基于雙向特征融合的露天礦區道路障礙檢測
2023-05-22 03:52:56阮順領李少博顧清華
煤炭學報 2023年3期
阮順領,李少博,顧清華,江 松,毛 晶
(1.西安建筑科技大學 資源工程學院,陜西 西安 710055;2.西安建筑科技大學 西安市智慧工業感知計算與決策重點實驗室,陜西 西安 710055;3.西安優邁智慧礦山研究院有限公司,陜西 西安 710055)
露天礦區無人駕駛逐漸成熟并落地,環境感知作為礦卡車實現無人化的關鍵環節之一,對于露天礦無人駕駛的實現有著重要意義。然而露天礦區非結構化道路相較于城市結構化道路,除了常規的車輛、行人等行車障礙,還存在著一些難以檢測的困難樣本,如坑洼、尖銳碎石等,容易造成陷車或輪胎夾石。同時露天礦區環境復雜惡劣,這對障礙檢測算法可靠性提出了更高的要求,因此亟待對露天礦區道路障礙的高效、可靠檢測方法進行研究。
基于機器視覺的無人駕駛車輛障礙檢測可以分為傳統的圖像處理方法和深度學習方法。基于二維圖像處理的障礙檢測算法通常分為以下步驟:①
圖像增強,如直方圖均衡化法、同態濾波法,暗通道去霧算法等;②
圖像邊緣檢測,如張金波[1]針對灰度圖像邊緣檢測的特點,提出的快速邊緣檢測算法,FERNANDO等[2]提出的基于強度函數的數字圖像邊緣檢測方法;③
圖像分割,如聚類算法[3]、閾值分割算法[4]等,同時針對特定應用場景,國內外學者提出了基于弱標注信息的語義分割方法[5]、交互式圖像分割方法[6]等。二維圖像處理技術容易受到各種不利因素的影響,尤其是在光照不足的非結構化道路,因此一些學者提出了立體視覺的障礙物檢測方法,如STANTANA等[7],ZHANG等[8]。
隨著深度學習的發展,PRABHAKAR[9],SANIL[10]等使用卷積神經網絡去解決無人駕駛車輛障礙檢測問題,獲得了更好的檢測精度和速度。基于深度學習的障礙檢測方法往往由以下3個結構組成:① 用于提取圖像特征信息的骨干網絡,如復雜骨干網絡VGG[11]、ResNet[12]、DenseNet[13]、EfficientNet[14],輕量型骨干網絡MobileNet[15]、ShuffleNet[16]、GhostNet[17]等;② 將不同尺寸特征圖進一步融合的特征金字塔模塊,如FPN[18]、PANet[19]、NAS-FPN[20]等;③ 對特征圖進行分類去預測的Head,如一階段算法的SSD[21]、YOLO[22]、RetinaNet[23]、FCOS[24],兩階段算法的Faster R-CNN[25]、R-FCN[26]、Mask R-CNN[27]等。針對非結構化道路障礙檢測,蔡舒平等[28]提出了基于改進YOLOv4的障礙物實時檢測方法,通過對模型進行輕量化改進并使用了逆殘差方法,使得模型擁有較好的自適應性和魯棒性。盧才武等[29]基于Mask R-CNN網絡,提出了融合目標檢測的露天礦行車障礙預警,達到了較好的檢測精確度和7.35 fps的檢測速度。然而其針對露天礦區障礙物檢測還不夠全面,雖然精度較高但缺少坑洞、尖銳碎石等困難樣本的檢測,同時檢測速度較慢難以滿足實時性要求。因此露天礦區道路障礙檢測模型需要在以下3個方面具備較好的能力:① 在光線和紋理復雜情況下,擁有高效的特征提取能力;② 對于坑洼等負向障礙,擁有良好的多尺度檢測性能;③ 對于行人和尖銳碎石等障礙,有著良好的小目標檢測性能。
鑒于以上分析,針對露天礦區復雜環境下道路障礙物多尺度和小目標特征,筆者提出一種基于深度學習的露天礦區道路障礙檢測模型。由于RepVGG網絡對復雜環境信息有著優良的特征提取能力和高效的推理速度,比較適合于露天礦區道路障礙的檢測,但同時該網絡使用大量3×3卷積導致其感受野較小,對小目標特征提取不充分[30],因此提出在特征提取階段采取優化的RepVGG+骨干網絡;并使用雙向特征融合金字塔模型進一步提升多尺度檢測性能;通過對損失函數和分類預測模塊進行優化進一步提升模型的檢測精度和速度,為復雜環境下露天礦區無人礦卡提供高效的障礙檢測方法。
1 露天礦區障礙檢測模型
