分布式氣象大數據快顯技術的設計與實現
2023-03-15 08:46:50雷鳴
計算機應用與軟件 2023年2期
雷 鳴
(天津市氣象信息中心 天津 300074)
0 引 言
隨著氣象業務高速擴展,數據的種類與數據量不斷增長。而與此同時,針對氣象數據的服務性能和響應速度的要求卻越來越高。但目前省級全國綜合氣象信息共享系統(CIMISS),卻是2009年由國家氣象信息中心負責組織建設,集數據收集、分發、處理、存儲和共享于一體。2013年,該系統推廣部署在全國各省級氣象數據中心,并獲得良好應用。但隨著設備老化和技術的落后,目前其數據處理能力已經明顯無法滿足要求[1-3]。但省級部門卻無權針對該系統進行改造。
為了進一步提升氣象數據服務的敏捷性和存儲動態擴展的需求。同時又能夠與CIMISS進行無縫銜接,在充分參考相關行業在解決海量數據查詢的成功方案基礎上[4-8],利用分布式技術[9-11],構建滿足省級特色需求的數據服務中心。同時,利用CIMISS的氣象數據統一服務MUSIC接口(Meteorological Unified Service Interface Community)[12-14],打通多系統之間的壁壘,屏蔽異構環境,提供統一的對外數據服務功能。
1 系統架構設計
通過引入系統面向的四類用戶,結合整個平臺進行管理和監控運行監管體系和平臺建設,并遵循氣象信息標準化體系規范,針對系統的六個層次分別進行了細化與分析,其具體技術架構如圖1所示。

圖1 系統總體框架設計
天津省級數據服務中心的總體設計機構共分為5層:展現交互層、應用功能層、數據存儲層、基礎支撐層與硬件層。
展現交互層:該層是天津氣象大數據共享平臺軟件進行交互的入口,該層主要負責接收用戶提交的輸入請求,通過后端的接口層對業務邏輯層進行訪問,從而獲得、并向用戶輸出可視化響應。
應用功能層:應用功能層則負責接收前端用戶的輸入請求,并以業務邏輯過程能夠理解的方式將其轉化。同時,根據特定的業務邏輯向數據層有序地發送數據請求,并將返回的數據層數據進行解釋和組合,形成用戶所需的信息,最終再返回到展現交互層。這一層在整個應用軟件系統里,是業務邏輯處理與實現的核心。
