神通Transformer:深度學習領域的黑科技
2023-06-07 16:31:17
中國信息技術教育 2023年11期
主持人:
楊? 磊? 天津市第五中學
嘉? 賓:
邱元陽? 河南省安陽縣職業中專
劉宗凡? 廣東省四會市四會中學
金? 琦? 浙江師范大學附屬中學
倪俊杰? 浙江省桐鄉市鳳鳴高中
應用沙龍
編者按:大型神經網絡模型具備龐大的參數數量和計算量,被稱為大模型,可解決自然語言處理、圖像識別和語音識別等各類任務。訓練大模型通常需要高性能計算設備和大規模數據集。由于Transformer可以處理大規模文本數據并構建更復雜的語言模型,因此它被廣泛應用于大模型中。本期我們將繼續介紹Transformer在深度學習領域中的應用。
模型、大模型與超大模型
楊磊:隨著技術的不斷發展和迭代,越來越多的大模型和超大模型被應用于各種領域,并取得了顯著的成果。那么,如何界定模型、大模型和超大模型?
劉宗凡:模型是機器學習的核心概念,是從數據中映射出規律和模式的函數,它的本質是對現實世界中數據和規律的描述和抽象。機器學習是一種人工智能技術,其目的是通過計算機算法從現有數據中學習和發現應用模式,以便預測或做出決策。在機器學習中,模型是一個重要的概念,因為其扮演了學習和預測的核心角色。簡而言之,模型就是從給定數據的輸入中預測出對應輸出的函數,其核心任務是利用給定的數據集訓練模型并調節其參數,使其能夠更好地擬合數據進行預測。模型的本質是對真實世界中的數據和規律進行抽象和描述,對現實世界的復雜性進行簡化。例如,對于一個簡單的二分類問題,模型可以是一個樣本點的一堆數學表達式的組合,但這些表達式背后的數學原理、公式和變量,卻是對整個問題的描述和抽象。因此,模型在機器學習中是無可替代的,其得出的結果決定了訓練模型的準確性和泛化能力。在機器學習中,模型可以是線性、非線性、簡單或復雜的。其中,最常用的模型是線性模型和隨機森林模型。線性模型是最簡單的模型之一,它利用線性方程對數據進行建模,如單一變量、多元線性回歸等。線性模型受限于其簡潔性,需要根據實際情況加以改進。
大規模深度神經網絡模型已成為機器學習和人工智能領域的一個熱門話題,尤其是在處理具有挑戰性的問題方面,這類模型可以通過在大規模的數據集中進行訓練和調整來達到極高的精度。在這些模型中,大模型和超大模型是最常見的兩種,雖然兩者在參數數量和規模上存在一定的差異,但它們的作用和意義都是一樣的。
大模型通常指的是那些具有大量參數,需要大規模數據集和計算資源以進行訓練和調整的深度神經網絡模型。這樣的網絡可以被用于各種任務,如語音識別、圖像識別、自然語言翻譯等。在這些任務中,網絡需要學習從輸入中抽取出有用的特征,并輸出相應的結果。例如,輸入一張圖片并輸出它所代表的物體類別。對于這種模型,訓練所需的計算資源是一個重要的限制因素。因為計算資源越多,網絡就可以擁有更多的層和參數,而這些層和參數是用來捕捉輸入數據中更多的信息。由于訓練速度的限制,大型網絡的訓練可能需要花費數天、數周乃至數月的時間。此外,大規模數據集也需要足夠多的數據以減少過度擬合的情況,如ImageNet數據集就包括了超過一千萬張圖片以及超過一千個物體類別。雖然大型神經網絡的計算和訓練需求巨大,但這樣的網絡結構已經成為許多領域中最先進的解決方案,在計算機視覺和語音處理領域也表現出了很好的應用效果。這意味著,在未來,大模型仍然會繼續發揮重要的作用,并且可能會變得更加精細和復雜。
