遮擋與幾何感知模型下的頭部姿態估計方法
2023-03-16 10:21:36賀建飚
計算機工程 2023年3期
付 齊,謝 凱,文 暢,賀建飚
(1.長江大學 電子信息學院,湖北 荊州 434023;2.長江大學 電工電子國家級實驗教學示范中心,湖北 荊州 434023;3.長江大學 西部研究院,新疆 克拉瑪依 834000;4.長江大學 計算機科學學院,湖北 荊州 434023;5.中南大學 計算機學院,長沙 410083)
0 概述
頭部姿態估計指的是根據給定的圖像推斷出人的頭部方向,包括俯仰角(pitch)、偏航角(yaw)、滾轉角(roll)的三維向量[1]。近年來,隨著計算機視覺和人工智能的發展,頭部姿態估計在人機交互[2]、輔助駕駛[3]、智慧課堂[4]、活體檢測[5]等領域得到了廣泛應用。國內外不少研究人員對頭部姿態估計算法進行了深入研究,提出多種頭部姿態估計算法。根據有無面部關鍵點,一般可將其分為基于模型的方法和基于外觀的方法兩類[6]。
基于模型的方法通過檢測面部關鍵點,建立三維空間到二維圖像間的映射關系來估計頭部姿態[7]。例如,文獻[8]提出基于眼睛定位的頭部姿態估計方法,利用眼睛的位置進行不同頭部姿態的估計。文獻[9]結合特征點的深度信息構建三維頭部坐標系,然后將頭部坐標系粗配準計算與點云配準算法相結合,最終得到精準的頭部姿態參數。該方法的準確率和穩定性表現比較好,但是獲取圖像的深度信息要使用特殊的設備,成本較高。文獻[10]先結合局部二值模式(Local Binary Pattern,LBP)特征進行面部關鍵點檢測,然后采用支持向量機對頭部姿態進行分類。
基于外觀的方法通過大量已標記的數據,訓練出樣本到頭部姿態角的映射模型。例如,文獻[11]利用殘差網絡作為主干網絡提取特征,有效提高了真實場景下的預測精度。文獻[12]通過改變卷積深度、卷積核大小等手段優化LeNet-5 網絡,使其能夠更好地捕捉到豐富的特征,進而提高預測精度。文獻[13]提出一種輕量級的特征聚合結構,使用多階段回歸估計頭部姿態參數。
在真實環境下進行頭部姿態估計是一個具有挑戰性的難題。文獻[14]為得到部分遮擋中面部特征的有效表示,從非遮擋人臉子區域中提取金字塔HoG 特征來估計頭部姿態。文獻[15]通過合成頭部姿態圖像,增加不同照明和遮擋條件下的樣本圖像,進而改善模型的性能。文獻[16]利用Gabor 二進制模式對人臉進行處理,以解決部分遮擋和光照變化。文獻[17]將遮擋字典引入到面部外觀字典中,以從部分遮擋的面部外觀中恢復面部形狀,并對各種部分面部遮擋進行建模。
