基于粒子群優化算法改進的XGBoost模型制備C4烯烴工藝條件優化
2023-03-27 12:49:54徐博涵阮敬
科學技術與工程 2023年5期
徐博涵,阮敬
(首都經濟貿易大學統計學院,北京 100070)
C4烯烴常作為化工生產中的基礎原料,以C4烯烴為原料生產清潔友好燃料已成為大勢所趨[1]。增大C4烯烴產量并對其進行綜合利用更是提高經濟效益的必要手段。因此,優化制備C4烯烴的反應條件對提高C4烯烴收率具有重要意義。通過分析實驗數據和調整反應條件,對有機化工反應進行優化,已成為近年來的研究熱點。
在乙醇偶合制備C4烯烴的反應中,收率是反應C4烯烴選擇性和轉化率的重要指標。項陽陽[2]利用回歸分析對反應數據進行建模,探究對實驗有高度顯著影響的因素以及各因素之間的交互作用,最后進行單因素優化。其中陳佳碩等[3]對數據建立回歸模型,得到在溫度和催化劑影響下C4烯烴收率的關系表達式,擬合優度達到0.98,但缺點在于該研究將由5個連續變量組成的催化劑組合視為分類變量,導致求解最佳工藝條件的范圍縮小。李三杰等[4]從關聯分析的角度對數據進行探究,但這一方法有著較好的可解釋性,但無法對優化效果進行量化,只能確定最佳的催化劑組合。
對于各因素之間影響關系復雜、難以量化表示的實驗,網絡和機器學習方法在構建預測模型和優化求解過程中能夠取得較好的效果。張棟等[5]在對變量進行特征選擇后,利用XGBoost算法構建預測模型,利用遺傳算法求解得到優化值。
王巖立等[6]、吳文俊等[7]采用機器學習方法對實驗數據進行擬合,將收率最大視為目標函數,通過優化模型尋找各因素的最佳值,雖然可以得到較高的擬合優度和更大的目標值,但依然會出現因約束條件使用不當而導致的解溢出邊界、計算結果不理想等問題。
雖然各學者利用統計學習和機器學習方法能夠很好地擬合實驗數據,提高了C4烯烴的收率,確定了最佳反應條件,但對于大多數算法來說,超參數是模型在開始訓練之前設定的參數,訓練過程中一直保持不變,其取值控制著模型的擬合程度[8]。因此,通過對模型參數進行優化,提高模型擬合效果,進行更精準的預測和優化,是該研究的創新之處。
為得到較高的預測精度,現以XGBoost模型為基礎,以模型對已知數據的擬合優度最大為目標的優化模型,并設計粒子群優化(particle swarm optimization,PSO)算法得到最優超參數。建立XGBoost和PSO-XGBoost模型,對仿真數據進行預測,從而得到最大收率及其對應的最佳工藝條件,并通過對比驗證超參數優化的有效性。
