基于組合模型的高原環境GDI汽油車排放預測
2023-04-25 14:32:50王瓏迪何超李加強劉學淵王浩
車用發動機 2023年2期
關鍵詞:模型
王瓏迪,何超,李加強,劉學淵,王浩
(1.西南林業大學機械與交通學院,云南 昆明 650000;2.云南省高校高原山區機動車環保與安全重點實驗室,云南 昆明 650224)
缸內直噴(GDI)汽油機具有良好的動力性、瞬態響應能力、燃油經濟性等優點,采用GDI技術的車型在市場上的占有率也越來越高。但有研究表明,與進氣道噴射(Port Fuel Injection, PFI)輕型汽油車相比,缸內直噴汽車的部分污染物排放量增加[1]。準確預測GDI汽油車在實際道路的污染物排放,有利于減少重復RDE試驗帶來的時間投入和經濟投入,并為GDI汽油車排放提供基礎數據支撐,為制定污染控制策略提供依據。
近年來,國內外學者將機器學習應用到排放預測領域。王志紅等[2]對一輛重型柴油車進行了道路污染物排放特性測試,利用測得的數據,在雙隱含層反向傳播神經網絡的基礎上引入GA遺傳算法優化網絡的權值和閾值,構建CO和NOx的排放預測模型,在整體誤差水平上,CO和NOx排放因子的相對誤差分別為2.61%和6.71%。Cha等[3]建立了基于最小二乘回歸法的多元回歸模型對輕型柴油車CO2排放量進行預測,并引入移動平均法對采集的數據進行濾波處理,消除預測變量的不確定性。結果表明,基于回歸方程的CO2預測值與CO2的實際值高度相關,模型預測精度較高。Claudio Maino等[4]提出了一種基于深度神經網絡的動態規劃算法的混合動力車CO2排放預測模型,開發了一種自動搜索工具(AST)對神經網絡中的參數進行尋優,捕捉混合動力汽車結構設計參數和CO2排放之間的相關性,仿真試驗結果表明,該模型的平均回歸誤差低于1%。
國內外對于排放預測模型的研究主要集中于平原地區,相較而言高原地區排放預測模型的研究較少。我國高原分布廣闊,海拔1 000 m以上的高原面積約占中國總面積的58%,2 000 m以上的高原占33%[5-6]。機動車在高原地區行駛時,由于海拔的升高,大氣壓力降低,吸入缸內的進氣量減少,將導致發動機動力性和經濟性下降、部分污染物排放增加[7]。由于單一模型并不能很好地擬合不平穩的時間序列數據[8],基于此,本研究提出了基于XGBoost-SVR組合模型的高原環境GDI汽油車CO和PN排放預測模型,實現對高原環境下GDI汽油車CO和PN的精準預測。
1 方法論
1.1 奇異譜分析
奇異譜分析(SSA)是一種處理非線性時間序列的方法[9],而汽油機污染物排放序列受到道路坡度、道路等級、駕駛員習慣等多種因素影響,是一種非平穩、非線性的時間序列,利用奇異譜分析對數據進行分解、重構,可以提取有效趨勢信息,去除時間序列中的噪聲部分。SSA的分析對象是有限長一維時間序列,以CO排放序列為例,定義CO排放序列數據為{x1,x2,…xN},然后計算軌跡矩陣X:
(1)
式中:K=N-L+1。通常情況下,滑動窗口長度L
(2)

(3)
1.2 XGBoost模型
XGBoost模型的基本單元為回歸樹[10],表達式為
(4)

XGBoost模型在每次迭代中加入新的函數,分別對應一顆回歸樹,新生成的回歸樹與之前所有樹預測的誤差進行擬合,迭代公式為
(5)
式中:t表示迭代次數。
XGBoost目標函數的表達式如下:
(6)
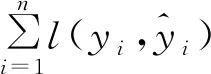
(7)
式中:ωj為第j個葉子節點的權重;T為葉子結點個數;λ為正則化懲罰項系數,保證葉子結點權重不會太大;γ為懲罰函數系數,防止葉子結點個數過多。
XGBoost對目標函數進行泰勒二階展開,得到的目標函數表達式為
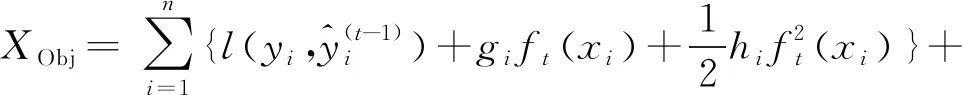
(8)
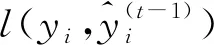
(9)
進一步對ωj求導得葉子的最優權重:
(10)
最優目標函數為
(11)
式中:Ij表示葉子結點的樣本集合。
1.3 SVR模型
支持向量機回歸(Support Vector Regression,SVR)是一種用于分類和回歸的監督學習算法,通過非線性映射函數φ(t),將低維空間的樣本映射到高維空間,從而進行非線性數據的擬合[11]。假定樣本集為{xi,yi},其中xi是輸入向量,yi是輸出向量。SVR模型的決策函數表示為
f(x)=ωTφ(x)+b。
(12)
式中:ω為權重系數;φ(x)為將輸入向量x從輸入空間映射到更高維空間的非線性映射函數;b為偏置量。SVR模型的訓練過程可以看作尋找最優的ω,b,使f(xi)無限接近yi,即
(13)
f(xi)-yi≤ε+ξi,
(14)
(15)
(16)
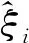
(17)
式中:k(x,xi)為核函數。
2 XGBoost-SVR模型
基于XGBoost和SVR提出了一種組合模型對高原環境下GDI汽油車CO和PN的瞬時排放進行預測,具體流程如圖1所示。

