基于數理方法的語音重構研究
2023-04-29 10:16:12王咿卜李建文王術
商洛學院學報 2023年2期
王咿卜 李建文 王術

摘 要:為了維護聽障患者的身心健康,探究弱聽患者在不同頻率段存在的分貝值衰減的現象,從語音的發音原理出發,采用自相關函數法、倒譜法分別對語音信號進行基頻、共振峰提取。通過語譜圖探究基頻曲線與共振峰的相關性,采用曲線函數擬合法對基頻進行擬合,采用幀重疊相加法實現語音合成。進一步調整特征參數值實現語音重構,總結聽障患者在不同頻段的分貝值變化規律。結果表明,對于語音重構函數,在特定頻率段內改變分貝值能夠有針對性地提升聽障患者的聽力效果。
關鍵詞:聽障患者;基頻曲線;共振峰;幀重疊相加法;語音重構
中圖分類號:TN912.33? ? 文獻標識碼:A? ? ?文章編號:1674-0033(2023)02-0062-09
引用格式:王咿卜,李建文,王術.基于數理方法的語音重構研究[J].商洛學院學報,2023,37(2):62-70.
Abstract: In order to maintain the physical and mental health of hearing impaired patients, and explore the phenomenon of attenuation of decibel values in different frequency bands for patients with hearing impairment, starting from the pronunciation principle of speech, the autocorrelation function is used to extract the fundamental frequency of the speech signal, and the cepstrum is used to extract the formant of the speech signal. The correlation between the fundamental frequency curve and the formant is explored through the spectrogram. The fundamental frequency is fitted by the curve function fitting method, and the speech synthesis is realized by the frame overlap addition method. Further adjust the value of the feature parameters to realize speech reconstruction, and