一種基于注意力機制的短臨降雨預報方法
2023-03-15 08:46:54曹文南張鵬程賈旸旸
計算機應用與軟件 2023年2期
關鍵詞:模型
曹文南 張鵬程 賈旸旸
(河海大學計算機與信息學院 江蘇 南京 210000)
0 引 言
降雨受地理位置、氣候、熱力和流場等多因素共同作用而產生,復雜的氣象特性使得降雨成為最難預報的天氣要素之一[1-2]。強降雨是其中形成最為復雜的一種情況,隨著氣候不斷變暖,強降雨事件發生的概率將不斷增加[3]。強降雨天氣主要造成滑坡、泥石流和洪水等自然災害,每年由于強降雨引起的災害都會導致生命和基礎設施的嚴重破壞和損失[4]。準確及時的降雨預報對農業生產和城市生活工作具有重要作用。
預報降雨的方法主要分為三類:(1) 根據物理定律結合超級計算機求解軌跡方程的NWP方法;(2) 統計學方法;(3) 機器學習方法。傳統的NWP方法求解物理軌跡方程極其復雜,需要消耗大量的計算資源和時間,由于一些初始條件和邊界條件的不確定性使得預報存在不及時、不夠準確的情況。統計學方法如灰色預測模型GM[5]和自回歸積分滑動平均模型ARIMA[6-7]等。文獻[8]將降雨量作為ARIMA模型的輸入,運用信息準則法中的BIC確定模型的階數,有效預測了城市降雨。這些方法能夠對降雨序列進行擬合并做出預測,但是較少考慮氣象因子對降雨量的影響。機器學習方法通過更新神經元的參數來學習地理位置、氣候條件等物理參數和雨量的關系,使得預報降雨的精度進一步提升。隨著人工智能領域的發展,機器學習方法在降雨預測領域取得了很好的效果[9-10],降雨預報中常見的機器學習方法主要包括誤差反向傳播神經網絡BPNN[11]、多層感知器MLP[12]、支持向量機SVM[13]、深度置信網絡DBNN[14]和長短期記憶網絡LSTM(Long-Short Term Memory)[15]等。文獻[16]利用改進的BP神經網絡預測城市降雨量,并且分析了不同氣象因子對于降雨的影響程度。文獻[17]充分挖掘水文時間序列中各隱藏要素的特征,建立了一種有效的基于深度信念神經網絡的降雨量預測模型,并以貴州遵義地區的氣象數據進行了驗證。文獻[18]建立了一種動態區域感知的降雨預報網絡,并在全國56個地區進行實驗證明了模型的有效性。此外,深度學習的廣泛應用使得利用雷達回波外推進行臨近預報的方法不斷有新的進展。