神經輻射場加速技術綜述
2023-05-13 08:44:50鄭清芳ZHENGQingfang
中興通訊技術 2023年2期
鄭清芳/ZHENG Qingfang
( 1. 中興通訊股份有限公司,中國 深圳 518057;2. 移動網絡和移動多媒體技術國家重點實驗室,中國 深圳 518055)
過去10 年,視頻相關技術[1-5]領域最深刻的變革發生在內容分析方面。自從2012年AlexNet[6]在ImageNet大規模圖像識別挑戰(ILSVRC)競賽中奪冠以來,基于深度學習的計算機視覺技術突飛猛進,將內容分析的準確率提升至前所未有的水平,并催生出巨大的市場應用規模。以人臉識別為代表的各項視頻內容分析技術走出實驗室,服務于千行百業。
未來10 年,同樣激動人心的突破有望發生在視覺內容生成方面。簡單便捷地從2D視頻/圖像集中合成出嶄新視角的視頻/圖像,甚至重建出物體及場景的3D模型,并且畫質達到照片級的逼真度和清晰度,一直是內容生成方面的長期技術研究課題[7]。2020年美國加州大學伯克利分校的研究團隊提出神經輻射場技術(NeRF)[8]。NeRF 因其創新的方法及突出的效果,吸引了業界的廣泛關注,成為視圖合成/3D重建領域新的技術框架。自從發表后近兩年的時間里,該NeRF 論文被引用超過1 000 次。同時業界研究者對NeRF 技術進行了大量的改進,并將其應用領域擴展到視頻編輯[9]、數據壓縮[10]、虛擬人[11]、城市建模[12]、地圖構建[13]等諸多方面。
NeRF 技術的一個顯著缺點是模型訓練及圖像渲染的速度極慢。在Nvidia的高端顯卡上,訓練一個場景的模型需耗時1~2 d,而從模型中渲染出一幅800×800分辨率的圖像需耗時超過20 s。運算速度方面的不足阻礙了NeRF 技術在實際應用中的部署。可喜的是,經過業界研究者近兩年的努力,渲染速度提升超過10 000 倍[14],訓練速度提升超過300倍[15]。
針對NeRF的各種加速技術,本文梳理并總結了速度提升的技術機理和工程技巧,并分析各項技術之間互相結合以達到復合加速效果的可能性,從而有助于激發更高效算法的產生,進一步推進NeRF 技術在內容生成及其他領域的應用。
1 相關研究工作
文獻[16]和文獻[17]分別對2021年3月之前的NeRF相關技術做了綜述。文獻[16]針對促使NeRF 出現的各種技術和NeRF 出現后的各種改進性技術這兩個主題,提供了注釋性的參考文獻,但不涉及對各技術的詳細說明。文獻[17]將相關技術大致分為兩大類:第1 類對NeRF 表示方法的理論性質和不足進行分析,并提出優化策略,包括對合成精度、繪制效率以及對模型泛用性的優化;第2 類則以NeRF 的框架為基礎對算法進行擴展和延伸,使其能夠解決更加復雜的問題。文獻[16]和文獻[17]促使更多的研究者對NeRF 進行研究,但也因其成文時間較早,無法涵蓋對2021 年3 月以后NeRF的許多重要進展的總結。