summarize the change rule of decibel value of hearing impaired patients in different frequency bands. The results show that for the reconstructed speech? ?function, changing the decibel value in a specific frequency range can purposefully improve the hearing effect of hearing -impaired patients.
Key words: the hearing impaired; the fundamental frequency curve; formant; the frame overlap addition method; speech reconstruction
聲音是人們實現信息交互的重要途徑之一。然而,據世界衛生組織發布的數據,目前全球有五分之一的人聽力受損,在我國則有2 000多萬人,聽力患者人口基數大。有調查顯示,長期的聽力障礙會對聽障患者身心的健康發展產生不良影響[1]。聽障患者進行助聽工作的主要途徑有兩種,一種是進行人工耳蝸手術,另一種是佩戴助聽器。傳統的人工耳蝸技術是用于重建聽覺的植入式電子裝置,普遍用于聽力差的患者。助聽器通過外部佩戴將接收到的聲音放大,使患者能夠聽到聲音[2]。韋芮[3]探討了人工耳蝸植入前后耳鳴與焦慮、抑郁的相關性,發現對于術前伴有耳鳴的人工耳蝸植入候選者,植入人工耳蝸對耳鳴具有積極作用,但隨著耳鳴嚴重程度增加,其焦慮及抑郁程度均增加。魏爽等[4]提出基于動態字典學習的欠定盲語音重構算法,利用正則化Sim CO字典學習對信號進行稀疏表示,依據最速下降思想得到信號恢復的總體最優解,提高了欠定盲語音的重構質量,該研究基于動態學習,依靠構建信號中最優的稀疏表示特征,但忽略了語音信號在現實情況下的復雜性,由于語音特征隨時間變化,因此各個語音時段的特征都對語音重構具有不可或缺性。郝雪瑩[5]提出一種語音增強算法來降低頻率響應,解決了聲源與附近物體之間的共振導致的頻率響應問題,提高了重建語音的準確性,該研究重構了語音的正弦信號,但未考慮到漢語語音關于聲調問題的影響,忽略了語音聲調對漢語表意的重要性。人工耳蝸手術復雜、成本高、需要定期維護,且植入后可能引發細菌性腦膜炎等其他疾病,因此僅適用于中重度患者[6-7]。對于輕度患者,適合佩戴新型或改進型助聽器,但對于聽力損失較輕的患者,由于助聽器的功率過大導致噪音偏大,會增加佩戴者的焦慮感,產生的聽力負荷還可能會加重聽力損失程度。本研究從語音的形成原理出發,旨在解決助聽器可能破壞殘余聽力結構的問題。首先,通過語譜圖分析聲音的特征參數——基音頻率和共振峰,探究語音參數之間的相關性。其次,通過算法將語音的特征參數進行提取,通過曲線函數擬合基頻曲線,進一步形成共振峰所在曲線。最后,基于幀重疊相加法進行語音重構,通過提取特征參數、調整分貝值大小,實現聽障患者的聽力提升,維護聽障患者身心健康。
