多茶類CNN 圖像識別的數據增強優化及類激活映射量化評價
2023-07-03 07:02:20章展熠張寶荃王周立楊垚范冬梅何衛中馬軍輝林杰
茶葉科學 2023年3期
章展熠,張寶荃,王周立,楊垚,范冬梅,何衛中,馬軍輝,林杰*
1. 浙江農林大學茶學與茶文化學院,浙江 臨安 311300;2. 麗水市農林科學研究院,浙江 麗水 323000;3. 麗水市經濟作物總站,浙江 麗水 323000
茶葉作為世界三大無酒精飲料之一,在我國有著悠久的歷史,根據發酵程度不同分為綠茶、黃茶、白茶、烏龍茶、紅茶、黑茶六大基本茶類。由于產地、茶樹品種及制作工藝各異,茶葉又細分為多個種類。在過去的研究中,茶葉種類識別通常采用人工感官審評[1]、紅外光譜成像技術檢測[2-3]、多光譜圖像顏色特征提取[4]等方法來完成。然而,人工感官審評存在評價環境缺乏獨立性、審評人員的主觀性差異等因素的干擾[5]。其他方法也存在設備專業性高、普適性較差及耗時較長等缺點。因此,亟需開發一種客觀、便捷、快速的多茶類識別方法。
近年來,隨著卷積神經網絡(CNN)的深度學習模型在眾多計算機視覺任務中取得了巨大成功,具有廣闊的發展前景,隨著AlexNet[6]、VGG[7]、ResNet[8]、DenseNet[9]等網絡模型的相繼提出,它們在圖像分類[6-7,10]、目標檢測[11-12]、語義分割[13-14]等領域有著廣泛的應用。目前,在茶葉領域中卷積神經網絡雖已用于茶樹病害識別[15]、綠茶種類識別和茶葉等級篩分[16],但對多茶類的分類識別鮮有報道。由 He 等[8]提出的殘差神經網絡(ResNet)便于訓練且性能優良,成為圖像分類任務中最典型的卷積神經網絡。圖像增強能改善圖像的視覺效果,有目的地強調圖像的局部或整體特征,擴大圖像中不同物體特征之間的差別,豐富圖像信息量[17]。搭建神經網絡模型需要大量的數據樣本,由于個別茶類通過網絡采集的圖像數量有限,目前的茶葉數據集還缺乏大量的圖像樣本,以此為基礎訓練的模型容易造成過擬合問題,導致模型預測效果不理想[18],而數據增強技術可以在有限的數據基礎上創造更多符合要求的數據,從而有效增加樣本的容量及多樣性,提升模型的魯棒性和泛化能力,解決過擬合問題[19-20]。盡管卷積神經網絡在物體識別上表現了優異的性能,但由于卷積神經網絡“端到端”的黑盒特性,其內部運作缺乏透明性和可解釋性[21]。Grad-CAM 作為一種類激活映射可視化方法,具有高度的類區分性,能夠使卷積神經網絡模型更“透明”。
ResNet-18 作為CNN 模型,其訓練速度快,識別準確率高,占用內存較少,具有輕量化、高效化的特點。ResNet-18 在花卉識別[22]、垃圾分類收運[23]等研究中都得到了良好的應用。本研究使用準確率(Accuracy)和損失值(Loss)作為指標能夠準確評估模型的識別性能,由于CNN 模型的“小黑盒”特性,僅用這些指標難以對模型的分類結果進行可視性解釋。目前,基于類激活映射方法的可解釋性研究,大多數只是根據類激活映射方法的熱力圖特點對模型進行定性評價,而缺乏對模型的定量評估[24]。
