基于多傳感器人工嗅覺系統及機器學習模型的蘋果種類識別方法
2023-07-12 09:01:28李書賢周琪樊亞楠葉詩琪趙志彪張思祥
天津農業科學 2023年7期
李書賢 周琪 樊亞楠 葉詩琪 趙志彪 張思祥


摘??? 要:基于多傳感器人工嗅覺系統的蘋果種類識別方法是將自行研發的便攜式硬件和上位機算法相結合,目的是將市面上常見的外形相似的‘花牛和‘阿克蘇蘋果進行無損種類識別,降低檢測成本。實施方法是根據實際情況選擇傳感器并設計電路對待測樣本氣味信息進行響應,下位機將采集到的信號傳輸至上位機的機器學習算法中進行模型訓練。通過線性判別分析算法(Linear Discriminant Analysis,LDA)、邏輯回歸算法(Logistic Regression,LR)、鄰近算法(K-NearestNeighbor,KNN)、前饋神經網絡算法(Back Propagation,BP)分類模型對氣味信息數據進行計算并作出分類。最終得到LDA、LR、KNN、BP算法識別的準確率分別為86.83%、85.33%、91.26%、85.00%,通過stacking框架將以上4種算法模型進行融合,融合后算法識別的準確率最高為97.14%。與傳統單預測模型相比,基于多模型融合的蘋果識別方法精確度更高。研究結果表明,基于多傳感器人工嗅覺系統可以直接通過氣味對其種類進行識別,為蘋果的無損分類做出有效的判斷,可為受主觀因素影響的的感官評價提供客觀的理論依據。
關鍵詞:多傳感器;種類識別;機器學習;stacking融合算法
中圖分類號:TP391??????????? 文獻標識碼:A???????????? DOI 編碼:10.3969/j.issn.1006-6500.2023.07.012
A Multi-sensor Artificial Olfactory System and Machine Learning Model Based on Apple Species Recognition Method
LI Shuxian1,2, ZHOU Qi1,2, FAN Yanan1,2, YE Shiqi1,2, ZHAO Zhibiao1,2, ZHANG Sixiang3
(1. School of Automation and Electrical Engineering, Tianjin University of Technology and Education, Tianjin 300222, China; 2. Tianjin Key Laboratory of Information Sensing and Intelligent Control, Tianjin University of Technology and Education, Tianjin 300222, China; 3. School of Mechanical Engineering, Hebei University of Technology, Tianjin 300401, China)
Abstract:The method of apple variety recognition based on a multi-sensors artificial olfaction system combines a self-developed portable hardware device with a PC-based algorithm. The aim is to achieve non-destructive identification of visually similar apple varieties, such as 'Huaniu' and 'Akane', in the market, thereby reducing detection costs.The implementation method involved selecting sensors based on the actual conditions and designing circuits to respond to the odor information of the tested samples. The lower-level device transmitted the collected signals to the machine learning algorithm implemented on the upper-level PC for model training. The collected odor information data was processed and classified using classification models, including Linear Discriminant Analysis (LDA), Logistic Regression (LR), K-Nearest Neighbor (KNN), and Back Propagation (BP). The classification accuracy of LDA, LR, KNN and BP algorithms was determined to be 86.83%, 85.33%, 91.26% and 85.00%, respectively. The four algorithm models were then fused using the stacking framework, resulting in the highest accuracy of 97.14%. Compared to traditional single prediction models, the apple recognition method based on multi-model fusion achieved higher accuracy. The research results indicated that the multi-sensors artificial olfaction system can directly identify the variety of apples based on their odor, providing an effective means for non-destructive classification. This method could offer objective criteria for sensory evaluation that may be influenced by subjective factors.