隨著大型網絡在深度學習中的成功,研究者們開始考慮是否可以創建更大的神經網絡模型以解決更加困難的問題。在這樣的情況下,超大模型便應運而生。超大模型擁有數萬億到數千萬億的參數,是目前計算機科學領域中最大的網絡模型之一。這種超大的神經網絡模型需要大量的計算資源和訓練數據。例如,OpenAI在訓練超大模型GPT-3時使用了3200個V100 GPU和1750億個參數。雖然這些超大模型的訓練成本極高,但是對于具有挑戰性的任務,如自然語言處理、語音合成和音樂生成等,這些模型通常要比小型的模型能夠產生更好的性能。
倪俊杰:超大模型有著廣泛的應用前景。例如,在自然語言處理方面,超大模型可以通過學習大量的文本語料庫來構建語言模型,在文本生成、文本分類和命名實體識別等任務方面表現出色。在圖像識別和計算機視覺領域,通過使用超大模型,可以更好地捕捉圖像中的細節和上下文,并減少類似于過度擬合的問題。
超大模型的發展在一定程度上受到計算資源限制。如果沒有大量的計算資源,研究者和開發者們就無法訓練和優化這些模型。除此之外,超大模型還面臨著缺少分類和其他領域的支持數據,因此,研究者需要重新思考如何更好地挖掘這些極值模型的價值。
大模型和超大模型對未來人工智能的發展具有深遠的影響。在機器學習、深度學習領域以及解決大型復雜問題的算法研究中,這些模型可以在數據處理和計算能力方面提高模型的表現并產生新的應用。未來,我們可能會看到更加復雜并高效的大型和超大型模型的出現,這些模型將推動人工智能領域的飛速發展。
谷歌的BERT和OpenAI的GPT
楊磊:BERT和GPT都是基于Transformer架構的預訓練模型,用于自然語言處理任務。那么從預訓練的角度看,它們之間有什么區別呢?
邱元陽:自然語言處理是一項日益重要的任務,需要將人類語言轉換為計算機可處理的形式,從而使計算機能夠理解和處理文本數據。在這個領域中,預訓練模型在最近幾年中引起了人們極大的興趣。其中,使用Transformer架構的預訓練模型(如BERT、GPT等)已經成為自然語言處理領域的頂尖解決方案。
BERT(Bidirectional Encoder Representations from Transformers)是一種雙向語言模型,由Google在2018年提出。它通過預訓練和微調的方式,可以用于文本分類、問答等任務。在預訓練階段,BERT利用大規模無標注數據進行訓練,學習到自然語言的語義和語法信息。BERT采用了雙向語言模型,即利用上下文信息來預測當前詞語,主要方法有兩種:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。MLM方法首先會在輸入文本序列中隨機選擇一定比例的詞語,并將這些被選中的詞語隨機替換成一個特殊的標記,稱為[MASK]。其次,模型會嘗試預測這些被覆蓋的[MASK]標記的正確詞語。預測的方式是利用模型對整個輸入序列的理解實現上下文感知的預測。對于預訓練過程中提供的輸入文本序列中未被替換的詞語,模型則可以從上下文中準確地學習它們的表示。而NSP方法是為了讓模型具有理解文本上下文之間關系的能力。具體來說,NSP的預訓練任務是從一大堆文本中提供兩個句子。在這兩個句子之間隨機選取一個標志,在輸入中把這個標志插入第一個句子和第二個句子之間,然后將文本輸入BERT模型中,生成一個表示兩個句子連接的向量。預訓練任務的目標是讓模型學會理解兩個句子之間是否有聯系,并預測下一個句子是什么。采用這個方法的目的是教會模型理解和處理不同的文本任務(如問答、命名實體識別、情感分析等),因為許多任務都需要模型理解文本上下文之間的關系。通過訓練模型推斷下一個句子,模型能夠在各種自然語言處理任務中更好地理解文本的含義和結構。這兩種方法通過語言模型和推斷兩個方面來預訓練模型,使BERT能夠理解上下文關系并將其應用于各種自然語言處理任務中。在微調階段,BERT利用有標注數據進行微調,以適應具體任務的需求,即將已經經過大規模預訓練的語言模型微調到特定的自然語言處理任務上。在微調之前,首先需要在大規模的語料庫上進行預訓練,得到語言模型的參數。在微調時,BERT模型需要通過微調進一步調整模型參數以適應具體的任務,而通常只需要微調較少的參數就可以達到良好的效果。BERT的微調方式可以有效地提高模型在具體任務中的準確率,尤其適用于需要理解上下文信息的任務。
