機(jī)械設(shè)備多模態(tài)聲源分離方法研究
2023-06-15 09:27:16肖曉萍李自勝
計算機(jī)技術(shù)與發(fā)展 2023年6期
簡 斌,肖曉萍,李自勝,張 楷,袁 昊
(1.西南科技大學(xué) 制造科學(xué)與工程學(xué)院,四川 綿陽 621010;2.西南科技大學(xué) 工程技術(shù)中心,四川 綿陽 621010;3.西南交通大學(xué) 機(jī)械工程學(xué)院,四川 成都 610031)
0 引 言
機(jī)械設(shè)備聲源分離是噪聲故障監(jiān)測與識別的前提條件,目前,機(jī)械設(shè)備混合音頻信號分離通常采用盲源分離方法,即在源信號及傳輸特征未知的情況下,僅依靠接收到的混合信號恢復(fù)各個獨立源信號[1]。畢鳳榮等人[2]通過集合經(jīng)驗?zāi)B(tài)分解與獨立分量分析相結(jié)合的方法,對裝載機(jī)室內(nèi)噪聲信號進(jìn)行盲源分離。侯一民等人[3]運用集合經(jīng)驗?zāi)B(tài)分解與快速獨立分量分析相結(jié)合的方法,對三臺異步電動機(jī)噪聲信號進(jìn)行盲源分離。孫玉偉等人[4]運用快速獨立分量分析方法,對斷路器合閘期間的音頻信號進(jìn)行盲源分離。此外,不同于盲源分離方法,Wang等人[5]通過Vold-Kalman濾波和循環(huán)維納濾波的級聯(lián)濾波方法,對直升機(jī)主、尾旋翼氣動噪聲進(jìn)行分離。嚴(yán)青等人[6]提出一種多元線性擬合的多源噪聲分離方法。上述聲源分離方法均能根據(jù)機(jī)械設(shè)備混合信號恢復(fù)源信號,但盲源分離方法由于分離結(jié)果存在兩個不確定性[7],從而造成分離后聲源信號與機(jī)械設(shè)備對應(yīng)關(guān)系不確定。
近年來,隨著深度學(xué)習(xí)的發(fā)展,多模態(tài)特征融合相關(guān)研究逐漸成為熱點,音視頻特征融合的多模態(tài)聲源分離方法可以依賴不同模態(tài)特征間存在的潛在聯(lián)系,解決單模態(tài)混合音頻信號分離方法存在的聲源分離效果不佳、分離后聲源與目標(biāo)對應(yīng)關(guān)系無法確定等問題。Zhao等人[8]提出一種融合視覺特征與音頻特征的樂器聲源分離方法;Gan等人[9]提出一種融合身體關(guān)鍵點特征、手指運動特征、視覺特征和音頻特征的樂器聲源分離方法;Gao等人[10]提出采用預(yù)訓(xùn)練Faster R-CNN檢測視頻中樂器目標(biāo),再將目標(biāo)視覺特征與音頻特征融合的樂器聲源分離方法;Zhu等人[11]提出一種融合樂器類別信息、單幀視覺特征與音頻特征的樂器聲源分離方法;Xu等人[12]提出一種融合音視頻特征的循環(huán)遞歸聲源分離方法;馬碩[13]提出一種在初分離的基礎(chǔ)上再進(jìn)行細(xì)粒度分離的樂器聲源分離方法。上述多模態(tài)聲源分離方法均能根據(jù)視覺特征分離對應(yīng)聲源信號且能夠取得較好的聲源分離效果。