露天礦區非結構化道路的背景信息復雜多變,各類障礙物尺寸跨度與特征差異較大,同時過于依賴自然光照條件。而在露天礦開采區道路多為臨時修建,道路信息經常變換,這導致了露天礦區障礙檢測具有挑戰性,如圖1所示。

圖1 露天礦區障礙物及其特征Fig.1 Obstacles and their characteristics in open pit mines
RetinaNet[23]作為一階段檢測法,具有良好的實時性和檢測精度,其網絡結構如圖2所示。
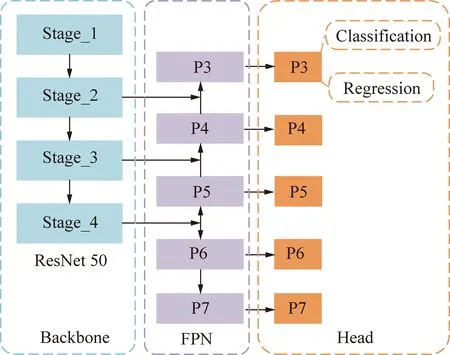
圖2 RetinaNet網絡結構Fig.2 RetinaNet structure
RetinaNet使用了ResNet50作為特征提取網絡,在FPN中P3、P4、P5使用ResNet50的Stage_2、Stage_3、Stage_4的輸出進行1×1卷積后歸一為通道數256的特征;P6是經過Stage_4的輸出進行步長為2的3×3卷積而來;P7則是通過對P6使用ReLU激活函數后再進行步長為2的3×3卷積,用來增強大目標的檢測。在網絡的預測分類的Head中,P3~P7每層的先驗框面積從322~5122像素依次遞增,先驗框的長寬比為[1∶2,1∶1,2∶1],size為[20,21/3,22/3],這樣每層的先驗框數量為9。雖然先驗框可以代表一定的框的位置信息與框的大小信息,但是其是有限的,無法表示任意情況,因此RetinaNet利用4次256通道的3×3卷積+ReLU和分類器的卷積結果對先驗框進行調整。
由于RetinaNet用了5個不同尺寸的特征進行分類回歸操作,使得網絡各個anchor之間過渡更加平滑,提升網絡的多尺度檢測性能。當RetinaNet的輸入分辨率為600×600時,在分類預測層中最大特征尺寸僅為75×75,使得露天礦區的小目標檢測性能較差,同時多尺度檢測性能和檢測速度有待進一步提升。
基于上述討論,為了解決露天礦區障礙物中小目標和多尺度問題,在特征提取階段,提出了更加高效的RepVGG+作為骨干特征提取網絡;在特征融合階段,使用基于SimAM空間與通道注意力和跨階段連接的雙向融合特征金字塔(Bidirectional Feature Pyramid Network,B-FPN);在分類預測階段,對Head結構進行進一步優化,降低特征冗余,并提高檢測性能,其結構如圖3所示。
1.1 骨干特征提取網絡優化
露天礦區障礙檢測需滿足無人礦卡環境感知的實時性需求,因此采用了RepVGG[30]作為骨干特征提取網絡,保證模型的檢測速度與精度。
RepVGG的網絡結構類似于ResNet,在VGG網絡的基礎上使用殘差結構去解決深層網絡的梯度消失問題,同時大量使用1×1卷積和Identity殘差結構,使得網絡更加簡單高效。其訓練和推理階段的基本卷積結構如圖4所示。
RepVGG在模型推理階段首先將殘差塊中的卷積層和BN層進行融合,然后將具體不同卷積核的卷積均轉換為具有3×3大小的卷積核的卷積,最后合并殘差分支中的Conv3×3。將所有分支的權重W和偏置B疊加起來,獲得一個融合之后的Conv3×3網絡層。由于在模型推理階段僅僅由3×3卷積和Relu激活函數堆疊而來,拋棄了殘差結構,同時當前大多數推理引擎對于3×3卷積有著特定的加速,相較于ResNet骨干網絡,更加易于模型推理和加速。
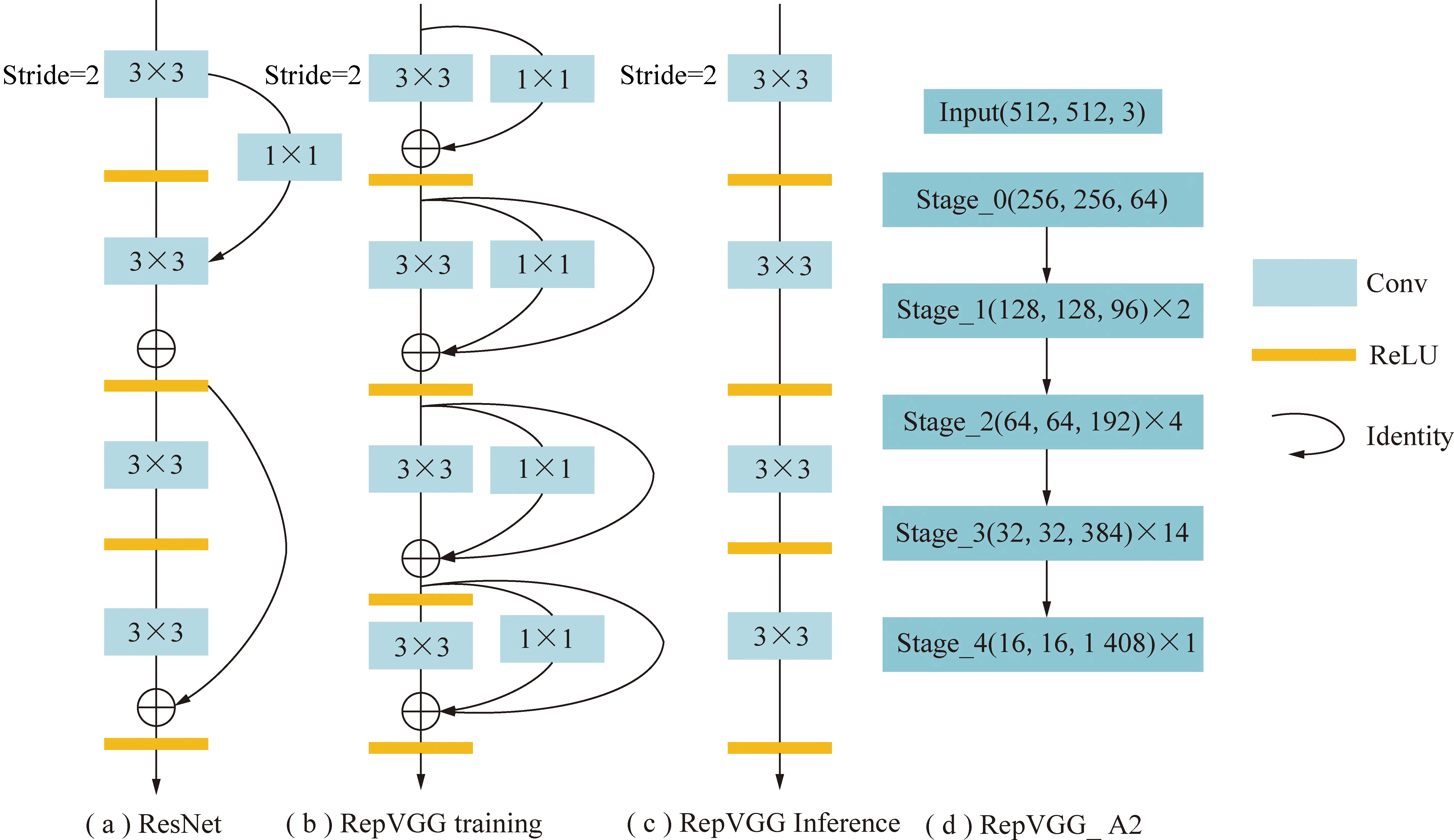
圖4 RepVGG+結構Fig.4 RepVGG+ structure
雖然RepVGG在圖片分類任務中取得了優異的性能,但其在目標檢測任務中還有待優化。如圖4(d)所示,RepVGG_A2的Stage4中只進行了一次基本卷積操作,并使用了1 408個通道,更大的通道數對于多分類任務會獲得更好的性能。但是將RepVGG應用于目標檢測時,由于其Stage4的特征卷積次數過少,使得16×16尺寸的特征,難以得到更加高層的特征信息。因此,本文提出了更加適應于目標檢測任務的RepVGG+(圖3),對Stage4模塊進行2次基本卷積操作,同時將Stage4的通道數調整為768,降低參數量,保證檢測精度與速度的平衡。使用大尺寸的卷積核可以擴大網絡感受野顯著提高網絡性能,但越大的卷積核其計算速度越慢,因此本文提出在Stage4中使用金字塔池化結構(Spatial Pyramid Pooling,SPP)[31],如圖3所示將RepVGG的Stage4_1特征層進行卷積降低通道數為384,然后進行13×13、9×9、5×5、1×1,4個不同尺度的最大池化操作,擴大感受野。將池化后的特征進行拼接,再次使用卷積批處理和激活操作使通道數還原為768。SPP通過使用大尺寸池化核增加神經網絡的感受野并分離出顯著的上下文特征,提升檢測性能。