GPT(Generative Pre-training Transformer)是一種單向語言模型,由OpenAI在2018年提出。它主要用于生成文本,如自動寫作、對話生成等任務。現在大紅大紫的ChatGPT并不是橫空出世的變革性產物,它及其近親GPT-1/2/3在模型本質上沒有重大改變。GPT的預訓練過程只包括MLM任務,它采用了“預訓練—微調”的訓練方式。在預訓練階段,GPT利用大規模無標注數據進行訓練,學習到自然語言的語義和語法信息。GPT的預訓練方法主要是基于單向語言模型,即利用上文信息來預測當前詞語。預訓練階段主要是學習文本的表示,使得模型在微調階段能夠更好地適應具體任務的需求。與BERT不同,GPT通過提示詞(Prompt)的方式進行微調,通過在一個較大的語言模型上進行迭代訓練,根據給定的Prompt生成相應的輸出。Prompt是指為生成語言任務提供的一些提示,如前面一小段文本或一些關鍵詞等。GPT將Prompt的輸入與訓練后的語言模型結合,生成與Prompt相關的輸出結果。GPT的提示詞方式使得模型在針對特定任務時能夠更好地基于一些提示信息生成相應的文本輸出,適用于需要生成自然語言文本的任務。
無論是BERT還是GPT,它們都證明了Transformer架構在自然語言處理領域的優秀性能,并且為自然語言處理任務的解決提供了強大的工具。
Transformer在視覺領域的發展
楊磊:眾所周知,Transformer已經在自然語言處理領域大放異彩,那么在視覺領域,如圖像分類和視頻生成等表現如何呢?
金琦:在視覺領域,Transformer模型也被應用于圖像分類和視頻生成等任務,但是相對于自然語言處理領域,它的表現可能并不那么出色。這主要是因為Transformer模型在自然語言處理領域中的優勢在于其能夠處理序列數據,而圖像和視頻數據則是二維和三維的數據結構,與序列數據有很大的區別。目前,已經有一些基于Transformer的視覺模型被提出,如Vision Transformer(ViT)和Swin Transformer等。
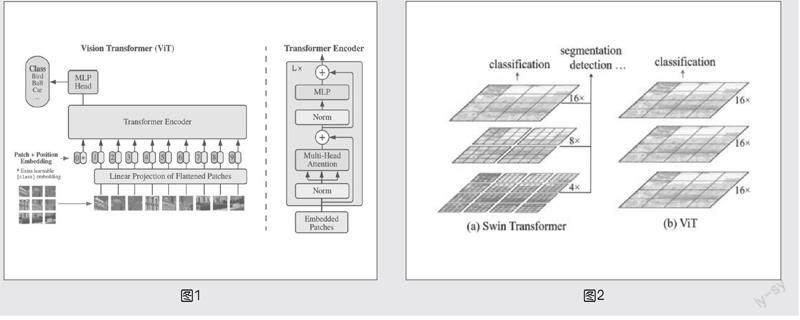
ViT最初由Google Brain團隊在2020年提出,它是一種基于Transformer的圖像分類模型,采用了將圖像劃分為若干個小塊,然后利用Transformer進行編碼的方式,實現對整個圖像的理解,模型原理如下頁圖1所示。
使用大規模數據集對ViT進行預訓練,然后對小型下游任務進行微調。為此,刪除預訓練的預測頭,添加一個用0初始化的D*K前饋層,其中K是下游任務的類別數。對于高分辨率任務,微調通常很有幫助。ViT能夠處理任意長度的序列,但預訓練的位置嵌入可能不再適用。因此,根據預訓練位置嵌入在原始圖像中的位置,對它們進行2D插值操作。需要注意的是,這種分辨率調整和塊的抽象只有在手動注入到視覺Transformer的2D結構的歸納偏置的情況下才有效。在中等規模數據集上,這種模型可以產生適中的結果,其精度比ResNets低幾個百分點。由于Transformer缺乏CNN固有的歸納偏置,因此,在訓練不足的數據集上可能不能很好地泛化。然而,如果在大規模數據集上進行訓練,則可以獲得出色的結果。在JFT-300M數據集上預訓練的ViT在許多圖像訓練基準上準確率可以達到或超越最先進的結果——ImageNet(88.36%)、CIFAR-10(90.50%)、CIFAR-100(94.55%)以及VTAB的19個任務(77.16%),這在一定程度上挑戰了傳統卷積神經網絡的地位。