鑒于多模態(tài)特征融合在聲源分離方面存在的優(yōu)勢與潛力,首次將該方法應(yīng)用于機(jī)械設(shè)備聲源分離研究,針對機(jī)械設(shè)備外觀與聲源特點,該文提出一種多模態(tài)特征融合的機(jī)械設(shè)備聲源分離網(wǎng)絡(luò)模型,以解決單模態(tài)機(jī)械設(shè)備混合音頻信號分離方法存在的聲源對應(yīng)關(guān)系不確定問題。
1 文中方法
1.1 網(wǎng)絡(luò)模型整體結(jié)構(gòu)
提出的機(jī)械設(shè)備多模態(tài)聲源分離網(wǎng)絡(luò)模型受PixelPlayer[8]算法啟發(fā)改進(jìn)而得。PixelPlayer是一種針對樂器聲源分離提出的網(wǎng)絡(luò)模型,該模型屬于雙流結(jié)構(gòu),以樂器視頻流和樂器混合音頻流作為網(wǎng)絡(luò)輸入,整個模型由視頻特征提取網(wǎng)絡(luò)、音頻特征提取網(wǎng)絡(luò)、音視特征融合網(wǎng)絡(luò)三部分組成,其中,混合音頻信號由兩個視頻的獨立音頻信號疊加而成,因此,模型實現(xiàn)無監(jiān)督的聲源分離。針對機(jī)械設(shè)備外觀與聲源的特點,對PixelPlayer模型的音視頻特征提取主干網(wǎng)絡(luò)進(jìn)行改進(jìn),以提升對機(jī)械設(shè)備音視頻特征提取能力,提高聲源分離質(zhì)量,所提網(wǎng)絡(luò)模型整體結(jié)構(gòu)如圖1所示。
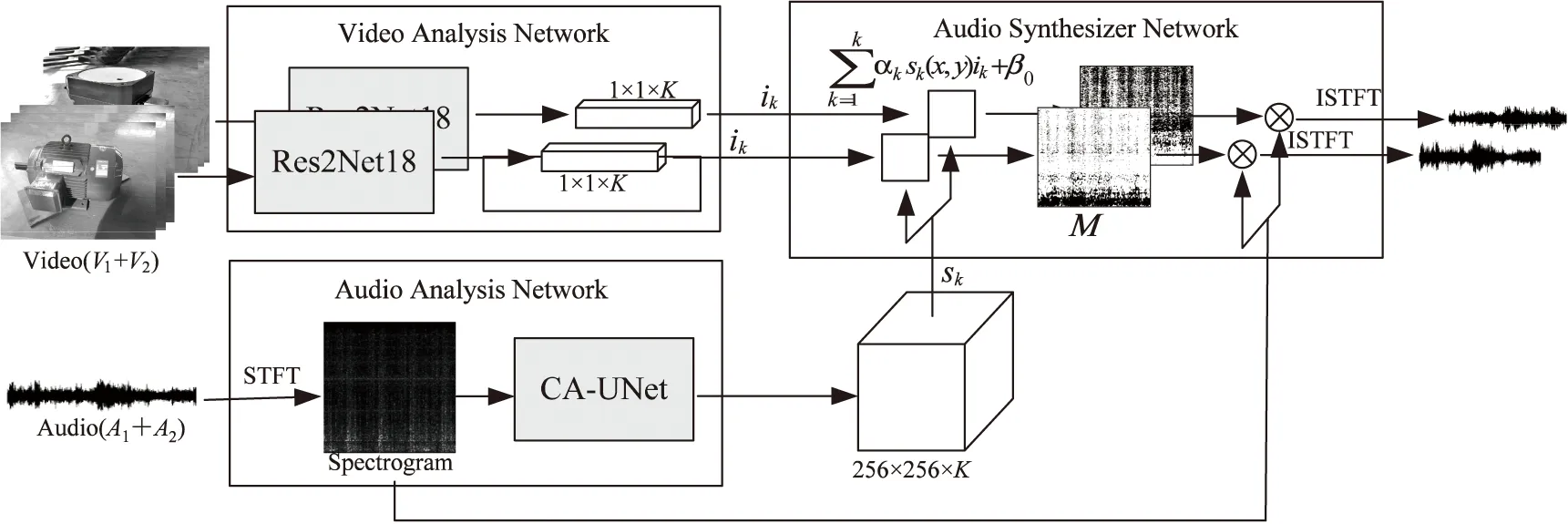
圖1 網(wǎng)絡(luò)模型整體結(jié)構(gòu)
1.2 音頻特征提取網(wǎng)絡(luò)
UNet網(wǎng)絡(luò)設(shè)計之初是為了解決在醫(yī)學(xué)圖像分割中存在的問題[14],其通過引入編碼器、解碼器、融合淺層特征與深層特征等方式有效恢復(fù)圖像的邊界和空間信息,隨后被廣泛應(yīng)用于圖像分割領(lǐng)域,UNet網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。
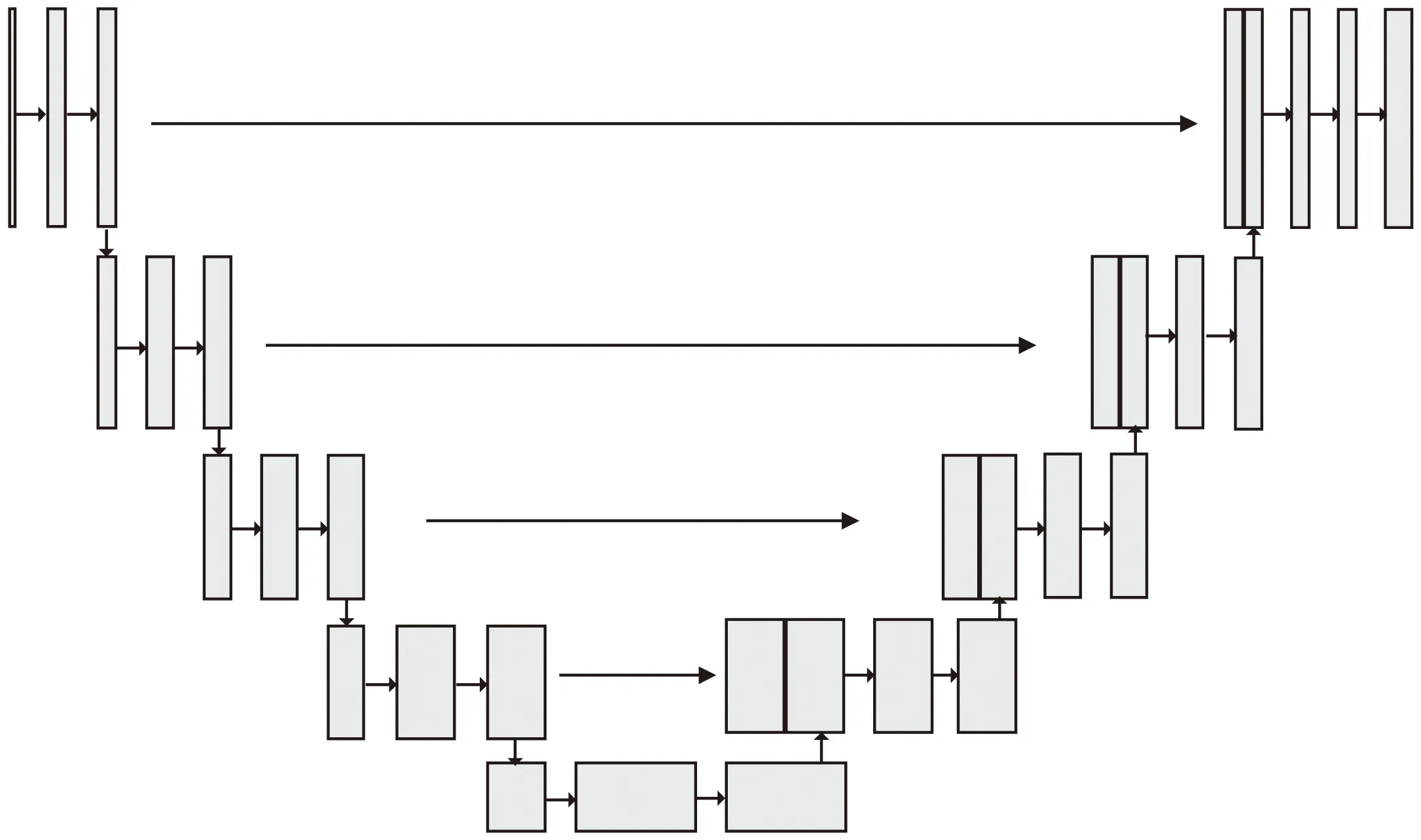
圖2 UNet網(wǎng)絡(luò)結(jié)構(gòu)
UNet網(wǎng)絡(luò)由左側(cè)的編碼器和右側(cè)的編碼器組成,兩者是對稱結(jié)構(gòu),編碼器對圖像進(jìn)行4次下采樣,通過卷積層提取不同深度圖像語義特征并獲取圖像上下文信息。解碼器對特征圖進(jìn)行4次上采樣,將圖像上下文信息傳遞給高分辨率層并恢復(fù)圖像尺寸,再通過跳躍連接與相應(yīng)淺層特征圖拼接,將淺層特征中更多的空間信息與深層特征中更多的語義信息融合,使網(wǎng)絡(luò)學(xué)習(xí)更多不同類型特征,提高網(wǎng)絡(luò)對特征的學(xué)習(xí)與表達(dá)能力。