1.2 基于通道與空間注意力的雙向特征融合模塊
露天礦區障礙檢測模型的多尺度和小目標檢測能力還有待進一步提升,提升小目標檢測常用的方法是擴大特征尺寸,使得網絡在分類預測時可以獲得更多特征信息。但是通過擴大輸入分辨率會增加網絡每一層的特征尺寸,進一步增加模型參數量并帶來極大的計算開銷。當輸入分辨率為512×512時骨干網絡的Stage1特征尺寸為128×128,包含了豐富的特征信息,因此本文將骨干特征網絡的Stage1的特征作為特征金字塔模塊P2層的輸入,并取消用于大目標檢測的P7層。但是Stage1特征信息具有較多的噪聲,在分類過程難以直接被解析。因此本文提出B-FPN結構,進一步優化網絡各層的特征信息使P2層使網絡可以獲得更加抽象高效的語義特征,同時提升多尺度檢測性能。其結構如圖5所示。

圖5 基于SimAM通道與空間注意力和跨階段連接的雙向特征融合模塊Fig.5 Bidirectional feature fusion module based on SimAM channels with spatial attention and cross-stage connectivity
將骨干網絡的Stage1、Stage2、Stage3、Stage4_2的特征圖進行1×1卷積獲得通道數為96的P2、P3、P4、P5層,同時對Stage2的輸出使用步長為2的3×3卷積獲得特征尺寸為8×8的P6層用于檢測大目標。在自下而上的融合過程中,P5層使用跨階段連接卷積(CSPnet)[32]后進行上采樣處理和SimAM注意力[33]進行特征增強,然后與P4的特征圖進行橫向連接,P3和P4層重復上述操作,使得每一層獲得了骨干網絡各層的特征信息,減少了P3層的噪聲信息。在P3層之后使用SSH[33]結構進一步擴大特征圖感受野,提升微小目標檢測能力。在自上而下的融合過程中,P3、P4、P5、P6層則與上一層下采樣之后的特征圖相加后進行CSP卷積處理,達到特征網絡雙向融合,增強多尺度檢測的目的。
網絡的基礎卷積模塊為卷積+批處理+LeakyReLU,相較于ReLU激活函數,LeakyReLU當x≤0時使用λ系數調節梯度,使得神經元在取負值時也有微小梯度,可以有效改善神經元死亡問題,2者的數學表達為
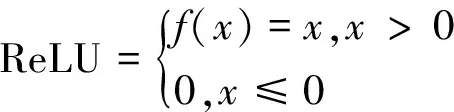
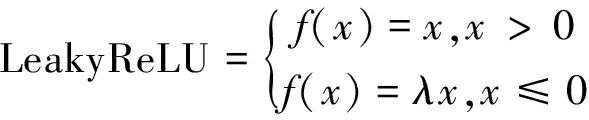
(1)
在特征融合模塊中使用跨階段連接結構(CSPNet)[32]提升不同特征層在橫向連接后的特征信息。CSPNet的結構如圖3所示,將輸入拆分為相同通道數的稠密分支與稀疏分支,稠密分支進行多次卷積后與系數分支進行拼接,還原輸入特征。CSPNet其原理是利用跨階段特征融合策略和截斷梯度流來增強不同層次特征的可變性,用于解決模型在訓練中由于梯度冗余,而導致的特征提取效率低下以及模型推理速度較慢問題。
上采樣的過程中,采用nearest插值方法會損失一定的局部特征圖信息,為此引入了SimAM空間與通道注意力機制[33],挖掘通道間各個神經元的重要特征。在計算機視覺中現有的注意力模塊集中在通道域或空間域,與人腦中基于特征的注意和基于空間的注意相對應。然而,在人類中,這2種機制共存,共同促進視覺處理過程中的信息選擇。SimAM為每個神經元定義了以下能量函數:
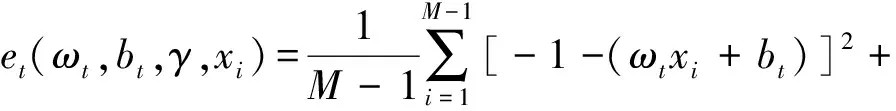
(2)
其中,t和xi分別為輸入特征X∈C×H×W的目標神經元和其他神經元;i為空間維度上的索引;M=H×W為在該通道上的神經元個數;ωt、bt為加權與偏置轉換。求解上述方程得到關于ωt和bt的快速封閉形式解:
(3)
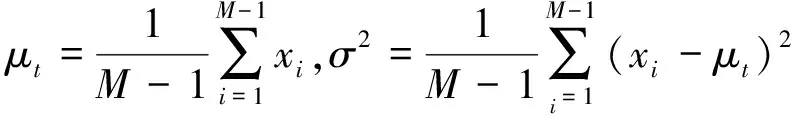
(4)
其中,
式(4)表示能量越低,神經元t與周圍神經元的區別越大,重要性越高。因此,神經元的重要性可以通過1/e*得到,最后使用sigmoid對特征進行增強處理:
(5)

為了進一步增強P2層特征,提升微小目標檢測性能。在P2層進行特征融合之后,使用SSH[34]模塊處理,其結構如圖6所示,通過引入5×5、7×7卷積核提高感受野,從而引入更多的上下文信息,同時為了減少大尺寸卷積核帶來的計算量提升,使用多個3×3卷積層進行拼接代替5×5、7×7卷積層。本文在3×3卷積模塊之后還加入了批處理層改善梯度消失問題,同時將激活函數由ReLU更換為LeakyReLU,優化模型結構如圖6所示。
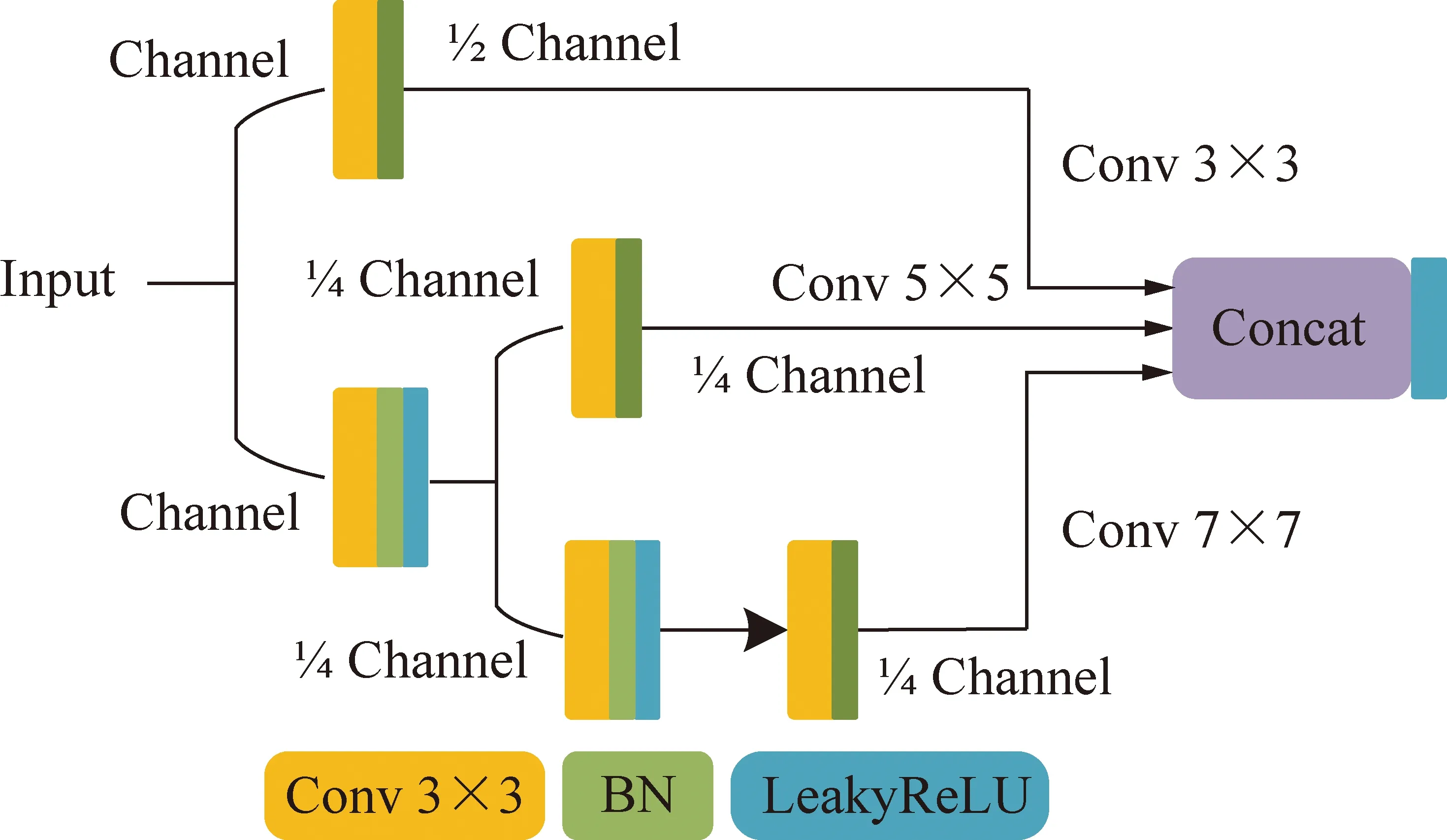
圖6 SSH模塊,使用多個3×3卷積層進行拼 接代替5×5、7×7卷積層增強感受野Fig.6 SSH module,using multiple 3×3 convolutional layers for stitching instead of 5×5 and 7×7 convolutional layers to enhance the perceptual field
1.3 分類與邊界框預測分支優化
露天礦區障礙檢測網絡的分類子網預測9個先驗框和K個類別在每個空間位置出現對象的概率,如圖7(a)所示,RetinaNet使用了4個3×3卷積層,每層都有256個過濾器,并在后面加入ReLU激活函數,最后使用帶有K×9個過濾器的3×3卷積層后,使用Sigmoid激活函數預測每個空間位置的二進制輸出。邊界框回歸分支與分類子網并行,將每個先驗框的偏移量還原到真實對象。其設計與分類分支相似,對于每個先驗框使用tx、ty、tw、th四個變量輸出預測其與真實框之間的相對偏移量(其中,tx、ty為先驗框的中心點坐標(x,y)的相對偏移量;tw、th為先驗框的寬高(w,h)的相對偏移量)。

圖7 分類與邊界框預測分支Fig.7 Classification and bounding box prediction branch
如圖7(b)所示,由于本文提出的模型在特征融合階段已經進行了高效的卷積,因此本文模型通道數和過濾器調整為96,并進行2次3×3卷積和與LeakyReLU激活,減少計算量和特征冗余。同時由于本文模型使用了更大的P2層的特征圖,刪除了P7層的特征圖,因此將P2~P6層先驗框的面積調整為162~2562,并針對露天礦區障礙物的特殊性將先驗框的長寬比重設為[0.7∶1.4,1∶1,1.4∶0.7]。
1.4 損失函數優化
露天礦區道路障礙檢測模型的損失函數包括分類損失和邊界框損失2部分。在分類損失函數方面,針對露天礦區的復雜背景易導致障礙圖像正負樣本比例失衡,RetinaNet提出了Focal loss[23]優化交叉熵損失函數優化正負樣本不均衡問題,其數學表達式為
(6)
式中,γ為調整難、易分類樣本之間的權重;α為調整正負、樣本之間的權重;p為模型分類后得到的概率。
為應對訓練過程中某些易樣本的過擬合,導致的難樣本置信度偏低引起的精度下降,本文在分類損失函數中引入了標簽平滑正則化(label smooth regularization)[35],通過減少易樣本真實樣本標簽的類別在計算損失函數時的權重,增加難樣本權重抑制過擬合。因此本文的分類損失函數為
(7)
式中,Csmooth為經標簽平滑處理后的類別數組;e為平滑因子,本文取e=0.01;δ為標簽的真實類別數組;δ0為與δ維度相同的全1數組;S為每層特征圖尺寸;Z為先驗框數量;本文取γ=2。
在邊界框損失方面RetinaNet采用Smooth L1 loss,其數學表達式為
(8)
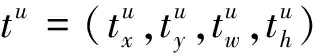
IoU可用來衡量2個邊界框的相似性,IoU的計算公式為
(9)