1? 語音頻譜分析
1.1 語譜圖
已知由振動產生的聲音是由基音與泛音形成的復合音。基音由發音源振動產生,是頻率最低的正弦波,各次諧波的微小振動所產生的聲音稱泛音。復合音的振幅是基音與泛音振幅進行帶方向的疊加。復合音的振動頻率包含兩部分,一部分是基音的頻率,簡稱基頻,基頻大小決定了語音音調的高低;另一部分是泛音產生的諧波頻率,諧波頻譜和包絡決定了聲音的音色[8-10]。
語音信號在宏觀上是不平穩的,在微觀上(10~30 ms)可以認為語音信號近似不變,因此首先采用時域分幀法對語音x(t)進行離散化處理,得到的語音信號為x(n)[11],分幀公式為:
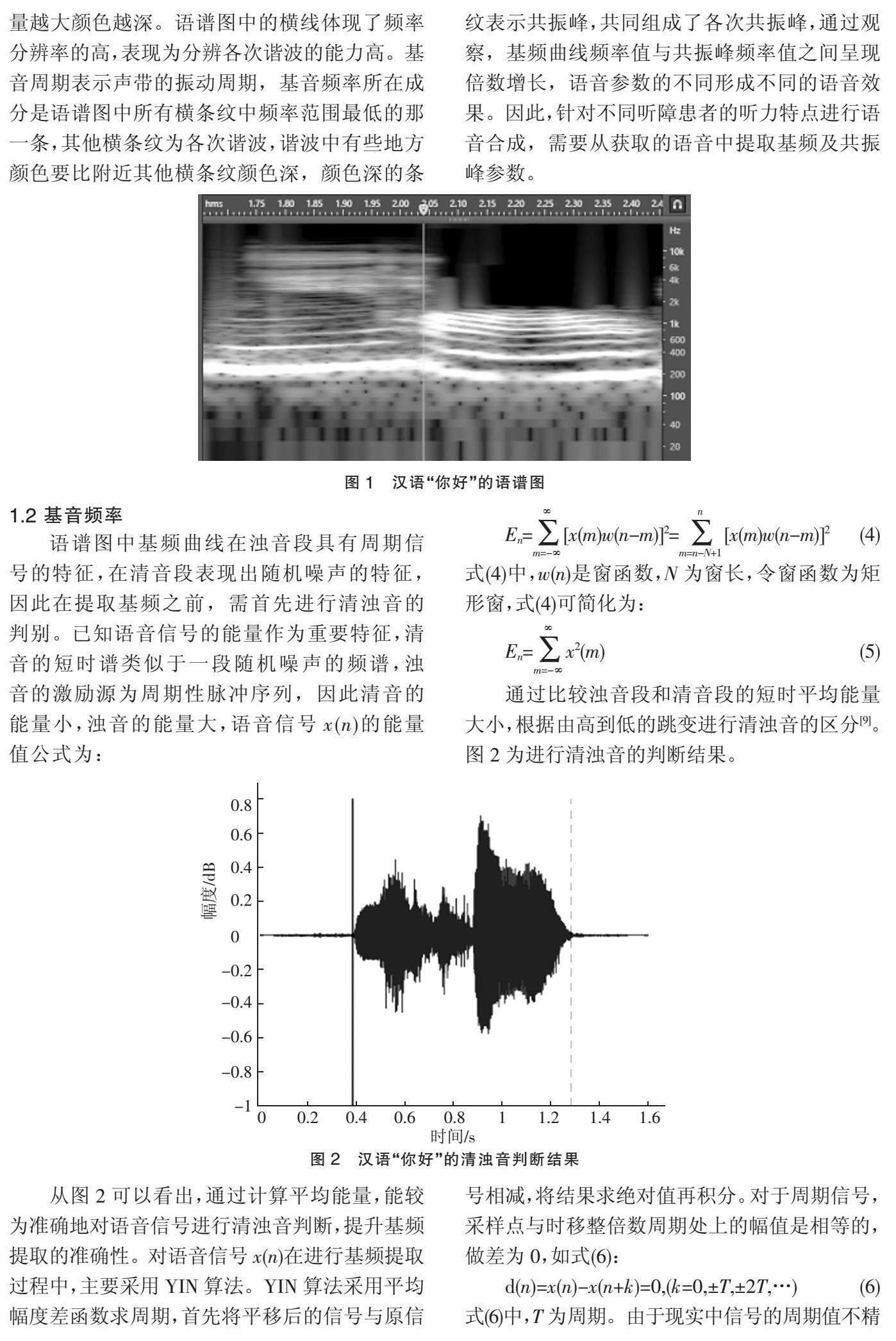
通過傅里葉變化得到的頻譜函數為Xi(K),使得語音波形可以分解為不同頻率正弦波的組合,如圖1為漢語“你好”的語譜圖。
在圖1語譜圖上的數據作為語音信號的特征,其中,橫坐標為語音時長(單位:s),縱坐標為頻率(單位:Hz),坐標點值為語音數據能量,能量越大顏色越深。語譜圖中的橫線體現了頻率分辨率的高,表現為分辨各次諧波的能力高。基音周期表示聲帶的振動周期,基音頻率所在成分是語譜圖中所有橫條紋中頻率范圍最低的那一條,其他橫條紋為各次諧波,諧波中有些地方顏色要比附近其他橫條紋顏色深,顏色深的條紋表示共振峰,共同組成了各次共振峰,通過觀察,基頻曲線頻率值與共振峰頻率值之間呈現倍數增長,語音參數的不同形成不同的語音效果。因此,針對不同聽障患者的聽力特點進行語音合成,需要從獲取的語音中提取基頻及共振峰參數。
1.2 基音頻率
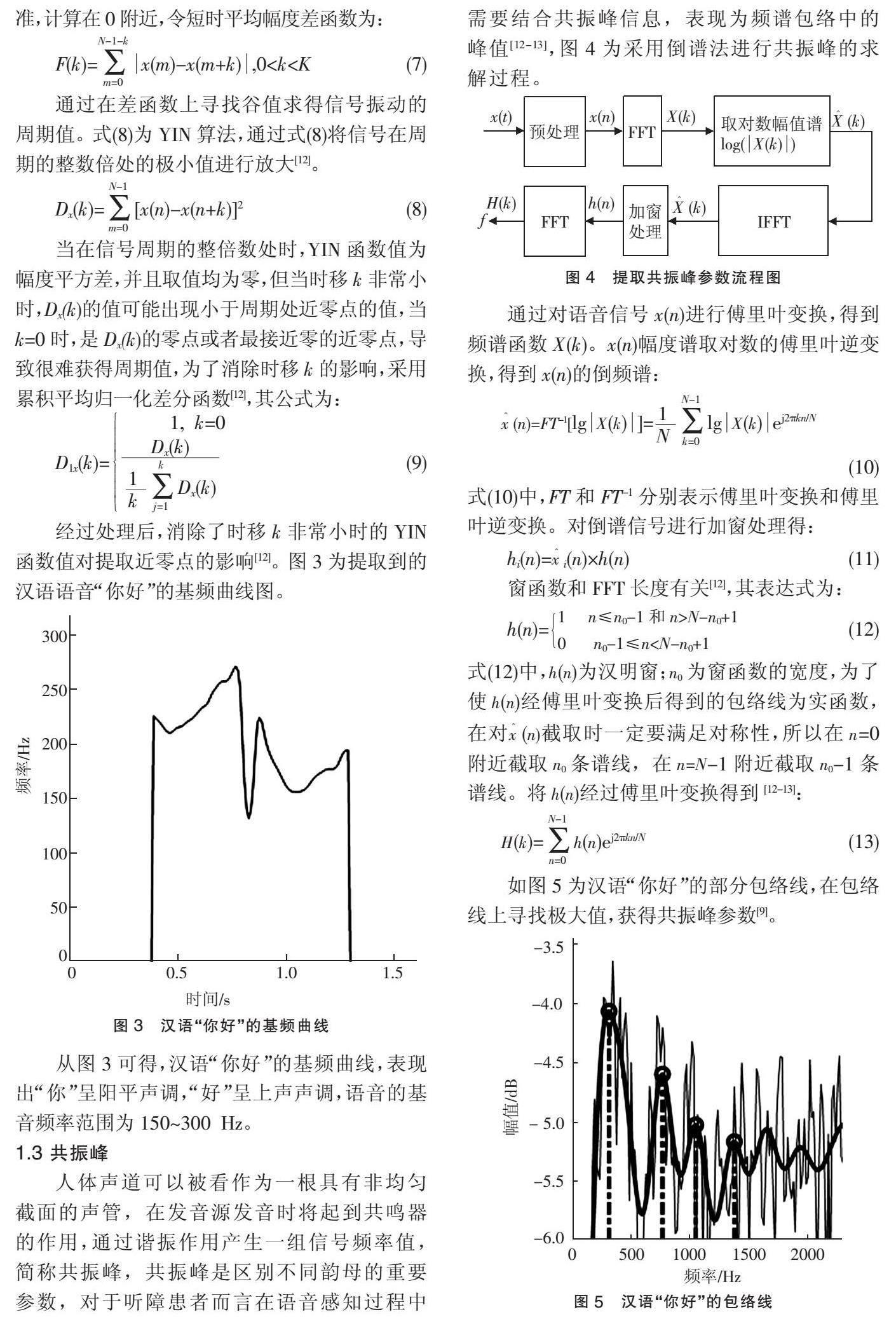
語譜圖中基頻曲線在濁音段具有周期信號的特征,在清音段表現出隨機噪聲的特征,因此在提取基頻之前,需首先進行清濁音的判別。已知語音信號的能量作為重要特征,清音的短時譜類似于一段隨機噪聲的頻譜,濁音的激勵源為周期性脈沖序列,因此清音的能量小,濁音的能量大,語音信號x(n)的能量值公式為:
經過處理后,消除了時移k非常小時的YIN函數值對提取近零點的影響[12]。圖3為提取到的漢語語音“你好”的基頻曲線圖。
從圖3可得,漢語“你好”的基頻曲線,表現出“你”呈陽平聲調,“好”呈上聲聲調,語音的基音頻率范圍為150~300 Hz。
1.3 共振峰
人體聲道可以被看作為一根具有非均勻截面的聲管,在發音源發音時將起到共鳴器的作用,通過諧振作用產生一組信號頻率值,簡稱共振峰,共振峰是區別不同韻母的重要參數,對于聽障患者而言在語音感知過程中需要結合共振峰信息,表現為頻譜包絡中的峰值[12-13],圖4為采用倒譜法進行共振峰的求解過程。
