基于歷史行為與高低階特征的點(diǎn)擊率預(yù)估模型
2023-05-29 10:19:38王凱,沈艷
軟件導(dǎo)刊 2023年5期
王 凱,沈 艷
(成都信息工程大學(xué) 計(jì)算機(jī)學(xué)院,四川 成都 610025)
0 引言
推薦系統(tǒng)可在信息過(guò)載的情況下為用戶快速高效地推薦想要的信息。點(diǎn)擊率(Click Through Rate,CTR)預(yù)估是推薦系統(tǒng)的重要組成部分,其是基于用戶信息、物品信息和其他信息預(yù)測(cè)用戶對(duì)指定目標(biāo)物品產(chǎn)生點(diǎn)擊或不點(diǎn)擊的行為。通常情況下,CTR 預(yù)估模型基于傳統(tǒng)機(jī)器學(xué)習(xí)算法構(gòu)建,以邏輯回歸[1]和因子分解機(jī)(Factorization Machine,F(xiàn)M)[2]為代表,在數(shù)據(jù)稀疏和用戶冷啟動(dòng)的情況下,模型很難學(xué)習(xí)到有用的信息并作出預(yù)測(cè),極大地影響了預(yù)測(cè)準(zhǔn)確性,而且在面對(duì)非結(jié)構(gòu)化數(shù)據(jù),如圖像、視頻等時(shí)也不能從中提取特征信息。近年來(lái),深度學(xué)習(xí)技術(shù)廣泛應(yīng)用于各個(gè)行業(yè),作為廣告、搜索、推薦業(yè)務(wù)核心的 CTR 預(yù)估模型也借助深度學(xué)習(xí)技術(shù)獲得了質(zhì)的提升。
1 相關(guān)研究
CTR 預(yù)估模型要處理的特征信息包括用戶特征、待預(yù)測(cè)物品特征、上下文特征和用戶的歷史行為4 類特征數(shù)據(jù),這4 類特征的提取會(huì)極大地影響預(yù)測(cè)準(zhǔn)確性。與傳統(tǒng)機(jī)器學(xué)習(xí)模型相比,基于深度學(xué)習(xí)的CTR 預(yù)估模型可在數(shù)據(jù)稀疏的情況下挖掘出復(fù)雜的特征信息,并根據(jù)實(shí)際業(yè)務(wù)進(jìn)行結(jié)構(gòu)調(diào)整,從而更加符合現(xiàn)實(shí)推薦場(chǎng)景[3]。例如,文獻(xiàn)[4]提出的Deep Crossing 模型采用Embedding+MLP(Multilayer Perceptron)結(jié)構(gòu),使用多層神經(jīng)網(wǎng)絡(luò)對(duì)特征進(jìn)行深度交叉,加強(qiáng)了特征提取能力;文獻(xiàn)[5]提出Wide & Deep Learning 模型,其結(jié)合線性模型的記憶能力和 深度神經(jīng)網(wǎng)絡(luò)模型的泛化能力,提升了模型整體性能,并成功應(yīng)用至 Google Play 的APP 推薦業(yè)務(wù);文獻(xiàn)[6]分別提出Deep-FM 模型,結(jié)合了推薦系統(tǒng)的FM 和深度神經(jīng)網(wǎng)絡(luò)中的特征學(xué)習(xí)能力,相比于Wide&Deep Learning 模型,DeepFM 模型只需要原始特征,不需要特征工程;文獻(xiàn)[7]在DeepFM 的基礎(chǔ)上利用分層注意力機(jī)制處理來(lái)自不同層次的特征,在使用神經(jīng)網(wǎng)絡(luò)提取高階特征的同時(shí)提取低階特征模塊,然而并沒有引入用戶的歷史行為特征;文獻(xiàn)[8]使用注意力機(jī)制捕獲待預(yù)測(cè)的目標(biāo)物品與用戶歷史行為之間的聯(lián)系,文獻(xiàn)[9]則考慮到歷史行為背后的時(shí)序信息,使用門循環(huán)神經(jīng)網(wǎng)絡(luò)(Gated Recurrent