基于機器學習的多模型耦合徑流預報研究
2023-05-26 12:25:44祝賓皓張勇傳
中國農村水利水電 2023年5期
祝賓皓,,方 威,張勇傳
(1.華中科技大學土木與水利工程學院,湖北 武漢 430074;2.華中科技大學數字流域科學與技術湖北省重點實驗室,湖北 武漢 430074)
0 引 言
洪水預報作為一種有效的防洪非工程措施,在防洪減災緊急決策中發揮著不可替代的作用。洪水預報相關理論方法,經歷了由經驗模型到具有系統理論概念的黑箱模型,再到結合物理過程和經驗概化的概念性水文模型,最后到反映流域空間分異性的分布式水文模型的發展過程[1]。然而任何一類水文模型都是對水循環過程選擇性概化的近似描述,理論上無法精確還原真實水文過程。另外,在洪水預報中難以避免地存在降雨輸入、模型結構以及參數的不確定性問題,前述不確定性的存在必將導致洪水預報結果的不確定性,因此探索一種強魯棒性、高精度的洪水預報模式已成為亟待解決的問題。
自19世紀40年代起,眾多水文工作者已開展關于水文不確定性對洪水預報的影響研究,其中,考慮降雨輸入、參數不確定性影響的研究聚焦于對誤差概率分布特征的定量刻畫;考慮模型結構不確定性影響的研究聚焦于模型產匯流機理的改進以及預報模型優選策略、模型耦合預報等方面。KRZYSZTO‐FOWICZ[2]提出貝葉斯洪水預報理論,應用降雨不確定性處理機(Precipitation Uncertainty Processor, PUP)和水文不確定性處理機(Hydrologic Uncertainty Processor, HUP)分別處理降雨輸入不確定性和降雨以外的其他不確定性,從而明確洪水預報的總不確定性;KAVETSKI等[3]采用額外隱變量降低降雨輸入的不確定性,提出了貝葉斯總偏差分析(BayesianTotal Error Analy‐sis, BTEA)方法;AJAMI等[4]通過改用折算系數映射降雨輸入的不確定性,并結合貝葉斯模型平均(Bayesian Model Averag‐ing, BMA)方法考慮模型結構不確定性,提出了貝葉斯綜合不確定性估計方法(the Integrated Bayesian Uncertainty Estimator,IBUNE);謝小燕[5]將多元門限回歸模型和(Artificial Neural Net‐work, ANN)模型進行耦合預報,完成了小山水庫的中長期水文預報;馮鈞等[6]將(Back Propagation, BP)網絡和(Long Short-Term Memory, LSTM)模型在子午河流域進行耦合預報,發現預報結果優于任一單模型的預報結果;丁武等[7]采用極端梯度提升樹法(eXtreme Gradient Boosting, XGBoost)進行多元水文時間序列趨勢相似性挖掘,達到了預測水文趨勢的目的。
為降低模型結構不確定性對洪水預報帶來的負面影響,擬探明各水文模型的預報特征,采用多祌水文模型的不同耦合策略構建洪水耦合預報系統,以探尋研究流域產匯流機理的精細化表達,降低極端降水事件所帶來的影響。