從圖5可得,在共振峰頻率提取過程中,對于漢語“你好”的包絡線,能較為清晰地對語音起重要作用的前四個共振峰頻率分別為312.50,765.62,
1 046.88,1 375 Hz,頻率關系呈倍數增長。
2? 語音重構
2.1 基頻曲線擬合
觀察語譜圖,對于同一語音的共振峰曲線與基頻曲線,所在頻率段不一樣,但曲線走勢相同。因此,首先對提取到的基頻曲線采用函數進行擬合,再通過平移基頻曲線得到共振峰曲線。在聽障患者的聽覺系統中,針對患者具體的聽力情況,對語譜圖上不同頻率段內的音頻曲線進行專門調整,提高特殊頻率段內曲線的分貝值,能夠保證患者在聽力不受損的情況下,有效地提高聽力效果。
一般來講,人通過聽覺能感知的聲音為20~20 000 Hz,范圍為0~130 dBHL。依據世界衛生組織指定的聽力障礙的分級標準,以較好耳500,1 000,2 000,4 000 Hz的平均純音聽閾為依據將聽力障礙分為四級:26~40 dBHL為輕度,41~60 dBHL為中度,61~80 dBHL為重度,>81 dBHL為極重度,而將兒童聽力殘疾定義為:較好耳500,1 000,2 000,4 000 Hz的4個頻率永久性非助聽聽閾級平均值≥31dB HL[6,16]。
非老年性弱聽及老年性耳聾聽力特點:非老年性弱聽指患者在特定頻率段內,出現分貝值衰減而導致的聽力效果下降。老年性耳聾一般從40歲開始出現,逐漸減退,主要是由于聽覺器官的衰老、退變而出現的,因此雙耳對聽力的感知幾乎是對稱的、緩慢進行的聽力減退,屬于生理范疇。
對于大部分聽障患者來說,只有通過助聽器進行語音的放大來實現語音的重構。語音中含有的能量,其中低頻率段為500 Hz以下,占據60%的能量;中頻率段為500~1 000 Hz,占據35%的能量;剩下的為高頻率段,占據極微少的能量。麥克風主要增強中頻段,而中頻段內又分為很多頻率,對于不同的音,發音頻段的分貝值的不同會產生不同的聽覺結果。
3.2 合成結果測試
對于語音合成函數,在20~20 000 Hz范圍內選擇性調整分貝值進而影響語音聽覺效果[9]。由于分貝值在3 dB變化,人耳剛好能夠感受到聲音大小的差異,為了保護人耳殘余的聽覺,令Ampm=3k,其中k為3 dB的倍數級,根據具體聽障患者的音域進行分貝值大小的調整公式為:
式(29)中m1≤m≤m2,m1=round(f1/f0),m2=round(f2/f0)。若聽障患者在200~400 Hz頻率段有聽力衰減,如圖8為再合成語音(分貝值增加)和原始語音語譜圖對比結果,如圖9、圖10分別為原始語音不同頻段的分貝值、再合成語音不同頻段的分貝值。
