基于局域社交網絡的輿情溯源算法研究
2023-06-21 19:20:21張欣王麗娟沐雅琪
現代信息科技 2023年9期
關鍵詞:網絡安全
張欣 王麗娟 沐雅琪


摘? 要:隨著互聯網技術的日益普及,加快了信息在網絡中傳播速度及影響。信息體量增加的同時,許多虛假輿情信息也應運而生,輿情信息的廣泛傳播會對國家、社會以及個人利益造成難以控制的負面影響。因此,需采用技術手段對網絡中的輿情信息進行溯源研究,從而保證網絡安全。文章提出了一種輿情溯源算法,并通過實驗結果表明:該算法具有準確率較高、錯誤距離較小的優點,適合在局域社交網絡中應用,對網絡安全具有重要現實意義。
關鍵詞:社交網絡;信息溯源;傳播中心性;網絡安全
中圖分類號:TP312? 文獻標識碼:A? 文章編號:2096-4706(2023)09-0177-04
Abstract: With the increasing popularity of Internet technology, the speed and influence of information dissemination in the network have been accelerated. With the increase of information volume, much false public opinion information also emerges as the times require. The wide spread of public opinion information will cause uncontrollable negative impact on the interests of the country, society and individuals. Therefore, it is necessary to use technical means to trace the source of public opinion information in the network to ensure network security. This paper proposes a public opinion traceability algorithm, and the experimental results show that the algorithm has the advantages of high accuracy and small error distance, which is suitable for application in local social network and has important practical significance for network security.
Keywords: social network; information tracing; communication centrality; network security
0? 引? 言