針對不同機(jī)械設(shè)備聲源相似度高,在混合聲譜圖中不同機(jī)械設(shè)備聲譜特征表現(xiàn)差異小,如果直接連接編碼器的輸出特征與解碼器上采樣之后的特征,由于淺層特征與深層特征語義差異較大,未消除初級噪聲干擾會對模型最后的輸出結(jié)果產(chǎn)生影響,降低聲源分離效果。因此,該文提出在UNet網(wǎng)絡(luò)中引入坐標(biāo)注意力機(jī)制模塊(Coordinate Attention,CA)[15]用以替換編碼器與解碼器之間的直接跳躍連接,增強(qiáng)編碼器中不同特征的空間位置信息表達(dá),抑制干擾噪聲,縮小編碼器與解碼器之間的語義特征差異。將融入CA模塊的UNet網(wǎng)絡(luò)稱為CA-UNet,CA-UNet結(jié)構(gòu)如圖3所示。
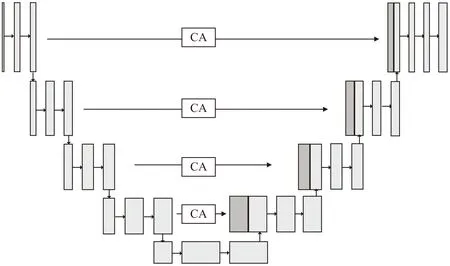
圖3 CA-UNet網(wǎng)絡(luò)結(jié)構(gòu)
其中,CA模塊是一個可以用來增強(qiáng)信息表達(dá)能力的計算單元,它可以將任意特征X=[x1,x2,…,xc]∈C×H×W作為輸入,并輸出一個有著增強(qiáng)表達(dá)能力的同尺寸輸出特征Y=[y1,y2,…,yc]∈RC×H×W。該模塊通過精準(zhǔn)的位置信息對通道關(guān)系和遠(yuǎn)距離依賴關(guān)系進(jìn)行編碼,具體步驟可分為坐標(biāo)信息嵌入和坐標(biāo)注意力生成,CA模塊結(jié)構(gòu)如圖4所示。
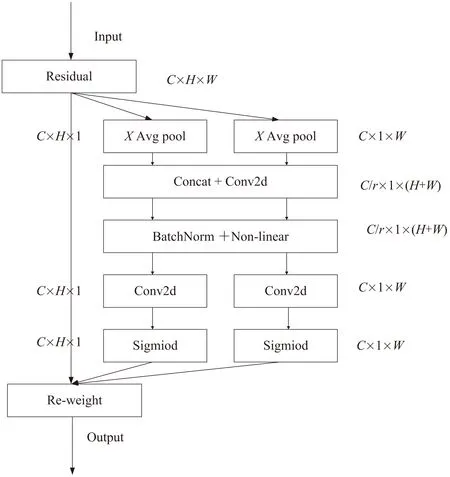
圖4 CA模塊結(jié)構(gòu)
對于坐標(biāo)信息嵌入,全局池化方法通常用于通道注意力機(jī)制編碼全局的空間信息,但它將全局空間信息壓縮到一個通道維度中,難以保存特征中存在的位置信息,而位置信息對于提取特征圖中的空間結(jié)構(gòu)特征至關(guān)重要。為了提高注意力模塊提取具有精準(zhǔn)位置信息的空間結(jié)構(gòu)特征,CA模塊將全局池化分解為兩個一維特征編碼過程,分別沿水平X和垂直Y兩個空間方向壓縮特征。對于特征圖F∈RC×H×W,在每個通道上使用尺寸為(H,1)和(1,W)的平均池化核分別沿著水平坐標(biāo)X方向和垂直坐標(biāo)Y方向進(jìn)行編碼,其計算如式(1)(2)所示。
(1)
(2)
通過這種編碼方式,返回一對方向感知注意力圖,它們在一個空間方向捕獲遠(yuǎn)距離依賴關(guān)系,同時在另一個空間方向保留精確的特征位置信息。這有助于網(wǎng)絡(luò)更準(zhǔn)確地定位當(dāng)前更感興趣的區(qū)域。
對于坐標(biāo)注意力生成,將上述坐標(biāo)信息嵌入得到的注意力圖進(jìn)行拼接,再對其進(jìn)行卷積操作,其計算如式(3)所示。
f=σ(F1([Zh,Zw]))
(3)
式中,σ為ReLU激活函數(shù),F1為1×1的卷積運算,[·,·]是將特征沿通道進(jìn)行拼接,為降低網(wǎng)絡(luò)復(fù)雜度,通常采用下采樣比例r來壓縮特征圖f通道數(shù),文中r=32,則f∈RC/r×(H+W)是在水平方向和垂直方向上編碼空間信息的中間特征映射,將特征f按通道維度劃分為兩個張量fw∈RC/r×W和fh∈RC/r×H,再分別進(jìn)行卷積操作,使其恢復(fù)到輸入特征的通道數(shù)目,其計算如式(4)(5)所示。
