全媒體時代智能洗稿的著作權法律規制研究
2023-05-30 17:08:06盧玨蓉
傳播與版權 2023年2期
關鍵詞:人工智能
盧玨蓉
[摘要]在全媒體時代,隨著人工智能與算法技術的發展,智能洗稿行為出現,且具有隱蔽性,而流量變現成為洗稿行為屢禁不止的動因。文章深入探究洗稿的內涵與表現類型,發現依據對人工智能的依賴程度,智能洗稿可分為輔助型洗稿與委托型洗稿,智能洗稿表現類型的劃分有利于解決智能洗稿的著作權法律規制困境,形成智能洗稿行為性質認定、侵權判定標準適用與責任承擔主體明確的智能洗稿的著作權法律規制路徑。同時,智能洗稿的著作權法律規制還應結合案例具體分析,通過整體比對法、抽象分離法做出實質性相似的量化判斷,以明確法律責任主體。此外,在傳播媒介深度融合背景下,智能洗稿的著作權法律規制也離不開新媒體平臺完善作品審核制度以及司法機關加大懲罰力度。
[關鍵詞]智能洗稿;實質性相似;人工智能;法律規制
隨著互聯網與信息技術、算法技術的發展,我國進入全媒體縱深發展時代。截至2018年1月,微信和WeChat合并月活躍賬戶數超過10億;截至2017年12月,微博月活躍用戶達到3.92億[1],用戶數據與流量成為核心競爭力。為了滿足用戶需求,獲取更多流量,由算法推薦實現用戶個性化定制成為全媒體時代作品的創作方式。
然而在全媒體時代,新媒體作品的創作現象紛繁復雜。2015年,霍炬起訴杭州麻瓜網絡科技有限公司對其“歪理邪說”微信公眾號的文章進行改編、洗稿,雖然最終法院認定原告證據不足,駁回訴訟請求,但是洗稿事件就此進入大眾視野,且愈演愈烈。2019年,微信公眾號“呦呦鹿鳴”發布的《甘柴劣火》遭到財新網記者王和巖質疑,他認為該文存在洗稿,該事件引發社會廣泛關注和關于洗稿的爭議,引起新聞傳媒界與知識產權界的辯論與思考。
當前,隨著算法技術的發展,洗稿行為頻繁出現,且出現智能洗稿行為。首先,個體利用數據庫中海量作品元素可實現內容的智能化歸整,從而迅速創作出貼合用戶喜好的偽原創內容,吸引大量流量。流量變現與內容夾雜的廣告收入又可抵減人為洗稿的成本消耗,這是洗稿行為屢禁不止的主要原因[2]。其次,新媒體平臺文稿原創性檢測功能逐漸被智能算法技術迭代,而智能算法在文稿原創性檢測過程中則存在識別機械性,即其可能出現識別失靈的情況,從而使偽原創內容得以發表[3]。最后,如今各新媒體平臺是獨立運營的,其所呈現的內容基于平臺數據庫推薦。在平臺數據庫中,一面是用戶界面,另一面連接相關的技術及其敦促者[4],雙方的信息技術具有封閉性,即用戶對平臺內容產生消費依賴,平臺又對用戶閱讀習慣的數據存在依賴,兩者共生共存,從而使偽原創洗稿作品得以出現在不同平臺上。
洗稿產生于新聞傳媒領域,并非著作權法意義上的法律概念。洗稿性質如何界定、智能洗稿是否屬于著作權侵權行為,是智能洗稿是否納入著作權法律規制的重要前提。因此,文章嘗試對洗稿內涵及其表現類型進行深入研究,準確辨析當前智能洗稿的表現類型,分析其著作權法律規制可能存在的困境,以期尋求全媒體時代智能洗稿的著作權法律規制路徑。
一、洗稿的內涵與表現類型
(一)洗稿的內涵
當前,學界對洗稿的內涵界定不一而足。有學者指出,洗稿就是新聞記者根據其他媒體報道的新聞事實撰寫文稿,或與其他記者分頭采訪并進行文稿交換,最終各自撰寫新聞稿進行發表[5];有學者認為,洗稿就是部分傳媒忽略作品真實來源,并對稿件進行多次編輯,逃避著作權法律規制的手段[6];有學者則總結,在自媒體語境下,洗稿指對原創作品內容進行轉換性表達,屬于對原創作品的變相“克隆”[7];也有學者將洗稿與刑法中的洗錢罪相比較,認為其就是通過替換文章的段落和詞句,掩蓋非法目的,使讀者產生與被洗稿作品相同的閱讀體驗[8]。綜上所述,無論通過何種視角進行解讀,洗稿都脫離不了對原創作品所含元素的隱蔽性使用,如人物、情節等,這種隱蔽性使用是洗稿內涵的核心。