隨著互聯網的日益普及與飛速發展,人們的生活也發生了巨大變化,越來越方便的在線交流功能極大地降低了人們生活的時間成本與社交成本,導致人們對于社交網絡的依賴性逐漸增加[1]。社交網絡最初只是獲取信息與資源的平臺,現已成為生活和情感的延續。因此,許多網民在運用社交網絡的時候,已經不僅僅是單純地通過社交網絡獲取信息與資源,而是會更加主動地去創造并傳播信息。與此同時,隨著網絡中信息傳播量的增多,有些為了達到某個負面影響的虛假輿情信息也隨之出現,但由于社交網絡的發展及使用速度過快,用戶發布信息的門檻較低,編輯和傳播的方式也越來越簡單,加之民眾對于網絡的依賴性愈加嚴重,致使監管人員無法及時地對社交網絡中全部的信息進行有效監管,因此社交網絡也變成了網絡輿情信息滋生的溫床。如果任由一則虛假的輿情信息在網絡中肆意傳播且不加以控制,將會造成民眾的恐慌并引發后續的公共信任危機事件,造成惡劣的社會影響[2,3]。
社交網絡中傳播的信息可以分為正面導向信息和負面導向信息[2]。特別是未經驗證的負面導向信息,在經過刻意的夸大修飾后,更能激發人們的興趣,并且總是能伴隨一定規模、一定熱度的傳播。例如,在2022年廣為流傳的“騰訊云數據庫泄露”“死亡的鳥類可以傳播猴痘病毒”“0蔗糖就是無糖”等虛假輿情信息,這些輿情信息在人群中進行快速傳播,造成了混亂影響。盡管后期有關部門及相關機構對上述輿情信息進行辟謠處理,但仍然對網絡造成了不良影響,如不及時控制,甚至會影響社會公序良俗和經濟的發展。
在現實世界中,當一個用戶接收到一則虛假的輿情信息,該用戶可以選擇相信或者不相信。如果該用戶不相信會直接丟棄這條信息,但如果該用戶相信了這條信息,那么就有一定概率會向該用戶的親朋好友繼續傳播,因此社交網絡中的傳播方向具有多向性和隨機性的特征[4]。我們可將每個人所處的社交網絡提取成為規模較小的局域社交網絡,用戶抽象成為局域社交網絡中的節點,某個用戶的親朋好友即為局域社交網絡中的鄰居節點,從而得到以每個用戶本身作為根節點擴展得到的局域社交網絡結構。針對一條輿情信息,我們假設一個節點有“相信”“不相信”兩個狀態,并且在節點之間無指定的傳播方向,即輿情信息是在無向網絡中進行傳播,并采用SI模型來模擬輿情信息的擴散,以此來驗證輿情溯源算法的有效性。
1? 基于局域網絡中的信息溯源方法研究
1.1? 構建局域網絡
生物代謝網、食物鏈(網)等,都是自古時候起已經存在的網絡。對人類社會而言,只要是有人群的時間與空間,就會有網絡。進一步地,隨著人與人之間的溝通、互動、往來等,引發了眾多學者對于社交網絡的深入研究。
伴隨著互聯網和計算機技術的發展,使得網絡中產生的現象具有可計算性,因此眾多學者聚焦于人群的行為與網絡之間互動的可預測性。為了更好地探究社交網絡領域,結合圖論的相關內容來進行分析研究。
圖是事物與聯系的集合體。圖可以用于表現網絡中各種事物的關系,是網絡結構信息的抽象體現。在現實世界中,人與人之間存在社交關系,所以采用圖論的觀點進行分析,可以將用戶和用戶之間的關系用圖來表示。
首先,具有共同興趣愛好,或共處于某一局域網絡的用戶,可以將其抽象為一個局域社交網絡。其次,在這個局域社交網絡中,用戶可以抽象為不同的節點,用戶之間存在互動關系即代表著兩個節點之間存在連邊關系。當有一則輿情信息在局域社交網絡中進行傳播,使用溯源算法可以快速定位到源節點,將輿論信息對于網絡的負面影響最小化。因此,在進行溯源計算時,需要根據局域社交網絡的結構與受感染節點集合構建出感染網絡。在感染網絡中運用溯源算法,快速準確定位源節點[5]。
在局域社交網絡中,每條邊將兩個節點連接起來,可以用式(1)進行表示:
式中,E代表的是網絡中的連邊集合,V代表的是網絡中的節點集合,i,j分別代表網絡中的不同節點。由式(1)得到的局域社交網絡連邊關系可以構成鄰接矩陣,從而進行計算。