Units,GRU)對(duì)用戶歷史行為進(jìn)行特征提取,但忽視了歷史行為內(nèi)部之間的聯(lián)系,從而造成歷史行為特征提取能力不足,同時(shí)也沒有考慮低階特征的構(gòu)建;文獻(xiàn)[10]首先使用自注意力機(jī)制處理歷史行為特征,在此基礎(chǔ)上采用卷積神經(jīng)網(wǎng)絡(luò)進(jìn)一步提取特征,雖然加強(qiáng)了高階特征提取能力,但沒有構(gòu)建低階特征;文獻(xiàn)[11]在DeepFM 的基礎(chǔ)上增加了一個(gè)高階顯示特征交叉模塊,以彌補(bǔ)FM 只能進(jìn)行二階特征組合的不足,但其沒有考慮不同特征對(duì)預(yù)測(cè)結(jié)果的影響,也忽略了用戶的歷史行為;文獻(xiàn)[12]提出AFM 模型,即在FM 模型的預(yù)測(cè)層與特征交叉層之間加入注意力網(wǎng)絡(luò),通過(guò)該網(wǎng)絡(luò)計(jì)算出每個(gè)特征的權(quán)重并利用Softmax 函數(shù)進(jìn)行加權(quán)求和得到最終特征向量;文獻(xiàn)[13]首次將Transformer[14]引入到推薦模型中,基于用戶歷史進(jìn)行推薦,但沒有提取其他特征;文獻(xiàn)[15]利用Transformer 提取用戶歷史行為特征,同時(shí)將其他特征與歷史行為特征進(jìn)行組合后預(yù)測(cè);文獻(xiàn)[16]在提取用戶歷史行為信息的基礎(chǔ)上將用戶特征、上下文特征等特征納入進(jìn)來(lái),并且使用注意力計(jì)算不同特征對(duì)預(yù)測(cè)結(jié)果的影響程度;文獻(xiàn)[17]將用戶序列分為長(zhǎng)期和短期行為,使用Transformer 提取長(zhǎng)短期行為特征,在最后一層融合兩種特征進(jìn)行預(yù)測(cè);文獻(xiàn)[18]認(rèn)為Transformer 的復(fù)雜結(jié)構(gòu)在推薦領(lǐng)域中會(huì)帶來(lái)過(guò)擬合的風(fēng)險(xiǎn),因此對(duì)Transformer 進(jìn)行改進(jìn),使用濾波算法代替Transformer 中的多頭注意力層,提升了序列推薦性能,但忽視了低階特征對(duì)預(yù)測(cè)的貢獻(xiàn)。
為克服現(xiàn)有模型對(duì)用戶歷史行為特征能力提取不足、忽視低階特征構(gòu)建、不同特征缺乏有效融合的問題,本文提出一種CTR 預(yù)估模型TDFA(TransDeepFM-Attention-Based)。該模型使用Transformer 網(wǎng)絡(luò)對(duì)歷史行為序列進(jìn)行特征提取,考慮到歷史行為中每個(gè)項(xiàng)目與預(yù)測(cè)目標(biāo)的關(guān)聯(lián)程度,使用注意力機(jī)制計(jì)算歷史中每個(gè)行為與預(yù)測(cè)目標(biāo)的相關(guān)性,并通過(guò)加權(quán)求和得到用戶的歷史行為特征;然后將用戶歷史行為特征與其他特征輸入多層神經(jīng)網(wǎng)絡(luò)獲取高階特征,同時(shí)采用FM 模塊獲取低階特征;最終在以上基礎(chǔ)上通過(guò)添加全局注意力層計(jì)算得到高、低階特征權(quán)重值,獲取CTR 預(yù)估值。TDFA 模型綜合考慮了用戶歷史行為和高低階特征信息,并且使用注意力機(jī)制有效融合高低階特征,提升了預(yù)測(cè)準(zhǔn)確性。
2 TDFA模型
2.1 CTR預(yù)估問題定義
CTR 預(yù)估模型的輸入數(shù)據(jù)可分為4 類,即用戶信息User_profile、待預(yù)測(cè)物品信息Item_info、上下文信息Context和用戶歷史行為序列User_history。用戶信息指人口屬性描述,如年齡、性別、職業(yè)等;物品信息包括id、類別等;上下文信息指環(huán)境特征,如時(shí)間、天氣、節(jié)日等;用戶歷史行為則是一個(gè)由物品信息構(gòu)成的序列。CTR 預(yù)估問題可定義為:
通過(guò)輸入4 類特征輸出預(yù)測(cè)值,并將物品的預(yù)測(cè)值排序后取top-k 個(gè)物品作為該用戶的推薦列表。
2.2 模型結(jié)構(gòu)
本文提出的TDFA 模型結(jié)構(gòu)如圖1 所示,分為5 層結(jié)構(gòu)。第一層為輸入層,第二層為嵌入層;第三層為特征提取層,該層分為高階特征部分和低階特征部分,其中高階特征部分包含Transformer 網(wǎng)絡(luò)、局部注意力層、拼接層和全連接層,低階特征為FM 模塊;兩部分得到的輸出在第4層全局注意力層結(jié)合后輸入到第5層的輸出層中進(jìn)行CTR預(yù)測(cè)。
2.2.1 輸入層
模型的輸入數(shù)據(jù)由用戶社會(huì)屬性、上下文信息、目標(biāo)物品信息和用戶歷史行為數(shù)據(jù)組成,這4 部分?jǐn)?shù)據(jù)又分為數(shù)值型數(shù)據(jù)和類別型數(shù)據(jù)兩類。采用one-hot 或multi-hot編碼將數(shù)據(jù)轉(zhuǎn)換為向量[18]。以用戶屬性數(shù)據(jù)為例,用戶屬性數(shù)據(jù)包含年齡、性別、職業(yè)等特征域,每個(gè)特征域用一個(gè)向量v*表示,則用戶特征可表示為:
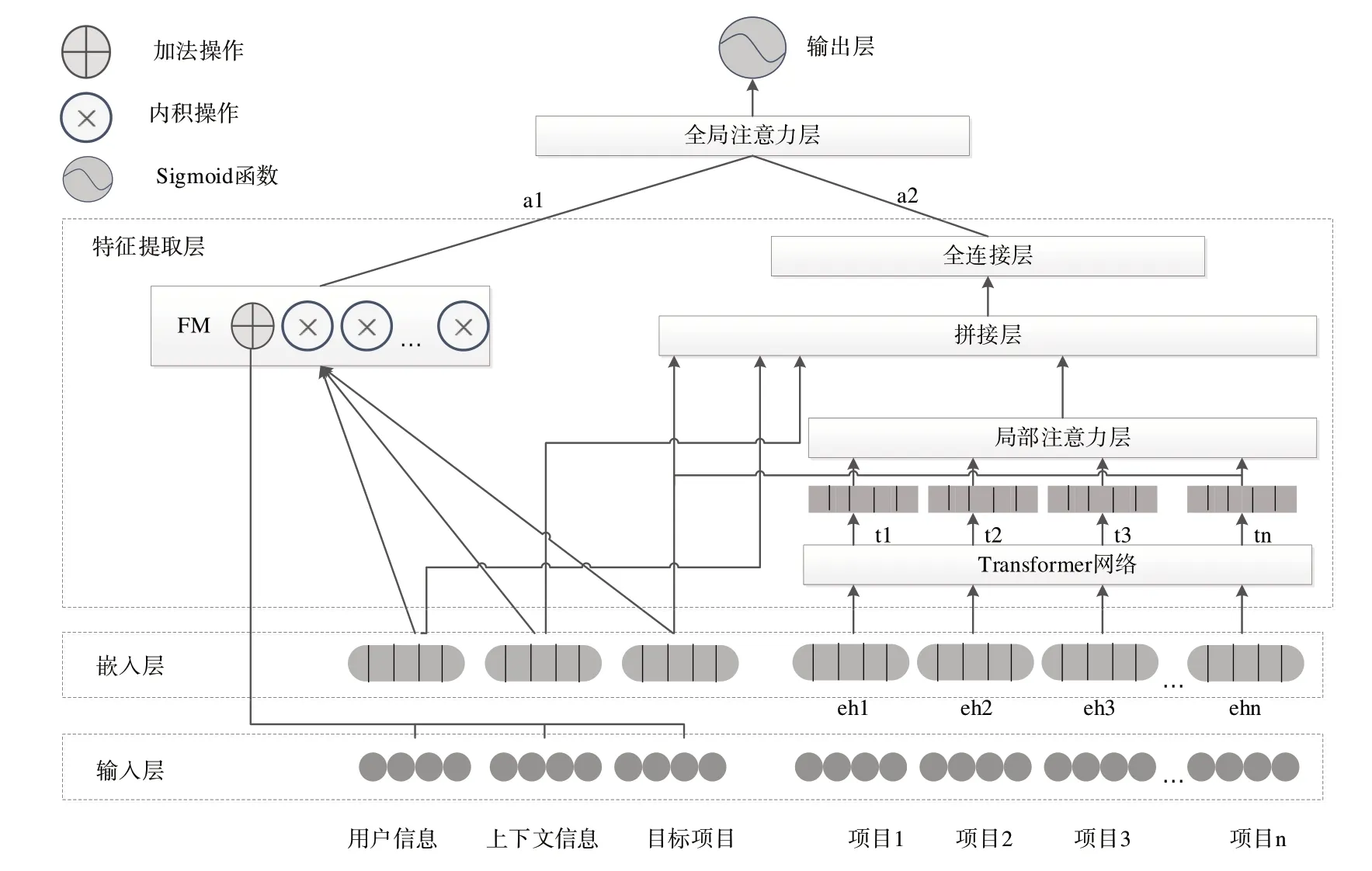
Fig.1 Overall structure of the TDFA model圖1 TDFA模型整體結(jié)構(gòu)
例如性別特征中男女為類別型數(shù)據(jù),采用one-hot 編碼將男編碼為[1,0]、女編碼為[0,1]。如果特征v*為數(shù)值型數(shù)據(jù),如年齡,則將其離散化處理成類別型數(shù)據(jù),然后轉(zhuǎn)換為one-hot 向量,在輸入層分別可以得到用戶特征向量Vuser,目標(biāo)物品向量Vtarget_item,上下文特征Vcontext和用戶歷史行為序列Vhistory_item=[vh1,vh2,vh3,…,vhn],其中vhn表示該用戶點(diǎn)擊(觀看、購(gòu)買等交互行為)過(guò)的物品向量。
2.2.2 嵌入層
One-hot 編碼的特點(diǎn)是向量長(zhǎng)度為該特征域下所有特征的數(shù)目。以特征域職業(yè)為例,如果職業(yè)分為老師、醫(yī)生、程序員、公務(wù)員和其他人員5 類,那么one-hot 向量即為五維,對(duì)應(yīng)特征位標(biāo)1,其余位置標(biāo)為0。因此,通過(guò)輸入層進(jìn)行one-hot 編碼處理得到的特征向量的主要問題是向量維度過(guò)大,特征數(shù)據(jù)高度稀疏,這將造成模型欠擬合。嵌入層的作用就是將高維稀疏的特征向量轉(zhuǎn)換為低維稠密的嵌入向量,其轉(zhuǎn)換規(guī)則為:
式中,v*為one-hot 或multi-one 向量,M*為嵌入層為該特征學(xué)習(xí)到的一個(gè)權(quán)重矩陣M*∈Rn×d。通過(guò)嵌入矩陣M*的轉(zhuǎn)換,n維向量v*轉(zhuǎn)換為d維的嵌入向量e*,d<<n。例如特征域下有老師、醫(yī)生、程序員3 類,嵌入向量維度為2維,假設(shè)特征為老師,one-hot 處理后得到[1,0,0],經(jīng)過(guò)嵌入層轉(zhuǎn)換為[0.3,0.7],如圖2所示。
因此,由輸入層得到的4 類特征Vuser、Vtarget_item、Vcontext、Vhistory_item經(jīng)過(guò)嵌入層后可表示為:
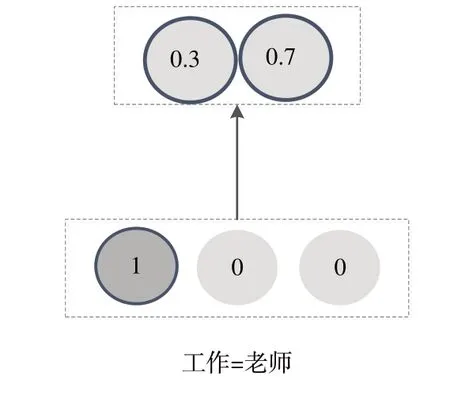
Fig.2 Example of embedding vector圖2 嵌入向量舉例
2.2.3 特征提取層