文獻[19]提出一種卷積長短期記憶網絡ConvLSTM預測降雨,該模型由一個編碼網絡和一個預測網絡構成,兩個網絡都是通過堆疊多個ConvLSTM層形成,減小了外推光流矢量中存在的累計誤差,提高了模型預測的準確率。文獻[20]提出一種預測遞歸神經網絡PredRNN,該網絡核心是一個時空長短期記憶網絡ST-LSTM,可以同時對空間和時間信息進行提取和記憶,該方法的優良性能在雷達回波數據集上得到了驗證。
目前,基于深度學習的降雨預報模型通常以站點的氣象因子和降雨值作為網絡的輸入和輸出,缺少對因子重要性評估及網絡特征表現的工具。現有方法對中長期降雨預報(12 h以上)的準確率有一定提升,但對于短臨降雨(0~12 h內)尤其是短臨強降雨(單位小時內16 mm及以上)樣本存在預測不精的問題。針對現有短板,本文提出一種基于含注意力機制LSTM的短臨降雨預測模型SRF(Short-term Rainfall Forecasting model),首先計算反映目標站點長期氣候狀況的標準化降水指數SPI,解決了數據集中少量強降雨樣本導致相關信息匱乏的問題,通過隨機森林算法篩選出與降雨最相關的氣象因子,減少無關信息對預測精度的影響。同時構建帶有注意力機制的長短期記憶網絡,將因子輸入網絡中訓練得到未來3 h內的降雨量。本文方法關注因子包含的降雨深層語義信息并針對強降雨特性在模型中進行了改進,嘗試提高短期降雨預報的準確率,并對模型訓練權重進行可視化。實驗結果驗證了本文方法的有效性。
1 多頭注意力機制
注意力機制是模擬人類視覺的注意力演化而來的,能夠尋找網絡中需要關注的信息并根據信息的重要程度進行加權。注意力機制在自然語言處理、語音識別、圖像識別領域都有廣泛的應用[21-22]。研究者根據不同需要研究出了各種形式的注意力機制。多頭注意力(Multi-Head Attention,MHA)可以有效地在網絡中關注多個子空間的信息,并行化計算多次注意力提升網絡的訓練速度,從多個維度捕捉序列信息的關鍵信息。多頭注意力機制的結構如圖1所示。
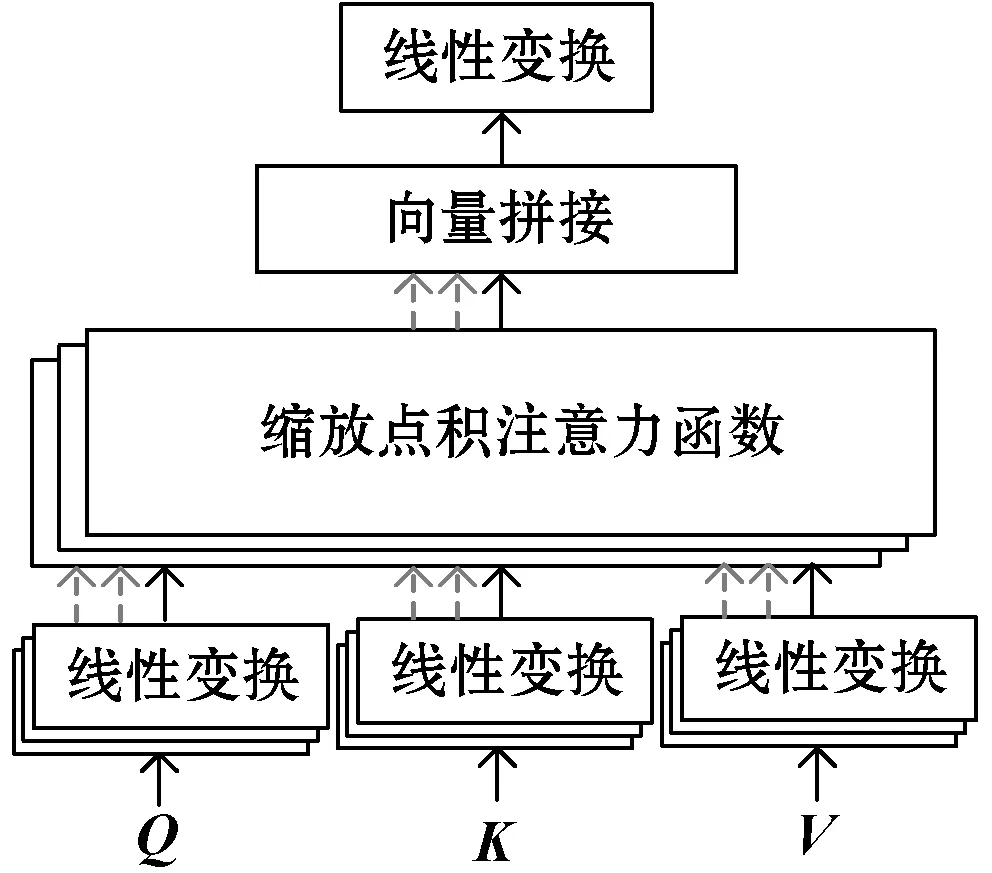
圖1 多頭注意力結構