將局域社交網絡結構轉換為鄰接矩陣可以表示為式(2)。在式(2)中,若a12=1代表在網絡環境中節點1和節點2存在連邊關系,那么映射到現實世界則代表著兩個用戶之間存在聯系,可能互為好友、同學等。
1.2? 傳播路徑分析
以經典的傳染病傳播模型—SI模型為例,S代表易感者,是容易被疾病感染的用戶;I代表感染者,指的是已經被感染的用戶,并且處于I態的患者還存在一定概率去感染其他處于S態的用戶。在信息傳播領域,通常采用傳染病模型來類比信息傳播過程[6]。在一個局域的社交網絡中,對于一則信息,節點會處于“相信”和“不相信”兩種狀態的其中之一,“相信”即為該節點已經被感染,對應SI模型中的I態;“不相信”即代表著這個節點未被感染,處于易感態,對應SI模型中的S態。當有一則輿論信息在局域社交網絡傳播后,處于感染態的節點會向自己周邊的節點進行傳播感染,在經過一定的時間步長后形成局域感染網絡。因此最初時刻處于感染態的節點是感染網絡的核心節點,感染網絡中其他節點都是被這一節點感染所導致的,所以這一核心節點在網絡中的節點重要性程度要高于其他感染節點。由于信息傳播在網絡中存在隨機性的特征,因此以一個包含10個節點的原生網絡為例,來模擬傳播的過程,如圖1所示。
圖1(a)代表的是某一時刻的原生網絡,其中2號節點代表該節點處于感染態,其他節點但處于易感態。當輿情信息開始由2號節點傳播后,第一個感染輪次t1內,首先感染了6、8、10號節點;第二個輪次t2在t1輪次已經感染的節點的基礎上,繼續感染了1、4號節點;第三個輪次t3在上述兩個感染輪次之后,繼續感染了7號節點。因此圖1(a)所示的網絡在經過了三個感染輪次之后,依次感染了網絡中6、10、1、8、4、7號節點,最終得到結果為圖1(b)的感染網絡。根據SI傳播模型的特點,在圖1所示的網絡中,如果一個節點被感染,那么該節點將一直處于感染態,不會被再次感染。
由圖1可知在局域社交網絡中信息傳播的過程,為了簡述輿情算法計算流程,可列出輿情溯源步驟如下所述:
1)初始化處理階段:獲取數據集,對數據進行預處理,構建局域社交網絡G。此時網絡G即為原生網絡,所有節點都處于易感染狀態,存在一定概率被感染。
2)信息傳播階段:在一定的傳播輪次之內,構建被感染節點的集合。如果節點被感染,則加入感染節點集合SI中。當信息傳播停止后,根據感染節點集合與鄰接矩陣,得到所有的受感染節點與感染子圖GI。
3)計算階段:根據感染子圖GI中的結果,采用溯源算法進行計算,得到最終信息溯源結果。
1.3? 溯源算法建立
輿情溯源算法(KRC)的計算思想如下:根據原生網絡G中誘導出的感染子圖GI,在GI的基礎上構建以節點v為根節點的廣度優先搜索樹Tbfs(v),之后進行溯源運算。KRC算法計算流程如圖2所示。
圖2的計算流程實現了基于SI信息傳播模型的溯源算法,通過溯源計算可以快速定位到輿情傳播的源節點,進一步地可以對網絡中的源節點進行處理,凈化用戶上網環境,為網絡中的信息安全提供了有力保障。
2? 實驗結果與分析
2.1? ?數據集介紹
為了驗證溯源算法的有效性,本文設計了仿真對比實驗來進行驗證。對比方法采用目前溯源領域中具有代表性的方法,分別是距離中心性算法(DC)、Jordan中心性算法(JC)、傳播中心性算法(RC)[7]。在實驗過程中,采用SI模型來模擬信息傳播,代表著網絡中的節點只可能處于感染態(I態)和易感態(S態)。在此模型下,被感染的節點會一直處于感染態并且會以一定的概率持續感染它的相鄰節點。與此同時,選用三個具有代表性的網絡進行模擬實驗,分別是人工網絡SCALE-FREE、真實網絡HARM及POWER-GRID。三個網絡的詳細信息如表1所示。