本文提出聯合遮擋和幾何感知模型下的頭部姿態估計方法,采用人臉檢測和圖像增強技術,減小背景和光照變化的影響。通過面部遮擋感知網絡和幾何感知網絡,在減小部分遮擋影響的基礎上加入人臉的幾何信息。在此基礎上,采用設計的多損失混合模型精準地估計出頭部姿態參數。
1 本文方法
本文提出一種新的頭部姿態估計方法,在聯合遮擋感知和幾何感知的模型下進行頭部姿態估計。如圖1所示,本文方法分為4 個部分:(1)為圖像預處理模塊,目的是進行人臉檢測和圖像增強;(2)為面部遮擋感知模塊,作用是通過遮擋感知網絡減少面部遮擋的干擾;(3)為面部幾何感知模塊,應用堆疊膠囊自編碼器[22]感知人臉幾何信息;(4)為頭部姿態估計模塊,通過使用多損失混合模型輸出頭部姿態角。
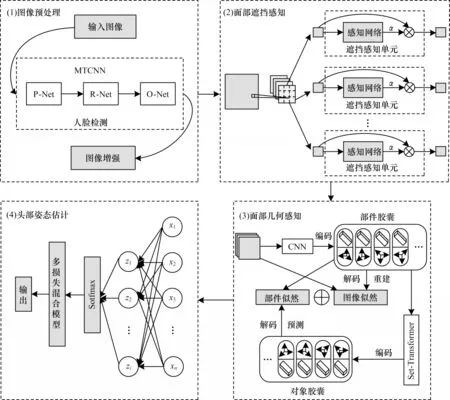
圖1 本文方法框架Fig.1 Framework of the method in this paper
1.1 圖像預處理
1.1.1 人臉檢測
本文的頭部姿態估計方法是從單張圖像中推理出頭部姿態角,建立圖像中頭部的空間特征信息到頭部姿態角向量的映射關系。為減小背景環境的影響,先對輸入圖像進行人臉檢測。在深度學習中,多任務卷積神經網 絡(Multi-Task Convolutional Neural Networks,MTCNN)是一個較實用的、性能較好的人臉檢測方法[18],由P-Net、R-Net、O-Net 3層網絡組成,其核心思想是通過多任務的形式訓練網絡參數,實現多個任務共同完成的目標,使人臉檢測的過程由簡到精。在實際運用中,MTCNN 可以很好地應對頭部的大幅度偏轉,同時對光照變化和部分遮擋具有一定的魯棒性。
1.1.2 圖像增強
考慮到低曝光、光照不均勻等復雜的光照情況對頭部姿態估計的影響,在提取特征之前,本文對檢測到的人臉進行圖像增強處理,以減小光照變化帶來的影響。受文獻[19-20]啟發,本文先采用自適應亮度均衡對亮度圖進行處理,然后采用色調映射技術對圖像的整體亮度進一步調節,以解決低曝光問題。
首先,本文將輸入圖像從RGB 通道變換到HSV 通道,單獨處理V 通道而不改變圖像色彩。為達到保持邊緣、降噪平滑的效果,本文對亮度圖像進行濾波,得到圖像的底層Ib和細節層Id,表達式如式(1)所示:
其中:I為輸入圖像;BF為雙邊濾波器,濾波過程可表示如下:
其中c(.)和s(.)分別表示像素位置間的相似度和像素值之間的相似度,定義如下:
提取到亮度圖像后,本文采用自適應的方法對亮度進行平滑處理,具體處理流程如下:
