基于改進YOLOv5的光學遙感圖像水壩檢測研究
2023-05-19 07:54:56薛繼偉孫宇銳
計算機技術與發展 2023年5期
薛繼偉,孫宇銳
(東北石油大學 計算機與信息技術學院,黑龍江 大慶 163000)
0 引 言
當今世界科學技術發展的同時也帶來了一系列環境問題,生態環境的破壞將會給人們的日常生活帶來嚴重影響,保護環境并及時采取措施已經刻不容緩[1]。水壩是影響全球碳循環和水循環的一個重要因素,對其進行監測是非常有必要的,想要監測水壩首先需要了解水壩在圖像中的位置。對高分辨率遙感影像的目標分類識別進行研究,是對地觀測系統進行圖像分析的一種重要手段[2],目標檢測是將圖像數據轉化為應用成果的關鍵一環[3]。目前大部分基于深度學習的目標檢測算法只針對普通圖像,對于遙感圖像的一些特征提取能力有待提升[4]。為了環境保護后續工作的開展,該文針對遙感圖像中的水壩目標檢測方法進行研究,使用檢測通用目標的YOLOv5算法進行實驗并結合CBAM注意力機制進一步提升水壩目標檢測的精度。
1 相關工作
目標檢測技術如今已經逐漸趨于成熟,從最初的SIFT[5]、HOG[6]、DPM[7]等傳統目標檢測算法發展到如今基于深度學習的目標檢測算法,目標檢測的精度和速度都在不斷提高。基于深度學習的目標檢測方法的發展主要分為三個階段,分別是雙階段、單階段和無錨框階段[8]。雙階段方法主要有R-CNN系列[9]、SPP-Net等,單階段方法主要有YOLO[10]系列、SSD[11]、EfficientDet[12]等,無錨框方法主要有CenterNet[13]、FCOS[14]等。
以上方法主要針對普通圖像,而光學遙感圖像具有背景復雜、目標形狀尺度變化大等特征[15],一些學者根據遙感圖像的特征在通用的目標檢測算法基礎上進行改進。R2CNN[16]方法改進了Faster R-CNN算法以適應遙感圖像中長寬較大的目標,YOLT[17]方法將YOLOv2模型引入遙感圖像檢測領域,ROI Transformer方法對水平框采用可學習參數訓練方式轉為旋轉框,再對旋轉框內部區域特征池化,R3Det[18]方法對特征圖重構解決特征不對齊的問題,SCRDet[19]方法針對遙感圖像背景復雜的問題引入并行的像素級注意力機制和通道注意力機制弱化背景信息,提高了檢測性能。
目前在光學遙感目標檢測領域大部分是針對艦船、運動場以及飛機和機場等目標的研究[20],針對水壩目標的檢測方法較少。在深度學習方法成為研究熱點之前,對水壩的檢測基本上使用傳統的目標檢測算法。