(1)Transformer 網(wǎng)絡(luò)。在CTR 預(yù)估領(lǐng)域中,用戶的興趣隱藏在該用戶的歷史行為中且用戶的歷史行為是一個(gè)時(shí)間序列,序列中的每個(gè)物品代表了該用戶的購(gòu)買或觀看行為。例如在電商網(wǎng)站的購(gòu)買行為中,某用戶購(gòu)買鍵盤后,那么該用戶接下來(lái)購(gòu)買鼠標(biāo)、內(nèi)存條的概率明顯大于購(gòu)買其他類型商品的概率,對(duì)這樣的序列信息進(jìn)行挖掘可以使模型學(xué)習(xí)到用戶從購(gòu)買某物品到購(gòu)買另一物品背后隱藏的動(dòng)機(jī),使系統(tǒng)推薦更加準(zhǔn)確。Transformer 網(wǎng)絡(luò)起源于機(jī)器翻譯領(lǐng)域,可以學(xué)習(xí)到單詞與單詞之間互相包含的聯(lián)系。將Transformer 引入推薦系統(tǒng),可以加強(qiáng)對(duì)用戶歷史行為特征的提取能力。本文中Transformer 網(wǎng)絡(luò)由位置編碼、多頭自注意力、殘差&層歸一化和一維卷積網(wǎng)絡(luò)(Conv1D)組成,結(jié)構(gòu)由圖3所示。
不同于循環(huán)神經(jīng)網(wǎng)絡(luò)的順序輸入,Transformer 是并行處理輸入信息的,這就導(dǎo)致Transformer 丟棄了序列中的順序信息,因此本文采用時(shí)間表示序列前后順序,將時(shí)間差分桶化后作為特征同樣轉(zhuǎn)換為Embedding 向量,拼接到用戶的歷史序列中,表示為:
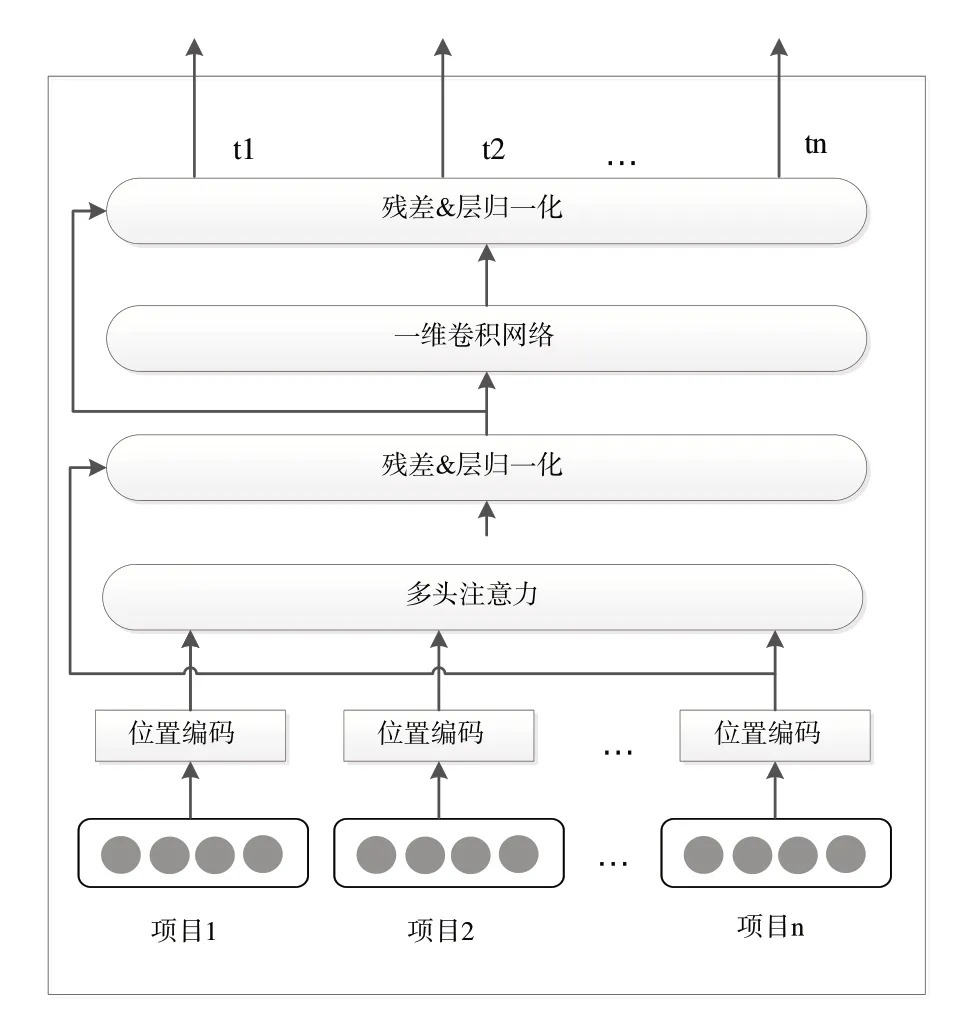
Fig.3 Transformer structure圖3 Transformer結(jié)構(gòu)
式中,eh表示物品向量,et表示時(shí)間向量,將eh與et拼接后得到帶有時(shí)間信息的向量eht。
注意力的計(jì)算公式為:
式中,Q表示查詢向量,K表示關(guān)鍵字向量,V表示值向量。Q、K、V的計(jì)算過(guò)程如下:將用戶歷史行為Eh通過(guò)線性投影得到對(duì)應(yīng)的權(quán)重矩陣WQ、WK、WV,則查詢向量Q=EhWQ,K=EhWK,V=EhWV。縮放因子d表示輸入向量的維度。
多頭注意力機(jī)制是將權(quán)重矩陣WQ、WK、WV按照頭數(shù)(head)分為x套,這樣對(duì)于Eh就有x套Q、K、V向量,每套參數(shù)各自進(jìn)行式(6)的注意力計(jì)算,共計(jì)算x次,最后將x次的計(jì)算結(jié)果進(jìn)行拼接。多頭注意力的計(jì)算公式為:
式中,(1≤i≤x)表示第套參數(shù),WO為可學(xué)習(xí)的參數(shù)矩陣。多頭注意層的輸出采用s表示。
層歸一化操作有利于穩(wěn)定和加速神經(jīng)網(wǎng)絡(luò);殘差網(wǎng)絡(luò)的核心思想是通過(guò)加入一個(gè)殘差連接將原始低階的特征輸入到高階,能保留原始序列特征。殘差和層歸一化表示為:
式中,正則化(Dropout)用于緩解神經(jīng)網(wǎng)絡(luò)過(guò)擬合問題。
多頭注意力網(wǎng)絡(luò)是對(duì)輸入特征數(shù)據(jù)進(jìn)行線性變換。為增強(qiáng)模型的非線性變換能力,將多頭注意力層的輸出送入兩層一維卷積網(wǎng)絡(luò)(Conv1D),同時(shí)添加殘差和層歸一化,公式為:
式中,W1、b1和W2、b2分別為兩層卷積網(wǎng)絡(luò)的權(quán)重系數(shù)和偏置項(xiàng)。
至此,用戶歷史行為序列Eh經(jīng)過(guò)Transformer 網(wǎng)絡(luò)后轉(zhuǎn)換為Fh=[t1,t2,t3,…,tn]。
(2)局部注意力層。在推薦場(chǎng)景中,并不是用戶歷史序列中的每個(gè)項(xiàng)目都與待推薦的項(xiàng)目有關(guān),注意力機(jī)制可以基于待推薦的目標(biāo)物品為歷史序列中的每個(gè)物品分配一個(gè)權(quán)重。通過(guò)一個(gè)全連接層計(jì)算出Fh每個(gè)歷史項(xiàng)目的初始權(quán)重,使用Softmax 函數(shù)進(jìn)行處理得到最終權(quán)重值,計(jì)算過(guò)程如圖4所示。
