基于“剪枝+并行”FP-Growth算法的密切接觸人員快速追蹤技術的研究
2023-06-22 21:08:10劉聰
現代信息科技 2023年2期


摘? 要:利用“剪枝+并行”式FP-Growth優化算法,通過提升計算精度和速度的方式對疫情發生地區確診患者的密接人員、次密接人員和同時空關聯人員實行快速精準的排查。與傳統的FP-Growth算法相比,“剪枝+并行”式FP-Growth算法的計算性能得到顯著提升。通過對某地區測試者7天內行跡及相關聯人員信息進行時間和準確方面的測試比較發現,計算時長縮短了近30%,準確率由82%提升至91%。實驗表明,利用優化后的FP-Growth算法能夠較好地滿足疫情發生地區快速精準確定相關聯人員的要求。
關鍵詞:FP-Growth算法;關聯性;快速精準
中圖分類號:TP311.1? 文獻標識碼:A? 文章編號:2096-4706(2023)02-0034-05
Research on Fast Tracking Technology of Close Contacts Based on “Pruning + Parallel” FP-Growth Algorithm
LIU Cong
(Weifang Vocational College, Weifang? 261041, China)
Abstract: The “pruning + parallel” FP-Growth optimization algorithm is used to quickly and accurately check the close contact personnel, sub close contact personnel and simultaneous air contact personnel of the confirmed patients in the epidemic area by the ways of improving the calculation accuracy and speed. Compared with the traditional FP-Growth algorithm, the computational performance of the “pruning + parallel” FP-Growth algorithm has been significantly improved. Through testing and comparing the time and accuracy of testers' tracks and related personnel information within 7 days in a certain area, it is found that the calculation time is shortened by nearly 30%, and the accuracy rate is improved from 82% to 91%. The experiment shows that the optimized FP-Growth algorithm can better meet the requirements of quickly and accurately determining the relevant personnel in the epidemic area.
Keywords: FP-Growth algorithm; relevance; fast and accurate
0? 引? 言
截至2022年8月,國內疫情仍處于低水平波動狀態,日均確診病例200人以上,無癥狀感染者1 000人以上,且變種病毒層出不窮,給地區疫情防控和經濟發展造成極大麻煩。思考如何利用現代化分析技術快速有效追蹤密切接觸者,成為后疫情時代防控疫情、推動經濟社會穩定發展的關鍵點。