其中:z(x,y)表示像素點(x,y)在一定范圍內的亮度平均值;I′(x,y)代表處理后的圖像。本文將某一點的亮度值與其鄰域內的亮度平均值作比,得到參數α,假如α>1,則對圖像進行亮度抑制,反之則對圖像進行亮度增強,最終達到亮度均衡的效果。
為進一步調節圖像亮度,本文對均衡后的底層圖像進行自適應色調映射,因為人類視覺系統感知亮度近似為對數函數[21],所以可將映射函數定義如下:
其中:Im為I′的最大值;代表對數平均亮度,其表達式如式(9)所示。
通過式(9),本文可以對圖像的整體亮度進行調整,為保留細節,本文將濾波后的細節層融入映射后的圖像,該過程的表達式如下:
最后,將處理后的亮度分量與原有的色調和飽和度分量進行合成,并轉化到RGB 空間得到最終的圖像。
1.2 面部遮擋感知模型
如圖1 中(2)所示,本文的面部遮擋感知模型先對處理后的圖像進行卷積操作以減少參數量,得到特征圖后將其劃分成n個子區域。接著將這些子區域分別送入遮擋感知單元得到對應的遮擋感知因子,該參數反映了子區域的遮擋程度。最后將感知因子與對應子區域相乘并恢復成原特征圖的形狀,得到新的帶有遮擋信息的特征圖。
每個遮擋感知單元包含1 個遮擋感知網絡,該網絡可以感知遮擋的子區域,對于未遮擋的、信息豐富的子區域,網絡輸出較大的遮擋因子參數。詳細網絡結構如圖2 所示。
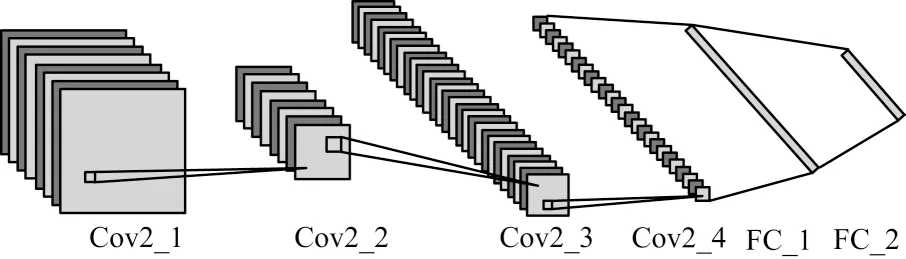
圖2 遮擋感知網絡結構示意圖Fig.2 Schematic diagram of occlusion sensing network structure
由圖2 可知,該網絡包含4 個卷積層、2 個全連接層。網絡的輸入為劃分好的子區域,通過遮擋感知網絡后經Softmax 函數輸出1 個遮擋因子,表示該區域的遮擋程度。在實際應用中,為充分細化遮擋程度,對于完全遮擋的、沒有面部信息的子區域,網絡輸出遮擋因子數值為無窮小,依此類推,遮擋程度越小、信息越豐富的子區域,網絡輸出遮擋因子的數值越大。
本文定義第i塊子區域為pi,則遮擋感知網絡可表示如下:
其中:y表示從區域特征到輸出的映射;αi表示該區域的遮擋因子。最后本文將每塊子區域乘以對應的遮擋因子并拼接在一起,得到帶有遮擋信息的新的特征圖F,表達式如下:
1.3 基于SCAE 的面部幾何感知
堆疊膠囊自編碼器(Stacked Capsule Autoencoders,SCAE)[22]通過無監督方式描述幾何關系,利用部件之間的幾何關系重建原始圖像。受到這一特點的啟發,本文使用SCAE 對面部圖像的組成部分和組成部分的姿態進行編碼,深度感知面部各部分的幾何關系,獲取面部的幾何表征,提高頭部姿態估計準確率。如圖1 中(3)所示,SCAE 由部件膠囊自編碼器和對象膠囊自編碼器堆疊而成。