應用功能層采用基于組件化架構思想進行設計,即將天津氣象大數據共享平臺軟件的業務功能單元封裝成各個相對獨立又互相聯系的功能組件,通過支撐層的調度控制,各功能組件相互配合,協作完成系統的各項任務。
數據存儲層:該層針對氣象數據進行管理,并向應用服務層提供開放式訪問的標準化接口。該層負責提供訪問位于持久化容器中數據的功能,以及涉及從持久化介質中寫入數據或者讀取數據的工作。
基于HBase存儲半結構化混合數據,基于MySQL存儲結構化觀測和預報資料,基于MongoDB存儲非結構化數據,數據存儲層為系統提供對緩存進行管理的功能,在此基礎上,分別對數據庫和文件庫的進行統一的接口封裝,為應用功能層提供統一基于時間索引、空間索引和要素索引的大數據SQL查詢器。
天津氣象大數據共享平臺軟件為加快上層訪問數據存儲層數據/文件的訪問速度,在數據庫與文件庫物理存儲基礎上使用緩存機制。
支撐層:支撐層描述了實現天津氣象大數據共享平臺軟件所使用的技術框架和所采用的關鍵技術,為應用功能層各個業務組件、功能模塊起到支撐與組織的作用。支持層包括兩部分:系統級技術框架及關鍵技術。
系統級技術框架描述支撐整個系統應用功能所使用技術架構,主要包括:展示交互技術框架、自動運行技術框架、地理信息技術框架、OSGI插件微內核技術框架、負載均衡與分布式計算框架和數據存儲技術框架。
關鍵技術指構建系統級技術框架中所采用的技術,主要包括本地客觀預報產品生成技術、網絡協同技術等。
2 可擴展性設計決策
為更好適應未來氣象預報業務發展,系統需具有可擴展性與開放性。可擴展性具體表現為業務可擴展性,可動態加載氣象預報業務算法。
對業務擴展性需求,采用的設計決策是:將具體的算法封裝成動態鏈接庫,與具體的業務邏輯相分離,算法可替換,參數可配置,業務流程可配置。業務流程配置如圖2所示。
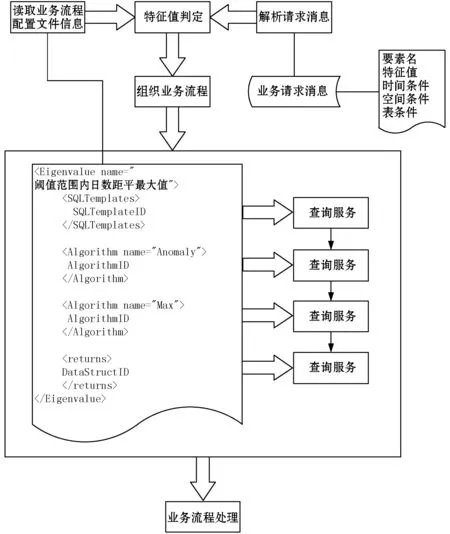
圖2 業務流程配置示意說明
針對系統的擴展性需求,采用設計決策是:業務邏輯及公共服務層與展示層之間功能分離,模塊之間松耦合,分別部署在不同的物理節點,可重用業務邏輯及公共服務層。
3 系統存儲設計
3.1 系統存儲架構設計
