基于卷煙陳列識別和品牌文本表示的銷量預測方法
2023-03-17 07:28:10劉雁兵劉曉蓉王義新汪偉飛吳凌翔
無線電工程 2023年3期
劉雁兵, 肖 駿, 劉曉蓉, 王義新, 汪偉飛, 吳凌翔
(1.廣西中煙工業有限責任公司, 廣西 南寧 530001;2.廣東煙草廣州市有限公司, 廣東 廣州 510610;3.武漢人工智能研究院, 湖北 武漢 430074)
0 引言
在現代零售行業,智能營銷是提升渠道[1]掌控力和商品銷售的關鍵性環節。 運用數據挖掘技術和大數據分析方法挖掘這些數據背后隱藏的信息,能促進煙草行業從傳統的批發模式升級為數據驅動的煙企商戶利益共同體模式[2-6]。 在煙草銷售環節,卷煙的陳列方式、不同的擺放位置往往會影響卷煙銷量。 穆建軍[7]為了解決商戶經營面積小、陳列困難等問題,創新地采用立體陳列方式來克服客戶選購不便的缺陷。 劉薇[8]探究卷煙陳列標準,為卷煙的陳列方式、陳列模型設立了原則要求與具體標準,來達到合理擺放、激發消費者購買意愿的目的。 對零售終端陳列的各種卷煙進行識別[9]與統計,分析其銷售情況進行評估,不僅對卷煙的品牌營銷[10]具有指導意義,更有助于智能化零售終端系統的探究。
在卷煙陳列與銷量的分析中,主要面臨2 個挑戰。 一個挑戰是數據質量,零售終端系統(POS 機)作為數據觸點,承載著信息采集和消費跟蹤等重要功能,然而部分客戶規范使用終端信息系統意識不強,導致零售終端數據的采集及其質量難以保證[11]。 目前煙草行業普遍采用的方法是選定少數經營較為規范的客戶作為信息采集點,但這些信息采集點數量占比非常低,通過這些少量的市場樣本去分析市場狀態、制定貨源投放策略以及開展品牌營銷等,可能會造成決策上的失誤。 另一個挑戰是多源特征的表達。 為預測銷量,涉及到陳列位置特征、品牌名稱特征、價格和地區等特征。 以陳列特征為例,由于卷煙品牌種類繁多,部分商品圖案相似難以區分,陳列特征難以獲取;以品牌名稱為例,需要基于文本的品牌嵌入式表達等。 提取卷煙的不同屬性作為特征,對訓練銷量預測模型至關重要。
為解決以上問題,本文提出一套卷煙銷量預測方法,包含樣本質量篩選、銷量預測模塊,后者又包含卷煙識別和文本表達等網絡。 在樣本質量篩選階段,設計了POS 機使用質量評估準則,構造數據集;為了更強的可解釋性,選擇隨機森林模型,訓練POS機質量分類器,并通過特征選擇,過濾掉冗余特征。基于POS 機信息系統登錄、在線、商品掃碼和支付等環節的數據、商品進銷存數據,結合異常值檢測,建立了一套量化的零售終端運行質量評估體系,結合日級評分和月級評分,將零售終端運行質量分為5 類,并以此為訓練數據。 最終選擇高質量的商戶,作為下游銷量預測模塊的樣本點。