1 多模型耦合方法
1.1 多模型耦合預報概述
水文預報是對未知水文情勢的預測,無論選用什么水文模型都會有預報誤差。但考慮到各個水文模型建模機制不同,在同一研究流域的預報表現也各不相同,擬綜合多個模型的預報特征對研究流域的徑流序列進行耦合預報。耦合預報定義如下:
式中:F為最終耦合預報徑流預測值;wi為各模型被分配的權重,可以是顯式的也可以是隱式的;fi是第i個水文模型預測值;h為水文模型個數。
1.2 單個預報模型的建立
為探明研究流域的產匯流機制,綜合考慮影響預報結果的各種可能因素,本研究選擇基于蓄滿產流理念的新安江模型[8]、適用性較強的水箱模型[9]以及基于變動產流面積原理的TOP‐MODEL模型[10],將3個模型的預測結果作為耦合模型的輸入,經各耦合方法確定模型權重后,可由式(1)確定耦合預報的徑流預測序列。由于(Particle Swarm Optimization, PSO)[11]算法已經廣泛應用于水文模型的參數率定中[12-14],故本研究各模型的參數以確定性系數(Determination Coefficient, DC)為目標函數,由PSO算法率定得到。確定性系數的計算如下所示:
式中:Q代表實測徑流序列,代表實測徑流序列的平均值代表預報徑流序列;n代表序列長度。
1.3 最小二乘法
最小二乘法是一種數學方法,它通過尋求最小誤差平方和的方式找到一組數據的最優函數形式,已經在參數估計、系統辨識以及預測等專業領域中得到廣泛的應用。周建中等[15]提供了最小二乘法在水文模型耦合預報中的應用細節。
1.4 嶺回歸法
由于前述最小二乘法在處理本文的耦合預報時容易出現結果不穩定的缺陷,故引入嶺回歸法[16]進行耦合預報。嶺回歸法是一種適用于多重共線性數據分析的有偏估計回歸方法,可視為改進的最小二乘法。該方法放棄最小二乘估計的無偏性,以損失部分信息、降低一定精度的代價獲得更符合現實的回歸系數[17]。本文的多模型耦合預報研究可歸類為多重共線性問題,采用嶺回歸法可以更有力的挖掘多模型預報的優勢,為研究流域的水文預報提供可靠保障。
1.5 極端梯度提升樹法
極端梯度提升樹,即XGBoost方法[18]在原始(Gradient Boosting Decision Tree, GBDT)模型的基礎上進行了改造,以二階泰勒展開方式代替GBDT模型中損失函數的一階泰勒展開方式,增加了模型的泛化能力和對多維度數據間復雜關聯的捕捉能力,該模型把正則化向的結構損失函數加入目標函數,以避免過擬合現象的發生,進一步提升了模型適用能力。本文將XGBoost算法應用于多模型耦合預報,有望精準捕捉各模型的預報特征并據此對該流域的徑流序列做出符合實際的預報方案。XGBoost方法的基本原理如下:
已知某樣本集
式中:xi為樣本輸入值;Xti、Yti、Zti分別為新安江模型、水箱模型和TOPMODEL模型在時刻i的預測值;n為徑流序列長度;yi是樣本輸入值xi對應的輸出值。