本研究采集圖像構建了具有復雜前景和背景的29 種常見茶類的數據集,利用卷積神經網絡ResNet-18 進行圖像識別訓練,著重對不同數據增強方法的模型訓練效果進行對比;在常規CNN 模型性能評價指標外,構建類激映射量化指標IOB 和MPI 對CNN 識別區域準確性進行客觀評價,以期篩選得到較優的數據增強方法,并訓練得到高魯棒性的多茶類CNN 圖像識別模型,從而為茶葉深度學習研究提供方法借鑒。
1 材料與方法
1.1 數據采集、數據集構建
使用深度學習技術進行識別茶葉的類別越復雜,種類越多,需要的數據就越多[25]。由于目前沒有公開的茶葉數據集,為了建立真實有效的多茶類數據集,本研究從社媒平臺、電商平臺和搜索引擎等收集圖像,比對相關茶類的產品標準,對外形特征不符、過度美化的圖像予以剔除,由浙江農林大學茶學系和浙江大學茶學系多名專家經過多次篩查后建立了數據集,其中安吉白茶205 張,白毫銀針208張,白牡丹205 張,碧螺春217 張,東方美人197 張,凍頂烏龍205 張,都勻毛尖193 張,恩施玉露184 張,鳳凰單樅275 張,貢眉287張,黃山毛峰197 張,金花茯茶200 張,金駿眉268 張,九曲紅梅155 張,君山銀針177張,六安瓜片197 張,六堡茶208 張,龍井237 張,普洱生茶220 張,祁門紅茶229 張,壽眉202 張,熟普205 張,太平猴魁216 張,條形滇紅213 張,鐵觀音208 張,武夷巖茶203 張,信陽毛尖200 張,正山小種216 張,竹葉青196 張,共6123 張。采集得到的多茶類圖片數據集,有著復雜的前景、背景(不同背景、不同亮度、不同前景角度和不同茶葉數量),基于本數據集訓練得到的模型能適應復雜背景下多茶類的識別,前景和背景復雜性如圖1 所示。
1.2 數據增強方法
本研究通過對圖像樣本進行幾何紋理變換與光學空間變換等操作引入細微的擾動從而實現數據擴充,有效減輕訓練階段的過擬合,提高模型的泛化能力。由于收集到的圖像大小不一,模型訓練前,預先將輸入模型數據集的圖像分辨率調整為512×512。本研究首先以CNN 數據增強中常用的水平鏡像翻轉作為基礎增強方法進行圖像數據加倍,再分別疊加10 種其他數據增強方法進行二次加倍,增強后圖片數量擴充為原數據集的4 倍,11 種數據增強方法的效果如圖2 所示。具體步驟如下:

圖2 圖像數據增強前后效果Fig. 2 Examples of image data augmentation
(一)基礎數據增強
①水平鏡像翻轉:以圖像垂直中線為軸翻轉圖像。
(二)幾何紋理變換
②網格擦除(Ratio=0.3):即GridDropout,以網格形式按照0.3 的區域比例對圖片進行擦除。③網格擦除(Ratio=0.5):即GridDropout,以網格形式按照0.5 的區域比例對圖片進行擦除。④隨機擦除:即Random Erasing,以若干分辨率80×80 方塊形式隨機擦除圖像部分信息。 ⑤隨機網格洗牌(2×2) :即RandomGridShuffle,將圖像以2×2 網格形式生成4 塊,并隨機打亂。⑥隨機網格洗牌(3×3):即RandomGridShuffle,將圖像以3×3 網格形式生成9 塊,并隨機打亂。⑦隨機旋轉:即Random rotation,對圖片進行隨機旋轉一個角度處理。⑧隨機旋轉(N×90°):對圖片進行隨機旋轉N 個90°。⑨隨機裁剪:即RandomCrop,隨機裁剪圖像分辨率為一定大小。⑩分辨率擾動:即RandomScale,隨機縮放圖像的分辨率。