2020年Zou Caigang等學者[21]使用深度學習的方法提出了基于雙閾值的目標檢測網絡模型,該模型在基本的單級目標檢測網絡基礎上增加雙閾值結構,對檢測結果進行二次決策,提高了網絡檢測的準確性,并在水壩遙感數據集中進行測試證明了該網絡的有效性。
針對水壩目標的特性,該文使用深度學習目標檢測方法YOLOv5模型結合CBAM注意力機制,對水壩目標進行訓練及驗證,可以使得檢測精度在只使用YOLOv5模型的基礎上有所提高。
2 目標檢測算法研究
2.1 YOLOv5算法
YOLOv5算法是單階段目標檢測方法,網絡結構主要分為四個部分,分別是輸入端、骨干網絡(Backbone)、Neck結構和Head輸出層。
輸入端為用戶輸入的圖像,YOLOv5在輸入端對數據進行縮放、歸一化、Mosaic數據增強等預處理。Backbone結構的作用是提取目標的通用特征,最新版本YOLOv5的Backbone包含CSPDarkNet53結構。Neck部分位于Backbone結構和Head結構之間,可以進一步提取特征,提升特征的多樣性和魯棒性。最新版本YOLOv5的Neck結構使用了SPPF和C3模塊。SPPF模塊通過多個大小為5*5的最大池化層串行傳遞輸入特征大小。
YOLOv5最新版本中的激活函數使用SiLU,該損失函數沒有上界,有下界,平滑且不單調,如公式(1)所示。
f(x)=x·sigmoid(x)
(1)
Head結構也是網絡的輸出層,包含三個預測分支,三個預測分支的總損失乘以batchsize可以得到用于更新梯度的損失。
YOLOv5的損失函數包括定位損失、置信度損失以及分類損失三個部分, 總的損失為三種損失之和。其中置信度損失采用二分類交叉熵損失函數(BCELoss),如公式(2)所示。
(2)
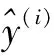
邊界框(Boundingbox)回歸損失使用CIoU Loss[22]。CIoU Loss考慮了重疊面積、中心點距離、長寬比三種幾何參數的計算,如公式(3)~公式(5)所示。
(3)
(4)
(5)
其中,α和v為邊界框的長寬比,w和h表示預測框的寬和高,wgt和hgt分別表示GroundTruth的寬和高。b表示預測框中心坐標的參數,bgt表示GroundTruth中心坐標參數。ρ2表示兩個中心點之間距離的平方。
2.2 CBAM注意力機制
在計算機視覺領域中適當應用注意力機制可以在一定程度上增強對圖像信息的處理。注意力模塊能夠在大量的信息中提取出重要信息從而增強對重點目標的關注,這種關注是根據不同的分配權重獲得。基于深度學習的目標檢測中常用的注意力機制模塊有SE[23]、ECA[24]、CA[25]、CBAM[26]等。該文在YOLOv5模型的網絡結構中添加通道注意力模塊與空間注意力模塊相結合的注意力機制Convolutional Block Attention Module(CBAM)模塊,可以進一步提高網絡特征的表達能力。
