基于XGBOOST特征選取的LSTM模型評估股票走勢分析
2023-05-08 23:34:00張訓韜范永勝
電腦知識與技術 2023年9期
張訓韜 范永勝



關鍵詞:XGBOOST;LSTM;特征排名;股票預測
自1990年滬深兩大證券交易所開市以來,中國股市蓬勃發展。中國證券登記結算有限責任公司于2022年2月披露,中國股民占全總人口七分之一,突破2億[1]。可見,隨著經濟的快速發展,人民的可支配收入顯著提高。除去日常開銷外,越來越多的人選擇股票投資來實現剩余資金的最大價值。雖然A股投資者大量增加,但投資者投資的技術水平參差不齊。陳興松等研究者發現A股投資者中,小散戶數量遠遠大于專業機構投資者[2]。大量散戶投資理念不成熟,有較強的從眾心理,無法很好地利用歷史數據對股票走勢進行分析判斷,更傾向于追漲殺跌。盲目投資的結果往往是虧損,更有甚者傾家蕩產。因此,通過一定的技術手段指導股票買賣,規避買家主觀的無效抉擇是很有必要的。
1 研究綜述
學者為了讓投資者方便地看出股票的未來趨勢,研究了很多的技術指標。傳統的技術指標預測法主要將K線圖和KDJ,MADC等技術指標結合來預測股票走勢,帶有一定的主觀性,且很難分析出多維數據間的關聯。統計學預測法處理線性問題具有一定優勢,Li等應用統計學的ARIMA模型預測了股價的變化趨勢[3]。但隨著機器學習和深度學習在非線性預測問題上取得了卓越表現,研究者們把研究股票預測問題的重心轉移到了機器學習和深度學習上。機器學習預測法一般就是把時序問題轉換為監督學習,通過特征工程和機器學習方法去預測。Hassan提出了一種結合隱馬爾可夫模型和模糊的方法預測股票,其預測的精度遠高于普通隱馬爾可夫模型和ARIMA 模型[4]。Wei等引入了最小二乘支持向量機(LS-SVM) 預測股票,通過動態慣性權重粒子群(W-POS) 優化參數,其訓練速度優于SVM,預測結果優于BP神經網絡[5]。機器學習在股票預測上取得了一定成就,但是股票作為時序數據,機器學習忽視了數據的前后關系。目前,研究者熱衷于用深度學習,尤其是LSTM模型訓練時序數據。Lstm在處理非線性問題上效果良好,三個門實現了對時序數據的保護和控制,并且解決了rnn長期和梯度消失的問題。Althelaya利用標準普爾500指數評估變種LSTM模型和GRU模型。實驗表明疊加的LSTM的體系結構有更好的預測性能[6]。有了成熟的預測模型,需要考慮的是特征的選取。充足的技術指標可以讓預測結果更準確,但可作為模型輸入數據的金融技術指標已有上百種,若將所有的指標應用于股票預測勢必會降低算法運行效率和增加模型復雜度。現有的降維算法很多,主要分為特征提取和特征選擇兩大類。特征提取通過訓練分析原有特征,提取出新的特征,且這些新的特征并未包含于原特征中,其中代表的算法就是主成分分析。而特征選擇主要是將原有特征按重要性排序,最終篩選的特征是原有特征的子集,代表算法有遺傳算法和決策樹算法。本次研究是選擇后者中的XGBOOST算法選擇特征,選擇排名靠前的金融指標訓練LSTM模型,達到預測未來股價的目的。
2 理論基礎
2.1 XGBOOST 模型
XGBOOST(極值的梯度提升樹)是陳天奇等人提出的一種基于樹構造的算法,其構造思想和GDBT(梯度提升決策樹)大致相同,只是在其功能上進行提升,兩者都是屬于boosting方法[7]。這種算法的構造原理集成多個弱分類器形成一個強分類器。XGBOOST不停地迭代,且每次生成的新樹都擬合了前一棵樹的殘差,迭代的次數越多,訓練的精度越好。增強學習的構建模型如下所示:
其中:n表示總共構建的決策樹個數,xi 代表輸入的特征值,F為所有生成決策樹的集合,ft 是單棵決策樹的訓練函數,yi 則表示最終的預測值。每一棵樹對應的ft 都包含了一種特征值和葉節點值的對應關系。為了更好地闡述XGBOOST樹與弱學習樹的關系和更好的訓練模型,我們定義了如下的目標函數:
其中:yi 是預測結果,yi 表示真實值或者標簽,(1)是預測結果和實際情況損失函數的簡單表示。(2)是一個正則化項,是每棵樹復雜度之和。fk 依舊表示的是第k棵樹的模型,T是每棵決策樹的葉子節點數目,ω是每棵樹葉子節點分數,γ和λ代表著系數,用于保證葉節點分數和葉結點個數不會太大。通過正則化的引入,防止了勾結樹的過程中過擬合的情況出現。
2.2 XGBOOST 重要性排名
其中X 是分類到每個葉節點的集合,Gainx 是每個節點的增益,Coverx 是每個節點上的樣本數目。
2.3 LSTM 模型
LSTM一共包含三個門控單元,即遺忘門,輸入門和輸出門。通過三個門更新參數和實現“記憶”功能,并通過引入“記憶細胞狀態”對其進行長期保存[8]。
LSTM狀態由圖1所示。
1) 遺忘門。遺忘門通過選擇性地拋棄上一時刻的數據,決定了上一時刻有多少信息可以保留在當前時刻。其公式如下:
3 實證分析
3.1 實驗流程與實驗環境
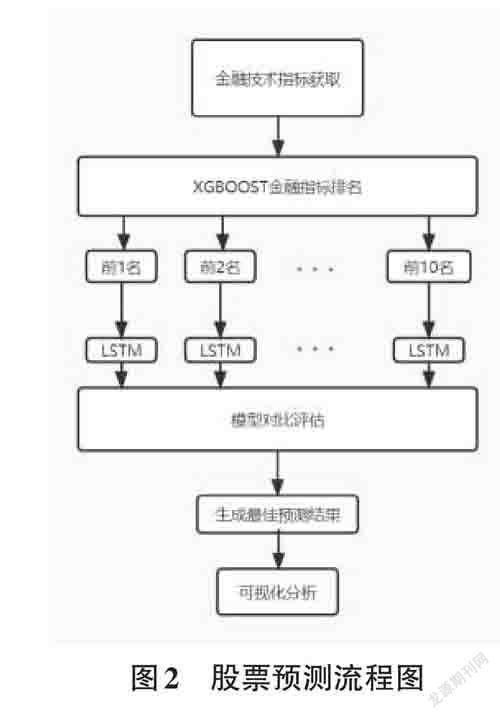
1) 獲取目標股票的金融指標,通過XGBOOST重要性分析,求得這些金融指標的排名。2) 選擇排名將靠前的十個指標做成多組組合數據訓練LSTM模型。3) 利用均方差等指標對模型進行評估,選出最佳的指標組合,并通過最佳組合數據預測股票。4) 利用可視化分析工具對比最佳組合的預測值和真實值的差距。實驗流程圖如圖2所示。本文選用Python3.7,Tensor?flow2.3.0,和Sklearn0.22.1的語言環境,通過交互式筆記本jupyter_notebook 實現編譯。操作系統是Win?dows10。硬件方面是10 代inter-CORE-i7 搭配一塊NVIDIA-RTX2060。
3.2 數據選取
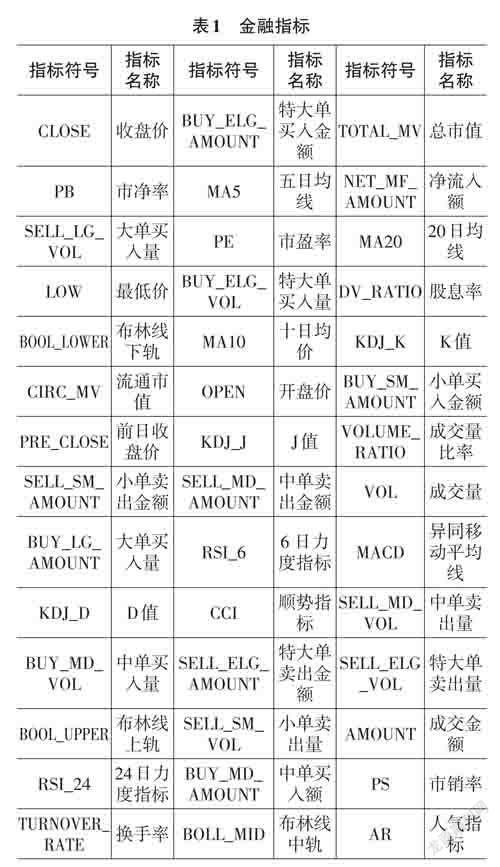
Tushare是一個免費、開源的Python財經數據接口包。主要實現對股票等金融數據從數據采集、清洗加工到數據存儲的過程,能夠為金融分析人員提供快速、整潔、和多樣的便于分析的數據。本次研究的金融數據依托于該接口包,通過對應的API 采集了2017-8-1至2022-8-1的某股票5年1237個交易日的股票數據。在以往的研究中,研究者們希望通過修改算法提高股票預測的準確率,在金融指標的選擇上僅僅依賴常規五項指標,即開盤價,收盤價,最高價,最低價和成交量。本次研究通過金融接口直接提取和人工編程計算,在常規五項指標基礎上,將金融技術指標擴展到42項。所有指標匯總如表1所示。
3.3 數據歸一化處理
金融屬性取值范圍很大,若直接用于預測模型訓練,程序運行收斂很慢。通過歸一化處理,可加快收斂。具體的公式如下:
歸一化以后的數據雖然方便模型訓練,但該模型預測的值也是歸一化的狀態,為了方便預測值和真實值比較,還要對預測值進行反歸一化處理。具體公式如下:
其中,x 是真實值,x'是歸一化以后的值,max(x)和min(x) 分別代表最大值和最小值。y'代表歸一化的預測值,y 代表反歸一化后的預測值。
3.4 XGBOOST 特征選擇
以每日42個金融屬性作為輸入,第二日收盤價作為輸出構建決策樹。借助于第三方庫XGBOOST下的feature_importances_方法對屬性打分。該方法首先借助GINI系數求得各個屬性重要性,再將所有重要性做歸一化處理,最后依據重要性對特征進行排名。排名前二十的屬性如圖3所示。