(三)光學內容變換
?HSV顏色空間擾動:使用Albumentations 數據增強工具中的HueSaturationValue改變圖像的色度、飽和度和明亮度,其中Hueshift limit=20,Sat shift limit=30,Val shift limit=20。
1.3 類激活映射可視化及量化評價
為了對CNN 模型圖像識別區域準確性進行客觀評價,本研究在參考Selvaraju 等[26]研究的基礎上,構建了交集比(Intersection over bounding box,IOB)及Grad-CAM 激活的平均比率(Mean position importance,MPI)兩個量化評價指標來度量類激活映射的準確性。從茶葉圖像集中隨機選取10 張具有背景干擾的圖像作為測試圖(即10 次重復測定)。通過圖像標注軟件Labelme 5.0.2 對測試圖進行語義分割和標注,將茶葉從圖像背景中分離出來,其他部分作為背景標注,得到帶有茶葉邊界點的Json 格式文件,再經過掩膜交集處理得到目標區域的二值化圖像,以白色標注茶葉區域,黑色標注背景區域。采用梯度加權類激活映射(Grad-CAM)對訓練得到的ResNet-18模型的圖像識別區域進行可視化,生成測試圖的類激活熱圖。
Grad-CAM 作為類激活映射方法之一,使用反向傳播中獲取的通道梯度均值作為通道權重生成熱力圖,具有良好的類別區分性,其原理如圖3 所示,可以對卷積神經網絡的分類結果做出合理的解釋,將網絡模型可視化[26-28]。使用Grad-CAM 方法生成類激活圖的過程可公式化描述為:
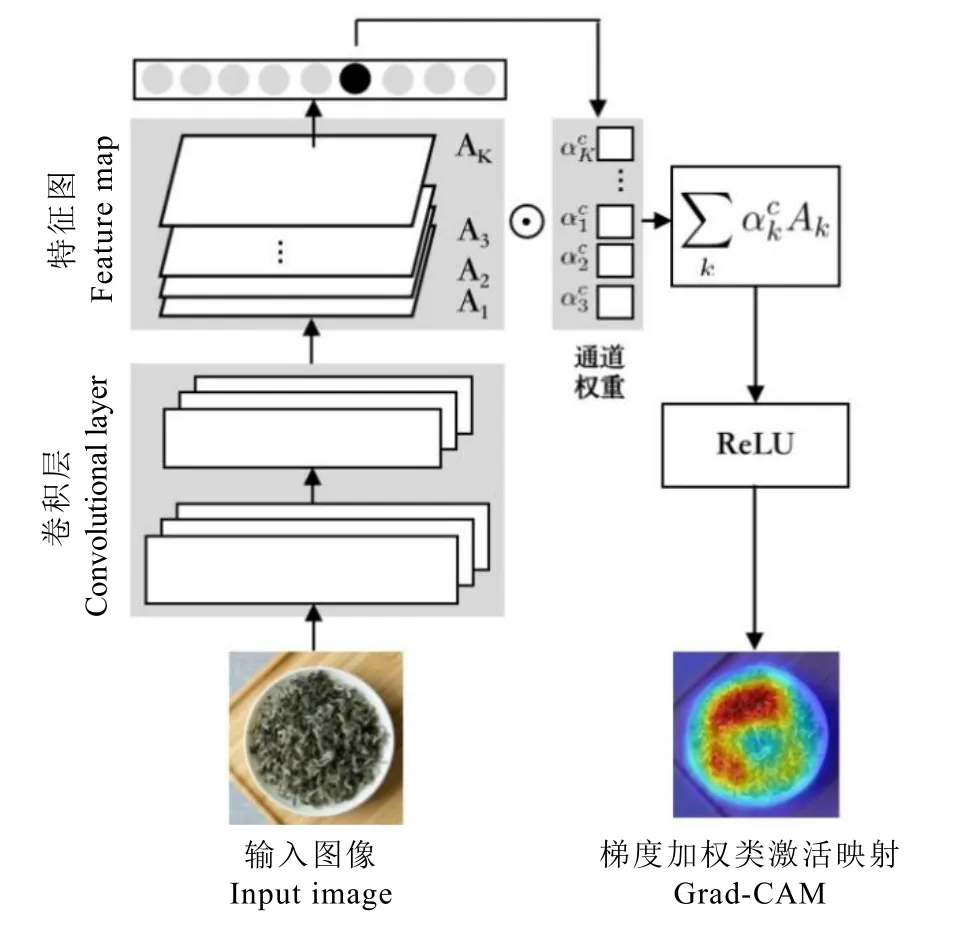
圖3 Grad-CAM 的原理Fig. 3 Principles of Grad-CAM
其中,Ak表示最高層特征圖的第k個通道,表示針對該通道的權重,yc表示網絡在未通過Softmax 分類器激活前針對類別c 的預測分數,Ak,i,j為第k個特征圖中位置(i,j)的激活值,其計算公式如下:
類激活映射量化評價指標1—IOB。原圖像中的茶葉區域定義為真實邊界框Bg(Ground-truth box),在Grad-CAM 熱圖中分割出高于最大熱點值20%的區域,取包圍分割圖的最大邊界框作為預測邊界框Bh(Bounding box),得到IOB 的計算公式為:
類激活映射量化評價指標2—MPI。計算目標區域二值化圖中茶葉部分的真實像素值Sh及Grad-CAM 類激活熱圖中的熱點區域(高于最大熱點值20%的區域)總像素值Sg,計算得到MPI,公式為:
1.4 試驗測試平臺、超參數設置
采用ResNet-18 卷積神經網絡框架進行遷移學習,Batch size 設置為8,優化器使用帶動量因子的SGD(Stochastic gradient descent)算法,動量因子(Momentum)設置為0.9,初始學習率(Learning rate)設置為0.001,學習率調度器為等間隔縮減(Step LR),等間隔系數(Step size)設置為5;為加快模型訓練收斂速度和提高模型訓練效果,采用交叉熵作為損失函數。在經過25 輪(Epochs)迭代后,模型基本收斂。