gh=σ(Fh(fh))
(4)
gw=σ(Fw(fw))
(5)
式中:σ為Sigmoid激活函數(shù),Fh和Fw為1×1卷積運算,gh和gw為坐標(biāo)注意力機(jī)制矩陣,則通過坐標(biāo)注意力機(jī)制的輸出特征yc可以用公式(6)表示。
(6)
1.3 視頻特征提取網(wǎng)絡(luò)
ResNet[16]是一種將殘差模塊的相同拓?fù)浣Y(jié)構(gòu)以跳躍連接的方式進(jìn)行堆疊而構(gòu)建的深度網(wǎng)絡(luò)結(jié)構(gòu),該結(jié)構(gòu)的提出有效解決了隨著網(wǎng)絡(luò)深度的增加而導(dǎo)致的梯度消失和爆炸等問題。ResNet18雖然能有效解決梯度消失和爆炸的問題,但應(yīng)用于機(jī)械設(shè)備視覺特征提取場景時,存在特征提取尺度單一、語義特征不夠豐富等不足。因此,該文提出將ResNet18網(wǎng)絡(luò)中的殘差模塊改進(jìn)為Res2Net[17]中的多尺度特征提取結(jié)構(gòu),該結(jié)構(gòu)利用特征分組的思想,在殘差塊內(nèi)以多組卷積替換原來單一卷積,并以層級殘差方式連接,通過構(gòu)建的多組不同尺度卷積層結(jié)構(gòu)增加輸出特征感受野,提高網(wǎng)絡(luò)對機(jī)械設(shè)備細(xì)粒度視覺特征提取,改進(jìn)前后的殘差塊結(jié)構(gòu)如圖5所示。
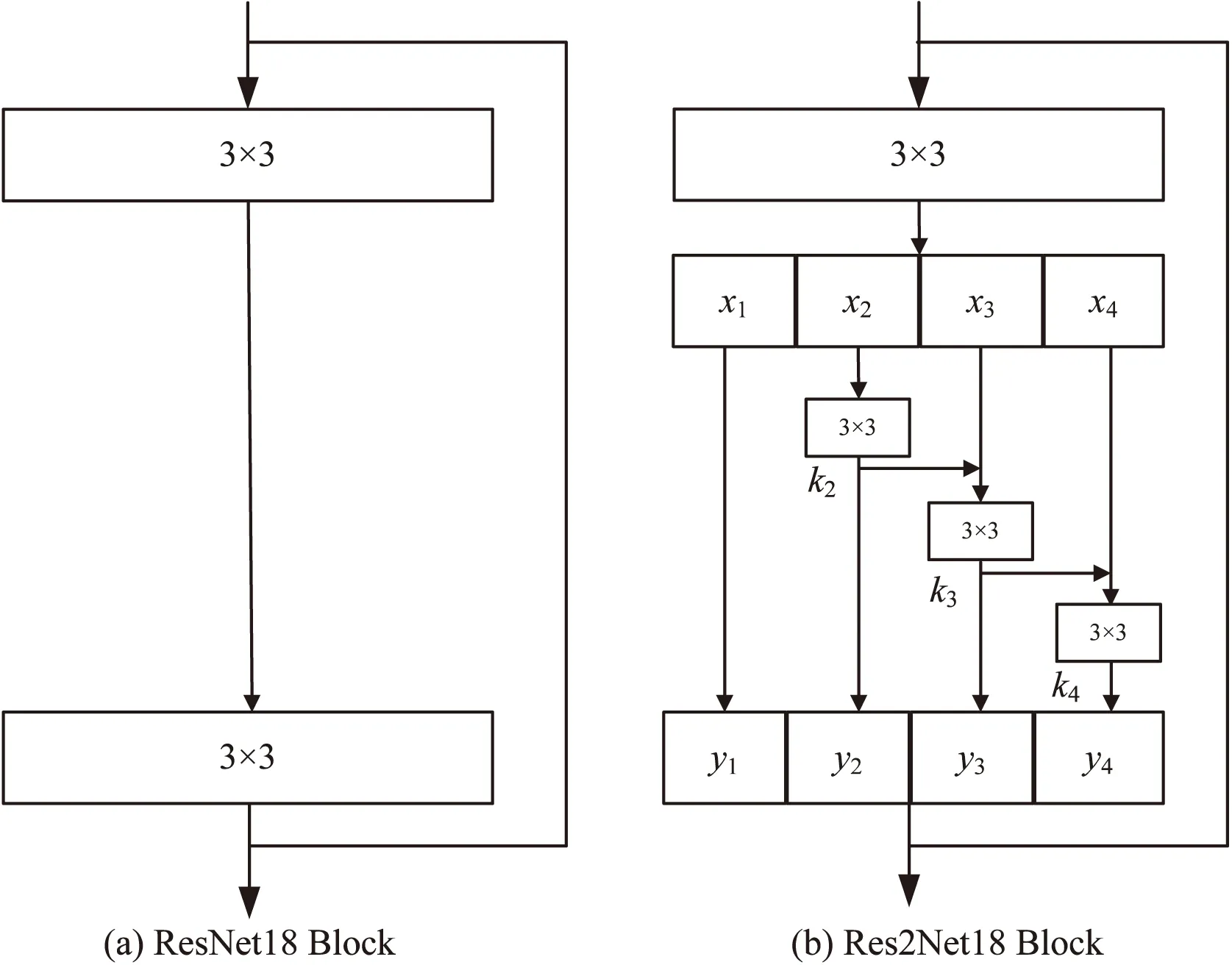
圖5 殘差模塊結(jié)構(gòu)
圖5(a)是ResNet18網(wǎng)絡(luò)中的殘差塊結(jié)構(gòu),包含兩個3×3卷積層;圖5(b)是改進(jìn)后的殘差塊結(jié)構(gòu),將ResNet18殘差塊中的第二個3×3卷積替換成多組不同尺度的3×3卷積,達(dá)到多尺度特征提取的目的。其中引入的超參數(shù)s,將經(jīng)過3×3卷積層輸出的特征圖F∈RC×H×W按通道劃分為S組,即每一組特征xi的形狀為F∈RC/s×H×W,其中i∈{1,2,…,s},在保持空間特征不變的同時,對經(jīng)過3×3卷積輸出的操作記為Ki()。第1組特征x1不經(jīng)過卷積操作直接輸出y1=x1,第2組特征x2,經(jīng)過3×3卷積層輸出y2=K2(x2),第3組特征x3和y2做特征融合后再通過3×3卷積層后輸出y3=K3(x3+y2),計算推導(dǎo)如式(7)所示。
(7)
將具有多尺度特征提取結(jié)構(gòu)的ResNet18網(wǎng)絡(luò)稱為Res2Net18,采用超參數(shù)s=4的Res2Net18作為視覺特征提取主干網(wǎng)絡(luò),網(wǎng)絡(luò)結(jié)構(gòu)參數(shù)見表1。

