基于Hilbert曲線-殘差網絡的勒索病毒分類方法
2023-06-15 09:27:14孫超遠蔣秋華徐東平
計算機技術與發展 2023年6期
孫超遠,蔣秋華,徐東平,李 琪
(1.中國鐵道科學研究院 研究生部,北京 100081;2.中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081)
0 引 言
2022年2月,中國互聯網絡信息中心發布了第49次《中國互聯網絡發展狀況統計報告》[1]。數據表明,截至2021年12月,國內網民規模和互聯網普及率均創新高。互聯網的快速普及與快速發展產生若干漏洞,這些漏洞被黑客所利用并進行攻擊,給互聯網安全造成了巨大的威脅。惡意軟件便是持續攻擊互聯網網絡空間安全其中一個嚴重威脅。惡意軟件被黑客通過各種形式安裝在用戶主機中,竊取用戶敏感信息,對計算機操作系統造成破壞。勒索軟件作為惡意軟件的一種特殊形式,自1989年第一個勒索軟件“AIDS”誕生以來,便給網絡空間安全帶來了嚴峻的挑戰。
勒索病毒主要分為四大類型:第一種是文件加密類勒索病毒,此類病毒進入用戶系統以后,通常會搜索系統中的數據文件,使用多種加密算法對文件進行加密,以此索要贖金,破解存在很大的難度;第二類是數據竊取類勒索病毒,此類與文件加密類病毒類似,通常采用混合加密算法對用戶數據進行加密,但攻擊者通過甄別和竊取用戶重要數據,通過公開重要數據,脅迫用戶支付勒索贖金,如Conti勒索病毒已經攻擊并感染政府、重點企業等300多家,竊取并公開大量數據;第三類是系統加密類勒索病毒,此類病毒同樣通過各類加密算法對系統磁盤主引導記錄、卷引導記錄等進行加密,阻止用戶進行磁盤訪問,影響用戶設備的正常啟動和使用;第四類是掩蓋真相類勒索病毒,此類勒索病毒對用戶設備屏幕進行鎖定,通常偽裝成系統藍屏錯誤或以全屏形式呈現勒索信息的圖像,導致用戶無法正常登錄和使用設備,進而進行贖金勒索。
據CNCERT《2020年中國互聯網網絡安全報告》[2],僅2020年就捕獲78.1萬余個勒索病毒,數量較2019年上升6.8%。同時,勒索病毒的攻擊方式和技術手段也在不斷升級,近年來,勒索病毒逐漸從“廣撒網”轉向定向攻擊,主要目標是一些大型高價值機構,更具有針對性,技術手段從利用漏洞入侵過程以及隨后的內網橫向移動過程的自動化、集成化、模塊化、組織化特點愈發明顯。勒索團伙將加密文件竊密回傳,在網站或暗網數據泄露站點上公布部分或全部文件,以威脅受害者繳納贖金。RaaS(Ransomware-as-a-Service,勒索即服務)商業模式的出現,也使得攻擊者進行勒索病毒攻擊成本大大降低,勒索病毒變種數量急劇增加。
在檢測勒索病毒的基礎上,對勒索病毒進行分類,不僅能夠加快應急響應速度,也使得安全工程師能夠更快速有效地進行針對性緩解,同時能夠快速檢測勒索病毒的新變種。目前國內對勒索病毒的研究大多數是對勒索病毒進行二分類,即檢測是否是勒索病毒,而對勒索病毒更進一步的分類工作較少,同時其分類方法各有不足,目前大多勒索病毒自帶環境檢測,因此動態分析無法完全獲得勒索病毒動態特征,且成本較高。靜態分析往往需要人工通過工具提取靜態特征如簽名、操作碼等,遇到大規模的分類時,具有極大的局限性。