圖1 組合模型流程
組合模型的預測首先使用SSA對CO和PN的原始數據進行降噪處理,利用訓練集數據進行XGBoost建模,利用XGBoost模型獲得初始的預測值,計算真實值與初始預測值的殘差,利用SVR模型進行殘差修正,最后將SVR模型預測的殘差結果與XGBoost模型的初始預測值相加得到最終的預測結果,具體過程如下:
1) SSA降噪。高原環境下GDI汽油機的CO和PN的排放序列受到多種因素的影響,是一種非平穩、非線性的時間序列數據,SSA可以將數據進行分解重構,丟棄數據內的噪聲部分,保留數據的有效趨勢信息。

(18)
4) 將XGBoost模型的預測結果與SVR模型獲得的殘差預測值相加,得到最終的預測值,即
(19)
本研究采用均方根誤差RMSE[12]、決定系數R2[13]評估模型性能。計算公式如下:
(20)
(21)
3 試驗結果與分析
3.1 RDE試驗與數據
試驗采用便攜式車載排放測試系統(Portable Emission Measurement System,PEMS)對一臺國Ⅴ輕型汽油車進行測試,被測車輛采用缸內直噴的供油方式。將PEMS安裝到測試車輛上,接通電源,預熱完畢后對氣體分析儀進行標零標定。國六標準的進一步擴展海拔條件為1 300~2 400 m。此外,國六標準規定,PEMS檢測道路中試驗開始點和結束點之間海拔差不得超過100 m,并且累計正海拔增加量不超過1 200 m/100 km。因此,選定如圖2所示的試驗路線。試驗路線包括市區、市郊和高速路段,具體道路信息見表1。PEMS設備在發動機第一次起動前開始記錄數據,在試驗期間不間斷地記錄污染物濃度和環境條件。按照規定的試驗工況駕駛車輛,達到要求后停止試驗。RDE試驗持續102 min,將試驗采集到的數據按照3∶1∶1的比例劃分訓練集、驗證集和測試集。
3.2 SSA降噪
對測得的輕型汽油車的PN和CO排放數據進行SSA分解,窗口長度L設置為10。從圖3可以看出,對于CO和PN,前五個成分明顯大于其他部分,可以代表原序列的大部分信息,提取前五個主成分重構CO和PN序列,其余部分是可以去除的噪聲部分。