表1 Res2Net18網(wǎng)絡(luò)結(jié)構(gòu)
1.4 音視頻特征融合網(wǎng)絡(luò)
音視頻特征融合階段將提取到的機(jī)械設(shè)備視頻特征融入音頻特征中,視頻特征ik的形狀F∈k×1×1,混合音頻特征sk的形狀F∈k×256×256,k是音視頻特征通道數(shù)。在特征融合時,按特征通道將視覺特征ik與音頻特征ik(x,y)每一個特征元素相乘,再按特征通道將對應(yīng)特征元素相加,則生成視覺特征對應(yīng)的聲源掩碼Μ,掩碼Μ的形狀F∈1×256×256,再將掩碼與混合音頻頻譜結(jié)合即可得到視覺特征對應(yīng)的獨立聲源頻譜,音視頻特征融合計算如公式(8)所示。
(8)
式中,αk和β0是一組能夠自適應(yīng)學(xué)習(xí)的權(quán)重系數(shù),在訓(xùn)練時自動調(diào)整以加快模型的收斂速度。
2 實驗與分析
2.1 實驗環(huán)境
本次實驗采用的深度學(xué)習(xí)框架是PyTorch1.10.0,編程語言為Python3.6.2,在此基礎(chǔ)上搭建實驗運行環(huán)境。電腦硬件方面,操作系統(tǒng)為Windows10專業(yè)版,CPU為i5-10400F,16G內(nèi)存,并使用NVIDIA GeForce RTX3060顯卡12G顯存的GPU對網(wǎng)絡(luò)訓(xùn)練進(jìn)行加速。
2.2 數(shù)據(jù)集及預(yù)處理
數(shù)據(jù)集來源于網(wǎng)絡(luò)和仿真模擬拍攝,共計5種機(jī)械設(shè)備,包括齒輪箱、電機(jī)、剪切機(jī)、機(jī)床和工業(yè)風(fēng)扇,每種機(jī)械設(shè)備有40條視頻數(shù)據(jù),總計200條,每條視頻中僅含有一種機(jī)械設(shè)備與相應(yīng)音頻信號,視頻時長由10秒到3分鐘不等,訓(xùn)練集與驗證集按8∶2隨機(jī)劃分。
隨機(jī)裁剪兩段不同類型的機(jī)械設(shè)備音頻信號,將兩段音頻信號混合模擬混合音頻信號。以11 025 Hz的采樣頻率對混合音頻采樣,共計65 536個采樣點用于訓(xùn)練,取每1 022個采樣點為一幀,幀移為256個采樣點,窗函數(shù)為漢明窗的短時傅里葉變換將音頻信號由時域轉(zhuǎn)為頻域,生成幅度譜和相位譜,再選擇幅度譜作為音頻特征提取網(wǎng)絡(luò)的輸入,輸入網(wǎng)絡(luò)前通過下采樣將幅度譜尺寸調(diào)整為256×256。
視頻特征提取網(wǎng)絡(luò)輸入機(jī)械設(shè)備視頻幀圖像,隨機(jī)選擇音頻段內(nèi)相應(yīng)的視頻幀圖像,如果將該音頻段內(nèi)全部圖像送入網(wǎng)絡(luò),會造成信息冗余,不利于網(wǎng)絡(luò)訓(xùn)練。因此,對于每個視頻選擇3幀圖像,輸入視頻特征提取網(wǎng)絡(luò)前采用雙線性插值方法將圖像尺寸調(diào)整為224×224。
2.3 評價指標(biāo)
