基于機器學習的大學生家教適配系統的設計與實現
2023-04-27 04:05:42高晨昊何謙胡梓
電腦知識與技術
2023年8期
關鍵詞:機器學習
高晨昊 何謙 胡梓

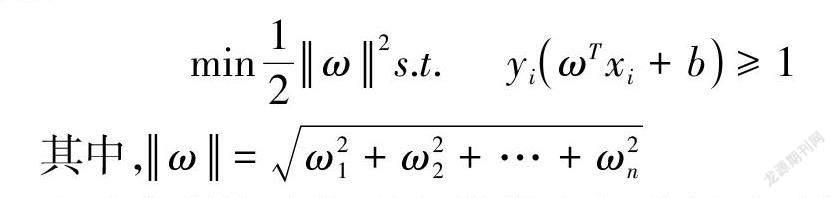


關鍵詞:大學生家教;機器學習;SVM支持向量機;家教系統;App
中圖分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2023)08-0005-04
0 背景概述
當下,“互聯網+教育”已經融入學生的方方面面,在“互聯網+”背景下,學生借助互聯網瀏覽教育信息,實現個性化教學目的。家教行業也借助這一背景,涌現出部分個性化教育平臺[1]。家教群體中有這么一個群體,占據家教市場近4成,和學生溝通強,物美價廉,這便是大學生家教。
有學者曾調研過遼寧省的大學生家教市場。調研指出,有85%的家長會選擇為孩子報名課后輔導班;所調查的近300家教育機構中,參與過家教兼職人員多達1萬人,目標學生群體約60萬人,學生平均年消費達2500 元[2]。據項目組成員調查,在一二線城市,約每10個學生中有8個學生上過課外補習班。因此,只要大學生有兼職意向,只要中小學生有補課需求,那么大學生家長市場將持續存在,并且會隨著人數、教育發展、教育需求提高而持續擴大,線上家教匹配系統的未來前景仍是一片光明。