在圖8語譜圖中,原始語音由于受到外界及生理因素的影響,高亮條紋處存在大量模糊的陰影,在一定程度上影響了整體語音的清晰度,而再合成后的語音,不僅有效地保留了原始語音中的重要頻率段,保證了語音具有的諧振特性,還減少了外界因素的干擾,頻譜曲線的邊界輪廓更加清晰。試驗中,若聽障患者聽到聲音具有發飄、不堅實的現象,通過判斷在300~400 Hz頻段存在分貝值衰減,針對該現象,對合成的語音函數在相應頻段進行分貝值增強。圖9中,調整前的分貝值為-25.54 dB,在整段頻域范圍內,峰值周圍還存在其他諧振波的現象,在非關鍵頻率段內,諧振波的分貝值較高。圖10為對基頻曲線進行分貝值調整后的結果,圖中基頻曲線調整之后分貝值變為-22.62 dB,據測試,經過調整后能使患者具有更好的聽覺效果,針對性的分貝值增強同時也保護了患者的殘余聽力。
試驗選取30名聽障患者為研究對象,被試者均為聽力模糊患者,且利用助聽器進行聽力重建水平皆為較適水平以上(語音最大識別率在65%以上),排除因智力因素對本研究的影響。針對聽障患者的聽力特點,對不同語音在不同頻段調整分貝值進行語音再合成,通過表2可以觀察到不同頻段內分貝值對人的聽覺感受的影響,進一步為助聽器的后續升級提供參考。
通過函數擬合原始語音進行針對性的語音再合成,對試驗測試人員進行收聽效果對比,如表3為不同音頻補償范圍內增加分貝值得到的再合成語音,較原始語音、合成語音關于平均識別率的對比情況,再合成語音相比于普通助聽器關于聽損程度的變化情況。由表3可得,在不同音頻補償范圍內對于20~100 Hz,再合成語音較原始語音、合成語音,關于平均識別率有一定程度地提升,在頻率范圍為100~500 Hz內,再合成語音較原始語音、合成語音,關于平均識別率顯著提升這是由于男女的基音頻率在此范圍內,而對于1 000~2 000 Hz頻段,處于較高頻,對語音整體影響較小,因此平均識別率提升效果不明顯,綜合分析表3,對聽障患者的聽力保護均有提升。
4? 結語
本研究通過觀察語譜圖,挖掘特征參數之間的相關性,提取語音形成的兩大特征——基頻和共振峰。通過分析語音的形成原理,探究語音的數理本質,根據特征參數值進行函數化的合成,形成初步的合成語音。研究進一步根據聽障患者特點及語音特點,有針對性地調整函數中相關的特征參數值,進一步實現語音再合成,一方面,降低了外界及生理因素對語音產生的影響,另一方面,避免了助聽器因整體擴大分貝值對聽障患者聽力健康產生的影響,維護了聽障患者的身心健康,對于助聽器產品的改善具有一定參考意義。
參考文獻:
[1]? 李勝利,孫喜斌,王蔭華,等.第二次全國殘疾人抽樣調查言語殘疾標準研究[J].中國康復理論與實踐,2007(9):801-803.
[2]? 費櫻平,鄭蕓,張林,等.骨傳導助聽器選配效果分析[J].中國聽力語言康復科學雜志,2022,20(5):361-363,367.
[3]? 韋芮,陳善文,唐開新,等.人工耳蝸植入前后耳鳴與焦慮、抑郁相關性分析[J].聽力學及言語疾病雜志,2022,30(4):432-435.