實驗采用的評價指標(biāo)為BSSEVAL[18],BSSEVAL通常用來評估模型的分離性能。根據(jù)BSSEVAL,聲源分離性能評估使用3個定量值表示,分別是信噪失真比(Source to Distortion Ratio,SDR)、信噪干擾比(Source to Interference Ratio,SIR)和信噪偽影比(Source to Artifact Ratio,SAR)。這3個評價指標(biāo)的核心思想是將預(yù)測信號y分解為目標(biāo)信號starget、干擾信號einterf、噪聲信號enoise和誤差信號eartif,其計算如式(9)所示。
y=starget+einterf+enoise+eartif
(9)
則SDR、SIR和SAR的計算如式(10)(11)和(12)所示。
(10)
(11)
(12)
其中,SDR反映聲源分離的總體效果,SIR反映分離算法對干擾信號的抑制能力,SAR反映分離算法對引入噪聲的抑制能力。因此,評估指標(biāo)SDR、SIR和SAR的值越高表明分離算法性能越好,實驗采用基于Python的開源聲音評估庫mir_eval[19]對SDR、SIR和SAR的值進(jìn)行計算。
2.4 訓(xùn)練參數(shù)及目標(biāo)
模型訓(xùn)練選擇隨機(jī)梯度下降法,動量值為0.9,視覺特征網(wǎng)絡(luò)學(xué)習(xí)率為0.000 1,音頻特征網(wǎng)絡(luò)學(xué)習(xí)率為0.001,特征融合網(wǎng)絡(luò)學(xué)習(xí)率為0.001,設(shè)置訓(xùn)練迭代為100個epoch,批次大小為8,音視頻特征通道數(shù)K=32。
聲源分離的目標(biāo)是獲取理想比值掩碼(Ideal Ratio Mask,IRM),通過計算單一音頻與混合音頻幅值比獲得,計算如式(13)所示。
(13)
式中,(t,f)代表聲譜圖的時間與頻率坐標(biāo),Sn和Smix是單一音頻和混合音頻的幅度譜,由此,可以計算每一種音頻在混合音頻中的真實比值掩碼M,在實驗中,將真實比值掩碼M作為訓(xùn)練目標(biāo)。
2.5 結(jié)果與分析
實驗在兩種不同類型機(jī)械設(shè)備音頻信號混合的情況下,模擬文中方法對聲源分離的效果。為了對比網(wǎng)絡(luò)模型改進(jìn)效果,也使用相同數(shù)據(jù)集在PixelPlayer模型上進(jìn)行訓(xùn)練與評估,兩次訓(xùn)練與評估相關(guān)超參數(shù)保持一致,實驗結(jié)果見表2。

表2 模型改進(jìn)前后對比實驗
從表2可知,通過對音頻特征提取的UNet網(wǎng)絡(luò)中添加CA模塊,對視覺特征提取的ResNet18網(wǎng)絡(luò)中添加多組不同尺度的卷積結(jié)構(gòu),改進(jìn)后的模型與PixelPlayer模型相比在SDR和SAR上分別有0.92 dB和4.31 dB的提高。從而可以看出,提出的兩種特征提取主干網(wǎng)絡(luò)能夠提高對機(jī)械設(shè)備的音視頻特征提取能力,提升模型對機(jī)械設(shè)備的聲源分離效果。