自可視化方法提出以來,人們得以通過視覺圖片來感受二進制文件的整體結構及特征,得到了廣泛使用。同時,二進制文件的圖像可視化使得安全分析人員可以通過卷積神經網絡的圖像識別及分類來達到二進制文件的識別及分類,實現自動化,大大減少工作量。在可視化勒索軟件分類方法的基礎上,該文利用Hilbert[3]曲線對勒索病毒進行可視化,得到對應的圖像,利用基于ResNet[4]改進的三種殘差神經網絡模型提取特征進行圖像分類,使用集成學習投票生成最終結果,從而達到勒索軟件的分類。
1 背景知識及相關工作
自勒索病毒首次出現于1989年以來[5],隨著勒索病毒的技術升級,不斷迭代,RaaS商業模式的出現,使得勒索病毒及其變種數量屢創新高。在實踐中,攻擊者往往對現有勒索病毒利用工具進行改造或轉換,生成新的變種,因此這些病毒往往在行為或代碼上存在一定的相似性,也即同一家族的勒索病毒,這種特征使得對根據勒索病毒產生的變種來源進行分類,也即勒索病毒家族分類,在理論上變得可行。
目前對勒索病毒分析的方法主要分為兩種:動態和靜態。動態分析通過在虛擬機或沙箱中運行,獲取勒索病毒的進程行為、API調用序列、注冊表訪問、通信行為等,提取勒索病毒的行為特征,進行進一步的分析。Hampton[6]通過API調用檢測特定活動來識別勒索軟件,Takeuchi等人[7]通過提取API調用行為,以2-grams表示,結合SVM檢測勒索病毒。Scaife[8]設計了勒索軟件預警系統。Usharani[9]通過分析網絡流量,對勒索病毒通信行為溯源從而識別勒索病毒。Cabaj[10]設計開發了SDN檢測系統。Zavarsky[11]通過監視文件系統、注冊表行為檢測勒索病毒。Cohen[12]對勒索病毒運行時轉儲內存鏡像分析,使用Volatility框架提取特征,進行訓練。Moussaileb[13]采用誘餌文件,遍歷文件系統,對勒索病毒進行檢測。郭春生[14]通過API調用對勒索軟件實現了家族分類。龔琪[15]對API序列進行對比,進行了勒索病毒同源性分析。此類方法需要專家提供專門的運行環境進行分析,手動篩選特征,缺乏自動化,此外,越來越多的勒索病毒代碼中自帶指紋識別以逃避檢測,在檢測到疑似沙箱虛擬環境時,勒索病毒只會運行一些正常的功能,并不會觸發惡意代碼的執行。這給安全分析師帶來了困難。靜態分析往往通過PEiD、IDA Pro、OllyDbg等工具從代碼上進行分析,一般不會受到加殼、混淆等技術的影響。Zhang H等人[16]將N-gram、操作碼、TD-IDF結合,對勒索軟件進行家族分類,Xiao[17]在操作碼中引入了自注意力,使用DBN進行訓練。但此類方法同樣需要人工工具分析處理,逆向思路難度大,效率低下,不適合大規模樣本分類。
