改進的漸進加密三角網機載點云濾波方法
2023-04-06 10:10:46王效蓋劉翔宇
北京測繪 2023年2期
關鍵詞:方法
王效蓋 王 健 劉翔宇 曹 一
(山東科技大學 測繪與空間信息學院, 山東 青島 266590)
0 引言
機載激光雷達(light detection and ranging,LiDAR)技術是一種高效、快速、大區域采集三維空間點云的主動遙感技術,已廣泛應用于數字模型構建、實景三維建設、森林資源管理、地質災害監測等領域[1]。其中,機載點云濾波是分離地面點和非地面點的關鍵步驟,也是LiDAR點云數據后續實際應用的基礎。目前地面濾波算法主要分為坡度濾波、形態學濾波、分割濾波和插值濾波。
坡度濾波是利用點云之間坡度變化分離地面點的一種濾波方法,這類方法十分依賴坡度閾值的設定,其對連續地形有較好的分割結果,但在陡坡、樹木與地面連接處等坡度突變區域容易出現錯誤濾波現象[2-3]。形態學濾波主要原理是LiDAR點云在形態學開閉運算前后存在高程差異,高程變化小的為地面點,反之為非地面點,其精度依賴窗口大小的設置,需要使用者設定合理的窗口參數,對非專業人員不友好[4]。分割濾波首先根據LiDAR點云某種屬性對其進行分割操作,并根據分割屬性之間的差異分離地面點和非地面點,在特殊地形中有較好的分割結果,但其精度受分割結果影響較大[5-6]。插值濾波首先需要選擇地面種子點,并使用插值方法生成初始參考面,若待分類點與參考面之間滿足一定的關系則將其劃歸為地面點,基于插值的濾波方法原理簡單、濾波結果可靠、魯棒性強,但是其結果容易受種子點構造初始參考面精度的影響[7-8]。Axelsson提出的漸進加密三角網(triangulated irregular network,TIN)濾波方法(progressive TIN densification,PTD)是插值濾波中的經典算法,因其較高的濾波精度和較快的濾波速度而被集成于多個開源或商業軟件中,如TerraSolid等[9]。實驗發現,PTD算法在對平坦或地形簡單的區域有較好的濾波效果,但在復雜林區中因獲取初始地面種子點數量變少且可靠性降低,導致在進行迭代運算時誤差累積增大,使其濾波效果不太理想。
為此,在PTD算法的基礎上,本文提出了一種適用于林區LiDAR點云改進的漸進加密三角網濾波方法(improved progressive TIN densification,IPTD)。IPTD算法在地面種子點選取策略上做出一定改進,借助布料模擬算法和局部薄板樣條插值獲得大量分布均勻且可靠的地面種子點,用以提高初始TIN的精度,然后對待分類點進行迭代濾波,從而提高算法在林區環境中LiDAR點云的濾波精度。
1 漸進加密三角網濾波
漸進加密三角網濾波算法是Axelsson在2000年提出的一種經典插值濾波方法并且得到廣泛的使用[9]。算法流程中選取局部窗口的最低點作為初始地面種子點,以此構建初始三角網,通過計算待定點P到ABC平面的距離d及連線之間的夾角α、β、γ,判斷距離和角度是否滿足設定閾值,若滿足則將P點加入地面點并構建新的三角網,反復迭代至沒有新點加入,濾波完成。漸進加密三角網濾波算法原理如圖1所示。
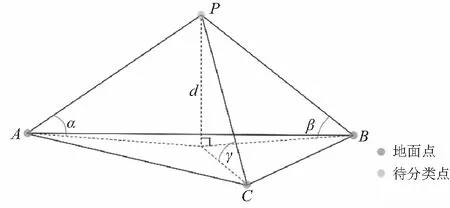
圖1 漸進加密三角網濾波原理
該算法具體步驟為:
(1)選擇地面種子點。對研究區域進行規則格網劃分,格網大小設置為區域最大建筑物大小,選取格網中最低點作為初始地面種子點。
(2)構建初始三角網。根據(1)中選擇的地面種子點構建一個稀疏的初始三角網。
(3)待定點分類。依次遍歷所有待定點,分別計算待定點到三角網平面的距離和夾角,若距離和角度均滿足設定閾值,將該點劃分為地面點。
(4)更新三角網。使用新加入的地面點對三角網進行更新,生成新的三角網。
(5)重復步驟(3)和(4),迭代至沒有新增的地面點,算法結束。
該算法原理簡單,效果穩定,對于城市和林區都有較強的適用性。其算法精度主要取決于初始三角網構建的準確性和迭代閾值的設定。在植被密集覆蓋且地形崎嶇復雜的林區,采用局部最小值獲取的種子點可靠性降低,從而影響初始三角網的準確性,最終使得濾波精度較低濾波效果不理想。
2 改進的漸進加密三角網濾波方法
2.1 噪聲剔除
原始機載LiDAR數據中噪聲來源于掃描儀本身或受環境影響產生的多路徑效應。這對使用布料模擬算法獲取潛在地面種子點時產生嚴重影響,導致獲取的潛在地面種子點結果不可靠。因此,在進行后續處理前需要剔除原始點云中遠離主體點云的離群噪聲點。基于空間位置分布的去噪算法(statistical outlier removal,SOR)能夠穩健的檢測這些離群點。SOR濾波器對每個點進行K鄰域統計分析,計算K個鄰近點平均距離分布的均值和標準差,將平均距離在給定閾值范圍之外的點視為離群點并剔除。如式(1)所示,本文使用12個最近鄰計算每個點的均值和中值距離。
Max(d)>Mean(d)+Std(d)
(1)
2.2 獲取潛在地面種子點
布料模擬濾波算法是由Zhang等提出的一種新型濾波方法,其基本思想:首先將機載LiDAR點云進行倒置并在測量點上方覆蓋一塊柔性布料,柔性布料在重力的作用下逐漸黏附在測量點上,最終柔性布料模擬出一個近似的地形表面,如果測量點到柔性布料的距離滿足閾值要求則標記為地面點[10]。布料模擬的優點在于:①參數設置簡單,僅需較少的參數即可完成濾波;②地形適應性好,可用于連續地形、陡坡和斷崖;③運算效率高。PTD算法中只有少數點被選為地面點,導致初始三角網精度較低。相比之下,布料模擬算法可以獲取大量分布均勻的潛在地面種子點。布料模擬算法過程如圖2所示。