(二)洗稿的表現類型
張文德、葉娜芬指出洗稿的表現類型大致可分為兩種:一種是混淆來源,另一種是改頭換面,前者通過篡改作者身份或原創作品標題來混淆來源;后者則對原創作品內容偷梁換柱,使文稿原創性檢測軟件無法辨識所檢測作品是否存在著作權侵權行為[6]。然而這種劃分標準較為模糊,并不能涵蓋洗稿的全部表現類型。在全媒體時代,洗稿不局限于人為,人工智能也能實施洗稿行為。
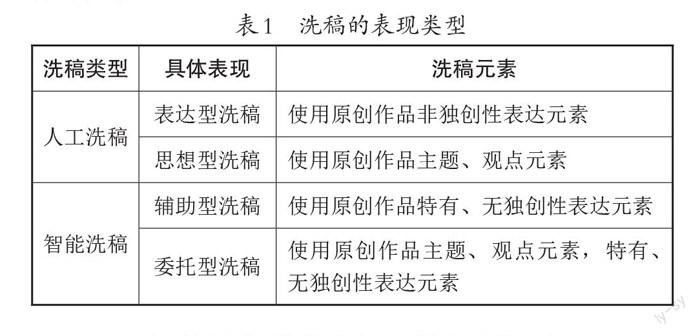
基于此,文章按洗稿形式不同,將洗稿的表現類型劃分為人工洗稿與智能洗稿,并依據“思想與表達二分法”原則,將人工洗稿細分為表達型洗稿與思想型洗稿。表達型洗稿使用原創作品的內容情節和人物特征、人物名稱、人物關系等表達元素,思想型洗稿使用原創作品的主題或觀點等思想元素[5]。而智能洗稿則依據洗稿者的要求,利用算法技術和軟件進行特定搜索,并形成專門的主題數據庫,再篩選數據庫中文章的詞句,采用轉述、替換、糅雜等算法程序進行內容的加工轉化,最終“洗”出看似具有獨創性的偽原創文章。智能洗稿又根據對人工智能的依賴程度劃分為輔助型洗稿與委托型洗稿兩種表現類型。輔助型洗稿利用智能洗稿軟件作為作品創作過程的輔助工具,僅對原創作品的人物關系、內容情節等某種表達元素進行洗稿。而委托型洗稿相當于洗稿者與人工智能之間建立委托創作協議關系,由洗稿者向智能洗稿軟件提出作品創作要求,智能洗稿軟件依據該要求全盤完成作品創作,被委托對象并非法律意義上的自然人(具體詳見表1)。
二、智能洗稿的著作權法律規制困境
(一)行為性質認定艱難
從洗稿表現類型的劃分可以看出,智能洗稿相比人工洗稿更不利于文學藝術產業的持續性發展。在網絡數字出版的生態環境下,智能洗稿比人工洗稿的被洗稿作品覆蓋范圍更廣,傳播速度更快,負面影響更為嚴重,侵權認定也更為艱難。有學者認為洗稿等同于抄襲[9],或稱為高級抄襲[2],也有學者認為洗稿和抄襲內涵一致[10],學界對洗稿的行為性質認定眾說紛紜。
司法實踐要認定著作權侵權案件被告存在侵權行為的邏輯前提是涉案作品的著作權屬于著作權法的保護范圍。而“思想與表達二分法”原則作為著作權法保護范圍的界限標準,思想和表達之間的邊界劃分是具有隱喻性的[11],甚至這種劃分是一種政策導向性區分,具有法官的主觀隨意性[12]。在全媒體時代,智能洗稿可能存在與原創作品思想保持一致,并對原創作品可利用元素進行隱蔽性表達的情況,在一定程度上難以受到法律規制。
(二)侵權判定標準適用困難
在“思想與表達二分法”原則的基礎上,司法實踐判定涉案作品存在侵權行為常用的判定標準為“接觸+實質性相似”。在全媒體時代,依靠流量的智能洗稿作品通常通過廣大受眾關注的新媒體平臺傳播,因此,要判定智能洗稿作品與原創作品之間是否存在“接觸”,司法實踐可以借助互聯網電子數據存儲技術進行時間證明,而如何判定智能洗稿作品與原創作品之間存在“實質性相似”才是判定的困難所在。根據作品思想部分是否剔除比對,整體比對法與抽象分離法這兩種不同的實質性相似比對方法得以產生。整體比對法是將涉案作品在整體比對的基礎上綜合其他因素,進而判定涉案作品是否構成實質性相似,而抽象分離法是先剔除原創作品的思想部分及其與涉案作品構成相似的部分,然后比對論證剩下的內容是否構成實質性相似[13]。
