基于YOLOv5的目標識別追蹤模型輕量化
2023-03-17 11:48:18李海鵬
汽車實用技術 2023年5期
李海鵬,余 強
(長安大學 汽車學院,陜西 西安 710064)
自動駕駛領域離不開道路環境感知,其中基于卷積神經網絡的目標檢測近年來發展迅速[1]。基于深度學習的目標檢測算法可以分為單階段與兩階段。其中單階段常用的有單階段多盒檢測器(Single Shot MultiBox Detector, SSD)[2]算法和YOLO系列,包括YOLOv3[3]、YOLOv4[4]和YO- LOv5[5],雙階段的有區域卷積神經網絡(Region Convolutional Neural Networks, R-CNN)系列等。目標追蹤算法用于車載移動端多采用在線追蹤算法,其中Deep SORT[6]算法被廣泛采用。但是由于網絡權重較大,不易于以較低成本部署在邊緣設備,而大幅度的壓縮權重會以犧牲目標檢測準確度為代價。因此,本文提出如何在減小YOLOv5模型權重下,盡可能減小目標檢測準確度的下降。
1 數據集準備
1.1 獲取車載視頻流
道路環境復雜多變,采用單目攝像機獲得車輛周圍物體的信息。通過安裝在車輛上的攝像頭獲取車輛在道路上行駛時的實時視頻,進而處理分析。實驗車輛與攝像機的安裝位置如圖1所示。

圖1 實驗車輛與攝像頭位置
數據包括在高速路、城市道路以及鄉村道路車載實時視頻,同時也應包括在城市行駛一天的早高峰、午低谷和晚高峰三個時間段內車輛道路環境視頻。
1.2 數據集標注
需要先從視頻中隨機截取圖片進行圖片標注,再進行視頻流標注。截取的圖片大小均為 1320 bits×1080 bits,標簽共分為15類。其中選擇3330張圖片作為訓練集,888張圖片作為測試集。利用軟件LabelImg標注所有圖片。完成后進行部分視頻流標注,隨機從數據集中選擇連續的241幀圖片和650幀圖片,其中分別有37條軌跡和108條軌跡。標注出每幀目標的位置信息、分類信息和序號。
