基于二次分解NGO-VMD殘差項與長短時記憶神經網絡的超短期風功率預測
2023-04-10 06:36:20宋江濤崔雙喜劉洪廣
科學技術與工程 2023年6期
宋江濤, 崔雙喜, 劉洪廣
(新疆大學電氣工程學院, 烏魯木齊 830047)
近年來,隨著人們生活質量不斷提高,使得能源消耗也逐日增加,同時生態環境也受到了嚴重的破壞,所以必須尋找新的清潔能源代替化石能源去緩解這一現象[1]。風能為一種環境友好型的綠色能源,其豐富的儲能讓它在各國得到了快速的發展。然而,風能受氣象和環境等因素的制約,使得風力發電呈現出波動與隨機等特點[2],這影響了電網對風電的調度,阻礙了風能的發展。目前,對風電功率的精準預測是幫助運行人員實現合理的風功率規劃和實時調度,保證電力系統可靠運行的重要方向[3-4]。現如今,超短期風功率預測方法大致可以分為物理方法、時間序列方法、人工智能方法三大類[5-6]。物理方法主要是利用氣象數據和地面物理信息計算風電機組輪轂高度的風速大小與風向等信息。通過物理方法預測風功率不需要風電場的歷史數據,但其預測精度高度依賴氣象數據[7],由于氣象數據往往更新較慢,這導致物理方法預測精度較低。
時間序列法指只采用歷史功率數據來預測未來的功率數據的方法。時間序列法有:持續法、自回歸滑動平均法[8]等。時間序列方法雖然簡單,但其未考慮氣象因素,當氣象變化劇烈時,其預測精度會隨時間的增加而降低。
人工智能是目前研究的熱門領域,其通過不同的人工智能方法找出功率影響變量和輸出功率之間的非線性映射關系。人工智能法主要包括極限學習機(extreme learning machines, ELM)[9]、支持向量機(support vector machine, SVM)[10]、人工神經網絡(artificial neural network, ANN)[11]等。文獻[12]為解決風功率預測過程存在過學習等問題,提出將支持向量機(SVM)應用于風功率預測,取得了較好的結果,但該方法應用于大規模數據時結果并不理想。文獻[13-14]采用長短時記憶神經網絡(long short-term memory, LSTM)和其他機器學習模型作對比,結果表明LSTM預測精度更高,但如果輸入LSTM的數據質量參差不齊時,其預測精度明顯下降,需要組合其他相關技術進行改善。