基于以上,本文提出利用改進的“剪枝+并行”式FP-Growth優化算法對疫情發生區域確診人員的密接關聯人員情況進行快速準確定位,從而實現疫情地區的精準快速防控,及時有效切斷疫情傳播鏈,將疫情影響本地生產生活降低到最小[1-6]。
1? 改進FP-Growth算法實現關聯數據挖掘
由于本文中存在大量的數據處理和分析工作,過去傳統的FP-Growth算法已經無法滿足大規模數據下的數據處理和分析。因此,根據前端特征數據采集設備所采集數據的特征,本文對傳統的FP-Growth算法進行優化改進,利用MapReduce編程模型,對FP-Growth算法的各個步驟使用“剪枝+并行”法處理,優化后的算法在計算效率上可提高約30%,運行內存降低近40%,精準度提高10個百分點[7]。
1.1? FP-Growth算法和關聯規則算法原理
FP-Growth算法主要是通過利用和獲取構建的樹形結構圖中的相關事件集,來進行關聯性分析,每個事件都會在樹形結構圖中以路徑的形式標出,出現疊加的路徑越多,說明在使用FP-Growth算法的優勢越明顯。FP-Growth算法的實現需要經過兩個過程,一是構建FP-Tree,二是對FP-Tree進行關聯性數據挖掘。
關聯規則在數學方面很容易理解,即某事件X和事件Y的關系,在其關聯算法中的應用規則相類似,事件X看作關聯規則的前導項,事件Y看作關聯規則的后續項,可用公式表示為:X—>Y,其中在關系規則中有兩個關鍵度,即一個是支持度(support),另一個是置信度(confidence)[8]。
支持度,主要是指前導事件X和后續事件Y的共同事件在總事件Z中所占的比例,可以用數學公式表示為:P(X∪Y )=(X∪Y )/Z。
置信度,主要指是在總事件中前導事件X和后續事件Y共同出現與只包含X事件或Y事件的比例,可以用數學公式表示為:
P(X |Y )=P(X∩Y )/P(X )或者P(Y |X )=P(X∩Y )/P(Y )。
關聯規則的產生主要來源于購物方面的相關聯性分析,即在更好的服務購物者的同時加大商品的銷量。在關聯規則中有兩個值較為關鍵,一是支持度事件值,另一個是置信度事件值,如果這兩個值的最小支持度(Min_support)和最小置信度(Min_confidence)都能夠達到自定義的閾值,那么系統在數據分析上就認為運用關聯規則是有意義的[9]。關聯規則在數據挖掘的整個過程中,需要經歷兩步:一是要從原始數據信息中尋找出現頻率較高的事件集,即必須要大于等于最小支持度的閾值;二是要利用這些頻率較高的事件集來確定相關的關聯規則,即必須要滿足大于等于最小置信度的閾值。FP-Growth算法整體工作流程圖如圖1所示。
1.1.1? 構建FP-Tree樹
第一步:首先需要對總數據集進行一次檢索,找出每個事件字符所出現的頻次,然后依據支持度的最小閾值,假設Min_support=3,測試中使用列表1進行試驗分析,排除小于最小閾值的事件字符,從而得到新的列表,如表2所示。
第二步:再一次對新的數據集列表2進行一次檢索,設根節點為root,根據數列集中的事件字符依次以樹狀圖的形式下順,每次出現重復的字符就進行加1操作,最終得到完整地FP-Tree,具體執行過程如圖2所示。
1.1.2? 對FP-Tree進行關聯性數據挖掘
在構建FP-Tree結束后,選擇樹狀圖中固定節點字符,然后從樹狀圖中找出與固定節點字符相關聯的路徑,以s為例,可以看出從根節點root開始依次查找到與s相關的路徑分別為h{1}—>f{1}—>d{1}—>u{1},h{1}—>f{1}—>d{1}和f{1}—>e{1},然后按照上面的第二步操作重新進行建立樹狀圖,可以得到一個關于s的關聯性的項fs{3}。
以上就是關于FP-Growth算法實現關聯性的整個過程,該算法在查看本系統中的相關監測人員的密切度方面有極大幫助。但是隨著數據量的增加,單一的FP-Growth算法在運算方面就比較吃力,為此,在設計無線管控系統時,考慮到了對FP-Growth算法進行一定優化處理,采用并行+剪枝+FP-Growth的算法達到實際系統高效運算的目的。