本文選用了三個具有代表性的網絡,其節點數量與連邊數量符合局域網絡的特征,使實驗結果更具有說服力。
2.2? 實驗指標選取
想要評價一個溯源算法的效果,一般采用溯源檢測率 (Detection Rate)和錯誤距離(Error Hops)來衡量。其中,溯源檢測率的計算方式如式(3)所示:
在上述公式中,M代表溯源計算的總次數,MT代表監測到真實源節點的次數。因此,如果檢測率的值越大,則說明溯源方法的準確率越高。
錯誤距離的計算方式采用式(4)可以表示為:
在上述公式中,v1代表通過溯源算法計算得到的源節點,v2代表網絡中的真實源節點。錯誤距離代表的是兩者之間的差值。因此,如果錯誤距離的值越小,則說明通過溯源方法計算得到的源節點距離網絡中真實源節點距離越小,溯源結果的準確率越高。
2.3? 實驗結果
2.3.1? 檢測率分析
圖3是四種算法在SCALE-FREE、HARM和POWER-GRID三個網絡中隨著感染節點數目的增加,檢測率所發生的變化。在實驗過程中,為了克服計算結果的隨機性,每組數據是通過信息傳播模型感染1 000次取平均值計算得到的。從圖中可以得知,隨著網絡規模與感染節點數目的增加,所有的計算方法準確率都呈下降趨勢,但KRC算法總體表現仍然優于其他算法。
值得注意的是在POWER-GRID網絡中,所有算法的檢測率均低于其他網絡,經過分析發現這是由于該網絡本身的特性導致的。POWER-GRID是一個較為稀疏的網絡,當網絡中一定數目的節點被感染之后,由于其稀疏的特性,導致了很難再感染網絡其他的節點,因此造成了檢測率偏低這一問題。但是通過實驗結果可以發現,盡管不同的網絡的稠密程度不同,KRC算法的表現仍優于其他算法。
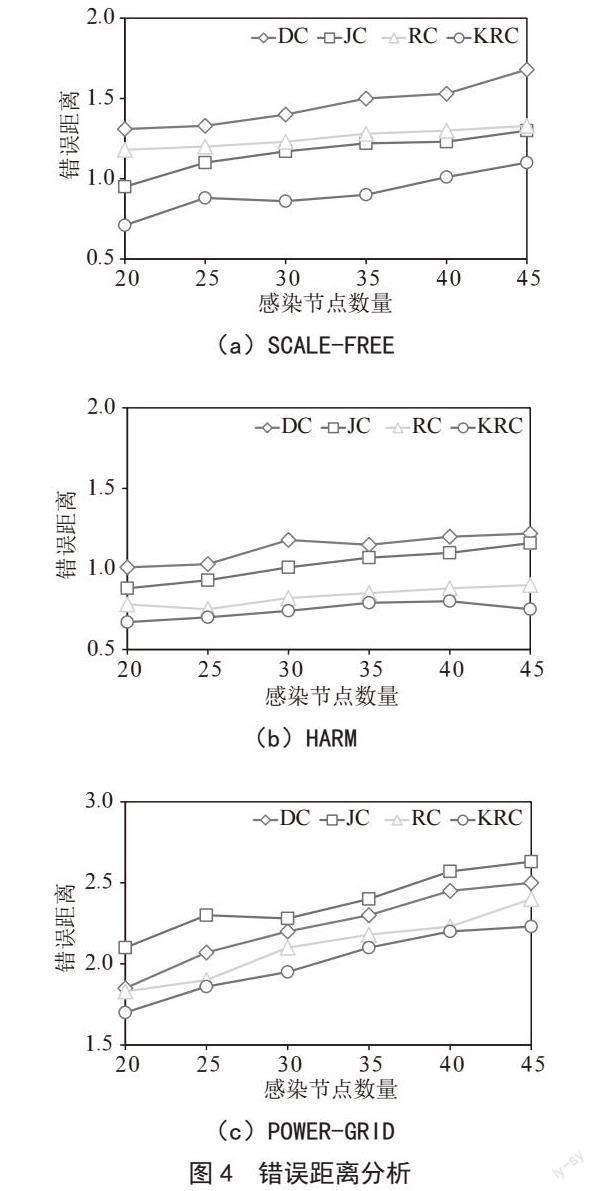
2.3.2? 錯誤距離分析
圖4是四種算法在SCALE-FREE、HARM和POWER-GRID三個網絡中隨著感染節點數目的增加,錯誤距離所發生的變化。算法通過計算所得到的錯誤距離越小,代表著其與真實源節點的距離越小,說明算法溯源性越強。同樣地,為了克服計算結果的隨機性,每組數據是通過信息傳播模型感染1 000次取平均值計算得到的。從實驗結果中我們可以發現,隨著網絡規模與感染節點數目的增加,所有算法的錯誤距離都有所增加,但KRC算法總體表現仍然優于其他算法且增長較為平穩。
同樣地,在POWER-GRID網絡中,所有算法的錯誤距離均高于其他網絡,原因在檢測率分析處已經進行詳解,因此此處不再進行贅述。
結合溯源檢測率和錯誤距離的實驗結果表明,在局域網絡中,本文所提出的溯源算法KRC具有準確率高、錯誤距離較小的優點。
3? 結? 論
隨著計算機技術的飛速發展,社交網絡的應用已經逐漸成熟。但與此同時隨著用戶數目的增加,網絡關系變得愈發復雜,信息傳播的方式也愈發多樣化。此時網絡中所產生的信息質量將無法保證,有些不實消息進而演變成輿情信息,如果縱容輿情信息在網絡中持續發酵,將對社會產生危害。由此可見,對輿情信息進行溯源是十分必要的[8-10]。