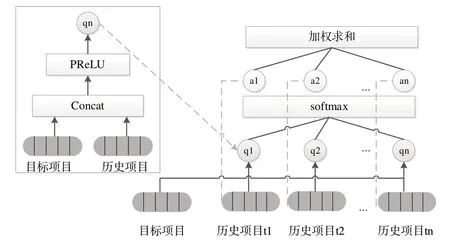
Fig.4 Final weight calculation process圖4 最終權(quán)重計(jì)算過(guò)程
首先將目標(biāo)項(xiàng)目與歷史序列Fh中的每個(gè)項(xiàng)目通過(guò)式(11)進(jìn)行拼接:
將式(11)的結(jié)果送入全連接層,使用PReLU 激活函數(shù)進(jìn)行處理,表示為:
式中,Wt和bt分別為權(quán)重系數(shù)和偏置項(xiàng)。然后使用Softmax 函數(shù)對(duì)式(12)結(jié)果進(jìn)行處理,表示為:
最后對(duì)用戶歷史序列進(jìn)行加權(quán)求和,得到最終用戶歷史特征向量H,表示為:
(3)拼接層。在該層中將用戶特征euser、目標(biāo)物品特征etarget_item、上下文特征econtext與經(jīng)過(guò)Transformer 和局部注意力層得到的用戶歷史特征H進(jìn)行拼接,表示為:
(4)全連接層。通過(guò)全連接層對(duì)特征向量中的各個(gè)維度進(jìn)行充分交叉組合,挖掘出更多非線性特征和復(fù)雜的交叉特征信息,使模型具有更強(qiáng)的表達(dá)能力。堆疊多個(gè)全連接層的計(jì)算公式為:
式中,yl為第l層的輸出,yl-1為第l-1 層的輸出,Wl為該層的全連接層權(quán)重系數(shù)矩陣,bl為該層的偏置向量。全連接層共k層,每層均使用PreLU 激活函數(shù),最終經(jīng)過(guò)全連接層的輸出表示為ydnn。
(5)FM。FM 用于解決二階特征交叉問題,本文模型包含一階線性特征部分和二階特征交叉部分,表示為:
具體來(lái)說(shuō),F(xiàn)M 為每個(gè)特征都學(xué)習(xí)到了一個(gè)隱向量v,在進(jìn)行特征交叉時(shí)使用兩個(gè)特征對(duì)應(yīng)的隱向量?jī)?nèi)積作為交叉特征的權(quán)重。DeepFM 模型中的FM 部分與deep 部分共享特征的嵌入層,即將式(17)中的vi·vj替換為對(duì)應(yīng)特征的嵌入向量點(diǎn)積ei·ej,表示為:
2.2.4 全局注意力層
目前已經(jīng)得到通過(guò)多個(gè)全連接層輸出的高階特征向量ydnn,以及通過(guò)FM 模塊得到的一階線性特征和二階交叉特征的組合特征向量yfm。Wide&Deep 和DeepFM 模型已經(jīng)證明了融合高低階特征可以提高模型的預(yù)測(cè)準(zhǔn)確度,但是DeepFM 模型同等看待兩個(gè)子模塊,而高階特征和低階特征對(duì)預(yù)測(cè)的影響程度是不同的。為此,本文添加注意力層為兩種特征賦予權(quán)重,以衡量在預(yù)測(cè)不同目標(biāo)物品時(shí)高低階特征影響的重要程度。將ydnn和yfm送入全連接層,使用tanh 激活函數(shù)計(jì)算出每個(gè)分量的注意力得分α1、α2,然后使用Softmax 函數(shù)進(jìn)行處理,最后將兩個(gè)輸入分量進(jìn)行加權(quán)融合得到全局特征Y,計(jì)算公式如下:
2.2.5 輸出層
Sigmoid 函數(shù)的值域在0~1 之間,與CTR 的物理意義相符合。全局特征Y仍然是特征向量,只使用一個(gè)神經(jīng)元。沒有激活函數(shù)的全連接層(Dense)將Y轉(zhuǎn)換為一個(gè)標(biāo)量Y'(見式(22)),然后輸入到Sigmoid 函數(shù)中,得到模型對(duì)于目標(biāo)物品預(yù)測(cè)的CTR(見式(23))。
2.3 模型訓(xùn)練的損失函數(shù)