其中,A、B分別為預測框和真實框。由于目標檢測任務以IoU作為是否檢測到任務的判定標準,因此訓練時使用Smooth L1 loss作為位置回歸損失這2者并不等價,尤其當預測框與真實框的L1和L2范數相近時,與IoU差異過大。如圖8所示,當使用IoU作為損失函數時,當預測框與真實框沒有重合時,IoU無法衡量2者之間的差異,這導致損失函數梯度為0而無法優化網絡之間的權重。

注:紅色表示預測框,綠色表示真實框,黑色表示2者的最小閉合框。圖8 預測框與真實框的不同情況Fig.8 Different cases of prediction frame and real frame
GIoU[36]充分利用了IoU具有尺度不變性的優點,加入了預測框與真實框之間的最小閉合框作為損失計算參數,其數學表達式為
(10)
其中,C為包含2者的最小閉合框。如圖8(c)、(d)所示,黑色框范圍即為C的表示區域。GIoU克服了IoU在預測框與真實框不重合時的不足之處,能夠更好地反映預測框與真實框的重合情。因此本文模型的邊界框損失函數為
(11)
綜上所述,本文模型的損失函數為
(12)
2 露天礦區障礙數據集構建
本文中的數據采集于2019年2月到2021年4月間在大型露天礦開采現場,使用canon EOS 80d 數字相機采集,檢測目標包括大型運載卡車、行人、挖機、汽車、道路坑洞、道路積水和尖銳碎石7類。在不同季節與不同光照條件下,總共采集2 081張圖像數據。其中坑洞和積水作為負向障礙,位于路面下方且尺寸形狀各異,同時行人和尖銳碎石往往占據像素面積極少,這導致了本文數據集存在大量多尺度特征和小目標障礙。隨機選擇1 581張圖片作為訓練集,其余500張圖片作為測試集,圖像原分辨率是4 032×3 024,在輸入網絡時將圖像大小調整為512×512。
本文數據集的訓練集過少,難以使網絡達到很好的擬合狀態,因此通過數據擴增取進一步豐富數據集。通過對原始數據進行變換,進一步增加數據量、豐富數據多樣性、提高模型的泛化能力。在傳統擴增方法中,本文對圖片進行了90°、180°、270°旋轉、改變亮度、灰度化,使樣本擴增為原來的6倍。同時由于尖銳碎石在圖像中占據很少的像素比例,處于道路中間,與道路的背景信息差異較小,導致其檢測難度很大。而在本文數據集中尖銳碎石樣本較少,這導致了訓練樣本的不均衡,會進一步增加碎石的檢測難度。為此本文針對尖銳碎石較小,樣本量較少難以檢測的問題,使用了一種小目標增強方法,其具體流程為
(2) 將小目標(尖銳碎石)圖像進行縮放;
(3) 根據縮放生成邊界框標簽文件,由于小目標往往處于路面之中,同時本文采集的照片,道路信息大多存在于圖片下半部分,因此對小目標的邊界框位置進行過濾,刪除部分位置錯誤的標簽文件;
(4) 與原始標簽文件進行交并比計算,防止尖銳碎石圖片生成的位置與原始圖片中的目標重疊;
(5)將生成的小目標(尖銳碎石)圖像,使用泊松融合(Poisson blending)[37]方法與原始圖片相融合。泊松融合實質為求取梯度向量場引導下的影像插值,其數學表達如下:
定義二維圖像平面為S(S∈R2)上的閉合區域為Ω,其邊界為?Ω,V為定義在Ω上的梯度向量場,f為定義在S上的標量函數,已知f在?Ω上的取值為f*,則f在Ω內取V引導下的插值函數,即求解

(13)
其中,?f為f*的梯度,由于其求解構成泊松方程,因此可化為
護理本科生的社會價值體現,社會地位要求,薪酬待遇和職稱要求等,不是僅僅靠國家政策、學校改革、醫療體制改革等措施能夠充分滿足和不斷完善,更重要的是,護理本科生要提高自身素質,提高專業知識和護理技能水平,提高護理科研水平,促進護理事業健康、長足發展。這樣,護理本科生的社會價值自然會得到社會各界的認同,本科護生自身也會由內而外,提高對護理職業的認同感,從而熱愛護理事業,為護理事業的蓬勃發展貢獻力量。
Δf=divV,f|?Ω=f*|?Ω
(14)
式中,Δ為拉普拉斯算子;div為散度算子;f|?Ω=f*|?Ω為狄利克雷邊界條件。
對于圖像融合應用,式(13)的離散化形式為
(15)
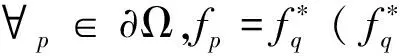