1 實驗介紹
乙醇在不同的Co負載量、Co/SiO2和羥基磷灰石(hydroxyapatite,HAP)裝料比、乙醇濃度以及一定溫度的作用下,通過反應生成C4烯烴和乙烯、乙醛、脂肪醇等副產物。不同的催化劑組合和溫度會導致產物的分布發生變化,從而對C4烯烴選擇性和乙醇轉化率產生影響。采用選擇性和轉化率描述這一可逆反應的反應程度,選擇性表示某一個產物在所有產物中的占比,轉化率表示反應物轉換成特定生成物的百分比。在上述反應中將C4烯烴選擇性與乙醇轉化率的乘積表示為C4烯烴收率。C4烯烴收率最大時所對應的條件即為最佳反應條件。實驗數據包含115條,記錄了21種催化劑組合在不同溫度下的乙醇轉化率和C4烯烴選擇性。以2021年全國大學生數學建模競賽[9]數據為基礎進行分析和建模,求解C4烯烴收率最大所需的溫度和催化劑組合。
2 實驗結果討論
2.1 相關性分析
數據中每種催化劑組合可用4個變量表示:Co負載量、Co/SiO2和 HAP裝料比、乙醇濃度、總質量,為方便表示和計算,將變量用符號表示,如表1所示。

表1 符號說明表Table 1 Symbol description table
如圖1所示,對于以上定量變量,通過散點圖矩陣展示其分布于相關性情況。從分布上看,各變量分布無明顯規律,催化劑的質量、Co負載量等變量大多集中在一個或多個水平上。溫度與乙醇轉化率、C4烯烴選擇性、C4烯烴收率存在一定正相關關系。還需進一步探究變量間關系。

2.2 影響因素分析
數據中共有21個實驗組,其中A1~A14使用裝料方式Ⅰ,B1~B7組使用裝料方式Ⅱ。通過控制變量的方法,在21組實驗中選取3組,作為主要的對比研究對象。3組實驗的催化劑配比如表2所示。
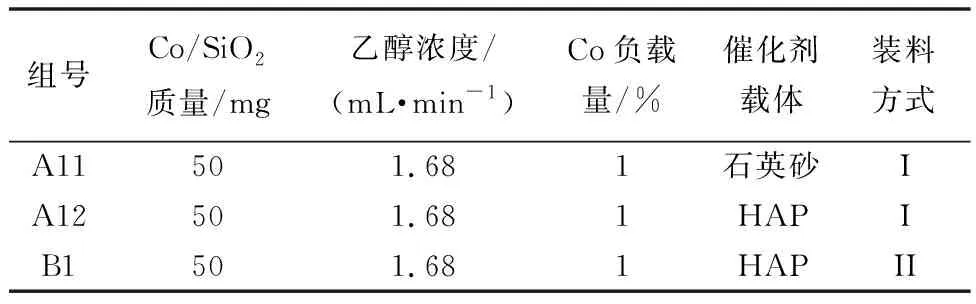
表2 催化劑成分配比表Table 1 Symbol description table
通過控制變量的方法對催化劑載體、裝料方式、反應溫度進行逐個分析,探究這些因素對乙醇轉化率和C4烯烴收率產生的影響。
2.2.1 催化劑載體對烯烴收率的影響
催化劑載體能夠起到提升催化劑活性、提高催化效率的作用。當前催化劑組合中僅有A11使用石英砂作為載體,其余均為HAP。為研究催化劑載體不同對反應的影響,在所有催化劑組合中通過控制變量的法則找到A11和A12兩組實驗,除催化劑載體不同之外,其余條件均相同。