自Conti等人[18]在2008年首次提出惡意軟件可視化的想法后,很多人在此領域做出了大量的貢獻。2010年Kinable等[19]提取API調用,通過圖形表示,使用聚類算法進行圖匹配,實現惡意代碼分類。2011年Nataraj[20]進行了惡意軟件分類的實驗,取得了98%的準確率。2020年郭春[21]進一步將可視化用于勒索軟件分類,取得了96.7%的分類準確率,展示了勒索軟件可視化分類的前景。與之前可視化方法不同的是,該文采用了保留數據特征更好的Hilbert曲線化圖像,使用更深層次的不同遷移模型進行驗證,最終結果使用集成學習進行投票,從而增加分類結果的魯棒性。結果表明,該方法在實驗中取得了更高的準確率。
2 基于Hilbert曲線化圖像的勒索病毒分類方法
勒索病毒分類方法的流程主要包括三部分:Hilbert可視化、深度模型訓練、集成學習投票,如圖1所示。
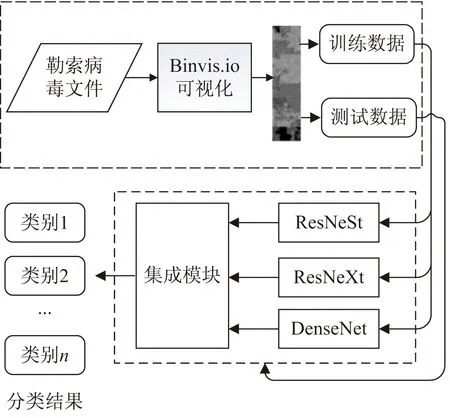
圖1 分類流程
第一部分,利用binvis[22]工具使用Hilbert[22]曲線將勒索軟件可視化成Magnitude圖;第二部分,使用基于ResNet-50的遷移學習模型ResNeSt-50[23]、ResNeXt-50[24]和DenseNet-161[25]對Magnitude圖進行特征提取并訓練,得出各自模型的分類結果;第三部分,使用集成學習模塊對三種模型結果進行投票,得到最終測試結果。
2.1 Hilbert曲線與可視化
在日常分析工作中,分析人員遇到未知的二進制文件時,使用常規的查看文件方法難以掌握文件的整體結構。因此,通過將代碼轉換為圖像定義一系列的規則實現二進制文件的可視化,可以使得分析人員快速了解文件代碼結構以輔助分析。此方法同樣適用于勒索病毒文件,而對于同一家族的勒索病毒,因其具有相似結構塊的代碼,所以其可視化圖像應保持局部結構相似性或者紋理特征一致性。同一家族圖像相似,不同家族圖像結構不同,從而通過可視化圖像實現勒索病毒家族分類。在前人所做的可視化工作中,往往都是將勒索病毒PE文件反編譯得到二進制文件,然后將文件中的二進制比特串分割為若干長度為8比特的字串,從左到右逐行遍歷,使用取值范圍為[0,255]的像素點表示文件中的元素,轉換為對應的灰度圖。但這種“之”字形的遍歷即Zigzag曲線往往不是很令人滿意——小比例元素(即只占幾條線的元素)信息往往會丟失,在一維空間中一些彼此靠近的數據點映射到二維空間時會跨越不同的位置同樣導致局部信息可能丟失。
在計算機科學中,常常采用空間填充曲線進行降維或升維,將n維空間數據與1維連續空間數據互相映射,Hilbert曲線便是一種常用的空間填充曲線方法。