文獻[18]綜述了神經渲染技術的整體發展。神經渲染技術廣義上是指所有利用神經網絡產生新的視覺內容的技術,而NeRF僅是其中的一個子領域,側重于合成出新的視角的視覺內容。文獻[18]重點介紹了將經典渲染與可學習3D表示相結合的高級神經渲染方法,盡管提及了許多NeRF相關的文獻,但本質上不是針對NeRF的綜述。
在本文的撰寫過程中,加拿大滑鐵盧大學的研究者在Arxiv.org上展示了預印本[19],全面介紹了過去兩年業界提出的各種NeRF 改進,以及NeRF 技術在各種計算機視覺任務中的應用。與文獻[19]不同,本文著眼于運算速度的提升,對各種加速技術進行分類,闡釋技術背后的機理和工程技巧,展現NeRF發表以來的技術演進脈絡,以期為相關研究者提供有益參考。
2 NeRF技術簡介
對于給定的三維場景,任意位置的外觀取決于具體位置和觀測角度。場景表現出的顏色與光照條件相關,導致從不同角度觀察同一位置時顏色也會出現變化。NeRF 是一個描述三維場景的函數(r,g,b,σ) = FΘ(x,y,z,θ,φ),其中FΘ用多層感知機(MLP)來具體表示。輸入位置信息(x,y,z)和觀測角度(θ,φ)后,該函數輸出該位置的體密度σ 和在對應觀測角度的顏色值rgb。在基于NeRF的場景表示基礎上,可以采用經典體渲染方法渲染出不同視角的新圖像。具體地,對于圖像中任意像素,沿著觀測角度的光線r 采樣N 個點Xi(i =1,…,N),對每個采樣點先根據FΘ計算出σi和rgbi,然后根據以下公式計算出最終的顏色值:
其中,δi代表在光線r上的采樣間隔。
為了訓練出FΘ對應的MLP具體參數,對于給定的場景,采用不同位姿的攝像頭拍攝得到n幅圖像,利用梯度下降的方法,通過最小化預測圖像Ip與真值圖像Ic之間的誤差對FΘ進行擬合,即
圖1 給出了NeRF 算法的流程。在文獻[8]中,作者為了得到含有更多高頻信息的輸出圖像,對輸入MLP 的位置和視角參數進行了高階編碼操作γ(.)。另外,為了提升運行速度,作者采用先粗放后精細的策略提高采樣的效率:首先在光線方向上均勻采樣64個點,然后由這64點的密度值估計出密度分布函數,再對高密度的區域采樣128點。
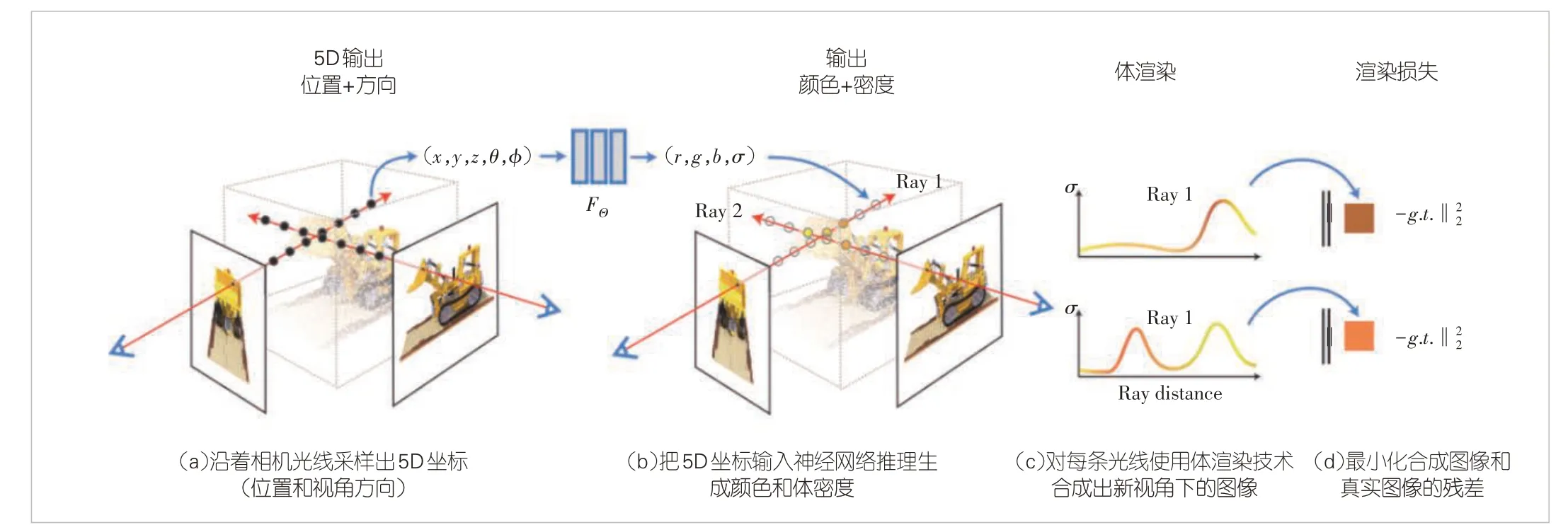
▲圖1 神經輻射場算法流程[8]
NeRF的運行速度十分緩慢,主要有兩個原因:
1)巨大的計算量。例如:在渲染一幅分辨率為800×800 的圖像時,NeRF 為了計算出每個像素的最終顏色值,需在光線行進的方向上采樣192(64+128)個點,并進行256次MLP推理。這意味著渲染該圖像總共需要800×800×256=163 840 000 次MLP 推理。MLP 的網絡架構如圖2(a)所示。每次推理計算需要超過100 萬次浮點運算。總體而言,整個過程需要超過100T次浮點計算。
2)低效的實現方式。在通常針對Nvidia 圖形處理器(GPU)優化的深度學習函數庫中,MLP 是逐層計算的。每一層用一個核函數來實現具體的計算,并向GPU 全局顯存寫入計算結果,而下一層在計算時又需從全局顯存讀取該計算結果并將其作為本層的輸入。在目前的GPU芯片架構中,全局顯存的數據讀寫速度遠小于計算速度。頻繁的數據讀寫嚴重制約了GPU的實際工作性能。