但是,大學生家教市場也存在著諸多問題。最主要的是大學生家教市場信息閉塞,大學生尋找家教系統途徑單一[3]。
根據項目組成員考察調研,將目前市場上的家教平臺分成以下三類:
1) 綜合性兼職平臺分屬家教模塊(如58同城、BOSS直聘);
2) 專職線下家教平臺(如學而思,學大教育);
3) 較強地域性的家教小網站和小平臺(如知善師家教)。
三種模式各有利弊,本項目設計為第三類家教平臺。
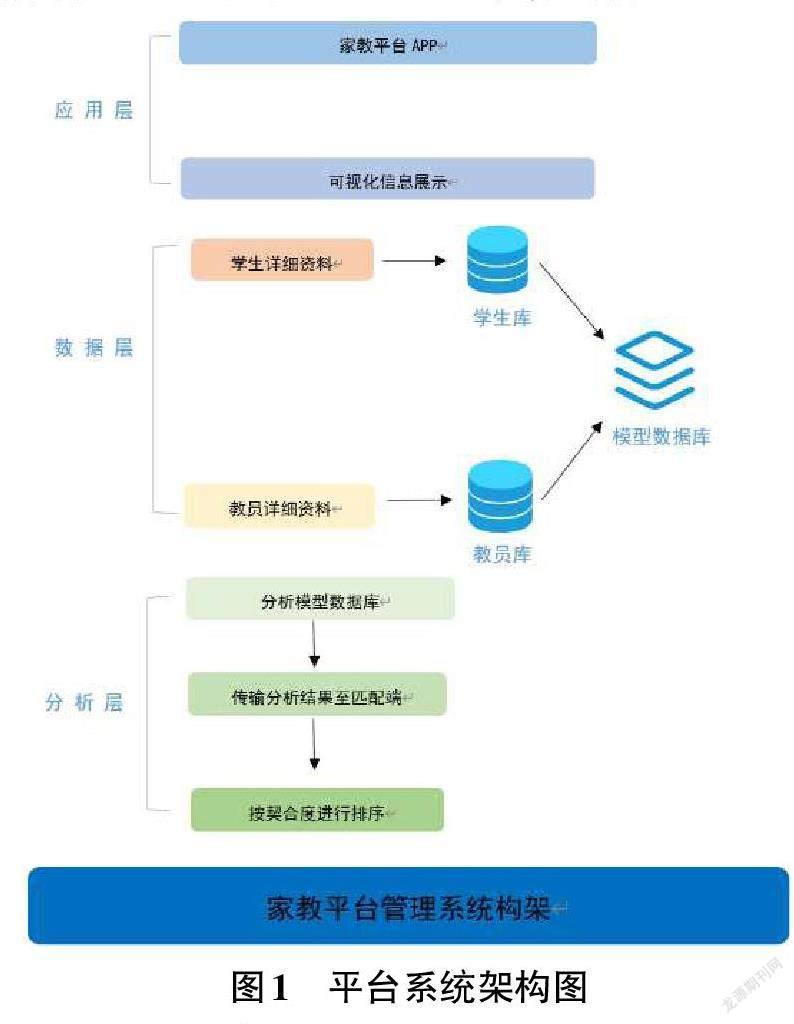
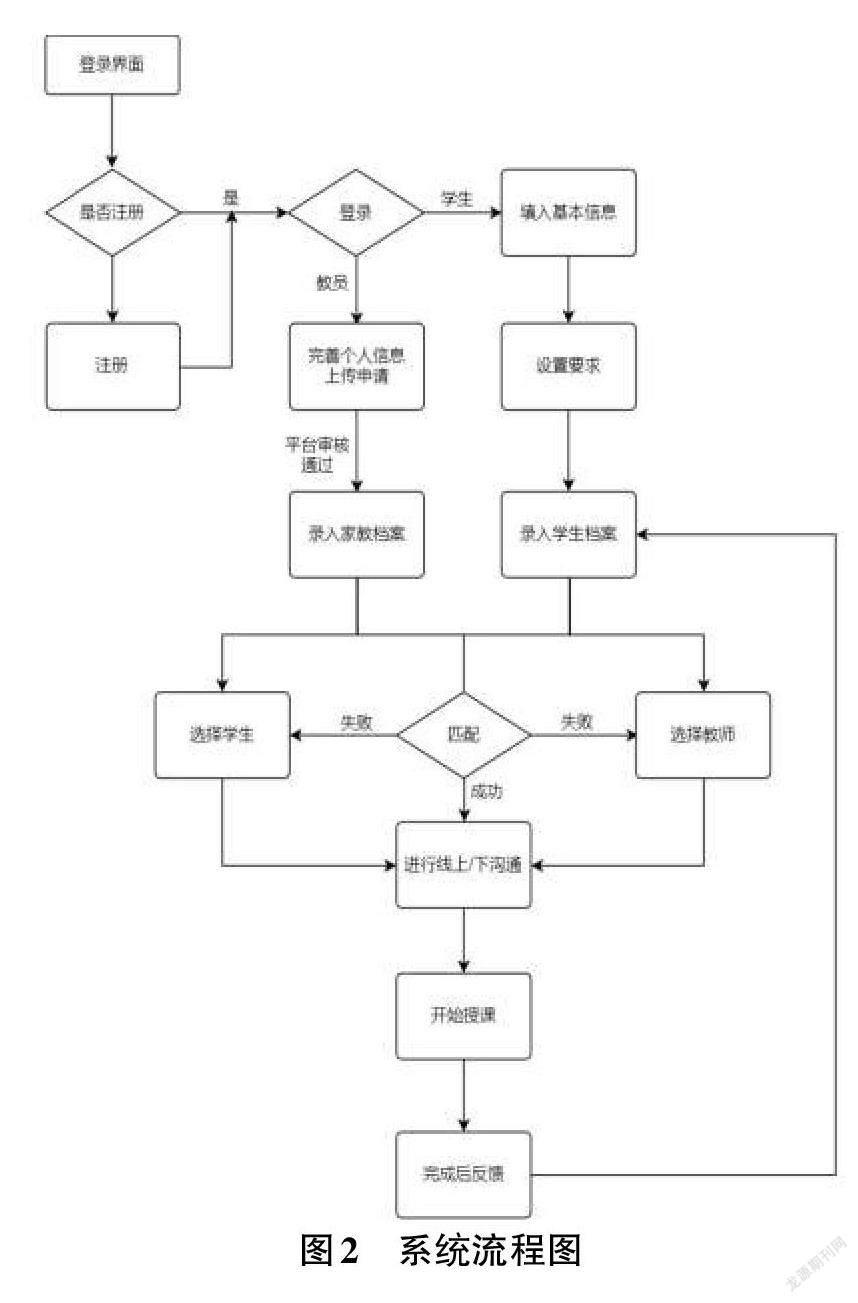
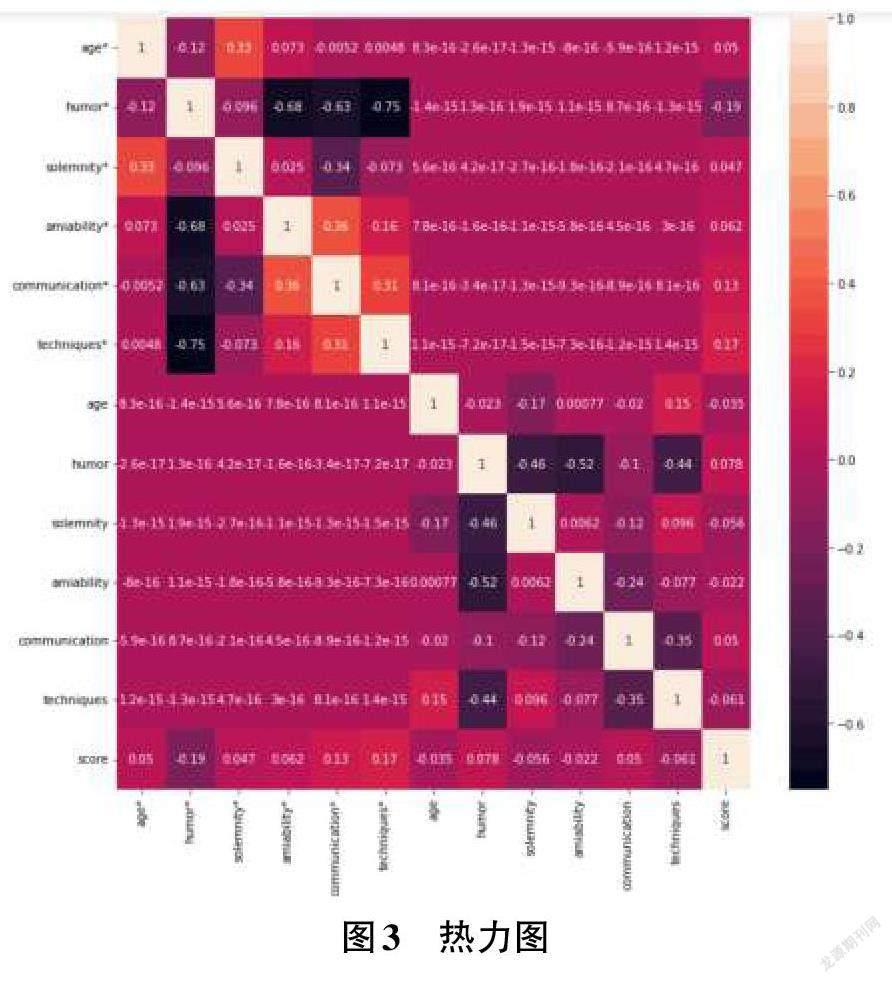