損失函數(shù)表示真實(shí)值與預(yù)測(cè)值的差距,模型訓(xùn)練的目標(biāo)是最小化損失函數(shù)值。本文模型訓(xùn)練采用推薦系統(tǒng)和CTR 預(yù)估模型常用的對(duì)數(shù)似然函數(shù),表示為:
式中,y∈{0,1},表示真實(shí)標(biāo)簽值,在本次實(shí)驗(yàn)的訓(xùn)練樣本中,標(biāo)簽1 表示點(diǎn)擊,0 表示未點(diǎn)擊;y'∈(0,1),表示模型預(yù)測(cè)的CTR 值。
3 實(shí)驗(yàn)方法與結(jié)果分析
3.1 實(shí)驗(yàn)環(huán)境
本次實(shí)驗(yàn)編程語(yǔ)言使用Python3.8 和Tensorflow2.2 框架,在操作系統(tǒng)為Windows10、內(nèi)存16G、顯卡型號(hào)為GTX 1050Ti的計(jì)算機(jī)上進(jìn)行實(shí)驗(yàn)。
3.2 數(shù)據(jù)集和評(píng)估指標(biāo)
亞馬遜產(chǎn)品數(shù)據(jù)集包含亞馬遜各類商品數(shù)據(jù),有19萬(wàn)個(gè)用戶、6 萬(wàn)個(gè)商品、800 多個(gè)類別。選取該數(shù)據(jù)集下的電子數(shù)據(jù)子集,分為reviews_Electronics 和meta_Electronics兩個(gè)文件,其中reviews_Electronics 記錄了用戶的評(píng)價(jià)信息,包括評(píng)論者id、商品id、產(chǎn)品評(píng)級(jí)等信息,meta_Electronics 記錄了商品信息,包括商品id、類別等信息。用戶的所有行為都是有順序的,可以通過(guò)前k-1 個(gè)商品的點(diǎn)擊情況預(yù)測(cè)用戶是否會(huì)點(diǎn)擊第k個(gè)商品。在本次實(shí)驗(yàn)中,為了得到更多特征,對(duì)用戶的點(diǎn)擊時(shí)間進(jìn)行處理后得到月份、季節(jié)等上下文特征。Electronics 數(shù)據(jù)集只有用戶的點(diǎn)擊數(shù)據(jù),為引入負(fù)樣本,將某用戶點(diǎn)擊過(guò)的物品從全部物品集中剔除后,隨機(jī)選取與用戶點(diǎn)擊過(guò)的物品數(shù)量相等的物品作為負(fù)樣本,使數(shù)據(jù)集正負(fù)樣本比例達(dá)到1∶1。經(jīng)過(guò)處理之后得到239.48 萬(wàn)條訓(xùn)練集、41.91 萬(wàn)條驗(yàn)證集和17.96 萬(wàn)條測(cè)試集。
Movielens-1M 是一個(gè)廣泛應(yīng)用于推薦模型訓(xùn)練的數(shù)據(jù)集,包含6 040 個(gè)用戶對(duì)3 883 部電影共100 萬(wàn)條評(píng)分記錄,評(píng)分范圍為1~5。為適應(yīng)CTR 預(yù)估問題,將4 分及以上劃分為正樣本,4 分以下劃為負(fù)樣本。與Electronics 數(shù)據(jù)集一樣,將前k-1 個(gè)觀影記錄作為歷史序列,用于預(yù)測(cè)第k個(gè)電影的CTR。處理之后得到69.59 萬(wàn)條訓(xùn)練數(shù)、20.88 萬(wàn)條驗(yàn)證數(shù)據(jù)和8.95萬(wàn)條測(cè)試數(shù)據(jù)。
淘寶用戶行為數(shù)據(jù)集是阿里巴巴提供的一個(gè)淘寶用戶行為數(shù)據(jù)集,包含2017 年11 月25 日-12 月3 日有行為的約100萬(wàn)隨機(jī)用戶的所有行為,包括點(diǎn)擊、購(gòu)買、加購(gòu)、喜歡,本實(shí)驗(yàn)僅使用點(diǎn)擊行為。受計(jì)算資源限制,本文僅選取id前10萬(wàn)用戶的點(diǎn)擊記錄。經(jīng)過(guò)處理后得到1 227.74萬(wàn)條訓(xùn)練數(shù)據(jù)、368.3萬(wàn)條驗(yàn)證數(shù)據(jù)和157.85萬(wàn)條測(cè)試數(shù)據(jù)。