本文使用圖像旋轉擴增障礙物的多尺度特征,通過調整亮度和灰度化增強不同光照條件數據,使數據集擴增為原始數據集的6倍,同時針對尖銳碎石的樣本量偏少,使用了小目標增強算法,使其樣本數量增加到1 028個(表1)。
3 實驗與分析
3.1 實驗環境配置及評價指標
本實驗采用的計算機配置為Intel? CoreTMi7-7800X CPU,NVIDIA GeForce 3090 (24G) GPU,本實驗的網絡模型基于Pytorch 1.7,Python3.6,Cuda11.1框架搭建,實驗的各項參數集合見表2。
由于本文數據集較少導致模型難以擬合,因此訓練采用了遷移學習方式,骨干網絡RepVGG使用了Imagenet海量數據集訓練的權重,本文目標檢測模型作為下游任務,對骨干網絡權重進行裁剪,刪除不必要分類分支,并在VOC2007+2012數據集上進行預訓練,得到遷移學習的VOC數據集權重;然后基于VOC數據集權重,對權重的分類分支進行修改以契合本文類別數目,并采取分段式訓練方法,首先凍結骨干網絡權重進行凍結訓練,使網絡骨干在訓練初期只參與特征提取并不對權值進行更新,防止訓練初期網絡隨機性過大破壞初始權值;訓練20個Epoch后,解凍骨干網絡權重參與整個網絡訓練,并進行50個Epoch的訓練。

表1 數據增強前后樣本分布
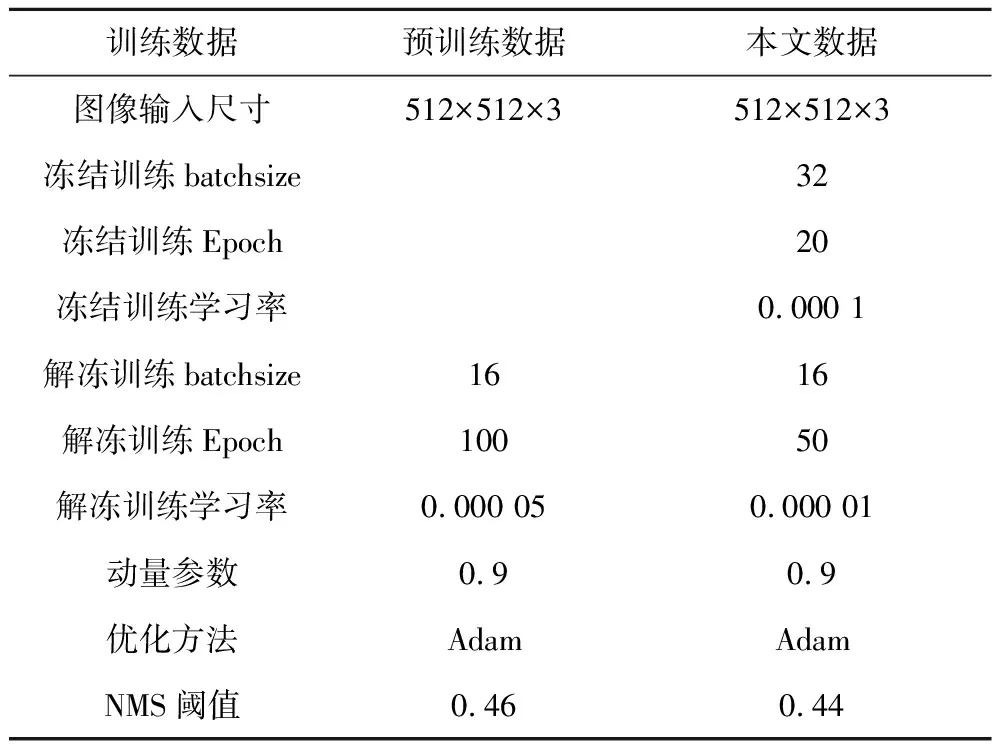
表2 實驗各項參數設置
實驗采用精確度(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,Pave)和平均精度均值(Mean Average Precision,Pmap)四個指標作為模型精度評價的標準:
式中,TP為正確檢測出的目標;FP為將背景錯誤檢測為目標;FN為未能檢測出的目標;n為目標檢測的類別;N為檢測到的障礙物數量;Pave為衡量模型對負障礙目標檢測的準確性;Pmap為所有Pave的平均值,用來衡量整個模型的檢測準確度。
在模型的推理速度和計算量方面采用了參數量(Pparams)和浮點運算數(Fflops),Fflops作為評價指標,Pparams和Fflops的計算方法為(以卷積層計算為例):
Pparams=KhKwCinCout+Cout,
式中,Kh、Kw為卷積核高度和寬度;Cin為輸入通道數;Cout為輸出通道數;H′、W′為輸出特征圖尺寸高度和寬度。
3.2 障礙檢測模型實驗與性能分析
如圖10所示,本文所提出的露天礦區障礙檢測模型在密集目標、光線不理想、復雜背景等情況下都有著良好的表現。在大尺寸物體的檢測上邊界框定位精準,物體置信度均高于0.9,在小目標的檢測中,對于行人和尖銳碎石的檢測性能較好,對于多尺度特征的負向障礙也能做到更加準確的檢測和精確定位,可以滿足露天礦區無人礦卡在封閉、低速環境下的安全駕駛需求。
如表3所示,本文模型與主流的目標檢測網絡進行了對比分析,所有訓練均使用遷移學習方式,由于網絡特性不同,SSD,Faster-RCNN,RetinaNet,本文模型均采用了VOC2007+2012作為預訓練數據集,YOLO4,YOLOX,EfficintDet使用了COCO2017數據集作為預訓練數據集。
本文模型達到了91.76%的Pmap取得了最好的檢測精度,檢測速度、參數量和Fflops分別達到了56.74 fps、28.2 MB和39.4 GB,有著最好的綜合性能。其中anchor free的代表網絡,YOLOX在面對多種任務時都有著良好的表現,取得了87.75%Pmap,anchor base的EfficintDet-d3也取得了88.01%Pmap,由于預訓練時YOLOX,EfficintDet-d3采用COCO數據集對于小微目標中的行人、汽車時有著良好的檢測效果,但是YOLOX,EfficintDet-d3在檢測碎石的Pave分別為59.70%、76.24%。

圖10 露天礦區障礙物檢測結果Fig.10 Obstacle detection results in open pit mine

表3 不同網絡模型對比