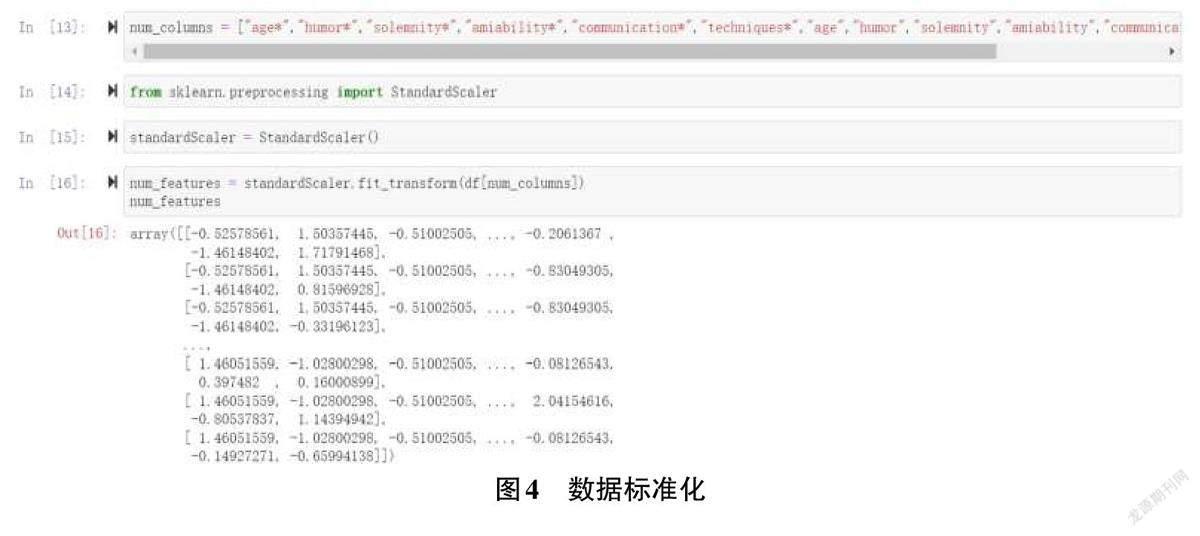
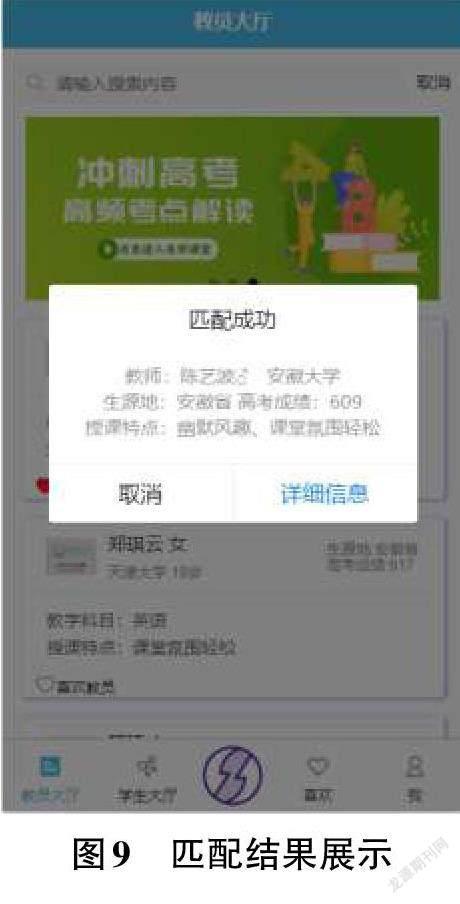
團隊利用機器學習算法庫中的SVM算法,將中小學生在本平臺的上課習慣、成績、學習能力以及家教需求等個人數據作為輸入,作為每個學生的學習模型,存儲在數據庫中,然后通過家教匹配系統,按需匹配最適合中小學生的大學生教員。……
登錄APP查看全文
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科學與財富(2016年28期)2016-10-14 21:19:17