CBAM模塊在SE注意力機制的基礎上對通道注意力模塊進行了改進,并且增加了空間注意力模塊。通道注意力在前,空間注意力在后,這種排列方式增強了模塊的特征提取能力。通道注意力機制將輸入的特征圖經過全局最大池化(Global Max Pooling)和全局平均池化(Global Average Pooling)后,分別經過多層感知機(MLP)得到通道注意力的權重,再經過一個激活函數Sigmoid將注意力權重進行歸一化,最后通過乘法加權到原始特征圖上,生成空間注意力需要的輸入特征。AveragePooling和MaxPooling共用一個MLP可以減少學習參數。
通道注意力模型如圖1所示。
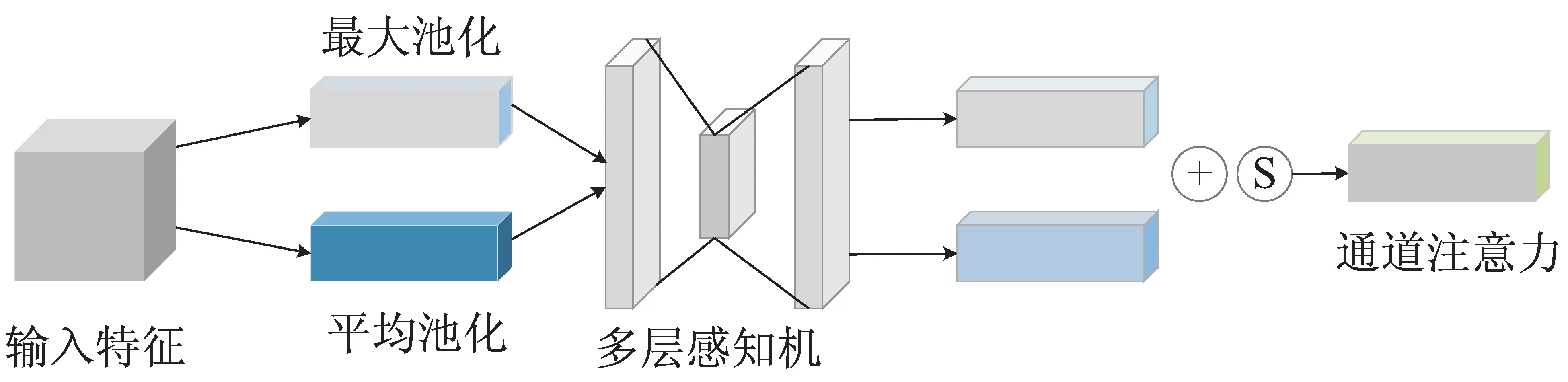
圖1 通道注意力模型
空間注意力模塊在得到的通道注意力權重基礎上進一步操作,與通道注意力部分相似,首先同樣需要經過MaxPooling和AveragePooling,將結果進行concat連接,再經過一個卷積層將特征圖降維為一個通道。最后同樣使用Sigmoid函數乘法加權相應特征,獲得最終的空間注意力特征。
空間注意力模型如圖2所示。
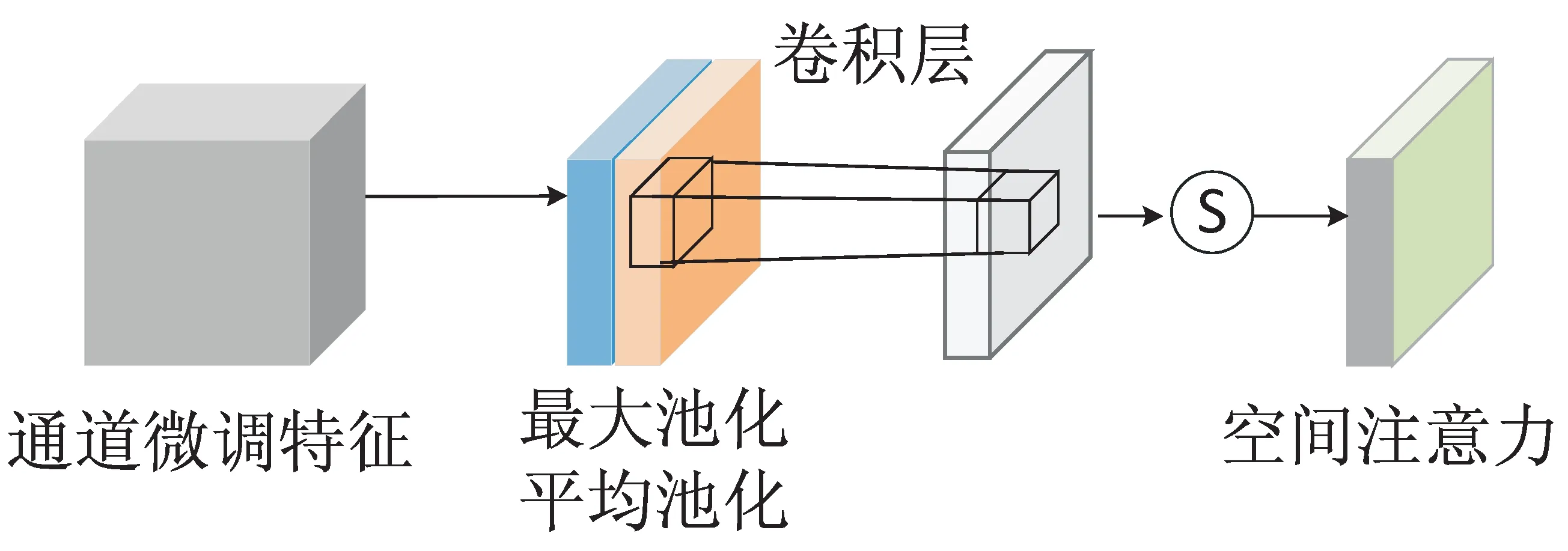
圖2 空間注意力模型
文中將CBAM注意力模塊插入YOLOv5模型backbone結構中最后一個C3模塊與SPPF模塊之間,結合CBAM后的模型如圖3所示。
圖3 YOLOv5+CBAM網絡結構
3 實驗與分析
針對目標檢測三個階段中的經典算法在水壩遙感目標檢測數據集上進行對比實驗,并選用其中精度最高的YOLOv5方法進行改進,結合CBAM注意力機制模塊進一步提高檢測精度。該文使用包含水壩目標的高分辨率遙感圖像目標檢測數據集DIOR,并對數據集進行預處理,提取需要的圖像,舍棄冗余圖像,最后對算法進行訓練和驗證,得到目標檢測模型。
3.1 數據集
現有的常用光學遙感目標檢測數據集中僅有DIOR[27]數據集含有水壩目標,該數據集使用LabelMe工具標注,共有23 463張圖像和190 288個實例,包含了20個目標類,每個類別包含約1 200張圖像,其中包含水壩目標的圖像987幅。DIOR數據集具有四個特征,圖像和實例數量規模較大,目標的尺寸變化范圍在不同空間分辨率以及物體類間和類內都較大。以水壩目標為例,在僅含有一個水壩目標的圖像中,水壩目標尺寸為大目標,但在含有其他目標的圖像中,如在含有高爾夫球場目標和水壩目標共存的圖像中,水壩相對來講是一個小目標,如圖4。對數據集中目標大小進行分析,散點圖分布如圖5,其中左圖表示數據集中所有目標標注框中心點的xy坐標,右圖表示標注框的高(height)和寬(width),越接近右上角說明目標越大,越接近左下角說明目標越小。