2 改進YOLOv5算法
在目標檢測算法中,模型太大不易于低成本地部署于邊緣設備中。在壓縮模型與保持模型精度需要進行取舍,本文選擇YOLOv5系列中的YOLOv5s進行改進,在降低模型大小同時以損失精度較小代價。
2.1 YOLOv5算法
根據模型大小的寬度和深度不同,可以將YOLOv5算法分為YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x四種版本。本文選擇寬度和深度最小的YOLOv5s進行改進,其結構主要分為預處理、主干網絡、Neck部分和Head檢測端。預處理需要對數據集進行Mosaic數據增強、自適應錨框計算以及自適應圖像填充處理。在主干網絡中需要運用Conv模塊和C3[7]模塊進行特征的提取,其中C3模塊可以起到壓縮模型并提高推理 速度的作用。在Neck部分由特征金字塔(Feature Pyramid Networks, FPN)和路徑聚合結構(Path Aggregation Network, PAN)所構成,可以將語義信息和特征信息進行不同層級間的交流傳遞。Head檢測端是處理得到的不同尺寸下的特征圖,具體區分為大目標、中目標和小目標。目標識別完成后將置信度信息、位置信息和分類信息重新映射回原圖,同時輸入給目標追蹤網絡進行進一步處理。YOLOv5流程圖如圖2所示。
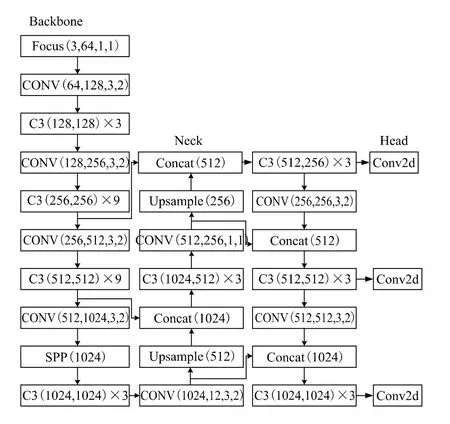
圖2 YOLOv5流程圖
2.2 YOLOv5結合GhostConv
在傳統的卷積特征提取中會存在大量的冗余,如圖3所示。對于給定數據X∈Rc×h×w,其中c是輸入通道數,h和w分別是輸入數據的高度和寬度,用于生成n個特征圖的任意卷積層的操作可以用公式描述:
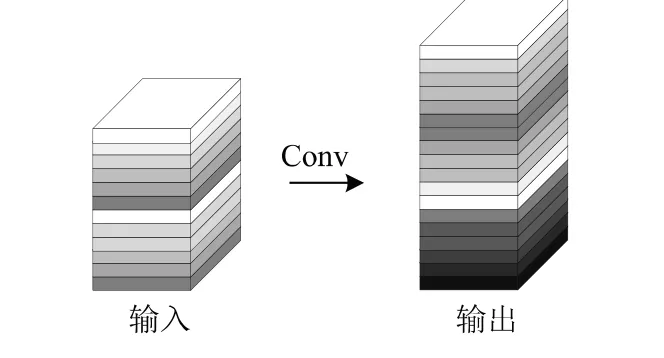
圖3 傳統Conv處理過程