對兩組實驗在不同溫度下的實驗數據進行分析,對比其在不同溫度下乙醇轉化率和C4烯烴收率的變化情況。兩組實驗的乙醇轉化率和C4烯烴選擇性變化趨勢分別如圖2、圖3所示。隨著溫度升高乙醇轉化率和C4烯烴選擇性逐漸增大,經過對比發現,和石英砂相比,A12催化劑使用HAP作為載體,在所有溫度條件下乙醇轉化率更高,C4烯烴選擇性更高,因此使用HAP載體效果更好。
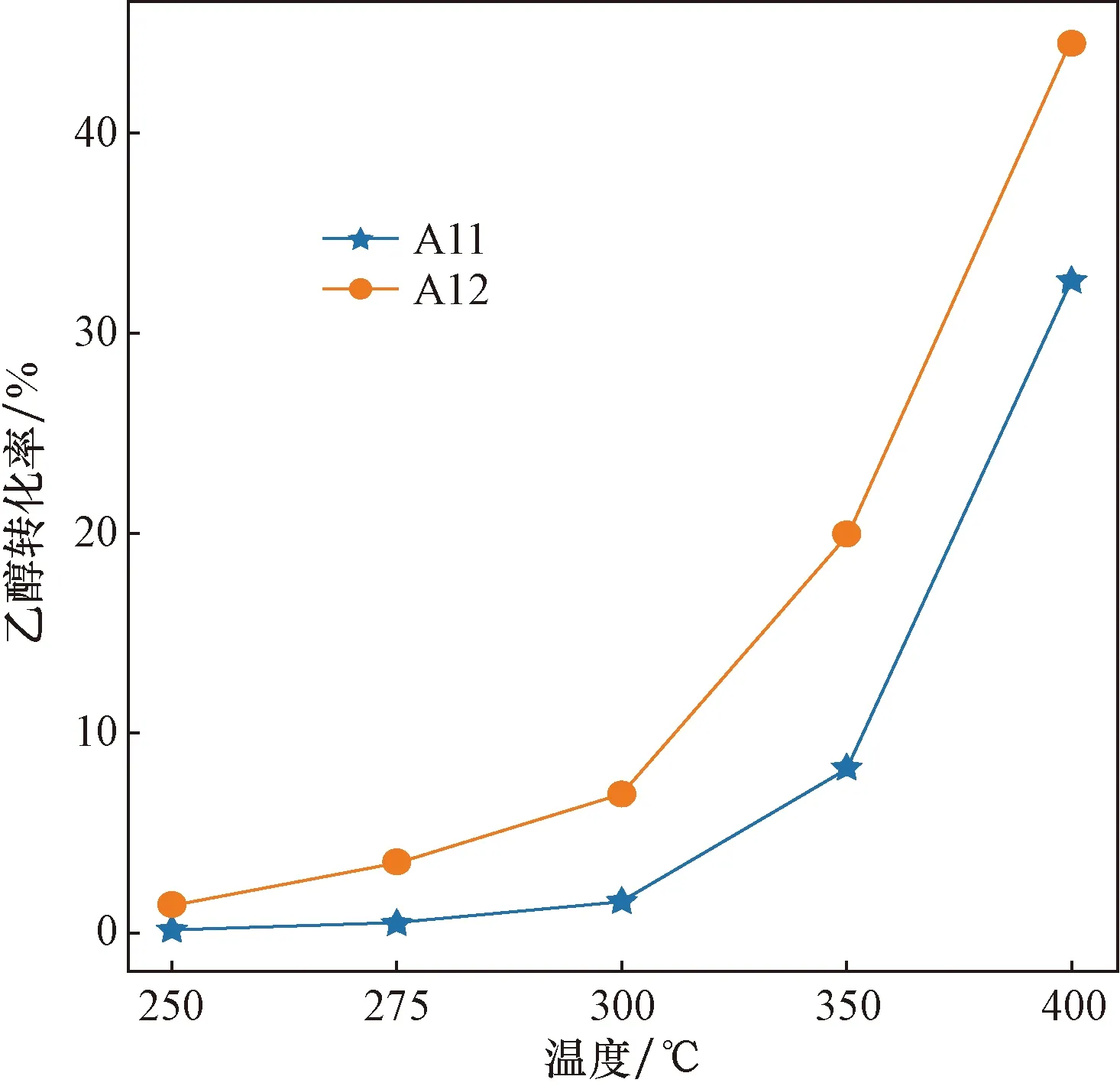
圖2 不同催化劑載體乙醇轉化率折線圖Fig.2 Line chart of ethanol conversion of different catalyst supports
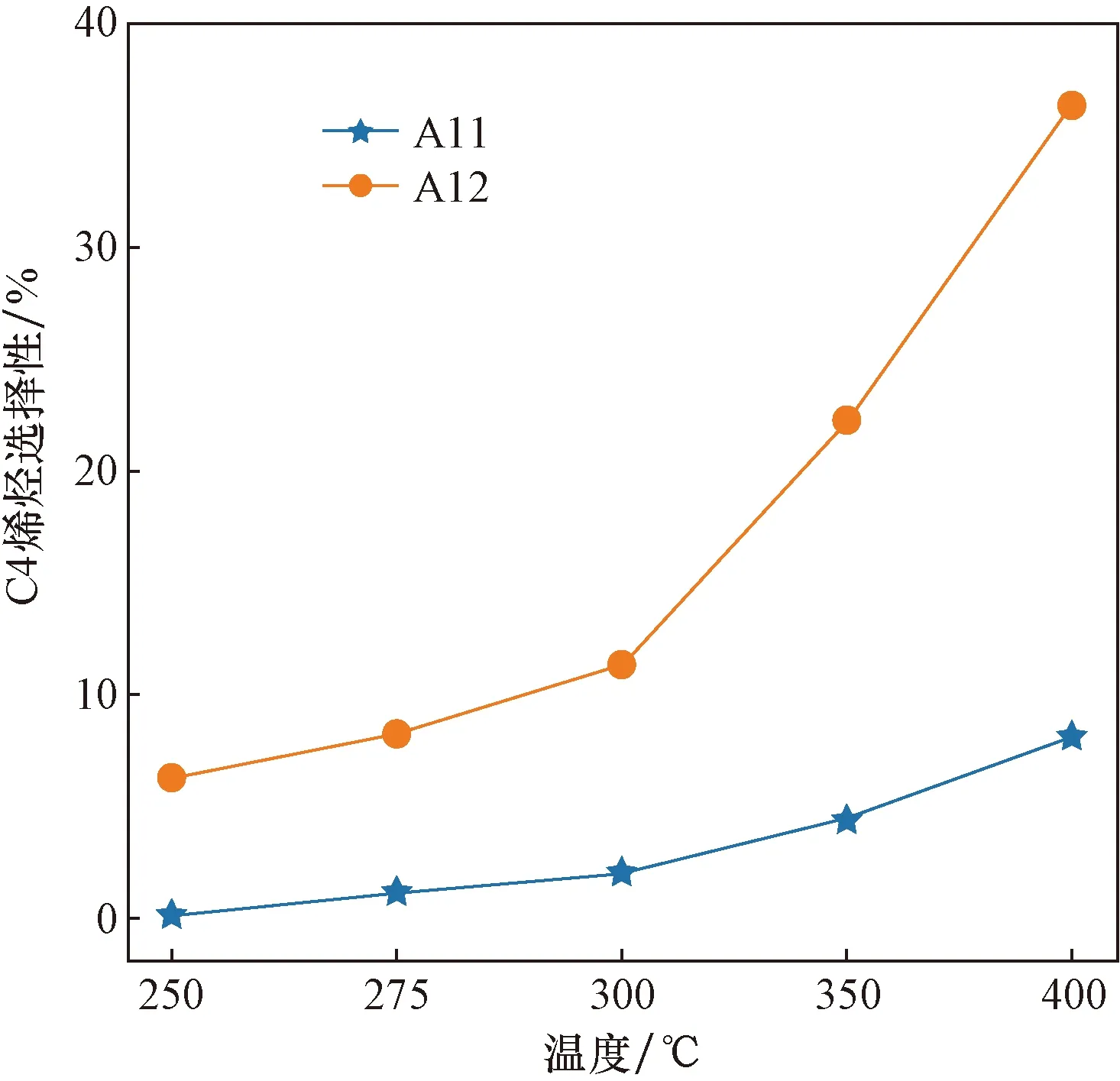
圖3 不同催化劑載體C4烯烴選擇性折線圖Fig.3 Line chart of C4 olefin selectivity for different catalyst supports
2.2.2 裝料方式對烯烴收率的影響
除催化劑載體不同之外,還應注意到A1~A14使用裝料方式Ⅰ,B1~B7使用裝料方式Ⅱ,為研究不同裝料方式對反應的影響,通過控制變量的法則找出A12和B1兩組實驗,除催化劑裝料方式不同之外其余條件均相同。對兩組實驗在不同溫度下的實驗數據進行分析,對比其在不同溫度下乙醇轉化率和C4烯烴收率的變化情況。兩組實驗的乙醇轉化率和C4烯烴選擇性變化趨勢分別如圖4、圖5所示。
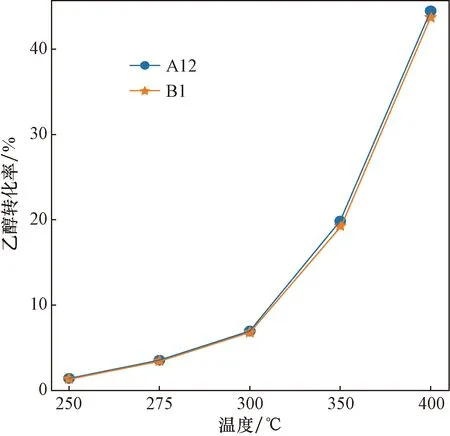
圖4 不同裝料方式乙醇轉化率折線圖Fig.4 Line chart of ethanol conversion by different charging methods
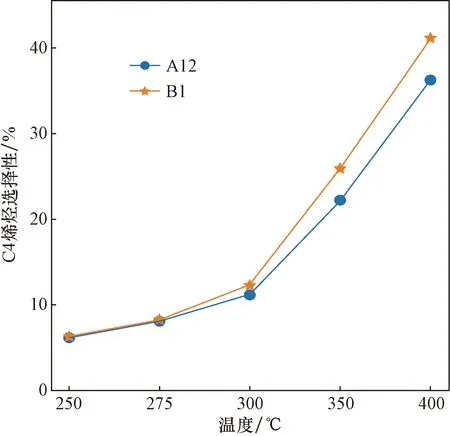
圖5 不同裝料方式C4烯烴選擇性折線圖Fig.5 Line chart of C4 olefin selectivity for different charging methods
雖然裝料方式不同,但各個溫度下的乙醇轉化率基本相同,C4烯烴選擇性在低于275 ℃時完全相同,高于275 ℃時裝料方式I效果更好。
由以上兩項對影響因素的初步分析可得出結論,在確定最優反應條件時,應使用HAP作為催化劑載體。同時,因為裝料方式對反應程度無顯著影響,在后續研究中不考慮這一變量。