通過Python 語言完成模型的搭建與訓練,基于PyTorch 深度學習框架,并行計算框架使用CUDA 11.1 版本。試驗基于Windows 11 操作系統,使用英偉達GeForce RTX 3060 GPU顯卡,處理器為 AMD Ryzen 75800H with Radeon Graphics@3.20GHz。
1.5 數據處理和評價指標
本試驗采用 k 折交叉驗證法(K-folder cross validation)進行重復交叉驗證(k=5),將圖像數據集隨機分成5 等份子集;依次遍歷這5 個子集,每次CNN 訓練把當前子集作為測試集,其余的4 個子集作為訓練集,進行模型的訓練和評估;取5 次的指標平均值來評價最終的模型訓練、測試效果。k 折交叉驗證中,所有數據都會參與到訓練和測試中,能有效避免過擬合,并充分體現了交叉的思想[29]。
采用方差分析進行差異顯著性分析(P<0.05),多重比較方法為Duncan,分析軟件為SPSS 22.0。為了評價不同數據增強方法對于多茶類模型識別性能的影響,本研究選取準確率和損失值作為評估算法性能的評價指標。準確率反映了本研究算法整體性能的優劣,損失值則用來表示模型預測值與實際值的誤差,損失值越小,模型的魯棒性越好,計算公式如下:
其中,Accuracy表示準確率,Loss表示損失值,FP代表預測錯誤的正樣本數,TP代表預測正確的正樣本數,FN表示預測錯誤的負樣本數,TN表示預測正確的負樣本數。N表示總的樣本數量;pn,i表示第n個樣本為類別i的概率。
2 結果與分析
2.1 不同數據增強方法的模型訓練效果對比
為評估得到較優的多茶類圖像識別數據增強方法,本研究基于基礎數據增強方法(水平鏡像翻轉),對比了10 種數據增強方法(9種幾何紋理變換和 1 種光學空間變換)的ResNet-18 網絡框架訓練效果。采用準確率、損失值這2 個常規指標來評估模型性能,結果如表1所示。基礎數據增強后訓練的ResNet-18 模型準確率、損失值分別為91.37%和30.27,已較可觀但仍需優化。經過10 種數據增強方法優化數據集后,準確率進一步提升(從+1.90 到+7.45 不等),損失值從30.27 下降到3.97~21.29,模型的魯棒性提高。其中,疊加分辨率擾動、網格擦除(Ratio=0.3)和HSV 顏色空間擾動訓練后模型的準確率分別提高至98.82%、98.77%、98.66%,顯著高于其他數據增強方法(P<0.05)。疊加分辨率擾動后模型損失值僅為 3.97,顯著低于隨機擦除、隨機裁剪、網格擦除(Ratio=0.5)、隨機網格洗牌、隨機旋轉 N×90°和隨機旋轉(P<0.05)。綜上所述,基于準確率、損失值評估模型性能,分辨率擾動、網格擦除(Ratio=0.3)和HSV 顏色空間擾動對于模型性能的優化效果較好。
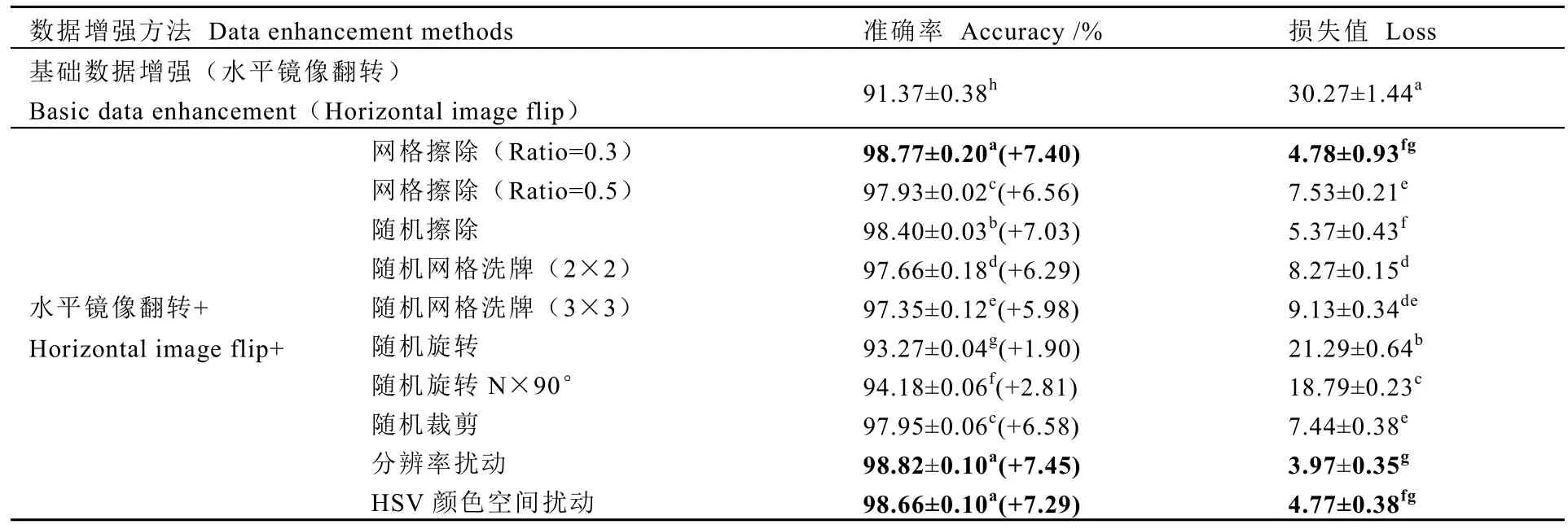
表1 不同數據增強方法模型性能評價Table 1 Model performances of different data enhancement methods
2.2 類激活映射可視化的量化評價