數(shù)據(jù)集總體統(tǒng)計(jì)信息如表1所示。
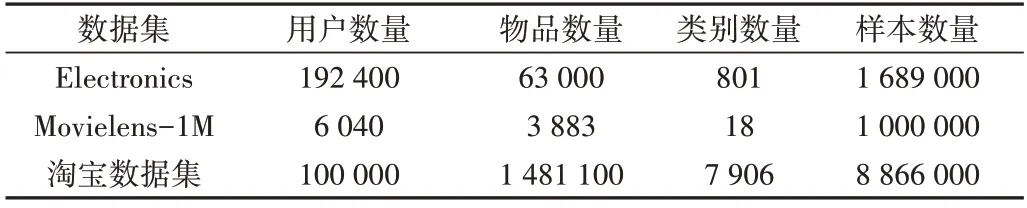
Table 1 Dataset overall statistics information表 1 數(shù)據(jù)集總體統(tǒng)計(jì)信息
使用AUC(Area Under Roc Curve)[19]和LogLoss(交叉熵?fù)p失)[20]兩個(gè)指標(biāo)評(píng)估模型性能,其中AUC 為CTR 預(yù)估模型的常用評(píng)價(jià)指標(biāo),其值為處于ROC 曲線(Receiver Operating Characteristic Curve)下方面積的大小,AUC 值越大表示模型性能越佳;LogLoss 表示真實(shí)值與預(yù)測(cè)值之間的差距,其值越小表示模型預(yù)測(cè)性能越佳。
3.3 參數(shù)設(shè)置
TDFA 模型參數(shù)如表2 所示,其中dim 表示Embedding向量維度大小,在{16,32,64,128}中選擇;seq_len 表示用戶歷史序列長(zhǎng)度,超過(guò)此長(zhǎng)度截取,不足時(shí)添加0 來(lái)補(bǔ)充,在{20,50,100}中選擇;lr 為學(xué)習(xí)率,dropout 為丟棄率,mlp_shape 為全連接層的層數(shù)和每層包含的神經(jīng)元個(gè)數(shù);Transformer 中的head_num 和blocks 分別表示多頭注意力的頭數(shù)和Transformer 堆疊的次數(shù)。為防止過(guò)擬合,采用L2正則化。在3 種數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)時(shí)采用統(tǒng)一參數(shù)設(shè)置。

Table 2 Experimental parameter settings of TDFA model表 2 TDFA模型實(shí)驗(yàn)參數(shù)設(shè)置
3.4 實(shí)驗(yàn)結(jié)果與分析
為了評(píng)估TDFA 模型的性能,采用DNN[4]、DeepFM[6]、DIN[8]、DIEN[9]、MIAN[16]模型與之進(jìn)行比較。同時(shí),為了驗(yàn)證Transformer 在序列建模中的優(yōu)越性,設(shè)計(jì)與傳統(tǒng)序列網(wǎng)絡(luò)循環(huán)神經(jīng)網(wǎng)絡(luò)RNN、長(zhǎng)短期記憶人工神經(jīng)網(wǎng)絡(luò)LSTM、GRU 的比較實(shí)驗(yàn),即采用RNN 替換Transformer 部分并將模型命名為RDFA,采用LSTM 替換Transformer 命名為L(zhǎng)DFA,采用GRU 替換Transformer 命名為GDFA。實(shí)驗(yàn)結(jié)果見表3—表5 所示。可以看出,TDFA 模型在3 個(gè)數(shù)據(jù)集上的AUC 和Logloss 指標(biāo)均優(yōu)于其他模型。在Electronics 數(shù)據(jù)集上,與DeepFM、DIN、DIEN、MIAN 模型相比,TDFA 模型的AUC 平均提升了1.16%,Logloss 平均降低了5.4%;在Movielens-1M 數(shù)據(jù)集上,TDFA 模型的AUC 平均提升了1.51%,Logloss 平均降低了3.51%;在淘寶數(shù)據(jù)集上,TDFA模型的AUC 平均提升了1.10%,Logloss 平均降低了3.73%。此外,使用RNN、GRU 和LSTM 代替Transformer 時(shí),模型性能下降明顯,證明了Transformer 在序列行為上強(qiáng)大的表征能力,優(yōu)于傳統(tǒng)循環(huán)網(wǎng)絡(luò)。