目標序列向量為Q,K為鍵向量序列,V為鍵向量對應的值的序列,Q、K、V序列經過線性變換后輸入到縮放點注意力(Scaled Dot-product Attention,SDA)中進行向量的點積相乘,計算方法為:
(1)
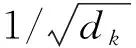
(2)
Z=Concat(head1,head2,…,headh)WO
(3)
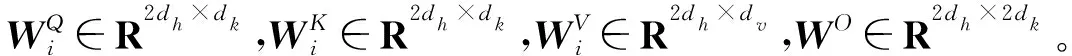
2 長短期記憶網絡
長短期記憶網絡(LSTM)在循環神經網絡(RNN)中增加了多個記憶單元,LSTM的記憶單元解決了原始RNN訓練時存在的梯度消失問題和梯度消失所導致的長期依賴問題。LSTM結構形態分為三層,輸入層、隱含層和輸出層。圖2是一個LSTM的結構示意圖。
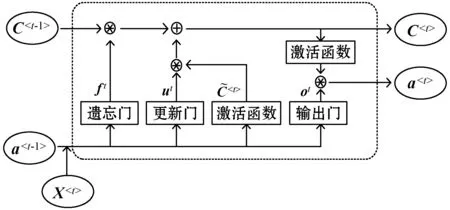
圖2 LSTM網絡結構
圖2中,a
ft=σ(Wf[a
(4)
式中:σ為sigmoid激活函數;Wf為權重矩陣;[,]表示把兩個向量拼接;bf為遺忘門的偏置項。
更新門ut確定需要更新的信息和新的加入信息,公式為:
(5)
ut=σ(Wu[a
(6)
式中:WC、Wu為權重矩陣;bc、bu分別為輸入節點和更新門的偏置項。更新后新的記憶單元C
(7)
輸出門ot經過激活函數后得到最終的輸出為a
ot=σ(Wo[a
(8)
a
(9)
式中:*表示元素乘法;Wo為權重;bo為輸出門的偏置項;tanh()為雙曲正切函數。
3 短臨降雨預測預報模型
本文首先計算目標站點的標準化降水指數,利用隨機森林算法計算出氣象因子與降雨的相關程度,根據重要性動態篩選出與降雨密切相關的因子作為帶有多頭注意力的長短期記憶網絡SRF的輸入,預測目標未來3 h內的降雨量。模型建立主要分為三個部分:數據預處理與SPI計算、因子篩選與網絡建模、權值可視化與模式對比。SRF模型建立過程如圖3所示。

圖3 SRF模型建立流程
3.1 數據預處理與SPI計算
在對數據集中的物理參數進行分析和選取后,主要收集了12個氣象因子,如表1所示。
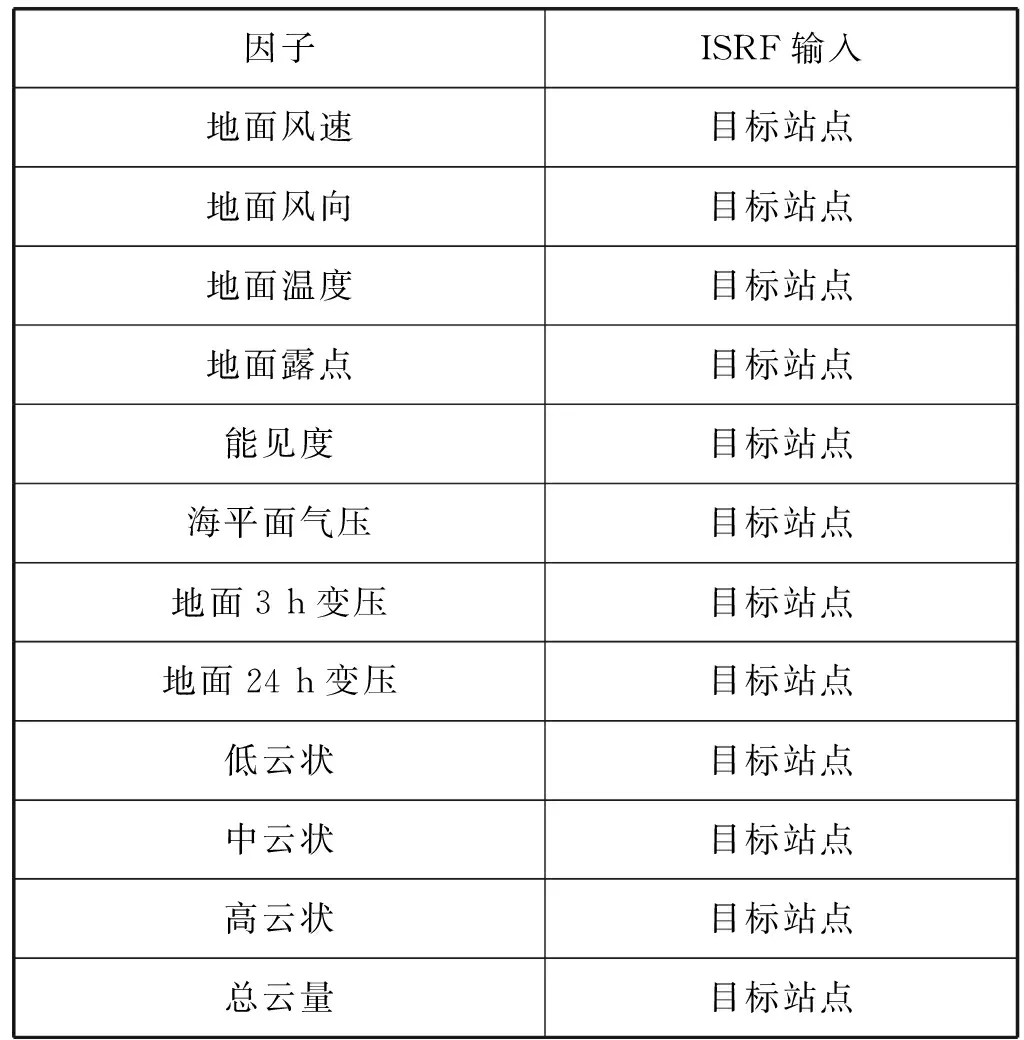
表1 氣象因子和模型輸入參數