文獻[15]提出了一種基于經驗模態分解(empirical mode decomposition, EMD)與LSTM組合預測方法,先用EMD對原始序列進行分解,將其再作為LSTM的輸入進行預測,該方法有效提高了LSTM的預測精度,但EMD容易產生模態混淆的現象。文獻[16]提出了變分模態分解(variational mode decomposition, VMD),該分解方式能夠有效解決EMD模態混淆的問題,但其效果與參數設置密切相關。文獻[17]采用麻雀搜索算法對VMD的參數進行尋優,并對各子模態采用不同LSTM參數分別進行預測,取得良好的預測效果。
為了充分挖掘數據信息,提高預測精度,許多學者嘗試研究二次分解技術。文獻[18]先采用快速集合經驗模態分解(fast ensemble empirical mode decomposition, FEEMD)[19]將風功率分解后,對其分解后的高頻模態采用VMD進行二次分解,有效提高了預測精度。文獻[20-21]均對分解后復雜程度較高的前幾個模態分量進行VMD二次分解。試驗表明二次分解技術的組合預測模型的預測精度較EMD、VMD等一次分解模型得到了很大提升。但目前使用變分模態分解(VMD)搭建的單次分解組合預測模型中,大多均直接忽略了風功率經VMD分解后殘差項,在二次分解風功率組合預測模型中都未對分解后的殘差項進行二次分解,其都忽略了殘差項所包含的豐富信息。
鑒于以上問題和結論,現提出一種基于二次分解NGO-VMD殘差項與LSTM的超短期風功率組合預測模型;首先,使用北方蒼鷹優化算法(northern goshawk optimization,NGO)[22]對VMD的參數進行尋優,以選出最佳VMD參數組合;其次,采用NGO-VMD模型對VMD殘差項進行二次分解,利用K均值聚類算法解決VMD分解模態分量個數多,計算量繁冗的問題;最后,建立LSTM模型對各子模態分別預測并疊加各子模態的預測值得到超短期風功率預測結果。通過對新疆某風電場的實際發電功率的預測結果分析來驗證該組合模型可行性和優越性。
1 理論與方法
1.1 變分模態分解
變分模態分解是一種時頻分析方法,其能夠自適應分解非平穩信號,將原始多分量信號分解為多個調幅調頻單分量信號,有效避免了在迭代的過程中遇到的端點效應等問題。