Key words: multi-sensors; variety recognition; machine learning; stacking fusion algorithm
蘋果散發的氣味是蘋果種類的一個重要標識[1],不同種類的蘋果散發的氣味也有差異[2]。傳統蘋果種類識別主要靠化學檢測,過程復雜,對被測樣本傷害高,無法實現無損檢測[3~4]。
為解決傳統水果檢測過程復雜的問題,乜蘭春等[5]通過對‘紅富士‘新紅星和‘喬納金等多個品種的蘋果的揮發性氣體進行研究,結果發現,紅富士蘋果未成熟時含量最高的揮發性氣體是乙醛,占總揮發性氣體含量的18.73%,成熟時含量最高的揮發性氣體為丁酸乙酯,占總揮發性氣體含量的19.51%;‘新紅星蘋果成熟時含量最高的揮發性氣體為乙醛和2-甲基環戊醇,占總揮發性氣體的20%以上;‘喬納金蘋果成熟時含量最高的揮發性氣體是1-丙醇,占總揮發性氣體的9.30%;乜春蘭[5]研究表明,不同品種的蘋果揮發性氣體差異較大。楊艷菊等[6]將傳感器陣列和人工神經網絡模式識別算法結合起來建立電子鼻系統,對水果的變化過程進行監控,嘗試對3種狀態(好、碰傷、壞)的蘋果氣體進行定性識別,其中對‘紅富士蘋果進行識別時的準確率達到83.33%以上。郭清乾等[7]研究發現,蘋果的成熟度與其產生的乙烯含量密切相關,乙烯含量小于1 mg·L-1時,蘋果處于未成熟的狀態;乙烯含量在1~6 mg·L-1時,蘋果處于成熟的狀態;乙烯含量高于6 mg·L-1時,蘋果過成熟,處于次新鮮的狀態。通過試驗證明,不同新鮮度的蘋果散發的乙烯濃度具有鮮明的區分性,乙烯含量可以作為蘋果鮮度檢測的一個重要指標。張艷麗等[8]采用氣相色譜檢測技術,對4種‘紅富士蘋果的香氣物質成分和含量進行分析,檢測到36種香氣物質,其主要成分為脂類,其次為醇類。含有2-甲基丁酸己脂和己醛等特有香氣物質的果實風味較好。Baietto等[9]探討了目前電子鼻的使用情況,指出其在辨別復雜的水果混合揮發物方面非常有效,可以作為新的高效工具對水果的香氣進行分析,以取代傳統的昂貴的水果香氣評估方法。研究提供了氣體傳感器陣列在水果識別、栽培品種鑒別、成熟度評估和水果分級等方面的有效數據。Valente等[10]通過將傳感器陣列與無人機技術相結合,根據果園中乙烯濃度判斷蘋果是否成熟,實現對蘋果林中的蘋果成熟度進行監測。
以上研究表明,蘋果的新鮮度、風味、成熟度與其散發的氣味之間存在聯系,但目前尚未見報道將蘋果散發的氣味與蘋果種類進行關聯研究。本文利用金屬氧化物半導體(MOS)傳感器陣列采集被測樣本散發的氣體,并將擬合結果通過識別算法與蘋果種類進行關聯研究,為蘋果的準確分類提供判別的依據。
1 材料與方法
1.1 蘋果種類識別系統硬件開發
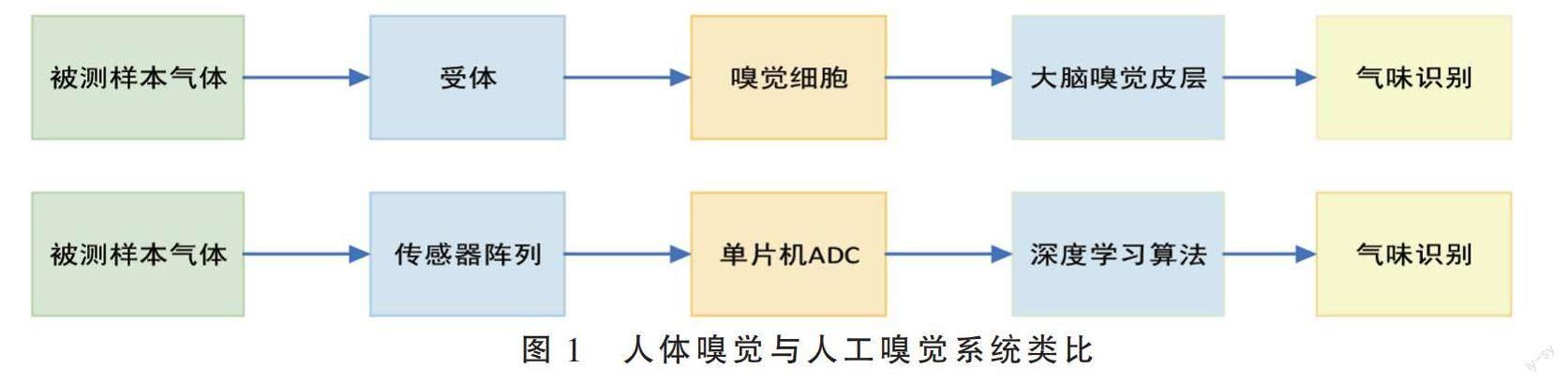
由傳感器陣列和上位機組成的人工嗅覺系統與人體嗅覺系統類似,如圖1所示。MOS傳感器陣列通過模仿生物嗅覺神經元,在檢測氣體的同時檢測編碼的尖峰信號[11],在傳感器內部實現模擬人類神經形態的功能,上位機中的機器學習算法模擬人類大腦對被測樣本進行識別。硬件系統搭建如圖2所示,電路系統為:直流穩壓電壓源給傳感器陣列提供5 V的工作電壓,單片機信號采集模塊由上位機PC端供電以方便采集信號的傳輸。傳感器陣列進行集體響應,優點是簡化了傳感器陣列的氣路設計,降低了信號采集的難度,簡化氣路的同時縮短了氣體與傳感器中氧化物反應的時間,提高了系統的效率[12]。
為避免傳感器的交叉敏感性給系統帶來的誤差,選擇8個不同型號的TGS金屬氧化物半導體氣體傳感器組成傳感器陣列[13],如圖3所示。本系統采用日本TGS系列傳感器,其電阻RS與待測樣本之間的濃度關系如公式1所示。
式中,A和α是只與目標氣體相關的常數,通常用于描述被測氣體濃度C發生變化時,MOS傳感器對濃度變化的分辨程度,通常由費加羅的傳感器手冊給出,與傳感器的特性有關,且α≤0.6。