SPI指數是反映地區旱澇時空特征的重要氣象參數[23],能夠反映目標區域在一定時間尺度內的降雨情況,靈敏表現區域的氣候特征,是評估目標區域降雨量或短時強降雨等極端天氣情況的重要參考指標,有效提高模型對強降雨特征的敏感程度,解決了數據集中強降雨樣本較少導致模型對強降雨特性學習能力較弱的問題。SPI將一段時間尺度的降雨序列服從gamma分布,通過分布概率密度函數推算求得累積概率,最后將累計概率轉化成標準正態分布。設某一時段的降雨量為x,則其τ分布的概率密度函數為:
(10)
式中:α為形狀參數,β為尺度參數,α與β采用極大似然法估計參數;τ(α)為Gamma函數。
(11)
(12)
(13)
H(x)=q+(1-q)G(x)
(14)
(15)
(16)
式中:q表示降雨量為0的概率;G(x)為在該時間段小于降雨x的概率。
將累計概率H(x)轉換成標準正態分布函數,計算待測站點的標準降水指數SPI值。
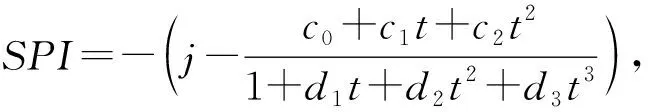
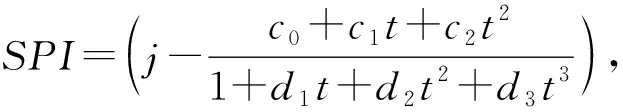
式中:co=2.515 517,c1=0.802 853,c2=0.010 328,d1=1.432 788,d2=0.189 269,d3=0.001 308。
由于各個因子的數值區間處于不同的數量級,歸一化可以將數據標準化到[0,1]之間防止某些指標被忽視,影響數據分析的結果。歸一化的計算方法如下:
(17)
式中:x*為輸入樣本歸一化后的值,x表示原變量序列中的某個值;xmax和xmin分別為變量中的最大值和最小值。
3.2 因子篩選與網絡建模
隨機森林算法是一種常用的機器學習算法,能夠很好地解決回歸和分類問題,它采用自助采樣的方法生成眾多并行式的分類器,多個分類器的結果通過“少數服從多數”的原則來確定最終的決策結果。由于每一個決策樹互不干擾,所以在算法訓練時可以高度并行化,隨機選擇決策樹節點對特征進行劃分可以有效地對高維數據進行降維訓練。隨機森林算法的基本步驟如下:
(1) 從訓練數據集中隨機選出M個樣本,然后放回,進行N次取樣,每一次取樣生成一個訓練集,得到N個訓練集。M為設定的訓練集中的樣本數量,N為設定的訓練集數量。
(2) 對于每一個訓練集,訓練一個決策樹模型。
(3) 每一個決策樹模型持續分裂,直到該節點的所有訓練樣例都屬于同一類。在分裂的過程中保留決策樹的完整性,不對決策樹進行剪枝操作。