通常CNN 模型只以準確率、損失值等指標來衡量性能,而類激活映射(CAM)則作為模型的識別熱點區域的可視化手段。但類激活映射可視化只是一種定性觀測手段,缺乏量化結果。本研究為準確評估模型對茶葉識別的準確性及Grad-CAM 的定位能力,創新性地構建IOB 和 MPI 兩個量化指標進行量化評價。Grad-CAM 基于4 種數據增強方法的類激活圖、二值化圖和量化評價示例分別如圖4 所示,圖中僅示例了HSV 顏色空間擾動、隨機旋轉、網格擦除(Ratio=0.3)和隨機擦除 4種數據增強方法的IOB 和MPI 可視化結果。目標區域二值化圖標示了多茶類識別的感興趣區域(Region of interest,ROI);理想狀態下希望類激活映射能準確且充分地識別到ROI 區域。圖4 中某恩施玉露圖片示例了2 種數據增強方法的Grad-CAM 量化評價優劣,Grad-CAM 熱圖顯示,HSV 顏色空間擾動的識別熱點雖然也有少部分落在背景干擾上(茶具、石頭),但大部分落在了ROI 區域(茶葉)內,且IOB 預測框(藍色)也更貼近真實框(紅色);而隨機旋轉有更多的識別熱點落在了背景干擾中,且IOB 預測框(藍色)明顯偏離了真實框(紅色),此圖片的模型在識別準確性指標上,HSV 顏色空間擾動要好于隨機旋轉。而IOB 和MPI 都顯示HSV 顏色空間擾動(IOB、MPI 分別為97.41%和77.42%)比隨機旋轉(IOB、MPI 分別為 68.93%和66.36%)表現更好,與Grad-CAM 主觀判斷一致。圖4 中某太平猴魁圖片示例了2 種數據增強方法的 Grad-CAM 量化評價優劣,Grad-CAM 熱圖顯示,網格擦除(Ratio=0.3)和隨機擦除的識別熱點大部分落在了ROI 區域(茶葉)內,且IOB 預測框(藍色)也都較貼近真實框(紅色),但主觀細致觀測下,預測框和識別熱點準確性網格擦除(Ratio=0.3)要稍好于隨機擦除;而IOB 和MPI 都顯示網格擦除(Ratio=0.3)(IOB、MPI 分別為98.69%和66.79%)比隨機擦除(IOB、MPI 分別為89.30%和56.34%)表現稍好,與Grad-CAM主觀判斷完全一致。整體而言,IOB和MPI兩個量化指標可以較好地客觀表征CNN 模型類激活映射的準確性,方便觀測和對比CNN模型識別性能。

圖4 Grad-CAM 的量化評價可視化圖Fig. 4 Visualization diagrams of quantitative evaluation of Grad-CAM
不同數據增強方法的類激活映射量化評價結果如表2 所示。由于不同圖片的量化指標波動較大,本研究選取了10 張測試圖片(即10 次重復)的IOB 和MPI 量化結果進行統計分析。隨機網格洗牌的2 種數據增強方法的目標區域識別準確性相對較低,甚至低于基礎數據增強方法。而其他8 種數據增強方法的IOB和MPI,雖然在均值上有差異,但在統計學上不存顯著差異(P<0.05)。其中IOB 均值最高的是分辨率擾動,而MPI 均值最高的是網格擦除(Ratio=0.3),雖然HSV 顏色空間擾動的兩個量化指標的均值均明顯低于分辨率擾動和網格擦除(Ratio=0.3),但不同測試圖片的量化評價結果波動較大,整體上不存在顯著性差異。