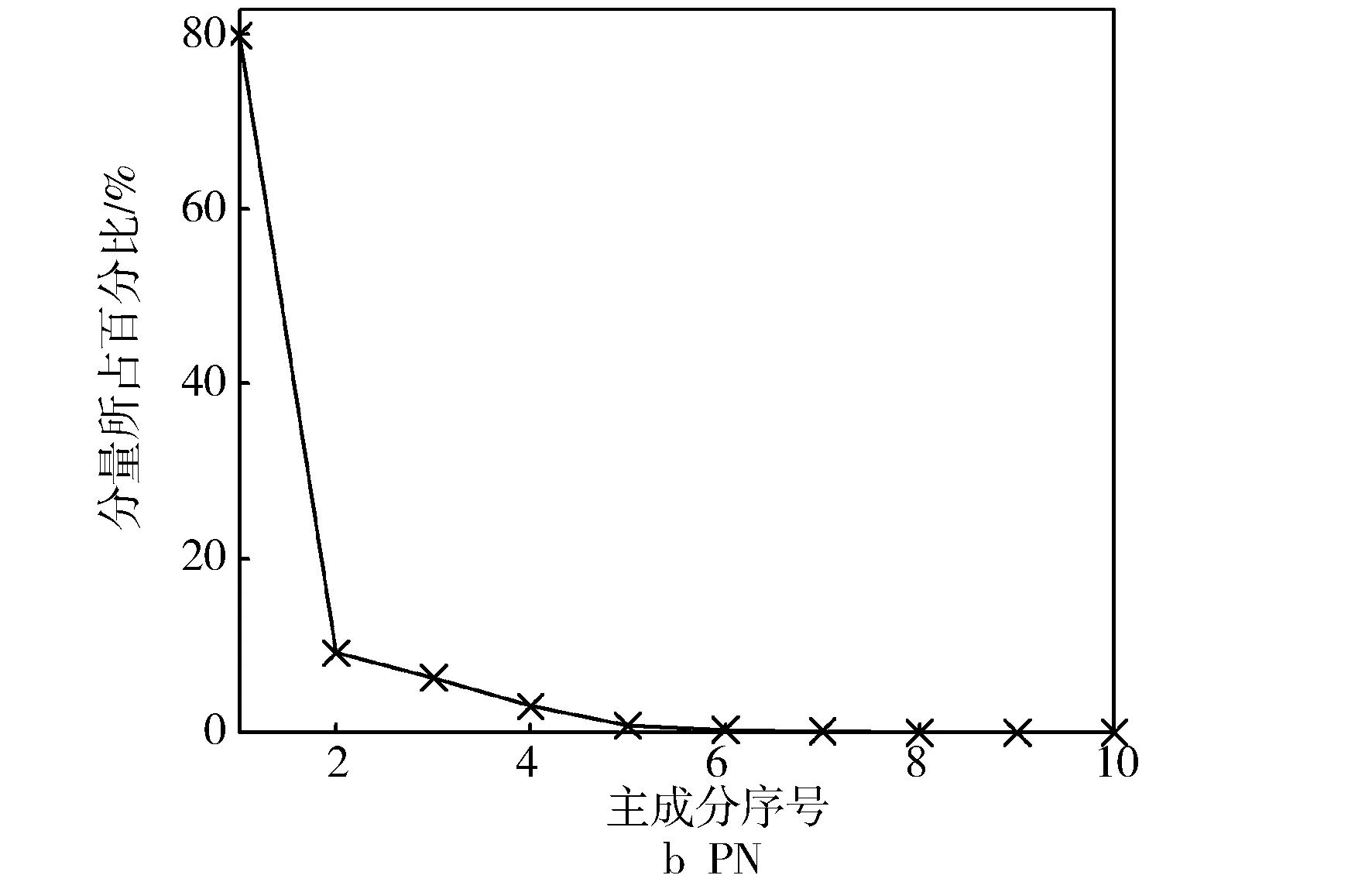
圖3 CO和PN的組件特征
圖4示出SSA處理后的CO和PN部分排放序列結果。從圖4可以看出,重構后的序列保留了原序列的總體變化情況,并且剔除了異常值,重構后的數據更有利于GDI汽油車CO和PN的瞬態排放預測。


圖4 SSA處理前后部分污染物排放序列比較
3.3 XGBoost建模
基于XGBoost模型對重構后的CO和PN排放序列進行初步預測,利用網格搜索結合4折交叉驗證尋找模型最優超參數,主要調節參數及范圍見表2。最終選定XGBoost模型學習率為0.006,決策樹數量為1 000,樹的最大深度為3。使用XGBoost模型的預測結果如圖5所示。從圖5可以看出,XGBoost單一模型在整體的排放趨勢上與試驗值相一致,但在某些波峰、波谷處存在較大誤差,因此利用SVR模型進行殘差修正。