Hilbert曲線的構造方式可遞歸生成。在階數為1的情況下,將一個平面劃分成四個相等的小正方形,然后以順時針方向從左下象限小正方形的中心點開始到右下象限的小正方形結束,用線段將四個正方形的中心點連接起來。增加階數時,分別將每個小正方形進一步分割成四個相等的更小的正方形,依據前述步驟將其中心連接起來,然后翻轉部分正方形以將相鄰圖形銜接起來,如此反復,無限分割連接,如圖2,得到最終填滿整個平面的Hilbert曲線。結果表明,在將一維樣本序列映射到二維圖像上的同時保持一維上相鄰元素在二維上盡可能彼此接近,從而最大程度地保留了局部性信息,而卷積神經網絡中提取特征的一個重要特性便是局部不變性,兩者相互吻合,意味著能夠提取到更多的特征,并且得到的圖像大小不會因文件大小不同而尺寸不同。由圖2(c)、(d)中黑點可看出,隨著階數的增加,一維樣本序列中的某個元素點在二維圖像中,趨于一個固定的位置,使得即使改變階數,也不用重新訓練卷積神經網絡,大大減少了訓練成本。因此,該文采用的空間填充曲線按照Hilbert曲線[24]規則對一個勒索病毒的二進制文件中的代碼進行采樣,同時增加更多的顏色映射的粒度來獲得更多的細節,并將相應的像素寫入圖像,轉換為Magnitude圖,實現可視化。

圖2 Hilbert曲線的構造
由圖3中可看到,勒索病毒文件十六進制中資源節在Magnitude圖中一一對應,代碼中的內部結構信息在Magnitude圖中得到了很好的保留,連續的數據塊都保存在一個可視塊中。圖4為兩個不同家族勒索病毒Magnitude圖的比較。可以直觀地看出兩個勒索病毒家族Conti和Stop之間的差異。
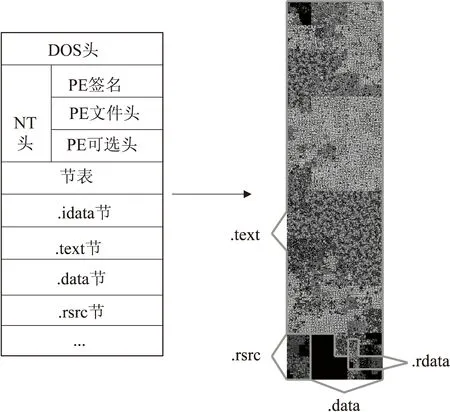
圖3 PE文件的簡要結構及對應Magnitude圖的資源節表示

圖4 兩個不同家族勒索病毒Magnitude圖的比較
2.2 深度模型訓練
殘差神經網絡在圖像分類領域具有很強的學習能力和遷移能力,可以選擇從上游預訓練好的模型遷移到下游分類任務中,自動提取圖像的特征,進行分類,大大減少了重新架構網絡模型的復雜度,降低了對數據集的要求。因此,該文采用三種均基于ResNet-50的深度遷移模型:ResNeSt-50、ResNeXt-50和DenseNet-161。ResNet出現于2015年,在此之前的卷積神經網絡模型加入更深的卷積層數后,模型準確率存在瓶頸,精確度上升到一定上限后甚至會出現退化問題,ResNet網絡使用殘差連接,在神經網絡的側面添加了恒等變換,同時取消各個卷積層之間的池化層,解決了深度CNN模型訓練困難的問題,其網絡結構圖如圖5所示。
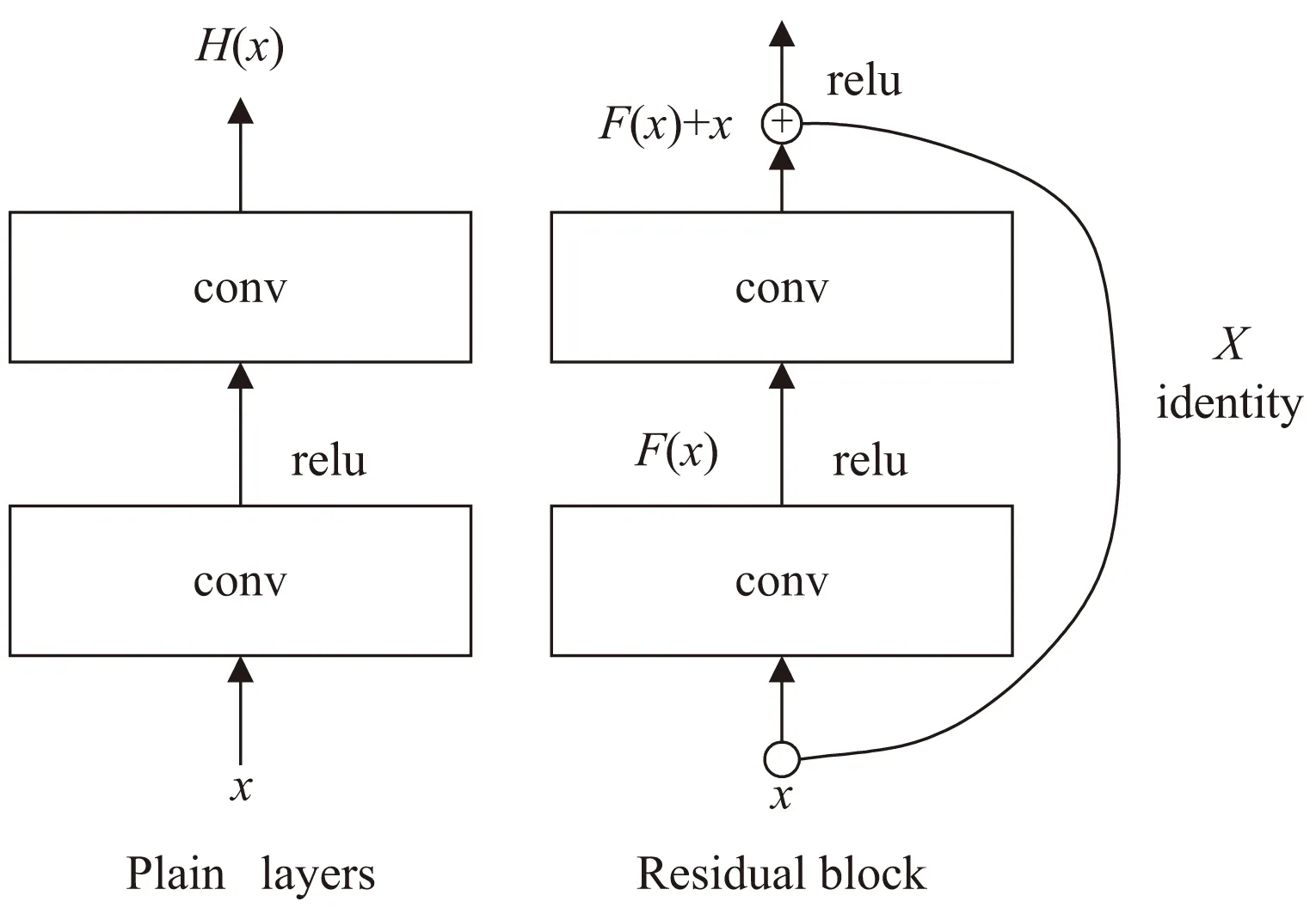
圖5 ResNet核心卷積結構
圖5是ResNet網絡中的核心卷積結構—殘差塊,中間是一個堆積層結構(由幾層堆積而成),當輸入為x時,其學習到的特征記為H(x),在引入右邊的殘差連接進行學習時,令其堆積層學習到殘差F(x)=H(x)-x,這樣原始的學習特征是F(x)+x,從而確保深層網絡模型的精確度。而ResNet-50網絡結構包含5個卷積模塊和1個全連接模塊,前5個模塊有50個卷積層,用于計算提取特征,全連接模塊包含1個平均池、1個全連接層和1個softmax,用于結果分類。
在CNN中,通過卷積模塊對輸入圖像提取特征,文中輸入圖像為Magnitude,在模型中輸入為RGB三維圖像,因此為三維卷積。