1.2? 優化改進FP-Growth算法
1.2.1? 樹枝合并化改進
首先,根據需求設定一個定義,假如構建的FP-Tree的樹狀圖中的路徑M中含有非頻繁的事件r,路徑N中也包含非頻繁事件r,同時滿足M∈N,那么就可以把N中的事件r去掉,然后合并到較短的路徑M中,合并前的樹狀圖如圖3所示,合并后的樹狀圖如圖4所示。
依據此假設,對本文在優化改進FP-Growth算法方面得到以下啟示:在面對多事件路徑時,對于路徑中存在的某些非頻繁的事件項,可以采用合并事件集路徑的方法,對FP-Growth算法進行升級改造,通過減少數據挖掘過程中的檢索路徑數量,來達到提高運算效率的目的[10]。
1.2.2? 數據挖掘并行化改進
依據前面的“剪枝”可以得知,主要是在構建FP-Tree樹狀圖時進行路徑優化處理,但是在后續對FP-Tree進行關聯性數據挖掘時,仍需繼續改進提速。因為在對數據進行挖掘時,對于不同事件集的挖掘,所對應的頻繁項集是不同的,它決定著FP-Tree的復雜程度,同時FP-tree又主要作用于內存中,所以FP-Tree的復雜程度越高,占用的內存就越大,對于運行速率方面有一定影響。為此,本文繼續提出了把FP-Growth算法傳統的串行法變為并行法的設計,解決數據量規模較大的問題,在運算效率上得到進一步提高,并行法的結構圖如圖5所示。
FP-Growth算法實行并行法的設計思路主要有以下幾步:
第一步:先對原始的數據信息求出其頻繁事件項集,然后對其不同事件出現的頻率由高到低進行編碼處理,最后把編寫好的列表文件傳送到指定的執行文件中,編碼列表如表3所示。
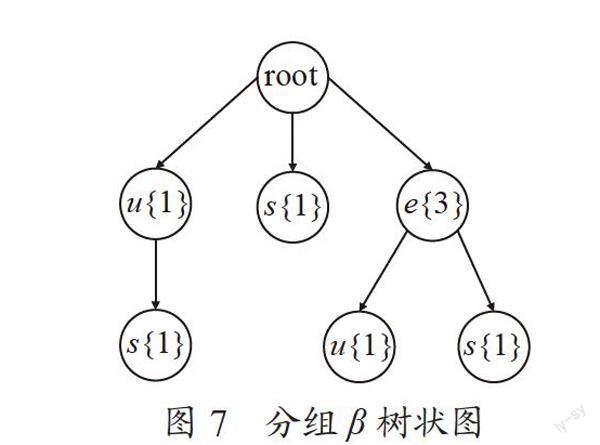
第二步:對原始數據進行分組,把初始事件組轉換為編碼的事件組,然后對所有的事件進行分組劃分,設定分為α組和β組,事件項集合{h,f,d,e,u,v}包含分組α{h,f,d,e}和分組β{e,u,v},若初始事組中的某一事件項既包含在α組中,又包含在β組中,那么這一事件項就要輸出到兩個分組中,具體分組情況如表4所示。
第三步:對上述分組結果,分別對每組的事件項進行建立樹狀圖的操作,具體的執行步驟如上節對原始數據的樹狀圖操縱類似,新建的樹狀圖α和β分別如圖6和圖7所示。
第四步:對新建的樹狀圖進行分別進行關聯性數據挖掘處理,一個map()函數對應一個分組進行挖掘操作,生成每個分組的頻繁事件項集,然后通過reduce()函數操作,把分散的頻繁事件項集合并成一個大的整體,最后根據支持度和置信度得出數據關聯性挖掘的最終結果,具體操作如圖8所示。
1.3? 關聯性數據挖掘的實現
客戶端在點擊執行關聯性查詢時,發送運行改進的FP-Growth算法的請求,程序端在接收到命令請求時會連同關聯性參數一起發送給FP-Growth_action函數進行處理,FP-Growth_action函數會啟動一個改進的FP-Growth算法線程,通過FP-Growth_monitor函數進行實時刷新監控,就可以獲取到改進的FP-Growth算法運行后的實時數據信息[11],具體調用改進的FP-Growth算法的流程圖如圖9所示。
2? 測試性能與結果分析
本文主要從單機數據處理和多節點性能測試兩方面對改進的FP-Growth算法和傳統的FP-Growth算法在性能方面進行差異化性能測試。
2.1? 單機處理對比
在保證實驗硬件、數據量等方面一致的前提下,通過植入兩種不同的算法,對運算性能進行測驗,同時為了保證實驗測驗的可靠性,減小誤差,分別對每組實驗數據進行100次以上的重復測驗,最后取其均值作為測驗結果進行分析。測試的方法主要是看折線圖中數據量和平均時間的比值大小,比例系數越小說明運算的效率越高,反之越低,具體的測試結果圖如圖10所示。