3 加速技術介紹
鑒于NeRF 巨大的潛在應用前景,針對當前NeRF 十分低效的運行速度,近兩年來研究者們提出了一系列加速技術。由上一節的分析可知,對于給定分辨率的圖像,NeRF的實際運行速度受到每道光線中的MLP 的計算復雜度、采樣點數量、硬件的技術特性等因素的綜合影響。本文從采用小型化MLP、減少采樣點數量、緩存中間計算結果以及充分利用硬件特性4個方面對現有技術進行分類和介紹。
3.1 采用小型化MLP
在NeRF 的實現中,圖像中每個像素的色彩值的計算都需上百次的MLP推理,因此減輕MLP 的計算復雜度是非常有必要的。如果采用更小型化的MLP,不論是減少其深度還是寬度,都會導致模型表征能力的下降,損害最終輸出圖像的視覺質量。因而,此類方法的關鍵在于采用何種策略能夠確保小型化MLP 的最終輸出不會影響最終的視覺質量。
DeRF[20]和KiloNeRF[21]采用了分而治之的策略:用更小的MLP來表示目標場景的一部分而非整個場景。DeRF把整個場景劃分為不規則的互相獨立的16個Voronoi單元。相比于NeRF 中的MLP,每個Voronoi 單元對應的MLP 深度不變但寬度減半,因此計算量只有原來的1/4。在渲染時,由于每條光線上的每個采樣點只計算與它相對應的MLP,因此整體速度可以達到原始NeRF 的1.7 倍。KiloNeRF 采用沿坐標軸均勻分解場景的方法,最多可以把場景分為16×16×16 = 4 096個小場景。每個小場景對應的MLP的具體架構如圖2(b)所示。該架構僅有4 個隱含層且每層只有32 個通道,其計算量為NeRF 中MLP 的1/87。相比于原始的NeRF,KiloNeRF 的總體渲染速度可以達到3 個數量級的加速倍速。為了保證視覺質量,在KiloNet 訓練過程中采用知識蒸餾的方式,使KiloNeRF的輸出與NeRF的輸出相一致。
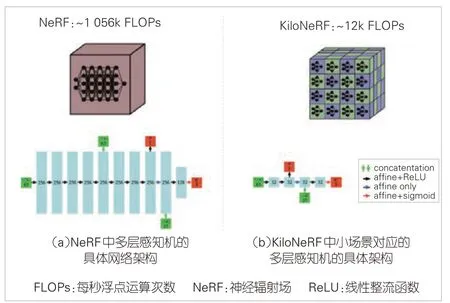
▲圖2 NeRF與KiloNeRF的比較[21]
Instant NeRF[22]的核心思路是:既然MLP 的最終輸出值取決于MLP 自身的參數和輸入的特征,那么小型化MLP 表征能力的減弱可以通過增強輸入特征的表征能力來彌補。Instant NeRF中的MLP由兩個分別包含1個及2個隱含層且每層都為64個通道的小型MLP串聯組成。不同于NeRF中的位置編碼,Instant NeRF對輸入參數采取多分辨哈希編碼方式:輸入參數在某個分辨率中經過哈希后對應一個特征向量,把輸入參數在所有分辨率中對應的特征向量串聯起來形成最終的特征向量。Instant NeRF 不但加速了渲染過程,在Nvidia RTX 3090 GPU上能夠以60 fps的速度輸出1 920×1 080的圖片,而且解決了NeRF 模型訓練慢的問題,將NeRF 訓練速度提高了60 倍。實驗結果表明,在最快的情況下,Instant NeRF模型的訓練時間只需要5 s。圖3以2D空間場景為例解釋了Instant NeRF 的計算過程。該計算過程包括5 個步驟:1)對于給定的輸入坐標x,在不同的分辨率中分別找到周圍的體素;2)在哈希表中查詢不同分辨率的體素所對應的特征向量;3)根據x 在各自體素中的相對位置,插值計算出x 在不同分辨中的特征向量;4)將在各分辨率上的特征向量串聯,形成最終的特征向量;5)將特征向量輸入神經網絡進行推理計算