圖2 布料模擬算法過程
2.3 獲取地面種子點
在應用布料模擬算法濾波后,某些非地面點會錯誤的包含在潛在地面點中,為了提高原始三角網構建的精度,需要識別并剔除這些非地面點,本文使用薄板樣條插值方法來檢驗并消除非地面點。薄板樣條插值是一種空間離散點擬合精度高、魯棒性強的空間插值方法,在對復雜地形的模擬中表現出較好效果[11]。
對于3維空間中的測量點集(X,Y,Z),薄板樣條插值曲面可由式(2)表示。
(2)
(3)
其中,N是用于TPS插值的控制點數;p(x,y)是趨勢函數,a是它的系數;wi是與控制點相關的權重;q(ri)是徑向基函數。徑向基函數定義為
q(r)=r2ln(r)
(4)
r為兩點間的歐氏距離。矩陣表達式如下:
(5)
實驗發現,非地面點存在局部高程突變的現象,本文認為在鄰域點云中高程值異常的點為非地面點,并構造插值曲面從潛在種子點中篩選并去除非地面點。因為求解薄板樣條插值函數系數的時間和插值點的數量成正比,所以本文采用局部薄板樣條插值代替整體薄板樣條插值來提高效率。具體步驟為:①使用規則格網(20×20)組織潛在地面點數據,并選擇局部最小值作為插值點;②搜索待估計潛在種子點K鄰域的插值點,構造局部薄板樣條插值曲面,K設置為12,并將激光腳點坐標代入求解插值高程;③計算真實高程與插值高程的殘差,若高程殘差大于設定的殘差閾值,則認為該點為非地面點并從潛在種子點中剔除;④逐點篩選得到地面種子點。
2.4 改進的漸進加密三角網濾波
傳統漸進加密三角網濾波算法選擇種子點采用格網區域高程最低點,在林區環境下種子點選取較少且可靠性低,在進行迭代運算時造成誤差累積。因此,本文在種子點選取策略上做出改進,使用布料模擬算法和局部薄板樣條插值獲得大量分布均勻和可靠的地面種子點,解決傳統漸進加密三角網濾波在林區環境下種子點稀疏的問題,提高林區下的適應性。改進的漸進加密三角網濾波步驟如下:
(1)種子點選取。首先使用布料模擬算法提取機載LiDAR點云中的潛在地面點,然后通過局部薄板樣條插值剔除潛在地面點中的非地面點,獲得分布均勻和可靠的地面種子點。
(2)初始三角網構建。在機載LiDAR點云四周設置寬度為m的緩沖區,并以固定間隔n構造輔助點,輔助點高程為最近種子點的高程[12]。通過種子點和輔助點構建初始三角網。
(3)三角網濾波。計算待定點到鄰近三角形的距離和角度,若其距離和角度小于設定的距離閾值和角度閾值,則分為地面點。
(4)更新三角網。將步驟(3)地面點與已有種子點重新構建三角網。
(5)迭代運算。重復步驟(3)和(4),迭代運算至沒有新的地面點加入。
3 實驗及結果分析
采用國際攝影測量與遙感學會(International Society for Photogrammetry and Remote Sensing,ISPRS)標準數據和林區數據進行實驗并對濾波結果進行精度分析。本文采用的濾波精度評價指標為Ⅰ類誤差(T.Ⅰ)、Ⅱ類誤差(T.Ⅱ)、總誤差(T.E)和Kappa系數,其中三種誤差數值越小和Kappa系數數值越大表示濾波精度越高。計算方法如表1所示,其中a和b分別為正確分類和錯誤分類的地面點數;d和c分別是正確和錯誤分類的非地面點數;e是a、b、c和d的總和。
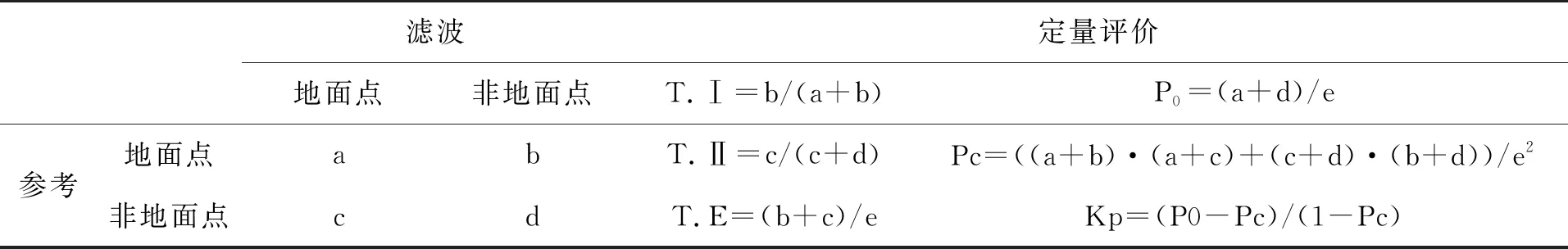
表1 地面濾波精度評價方法
3.1 ISPRS標準數據
采用ISPRS提供的標準數據集中山地部分(samp51-samp71)作為測試數據,驗證本文所提方法的有效性。每個樣本的參考數據都是人工濾波生成的,樣本點被分類為地面點和非地面點。IPTD對ISPRS標準數據集的濾波結果如表2所示。