(4) 生成的n棵決策樹組成隨機森林,按多棵樹分類器投票決定每個因子最終的權重大小。
LSTM能夠保存長時間降雨序列的歷史信息,LSTM中加入多頭注意機制強化了模型對于降雨關鍵信息的敏感程度。SRF結構如圖4所示。
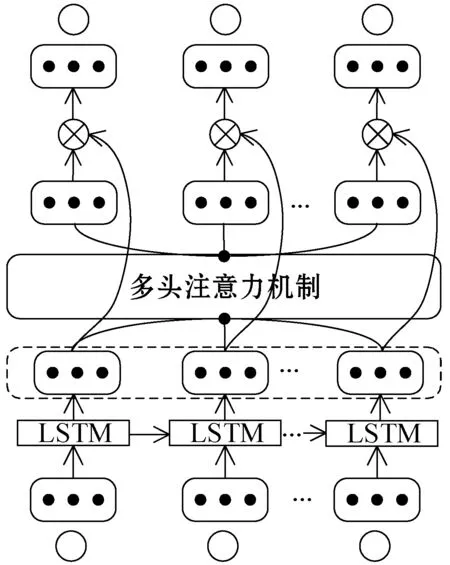
圖4 SRF網絡結構
輸入降雨序列W=(w1,w2,…,wn),輸出預測序列Y=(y1,y2,…,yn)。將篩選得到的因子輸入SRF網絡中,LSTM的輸出作為下一層Attention的輸入,經過LSTM層得到的向量hn與多頭注意力機制形成的向量mt融合形成新的加權向量S,γ、δ作為網絡中的兩個參數,在模型訓練中自動學習。融合公式如下:
S=γ*hn+δ*mt
(18)
為了避免訓練過擬合,本文設置學習率為0.1,droupout率為0.5,最大迭代次數設置為5 000,設定h=9,即進行9次多頭注意力計算。
3.3 權值可視化與模式對比
深度神經網絡又被稱為“黑盒”模型,復雜的網絡構成和隱含層的多樣性使得網絡內部結構與模型輸出之間的關系難以建立。循環神經網絡中加入注意力可以有效提高對于重要因子的關注能力,因子輸入網絡后,隱含層提取因子中的降雨信息并不斷更新神經元存儲的有效信息,因子權重變化的可視化表達展示了網絡對于特征的動態學習能力,可以觀察到不同權重的因子對于結果的影響,當高權重的輸入因子對于輸出的結果具有決定性作用時,則一定程度上認為整個模型的決策是合理的,幫助判斷和理解模型決策結果的有效性。
在模式對比階段,評估所提模型預測降雨能力優劣的判定標準主要考慮兩個方面:預測量級精度和預報概率精度,預測量級精度主要考慮均方誤差MSE和絕對誤差MAE,誤差小可以體現模型在預測量級上的準確性,其計算方法如下:
(19)
(20)
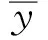
預報概率精度主要考慮TS,中國氣象局規定,TS是短期降雨預報能力的計算方法之一。預報概率較高可以體現模型在分類上具有較高的準確性。TS用于表示正確預測的樣本比例,包括準確預測降雨量或無降雨量。其計算方法如下:
(21)