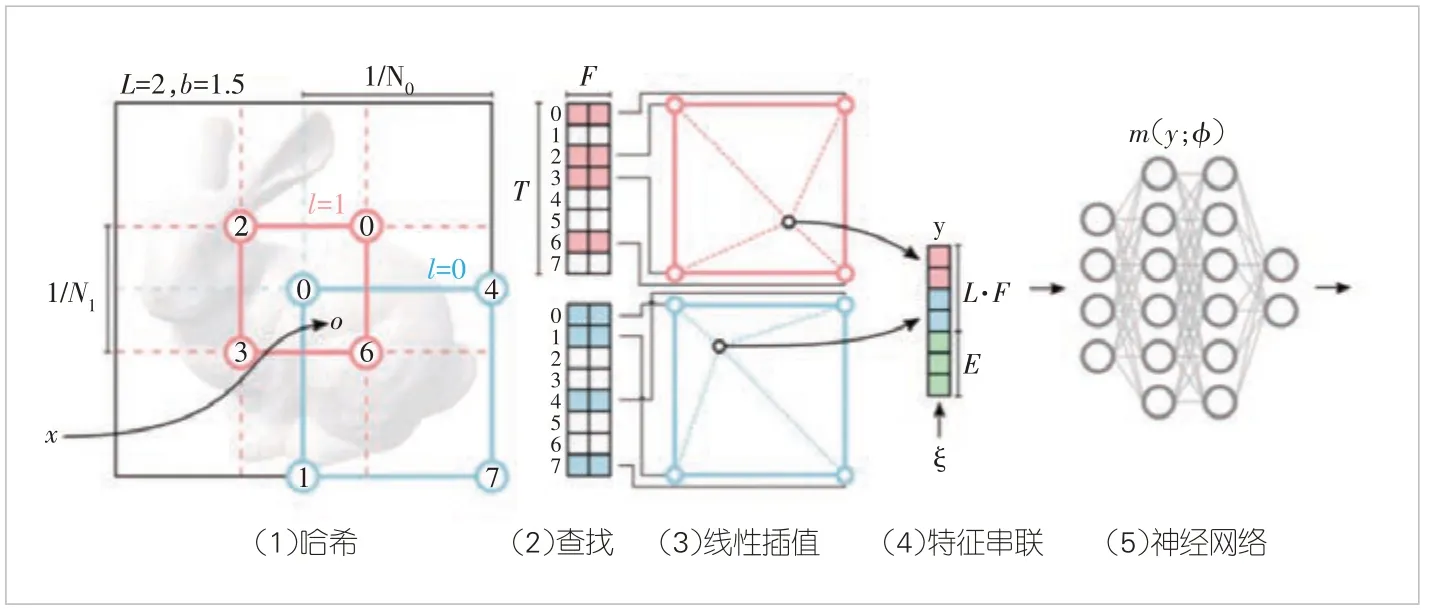
▲圖3 Instant NeRF的計算過程[22]
3.2 減少采樣點數量
盡管NeRF已經采用了層次化的采樣策略來避免對整條光線進行密集采樣,但是仍然需要固定的192個采樣點。事實上,由于目標場景通常無法完全充滿整個三維空間,必然有某些采樣點落在目標場景之外。另外,某些采樣點在視角方向上被完全遮擋,使得這些采樣點對最終的計算結果并無幫助。因此,更合理的采樣策略應該可以避免把計算資源浪費在這些采樣點上。
文獻[23]引入了一種用于快速和高質量自由視角渲染的新神經場景表示方法:神經稀疏體素場(NSVF)。NSVF 定義了一組由稀疏體素八叉樹組織的體素有界隱式場,以對每個體素中的局部屬性進行建模,并為體素的每個頂點分配一個特征。體素內部具體位置的特征通過對體素8個頂點處的特征進行插值計算。在渲染過程中,需要對每條光線進行軸對齊邊界框相交(AABB)測試,即比較從光線原點到體素的6個邊界平面中的距離,檢查光線是否與體素相交。對于不相交的空體素,可以直接跳過,從而實現10 倍以上的渲染加速。圖4比較了NSVF與NeRF的不同采樣策略。因為NSVF 渲染過程是完全可微的,所以可以通過將渲染的輸出結果與一組目標圖像進行比較,然后進行反向傳播來實現端到端優化。監督訓練NSVF的過程采用了漸進式的策略,使得不包含場景信息的稀疏體素會被修剪掉,以允許網絡專注于具有場景內容的體積區域的隱函數學習。文獻[23]中的實驗表明,只需1 萬~10 萬個稀疏體素就能夠實現復雜場景的逼真渲染。
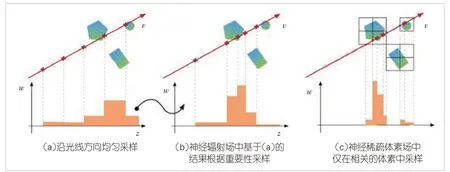
▲圖4 神經稀疏體素場和神經輻射場的不同采樣策略對比[23]
盡 管TermiNeRF[24]、NeuSample[25]、DONeRF[26]的具體做法不同,但背后的思想卻是類似的:在訓練的過程中,聯合訓練NeRF 和一個采樣神經網絡,而在渲染過程中,僅需對每條光線推理一次采樣神經網絡,即可得到所需的全部采樣點位置。以加速效果最好的DONeRF為例,為了在不影響圖像質量的前提下大幅減少每條光線所需的采樣點數量,文獻[26]的作者引入真實深度信息,只考慮物體表面周圍的重要采樣點。DONeRF 由一個著色網絡和一個采樣網絡組成。其中,著色網絡使用類似NeRF 的光線行進累積法來輸出顏色值,而采樣網絡則通過將空間沿光線離散化并預測沿光線的采樣概率,來預測每條光線上的多個潛在采樣對象。為了消除輸入的模糊性,光線被轉換到一個統一的空間中。作者使用非線性采樣來追蹤接近的區域,并在采樣網絡和著色網絡之間,對局部采樣進行扭曲,以使著色網絡的高頻預測被引導到前景上。圖5 展示了DONeRF 的計算過程。實驗結果表明,DONeRF 只用4 個采樣點就取得了與NeRF 相似的圖像質量,渲染速度可實現20~48倍的提升。