Table 3 Performance of each model on the Electronics dataset表3 各模型在Electronics數(shù)據(jù)集上的表現(xiàn)
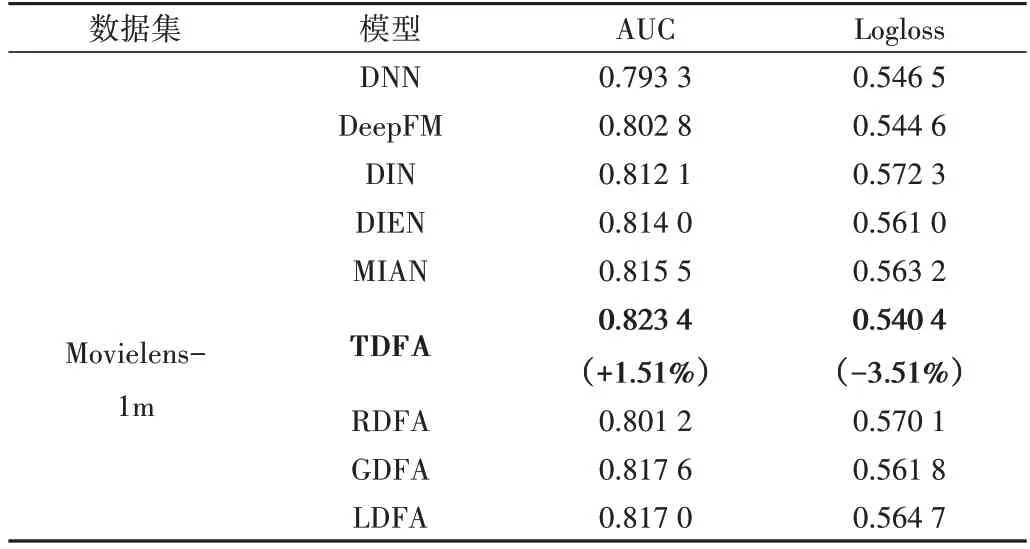
Table 4 Performance of each model on the Movielens-1m dataset表4 各模型在Movielens-1m數(shù)據(jù)集上的表現(xiàn)
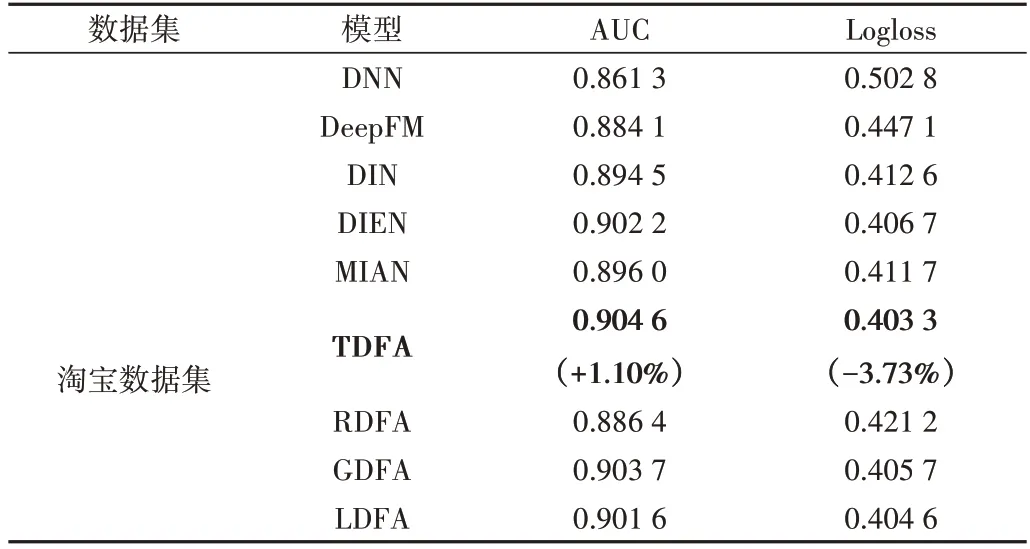
Table 5 Performance of each model on Taobao dataset表5 各模型在淘寶數(shù)據(jù)集上的表現(xiàn)
為了證明TDFA 模型關(guān)鍵部分設(shè)計(jì)的有效性,分別采用去除全局注意力層、去除FM 模塊、去除Transformer 模塊等方式在3 個(gè)數(shù)據(jù)集上進(jìn)行消融實(shí)驗(yàn),結(jié)果如表6 所示。可以看出,在去掉全局注意力層時(shí),AUC 指標(biāo)分別下降0.52%、1.08%、0.11%,這是由于高低階特征對(duì)預(yù)測(cè)結(jié)果的影響程度是不一樣的,使用注意力機(jī)制為兩種特征分配權(quán)重可有效融合兩種特征,提升模型的預(yù)測(cè)精度;在去掉FM模塊時(shí),AUC 分別下降1.26%、1.58%、1.48%,這是由于經(jīng)過(guò)多層神經(jīng)網(wǎng)絡(luò)處理的特征消解了原始特征中的有效信息,弱化了模型的記憶能力,使用FM 模塊獲取低階特征信息可以作為深度模型的有效補(bǔ)充,提升預(yù)測(cè)準(zhǔn)確度;在去掉Transfomer 模塊時(shí),AUC 指標(biāo)下降比較明顯,分別下降了3.21%、2.71%、4.43%,這是由于如果去除了Transformer,即摒棄了用戶歷史行為這一重要特征信息,會(huì)明顯降低模型性能。以上實(shí)驗(yàn)證明了模型各個(gè)關(guān)鍵部件對(duì)預(yù)測(cè)的有效性。
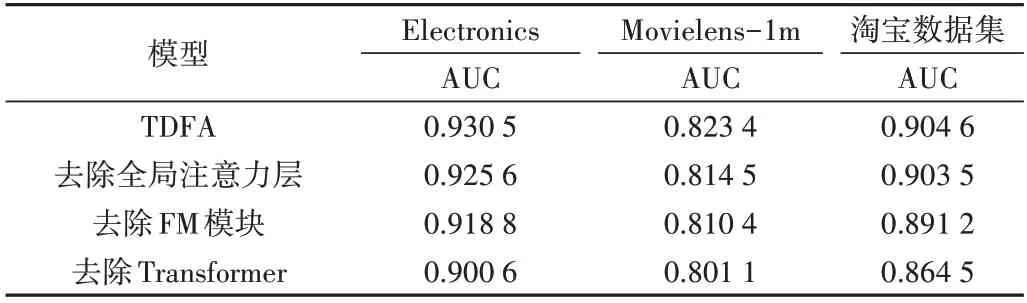
Table 6 Ablation experiment results表6 消融實(shí)驗(yàn)結(jié)果
4 結(jié)語(yǔ)
針對(duì)以往推薦模型中對(duì)用戶歷史行為特征提取能力不足、忽略低階特征交叉的問題,本文提出TDFA 模型。該模型首先使用自注意力方法獲取用戶歷史行為之間的關(guān)系;然后將歷史行為與預(yù)測(cè)目標(biāo)進(jìn)行關(guān)聯(lián)得到用戶歷史行為特征,將用戶歷史行為特征與其他特征一起送入多層神經(jīng)網(wǎng)絡(luò)得到高階特征,同時(shí)增加FM 模塊提取低階特征,添加全局注意力為高低階特征分配權(quán)重;最后在3 個(gè)公開數(shù)據(jù)集上證明了TDFA 模型的優(yōu)越性。后續(xù)計(jì)劃將用戶歷史行為區(qū)分為長(zhǎng)期和短期行為分別進(jìn)行研究,同時(shí)加強(qiáng)用戶歷史行為的特征提取能力或增加子模塊提取更多特征交叉信息,以獲得更加精準(zhǔn)的推薦模型。
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
全體育(2016年4期)2016-11-02 18:57:28
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
科普童話·百科探秘(2015年6期)2015-10-13 07:21:18
科普童話·百科探秘(2015年8期)2015-08-14 07:13:06
科普童話·百科探秘(2015年4期)2015-05-14 07:25:32