表2 ISPRS標準數據濾波精度
從表2可以看出:IPTD算法濾波結果Ⅰ類誤差為1.23%,Ⅱ類誤差為12.29%,樣本平均Kappa系數和總誤差分別為84.96%和2.16%,說明本文算法有效控制了Ⅰ類誤差的產生。samp51、samp61和samp71獲得的Ⅰ類誤差均小于1%,其中samp51的Ⅰ類誤差最小,僅為0.09%,說明本文方法在緩坡濾波中能較較好地保留真實地面點,減小其誤分類的可能性。Samp53Ⅱ類誤差最大,高達34.06%,其余樣本數據都控制在一定范圍內,本文算法在斷崖處的濾波還有待優化。表中samp51的Kappa系數最高,高達96.04%,samp61的總誤差最小,僅為0.85%。samp52和samp53的總誤差都較大,samp53的Kappa系數最小,僅為56.06%。圖3和圖4展示了兩個樣本的數字地表模型(digital surface model,DSM)、濾波后的數字高程模型(digital elevation model,DEM)及濾波誤差的空間分布情況,其中藍色為Ⅰ類誤差,紅色為Ⅱ類誤差。由圖3可見,samp52的數據中存在斷崖和陡坡,沿河分布低矮的植被,這些高差突變區域對閾值有一定挑戰,判斷錯誤而造成Ⅱ類誤差較大。由圖4可見,samp53的數據中分布有梯田等落差較大區域,其中誤差分布較多的地方地形變化較大,導致Ⅱ類誤差較大。