邱元陽:隨著ViT的提出,越來越多的研究者開始關注基于Transformer的視覺模型。雖然ViT在圖像分類領域表現出色,但由于其編碼器輸入固定為16×16的圖像塊,因此無法適用于需要更細致視覺細節的密集視覺任務,如目標檢測和語義分割。這些任務的圖像通常比圖像分類數據集中的圖像更大,使用較小的圖像塊將增加自注意力層必須處理的塊數,導致注意力機制計算復雜度隨著圖像塊數量的增加而增加。在2021年,微軟發布了一款新的視覺Transformer,稱之為Swin Transformer。它可用作計算機視覺任務(如圖像分類、物體檢測和語義分割)的骨干。Swin代表著Shifted windows,為Transformer提供了分層視覺,使用4×4的塊大小在高分辨率圖像上表現更為優秀,因為ViT的全局注意力方法不適合進行語義分割。因此,我們需要更細致的像素級預測,同時需要考慮注意機制的計算復雜度的改進和優化方法,Swin Transformer采用了分層的策略,將圖像分為多個子區域進行編碼,從而實現對全局信息的建模,并采用了窗口交換策略,將相鄰子區域之間的信息進行交換,從而實現了不同子區域之間的信息交互,具有更好的信息傳遞能力。Swin Transformer通過從小的patch開始逐漸合并深層Transformer層中的相鄰patch來構建分層特征映射。例如,Swin Transformer從不重疊的16(4×4)個本地窗口開始(圖2(a)中底部的紅色正方形),每個本地窗口都有16(4×4)個圖像patch。隨著自注意力層在每個本地窗口內計算,它們只處理16個圖像patch之間的關系。與此相反,ViT的注意力層適用于整個圖像patch(如圖2(b))。如果它使用相同的較小的patch尺寸,則注意力層需要處理256個patch。由于ViT是一個圖像分類模型,因此使用較大的patch(粗略特征)是可以的。然而,Swin Transformer需要細粗特征。在層次結構的下一級中,Swin Transformer合并相鄰patch以形成4(2×2)個本地窗口,同樣,自注意力層在每個本地窗口內計算。因此,這些層只處理16個特征patch。換句話說,在任何級別上,每個窗口中的patch數量都是相同的。最終,一個本地窗口覆蓋整個圖像,并包含16個特征patch。因此,計算復雜度與輸入圖像大小成線性關系。下面以4×4的patch尺寸處理各種圖像大小來說明這一點。合并相鄰patch會減小圖像大小,同時增加每個patch的感受野,就像ResNet的卷積和最大池層減小特征映射大小,同時增加感受野一樣。
與自然語言領域的發展相比較,Transformer在視覺領域的發展還處于起步階段,但已經展現出了不少有趣的應用,前景十分樂觀。隨著深度學習技術的不斷發展,這種模型將有更廣泛的應用,也許未來可以更好地發揮這種模型的潛力。
結語
楊磊:Transformer和大模型技術的不斷發展,在給我們帶來便利的同時,也增加了我們學習人工智能的難度。因此,我們只有不斷地學習、實踐和創新,才能更好地掌握這些技術,應對人工智能領域的變化和挑戰,發揮潛力和創造力,創造更多的價值。希望本期討論可以讓讀者了解Transformer在深度學習領域的應用,以更好地應對大模型時代的機遇和挑戰。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