1.3.1 部件膠囊自編碼器
部件膠囊自編碼器將輸入的面部特征圖編碼成M個部件膠囊,每個膠囊包含1 個姿態向量xm,1 個存在概率dm和1 個特殊的特征zm參數,姿態向量里包含了面部各部分之間的相對位置,特殊的特征參與下一部分對象膠囊自編碼器的編碼。為了能更好地優化部件膠囊的參數,本文將卷積神經網絡(Convolutional Neural Network,CNN)當作編碼器,編碼過程可以表示如下:
在解碼過程中,本文首先為每個部件膠囊定義1 個模板Tm∈[0,1]h×w×1,為了獲得帶有模板的實際圖像部分,本文使用獲取到的姿態向量xm對模板進行仿射變換:
然后,本文用空間高斯混合模型(Gaussian Mixture Model,GMM)重建輸入。圖像似然值可表示如下:
元素及其化合物是中學化學基礎知識之一,是解決化學反應過程中思維活動的基礎,沒有扎實的基礎知識,就如同漏水的水桶,在解決問題時就會千瘡百孔,漏洞百出。
這一階段訓練的目標是提取代表面部各部分的部件膠囊、姿態等參數,并得到部件的模板,用于第2 個階段的對象膠囊自編碼器。訓練的目標函數是最大化圖像似然函數。
1.3.2 對象膠囊自編碼器
在第2 個階段,對象膠囊自編碼器對部件膠囊自編碼器的輸出進行編碼,以獲取各個部件膠囊之間的內部關系,并重建部分膠囊的姿態。
在對象膠囊自編碼器階段,本文將上一階段得到的姿態向量、特殊的特征和模板作為輸入,使用set-transform[23]作為編碼器,將輸入編碼成K個對象膠囊,每個膠囊包含1 個特征向量ck、存在概率βk和1 個3×3 的對象,即視角關系矩陣Vk。編碼過程可以表示如下:
其中:hcaps函數表示編碼器。在解碼過程中,對于每個對象膠囊,本文使用1 個多層感知器預測出N個候選區域,每個候選區域包含1 個條件概率βk,n、1 個聯合的標量標準差λk,n和1 個3×3 的對象—部件關系矩陣Pk,n。解碼過程如式(18)所示:
其中:μk,m和λk,m分別代表各向同性高斯分量的中心和標準差,μk,m=Vk×Pk,m,目標函數是最大化部件似然函數。
1.4 基于多損失的頭部姿態估計混合模型
輸入圖像經過以上遮擋感知模塊和幾何感知模塊后,本文得到了面部圖像的遮擋表征和幾何表征,然后本文利用這些特征建立映射模型,得到最終的頭部姿態參數。在之前預測頭部姿態的工作中,大多直接使用回歸的方法建立映射模型,然而這種方法難以處理頭部姿態的細微變化,預測精度不高。
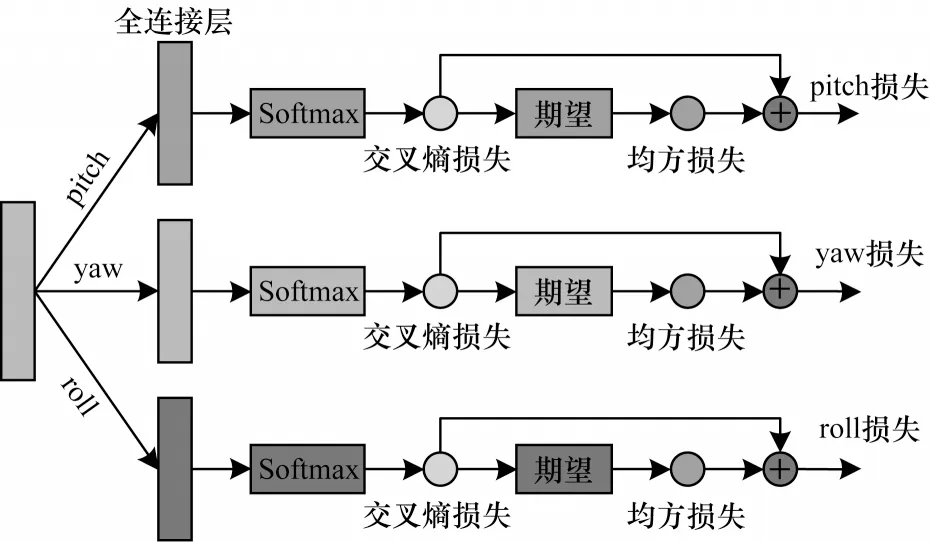