網格擦除(Ratio=0.5)相較網格擦除(Ratio=0.3),雖然IOB 和MPI 不存在顯著差異,但性能指標的評價結果稍差且存在顯著差異(P<0.05),因此本研究優選網格擦除(Ratio=0.3)進入下一步研究。隨機擦除也是圖片信息擦除類的數據增強方法,但其4 項指標的整體表現不及網格擦除(Ratio=0.3)。結合模型性能指標的評價結果,以及實際圖片識別中分辨率變動和顏色擾動等常見情況,本研究優選網格擦除(Ratio=0.3)、分辨率擾動和HSV 顏色空間擾動3 種數據增強方法進行后續的消融實驗。
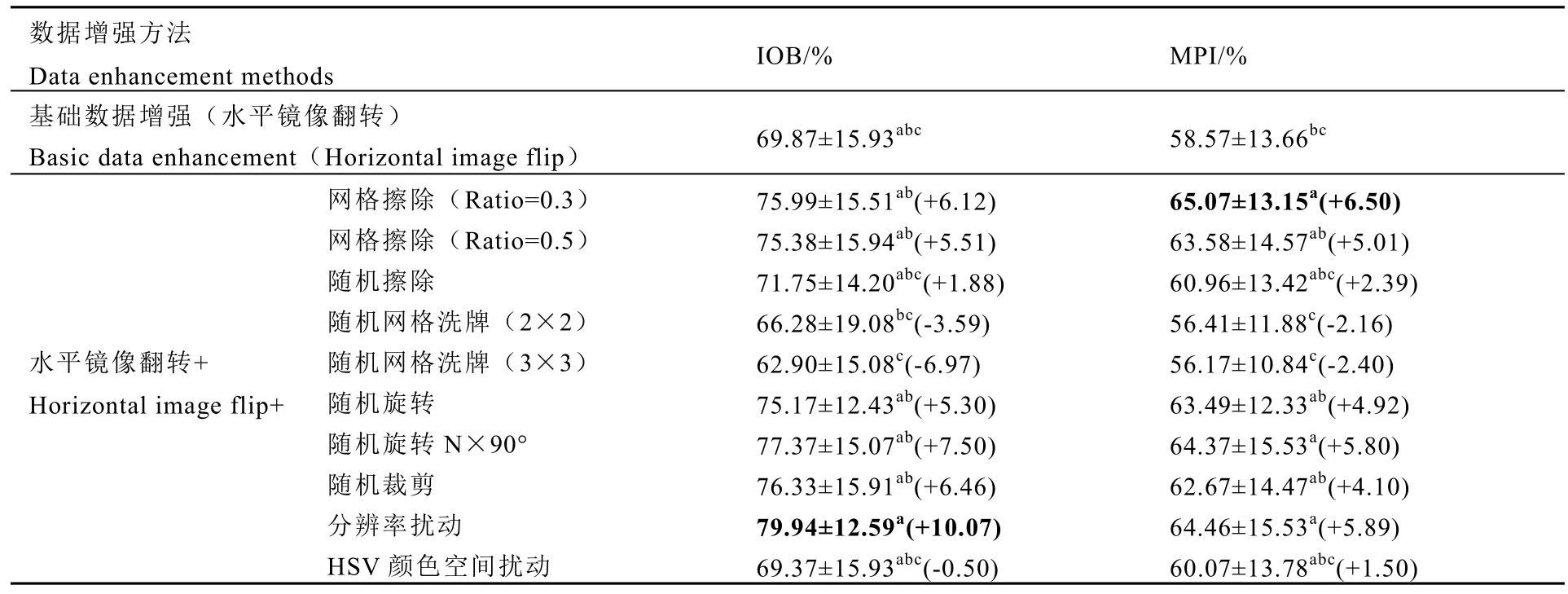
表2 不同數據增強方法的類激活映射量化評價對比Table 2 Comparison of quantitative evaluation of class activation for different data enhancement methods
2.3 消融實驗
在對比了10 種數據增強方法CNN 訓練效果的基礎上,初步優選得到了網格擦除(Ratio=0.3)、分辨率擾動和HSV 顏色空間擾動3 種較優的方法。進一步開展消融實驗,對比了不同數據增強方法組合的CNN 訓練效果,以期得到最佳的數據增強方法組合,結果如表3 所示。使用網格擦除(Ratio=0.3)、分辨率擾動和HSV 顏色空間擾動的數據增強方法兩兩組合時,準確率得到一定程度提升,都超過了99%;損失值也得到一定程度下降,而類激活映射量化評價指標IOB 和MPI 未有顯著提升(P<0.05)。其中“水平鏡像翻轉+網格擦除(Ratio=0.3)+HSV 顏色空間擾動”組合的準確率達到了99.82%,顯著高于其他數據增強方法組合(P<0.05),損失值僅為0.64,且MPI 的均值也達到了68.44%,是所有數據增強方法組合中最高的,IOB 也達到74.79%,整體而言是最佳的數據增強方法組合。而“水平鏡像翻轉+網格擦除(Ratio=0.3)+分辨率擾動+HSV 顏色空間擾動”組合的準確率不及“水平鏡像翻轉+網格擦除(Ratio=0.3)+HSV顏色空間擾動”組合,其他3 個指標均值則不存在顯著差異(P<0.05),且該方法數據集更大,意味著需要更長的模型訓練時間。消融實驗的結果也表明,更多的數據增強方法組合擴充圖像數據集,雖然可能提升模型性能評價指標,但在模型識別區域準確性指標上未表現出顯著差異。
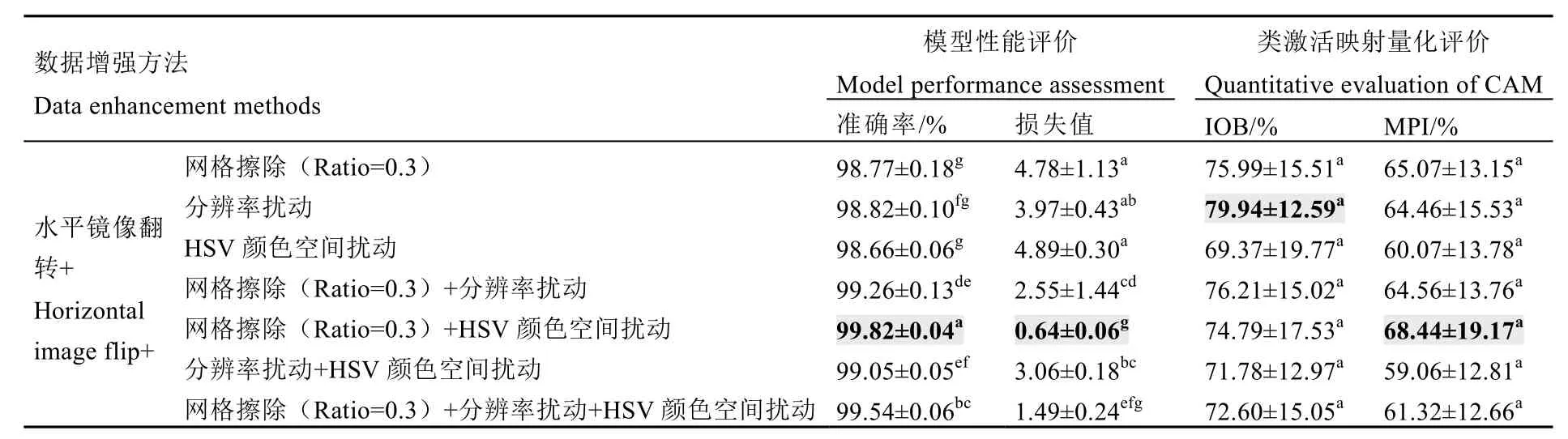
表3 消融實驗結果Table 3 Results of ablation experiment
2.4 多茶類圖像識別的混淆分析
通過“ 水平鏡像翻轉+ 網格擦除(Ratio=0.3)+HSV 顏色空間擾動”最佳數據增強方法組合訓練得到平均識別準確率達到99.82%的ResNet-18 模型,并記錄該模型的訓練與測試迭代表現(如圖5)。整體上,該ResNet-18 模型收斂速度較快,未出現收斂抖動狀態,并在第6 次迭代后準確率、損失值呈現穩定的收斂狀態。收斂速度越快,意味著模型快速穩健的融合,可避免過擬合或者是陷入局部最佳狀態。ResNet-18 模型大小為43.7 MB,所需空間較小。對10 張圖片的識別時間進行記錄,計算得到每張圖片的平均識別時間僅為(0.102±0.001) s,說明識別每張圖片所需時間非常短。綜上所述,該多茶類ResNet-18 模型識別準確率高、占內存較少、識別時間較快,適合移動端應用[16]。