綜合Mulligan的研究,我們探討出許多問題。其一,對于Mulligan技術操作方便,效果顯著,但是機制不明確;其二,研究探討某種疾病或功能障礙時,無法給出明確納入標準,禁忌癥與適應證無明確的指南,只是通過疾病的適應癥與禁忌癥大體估量;其三,樣本量和局限性的問題仍不能解決。目前國內與國外的差距明顯。從研究內容上,國外Folk[47]的研究已經進展到手指關節,國內還沒有研究到小關節;從研究文獻的數量上,國外的研究也是領先于國內;從研究領域上,Kim[48]對腦卒中患者步態功能的恢復,應用動態松動術進行研究。
那么XGBoost模型的目標函數可以表示為:
式中:Fm代表模型在第m次迭代學習中的目標函數;式中第一項為損失函數項為第i個樣本在第m-1次迭代學習中的預測值,fm(xi)為第m輪迭代學習中新加入的樹基于輸入值xi和上一次迭代學習誤差做出的預測值;式中為正則化項,是對于模型復雜度的懲罰函數,T為葉子結點個數,ω為葉子權重向量,γ和λ為權重系數。
為使目標函數值最小,XGBoost方法需要評估所有葉子節點,挑選能使目標函數值最小的葉子節點進行分裂,評估函數如下:
最終葉子節點分裂完成且所有決策樹的添加也完成時,各模型預測結果與耦合預報結果的隱特征關系就存儲在XGBoost模型的結構中,再次調用訓練過的XGBoost模型就可計算耦合預報結果。
2 應用實例
2.1 研究區域概況及數據集構造
雅礱江流域位于青藏高原東側,四川西部,全長1 571 km,流域面積13.6萬km2,干流狹長,支流呈樹枝狀均勻分布于干流兩岸;河源至河口天然落差3 830 m,上游呈高山及高原景觀,徑流補給以冰雪為主,中下游為高原、高山峽谷河流,徑流補給以降水為主,地勢自西北向東南漸趨平緩;流域干濕季節明顯,暴雨一般出現在6-9月,呈連續性、大范圍、高強度的特點;全年徑流量豐沛穩定,且空間異質性明顯。
因雅江~吉居區間處于雅礱江流域中游和下游的分界處,徑流受融雪、降水、地形各因素的影響程度不明確,故本文將其作為研究區域。研究中耦合預報采用的數據集由3 h尺度的新安江模型、水箱模型、TOPMODEL模型徑流預報數據以及雅礱江流域雅江、吉居站點實測徑流序列構成。其中各模型徑流預報數據是本文基于雅礱江流域水電開發有限公司提供的雅江~吉居區間各氣象站點3 h尺度的降水、蒸發、徑流資料,以2005-2010年為率定期、2011-2013年為檢驗期,采用PSO算法確定模型參數后計算得到。研究流域圖及水文、氣象站點的空間分布信息見圖1。
圖1 研究區域氣象站、流量站分布圖Fig.1 Distribution diagram of meteorological stations and flow stations in the study area
2.2 模型性能評價指標