由于EfficintDet-d3的輸入分辨率為896×896,使得其小目標預測分支的特征圖尺寸為112×112,這使得它對于露天礦區障礙物數據集有著極好的精度,由于EfficintDet網絡使用了大量的深度可分離卷積降低參數量這導致其參數量和Fflops僅為11.9 MB、23.15 GB,但其輸入分辨率過大,網絡結構復雜導致推理速度較慢,難以滿足實時性要求。
傳統的網絡如SSD和Faster-RCNN的檢測精度均不理想,但是SSD取得了112.96 fps的檢測速度。而YOLO4由于輸入分辨率僅為416×416對于小微目標難以取得良好效果。
3.3 障礙檢測模型預訓練影響因素分析
如上文所述,本文提出的目標檢測模型作為分類骨干網絡的下游任務,使用ImageNet 1K大規模圖像分類數據集進行訓練的RepVGG權重,作為遷移學習的基礎權重。ImageNet 1K包含1 000個對象類,1 281 167個訓練圖像、50 000個驗證圖像和100 000個測試圖像。為了驗證遷移學習的必要性與骨干網絡的選擇,分別使用RepVGG、RepVGG+、ResNet三種骨干網絡在VOC2007和2012數據集上進行訓練,使用權重隨機初始化與載入預訓練權重進行對比。
如圖11所示,通過對比網絡是否使用ImageNet海量數據訓練的權重,可以看出網絡在loss收斂和每個epoch的Pap中都有著顯著的差異性,圖11(c)中,在不使用骨干權重時,網絡在60個epoch時漸漸趨于擬合,此時模型精度僅為60%左右。而使用了預訓練權重的網絡,在20個epoch時網絡已經逐漸趨于擬合,且精度為80%左右。在圖11(d)中RepVGG作為骨干網絡相較于ResNet有著近似的性能表現,可見使用了海量數據作為預訓練的權重,在實驗中,有助于加速模型的收斂,同時提升模型的精度。同時如圖11(d)所示,本文所提出的RepVGG+,相較于ResNet和原始結構,有著更加優異的性能表現。
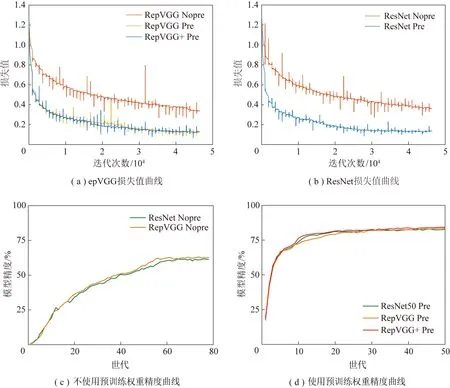
圖11 RepVGG_A2、RepVGG_A2+、ResNet50骨干網絡預訓練結果Fig.11 Pre-training results of RepVGG_A2,RepVGG_A2+,and ResNet50 backbone networks
3.4 障礙檢測模型有效性分析
3.4.1 RepVGG+網絡性能分析
為驗證提出的RepVGG+的有效性,針對露天礦區障礙檢測模型的骨干網絡消融實驗對比,并分別在預訓練的VOC數據集和本文數據集上進行測試。其結果見表4。
如表4所示,當本文按照常規的網絡設計,提取骨干網絡后3層作為FPN結構的輸入時,由于Res-Net50相較于RepVGG A2的參數量更多,在VOC數據集和本文數據集中都比RepVGG A2更加優異,但RepVGG由于在推理時使用了層間融合等方法,推理速度顯著優于ResNet50。RepVGG A0作為輕量型骨干網絡參數量僅有7.03 MB,但精度也較低,RepVGG B2由于其網絡更深,能夠提取到更多的特征信息,在預訓練中達到了82.45%Pmap,但是其參數量巨大,檢測速度較慢。本文針對RepVGG在目標檢測任務中的缺陷,所提出的RepVGG A2+結構,在擴增了Stage4的卷積層數并引入金字塔池化結構,使模型更加適應于小類別目標檢測。如表4所示,使用RepVGG+骨干網絡的模型在VOC數據集的精度超越了ResNet50,達到了81.94%的Pmap,同時增加了少許參數量,由于RepVGG作為輕量型骨干網絡,其特征提取能力還稍顯不足,在針對碎石等小目標時,難以獲取更加抽象的特征信息,去分離背景特征,導致在本文數據集中相較于ResNet50低了0.58%的Pmap。
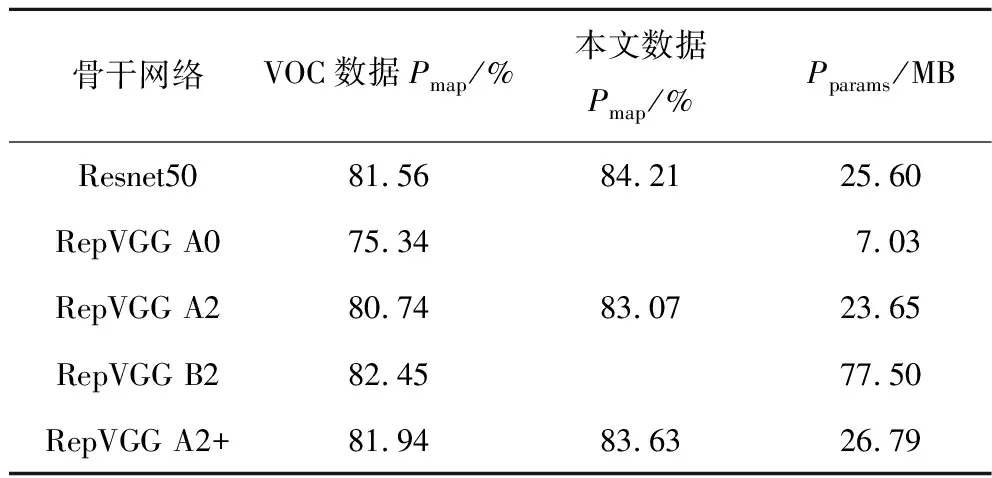
表4 不同骨干網絡對于模型性能影響
3.4.2 注意力機制影響分析
為了改善模型在上采樣過程中的特征信息丟失問題,在B-FPN中引入了SimAM注意力機制,見表5,相較于傳統的通道注意力SENet[38]和通道與空間注意力CBAM[39],SimAM在不增加參數量的基礎上有著更好的性能。