VMD分解的每個模態uk(t)具有不同的有限帶寬,而VMD的目標是使其分解的各子模態的估計帶寬的和最小,其變分模型表達式為
(1)
為了求解式(1),先構建一個的增廣拉格朗日函數,即
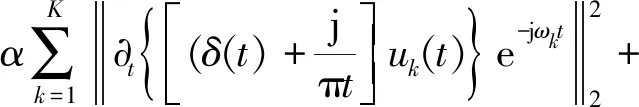
(2)
式(2)中:α>0;λ為乘法算子。
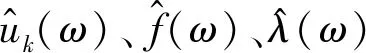
(3)
再更新中心頻率,方法為
(4)
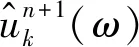
最后更新λ(t)的傅里葉變換,即
(5)
式(5)中:τ為步長,τ>0。
VMD分解的具體流程如表1所示。

表1 VMD具體流程Table 1 VMD-specific process
1.2 北方蒼鷹優化算法
北方蒼鷹優化算法(northern goshawk optimiz-ation, NGO)是一種群體的優化算法,該算法模擬了北方蒼鷹捕殺獵物時的行為,具有卓越的優化性能,其尋優準確度及穩定性[22]。其規則如下。
步驟1初始化種群。種群成員在搜索空間中隨機初始化。在北方蒼鷹優化算法中,北方蒼鷹種群用種群矩陣X為
(6)
式(6)中:Xi為第i個北方蒼鷹的位置;N為北方蒼鷹的種群數量;m為求解的維度;xi,j為第i個北方蒼鷹的第j維的位置。
進行北方蒼鷹優化算法時,北方蒼鷹種群的目標函數值可以用向量表示,即
(7)
式(7)中:F為北方蒼鷹種群的目標函數向量;Fi為第i個北方蒼鷹的目標函數值。
步驟2獵物的識別和攻擊。獵物識別是北方蒼鷹在狩獵的第一階段,北方蒼鷹隨機選擇一個獵物,然后快速攻擊它。此階段為搜索空間的全局搜索,目的是識別最優區域。數學模型為
Pi=Xk,i=1,2,…,N,k=1,2,…,i-1,
i+1,…,N
(8)
(9)
(10)
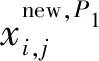
步驟3追逐和逃生。北方蒼鷹攻擊獵物后,獵物會試圖逃跑,北方蒼鷹需要繼續追逐獵物。北方蒼鷹的速度很快,所以它們幾乎可以在任何情況下追逐獵物并最終捕獲獵物。這種行為的模擬增加了算法對搜索空間的局部搜索的利用能力。在北方蒼鷹優化算法中,假設這次狩獵范圍的半徑約為R。北方蒼鷹與獵物之間的追逐過程的數學模型為