因此可將乙醇轉化率和C4烯烴選擇性作為因變量,Co/SiO2、Co負載量、HAP、乙醇濃度、溫度作為自變量。以C4烯烴收率最大為目標,進一步探究因變量和自變量的關系,從而確定最佳的反應條件。
2.2.3 反應溫度對烯烴收率的影響
由表3可知,溫度和乙醇轉化率、C4烯烴選擇性、C4烯烴收率的相關系數均在0.7以上,并且顯著性檢驗P<0.001。對于所有催化劑組合,乙醇轉化率和C4烯烴選擇性均隨著溫度升高而升高。
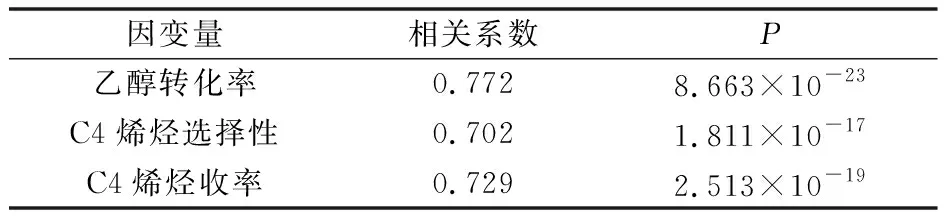
表3 溫度與各因變量相關系數表Table 3 Correlation coefficient between temperature and dependent variable
3 原理分析和模型參數選擇
3.1 XGBoost算法原理分析
XGBoost算法思想是在訓練一棵樹的基礎上訓練下一棵樹,通過不斷訓練彌補差距的樹,用樹的組合實現對真實分布的模擬。算法優勢在于目標函數的正則項能夠控制模型復雜度,有效避免過擬合出現,通過計算損失函數的二階導數,又進一步考慮了梯度變化的趨勢,達到擬合速度快、精度高的效果[10]。
3.1.1 XGBoost建立回歸樹擬合
XGBoost使用分類回歸樹(classification and regression tree,CART)模型,可看作根據輸入的xi預測yi的結構,公式為
(1)
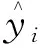
obj(θ)=l(θ)+Ω(θ)
(2)
式(2)中:l為訓練損失函數,用來衡量模型的預測能力,預測準確率越高l則越小;Ω為正則化項,與樹的復雜度有關。
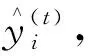
(3)
在添加最后一個新函數時,得到一棵最優的CART樹ft(xi),該樹是在ft-1(xi)樹的基礎上使得目標函數最小,即
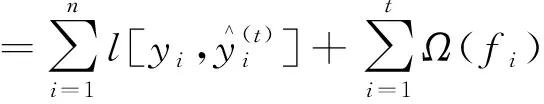
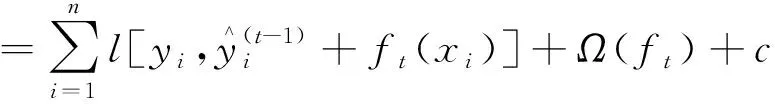
(4)
式(4)中:c為簡化后與自變量無關的常數部分。對目標函數進行求解,需要分為損失函數和正則項兩部分計算。
3.1.2 處理損失函數
為了找到能夠最小化目標函數的ft(xi),模型對其中的損失函數進行二階泰勒展開,得到目標函數的近似函數為
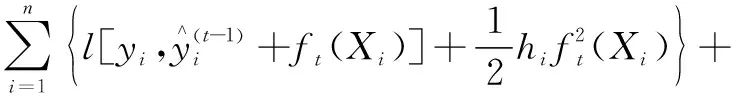