然而,智能洗稿不同于人工洗稿,其通過智能洗稿軟件海量剔除原創作品的特定元素,并進行內容的整合表達,從而使作品比對過程無法相對確定地進行一對一的內容肢解式分析。同時,在整體比對過程中,智能洗稿作品很可能因其與原創作品所涉的獨創性表達元素相似比例較低,或在抽象分離下智能洗稿作品的表達元素與原創作品的表達元素并不具有緊密性,從而無法達到實質性相似,進而無法判定智能洗稿作品存在侵權行為。由此可見,在智能洗稿的著作權法律規制中,這兩種比對方法存在比對作品數量及其相似程度無法準確量化的困境。
(三)責任承擔主體存在爭議
隨著人工智能技術的不斷發展,智能洗稿軟件的智能化程度存在差別,其對原創作品的參與度也有所差異,與人工洗稿的法律責任主體不同。在智能洗稿過程中,除了原創作品作者與洗稿者,還存在人工智能洗稿軟件。因此,人工智能生成物的可版權性問題影響智能洗稿的法律責任承擔主體的選擇。然而,這一問題至今在學界仍存在巨大爭議。
三、智能洗稿的著作權法律規制路徑
(一)行為性質的認定
第一,被認定為抄襲、剽竊都不是對智能洗稿精確的法律定性。從語義上來說,抄襲與剽竊概念本身就具有模糊性。抄襲源自拉丁語“plagiarius”,原意指“綁匪”,后來被指代“盜竊文學作品的人”,而剽竊指“故意挪用他人的創造性成果或學術成果而不注明出處的行為”[14]。智能洗稿與抄襲或剽竊之間的關系在學界爭議頗大,且用一個模糊性詞匯定義另一個模糊性詞匯并不能從根本上解釋智能洗稿的行為。就侵權類型而言,《中華人民共和國著作權法》第五十二條規定了剽竊是侵權行為之一,而智能洗稿雖然完全可能存在侵犯原創作品發表權、署名權、保護作品完整權、改編權、信息網絡傳播權等其他著作權以及與著作權有關的權利的行為,但是仍需要結合具體案例進行具體分析。
第二,“思想與表達二分法”原則在一定程度上是著作權法利益平衡的體現。盡管智能洗稿在“思想與表達二分法”原則下存在免于著作權法律規制的可能,但也不能限制“思想與表達二分法”原則的適用[8]。同時,將智能洗稿全盤認定為侵權行為也具有武斷性。智能洗稿需要結合客觀現實案例進行具體判斷,避免打破個人主體與公眾主體之間的利益平衡。只有嚴格限制智能洗稿的法律可歸責性,保護原創作品作者的合法權益,防止權利濫用,才能更好地滿足文學藝術創作領域公眾的創作需求。
(二)侵權判定標準的適用
第一,智能洗稿的侵權判定過程可運用技術進行反向追蹤,解決海量作品比對的問題。部分高級智能洗稿軟件通過深度學習生成相關內容,且生成過程隱秘,使用原創作品的元素并不明顯,內容也具有不確定性,甚至以程序設計和拼接、糅雜等形式來模糊原創作品的來源,而司法實踐可借助技術手段對智能洗稿生成過程進行反向破譯,確定特定洗稿元素的數據庫范圍。
第二,智能洗稿的侵權判定可通過智能洗稿的表現類型劃分,靈活適用實質性相似的判定標準。對輔助型洗稿而言,其隱蔽性地使用原創作品的特定表達元素,且使用所占比重不大,甚至有些洗稿者在作品的洗稿過程中,將原創作品的其他表達元素通過排列組合來體現一定的“獨創性”,使內容具有一定的“創作構思”,但若采取整體比對法,普通用戶通過觀感即可對其形成實質性相似的判斷。對委托型洗稿而言,洗稿者并未參與洗稿過程,而是由智能洗稿軟件完成洗稿,并生成大量蘊含其他被洗稿作品的思想元素與表達元素,而通過整體比對法、抽象分離法無法具體量化其實質性相似程度,若將整體比對法置于抽象分離法之前,并進行疊加適用,則可形成對其實質性相似的加成判定,即在把握洗稿作品思想脈絡的基礎上,以不影響作品中心主旨為前提,抽離出思想與公共領域有關的表達,對作品中剩下的表達內容進行判斷[15]。
(三)責任承擔主體的明確