圖3 多損失混合模型的網絡結構Fig.3 Network structure of multi-loss hybrid model
其中:CEL 和MSE 分別代表交叉熵損失和均方損失;yi和分別代表真實值和預測值;α代表權值因子,該因子的評估將在2.2.2 節進行。本文將不同維度的3 個損失反向傳播到網絡,以加強模型學習,最終獲得細粒度較高的預測結果。
2 實驗結果與分析
2.1 實驗數據集與評估指標
在3個公開的數據集上進行實驗,以評估本文提出的頭部姿態估計模型。圖4所示為數據集圖像示例,第1行為300W_LP[24]數據集樣本,第2行為AFLW2000[24]數據集樣本,第3行為BIWI[25]數據集樣本。

圖4 數據集圖像示例Fig.4 Sample image of dataset
300W-LP 數據集由300W[26]數據集擴展而來,它標準化了多個用于面部對齊的數據集,使用帶有3D圖像網格的面部輪廓人工合成了61 225 個不同姿態的樣本。AFLW2000 數據集是一個野外數據集,共有2 000 張受各種姿態、部分遮擋、光照、種族等因素影響的人臉圖片,每張圖像都標注了對應的姿態。BIWI 數據集是一個實驗室數據集,記錄了20 個志愿者(包括6 名女性和14 名男性)坐在Kinect 前(約1 m的距離)自由轉動頭部的視頻序列,該數據集擁有超過15 000 張圖像數據,其中頭部姿態偏轉角度變化范圍在[-75°,75°]之間,俯仰角度在[-60°,60°]之間。
為訓練遮擋感知網絡,本文從上述數據集中隨機選取200 張樣本圖像合成遮擋的樣本,用作網絡訓練。本文的遮擋物選取了日常生活中常用的物品,將遮擋物隨機疊加到人臉圖像上生成遮擋數據集。圖5 為遮擋數據集部分圖像示例。

圖5 遮擋數據集圖像示例Fig.5 Sample images of occlusion dataset
本文將平均絕對誤差(Mean Absolute Error,MAE)作為評估指標。假設給定一系列訓練的人臉圖像X={xn|n=1,2,…,N}和對應的頭部姿態標簽yn,將通過本文網絡預測出的頭部姿態設為,則MAE 定義如下:
2.2 實驗設置和參數評估
2.2.1 實驗設置
本文通過Pytorch 框架實現本文方法,實驗平臺為搭載Intel?CoreTMi710875 CPU、NVIDA RTX2070 GPU的計算機。實驗以300W_LP 為訓練集,將AFLW2000和BIWI 分別作為測試集。模型訓練結合了無監督學習和有監督學習。