Ω(ft)
(5)
在ft=0處進行二階泰勒展開可得
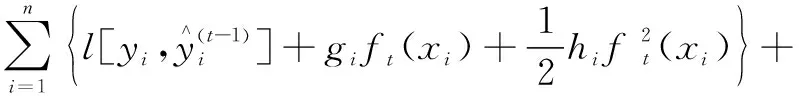
Ω(fi)+c
(6)
去掉常數項可得
(7)
式(7)中:gi和hi被定義為
(8)
3.1.3 正則化項計算
首先將樹的定義可表示為
ft(x)=ωq(x),ω∈RT,q:Ra→{1,2,…,T}
(9)
式(9)中:ω為用來記錄各個葉子節點得分的向量;RT為長度為T的一維向量的集合;q(x)函數的作用是將輸入的xi∈Ra映射到某個葉子節點,→表示映射關系。在XGBoost模型中,正則化項可表示為
(10)
式(10)中:λ為正則化項的權重;γ為用于控制節點分裂的閾值,因此λ和γ越大,模型越簡單。
Ij={i|q(xi)=j}為分配給第j個葉子的數據點的指數集合,至此公式可變形為
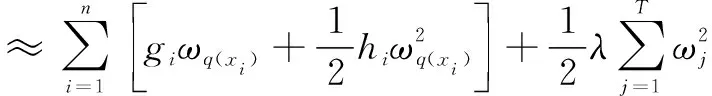
(11)
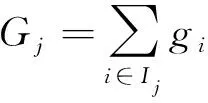
(12)
求解所得到的最優ω值和目標函數值分別為
(13)
(14)
3.2 模型參數選取和調整
3.2.1 參數選取
超參數直接影響XGBoost模型的性能和預測的效果,通常選擇超參數是手動調節的,依靠有限次數的實驗,得到一組相對合適的超參數。這樣的方法很容易錯過最優超參數組合,為了可以更合理、更準確地選擇最優超參數,采用粒子群對超參數進行優化[12]。
XGBoost模型預測時需要確定3種參數:通用參數、Booster參數和學習任務參數。其中學習任務參數定義了最小化的損失參數,對于回歸問題默認損失函數為均方根誤差(root mean squared error,RMSE),與減小模型誤差目的相同,不再進行更改。通用參數根據CART樹及其公式描述,選擇gbtree表示的樹模型對數據進行擬合,用RMSE作為損失函數。相比前兩種參數,Booster參數對算法的性能有著更大的影響,包括學習率、樹的最大深度、最小權重總和、每棵樹隨機采樣的比例等參數。
如果max_depth樹的最大深度過大會導致模型過擬合,過小會導致模型過于簡單。n_estimators 迭代次數過多會影響訓練速度,過少會得不到理想的效果。為降低仿真優化步驟的時間復雜度,將原始數據的20%作為驗證集,80%作為訓練集,在驗證集中考察模型擬合程度和誤差。