表5 不同注意力機制對模型性能影響
如圖12所示,筆者使用GradCAM++[40]方法對不同注意力機制進行了特征可視化。SENet基于通道維度對神經元進行增強,其效果并不顯著,而基于通道與空間的注意力機制CBAM和SimAM都能很好地增強神經元信息,從而改善特征丟失問題。
3.4.3 消融實驗與分析
為驗證針對小目標和多尺度目標提出的特征融合機制、分類預測模塊和改進Loss函數的有效性,設計了消融實驗,針對露天礦區道路障礙物數據不足問題進行了數據擴增,見表6,由于擴增前模型處于欠擬合狀態且訓練樣本極不均衡,通過數據集擴增后大幅提升了模型精度。對FPN模塊進行了重新設計,提出了基于通道和空間注意力的SimAM注意力和跨階段連接卷積的雙向特征融合的B-FPN結構,針對小微目標,在最大尺度的特征圖后加入了SSH卷積模塊,擴大感受野,進一步提升其檢測性能。如表6所示,提出的特征融合模塊在加入了SimAM注意力機制和SSH后檢測精度均得到了提升。同時由于雙向FPN結構已經提取到大量的特征信息,如果在模型的Head中還是使用連續的4次卷積+ReLU會導致特征冗余,因此將Head優化為連續2次3×3卷積+LeakyReLU,使用改進的骨干網絡+FPN+Head取得了更好的精度,在VOC數據集和本文數據集上分別達到了83.87%、86.35%的Pmap。

圖12 基于GradCAM++的不同注意力機制特征Fig.12 Characterization of different attention mechanisms based on GradCAM++
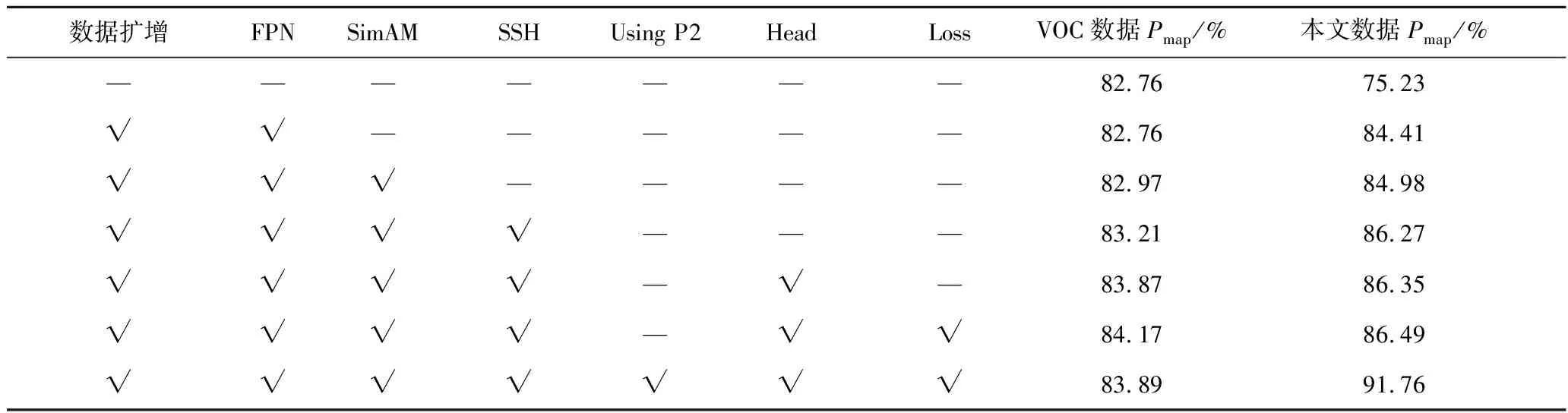
表6 消融實驗

圖13 Loss函數對模型檢測效果影響Fig.13 Effect of Loss function on model detection effect
如圖13(a)所示,在模型的實際驗證過程中,取置信度為0.05時,發現同一目標有著大量的重合框與定位不準確問題,因此本文在訓練過程中對Loss進行優化。
如圖13(b)所示,改進后的Loss函數很好的抑制了這一問題,同時表6也表明,在引入改進后Loss函數模型在2個數據集的精度達到了84.17%和86.49%的Pmap。
但是本文模型針對露天礦區障礙物中的碎石檢測仍然是個難點,在對網絡的骨干網絡、FPN、Head、Loss函數優化后,碎石的Pap只有63%,因此本文提取骨干網絡的4層輸出,進一步擴大網絡預測小目標分支的特征圖尺寸,使網絡預測最大特征圖從64×64,提升為128×128,極大地提升了小目標的預測能力,在本文數據集中達到了91.76%Pmap,其中尖銳碎石的Pap為85.38%。如表6所示,由于小尺寸特征圖主要作用與大尺寸抽象目標預測,導致了本文模型在VOC數據集上的精度為83.89%Pmap,相較于3個骨干網絡輸出層的模型減少了0.27%。
4 結 論
(1)針對露天礦區無人礦卡行進障礙檢測,提出了基于雙向融合機制的露天礦區障礙檢測模型,模型采用了改進的RepVGG A2+進行障礙特征提取,B-FPN對多尺度障礙特征進行雙向融合,增強不同尺寸特征圖的特征信息,對小微目標檢測分支額外使用SSH結構增強感受野,提升尖銳碎石等障礙信息表達能力。
(2)針對分類預測模塊進一步調整,刪除冗余信息提升模型檢測精度與速度。針對類別不均衡問題使用標簽正則化優化Fcoal Loss,使用GIoU Loss優化邊界框回歸Loss。
(3)實驗表明本文模型在多種情況下都有著良好的檢測性能,達到了91.76%Pmap和56.76 fps的檢測速度,滿足無人礦卡準確快速檢測需求,對比主流的目標檢測網絡也處于領先地位。
(4)通過實地采集與數據擴增建立了露天礦區障礙數據集,然而受限于采集數據的露天礦區較少以及規模較小,本研究仍有不足之處難以覆蓋不同路況的露天礦區。此外,如何利用大量數據缺失標注的圖像進行自動標注和對抗生成圖像,去擴增數據集也有待進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