▲圖5 DONeRF的計算過程[26]
如圖6所示,EfficientNeRF[27]在訓練時采用了與NeRF相似的先粗放后精細的采樣策略,但是在粗放采樣階段只計算體密度σ > 0 的有效樣本,在精細采樣階段只計算w >0.000 1的關鍵樣本以及與其臨近的另外4個關鍵樣本,整體的訓練時間減少了88%。每個位置對應的σ值被初始化為非零值并存儲在Vσ中,在后續的每次訓練迭代中根據Viσ =進行更新。其中,β ∈(0,1)是控制更新率的參數,σ(x)是本次迭代中得到的體密度值。w根據公式(2)—(4)計算。
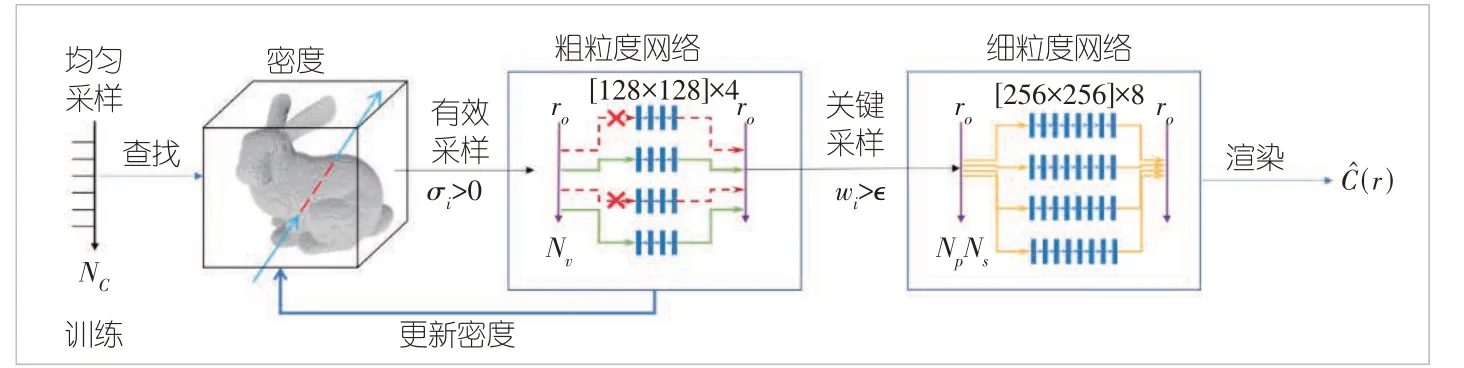
▲圖6 EfficientNeRF訓練過程中的采樣策略[27]
3.3 緩存中間計算結果
通過預先計算并將計算結果緩存起來,在后續使用時直接獲取該結果,是常見的加速方法。NeRF 本質上是將5 維的輸入參數(3維的位置參數+2維的視角參數)映射到4維向量的函數(r,g,b,σ) = FΘ(x,y,z,θ,φ)。對此,最簡單方法是直接將5 維輸入空間離散化,并將對應的計算結果全部緩存。但該方法因為所需的內存容量太大而不具可行性:即使假設輸入參數每個維度的分辨率都是512,所需的內存也超過150 TB。
如圖7 所示,FastNeRF[28]和SqueezeNeRF[29]都利用了函數分解的思想。FastNeRF 將NeRF 分解為兩個函數:第1 個函數(σ,u,v,w) = Fpos(x,y,z)將位置參數映射到體密度σ 和輻射圖(u,v,w);第2 個函數β = Fdir(θ,φ)則將視角參數映射到與輻射圖對應的權重向量β,其中u、v、w、β 都是D 維向量。Fdir和Fpos的全部結果被預先計算并緩存。渲染時先根據位置和視角參數從緩存中分別查詢得到權重向量和深度輻射圖,然后通過計算二者的內積即可獲得顏色值:(r,g,b) =。該計算量遠小于NeRF 中的一次MLP 推理,因此FastNeRF的渲染速度比NeRF提升了約3 000倍。假設k和l分別表示位置和視角方向的分辨率,緩存Fpos和Fdir所需的內存空間復雜度分別為O(Dk3)和O(Dl2),且O(Dk3)和O(Dl2)遠小于緩存NeRF 所需的內存空間復雜度O(k3l2)。在通常設置中,k = l = 1 024,D = 8,FastNeRF 所需的最大緩存空間大約為54 GB。為了能夠運行在內存更小的嵌入式設備上,如圖7 所示,SqueezeNeRF在FastNeRF的基礎上將函數Fpos進一步分解為3 個函數并緩存其結果,所需內存空間的復雜度也從O(Dk3)降到O(Dk2)。
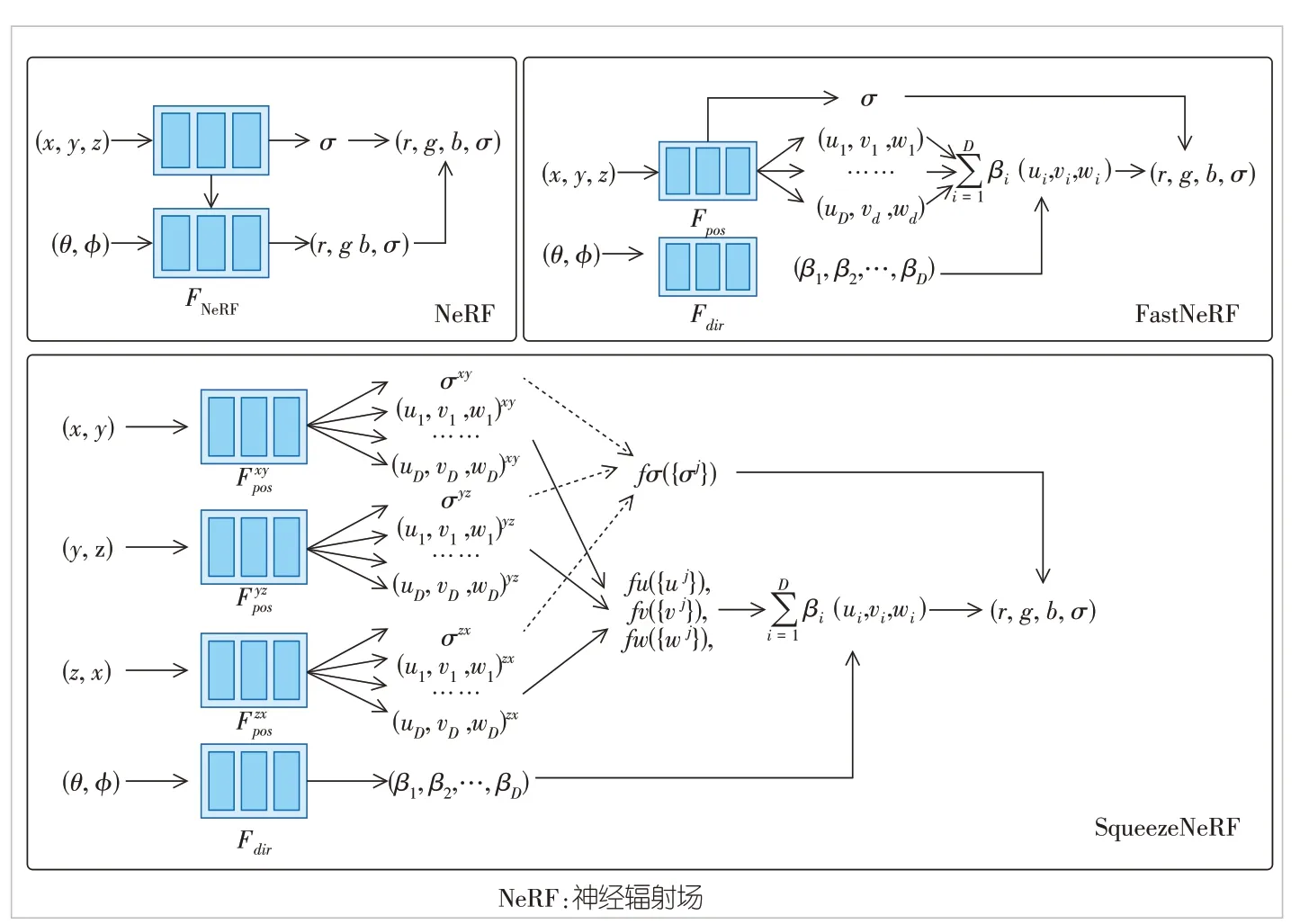
▲圖7 NeRF、FastNeRF、SqueezeNeRR 3種神經網絡架構的對比