圖3 Samp52濾波誤差空間分布

圖4 Samp53濾波誤差空間分布
將本文方法與近年來提出的5種方法進行對比[8,13-16],如表3所示。本文方法在6種方法中總誤差平均值最小,較原有濾波方法總誤差的平均值減小0.75%,且本文方法在所有樣本數據中有3個總誤差最小,說明本文方法在濾波精度上具有一定的優勢。

表3 本文方法與其他5種方法的總誤差對比 單位:%
3.2 林區數據
ISPRS標準數據集點云密度較小且植被特征不夠明顯,為了進一步驗證本文方法在森林地區的適用性,本研究從OpenTopography網站(http://www.opentopography.org/)下載3組高密度林區機載LiDAR數據。3組林區數據具有不同地地形特征:數據Site1位于美國加利福尼亞州內華達山脈南部,為坡度較小和植被覆蓋密集的緩坡地形;Site2位于美國猶他州中南部山區,為覆蓋分散低矮植被的陡坡地形;Site3位于美國科羅拉多州,地形起伏明顯,覆蓋較多密集的植被。3組林區數據點云如圖5所示。

圖5 林區點云數據
采用本文方法和PTD算法對3組樣本數據進行濾波處理并進行對比分析,其結果如表4所示。根據表中數據可以看出,本文方法在Ⅰ類誤差和Ⅱ類誤差上都有大幅的降低,說明本文方法在林區濾波中能夠大幅度減少錯誤分類現象,獲得較準確的地面模型。從總誤差來看,本文方法相較于PTD算法在Site1區域降低了3.51%,在Site2區域降低8.68%,在Site3區域降低4.02%,說明本文方法在總誤差控制上有較好的表現。本文方法Kappa系數最大為94.57,最小為80.14,在Kappa系數有了大幅的提高,其中Site2區域提高僅14.50%。由圖6、圖7和圖8可以看出,本文方法生成的DEM與參考DEM接近。綜上所述,相較于傳統的PTD算法,本文方法可以應用于林區點云濾波中。

表4 林區數據濾波精度對比

圖6 Site1參考數據、PTD和本文方法生成的DEM

圖7 Site2生成的DEM

圖8 Site3生成的DEM
4 結束語
為了提高漸進加密三角網濾波算法在林區機載點云數據中的濾波精度,提出了一種改進的漸進加密三角網濾波方法。所提方法使用布料模擬濾波和局部薄板樣條插值方法代替局部最小值法獲取大量均勻可靠的地面種子點,解決了因種子點稀疏導致初始三角網精度較低的問題。使用ISPRS標準數據和林區數據對方法進行驗證,并與其他濾波方法進行對比分析,本文方法有較低的總誤差和較高的Kappa系數,證明本文方法能有效應用于林區點云濾波中。本文方法在陡坡等復雜地形中濾波誤差仍然較大,未來就提高不同地形下林區點云的濾波精度繼續展開工作。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