(11)
(12)
(13)
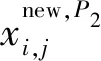

表2 NGO具體流程Table 2 NGO-specific process
1.3 K-means算法
K-means算法是最為常用的一種經典的聚類算法[23],基于數據之間的距離將相似特征的樣本自動歸到一個類別中,具有執行過程簡單、收斂速度快的優點。K-means算法的基本過程如下。
步驟1隨機選取K個點作為初始聚類的簇心。
步驟2分別計算其他每個樣本點到K個簇心的歐式距離,將其余所有樣本點歸屬到離該點最近的簇。
步驟3將所有樣本點都歸屬到對應的K個簇后,更新簇心。
步驟4反復迭代步驟2~步驟3,直至簇心不再發生明顯的變化,即收斂。
1.4 長短期記憶網絡(LSTM)
長短期記憶網絡(long short-term memory,LSTM)是為解決傳統循環神經網絡(RNN)在信息傳遞時出現的梯度消失、爆炸等問題而提出的一種改進RNN神經網絡,其用記憶單元代替RNN的隱含節點,能夠有效可靠地處理長時間序列數據。
LSTM的核心是它的“細胞狀態”以及“門”結構。細胞狀態是信息傳輸的路徑,相當于網絡的“記憶”;“門”結構的功能是實現信息的添加和丟棄。LSTM由多個重復的記憶塊結構組成,每個記憶塊結構都包含3個“門”結構,分別是遺忘門、輸入門及輸出門。LSTM利用激活函數σ來控制其3個“門”結構。單個LSTM的結構示意圖如圖1所示。
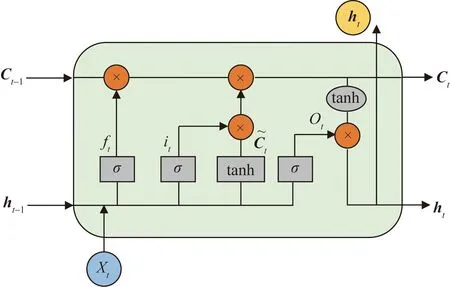
圖1 LSTM結構示意圖Fig.1 Schematic diagram of LSTM structure
LSTM3個“門”變量運算公式如下。
(1)遺忘門層ft由sigmoid層決定信息的更新。
ft=σ(Wf[ht-1,xt]+bf)
(14)
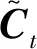
(15)
(3)輸出門層有選擇性地輸出細胞狀態信息。
(16)
式中:xt為細胞輸入值;σ為sigmoid激活函數;Wf、Wi、WC、Wo分別為遺忘門、 輸入門、細胞狀態、 輸出門sigmoid 激活函數的權重;bf、bi、bC、bo分別為遺忘門、 輸入門、細胞狀態、 輸出門sigmoid 激活函數偏置;ht為時刻t的隱藏層向量。