從測驗的結果中可以得出:當數據量較小時,傳統的FP-Growth算法在工作效率方面具有一定的優勢,但是隨著數據量的增加,改進的FP-Growth算法就逐漸地顯示出其自身的優勢。因此,把合并分支路徑和并行運算整體運用到FP-Growth算法中,能夠實現在數據量不斷擴大的前提下,使運行的效率不至于出現急劇的下滑,大大地提高了關聯性數據挖掘的速率。
2.2? 多節點性能測試
為了進一步測驗優化改進的FP-Growth算法性能,實驗中又設計了另外一組對比實驗,在集群的環境下測試該算法的性能。本實驗中采用主從式架構,一共包含10個節點,其中1個節點作為服務節點,另外的9個節點作為數據節點,其他配置均相同。測驗中選擇最小的支持度分別為10%和20%,同時從數據庫中的相關存儲文件中隨機選取大量數據,構建三組大數據,分別標記為D1、D2、D3。圖11至圖14分別顯示在最小支持度分別為10%和20%的情況下,三組不同的數據及9個任務節點執行傳統FP-Growth算法和改進FP-Growth算法的時間對比。
從以上兩組測驗對比圖中的折線規律可以得出。在數據量一定的情況下,隨著節點數的增加,通過優化改進的FP-Growth算法的相對運行時間在不斷減少。出現這種狀況的主要原因在于,節點數量的增加導致消耗通信時間的增加程度明顯的小于計算時間所減少的程度。另外,相同的數據,會隨著最小支持度的增加而相對應的運行時間有所減少,這是因為最小支持度變大后,頻繁數據項集的數量和長度也會相應地減少,從而運行時間縮短[12]。
3? ?結? 論
本文在研究FP-Growth算法的基礎上,針對當前疫情區域人員信息數據量大、數據及時性高等特點和存在的問題,提出了一種基于“剪枝+并行”FP-Growth算法的密切接觸人員快速追蹤技術的方法,并在實地場景進行測驗。但仍有改進的余地,下一步的研究工作主要有以下幾個方面:
(1)目前還存在數據采集過程中斷斷續續不穩定的情況,數據的傳輸過程中如何提高丟包率是接下來需要考慮的因素之一。
(2)對算法進一步優化,減少在使用過程中算法訓練所需的次數,使精度的提高更快。
(3)通過更多的實驗,進一步精確算法的主要參數值,以盡可能提高算法性能。
參考文獻:
[1] 秦雷.公安監控聯手“數字城管”南崗公安分局新中心揭牌 [N].哈爾濱日報,2008-04-11(2).
[2] 汪明峰,顧成城.上海智慧城市建設中公共WLAN熱點的空間分析與檢討 [J].地理科學進展,2015,34(4):438-447.
[3] 張崢嶸.淺談公安網絡監控系統的建設與管理 [J].中國公共安全,2013(13):130-133.
[4] 向庭勇,向庭波.用大數據技術構建公安Wi-Fi偵測系統的研究與應用 [J].中國公共安全,2016(13):75-81.
[5] 陳剛,羌鈴鈴.針對不同平臺系統獲取MAC地址的特定方法 [J].微計算機信息,2012,28(5):182—183+154.
[6] 公安監控網絡集成系統為平安城市保駕護航 [J].中國公共安全,2015(7):127-128.
[7] 馬月坤,劉鵬飛,張振友,等.改進的FP-Growth算法及其分布式并行實現 [J].哈爾濱理工大學學報,2016,21(2):20-27.
[8] 陸楠,王喆,周春光.基于FP-tree頻集模式的FP-Growth算法對關聯規則挖掘的影響 [J].吉林大學學報:理學版,2003(2):180-185.
[9] 張星,李蓓.FP-Growth關聯規則挖掘的改進算法 [J].平頂山工學院學報,2008(1):21-24.
[10] 晏杰,亓文娟.基于Apriori&FP-Growth算法的研究 [J].計算機系統應用,2011,47(7):153-155.
[11] 何月順.關聯規則挖掘技術的研究及應用 [D].南京:南京航空航天大學,2010.
[12] 楊勇,王偉.一種基于MapReduce的并行FP-growth算法 [J].重慶郵電大學學報:自然科學版,2013,25(5):651-657+670.
作者簡介:劉聰(1990—),男,漢族,山東濰坊人,助教,碩士研究生,研究方向:圖像識別和算法研究。
收稿日期:2022-09-02