[4]? 魏爽,王曉楠,楊璟安.基于動態字典學習的欠定盲語音重構算法[J].計算機工程與設計,2022,43(5):1351-1357.
[5]? HAO X Y, ZHU D L, WANG X L, et al. A speech enhancement algorithm for speech reconstruction based on laser speckle images[J].Sensors,2022,23(1):330-330.
[6]? 蘆婷,周馨宇,趙霞,等.聽障兒童人工耳蝸植入術后生活質量評估及影響因素分析[J].寧夏醫學雜志,2021,43(8):718-721.
[7]? SLADEN D P, NIE Y, BERG K. Investigating speech recognition and listening effort with different device configurations in adult cochlear implant users[J].Cochlear Implants International,2018,19(3):119-130.
[8]? 顧晰,吳小波,林有輝,等.人工耳蝸植入術后皮瓣相關并發癥的臨床特點及處理方法分析[J].中華耳科學雜志,2018,16(6):765-771.
[9]? 王咿卜.基于基頻控制的語音合成的研究[D].西安:陜西科技大學,2021:1-82.
[10] YANG J H. The application of speech synthesis technology based on deep neural network in intelligent broadcasting[J].Journal of Control Science and Engineering,2022,2022(4):1-6.
[11] 吳進.語音信號處理實用教程[M].北京:人民郵電出版社,2015:225,230-349.
[12] 馬效敏,鄭文思,陳琪.自相關基頻提取算法的MATLAB實現[J].西北民族大學學報(自然科學版),2010,31(4):54-58,63.
[13] 張巖,王偉.基于YIN算法的樂器單旋律音高的提取[J].沈陽師范大學學報(自然科學版),2020,38(5):438-442.
[14] 張永濤,賈延明.最小二乘法中代數多項式曲線擬合的分析及實現[J].計算機與數字工程,2017,45(4):637-639,654.
[15] 李建文,王咿卜.函數擬合實現帶聲調的語音合成[J].計算機應用與軟件,2022,39(9):193-200.
[16] 劉艷慧.聾兒助聽器佩戴前后聽力檢測在WHO和ANSI分級標準中的應用分析[J].中國衛生標準管理,2014,5(13):123-124.