首先,應用如表4所示的XGBoost的初始化參數擬合數據,在訓練集和測試集中的擬合情況如圖6所示,模型出現過擬合現象,訓練集精確度為0.99,平均絕對誤差(mean absolute error,MAE)為4.58,驗證集精確度為0.76,MAE為247.83。由于超參數對XGBoost模型性能有著較大的影響,并且參數過多,為了得到更精確的仿真模型,選擇利用PSO算法尋找最優參數。

表4 參數初始化值Table 4 Initial values of parameters
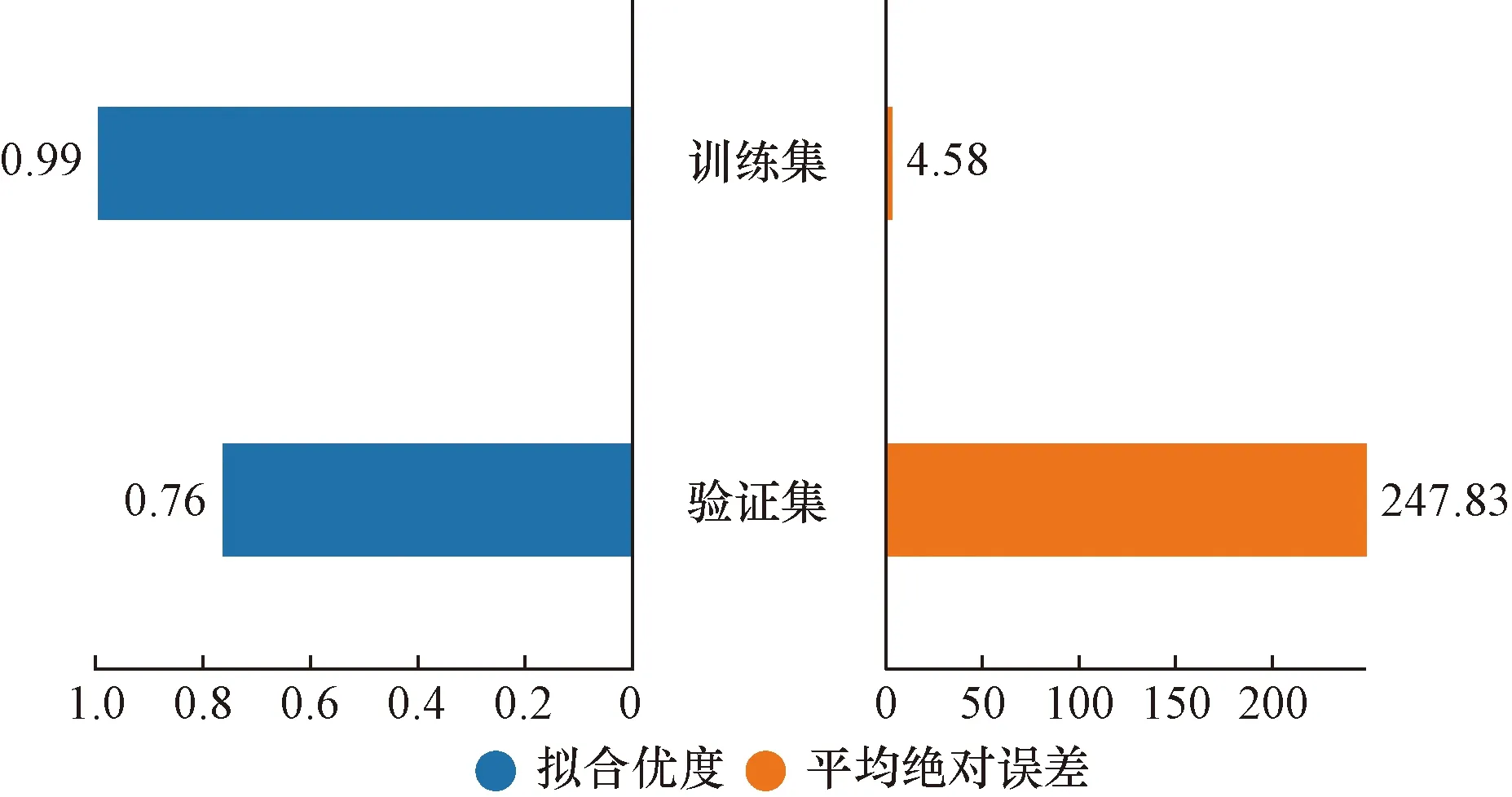
圖6 XGBoost擬合效果Fig.6 XGBoost model fitting effect
3.2.2 應用粒子群算法進行調參
粒子群算法作為一種智能優化算法,常用來求解復雜的多目標優化問題。算法不依賴于梯度下降為搜索方向,而是以適應度函數值作為衡量標準,依概率隨機地在決策空間中進行尋優搜索。該算法的優勢在于操作簡單、收斂速度快,目前已被廣泛應用于函數優化、神經網絡訓練、模糊系統控制以及其他遺傳算法的應用領域。
應用python中的optunity調參優化庫,將驗證集的R2作為目標函數,選擇粒子群算法作為優化方法。調用optunity.maximize函數將約束條件和優化方法作為參數輸入,執行150次。執行粒子群算法過程中,將一些隨機粒子作為初始解,隨后在每一次迭代中,粒子與個體極值和歷史全局最優解進行比較,更新自己的速度和位置。
vi=vi+c1rand()(pbestti-xi)+
c2rand()(gbestti-xi)
(15)
xi+1=xi+vi+1
(16)
式中:i=1,2,…,N,N為群中的粒子總數;vi為第i個粒子的速度;rand ()為介于(0,1)的隨機數;xi為粒子的當前位置,當算法達到指定迭代次數并且全局最優位置滿足最小界限時終止迭代,初始狀態分散的粒子聚集在一個小范圍中或一個點附近。
通過粒子群算法的尋優計算,最終確定文本所用的XGBoost回歸模型最佳參數如表5所示。應用最佳參數組合擬合數據,驗證集效果得到顯著提升,過擬合現象有所緩解。如圖7所示,訓練集R2為0.99,驗證集R2為0.93,MAE為78.00。相比優化之前模型擬合優度提升17%,平均絕對誤差降低169,優化效果明顯。
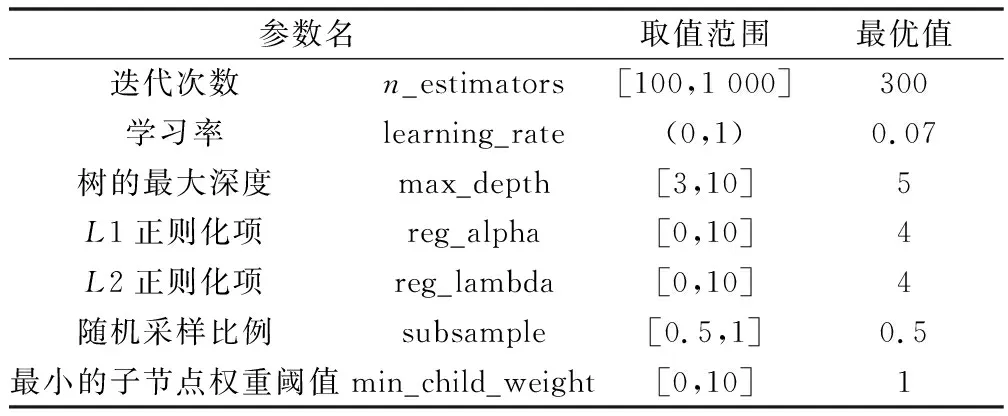
表5 最優參數值Table 5 Optimal parameter value