在文獻[30]中,作者首次提出NeRF-SH 模型(σ,k) = FSH(x,y,z),將空間位置映射為體密度σ 和球諧系數k =。NeRF-SH 的 訓 練 過 程、渲染過程與NeRF 類似。作者采用稀疏八叉樹表示3維場景,在葉子節點上存儲各體素位置對應的體密度σ 和球諧系數k。該位置在方向(θ,φ)的顏色值為,其中,Yml(θ,φ)是與方向(θ,φ) 相對應的球諧系數,S(x) =(1 + exp(?x))?1。與NeRF 相比,PlenOctree 技術不僅可以將渲染速度提升3 000多倍,還能將訓練速度提升約4倍。在一般的場景中,Ple‐nOctree需要的內存空間通常不超過5 GB。EfficientNeRF[27]采用不同的數據結構來組織緩存數據,用一個兩層的樹NerfTree 代替PlenOctree 中的稀疏八叉樹,實現了更快的緩存查詢速度。
根據圖形學知識,物體的顏色可以表示為漫反射色與鏡面反射色兩者之和,其中鏡面反射色與相機觀測角度有關。文獻[31]定義一個函數(σ,cdiffuse,vspecular)= F(x,y,z),場景中的每個位置都對應著體密度σ、漫反射色cdiffuse,以及與鏡面反射色有關的4 維特征向量vspecular。這些數據經預先計算后被緩存在稀疏神經輻射網格(SNeRG)中。在渲染時,每條光線上采樣點通過查詢緩存直接獲取對應的σ、cdiffuse和vspecular,這些采樣點的cdiffuse和vspecular分別根據σ值加權累積得到Cdiffuse和Vspecular。Vspecular只需經過一次MLP 推理就可得到累積的鏡面反射色Cspecular,則最終像素的顏色為rgb = Cdiffuse+ Cspecular。利用該技術在AMD Radeon Pro 5500M GPU 上渲染Synthetic 360o圖像時,速度可達到84 fps。SNeRG 中的數組內容可以通過便攜式網絡圖形(PNG)、聯合圖像專家組(JPEG)等算法被壓縮到平均90 MB以內。
3.4 充分利用硬件特性
在實際部署中,算法總是運行在特定芯片上的。提升算法的運行速度通常意味著必須高效地利用芯片中的并行處理能力和內存/緩存資源。
在Nvidia GPU 上,Instant NeRF 和KiloNeRF 取得顯著加速效果的重要原因之一在于:小型化的MLP 能夠更充分利用GPU 芯片的技術特性。例如,與NeRF 中的MLP 相比,KiloNeRF 中MLP 的理論計算量只有1/87,而實際加速效果卻高出1 000 倍。在常規的統一計算設備架構(CUDA)深度學習函數庫中,MLP逐層用一個核函數計算,需要在GPU的全局顯存中讀寫中間計算結果。對于計算小型化MLP,數據訪問的時間遠大于數據計算的時間。KiloNeRF 和Instant NeRF 都使用CUDA 重新編寫一個核函數,并在其中完成MLP的所有計算,從而省去中間計算結果的數據搬運操作,減少頻繁啟停核函數的時間開銷。
