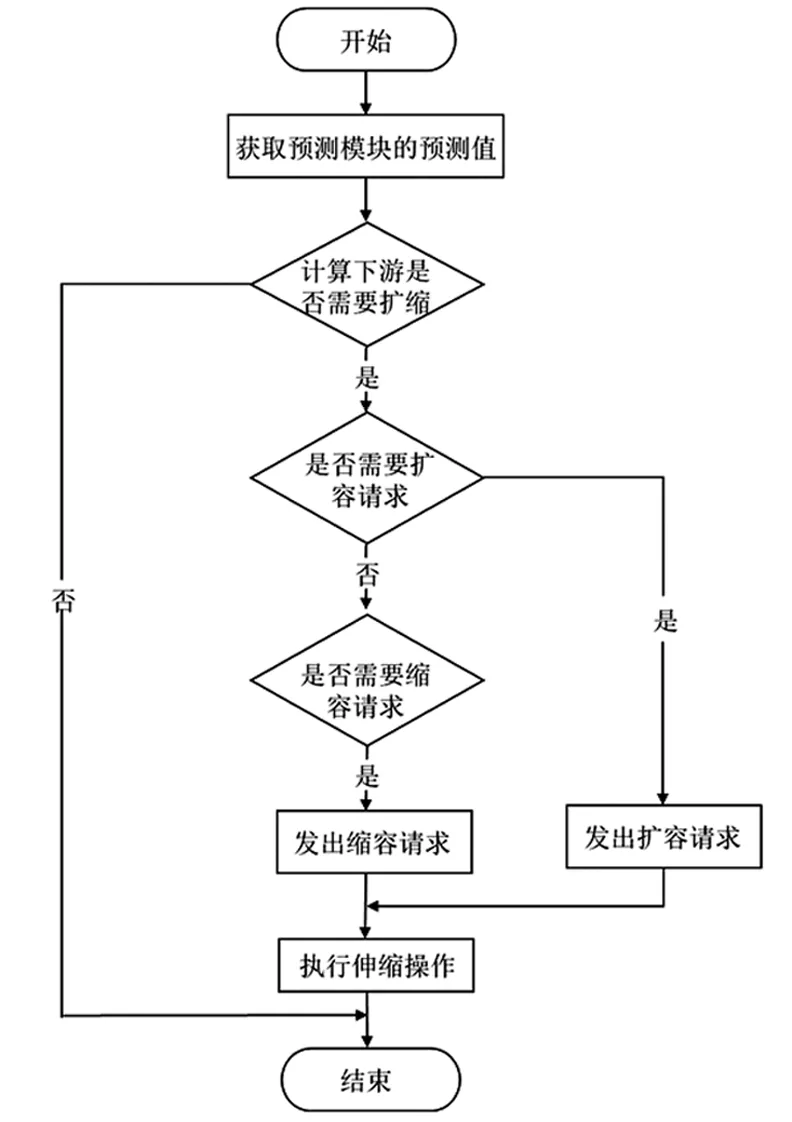
圖8 容器伸縮模塊流程圖
2 實驗測評
2.1 實驗環境配置實驗在兩臺云主機所組成的集群上進行,采用一主一從結構,實驗環境見表3。

表3 實驗環境
2.2 數據集和預處理
為了驗證本文提出的C-BiLSTM模型的資源負載預測效果,使用了通過監控Flink作業的上游容器工作負載得到的數據集來進行資源負載預測實驗,數據集包含了一系列真實場景下的工作負載,本數據集包含的指標有容器的CPU利用率和內存利用率以及磁盤利用率。CPU利用率是集群信息中的重要指標,由于Flink內部上下游容器是共享整個pod的CPU資源,所以本文主要預測指標是內存利用率。
2.3 實驗結果與分析
在對本文模型進行訓練之后,使用本文模型對15個采樣點的數據進行了預測,預測結果與真實值的對比如圖9。本文模型與真實值的數據非常接近,預測誤差非常小,即使是在面臨突發負載時預測效果也很好,大部分采樣點的數據曲線貼合效果比較好,證明了本文模型具有很好的預測效果。

圖9 真實內存利用率與預測內存利用率對比
本文方法預測的下游所需容器數量與實際所需窗口數量的對比如圖10。可以看出預測下游容器數量并且與實際所需容器數量基本的誤差很小,驗證了本文提出的伸縮策略的有效性。

圖10 實際下游所需容器數量與預測下游
為更好的說明本文模型的預測效果,選取了三種不同模型RNN、LSTM和EMD-LSTM作為對比模型,然后與本文模型進行對比驗證,這些模型的預測誤差指標值對比如圖11。本文提出的C-BiLSTM模型的所有預測誤差指標都要低于三個對比模型,并且要比EMD-LSTM模型誤差要更低,說明本文模型的預測誤差都很低,使用CEEMDAN方法來對時間序列的分解進行優化也是有效的。說明本文提出的C-BiLSTM模型可以針對時間序列數據,有效地對時間序列數據進行處理,消除數據的波動性,從而提高了Flink上下游負載序列的預測精度,降低預測誤差。

a)不同模型內存利用率均方根誤差(RMSE)

b)不同模型內存利用率平均絕對百分比誤差(MAPE)圖11 不同預測模型內存利用率誤差對比
不同數據規模數據的運行時間如圖12。提出的基于C-BiLSTM模型之負載預測的彈性伸縮策略明顯比Flink減少了約20%的運行時間。

圖12 不同數據規模任務運行時間對比

圖13 不同類型任務負載運行時間對比
為驗證負載均衡策略的有效性,使用WordCount、PageRank和TeraSort三種不同類型的計算任務來對策略評估,結果如圖13。從實驗結果可以看出,本文提出的伸縮策略與Flink默認算法比,在運行時間上,均有一定的優化效果。其中,在PageRank任務上的優化效果最為明顯,這是由于PageRank屬于計算密集型作業,而WordCount屬于數據密集型作業,TeraSort屬于I/O密集型作業,后兩種作業中消耗較多的I/O資源,而本文提出的調度算法在資源均衡方面主要考慮了CPU和內存的使用率,故算法在計算密集型作業上的優勢較為明顯。
3 總結與展望
本文提出的Flink上下游負載均衡策略,通過深度學習的方法對Flink上游容器進行分析來預測下游所需要的內存利用率,以此提前對下游容器數量進行伸縮,使上下游容器的負載進行均衡,減少下游處理時間和上游的等待時間。經實驗驗證,該算法可以緩解下游容器的內存資源不夠的問題,讓任務的處理時間得到了明顯的縮減。受研究環境有限,本實驗僅使用了數據量不夠大的數據集進行實驗。以后需要在更大的數據集及更多流數據上應用,以進一步驗證該策略的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