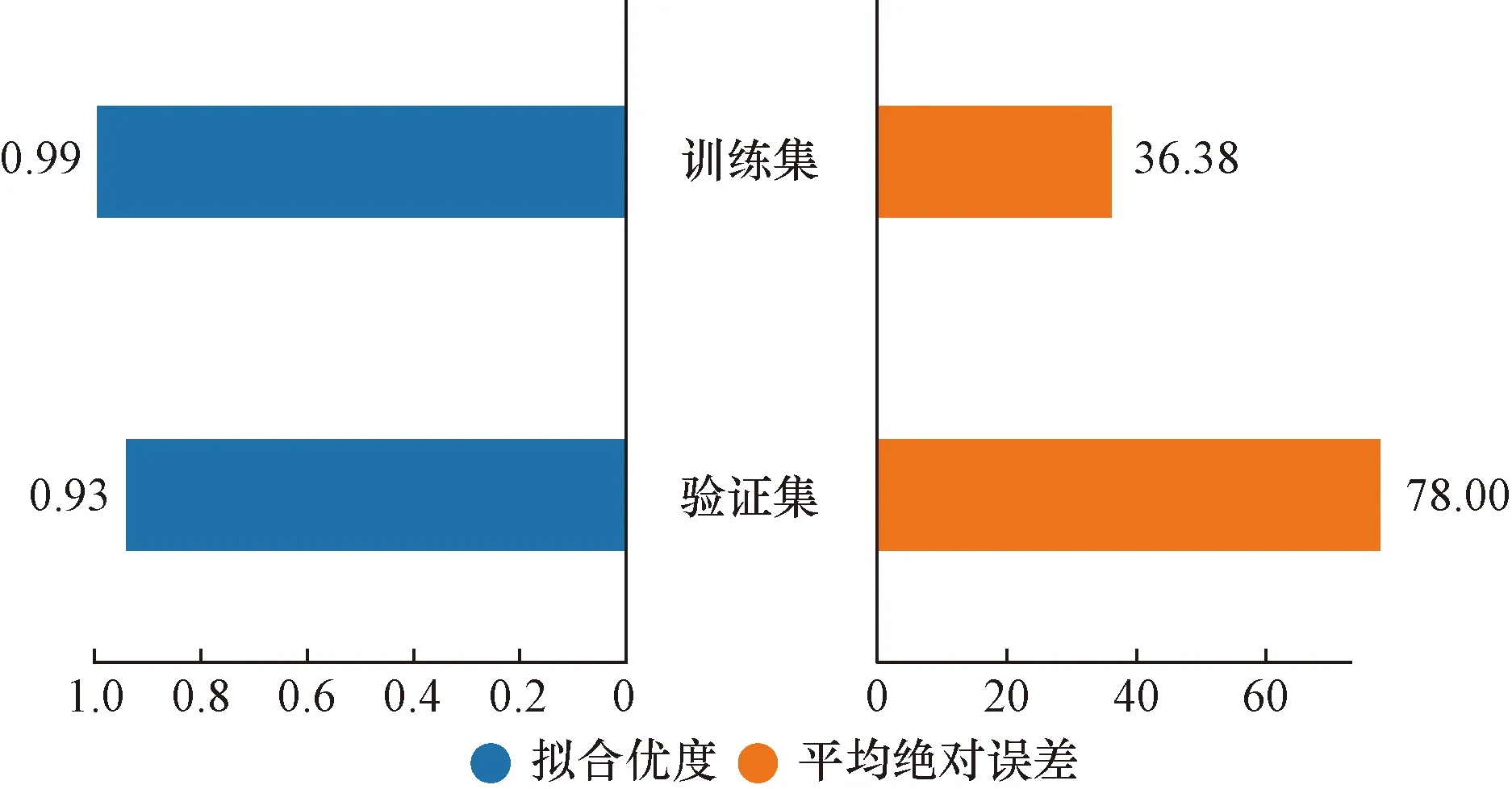
圖7 PSO-XGBoost擬合效果Fig.7 PSO-XGBoost model fitting effect
4 模型求解
4.1 構造仿真數據
對于乙醇制備C4烯烴這一可逆反應,其反應程度除了受到催化劑和溫度的影響之外,還需考慮有機物分子結構復雜、不穩定的特點,以及生成物之間的相互影響、生成物對產物的影響。鑒于反應的復雜性和可變性,函數往往帶有隨機參、變量[13],導致基于數學模型的優化方法在應用中具有相當局限性。
利用仿真方法可以求解一些難以用數學模型表達的優化問題。侯影飛等[14]通過建模對微波反應器的負載參數進行仿真訓練,優化出使得微波反應器獲得最優加熱均勻性和加熱效率的負載參數。仿真優化的過程先用XGBoost模型擬合自變量和因變量,并通過粒子群算法調整參數提升擬合優度,最后將生成的催化劑和溫度組合策略逐一輸入仿真模型中,比較模型訓練后的輸出結果,從中確定最佳制備條件[15-17]。
通過對Co/SiO2質量、Co負載量、HAP質量、乙醇濃度、溫度5個自變量設置取值范圍和間隔,并將各自變量取值進行組合,生成1 312 000種反應條件的組合。其中溫度取值為250~450、步長為5的序列;Co/SiO2質量取值為10~200、步長為10的序列;HAP質量為50~200、步長為10的序列;Co負載量為0.5~5、步長為0.5的序列;乙醇每分鐘滴入的濃度為0.3~2.1、步長為0.3的序列,設置模型的輸出結果為C4烯烴收率。
4.2 應用改進后模型優化工藝條件
經過粒子群優化算法調整后的XGBoost模型可以較好地擬合數據,將模型應用于構造出的測試數據集。其中溫度、Co/SiO2質量、HAP質量、Co負載量、乙醇濃度作為輸入變量,應用改進后的XGBoost模型對輸入數據進行預測,輸出每一種條件下對應的C4烯烴收率。找出輸出結果中最大值及其對應的反應條件。最終得到C4烯烴收率最大值為43.52%,對應的反應條件為450 ℃、Co/SiO2質量為200 mg、Co負載量為1%、HAP質量為200 mg、乙醇濃度為0.9 mL/min,即催化劑組合為200 mg 1%Co/SiO2-180 mg HAP質量-0.9 mL/min乙醇濃度。
4.3 模型結果分析