式中:N1表示預測正確降雨量的樣本數;N2表示預測無降雨的正確樣本數;N3表示預測無降雨但實際降雨的樣本數;N4表示預測降雨但實際上沒有降雨的樣本數。Acc用于表示正確預測強降雨樣本的比例,是評估模型強降雨預測能力的重要指標,N5表示預測強降雨正確的樣本數,N6表示預測無強降雨但實際有強降雨的樣本數。Acc計算方法如下:
(22)
4 實 驗
4.1 實驗設置
本文算法實現在Pycharm平臺上完成,計算機CPU為Intel i7- 8750H,內存為16 GB。
本文實驗數據包括中國氣象局發布的2015年至2017年地面填圖數據,該文本數據集按照氣象站點排列,可以按照地區編號提取數據。在比較準確率時使用ECMWF(European Centre for Medium-range Weather Forecasts)和JAPAN數值模式2017年發布的逐3 h降雨預報數據。這種數據是按照經緯度排列的格點式文本數據,可以根據經緯度提取相應地區的降雨預報值。實驗選擇全國92個大型氣象站點作為預報對象,這92個地區均有地面氣象觀測站和雷達探空站。
4.2 因子選取
數據集輸入到隨機森林中計算各氣象因子的權重大小,在單個決策樹模型進行分裂時,采用基尼指數選擇最好的特征進行分裂。基尼指數的計算公式為:
(23)
式中:訓練樣本特征的個數為a,分為K個類,樣本點屬于第k類的概率為pk,實驗設置a=12,K=2。因子篩選個數根據模型訓練結果進行動態擇優,實驗選出的9個因子和各因子對于降雨的平均權重如表2所示。
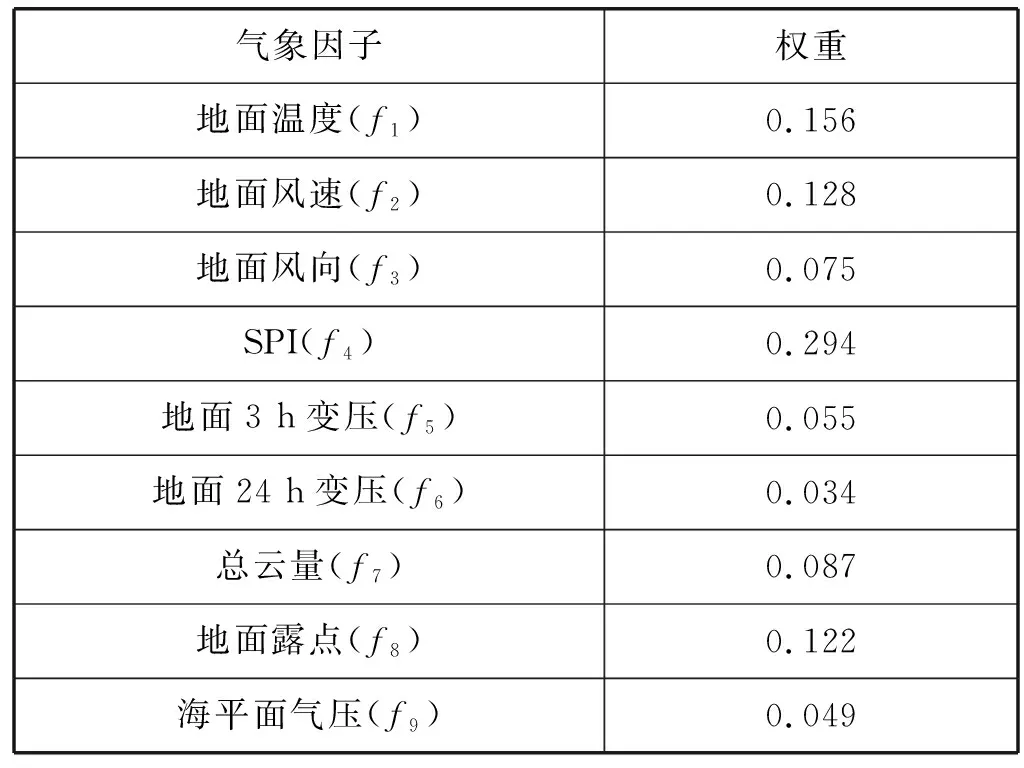
表2 模型輸入的氣象因子和權重
4.3 模型可視化
輸入因子權重在網絡中的動態變化解釋了模型的迭代學習能力,實驗使用熱力圖對網絡中因子的參數變化進行可視化實現。圖5(a)至圖5(f)為連續六個時刻的因子權重變化圖,橫坐標f1,f2,…,f9為輸入模型的因子,縱坐標t,t-1,…,t-9為歷史時刻。色塊顏色深淺表示因子權重大小。因子對于降雨影響程度越大,則色塊顏色越深。白色代表權重影響最小,黑色代表權重影響最大。

(a) (b)

(c) (d)
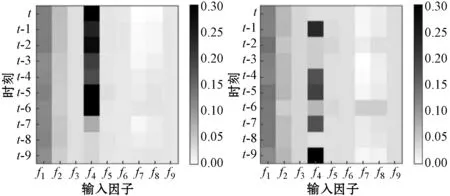
(e) (f)圖5 因子權重可視化