2 風電功率預測模型的構建
2.1 基于NGO優化VMD
VMD可將原始風電功率分解成不同頻率、具有較強規律性的風功率子序列,降低了風電功率序列的復雜度,但VMD必須需要預先人工設置其參數,在一定程度上影響了VMD分解的精度和效果,具有一定局限性。由于VMD分解效果與參數懲罰因子α和分解層數K密切相關,故本文采用北方蒼鷹優化算法(NGO)對VMD的分解層數K和懲罰因子α進行尋優,將局部最小包絡熵作為參數尋優的適應度函數。
包絡熵可以反映原始風電信號的稀疏特性,當分解的子分量中包含較多的特征信息且噪聲較少時,則包絡熵值較小,反之,則包絡熵值較大。包絡熵Ep運算公式為
(17)
式(17)中:ej為a(j)歸一化得到的結果;a(j)為VMD分解的K個子分量經過希爾伯特解調后的包絡信號。
NGO-VMD算法的流圖如圖2所示。
2.2 基于K-means算法的數據重構
為了解決VMD分解出的模態分量個數過多,計算量繁冗的問題,通常需要對模態分量進行重構,已有文獻大多將熵值相似的分量分為一類完成重構,如使用樣本熵、排列熵[24]等。但使用熵值相似度進行各模態分量的重構的方法并為考慮到各模態分量數據本身的相似性,存在一定缺陷,因此本文研究中使用K-means算法完成對模態分量的重構。
K-means聚類算法基于數據之間的距離將相似特征的樣本自動歸到一個類別中,具有執行過程簡單、收斂速度快的優點,但其需要人工確定聚類個數,具有一定局限性,為了更加合理地從不同角度地確定K-means的聚類個數,使用輪廓系數法與Davies-Boundin(DB)值對各聚類個數進行得分評價。
輪廓系數s越接近1表示該聚類效果越好,其計算公式為
(18)
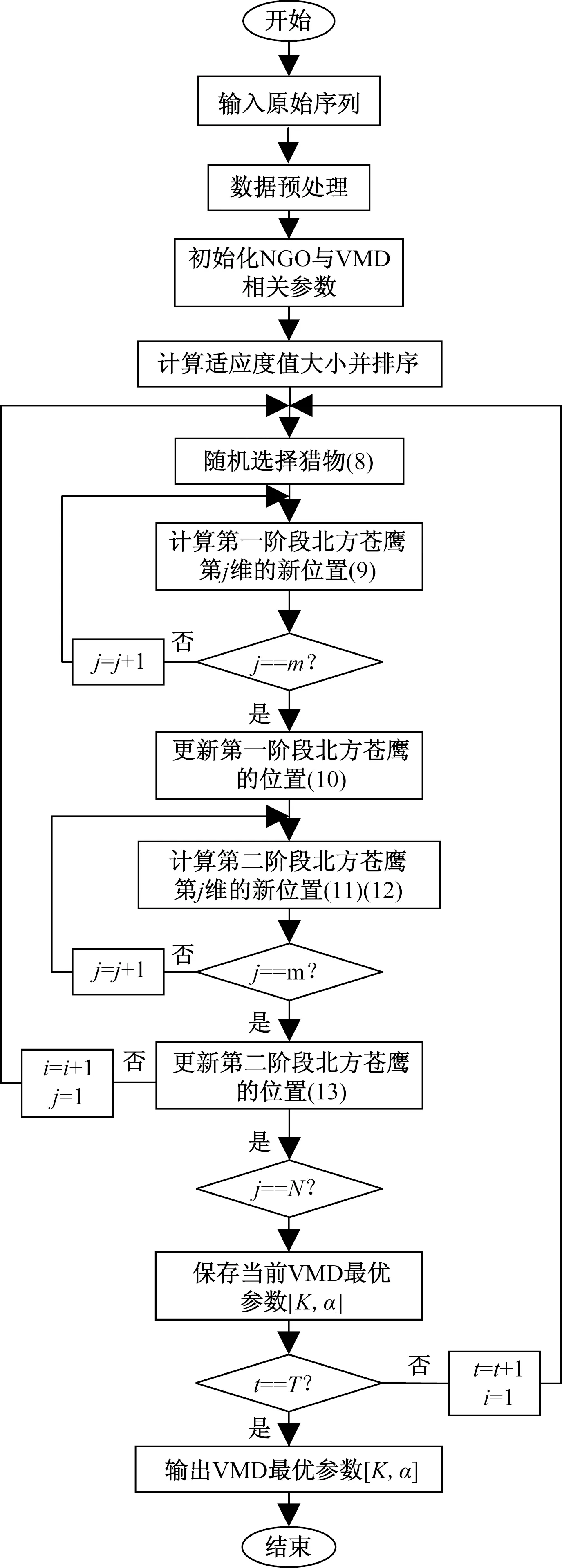
圖2 NGO-VMD算法流程Fig.2 Flow of NGO-VMD algorithm
式(18)中:disMeanout為該點與樣本中非本類點的平均距離;disMeanin為該點與樣本中本類點的平均距離。
DB值越小表示該分類效果越好。其計算公式為
(19)
式(19)中:K為分類數目;Si與Sj分別為樣本i和樣本j的類內平均距離;Mij為i類與j類中心的距離。
2.3 風電功率預測模型構建