在銷量預測過程中,通過基于深度學習的圖像識別檢測技術對卷煙位置進行精準定位與品牌識別。 利用品牌文本表達、視覺信息和價格等多維度信息,結合大數據分析方法研究卷煙品牌、陳列位置和卷煙銷量之間的關聯關系,研究卷煙陳列與消費選擇行為之間的內在機理,綜合評估卷煙陳列不同區域價值,為終端陳列優化和智能化管理提供指導。針對某個規格的卷煙,繪制其在不同擺放位置的陳列價值圖,從而為商家提供陳列最優決策。 最后,構建BERT-MLP 模型來預測卷煙銷量,分析卷煙規格、位置和價格對銷量的影響。
1 高質量樣本篩選
1.1 零售終端運行質量評估體系及數據集構建
本文提出了一種融合日級評分和月級評分的評估體系,首先通過規則設計的方式構建質量評估數據集。 基于對實際業務的調研,設計可量化的統計特征,結合統計學中的異常值分析方法和專家的經驗設計相關評估準則。 通過對日級評分和月級評分進行加權得到綜合評分,將零售客戶按數據采集質量分為5 類,從而建立起零售終端運行質量評估體系。
本文的分析數據源包括銷售信息、商品信息、登錄日志和店鋪信息等,關鍵指標定義如表1 所示。

表1 評估指標Tab.1 Evaluation indicator
評估規則實際上是對上述評估指標的具體化,為了更加全面具體地評價零售終端的運行質量,從日和月時間維度來設計評估規則。 日級評估規則主要對每日零售終端可能存在的在線異常、漏刷、集中補刷和價格異常等情況判斷,規則涉及的指標包括在線時長、銷售時段、掃碼間隔、日卷煙銷量、單筆銷量、卷煙掃碼筆數和卷煙銷售價格等,記為n1,n2,n3,…,n20。
月級評估規則通過對每月零售終端銷售數據進行分析,判斷零售終端可能存在的異常,規則涉及的指標包括月均掃碼時段、日均掃碼筆數、在線時長、卷煙銷售寬度、在線支付占比和卷煙銷量同比波動等,記為m1,m2,m3,…,m9。
按照日級和月級2 個維度,對評估規則中涉及到的量化指標進行聚合分析,按照3σ 法則、箱線圖和專家經驗相結合的方法確定評估規則的邊界,判斷是否觸發,進而對其進行評分。 在日級評估環節,采用滿分扣分制度,日級規則的初始分為100,每觸發一個日常監控規則扣5 分;在月級量化評估環節,按照月的時間維度對終端POS 機的使用情況進行評分,每滿足一條規則加10 分。 最后,對日級評估均分和月級評分進行加權求和,最終得到該零售終端的月度綜合評分。 評分與樣本分類對應關系如表2 所示。

表2 終端質量等級劃分Tab.2 Terminal quality classification
1.2 質量分類模型
基于前文構造的數據,訓練零售終端運行質量分類模型,包含3 類:高質量樣本點、正常樣本點和異常樣本點。 考慮到商業分析中更注重可解釋性以及特征篩選的需求,質量分類模型選擇隨機森林模型。
備選特征共29 個,如表3 所示。