式中,b為偏置常數;n為通道數;Y∈Rh'×ω'×n為輸出的特征圖;卷積核為f∈Rc×k×n;h'和w'為輸出特征圖的高和寬;k×k為卷積核f的大小。
可以運用GhostConv[8]來代替YOLOv5中的卷積模塊來對模型進行壓縮,同時減小對模型精度的影響,如圖4所示。需要先進行普通卷積得到部分的基礎特征圖,再對基礎特征圖進行廉價卷積線性變換φk得到ghost特征圖,最后特征圖數目與原來的卷積操作一致,如以下公式描述:
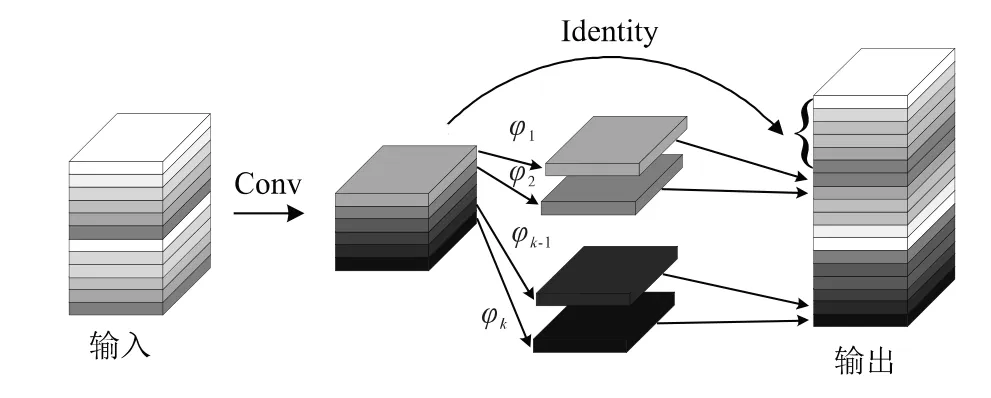
圖4 GhostConv處理過程
式中,Y'∈Rh'×ω'×m;*為卷積操作;m為進行普通卷積的通道數;φi,j為進行線性變化卷積操作。廉價的卷積操作消耗算力少,也可以包括其他變換等。其中m始終不大于n,若m=n則與等價于普通卷積。
2.3 YOLOv5結合shufflenetv2
shufflenetv2是一種輕量形網絡,融入YOLOv5網絡中能起到壓縮模型大小,加快推理的效果,主要是圖5中的兩種模塊起作用。
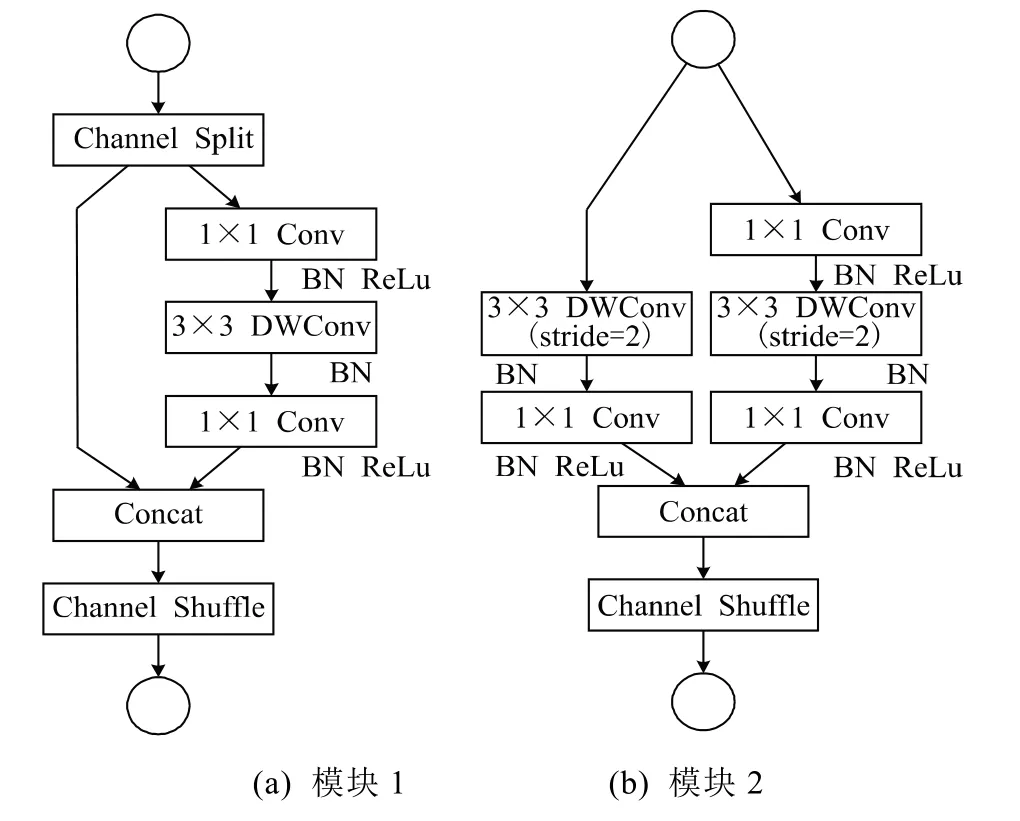
圖5 shufflenetv2模塊
圖5 (a)中的Conv為普通卷積,DWConv表示深度卷積。Channel Split操作為對特征圖的通道進行分割,在此為均分。Channel Shuffle操作可以增加通道間的信息交流,類似于將通道以某種方式打亂重組。
圖5(a)中先將通道均分,一部分不做處理,另一部分進行卷積等操作。隨后將兩份特征圖合并,使得輸出的通道數和輸入的通道數一致,最后進行的Channel Shuffle操作。圖5(b)中沒有Channel Split操作,將特征圖進行不同的卷積處理,后續操作與圖5(a)一致。兩者模塊均采用了1×1卷積,可以壓縮模型大小同時對精度影響不大。
3 結合Deep SORT算法