為了解決在風電功率預測領域VMD人工設置難度大、分解效果差、分解模態分量個數多,計算量繁冗,以及未深度挖掘VMD殘差項所包含的豐富信息導致超短期風功率預測精度受限的問題,提出了一種基于NGO-VMD二次分解其殘差項、K-means重構與長短期記憶網絡相結合的組合預測模型以提升超短期風電功率預測精度。具體流程如圖3所示。
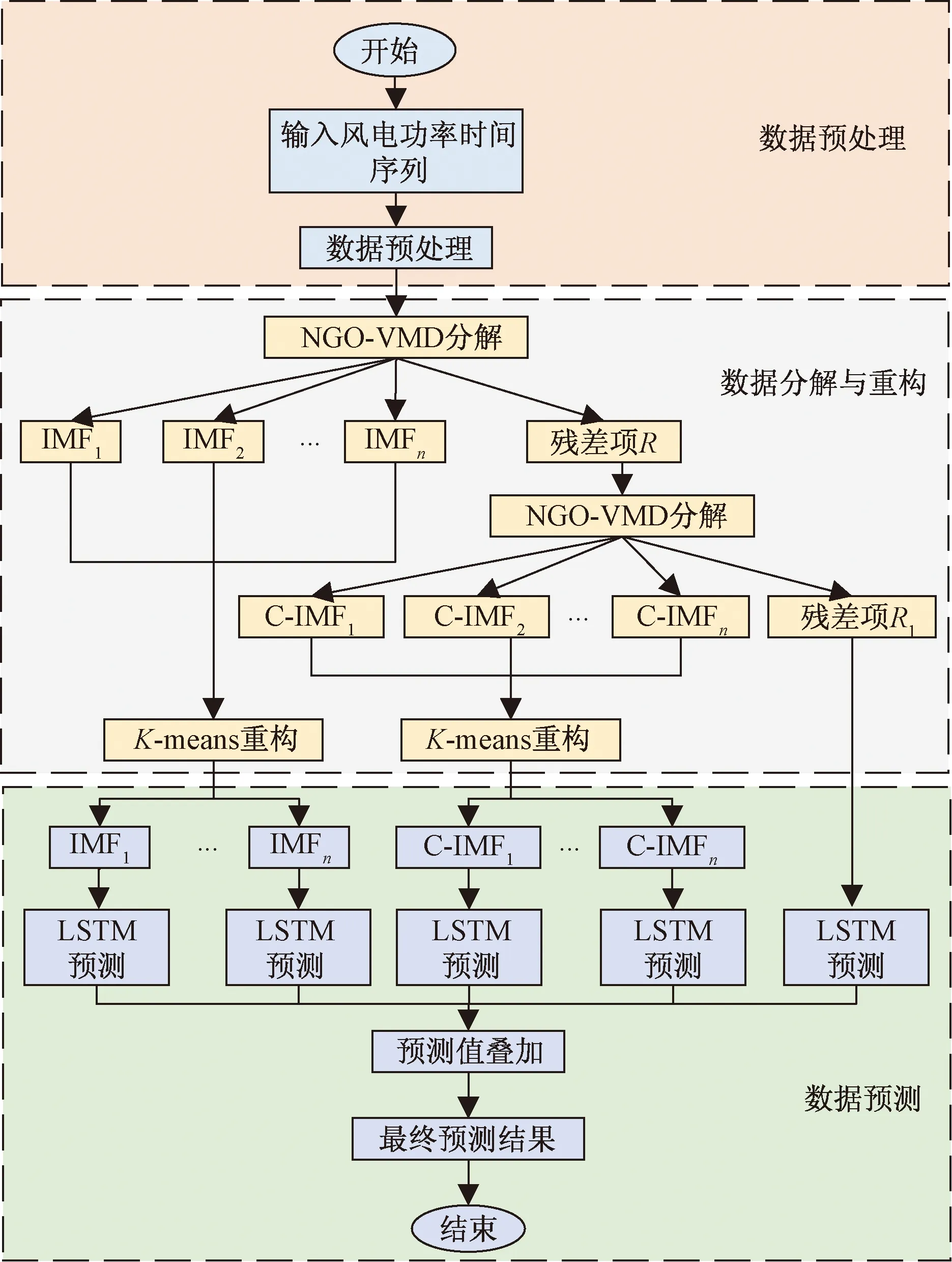
圖3 組合預測模型流程Fig.3 Combined predictive model process
2.4 預測模型結果評價指標
為進一步驗證模型預測性能及其有效性,選用均方根誤差(RMSE)、平均絕對百分誤差(MAPE)、平均絕對誤差(MAE)、決定系數(R)對模型預測結果進行對比評估,其運算公式為
(20)
(21)
(22)
(23)
3 算例分析
通過對新疆某風電場的2019年實測風電功率數據的預測分析和比較來驗證該組合模型的有效性和優越性。研究對象為6月1日—7月1日的實際風電功率數據,同時采樣了風速、風向、溫度、氣壓、濕度等數據,采樣的間隔為15 min,即每日采樣96個采樣點。將6月1—30日的2 880個數據集作為模型的訓練集,將7月1日的96個數據集作為測試集。
3.1 NGO-VMD分解
采用2.1節方法對VMD的分解層數K和懲罰因子α進行尋優。設置北方蒼鷹種群數為20、最大迭代次數為30;設置分解層數K的尋優范圍為[3,15],懲罰因子α的尋優范圍為[100,3 000]。VMD其他參數均取默認值。經過北方蒼鷹優化算法尋優的VMD最優參數組合[K,α]為[8,2 700]。NGO-VMD分解如圖4所示,最后一個分量為殘差項R,其大小為原始風電數據減去NGO-VMD分解的8個分量。
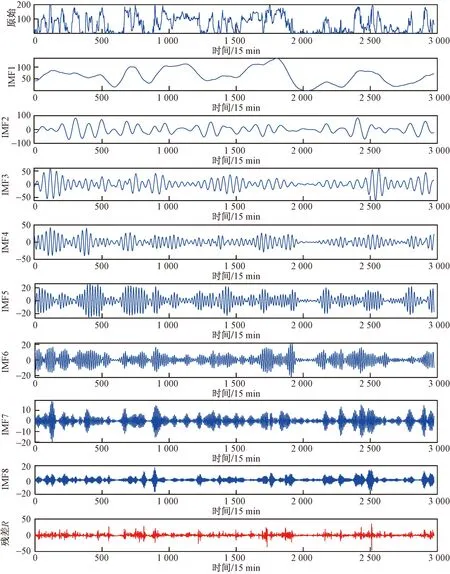
圖4 NGO-VMD分解結果Fig.4 NGO-VMD decomposition results
將NGO-VMD分解的殘差項R進行二次VMD分解,使用北方蒼鷹優化算法對殘差項R二次VMD分解的參數再次進行尋優,得到其最優參數組合[K1,α1]為[6,2 300]。NGO-VMD二次分解R如圖5所示,最后一個分量為殘差項R1,其大小為殘差項R減去NGO-VMD二次分解的6個分量。