表3 特征含義Tab.3 Feature meanings
為去除無關特征和冗余特征,采用遞歸特征消除法(RFE)結合相關系數熱力圖篩選特征。 通過RFE 方法刪除4 個特征:每月觸發日級規則的D5,D15 和D16 的次數,以及是否滿足月級規則M2。 經過RFE 篩選出與目標變量有較高相關性的特征,在此基礎上,通過Pearson 相關分析剔除冗余特征。經雙層特征篩選,將特征數量縮減為19 個。 具體篩選過程、模型細節及特征重要性詳見3.1.1 節。
2 卷煙銷量預測
2.1 卷煙識別模型
零售終端的卷煙陳列識別需要采集卷煙陳列前柜圖片作為數據,識別陳列位置pos=(x,y,w,h),其中,(x,y)表示卷煙盒左下頂點的坐標,(w,h)表示煙盒的寬度與高度。 采用了復雜深度耦合網絡模型,并利用多元組排序方法作為損失函數來訓練該精細化識別模型。
復雜深度耦合網絡在骨架網絡中加入了注意力機制,同時設計了深度耦合結構,其主要由3 個模塊組成:骨架網絡(Backbone)、特征金字塔[12](Feature Pyramid Network,FPN)以及深度耦合預測頭(Coupling Head),框架如圖1 所示。 骨架網絡中含注意力模塊[13-14]。
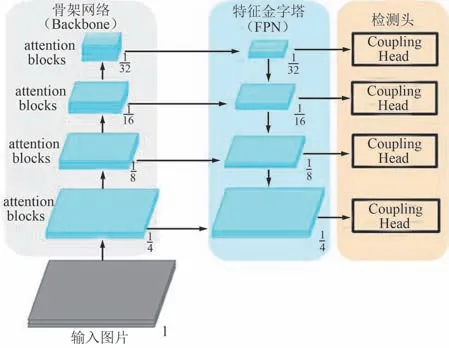
圖1 復雜深度耦合網絡示意Fig.1 Schematic diagram of complex deep coupling network
由于卷煙規格具有多樣性,每種規格之間差異性比較小,個別規格之間只有些許文字或者圖案上的差異,給規格的精細化識別帶來了巨大的挑戰。針對上述問題,本文提出了一種基于多元組排序學習[15]的卷煙精細化識別方法,如圖2 所示,通過度量學習的方法學習更加精準的特征,來增強算法的分類能力。
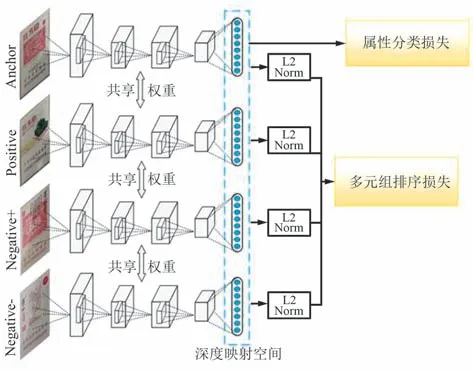
圖2 基于多元組排序學習的精細化識別示意Fig.2 Schematic diagram of refined recognition based on multivariate group sorting learning
針對具體任務,設計合理的目標損失函數用來監督深度神經網絡的訓練,可以學到一個高效的映射空間,在該空間中,目標被映射為一個有效的特征表示,使得特征之間的歐式距離可以直接反映目標之間的語義相似性。 多元組排序學習采用排序損失[16]作為目標損失函數來訓練CNN(Convolutional Neural Network)模型。 以三元組為例,定義排序損失函數為:
該損失包含一個目標圖像三元組,其中Ia與Ip屬于同一個類別,In來自不同類別,該排序損失致力于減小特征空間中f(Ia)與f(Ip)之間的歐式距離,同時要求f(Ia)與f(In)之間的歐氏距離至少要比前者大。 該損失隱含的排序特性非常適合于精細分類任務,而且可以有效減小目標的類內差異,同時增大類間差異,學到更加具有判別力的特征映射空間。
2.2 陳列-銷量初步分析
卷煙擺放位置與銷量息息相關,即使是相同的卷煙,在不同的擺放位置也會產生不一樣的效果,探究特定的卷煙品牌在不同位置上的銷量有助于智能化零售終端系統的更優決策。 給定卷煙陳列圖片與零售終端獲取到的卷煙銷售數據,智能化卷煙識別與陳列分析系統利用圖像識別技術得到卷煙位置與規格數據,并結合來自零售終端的卷煙銷售數據進行分析。
以某店鋪為分析對象,繪制其卷煙陳列圖譜,如圖3 左上圖所示。 從圖中可以看出,紅褐色的位置銷量較好;對于同一品牌,卷煙的不同陳列位置一定程度上會影響卷煙的銷量。 為了更加直觀地展示卷煙品牌受歡迎程度,基于月銷量數據,繪制了卷煙規格的詞云圖,從圖3 左下圖可以看出,蘇煙(五星紅杉樹)、雙喜(硬藍紅玫王)較受消費者歡迎。

圖3 卷煙銷量分析Fig.3 Cigarette sales analysis
2.3 卷煙銷量預測
本節進一步以卷煙的規格、陳列位置和價格等因素為特征,基于中文BERT 預訓練模型[17-18]和全連接神經網絡[19]來預測卷煙的銷量。
本文提取卷煙的不同屬性作為特征來訓練模型。 對于卷煙規格,用BERT 獲取其文本特征;對于其他特征,本文將卷煙的位置和價格特征拼接到BERT 預訓練模型獲取卷煙規格的詞向量上,作為模型最終的輸入特征。
BERT 預訓練模型是從大量無標記的語料中訓練得到的預訓練語言模型,在2018 年由谷歌團隊提出,其網絡結構由若干個雙向Transformer[20-21]的編碼器模塊堆疊組成。 如圖4 所示,卷煙規格經過多層Transformer 之后輸出為字符級向量。 本文采用了BERT 的預訓練的模型BERT-Base,它含有12 個網絡層數,768 個隱藏層,12 個注意力頭數,模型參數量為1.1 億。 BERT 輸入表示是字符嵌入向量和位置嵌入向量的和,字符嵌入向量的開頭和結尾分別用起始符和分隔符表示,中間部分用文本中的單個字符表示,位置嵌入從0 開始代表文本中每個字符的位置信息。

圖4 BERT-MLP 模型結構Fig.4 BERT-MLP model structure
最后,將BERT 預訓練模型得到的特征向量與位置特征以及價格特征拼接,并對拼接后的特征作歸一化處理。
3 實驗及結果分析
3.1 質量評估模型
3.1.1 特征選擇