為了做到數據與應用分離,使用戶對后臺變動無感。基于MUSIC服務接口,將全部數據庫打通,形成一個邏輯上統一的數據服務中心,對外透過API接口提供服務。整個存儲設計架構如圖3所示。
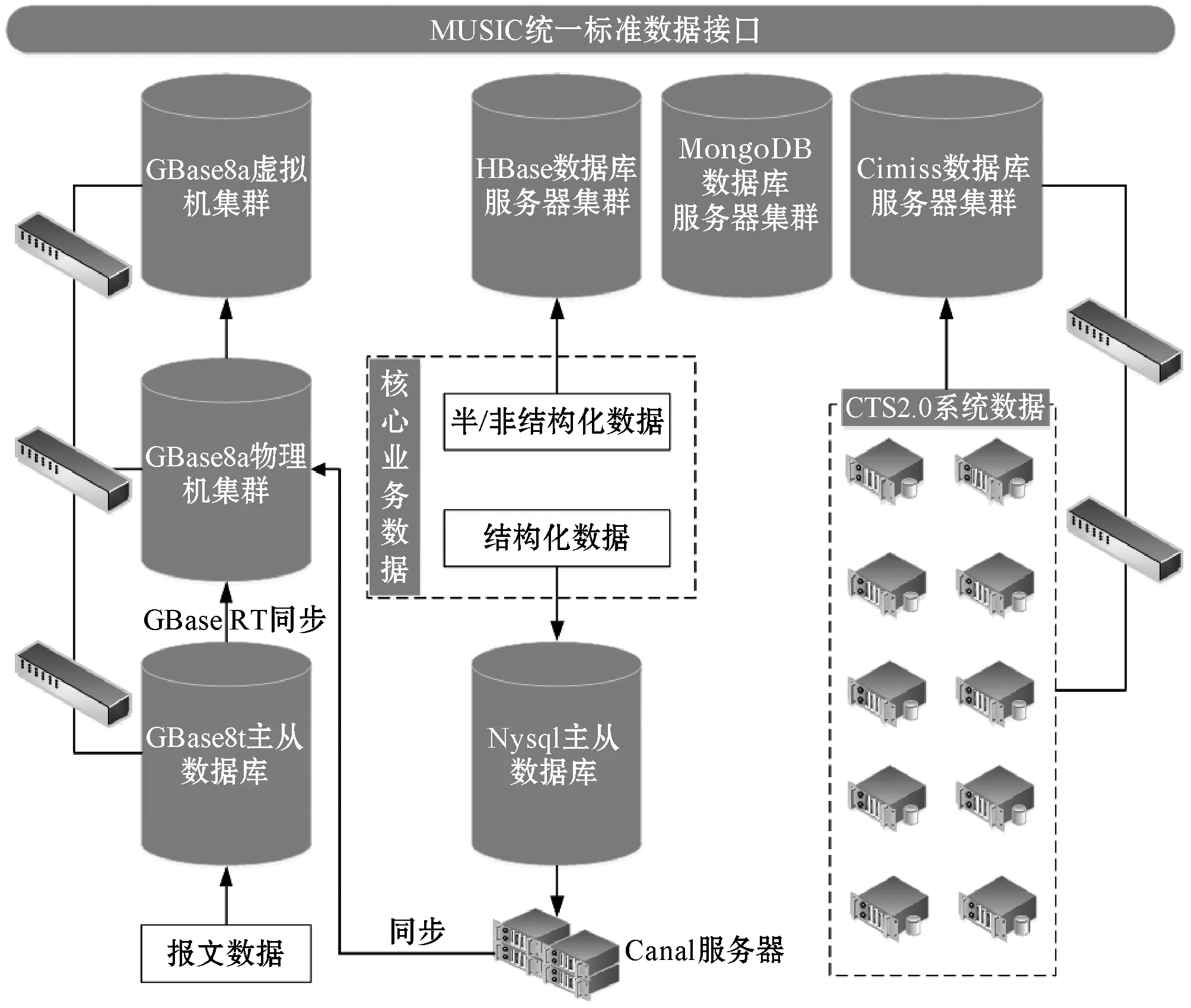
圖3 系統存儲架構設計圖
3.2 數據庫存儲配置
系統涉及到多種數據庫,如MySQL、MongeDB、HBase等。為進一步提升系統響應速度,特別針對各數據庫分別進行了優化處理。限于篇幅,僅以MySQL優化為例:
MySQL提供了一些存儲分配參數,例如:數據庫的大小、鎖的數目,以及使用的緩沖區大小等。但這些分配參數的默認值不能達到天津省級數據服務中心的功能需求。為進一步優化數據庫性能,根據天津省級數據服務中心的特點,針對系統的配置參數進行了如下調整:
[mysqld]
server-id=115
basedir=/mysqldata
datadir=/mysqldata/data
log-bin=mysql-bin
log-bin-index=mysql-bin.index
sync-binlog=1
max-binlog-size=200M
expire_logs_day=3
skip-host-cache
skip-name-resolve
innodb_buffer_pool_size=40G
innodb_log_buffer_size=32M
max_connections=1000
event_scheduler=ON
4 并行加速算法
為了進一步提升數據服務的速度,尤其是涉及到圖形渲染等高密度計算場景時,本文利用并行計算技術進行數據顯示增速[15],如:針對格點數據等值線提取、色斑渲染等功能。天津省級數據服務中心所使用的WebGIS以及其他需要渲染計算等方面,均采用了并行運算。其具體策略為:結合OpenMP的CPU并行計算以及基于OpenCL的GPU并行計算技術,將其應用與氣象格點數據計算處理和氣象信息圖形顯示分析中,提高基于WeBGL地圖渲染的執行效率和運算速度。
4.1 基于OpenMP的CPU并行算法
CPU并行框架底層基于OpenMP編程框架,透過使用計算機的多線程多核處理機制,提供了對CPU并行算法的高層抽象描述,以及線程粒度的控制和負載均衡,具體工作流程如圖4所示。