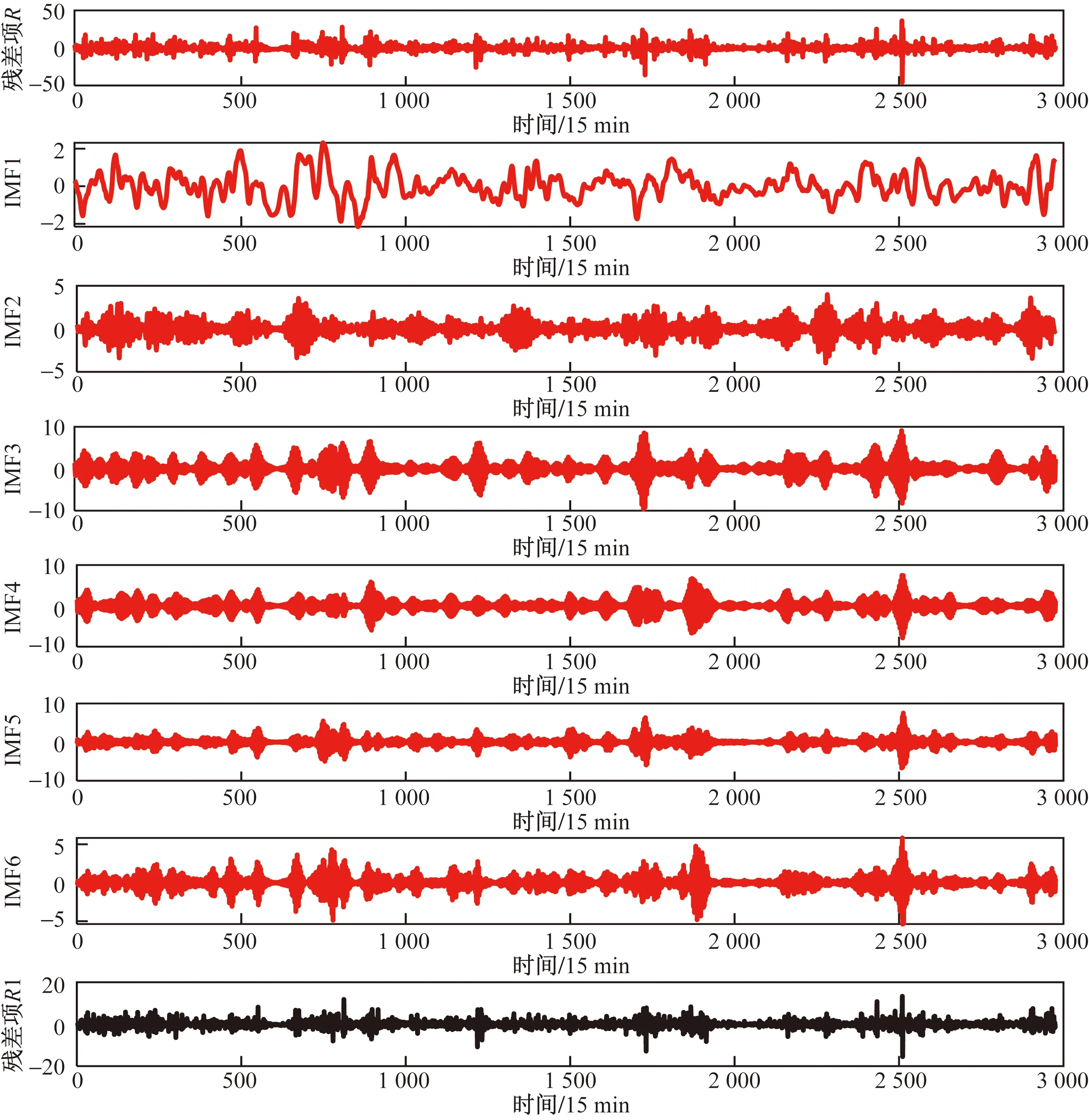
圖5 NGO-VMD二次分解結果Fig.5 NGO-VMD quadratic decomposition results
3.2 K-means數據重構
使用輪廓系數法與Davies-Boundin(DB)值將原始風電數據NGO-VMD分解后的8個分量以及殘差項R二次分解后的6個分量進行聚類數目得分評價,以確定各分量最佳重構個數。輪廓系數越接近1表示該聚類數目效果越好。DB值越小表示該聚類數目效果越好。
對首次原始風電數據NGO-VMD分解的8個分量進行K-means聚類,其聚類數目設置范圍為[2,7]。由圖6可知其IMF最佳聚類數目K為4,此時輪廓系數值最接近1,為0.935 9;DB值最小,為0.160 5。
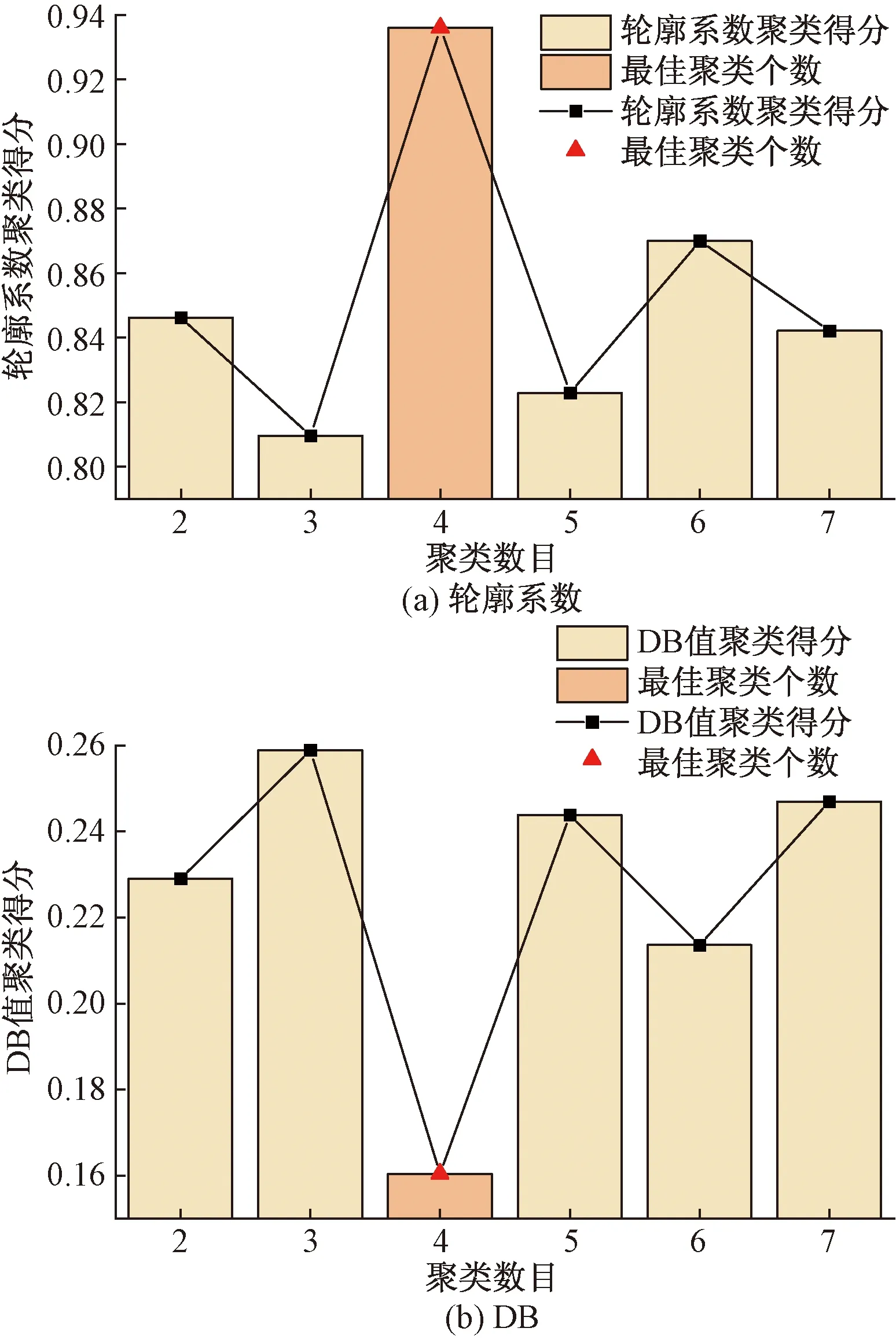
圖6 首次NGO-VMD分解聚類個數Fig.6 Number of first NGO-VMD decomposition clusters
對殘差項R二次NGO-VMD分解的6個分量進行K-means聚類,其聚類數目設置范圍為[2,5]。由圖7可知其IMF最佳聚類數目K為3,此時輪廓系數值最接近1,為0.715 6;DB值最小,為0.423 8。
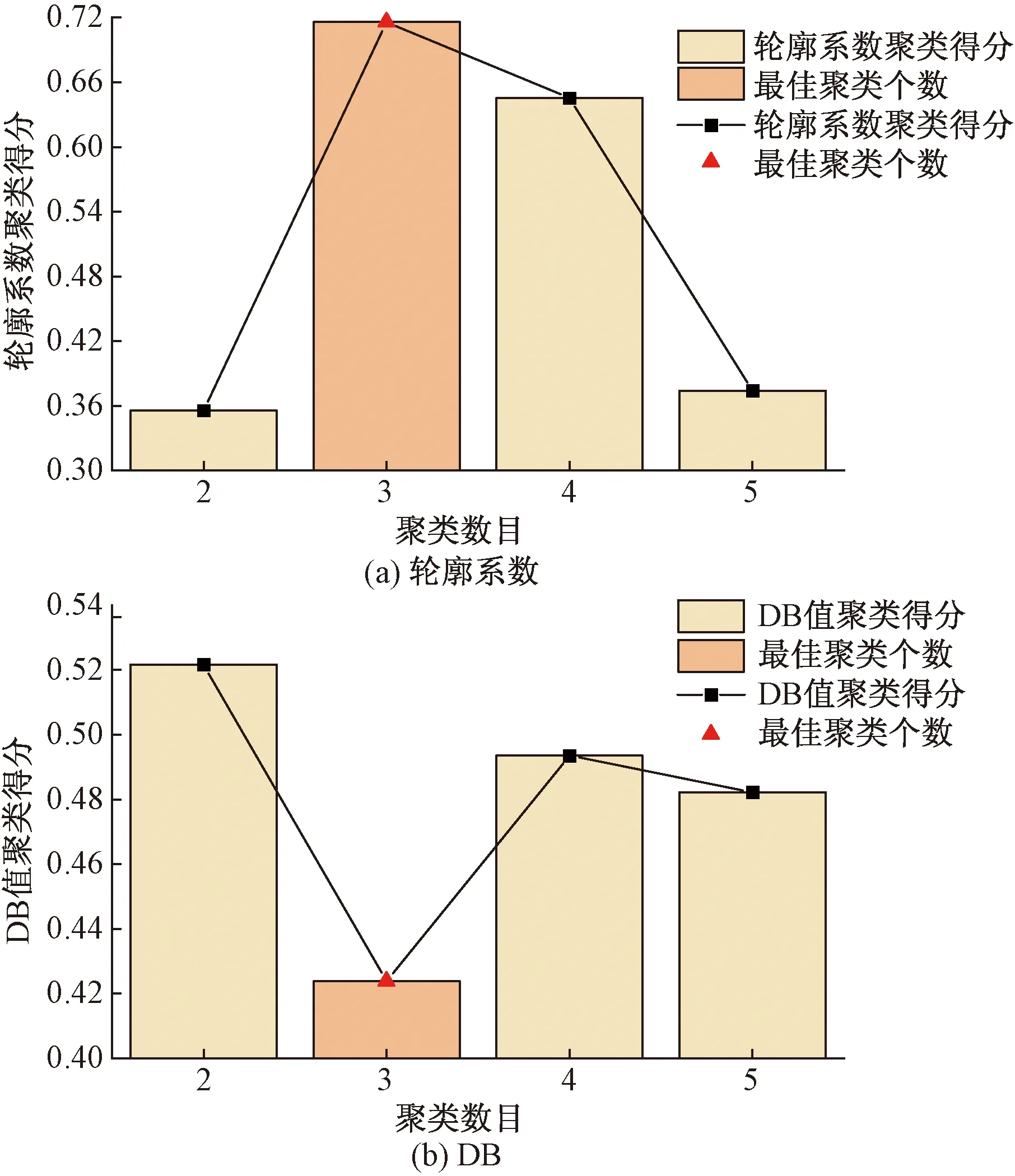
圖7 二次NGO-VMD分解聚類個數Fig.7 Number of quadratic NGO-VMD decomposition clusters
3.3 風電功率模型預測結果
LSTM輸入變量維數為6,包括風電功率、風速、風向、溫度、氣壓、濕度;輸出變量維數為1,為風電功率。將LSTM的迭代次數設為100次,初始學習率為0.005。由于Adam算法能計算不同參數下的學習率且運算速度快、內存小,因此本文研究中LSTM求解器選擇為Adam。隨著LSTM隱藏層數的增加,雖然預測模型的擬合能力會進一步得到改善,但如果不加限制,會出現模型預測時間過長、過擬合等問題,因此本文設置LSTM隱藏層數為兩層,層數分別為100、50,為了避免出現過擬合現象,給LSTM每一層加入元素失活概率為20%的隨機失活(Dropout)層。