首先,結合交叉驗證,確定最優特征數量為23。之后,通過遞歸式特征消除(Recursive Feature Elimination,RFE),每次刪除一個特征,得到最終特征選擇狀況的布爾型表達和特征重要性排序。 RFE 方法刪除了4 個特征:每月觸發日級規則的D5 的次數、每月觸發日級規則D15 的次數、每月觸發日級規則D16 的次數、是否滿足月級規則M2。
通過皮爾遜(Pearson)相關分析剔除冗余特征。由圖5(a)共線性處理前的相關系數熱力圖可知,n1與n2,n7,m5,m7 之間的相關性分別為0. 99,-0.98,-0. 86,-0. 86;n2 與n1,n7,m5,m7 之 間 的相關性分別為0.99,-0.97,-0. 85,-0. 87。 考慮刪除每月觸發日級規則D2 的次數、每月觸發日級規則D7 的次數、是否滿足月級規則M5、是否滿足月級規則M7,處理后的熱力圖如圖5(b)所示。 最終入模特征有19 個,包括n1,n3,n4,n6,n8,n9,n10,n11, n12, n13, n17, n19, n20, m1, m3, m4, m6,m8,m9。
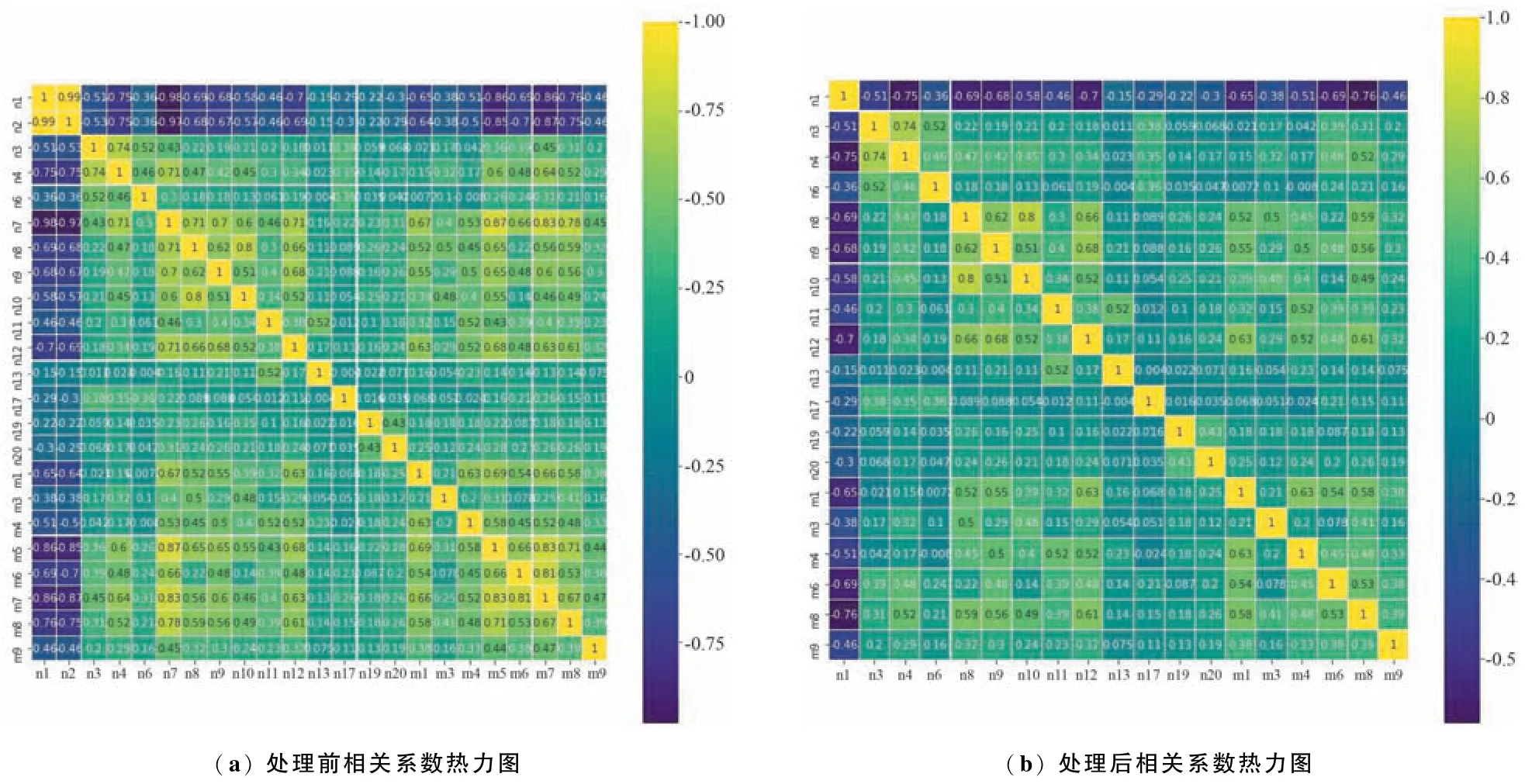
圖5 Pearson 相關系數熱力圖Fig.5 Thermodynamic diagram of Pearson correlation coefficient
3.1.2 質量分類模型
質量分類模型測試集混淆矩陣及接受者操作特性曲線( Receiver Operating Characteristic Curve,ROC)如圖6 和圖7 所示,其中圖7 的橫縱坐標分別表示假正率和真正率。 模型宏平均ROC 下面積AUC(Area Under Curve)和微平均AUC 分別是0.97和0.99。 為了分析每個特征對于終端運行質量分類的重要程度,本文按照gini 指數計算特征的重要性,排序如圖8 所示。

圖6 隨機森林模型的混淆矩陣Fig.6 Confusion matrix for the random forest model
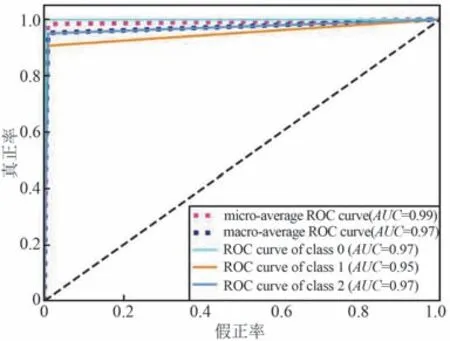
圖7 隨機森林模型的ROC 曲線Fig.7 ROC for the random forest model
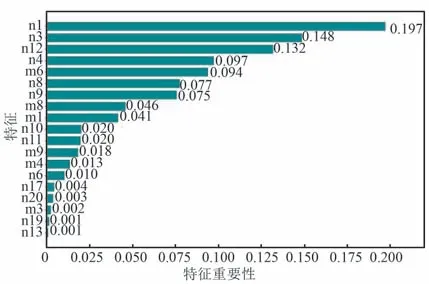
圖8 特征重要性排序Fig.8 Sorting of feature importance
由圖8 可以看出,特征重要性較高的是n1 和n3,即每月有掃碼數據的天數和每月有零售記錄的時段小于8 h 的次數這2 個特征對于終端運行質量的分類較為重要。
3.2 銷量預測模型
3.2.1 實驗設置