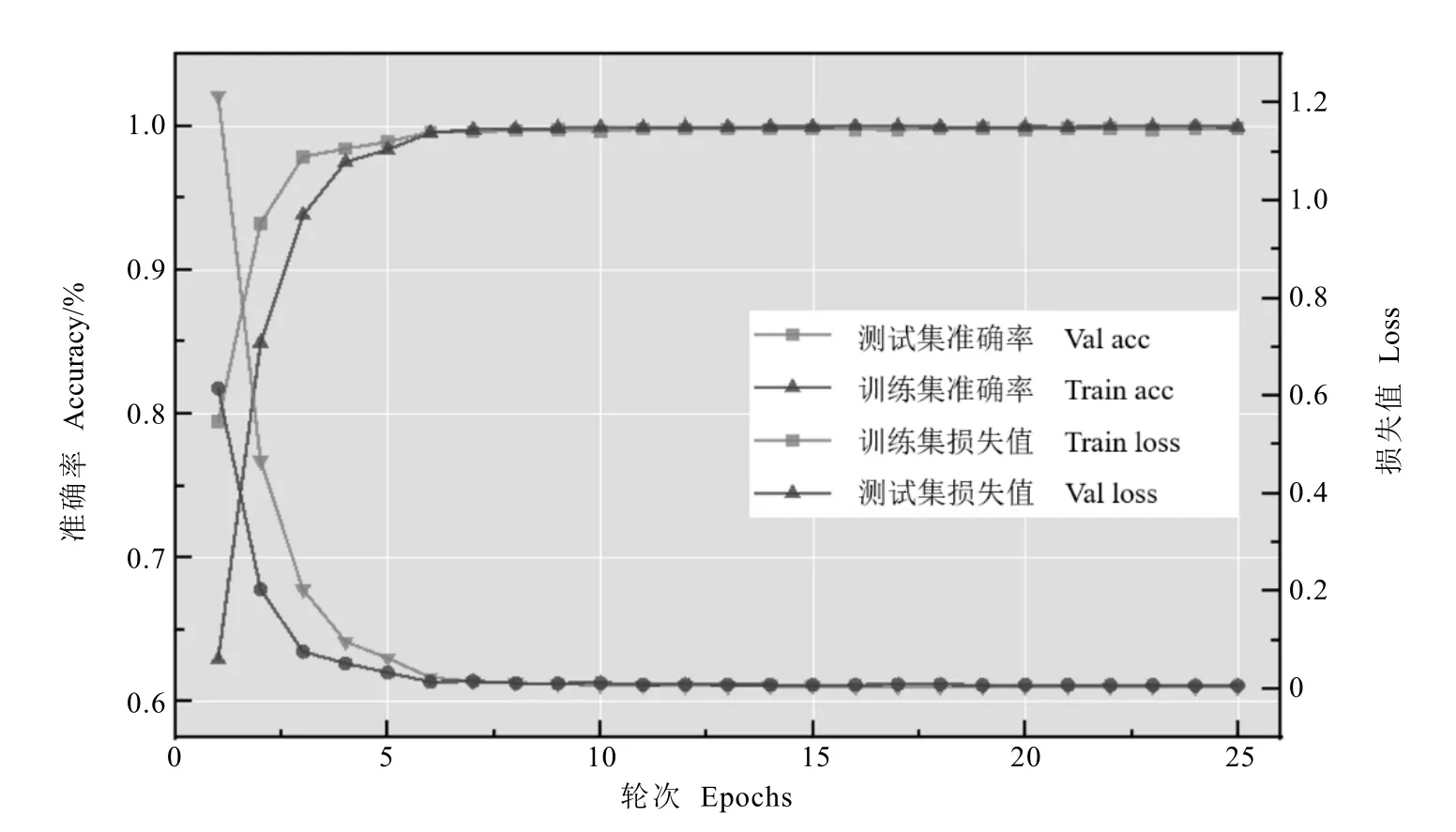
圖5 ResNet-18 模型訓練與測試迭代曲線Fig. 5 Iteration curve of training and validation of ResNet-18 model
進一步對該模型的多茶類圖像識別結果進行解析,采用混淆矩陣對識別模型中易識別、易混淆茶類進行可視化(圖6)。對角線上的數值為所有正確的預測結果,其余數值均為模型誤判導致的錯誤的預測結果,并且矩陣的每一列表示真實類別,而矩陣的每一行表示模型的預測類別。除貢眉、黃山毛峰、武夷巖茶、信陽毛尖以外,其他25 種茶類的識別準確度達到100%,未出現混淆,并且對于貢眉和信陽毛尖這2 種茶葉也表現出優異的分類性能,識別準確率均達到99%以上。黃山毛峰識別準確率最低, 也達到了 98.77%( 240/243),說明本研究優化得到的ResNet-18 模型能讓網絡有效提取各類別茶葉圖像的淺層(顏色、紋理等)或深層抽象特征,進而在復雜前景、背景下實現多茶類的高精度識別。個別茶類產生了一定的識別混淆,其中黃山毛峰有2 例錯誤識別為普洱生茶,1 例錯誤識別為太平猴魁;武夷巖茶則各有3 例識別成了金駿眉和壽眉。
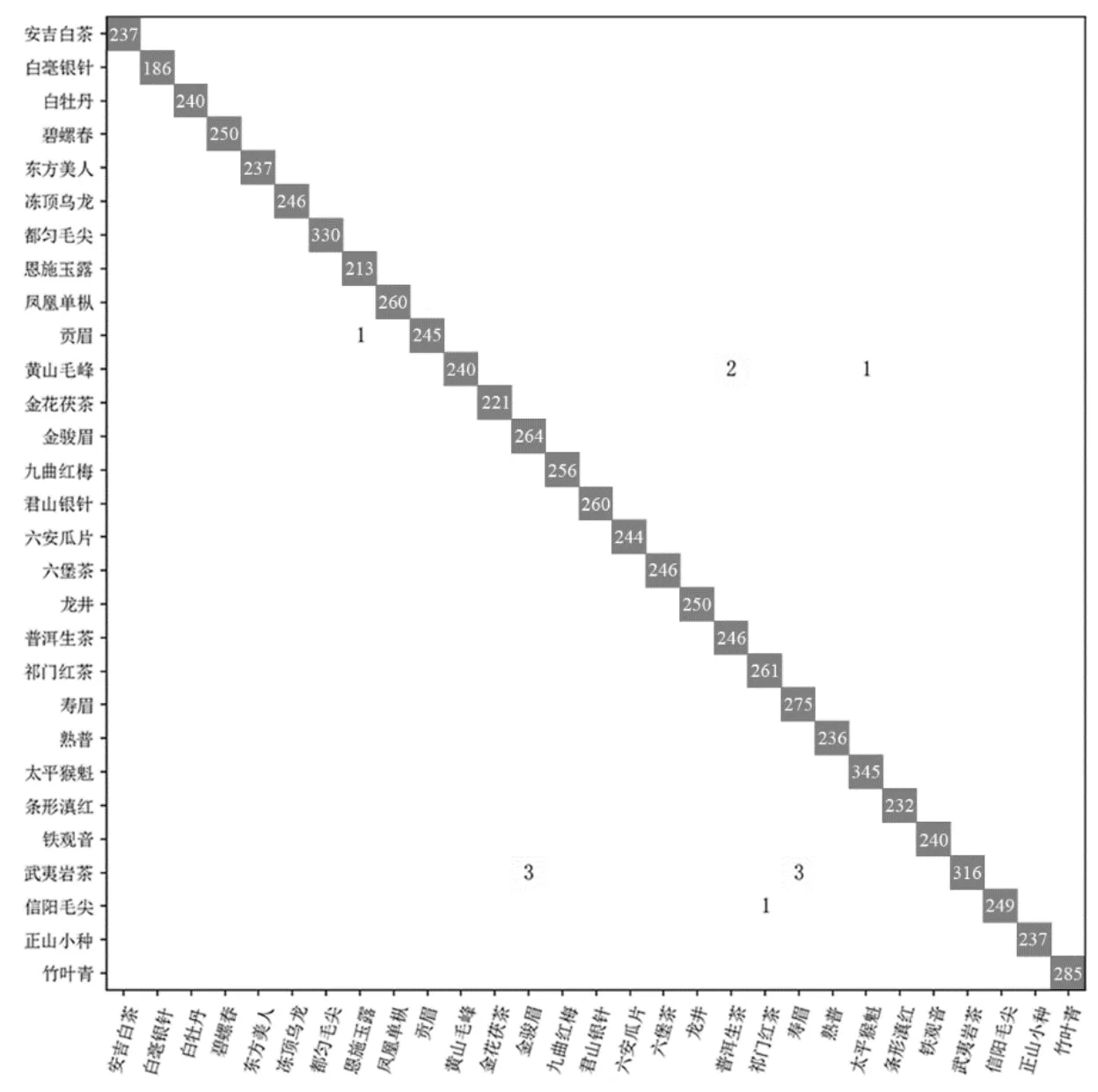
圖6 29 種茶類ResNet-18 模型識別結果混淆矩陣Fig. 6 Confusion matrix of recognition results of twenty-nine ResNet-18 tea models
3 討論
本研究通過自主采集茶葉圖像,建立了1個包含29 種茶葉類別的數據集,所采集圖像包含不同角度、不同背景及不同數量等情況下的茶葉,共6 123 張。本研究所構建的數據集涵蓋了六大茶類,并且具有一定代表性,具有較強的適用性和泛化能力。相比于張怡等[16]構建的8 種綠茶數據集,本研究構建的數據集量更大,包含更豐富的茶葉種類。以本數據集為基礎所構建的多茶類識別模型在識別準確率上達到了99.82%,具有優良的識別效果。在過去的研究中,茶葉的識別可通過基于圖像處理的視覺識別技術[30]、基于顏色和形狀的計算機視覺技術[31]等技術來完成,但缺乏基于卷積神經網絡和數據增強的多茶類識別模型。本研究首次針對多茶類數據集進行數據增強以優化模型,選取幾何紋理變換與光學空間變換中的10 種作為數據增強方法,基本覆蓋了主要的數據增強方法,同時也能應對茶葉擺放中出現的變換情況。對比10 種不同數據增強方法發現,分辨率擾動和網格擦除對模型的優化效果較好,這是由于采集的茶葉圖像分辨率大小不一,分辨率擾動能改變圖像的分辨率大小,可得到更多分辨率下的茶葉圖像,符合更多實際場景下的圖像存在形式,與Liu 等[32]的研究結果較為一致。網格擦除能讓CNN 學習到更多特征信息,并增加感知場,相比于隨機擦除,網格擦除更能顯著提高模型的泛化能力和魯棒性,與Chen 等[33]的研究結論相似。然而,旋轉變換對茶葉識別模型的優化效果不理想,這可能由于茶葉圖像經旋轉后,茶葉的特征信息變化不明顯,對模型的泛化能力提升較差。本研究所構建的模型在識別準確率上達到了99.82%,但在后續研究中,將針對其他數據增強方法的優化效果展開相關研究,為多茶類識別模型的數據集構建提供一定的參考。