本文聚焦于局域社交網絡,針對現有算法對于網絡結構特性分析不足,從而導致了溯源結果準確率不高的現狀,對局域網絡的結構特征和節點自身特性進行分析,提出了一種融合先驗估計與后驗估計的信息溯源算法,彌補了當前溯源算法存在的缺陷。當一則信息在網絡中傳播一定時間步長后,根據感染網絡快照中已感染節點其節點重要性值進行排序并處理,以此作為溯源算法的先驗估計;隨后,采用傳播中心性算法作為后驗估計,得到融合先驗估計和后驗估計的信息溯源算法。并且經過多維度的對比試驗,驗證了本文所設計的算法在檢測率和錯誤距離兩個方面均優于其他算法。
因此可以考慮將本文所設計的融合先驗估計與后驗估計的輿情溯源算法應用于真實的局域社交網絡中,可以精準鎖定局域社交網絡中傳播輿情信息的源點,并對其加以管理,從而凈化網絡環境,維護網絡安全。
參考文獻:
[1] 陳齊瑞,徐家寧,張維,等.基于AARRR模型的電力微信公眾號信息溯源方法研究 [J].微型電腦應用,2021,37(7):97-99.
[2] 查蘊初.論復雜網絡在公安情報網絡中的應用 [J].網絡安全技術與應用,2022(6):113-115.
[3] 范詩雨.突發事件下網絡謠言傳播結果影響因素研究 [D].太原:山西財經大學,2021.
[4] 黃春林,劉興武,鄧明華,等.復雜網絡上疾病傳播溯源算法綜述 [J].計算機學報,2018,41(6):1156-1179.
[5] VEGA-OLIVEROS D A,COSTA L D F,RODRIGUES F A. Influence maximization by rumor spreading on correlated networks through community identification [J].Communications in Nonlinear Science and Numerical Simulation,2020,37 (4):83-98.
[6] 趙文,水銘偉.大數據背景下個人信息安全保護措施研究 [J].電腦編程技巧與維護,2018(7):86-87+93.
[7] 于歡. 社交網絡中信息溯源算法研究 [D].徐州:中國礦業大學,2021.
[8] 邊娜.大數據信息安全典型風險及保障機制研究 [J].大眾標準化,2022(19):110-112.
[9] 張欣.基于節點重要性的溯源算法研究 [D].徐州:中國礦業大學,2021.
[10] 陳業華,白靜,李興源.基于網絡媒體信息的傳染病傳播模型及其仿真研究 [J].數學的實踐與認識,2017,47(13):176-185.
作者簡介:張欣(1997.05—),女,漢族,遼寧營口人,助教,碩士研究生,研究方向:社交網絡;王麗娟(1981.11—),女,漢族,江蘇贛榆人,副教授,碩士研究生,研究方向:機器學習、聚類分析;沐雅琪(1996.10—)女,漢族,江蘇興化人,助教,碩士研究生,研究方向:動態規劃算法。
猜你喜歡
兒童故事畫報·智力大王(2025年3期)2025-03-09 00:00:00
工會博覽(2023年27期)2023-10-24 11:51:28
科學大眾(中學)(2019年2期)2019-04-08 02:26:40
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
湖北警官學院學報(2017年3期)2017-06-21 09:25:51
信息安全與通信保密(2016年3期)2016-08-23 01:23:32
互聯網天地(2016年1期)2016-05-04 04:03:20
信息安全研究(2015年3期)2015-02-28 20:18:17