為了從多個角度全面、準確的評價本文采用的各種耦合預報方法,本文引入確定性系數DC、均方根誤差(Root Mean Square Error,RMSE)和平均絕對誤差(Mean Absolute Error,MAE)3個指標對模型的預報性能、預報穩定性進行評價。其中DC的計算由式(2)給出,RMSE和MAE的計算公式如下:
式中:Q代表實測徑流序列?代表預報徑流序列;n代表序列長度。
2.3 應用實例結果分析
3個獨立模型在3種耦合方法下的權重如表1、圖2所示。
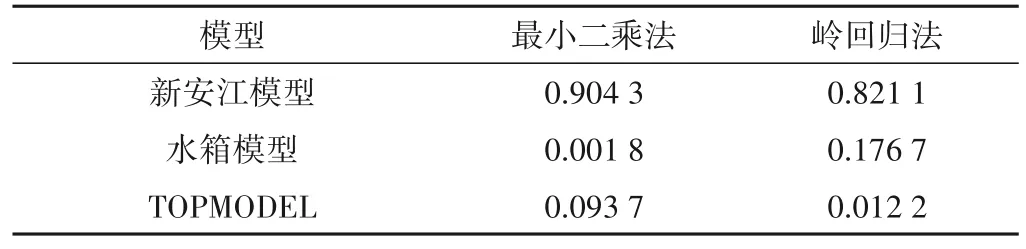
表1 各模型在兩種回歸方法中被賦予的權重Tab.1 The weights assigned to each model in two regression methods
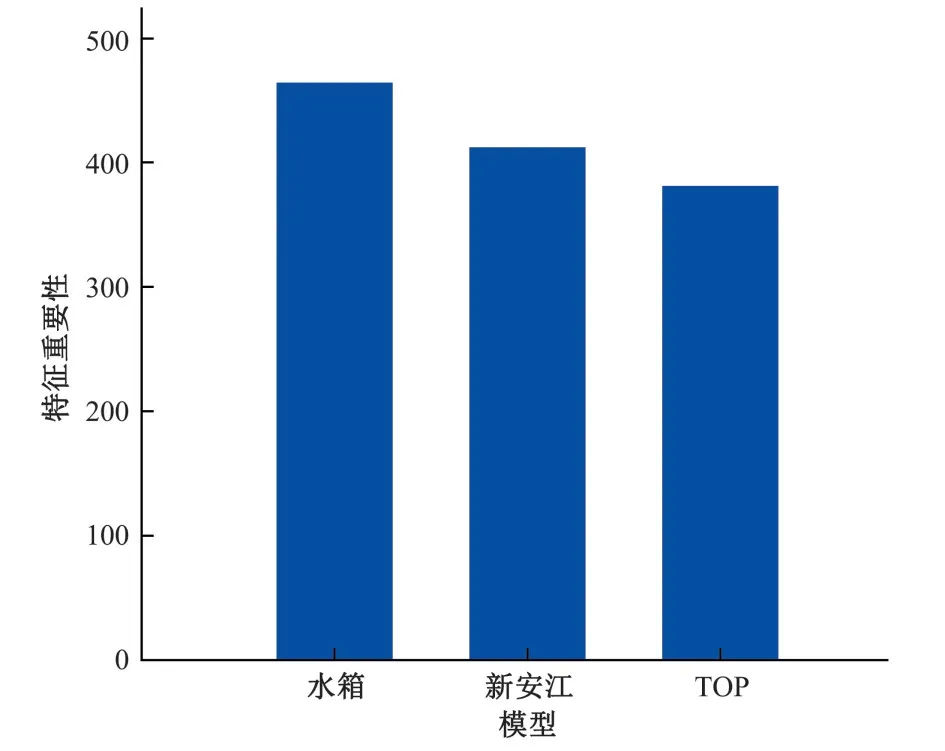
圖2 各獨立模型在XGBoost中的特征重要性Fig.2 Feature importance of each independent model in XGBoost
由表1可知,最小二乘法在賦予模型權重時,易受到模型間共線性的影響,從而賦予某個預報效果較好的模型過多的權重,這導致耦合預報失去了原本的意義;相較于最小二乘法,嶺回歸方法能提供一組更穩定、可解釋性更強的模型權重;但以上兩種回歸方法都是直接將權重與預測序列相乘之后得到最終預測序列,這與綜合考慮各模型預報特征進行耦合預報的初衷仍有出入。在XGBoost中,特征重要性是指節點分裂時該特征帶來信息增益(目標函數)優化的平均值,特征對信息增益影響程度的大小決定了重要性的大小,且由圖2可知各模型的預報特征在XGBoost的建模過程中得到了充分考慮,特征重要性并未出現過大的差距。結合圖2中各模型的特征重要性以及各模型的建模原理(新安江模型側重于蓄滿產流,即土壤類型;水箱模型側重于冰雪融水;TOPMODEL側重于地形條件),可以認為對研究流域產匯流特征影響最大的因素是冰雪融水,其次是土壤類型和地形特征,這也與雅江~吉居區間地處青藏高原的地理位置相符合。
3個水文模型的預測表現以及3種耦合預報方法的預測表現如表2所示(加粗指標對應的模型為該評價指標下的最優模型)。
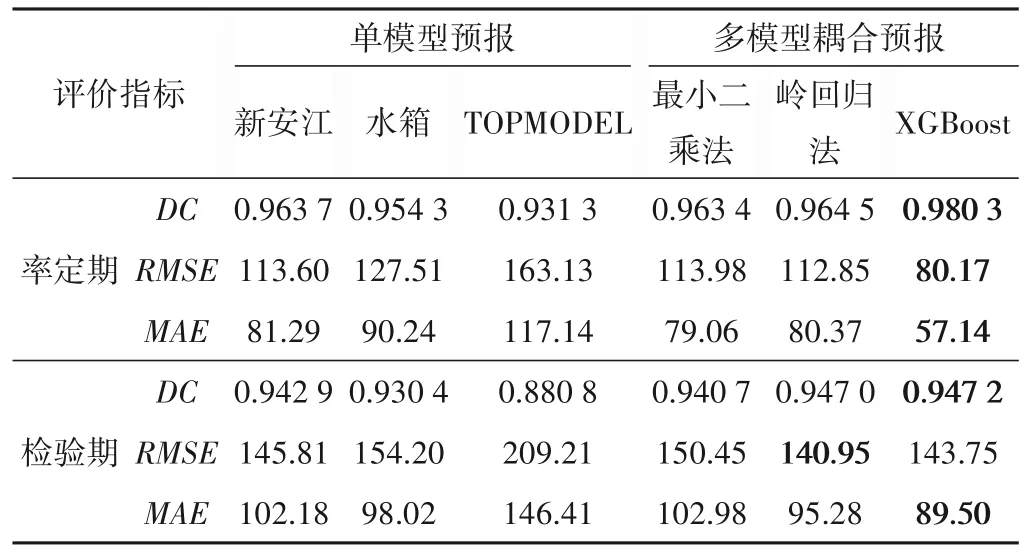
表2 模型輸出結果Tab.2 Performances of all models
由表2、圖3可知,獨立模型的預報中,不同評價指標下的最優單個水文模型也是不同的,例如新安江模型在確定性系數、均方根誤差這兩個指標上的表現比其余兩個水文模型好,但在檢驗期平均絕對誤差的表現上不如水箱模型。所以沒有任何一個水文模型能在所有評價指標上同時表現出最優。與此同時,在同一研究流域的不同預報階段,同一水文模型的表現也會出現差異性,例如新安江模型在洪峰階段的擬合效果較好,但在退水階段,新安江模型就失去了擬合優勢。這是因為天然水文過程自身具有極大的隨機性和非線性特征,而各模型都是在某個側重點上實現對水文過程的概化模擬,無法完全準確的模擬水文過程,所以單個模型的預測能力是有限的,目前不存在一個最優水文模型。