為了在移動設備上部署NeRF,Google 推出MobileN‐eRF[14]。MobileNeRF充分利用了標準GPU光柵化管道的并行性。測試結果表明,在輸出圖像視覺質量相當的前提下,MobileNeRF 能夠比SNeRG 快10 倍,相當于比原始NeRF 快了10 000 倍以上。為了適配GPU 的光柵化管道,MobileN‐eRF 采用與原始NeRF 不同的訓練過程和表征方法,用帶有紋理的多邊形來表征每個場景模型。其中,多邊形大致沿著場景表面排布,紋理圖中存儲特征向量和離散的不透明度。渲染時MobileNeRF 先利用帶Z-buffering 的經典多邊形光柵化管道為每個像素生成特征向量,然后將特征向量傳遞給OpenGL著色語言(GLSL)片段著色器,并在其中運行小型化MLP,生成每個像素的色彩值。此外,MobileNeRF 的GPU 顯存利用率也高于SNeRG,在運行過程中前者占用的GPU顯存約為后者的1/5。
基于現場可編程邏輯門陣列(FPGA),上海科技大學開發了首個針對NeRF 渲染算法的定制化芯片ICARUS[32]。ICARUS的架構由定制的全光核組成,其中每個全光核集成了位置編碼單元(PEU)、MLP 引擎和體渲染單元(VRU)。當采用40 nm 互補金屬氧化物半導體(CMOS)工藝且工作在300 MHz 時,單個全光核僅占7.59 mm2面積,功耗為309.8 mW,能效比GPU 高146 倍。ICARUS 的高效性能主要得益于以下3個方面:
1)使用經過量化的定點數模型,尤其對于對復雜度最高的MLP計算,使用移位累加等近似算法。
2)全光核內部完成NeRF 的全部計算過程。當芯片加載經過訓練的NeRF網絡模型參數后,只要輸入觀察位置與視角,即可輸出對應像素的最終色彩值,無須在片外存儲中間計算結果,從而消除了各運算單元內部、單元之間的數據存儲和搬運操作。
3)每個像素的計算過程和結果完全獨立,控制邏輯大大簡化,可以方便地通過增加全光核數量來實現并行加速。
4 總結與討論
NeRF 技術可以從不同視角的2D 圖像集中學習并建立3D場景的隱含模型,并渲染出嶄新視角的圖像。不僅如此,新圖像的視覺效果能夠達到非常逼真的程度。自從2020 年第1篇關于NeRF的論文發表以來,NeRF技術為視角合成乃至3D 重建領域帶來新的研究思路。在兩年左右的時間里,該技術引起了業界廣泛關注,并得到了突飛猛進的發展。在未來,NeRF 技術將為視覺內容生成領域帶來巨大變革,如同當前深度卷積網絡技術為視覺內容分析領域帶來的變革一樣,在虛擬現實(VR)/增強現實(AR)及未來的元宇宙時代起到關鍵作用。
為了解決由NeRF技術運行速度緩慢導致的實際部署難的問題,研究者們已經提出各種加速技術。本文介紹了NeRF 的技術原理,并分析該技術運行緩慢的原因:在獲得每個像素的最終顏色值時,整體運行速度取決于MLP 的計算復雜度、每道光線沿線的采樣點數量等綜合因素。本文相應地從采用小型化MLP、減少采樣點數量、緩存中間計算結果以及充分利用硬件特性4個方面對現有技術進行綜述,介紹了各技術的加速原理和實現方法,希望可以幫助相關研究者快速了解本領域的技術現狀及演進脈絡。
另外,NeRF 相關技術仍在快速發展中,同時實際應用場景仍需要更加高效的加速技術。展望未來的技術發展,我們認為應重點關注以下幾個研究方向:
1) 復合加速效果