為了可視化對比文中方法和PixelPlayer模型對聲源分離效果的差異,選擇剪切機(jī)和電機(jī)混合音頻分離前后聲譜圖像作為對比,分離效果如圖6所示。

圖6 模型改進(jìn)前后分離效果對比
圖6中,Mixture是混合聲譜圖,Ground Truth為混合前單一聲源的聲譜圖像,上側(cè)為剪切機(jī)下側(cè)為電機(jī)。對于分離后剪切機(jī)的聲譜圖,文中方法更加接近真實的聲譜圖,而PixelPlayer模型中還殘留少量電機(jī)的聲譜能量。對于分離后電機(jī)的聲譜圖,文中方法表現(xiàn)也更加優(yōu)異,分離后的整體聲譜變化更加接近真實的聲譜圖,而PixelPlayer模型分離后的電機(jī)聲譜圖還殘留大量剪切機(jī)的能量,聲譜圖整體變化趨勢也相差較大,說明PixelPlayer模型并不能較好地分離機(jī)械設(shè)備聲源信號。
為了對比文中使用的多尺度特征提取結(jié)構(gòu)與CA模塊對聲源分離的影響,設(shè)計了對比消融實驗。通過搭配不同的特征提取網(wǎng)絡(luò),探究其不同模塊對聲源分離的影響程度,音頻特征提取網(wǎng)絡(luò)和視頻特征提取網(wǎng)絡(luò)分別為CA-UNet+Res2Net18、CA-UNet+ResNet18、UNet+Res2Net18和UNet+ResNet18,實驗結(jié)果見表3。
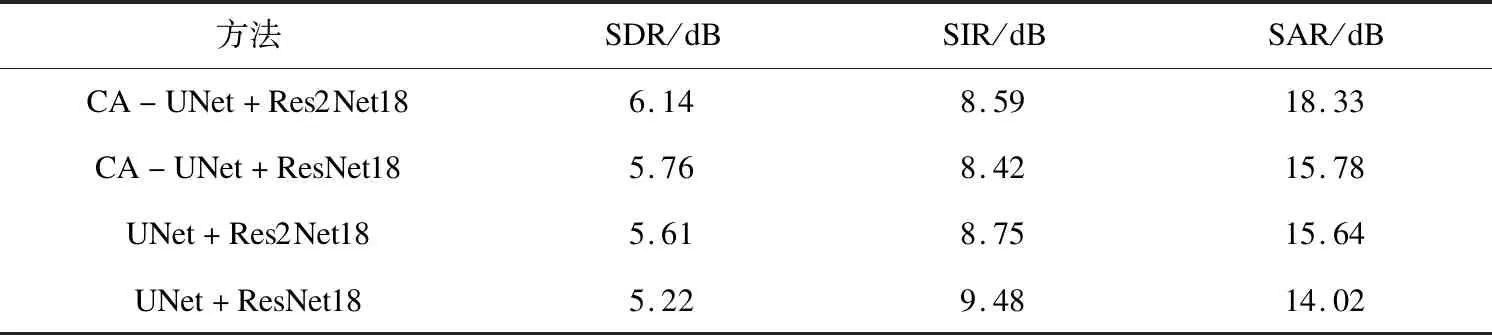
表3 消融實驗
從表3可知,含有多尺度特征提取結(jié)構(gòu)和CA模塊的音視頻特征組合網(wǎng)絡(luò),獲得了最好的分離效果,在SDR和SAR上表現(xiàn)最優(yōu)。說明多尺度特征提取結(jié)構(gòu)和CA模塊均能夠提高網(wǎng)絡(luò)對機(jī)械設(shè)備音視頻特征的提取能力,提高對機(jī)械設(shè)備聲源的分離效果。當(dāng)音頻特征提取網(wǎng)絡(luò)相同時,具有多尺度特征提取結(jié)構(gòu)的Res2Net18網(wǎng)絡(luò)對聲源分離的總體效果SDR上有0.38 dB和0.39 dB的提高。當(dāng)視頻特征提取網(wǎng)絡(luò)相同時,具有坐標(biāo)注意力模塊的CA-Unet網(wǎng)絡(luò)對聲源分離的總體效果SDR上有0.53 dB和0.54 dB的提高,可以看出,音頻特征提取網(wǎng)絡(luò)的改進(jìn)對聲源分離總體效果影響更大。
為了進(jìn)一步驗證所提多模態(tài)聲源分離方法在機(jī)械設(shè)備聲源分離任務(wù)的先進(jìn)性,將所提模型與文獻(xiàn)[11-12]所提多模態(tài)聲源分離模型進(jìn)行對比。文獻(xiàn)[11-12]所提模型與PixelPlayer模型結(jié)構(gòu)類似,特征提取主干網(wǎng)絡(luò)均為ResNet18和UNet,不同之處在于文獻(xiàn)[11]所提模型的視覺特征提取網(wǎng)絡(luò)輸入為單幀圖像且在聲源分離過程中融入聲源物體的類別信息。而文獻(xiàn)[12]所提模型按循環(huán)遞歸方式進(jìn)行聲源分離,并在分離時通過殘差UNet對分離頻譜進(jìn)行修正。使用相同數(shù)據(jù)集對上述兩種模型進(jìn)行訓(xùn)練與評估,訓(xùn)練與評估相關(guān)超參數(shù)均保持一致,實驗結(jié)果見表4。