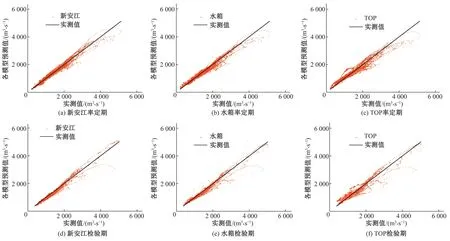
圖3 獨立模型預測結果Fig.3 Prediction results of independent model
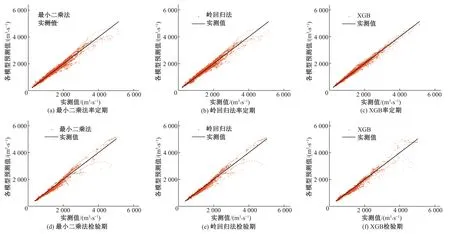
圖4 耦合模型預測結果Fig.4 Prediction results of coupled model
由表2、圖3、4可知,多模型耦合預報的預測表現普遍優于單模型預報,但基于最小二乘法的傳統耦合預報在處理此類多重共線性問題時,效果劣于最優獨立模型。針對此缺陷做出改進的嶺回歸法在預測表現以及適用性上都要強于最小二乘法,但在多數評價指標上的表現劣于XGBoost方法。多模型耦合預報中,在率定期的擬合效果方面,XGBoost方法相較于最小二乘法、嶺回歸法分別提升了1.69%、1.58%;在預測誤差方面,以RMSE為指標,XGBoost方法相較于最小二乘法、嶺回歸法分別降低了29.66%、28.96%;以MAE為指標,XGBoost方法相較于最小二乘法、嶺回歸法分別降低了27.72%、28.90%。檢驗期內,在擬合效果方面,XGBoost方法相較于最小二乘法、嶺回歸法分別提升了0.65%、0.02%;在預測誤差方面,以RMSE為指標,XGBoost方法相較于最小二乘法降低了4.45%、相較于嶺回歸法提升了1.99%;以MAE為指標,XGBoost方法相較于最小二乘法、嶺回歸法分別降低了13.09%、6.07%。
整體來看,3種耦合預報方法中,XGBoost方法預報效果最優、嶺回歸法次之、最小二乘法最差,且不同時期內XGBoost方法的預報效果未出現較大差異。充分證明XGBoost方法較其他方法能更深入地挖掘各模型在研究流域表現出的不同預報特征并據此進行耦合預報,同時展現出XGBoost方法良好的穩健性和強大的泛化能力。
3 結 論
以雅礱江流域雅江~吉居區間為研究對象,將新安江模型、水箱模型和TOPMODEL模型作為備選模型,采用最小二乘法、嶺回歸法和XGBoost模型進行多模型耦合徑流預報研究,經數據對比分析得出如下結論。
(1) 從預測精度上看,基于隱式特征挖掘的XGBoost模型預測表現要明顯優于服從線性假定的最小二乘法、嶺回歸法預測表現,將其應用于研究流域能更好的指導水庫防洪調度工作,增加社會效益。
(2) 從預測穩定性上看,不同時期內各方法的預報效果差距較小,均未出現過擬合現象,但XGBoost模型與嶺回歸法在應用上的泛化能力、合理性均強于傳統最小二乘法,有望在其余流域推廣使用。
(3) 本研究有尚待改進的地方,例如可以在單個水文模型的預報中加入洪峰識別功能,進一步增強洪峰部分的預報準確度;還可以在數據集中加入臨近數時段的預報誤差,預報時考慮實時誤差的影響,這些都將在以后的研究中逐步落實。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