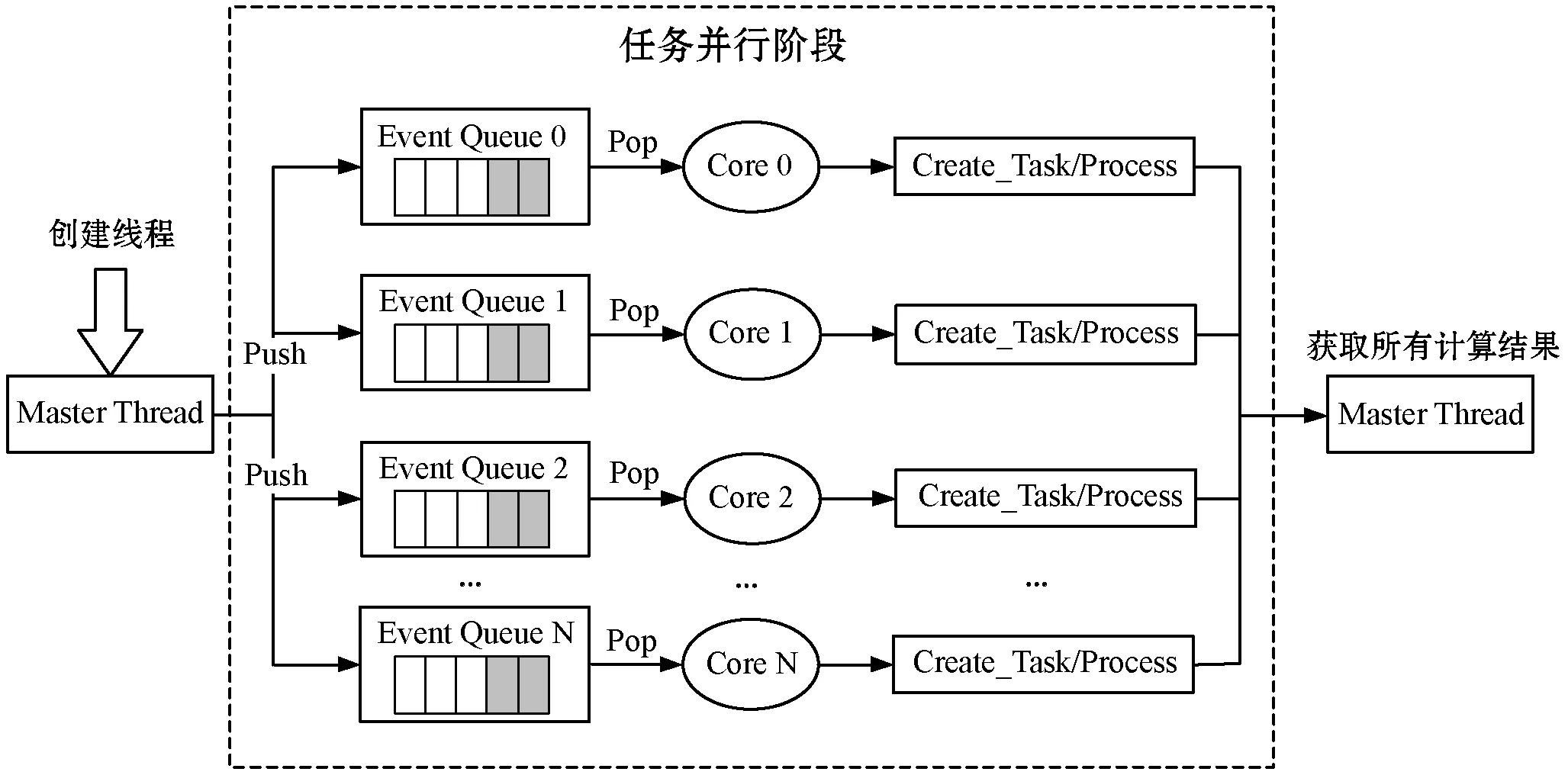
圖4 并行計算工作流程示意圖
OpenMP的算法設計基于如下阿姆達爾定律的最小化串行代碼原則進行:
(1)
式中:a是并行計算部分占用的比例大小,n則是并行處理部分的結點個數,即處理器個數。可以看到,當沒有串行,而僅有并行,即1-a=0時,最大加速比S=n;而當僅有串行,并不存在并行,即a=0時,其最小加速比S=1;最大加速比的上限發生在n→∞時,此時,極限加速比S→1/(1-a)。為了使速度最大化,在并行處理節點個數固定的情況下,應盡可能地提升并行計算部分所占的比例。
OpenMP中的執行模型采用的是fork-join,其中,fork的含義表示喚醒已有線程或者創建線程,而join則代表了多線程的會合。當Fork-join執行模型最初執行時,它僅有一個在運行的線程:即“主線程”(Master Thread)。而當需進行并行計算時,系統則會由主線程派生出新線程來執行并行任務。而此時,主線程與派生線程將會在并行執行階段一同協同工作。當并行運算完結之后,派生線程會自動阻塞或退出,而不再繼續執行,控制流程將會回到單獨的主線程中。當系統涉及高密度數據計算的時候,如:數據渲染和數據時間插值等操作,計算將會由CPU轉到GPU中進行處理。
4.2 基于OpenCL的GPU并行算法
GPU并行計算基于開放運算語言(Open Computing Language,OpenCL),利用GPU強大的浮點數計算能力,輔助CPU完成大規模的并行計算任務。OpenCL可運行在多種不同的平臺之上(Windows、Linux、Unix等),通過對不同平臺底層的抽象與封裝,屏蔽了相異平臺底層的不同設計,并對應用層提供了統一的接口服務。
而GPU渲染常采用構建三角形帶和LOD(多細節層次)技術[16]以減少GPU固有的渲染數據量,則其渲染的數據量公式如下:
(2)
式中:m則是場景模型的總數;ky是Ny縮減的比例;Ny則是單個模型在場景中的總頂點數;x是反射次數;kb是在并行架構下頂點的冗余度系數(在2-3之間);kf是材質種類所固有的反射系數;I是平均光強值;n是場景光源的個數。