圖4 DIOR數據集水壩目標圖像示例
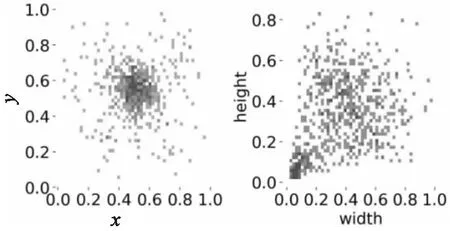
圖5 DIOR數據集水壩目標分布散點圖
3.2 數據預處理
DIOR數據集的標注格式為VOC格式,為了避免DIOR數據集中其他類別目標對水壩目標檢測精度的影響,需要將images文件夾中含有水壩標注信息的圖像篩選出來。
由于依舊存在部分圖像中含有多個類別的標注信息,需要對標注信息進行二次處理。刪除初篩集多類別標注圖像中除水壩類別外的其他類別標注,最終得到僅含有水壩類別標注的xml文件。
將數據集進行劃分,20%作為驗證集,80%作為訓練集,網絡的輸入層將圖像大小由800 px*800 px Resize為640 px*640 px并進行一系列縮放、翻轉等操作。
在將圖像輸入到網絡之前,需要對數據進行歸一化處理,使得數據經過處理后的限制區間為[0,1]。在對比實驗中,除了YOLOv5,其他方法在歸一化的基礎上進行了標準化,使得處理后的數據限制區間為[-1,1]。基于數據的均值和方差進行標準化,即在R、G、B三個維度減去均值并除以方差。在對比實驗中除YOLOv5方法外,其他幾種方法使用的均值在R、G、B上分別為0.485、0.456、0.406,方差分別為0.229、0.224、0.225。YOLOv5在文中只進行歸一化,不進行標準化。
3.3 設備及環境
CPU:Intel Core i7-11800H;
GPU: NVIDIA GeForce RTX3070;
語言:Python3.7;
深度學習框架:Pytorch1.11.0;
CUDA:11.3.0;
編譯器:Pycharm2021。
3.4 評價指標
單類別目標檢測中的評價指標主要為AP、AP50。目標檢測的精確率(Precision)是指一組圖像中模型檢測出真正例占所有目標的比例,召回率(Recall)表示所有真實目標中被模型檢測出的目標比例。根據精確率與召回率的值可以繪制PR曲線,AP即為PR曲線下的面積值,可以用積分計算,如公式(6),其中p表示PR曲線中作為縱坐標的精確率值,R表示作為橫坐標的召回率值。對目標檢測模型性能的評估通常需要與IoU閾值聯系起來,而AP50表示的是IoU閾值為0.5時,AP的測量值。