在人工智能生成物可版權性問題的討論中,少數學者認為,“人工智能生成物是一種模仿,其生成過程不具備個性創作,生成結果也僅是算法推演”[16]。這就意味著一旦洗稿存在侵權行為,洗稿者就必然承擔侵權責任,這使得軟件開發者、設計者、投資者在一定程度上有脫離法律規制的可能,從而導致責任配置的不均。然而,大多數學者則認為,對該問題應采取階段式的判斷,文章也認同此觀點,即以弱人工智能到強人工智能的不同智能化階段來具體判定人工智能生成物的可版權性。弱人工智能是一種自學習的系統,基于學習(監督或無監督),其算法可以解決某個級別的問題,對人類智能進行模擬,利用人類所期望的學習類型數據庫來完成特定目標。而強人工智能指能夠產生智能行為的機器,其能夠表達自我意識以及真正的情感,可以理解所做的事情及原理[17]。
結合前文智能洗稿的表現類型,輔助型洗稿屬于弱人工智能類別,是一種輔助創作工具。若輔助型洗稿使用的是原創作品中無獨創性的表達元素,則該行為不具有法律可責性,若其在洗稿過程中大量使用原創作品獨創性表達的特定元素,則該行為需要承擔法律責任,責任承擔者為洗稿者。而委托型洗稿并未達到強人工智能的程度,處于弱人工智能和強人工智能之間的過渡階段,可在深度學習過程中自主完成限定命題式的指令任務。因此,委托型洗稿所生成的行為結果是現階段人工智能生成物可版權性問題爭議的焦點。
從著作權法的應然層面而言,在人類中心主義倫理原則的制約下,部分學者認為,作品創作的版權很難歸屬于人工智能,不僅因為人工智能從人類輔助工具轉換為法律主體會給著作權法存在的根基帶來嚴重打擊[18],直接原因更在于人工智能無法承擔法律責任。但也有不少學者采取折中態度,從生成結果的實然層面出發,依據作品的獨創性標準進行判定,認為人工智能生成物與人類創作作品成果相比并無明顯差異,可以承認人工智能生成物具有可版權性,但其權利歸屬與法律責任承擔仍要體現人本主義,追溯人工智能洗稿軟件的開發者、設計者、投資者和使用者[19]。在智能洗稿的委托型洗稿中,人工智能與洗稿者之間是一種委托創作協議關系,洗稿者委托智能洗稿軟件按照要求進行作品創作,但這并不意味著承認人工智能的法律主體性。同時,委托型洗稿雖在現階段是命題式的半開放式自主創作,但智能洗稿程序設計仍體現軟件所有者(投資者或開發者)的一定思想。因此,該委托關系真正具有法律意義的雙方主體是智能洗稿軟件所有者與使用者。在一般情形下,該委托關系的法律責任由委托人即智能洗稿軟件使用者來承擔。但在委托型洗稿的法律責任認定中,洗稿的主觀意圖和所使用的元素要進行具體分析,除了使用思想元素與無獨創性表達的特定元素不具有可責性,委托型洗稿使用大多數原創作品具有的獨創性表達特定元素,則存在主觀惡意,屬于《中華人民共和國民法典》第一百五十四條規定的行為人與相對人惡意串通,損害他人合法權益的民事法律行為,智能洗稿軟件所有者與使用者要共同承擔法律責任。
在全媒體時代,智能洗稿要得到法律規制,還需要各新媒體平臺加強原創作品的鑒定審核工作,司法機關也要嚴格明確新媒體平臺的法律責任。若新媒體平臺以傳播大量洗稿作品為運營方式,與洗稿者共同謀利,侵害原創作品權利人的合法權益,就需要承擔法律責任;若新媒體平臺盡到事前審核義務,不具有主觀故意,且在事中按照“通知—刪除”規則及時復查,并對洗稿作品進行刪除,則新媒體平臺不需要承擔法律責任。此外,司法機關還可以根據智能洗稿存在的主觀惡意程度來加大懲罰力度,輔助型洗稿與委托型洗稿相比,后者的主觀惡意程度更深,嚴重侵害原創作品權益,應予以懲罰性賠償,從而規制智能洗稿行為,保護原創作品創作者的合法權益,降低智能洗稿對文學創作領域的負面影響。
[參考文獻]
[1]克勞銳指數研究院.克勞銳2018自媒體行業白皮書[EB/OL].(2018-03-22)[2021-05-22].https://max.book118.com/html/2018/0914/7115114152001146.shtm.