設ty為同一線程塊處理面片集合的平均時間,Ab為同一批次處理的渲染數據量,T為處理渲染數據消耗的總時間,則有:
(3)
整體OpenCL并行計算框架的架構設計由設備、上下文環境、程序、內核、內存對象、命令隊列六個部分組成,具體組成如圖5所示。
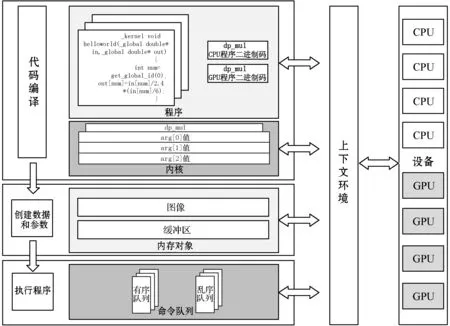
圖5 并行計算系統流程圖
設備:它是并行計算框架中的計算單元,一個GPU或者CPU將會對應一個設備。而設備通過命令隊列,獲取自己需要執行的計算指令。
上下文環境:上下文是一個抽象的容器,是整個并行計算框架的紐帶,上下文環境管理在設備上的列中的有序隊列與無序隊列。只有在一個上下文環境上的系統的設備才能彼此交流工作。
程序:這是所有代碼的集合,包含核函數和其他庫。OpenCl是一個動態編譯的語言,代碼編譯后生成一個中間文件(可根據需要實現為虛擬機代碼或者匯編代碼),在使用時連接進入程序讀入處理器。
內核:這是在設備上運行的核函數及其參數組。為了進一步提升計算速度,在其中特別使用了單指令多數據流技術。這是一種采用一個控制器來控制多個處理器,同時對一組數據(又稱“數據矢量”)里面的每一個各自進行相同操作,從而達到空間上并行性的技術。
內存對象:包括圖像和緩沖區,并行計算需要在不同設備上使用的內存,內存對象由上下文創建,從而實現上下文管理的多個設備,能夠將內存對象中的數據進行共享。
命令隊列:這是上下文環境給每個設備提交的指令序列,通過命令隊列,上下文環境將需要執行的指令,發送到每個設備上。在順序執行命令隊列里(默認),命令將會按照接收的順序壓入到命令隊列中。亂序隊列允許OpenCL在實現時重排命令以便高效地執行。如果使用亂序隊列,須指定依賴關系以確保正確地執行順序。
OpenCl執行分為三個階段,第一個階段進行代碼編譯,創建上下文環境以及命令隊列,生成內核與程序,并完成設備的初始化;第二個階段創建參數和數據,上下文環境創建內存對象,并將計算需要使用的數據寫入其中;第三個階段上下文環境將需要執行的計算指令發送到命令隊列中,并等待設備計算完成。設備計算完成之后,上下文環境讀取內核對象處理的結果(存放在內存對象中),并釋放資源。