表4 不同模型對比實驗
從表4可知,所提模型在SDR和SAR上均取得最優(yōu)結(jié)果,SIR略低。與文獻(xiàn)[11-12]所提模型的主要不同在于,文中模型對特征提取主干網(wǎng)絡(luò)進(jìn)行改進(jìn),以提高對機(jī)械設(shè)備音視頻特征提取能力,而文獻(xiàn)[11]模型中融入聲源類別信息對聲源分離效果的提升并不明顯,而文獻(xiàn)[12]模型在分離時使用殘差UNet對分離頻譜進(jìn)行修正,與文獻(xiàn)[11]模型相比使用殘差UNet對分離頻譜進(jìn)行修正有效改善了對機(jī)械設(shè)備聲源分離效果,在SIR上達(dá)到最優(yōu)表現(xiàn),但在SDR和SAR上略低于文中所提模型。
3 結(jié)束語
針對單模態(tài)混合信號分離方法存在的無法確定機(jī)械設(shè)備與聲源對應(yīng)關(guān)系問題,提出一種多模態(tài)特征融合的機(jī)械設(shè)備聲源分離方法。與單模態(tài)分離方法僅依靠音頻信號進(jìn)行分離不同,該文將機(jī)械設(shè)備視覺特征融入音頻特征中,通過融合機(jī)械設(shè)備音視頻特征生成視覺特征對應(yīng)聲源掩碼,將聲源掩碼與混合音頻頻譜結(jié)合得到獨立聲源頻譜,從而實現(xiàn)根據(jù)視覺特征分離對應(yīng)聲源信號。實驗結(jié)果表明,所提機(jī)械設(shè)備多模態(tài)聲源分離方法,能夠有效對兩種不同類型的機(jī)械設(shè)備混合音頻信號進(jìn)行分離,通過改進(jìn)的Res2Net18和CA-UNet網(wǎng)絡(luò)提高對機(jī)械設(shè)備音視頻特征提取能力。與現(xiàn)有三種多模態(tài)聲源分離模型相比,所提模型在機(jī)械設(shè)備聲源分離任務(wù)上具有明顯優(yōu)勢,為機(jī)械設(shè)備混合音頻信號分離提供了新的解決方法。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學(xué)工程學(xué)報(2017年6期)2017-02-10 05:11:45
湖北經(jīng)濟(jì)學(xué)院學(xué)報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機(jī)學(xué)院學(xué)報(2015年4期)2015-02-28 14:30:00
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
計算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