必須指出的是,盡管本文從技術原理的角度做了正交分類,并在各分類中列舉了代表性的工作,但所提及的諸多具體技術都綜合利用了多種加速原理。例如,EfficientNeRF在訓練階段減少采樣點數量,而在渲染階段緩存計算結果;Instant NeRF 和KiloNeRF 都采用小型化MLP,并針對特定GPU 架構優化MLP 的推理速度。我們推測,通過結合額外的加速原理,現有的方法可以實現更高的加速倍數,例如:KiloNeRF 可以進一步與DONeRF 相結合,減少采樣點數量,進一步提高渲染速度;Instant NeRF 可以在訓練階段結合EfficientNeRF中的采樣策略,并采用DS-NeRF[33]中在損失函數里增加深度信息約束的做法,來加快訓練過程收斂。對此,我們希望本文的分析能夠啟發感興趣的研究者設計出更加高效的算法。
2)訓練加速和渲染加速
NeRF 技術的特點是:針對每一個靜態場景都需要訓練一個模型,然后從模型中渲染出所需的圖像。鑒于原始NeRF 的訓練渲染過程都十分緩慢,為了在實際應用中使用NeRF 技術,加速訓練過程和渲染過程都十分必要。前述加速方法中有些只適用于渲染過程,甚至是以犧牲訓練速度為代價的,例如:在KiloNeRF 和MobileNeRF 之類的采用小型化MLP 的方法中,為了保證最終模型的輸出質量,需要先訓練出NeRF中的MLP模型,再通過知識蒸餾的方式,訓練出更小型化的MLP。
在諸如電商貨品展示的應用場景中,可以通過兩階段的過程來綜合利用上述兩類加速方法:先離線使用某種加速方法訓練出NeRF 模型,并進一步轉換成更高效的表達形式,然后在線展示過程中采用另外一種加速方法渲染出圖片。而對于諸如3D 視頻通信的端到端實時應用而言,往往需要同時加速模型訓練和渲染過程。在本文提及的方法中,Ple‐nOctree、EfficientNeRF 和Instant-NeRF 能同時加速訓練過程和渲染過程,但訓練過程的加速比遠小于渲染過程,訓練速度遠小于30 fps。
3)專用加速芯片
算法與芯片的發展總是相輔相成、互相促進的。當某種算法被廣泛采用時,通常研究者會為之設計專用的加速芯片,在性能、成本、功耗等方面實現更佳的匹配,從而進一步推廣算法的應用。在關于AlexNet 的論文發表之后大約兩年的時間,中科院計算所設計出第一款深度卷積網絡加速原型芯片DIANNAO[34]。該芯片將速度提升近120 倍,從此拉開波瀾壯闊的人工智能(AI)計算芯片產業化序幕;在有關NeRF 的論文發表之后大約兩年的時間,上海科技大學設計出第一款NeRF 渲染加速芯片ICARUS,使能效提升近140倍。ICARUS是否會同樣在芯片產業風起云涌?現有GPU的技術特性并不完全適配神經渲染的計算流程。類似Mobile‐NeRF 的技術通過復雜的轉化過程后,可以更加高效地利用現有GPU 的并行能力,從而能夠運行在移動設備中的嵌入式GPU 上。我們十分期待業界共同努力,持續創新,研發出神經渲染專用加速芯片產品,并創造出巨大的市場應用空間,使得在各種設備上便捷、快速、經濟地渲染出逼真高清的視覺內容成為現實。