將構建的數據集按照7 ∶3 的比例劃分為訓練集和測試集。 本文搭建的BERT-MLP 模型由2 部分組成:第1 部分BERT 預訓練模塊采用中文“Chinese_L-12_H-768_A-12”網絡框架;第2 部分多層感知機模塊,主要包括2 個隱藏層和一個回歸預測層。 模型的超參數設置如表4 所示。 激活函數選用ReLU,初始學習率設置為0. 001,并采用隨機梯度下降法進行優化。

表4 模型超參數Tab.4 Hyperparameters of the model
3.2.2 模型評估
模型訓練損失曲線如圖9 所示。
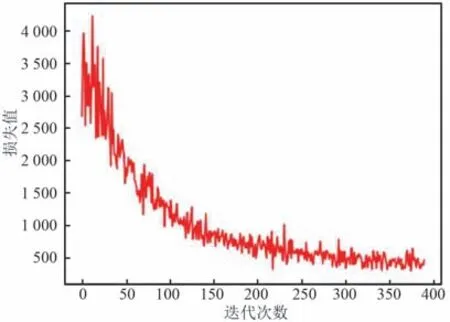
圖9 模型訓練的損失曲線Fig.9 Loss curve of model training
本文選擇平均絕對誤差(Mean Absolute Error,MAE)、均方根誤差(Root Mean Square Error,RMSE)和決定系數(R2)作為評估模型性能的評價指標,計算公式如下:
式中,表示預測值;yi表示真實值。
模型在測試集上各個評估指標的結果如表5 所示。 此外,將真實值和預測值進行比較并可視化,如圖10 所示。 可以看出模型具有較好的擬合效果,能夠有效地預測卷煙銷量。
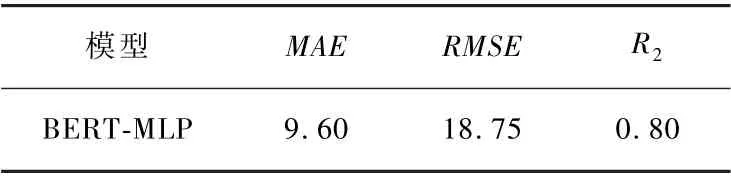
表5 不同評估指標的結果Tab.5 Results of different evaluation indicators
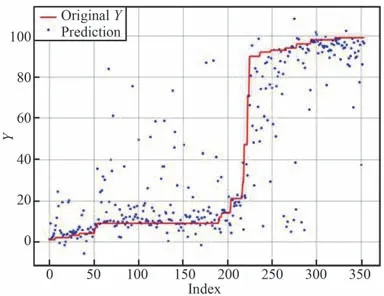
圖10 預測值和真實值的比較Fig.10 Comparison between predicted value and actual value
4 結束語
本文搭建了卷煙銷量預測方法,包含樣本質量篩選、銷量預測2 個主要階段。 首先,建立了一套量化的零售終端運行質量評估體系,構建質量分類模型,篩選高質量樣本點為后續所用。 在銷量預測階段,通過基于復雜深度耦合網絡的深度學習模型識別卷煙陳列圖片,較為準確地輸出圖片中卷煙的規格及位置,并結合終端卷煙的銷售情況,繪制卷煙陳列價值圖譜。 基于卷煙識別得到的數據,結合品牌文本表示,通過BERT-MLP 模型預測了卷煙的銷量,分析了卷煙規格、陳列位置與銷量之間的相關關系,可為終端陳列優化和智能化管理提供理論和決策支持。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國生殖健康(2019年2期)2019-08-23 08:12:08
當代陜西(2019年10期)2019-06-03 10:12:04
Coco薇(2017年11期)2018-01-03 20:59:57
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