本文將預處理后的圖像通過已經訓練好的遮擋感知網絡提取出帶有遮擋信息的面部特征,然后將特征送入幾何感知網絡進行無監督學習,在幾何感知網絡模型訓練階段,使用RMAProp 優化器訓練網絡,部件膠囊和對象膠囊的個數都設置為32,學習率設為0.000 1,迭代次數為500 次。在多損失預測頭部姿態模型階段,使用Adam 優化器進行訓練,將初始學習率設為0.000 1,每迭代50 次學習率衰減0.000 001,最大迭代次數為400 次。
2.2.2 參數評估
針對多損失混合模型中交叉熵損失和均方損失間權重因子的評估,本文分別在AFLW2000數據集和BIWI數據集上評估不同權重因子下本文模型的性能,將權重因子分別設置為0、0.25、0.5、1、2、3,測試結果如圖6所示。可以看到,當權重因子為2 時,模型在兩個數據集上的MAE 均最小,模型預測準確率最高。
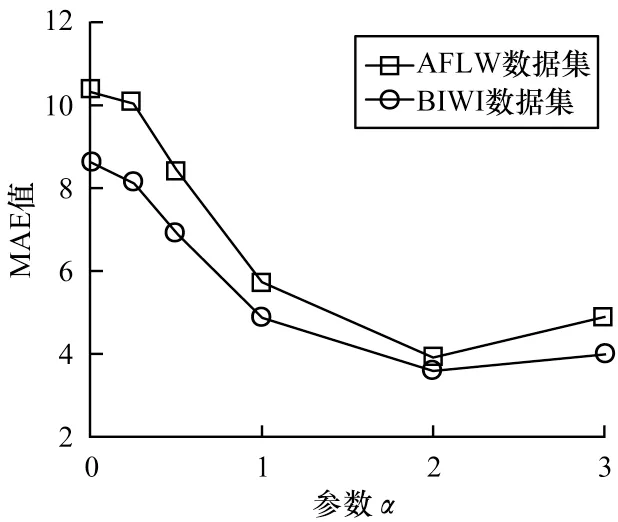
圖6 不同權重因子下的測試結果Fig.6 Test results under different weight factors
2.3 圖像預處理
本文在預處理階段進行了人臉檢測和亮度均衡操作,目的是減小背景和光照變化的干擾。圖7 為部分預處理實驗結果,圖7 中第1 列圖像代表輸入的原圖,第2 列圖像為進行人臉檢測后按一定比例裁剪的圖像,第3 列為進行亮度均衡處理后的圖像。

圖7 預處理結果示例Fig.7 Example of preprocessing results
2.4 消融實驗
為評估本文方法中遮擋感知模塊和幾何感知模塊的影響,本文對比了模型在有無嵌入遮擋感知和幾何感知情況下的性能,實驗以300W_LP 為訓練集,將AFLW2000 和BIWI 分別作為測試集,結果如圖8 所示。
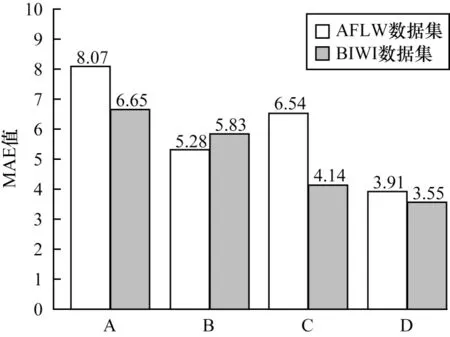
圖8 不同模型的消融實驗結果Fig.8 Results of ablation experiments of different models
在圖8 中,A 組代表模型中既無遮擋感知塊也無幾何感知塊,B 組表示只有遮擋感知塊,C 組表示只有幾何感知塊,D 組表示兩者都有。A、B 組對比結果顯示,嵌入遮擋感知模塊的模型在野外數據集AFLW2000 上測試性能明顯提升,在BIWI 數據集上測試性能相近。A、C 組對比結果顯示,嵌入幾何感知模塊后的模型在BIWI 數據集上測試性能明顯提升,而因未考慮遮擋,所以在AFLW2000 數據集上測試結果沒有B 組好。D 組在嵌入遮擋和幾何感知塊后,在兩個數據集上的測試性能都明顯提升,平均絕對誤差均低于B 組和C 組。消融實驗的結果表明,本文方法中的遮擋感知模塊和幾何感知模塊有效提高了模型的估計性能,具有一定的實際應用價值。