將NGO-VMD二次分解R-Kmeans-LSTM模型各部分的參數確定好后,用該模型預測首次及二次分解后重構后的各子模態分量,并疊加各子模態分量的預測結果作為超短期風功率預測的最終結果。為了驗證本文模型的有效性,構建LSTM、未經二次分解的NGO-VMD-LSTM、子模態未重構的NGO-VMD二次分解R-LSTM 等模型與本文方法做對比,試驗結果如圖8及表3所示。

表3 不同方法誤差比較Table 3 Error comparison between different methods
從上述試驗結果可知本文方法可有效提升超短期風電功率預測的準確度。為了進一步證明本文方法性能,選取其他文獻方法搭建組合預測模型進行對比,試驗結果如表4所示。
4 結論
為改善超短期風電功率預測精度,提出了NGO-VMD二次分解R-Kmeans-LSTM的組合預測模型。經過多次試驗算例分析,得出以下結論。

表4 其他文獻不同方法誤差比較Table 4 Other literature different methods error comparison
(1)針對已有風功率組合預測模型中大多均直接忽略了風功率經VMD分解后殘差項所包含的豐富信息的缺陷,通過二次分解組合預測方法,深度挖掘了VMD殘差項所包含的有效信息,提高了超短期風電功率預測精度。
(2)首次將北方蒼鷹優化算法用于對VMD的分解層數K和懲罰因子α尋優,得到NGO-VMD比EEMD等分解方法有更好的分解效果。
(3)考慮了VMD分解后各子模態分量數據本身的相似性,采用K-means算法進行聚類重構,解決了VMD分解模態分量個數多,計算量繁冗的問題,有效提升了超短期風電功率預測時長和精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
廣西科技大學學報(2016年1期)2016-06-22 13:10:37
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
核科學與工程(2015年4期)2015-09-26 11:59:03
航空學報(2015年4期)2015-05-07 06:43:35
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