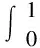
(6)
3.5 訓練和驗證
該文分別使用雙階段模型FasterR-CNN、單階段模型YOLOv5、EfficientNet以及AnchorFree模型CenterNet、FCOS進行訓練,并選擇AP50相對較高的YOLOv5模型進行改進實驗。
訓練設置batchsize為8,epoch為300,學習率為0.01,YOLOv5模型使用Backbone為DarkNet53,FasterR-CNN、FCOS和CenterNet使用ResNet50作為Backbone,EfficientNet使用RetinaNet作為Backbone。對比實驗結果如表1。
在YOLOv5的基礎上結合CBAM注意力機制對水壩單目標進行訓練,訓練設置同上。結果表明添加CBAM注意力機制模塊可以提高對水壩目標的檢測精度。YOLOv5和YOLOv5-CBAM的PR曲線對比如圖6所示,結合CBAM訓練得到的best.pt最佳模型在驗證集中的AP50可以達到86.4%,未結合CBAM的模型AP50為83.2%。
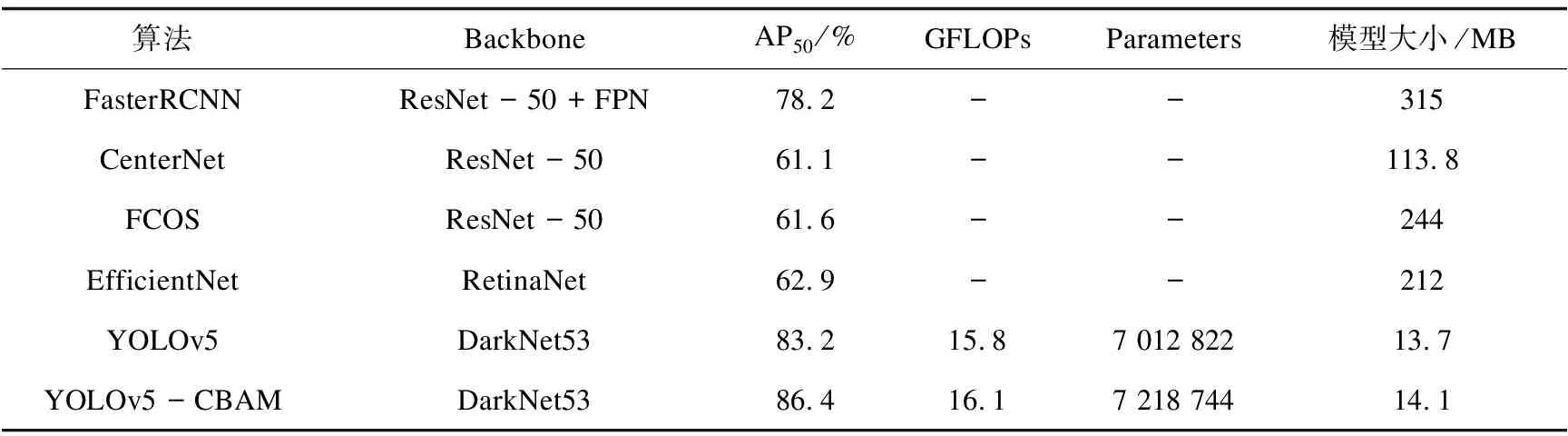
表1 水壩目標檢測算法實驗結果對比
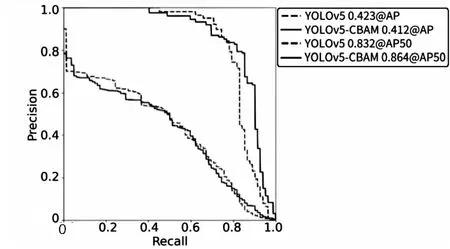
圖6 PR曲線對比
在驗證過程中發現,有部分圖像產生漏檢情況如圖7左,與其他圖像相比水壩在圖中目標較小,在下一步的改進中考慮提高算法對小目標的檢測能力。圖7右中產生了誤檢情況,檢測器將與水壩特征相似的湖泊邊沿誤檢為水壩進行了標記,說明未來算法改進應考慮到與水壩具有相似特征的目標影響,如橋梁等。

圖7 漏檢和誤檢情況
3.6 測 試
測試集為根據全球水壩地理位置信息數據集GOODD在谷歌地圖中靶向搜索國內水壩圖像并進行標注,共100張,將上述訓練得到的模型應用于測試集中,測試結果如圖8所示,其中上為標簽,下為檢測結果。


圖8 YOLOv5-CBAM檢測結果
4 結束語
該文主要針對光學遙感圖像中的水壩目標進行檢測,在單階段目標檢測模型YOLOv5的基礎上在Backbone階段引入了CBAM注意力模型,該方法結合了通道注意力和空間注意力,增強模型對水壩目標的關注進而提高對水壩目標的檢測精度。在驗證集上,可以將YOLOv5的AP50從83.2%提升至86.4%,有針對性地單獨訓練水壩目標可以降低誤檢率。后續可以根據此模型建立水壩目標檢測系統,擴展該模型在遙感圖像目標檢測范圍內的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