2.5 對比實驗與分析
本文對比了目前較好的姿態估計方法。前3 組方法是基于面部關鍵點的,后幾組為無面部關鍵點的方法。其中,Dlib[27]是一個標準的人臉庫,使用回歸樹集合估計人臉的關鍵點位置。FAN[28]是一種非常先進的面部關鍵點檢測方法。該方法通過跨層多次合并特征獲取多尺度信息。3DDFA[24]通過CNN將三維空間人臉的模型擬合到彩色圖像上,在AFLW 數據集上取得了很好的效果。Hopenet[29]提出結合分類與回歸計算三維頭部姿態。FSA-Net[13]設計了一個細粒度回歸學習映射模型。文獻[30]提出一種新的三分支網絡架構來學習每個姿態角的區別特征,再通過引入跨類別中心損失來約束潛在變量子空間的分布,得到更緊湊、更清晰的子空間。文獻[31-32]探索了最近比較流行的VIT 在頭部姿態估計的應用,取得了比較好的估計結果。
表1 和表2 分別為本文方法在2 個基準數據集上與最新方法(包括基于面部關鍵點的方法和無面部關鍵點的方法)的對比結果,其中“—”表示無此數據。本文是基于無面部關鍵點的方法,與基于面部關鍵點的方法(文獻[24]、文獻[27]和文獻[28]方法)相比,本文方法準確率更高,這是因為基于面部關鍵點的方法受關鍵點檢測過程的影響,依賴面部關鍵點,而對關鍵點外的面部特征學習能力較差,難以適應訓練和測試之間的差異。
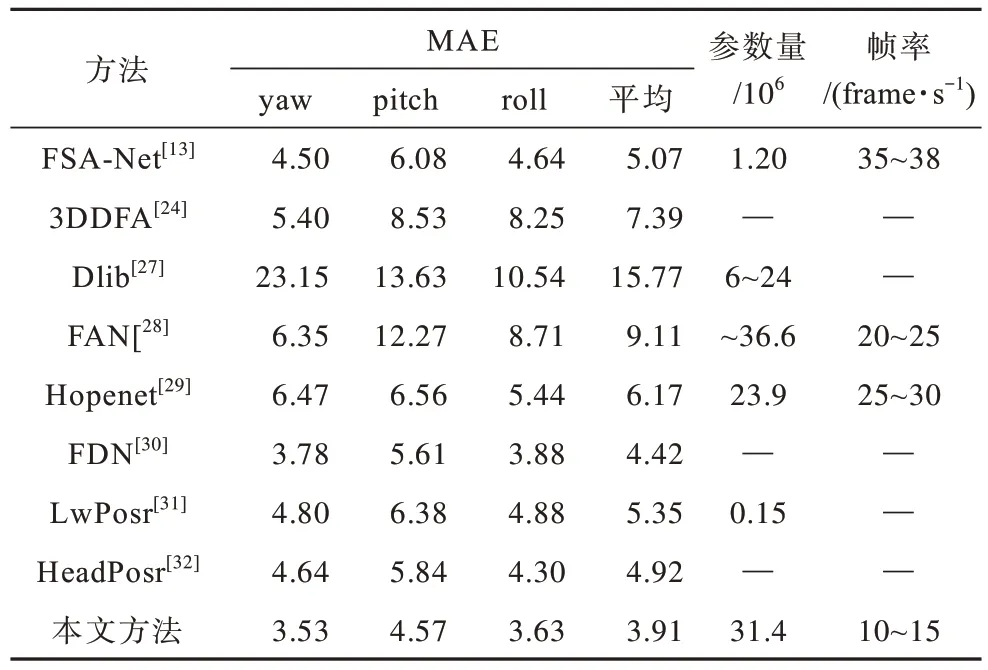
表1 AFLW2000 數據集上不同方法的對比結果Table 1 Results comparison of different methods under AFLW2000 dataset
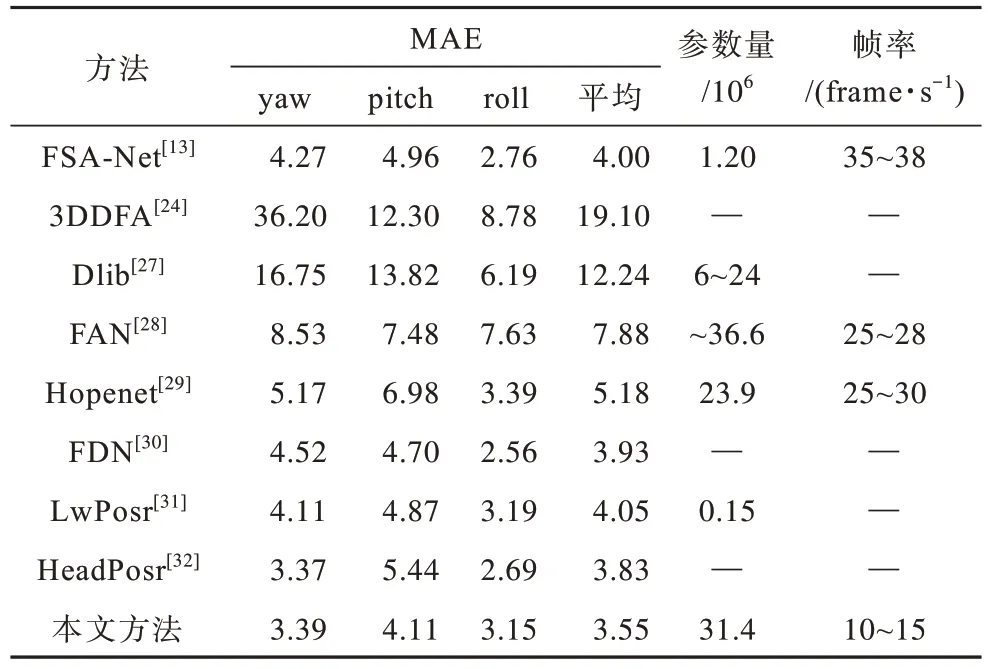
表2 BIWI 數據集上不同方法的對比結果Table 2 Results comparison of different methods under BIWI dataset
由表1 和表2 還可以發現,在無面部關鍵點的方法中,本文方法的測試結果均優于其他方法,在AFLW2000數據集和BIWI 數據集上的平均絕對誤差分別為3.91和3.55,比對比方法中表現最好的方法分別降低了11.53%和7.31%。BIWI 數據集為實驗室數據集,本文方法通過幾何感知網絡提取了其他方法忽略的面部幾何信息,使測試準確率有一定程度的提升。此外,本文方法在具有挑戰性的AFLW2000 數據集上的測試結果與其他方法相比有所提升,這顯示了本文方法的優越性,進一步證實了本文方法中遮擋感知模型和幾何感知模型的有效性。