表2 XGBoost超參數含義及其取值范圍

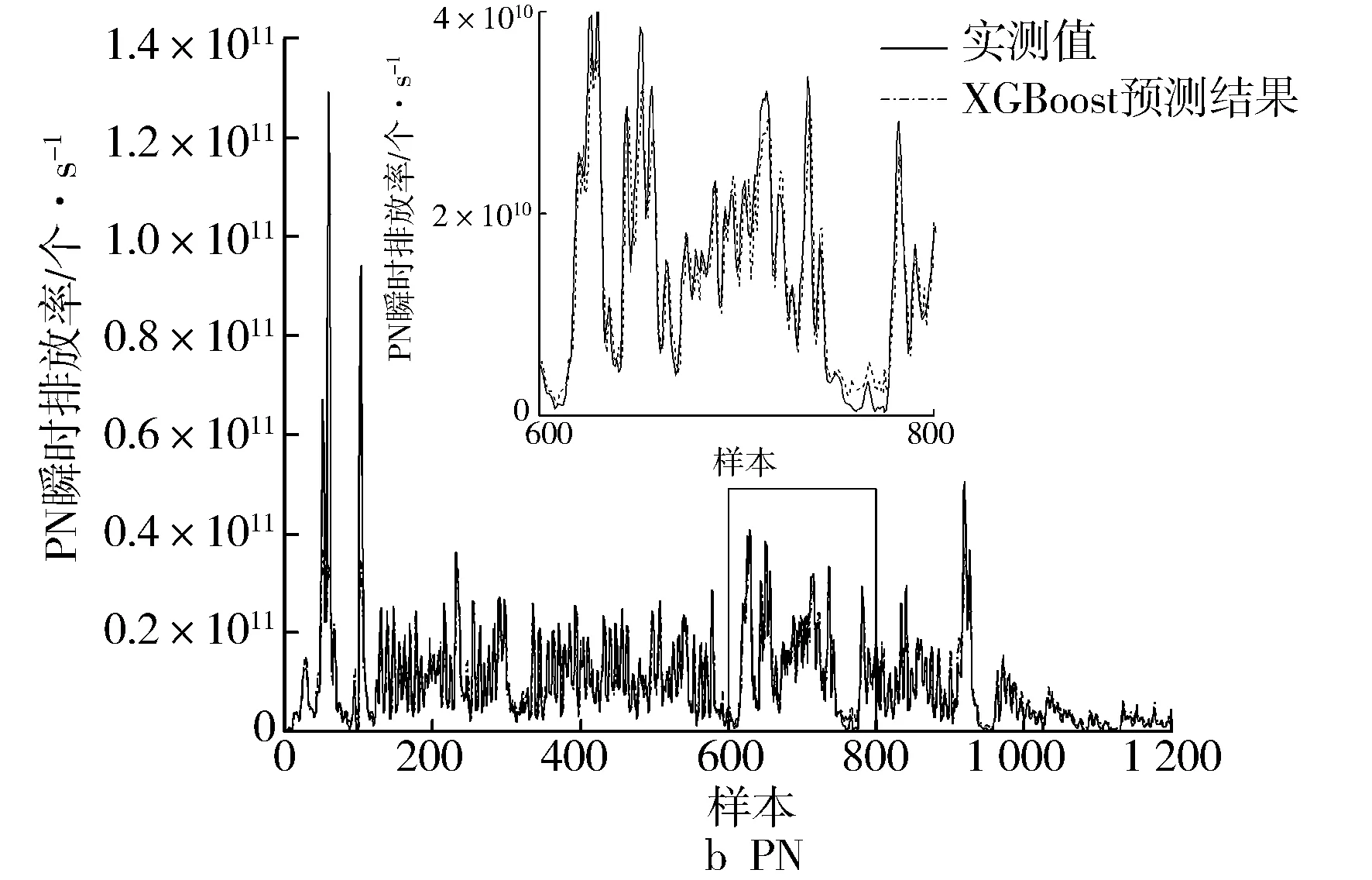
圖5 XGBoost模型預測結果
3.4 SVR建模
本研究SVR模型中的核函數選擇徑向基函數(RBF),核函數的表達式如下:
(22)
將原始數據與XGBoost模型預測數據作差,得到殘差序列,將原始數據和殘差序列代入SVR模型,殘差的預測結果如圖6所示。


圖6 SVR殘差預測結果
將XGBoost預測結果與SVR預測結果相加得到最終的預測結果,如圖7所示。從圖7中可以看出,對于XGBoost單一模型,在某些波峰、波谷處CO和PN的瞬時排放預測結果與實測值誤差較大,這是由于在波峰、波谷附近,發動機工況在短時間內發生變化,預測模型響應時間受到限制,導致預測精度不足。而組合模型通過SVR殘差修正,預測結果能與實測值較好地吻合。相比于XGBoost單模型,組合模型的擬合精度得到提高。組合模型和XGBoost模型對CO和PN的瞬態排放預測的精度對比見表3。在高原環境GDI汽油車瞬態CO排放預測中,組合模型RMSE和R2的值相比于XGboost單一模型分別提高了22.9%和25.1%;在瞬態PN排放預測中,組合模型RMSE和R2的值相比于XGboost單一模型分別提高了39.7%和12.8%。從RMSE和R2的值可以看出,組合模型具有更高的預測精度。


圖7 組合模型預測結果
4 結束語
提出了一種基于XGBoost預測時間序列結合SVR殘差修正的高原環境下GDI汽油車排放預測模型,以一輛高原環境下的GDI汽油車作為研究對象進行實證研究。對原始排放數據進行SSA降噪,去除原始數據中異常值,經SSA降噪后建立的組合模型表現出良好的預測性能;對CO和PN排放預測的RMSE分別為0.037和0.047,且決定系數R2均大于0.9。利用XGBoost-SVR組合模型對高原環境下GDI汽油車瞬時排放中CO和PN進行預測,結果表明,組合模型相比于單一的XGBoost模型,RMSE分別提高了22.9%和39.7%,R2分別提高了25.1%和12.8%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