[2]盧婷婷.微信公眾號“洗稿”現象探析[J].新聞研究導刊,2019(06):55-56,90.
[3]莫家輝,俞鋒.網絡“洗稿”的法律屬性、社會危害及治理策略[J].中國出版,2019(24):56-60.
[4]盧西亞諾·弗洛里迪.第四次革命:人工智能如何重塑人類現實[M].王文革,譯.杭州:浙江人民出版社,2016.
[5]許春明,潘娟娟.“洗稿”的法律定性及其規制[N].上海法治報,2019-02-20.
[6]張文德,葉娜芬.網絡信息資源著作權侵權風險分析:以微信公眾平臺自媒體“洗稿”事件為例[J].數字圖書館論壇,2017(02):48-51.
[7]余為青,桂林.自媒體洗稿行為的司法認定規則及其治理[J].科技與出版,2019(03):86-89.
[8]王雅芬,韋俞村.自媒體“洗稿”的著作權法規制[J].出版廣角,2019(18):68-70.
[9]張乾.互聯網時代“洗稿”現象的可責性及保護路徑[J].出版廣角,2020(05):38-40.
[10]周勇.智能洗稿法律規制研究[J].當代傳播,2019(04):76-79.
[11]李雨峰.中國著作權法:原理與材料[M].武漢:華中科技大學出版社,2014.
[12]李琛.“法與人文”的方法論意義:以著作權法為模型(英文)[J].Social Sciences in China,2007(04):37-50.
[13] 蘇志甫.利用他人作品元素改編行為的判斷思路與邏輯展開:從“武俠Q傳游戲”侵害改編權及不正當競爭案說起[J].法律適用,2020(18):141-149.
[14] Mary W,John. M. The Intersection of Copyright and Plagiarism and the Monitoring of Student Work by Educational Institutions[J].Australia and New Zealand Journal of Law and Education,2006(11):73.
[15] 康瑞.自媒體“洗稿”的著作權法審視[J].傳播與版權,2019(02):177-179.
[16] 王遷.論人工智能生成的內容在著作權法中的定性[J].法律科學(西北政法大學學報),2017(05):148-155.
[17] 費爾南多·伊弗雷特.人工智能和大數據:新智能的誕生[M].吳常玉,譯.北京:清華大學出版社,2020.
[18] 曹新明,楊緒東.人工智能生成物著作權倫理探究[J].知識產權,2019(11):31-39.
[19] Bridy A. Coding Creativity:Copyright and the Artificially Intelligent Author[J].Stanford Technology Law Review,2012(05):1-28.
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
汽車零部件(2020年3期)2020-03-27 05:30:20
表面工程與再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技術(2018年9期)2018-11-02 05:31:34
IT經理世界(2018年20期)2018-10-24 02:38:24
通信電源技術(2018年3期)2018-06-26 06:33:30
軍營文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
學與玩(2017年12期)2017-02-16 06:51:12