為評估本文方法的效率,本文采用模型參數量和運行的視頻幀率(Frames Per Second,FPS)作為評定指標。由表1和表2可知,與FSA-Net[13]和LwPosr[31]相比,本文方法的模型參數量較多,這是因為FSA-Net[13]設計了輕量級的特征聚合結構,LwPosr[31]使用深度可分離卷積替換了普通卷積,能夠減少模型參數量。而本文從解決復雜環境下的頭部姿態估計問題出發,設計了遮擋感知模型和幾何感知模型,導致模型參數量增加。另外,與其他方法相比,本文方法的幀率較低,這是因為本文方法進行了圖像預處理,在該過程中會消耗較多的時間成本。但本文方法可以很好地適應復雜的現實場景,提高現實場景下頭部姿態估計的準確率。
2.6 復雜環境下的性能測試
在得到訓練好的網絡模型后,本文選取光照變化差異大、有部分面部遮擋的樣本圖像進行測試,以直觀地驗證本文方法在復雜環境下的性能,測試結果如圖9 所示。

圖9 本文方法在復雜環境下的測試結果示例Fig.9 Example of test results of method in this paper under complex environment
在圖9中,第1行是光照條件較差時的結果,第2行是面部有部分遮擋時的結果。可以看出,本文方法在光照不均、低曝光、部分遮擋等復雜環境下表現良好,達到在復雜條件下進行頭部姿態估計的目標。
2.7 局限性分析
本文提出的頭部姿態估計方法在一定程度上提高了在復雜環境下的預測準確率。然而,本文方法也存在一些局限性,本文可以很好地應對小部分面部遮擋情況,但當面部區域遮擋過大時,本文方法可能無法產生令人滿意的結果,因為當面部區域遮擋過大時,本文提取的有效面部特征就會變少,進而影響模型預測頭部姿態。另外,本文方法可能在移動嵌入式設備表現不佳,因為本文方法的模型參數較大。
3 結束語
本文提出一種基于遮擋感知模型和幾何感知模型的頭部姿態估計方法,通過圖像預處理操作與使用遮擋感知網絡,減少背景、光照變化、遮擋等環境因素的干擾,提高預測準確率。采用幾何感知網絡提取特征,為獲取幾何感知的人臉圖像提供了一種無監督學習的解決方案。實驗結果表明,本文方法能有效應對光照不均、部分遮擋、面部外觀差異大等問題,在不同數據集上的表現較好。下一步將進行遮擋部分的復原工作[33],以豐富面部特征,提高頭部姿態估計準確率。同時通過減少模型參數,使其適用于移動嵌入式設備。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