Deep SORT算法是由SORT算法改進而來。以YOLOv5處理后得到的目標檢測框、置信度和特征作為輸入,運用級聯匹配算法、交并比(Intersection over Union, IOU)匹配算法和卡爾曼濾波算法進行處理,完成目標追蹤。
在Deep SORT算法中,先收到由YOLOv5網絡傳來的已識別目標的種類信息、置信度信息和位置信息。在初步篩選后運用卷積神經網絡進行重識別,對目標框內的特征進行提取。利用余弦距離計算距離,結合卡爾曼濾算法,加權馬氏距離進行級聯匹配,未匹配目標則繼續進行IOU匹配,最終可得到目標軌跡,在經過最終結果可利用匈牙利算法得到目標追蹤軌跡。此處將重識別網絡使用shufflenetv2中的模塊進行組合替換,可進一步壓縮模型大小,并對追蹤精度影響較小。目標追蹤算法流程圖如圖6所示。
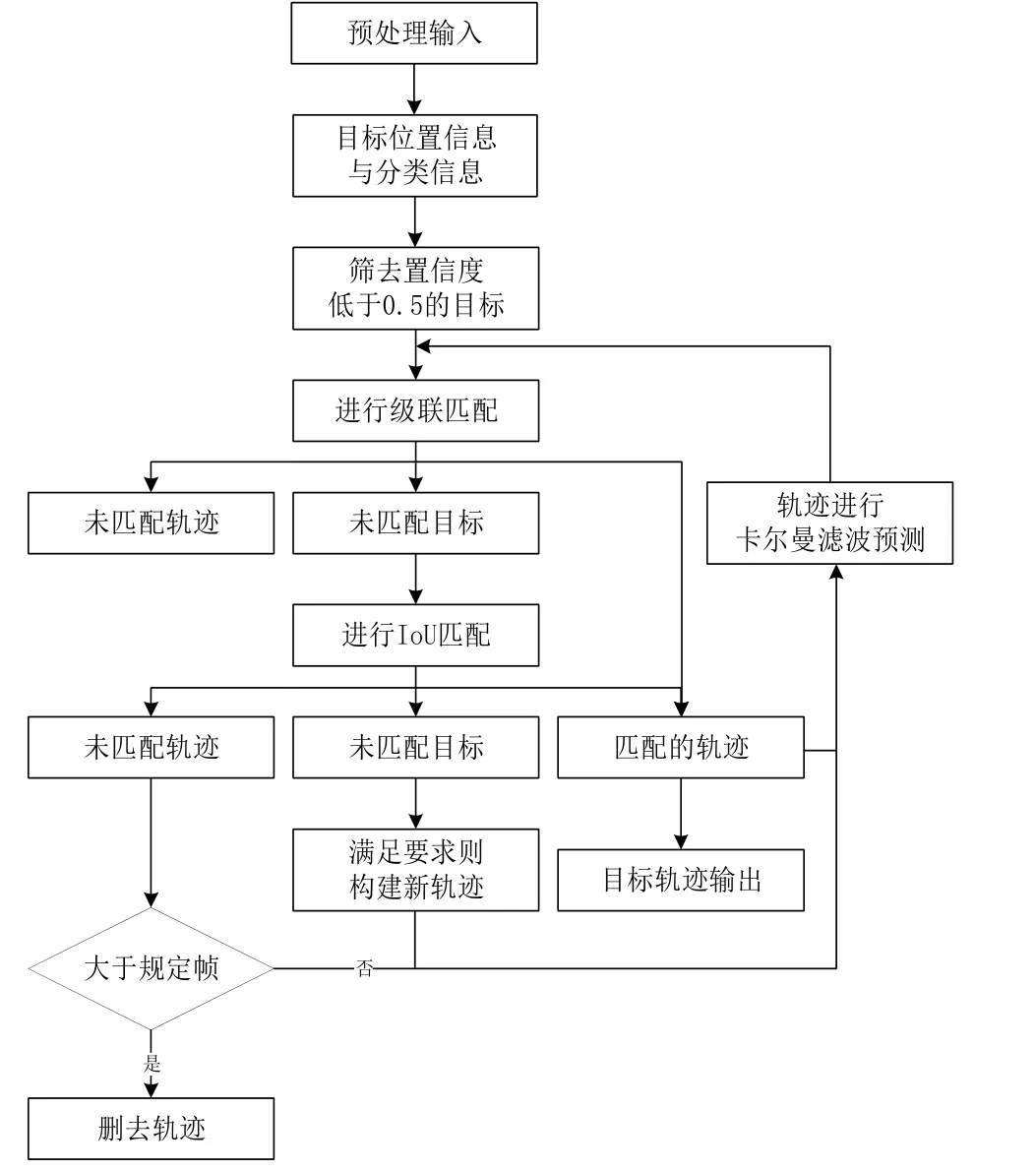
圖6 Deep SORT流程圖
4 實驗結果
表1為YOLOv5s、YOLOv5s+ shufflenetv2和YOLOv5s+shufflenetv2+Ghostconv的結果對比,包括模型參數、GFLOPs、權重大小和mAP-0.5的對比。

表1 mAP-0.5對比
圖7為在數據集中視頻流的追蹤效果圖,其模型大小在壓縮的情況下實時性和模型精度均可達到預期要求。

圖7 目標追蹤示意圖
5 結論
本文通過對YOLOv5s結合shufflenetv2中的模塊,模型大小從13.7 MB下降為1.9 MB,而mAP-0.5只從0.888下降到0.810。網絡在融入Ghost模塊后,可以對模型整體進一步進行壓縮,模型大小下降至1.7 MB,而mAP-0.5可以達到 0.835。選取同樣權重大小較小的模型NanoDet-m模型進行橫向對比,在檢測精度上YOLOv5s+ shufflenetv2+Ghostconv的精度更高。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