可以看出網絡在動態訓練時因子的注意力權重與使用隨機森林算法篩選因子時計算的大小順序一致,符合模型的預期結果。當使用權重擦除法將權重大小刪去其中一個因子進行訓練時,預報準確率下降的程度與權重大小呈正相關。因子權重的可視化展示了模型訓練時參數的動態變化過程,增加了模型透明度,提高SRF的可理解性。
4.4 實驗結果和模型對比
本文將所提模型SRF與不帶多頭注意力機制的LSTM模型用相同的數據集進行訓練,LSTM層使用相同的結構和參數設置。SRF與LSTM的網絡損失值與迭代次數的關系如圖6所示。當迭代次數達到5 000時,SRF和LSTM的預測結果趨于穩定,帶有多頭注意力機制的SRF比LSTM有更低的損失值,說明SRF的降雨預測準確率更高,驗證了多頭注意力機制能夠強化LSTM網絡對于降雨特性的學習能力,有效提升模型的預測精度。

圖6 SRF降雨預測
為了驗證模型的泛化能力,SRF在全國92個氣象站點進行了實驗,2015年和2016年數據集作為訓練集,2017年數據集作為測試集。將統計模型中的自回歸移動平均模型(ARIMA),機器學習模型中的長短期記憶網絡(LSTM)、支持向量機(SVM)、多層感知器(MLP)作為對比模型,中國氣象局常用的業務預報模型ECMWF、JAPAN也作為對比模型來驗證方法的有效性,各模型的結果見表3。
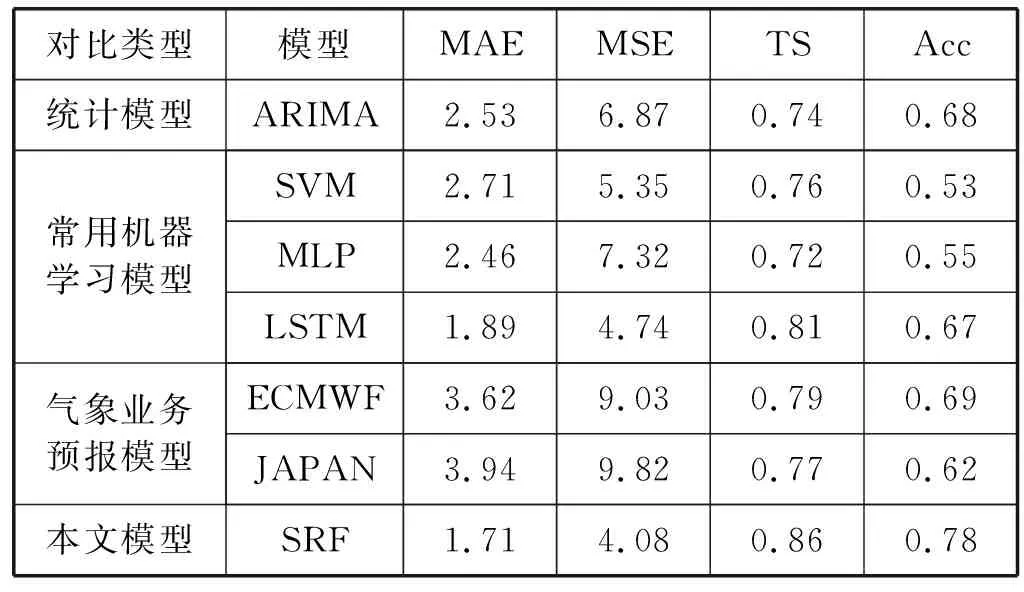
表3 模型對比
SRF降雨預測的準確率為86%,優于其他方法。SRF在短臨強降雨預報上比效果最好的氣象業務模型ECMWF準確率提高了0.09。結果表明,通過引用相關因子和多頭注意力機制,SRF對比傳統的機器學習模型和氣象業務預報模型在預測量級精度和預報概率精度上均有一定提高。
5 結 語
為了準確預測短臨降雨,提高短臨強降雨的預測精度,本文提出一種基于注意力機制的短臨降雨預報方法SRF,基于氣象局數據,利用隨機森林算法計算氣象因子和標準化降雨指數與降雨的權重,動態篩選出影響降雨最密切的因子作為輸入,建立多頭注意力機制的長短期記憶網絡SRF來學習因子中的降雨信息并根據重要程度進行加權處理,預測得到目標站點未來3 h內的降雨量。結果表明,本文方法可以有效提高短臨降雨的預測能力。未來會對雨量進行分級預報,針對性地提高不同量級降雨的預報準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