如圖8所示,從各變量重要程度看出,溫度對C4烯烴收率的提升起到了重要的作用,將各變量F-score進行歸一化后,溫度變量的影響占比56.5%。其次是Co/SiO2質量,結合相關系數熱力圖(圖9)可知,Co/SiO2質量增大能夠對反應起到促進作用。Co負載量和乙醇濃度變量重要程度較低,從相關系數可知,C4烯烴收率隨著兩個變量的增大而減小。HAP質量對反應優化的貢獻最小,影響占比僅有5%。
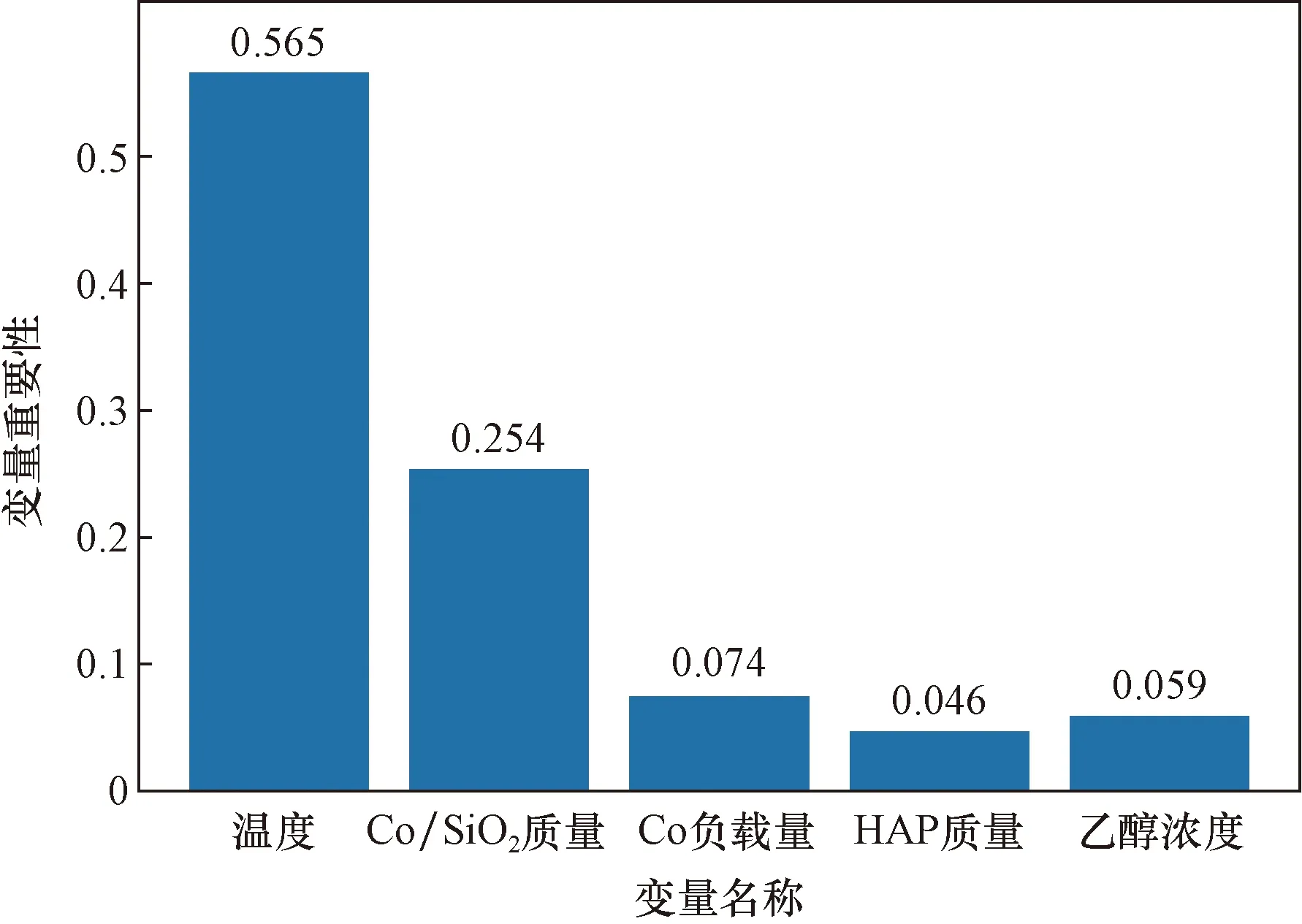
圖8 變量重要程度直方圖Fig.8 Histograms of the importance of variables
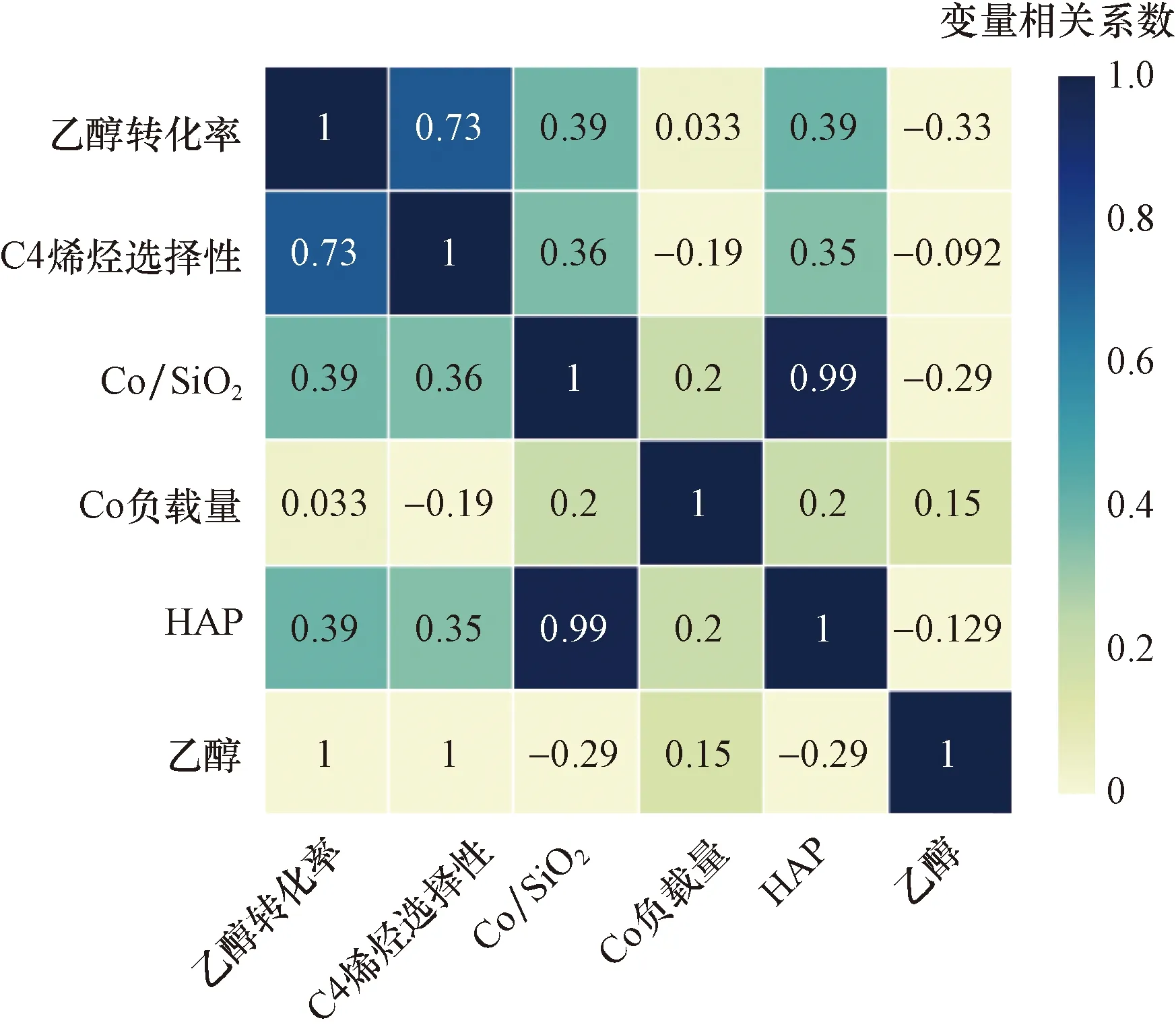
圖9 變量相關系數熱力圖Fig.9 Variable correlation coefficient thermal map
5 結論
XGBoost和粒子群算法等機器學習模型,已廣泛應用于各個領域的系統分析及優化,采用粒子群算法確定XGBoost模型的最佳參數,將其用于提升XGBoost回歸模型對數據擬合的效果,從而進行更精確的仿真訓練、尋找最優反應條件,得出如下結論。
(1)對原始數據給出的實驗結果進行分析可知,對C4烯烴收率產生影響的有如下5個變量:Co/SiO2、Co負載量、HAP質量、乙醇濃度、溫度。并且隨著溫度增加,乙醇轉化率和C4烯烴選擇性逐漸增大。
(2)通過粒子群算法確定XGBoost模型的最優參數,目的在于提高數據擬合精度,得到更準確的預測結果。實驗結果表明,使用最優參數的XGBoost模型擬合優度達到93%,能有效提高模型的精度。
(3)通過將調參后的XGBoost模型應用至構造的數據中,輸出的C4烯烴收率最大值為43.52%,對應的最佳反應條件為:溫度450℃,Co/SiO2質量為200 mg,Co負載量為1%,HAP質量為200 mg,乙醇濃度為0.9 mL/min,即催化劑組合為200 mg 1%Co/SiO2-180 mg HAP-乙醇濃度0.9 mL/min。
(4)通過對數據進行擬合以及仿真訓練確定最佳工藝制備條件,為其他工業生產中的問題提供了方法上的參考,具有一定的經濟價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
石油石化綠色低碳(2019年6期)2019-02-13 09:39:01
光學精密工程(2016年6期)2016-11-07 09:07:19
浙江大學學報(工學版)(2016年11期)2016-06-05 09:21:04