本研究使用ResNet-18 作為CNN 模型,其訓練速度快,識別準確率高,占用內存較少,具有輕量化、高效化的特點。ResNet-18 在花卉識別[22]、垃圾分類收運[23]等研究中都得到了良好的應用。但在未來的工作中,將使用更輕量化的 MobileNet[34]作為特征提取網絡進一步提高模型識別精度,為在移動端的識別應用建立基礎。本研究使用準確率、損失值作為指標能準確評估模型的識別性能,由于CNN模型的“小黑盒”特性,僅用這些指標難以對模型分類結果進行可視性解釋。目前,基于類激活映射方法的可解釋性研究中,大多只是根據類激活映射方法產生的熱力圖的特點對模型進行定性評價,而缺乏對模型的定量評估[24]。本研究進一步應用類激活映射量化評價,在已有研究[27-28,35]的基礎上,將量化方法改進后應用于茶葉識別模型的評價中,產生的熱力圖不僅能準確定位茶葉,而且能客觀評價模型的識別定位能力,使模型更具有可解釋性,為客觀評價CNN 模型的性能提供了一種新思路、新方法。消融實驗在復雜的深度神經網絡模型的背景下得到了廣泛的應用,張家鈞等[36]通過消融實驗進一步優化了網絡的瓶頸結構,提高了鞋型識別算法的準確性;楊繼增等[37]通過消融實驗探究了不同階段卷積層組合對算法性能的影響。本研究將不同數據增強方法組合進行消融實驗,結果表明,分辨率擾動和網格擦除方法相結合,使模型識別準確率進一步提高到99.82%,量化評價結果也更優。29 種茶類的混淆矩陣結果表明,安吉白茶、白毫銀針、白牡丹、碧螺春、東方美人、凍頂烏龍、都勻毛尖、恩施玉露、鳳凰單樅、金花茯茶、金駿眉、九曲紅梅、君山銀針、六安瓜片、六堡茶、龍井、普洱生茶、祁門紅茶、壽眉、熟普、太平猴魁、條形滇紅、鐵觀音、正山小種和竹葉青這25 種茶類在識別準確率上達到了100%,但也有個別茶類的識別率存在一定的混淆,這些茶類混淆可能是茶類外形本身存在一定的混淆可能性,也可能是CNN 識別混淆和熱點區域與人感官識別的差異造成(如3 例武夷巖茶被混淆識別為金駿眉,2 例黃山毛峰被混淆識別為普洱生茶)。未來將進一步應用類激活映射可視化方法確定CNN 的識別區域來輔助訓練,以使模型更加“透明”。
本研究首次對茶葉圖像數據增強方法進行了優化,對比了10 種數據增強方法的多茶類CNN 模型訓練效果,得到了較優的數據增強方法組合,即水平鏡像翻轉+網格擦除(Ratio=0.3)+HSV 顏色空間擾動。訓練得到了高魯棒性的多茶類CNN 圖像識別模型,其識別準確率達到了99.82%、損失值僅為0.64。同時本研究創新性地構建了量化指標IOB 和MPI,解決了類激活映射識別區域準確性的客觀評價問題,可配合常規評價指標(準確率、損失值等),對CNN 模型的訓練效果進行更科學地衡量,為CNN 模型性能的客觀化、量化評價提供了一定的參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