假設一個圖像的輸入格式x為[hin,win,c],其中hin、win、c分別代表圖像的長、寬、維度(通道數),卷積核kernel的格式為[fk,fk,c],步長為stride,輸入圖像與卷積核進行卷積后的結果會損失圖像邊界處的信息,因此卷積操作前需要對原矩陣邊界進行填充。ResNet對圖像像素采用same方式填充,這種填充方式能夠最大程度地保留圖像的原始特征,卷積時對圖像填充數為padding。每次卷積計算后得到的特征映射y為[hout,wout,c],其中特征映射尺寸大小的計算公式及填充圈數分別為:
經過多輪卷積得到最終的圖像特征圖。
該文分別使用三種遷移模型進行特征提取和訓練,分別使用各自的Softmax層得出分類結果。
ResNeSt-50在ResNet-50的基礎上添加了分散注意力機制,可以跨越不同的特征圖組實現特征圖注意力,能夠更好地提取到全局特征。
ResNeXt-50對ResNet-50進行了改進,將單個卷積結構替換成了組卷積,采用了多分支的策略,添加了一個新的維度-基數以表示組卷積中卷積單元的數量,此結構可以在模型參數量不變的情況下提升精度。
DenseNet-161將ResNet-50的殘差連接加到極致,計算公式由xl=Hl(xl-1)+xl-1變為xl=Hl([x0,x1,…,xl-1]),將每一層的輸出都直連到后面所有的層的輸入,使得后面的層融合了前面多層特征的特性,同時這種向后跳躍的結構能夠緩解一定程度的過擬合。
三種遷移模型在提取到特征之后,均使用average Pooling層替代全連接層傳遞給Softmax進行分類,該文在原有三種遷移模型的基礎上修改最后Softmax層,使其適合本實驗結果分類,每種模型輸出各自的預測結果標簽。
2.3 集成學習投票
在2.2節中,分別得到三種模型預測結果后,因三種遷移模型均基于ResNet-50模型,相互之間具有較小的同質性,因此使用集成學習進行投票,將三個模型預測結果中出現次數最多的類別作為最終類別標簽,降低方差,從而提高模型的魯棒性。
3 實驗設計與分析
3.1 實驗數據集
目前勒索病毒沒有公開的數據集,因此實驗的數據集主要來自VirusShare,另用VirutTotal進行補充,一共收集了18個家族的勒索病毒。因采用轉換為Magnitude圖像進行識別分類,需要對數據集樣本進行加殼識別,同時為了確保樣本的勒索家族標簽,對樣本通過VirutTotal報告分析進行篩選。實驗還在360平臺下載可信(Benign)樣本,以區分模型對正常樣本和勒索病毒樣本的二分類結果。在對數據集樣本進行篩選后,確定最終的數據集包含17個家族的勒索病毒樣本2 409個以及可信樣本192個,其中QNACRYPT為Linux平臺的ELF勒索病毒,其余均為Windows平臺的PE文件。實驗數據集構成如表1所示。

表1 勒索病毒家族實驗數據集
3.2 評估指標
該文采用分類精度accuracy、準確率precision、召回率recall和F1-score四個性能指標[26]來評估模型的性能。四個指標的計算公式分別如下:
3.3 實驗設置與結果
在預訓練階段,由于轉換的Magnitude圖尺寸大小為255×1 020,而模型輸入圖像大小為224×224,因此使用ReSize函數將圖像統一調整為224×224,對圖片處理節點采用了數據增強,隨機裁剪圖像,縮放,隨機更改亮度、對比度和飽和度,添加隨機噪聲等手段增強圖像質量,特別是在預測階段對Test樣本進行了TTA(Test Time Augmentation)來提高預測精度。優化器使用AdamW,其效果與Adam+L2正則化相同,但是計算效率更高。學習率采用cosine,計算公式為:
其中,ηmin表示最小學習率,ηmax表示初始學習率,也是最大學習率,Tcur表示當前的epoch,Tmax表示cos周期的1/2。
由于實驗數據集各家族樣本中個別家族樣本數量不均衡,因此采樣使用改良的K折交叉驗證即StratifiedKFold,StratifiedKFold使用分層采樣,能夠保證訓練集與測試集中各家族類別樣本比例與原始數據集相同。
使用3.1節的數據集對分類模型進行測試驗證,樣本按8∶2的比例劃分為訓練集與測試集,得到訓練集2 082個樣本,測試集519個樣本。訓練集中使用StratifiedKFold進行十折交叉驗證,設置epoch為30,分別對三個模型進行訓練最后進行集成投票。同時設置Hilbert曲線和Zigzag曲線的對比實驗,每種方法與模型分別運行三次實驗,結果取平均值,結果如表2所示。

表2 不同曲線的實驗結果對比 %
實驗結果表明,Hilbert曲線在性能上優于Zigzag曲線,并且具有更強的魯棒性,基于Hilbert曲線對勒索病毒文件可視化得到的Magnitude圖能很更好地提取到特征,模型能夠對Magnitude圖進行識別和分類從而達到對勒索病毒的檢測和分類。且因該文采用了更深的神經網絡,在采用更大規模數據和進行更深層次的訓練時,模型的分類準確度還能得到更進一步的提高。因樣本涉及Windows、Linux兩大平臺,其中Windows樣本結果分類率達到98.62%,Linux樣本數量雖然較少,分類率也達到了90%,實驗結果表明該模型同樣適用于Linux平臺,更具有普適性。
4 結束語
勒索病毒近年來呈爆發式增長,對用戶文件進行加密勒索,令用戶難以防范,造成巨大損失。此時對勒索病毒進行檢測和分類對于防范和應急響應都具有重要的意義。在基于空間填充曲線可視化的Magnitude圖,通過三種模型進行集成學習投票,無需通過動態執行和靜態逆向分析即可很好地進行勒索病毒家族分類以及良性軟件的識別。
在實驗中發現,模型對于Magnitude圖沒有更好地提取到特征,從而導致個別家族分類率較低,因此下一步將研究更多的特征提取方式,同時將結合勒索病毒文件的asm文件和bytes文件轉換為香農熵和字節類圖以探索更多的可視化方式,并且將勒索病毒家族更多地擴大到Linux平臺以適應企業實際生產環境。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