5 實踐與測試
為大數據分布式存儲數據中心的數據服務能力,特別對其進行了綜合測試。測試使用的硬件配置為:CPU i5- 3470 3.20 GHz,內存4 GB,支持谷歌內核的主流瀏覽器,如Chrome。獲得的系統測試指標如表1、表2所示。

表1 基于WebGIS的自動站顯示指標
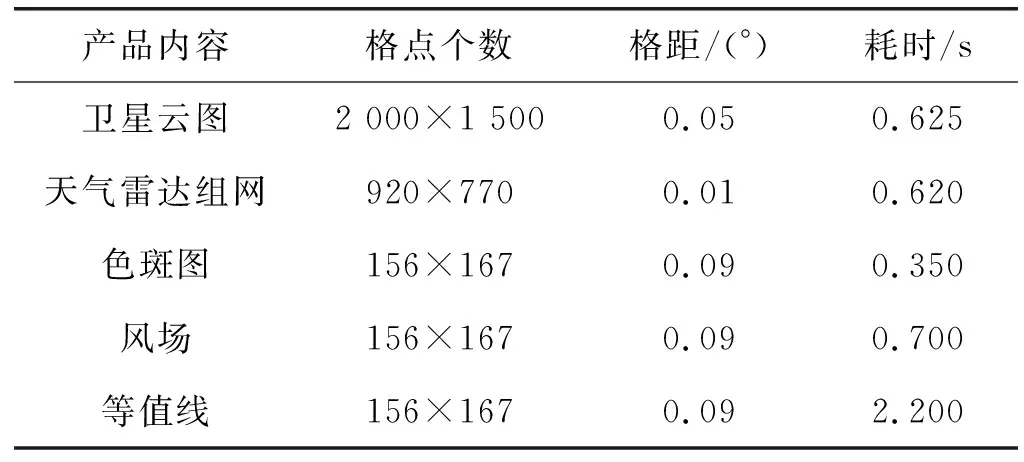
表2 基于WebGIS的數據渲染顯示指標
為了進一步獲得系統的查詢性能,特別針對頁面響應速度進行了測試,獲得如表3所示的各項數據查詢結果。
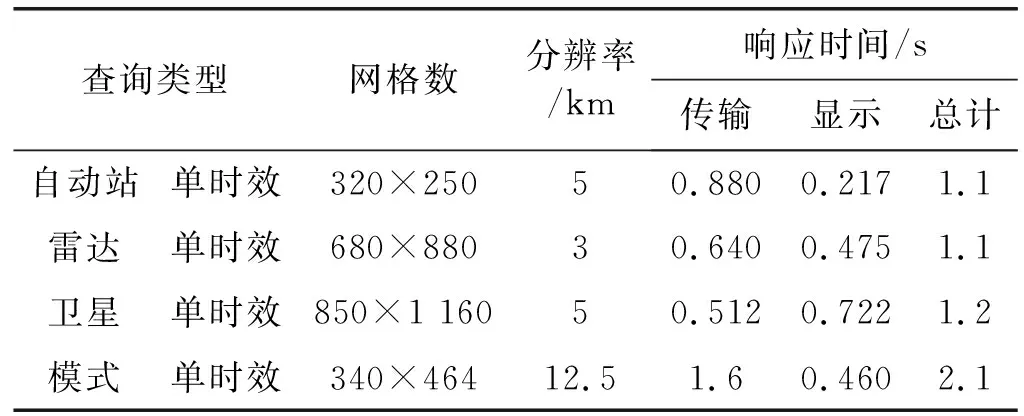
表3 頁面查詢響應速度表
其中,查詢類型為常規產品中的典型查詢項目,而響應時間中的顯示則為第1次的顯示耗時。頁面的響應速度比基于CIMISS的速度平均提升了860%。下面展示了幾類不同的查詢顯示效果圖。

圖6 自動站實況溫度查詢效果圖
圖7 EC集合統計量:24小時降水
6 結 語
本文在不改變現有業務系統和系統架構的基礎上,基于MUSIC接口,利用分布式和并行計算技術構建了滿足省局氣象需求的大數據環境中心,提高了氣象數據顯示分析過程中各種復雜的氣象算法運算的效率,并對系統中整個業務流程執行效率和圖形顯示分析的人機交互體驗也有較大的提升,為氣象數據的高質量服務,提供了一個可行的解決方案。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
中國特種設備安全(2022年6期)2022-09-20 02:52:28
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
電子制作(2018年11期)2018-08-04 03:26:08
家庭影院技術(2017年9期)2017-09-26 03:41:45
中國科技論壇(2017年7期)2017-07-25 08:49:53
工業設計(2016年12期)2016-04-16 02:52:00
消費者報道(2014年7期)2014-07-31 11:23:57