其中對第二日收盤價影響最明顯的是前一日的最收盤價,五日均價,市銷率,流通市值,最低價和最高價。由圖可知,排名靠后特征對收盤價影響太小,本研究僅保留排名前十的特征。通過累加屬性種類,將前十的屬性分為十組。如:第一組一個屬性,第二組兩個屬性,以此類推。將十組屬性分別投入到LSTM,通過預測結果對比找到最優的金融屬性預測組合。
3.5 LSTM 模型構造
首先需確定LSTM的輸入數據類型。本次研究將通過前5天金融指標對第6日的收盤價進行預測。原始的數據包含了一年內所選股票1237個交易日的42個金融指標,其張量的維度為(1237,42)。若將連續5天數據作為一個輸入單元,則整個數據輸入張量的維度變為(1232,5,42),對應的標簽張量維度為(1232,)。所以,根據我們所選的屬性個數知道模型的訓練數據張量維度為(1232,5,X),5代表前五天的數據,X代表所選擇的金融屬性個數。
整個股票預測模型采用了兩層LSTM和一個全連接層來構造,每個LSTM層各有64個神經元。為了防止過擬合的出現,每個LSTM層后面添加了一個失活率0.2 的Dropout 層。LSTM 層的激活函數選擇的‘relu’,優化器選擇的是‘adam’,損失函數選擇的是均方差‘mse’。
將排名前十的屬性分為十組,第一組包含排名第一的屬性所有數據,第二組包含排名前二屬性的所有數據,以此類推。將每一組數據放入LSTM 中,batch_size設置為32,每一組數據訓練100次。
3.6 預測結果分析
本次實驗通過MSE,MAE 和R2 作為模型好壞的評價指標。三個評價指標公式如下所示:
其中m 代表預測值數目,yi,yi 和yˉ分別代表真實值,預測值和平均值。其中MSE,MAE 越小預測誤差越小,R2越接近1說明模型擬合效果越好。
用十組組合數據訓練LSTM,每一組數據分別訓練十次,取十次指標的平均值作為該組的評測指標。十組指標如表2所示。
由表2可知在包含開盤價,五日均價,市銷率和流通市值四個金融指標的第四組數據訓練結果中MSE值和MAE 值最小,且R2值最接近1。該組模型的預測效果最好。用第四組指標預測數據并與真實數據進行可視化分析,近三個月和近五年的對比結果如下圖4所示。
從上圖可知,近來三個月預測數據和真實數據略有偏差,但價格走勢基本一致。近五年的預測值走勢和實際價格走勢完全重疊。這表明用排名前四的金融指標訓練的LSTM模型對長線交易有一定的指導作用。
4 結論
為了找到預測股票收盤價的最佳金融指標組合,本文提出了一種結合XGBOOST和LSTM的股票預測方法。利用某股票五年的歷史數據進行實驗,結果表明以前五日開盤價,五日均價,市銷率和流通市值為組合的金融數據預測第六日的收盤價效果最好。因此本文提出預測方法對股民判斷股市價格變化有一定的作用。
本次研究的重心是尋找預測股票走勢的最佳金融指標組合。雖然得出了有一定參考價值的結論,但還存在一些可進一步研究的方向:
1) 本次研究未能對預測的LSTM參數進行優化。比如未曾通過優化算法尋找適合本次算法的最佳神經網絡層數和每層神經網絡的神經元個數,而是直接地指定這些參數。在后續研究中,可以進一步調整和優化模型,使得預測結果更加準確。
2) 這次使用的模型中未曾考慮市場情緒對股票的影響。在后續的研究中,可以嘗試加入股民的情緒因子作為輸入指標幫助預測。這樣可以提高預測的精度和時效性。
3) 本次研究的模型,對于長期走勢的判斷基本吻合,但短線的效果吻合度仍然不理想。