選擇傳感器濃度響應區間與蘋果散發的香氣濃度相對應的傳感器以保證被測氣體濃度數據能夠被正常采集[14]。反復測試后,選擇的傳感器型號及其性能指標如表1所示。其中S3、S7、S8傳感器對氨氣、乙醇和硫化氫有良好的響應特性,適用于水果的特征氣體檢測。由于TGS系列傳感器的廣譜性,選擇S1、S2、S4、S5、S6對蘋果中的其他氣體進行響應,減小傳感器的交叉敏感性。測量范圍的單位PPM全稱parts per million,即一百萬體積的空氣中所含污染物的體積數。
1.2 試驗過程
本試驗用到的蘋果樣品為2類:分別是產自甘肅天水市的‘花牛與新疆維吾爾族自治區的‘阿克蘇。每種蘋果樣本為20個,每個樣本取4個不同時期分別進行試驗測量,共進行160次數據測量。選取大小一致外表完好的蘋果進行編號,將編好號的蘋果放入750 mL的密閉容器內,常溫平衡20 min,傳感器陣列預熱15 min,氣泵流量進氣和出氣均設置為100 mL·min-1,樣本測定時間為180 s。隨著樣本蘋果散發的各種氣體濃度的變化,得到不同種類散發氣體原始濃度數據,如圖4所示。
圖4-A、圖4-B為部分‘花牛的氣體濃度響應曲線,圖4-C、圖4-D為部分‘阿克蘇的響應曲線,由于TGS2602的靈敏度最大,故2種被測樣品的最大響應曲線均來自硫化氫傳感器。由圖4可知,被測氣體穩定時,‘花牛樣品中的烷類氣體與乙醇氣體的差別較大,氫氣含量轉化為電壓值高于2 V;‘阿克蘇樣品中烷類氣體與乙醇氣體相差則較小,氫氣含量轉化為電壓值低于2 V。
1.3 單一模式識別算法模型研究
本文采用線性判別分析(Linear Discriminant Analysis,LDA)、邏輯回歸(Logistic Regression,LR)、鄰近算法(K-NearestNeighbor,KNN)、前饋神經網絡(Back Propagation,BP)4種單一算法對測得的樣本數據進行訓練和測試。
LDA是一種有監督的學習算法[15]。LDA的思路為:找到一個最優的向量,將高維空間中的樣本點(特征向量)都投影到這個最優向量的方向上,投影結果即為判斷類別的依據。為了尋找一組數據集的最優投影方向,首先要考慮種類內的緊湊性和不同類別間的分離性,即‘花牛與‘阿克蘇樣本類內距離和類間距離,如圖5所示。
類內距離和類間距離的計算公式分別為:
式中,a1和a2分別表示‘花牛和‘阿克蘇響應數據特征向量集合;m1和m2表示2個類別的樣本均值向量。
LDA求解的目標是最小化同類樣本類內距離,最大化不同類樣本類間距離。將高維特征記作x,投影后向量記作ω,2個類別的樣本高維度特征均值向量分別記作μ1和μ2,投影后的兩均值點則分別為ωTμ1和ωTμ2,投影后的一維特征為ωTx,將投影后的一維特征點帶入上述由類內距離和類間距離組成的目標函數得到公式4,最大化類間距離從而對不同種類蘋果的數據進行分類。
LR[16]是在線性回歸的計算結果上加上一個Sigmoid函數,將線性回歸的數值結果轉化為0到1之間的概率。對2種蘋果進行分類,建立如下線性方程:
式中,w為自變量系數矩陣;x為特征值,w0為偏置項。
將線性方程與Sigmoid函數相結合得出用于概率計算的歸一化指數函數。
式中,ezk為類別K的得分經過指數函數轉化后的值;∑l k =1 ezl表示所有類別得分經過指數函數轉化后的值的總和。
每個類別的得分通過指數函數轉化為正數,并對2個類別得分進行求和,類別K的得分除以總和獲得類別K的歸一化概率值。這樣可以將‘花牛和‘阿克蘇的分類問題轉化為概率計算問題,方便進行概率預測和決策。
KNN算法是一個簡單而經典的機器學習分類方法[17]。通過度量待分類樣本和已知類別樣本之間的距離(通常使用歐氏距離)或相似度,對樣本進行分類。因為K最近鄰算法在分類時只根據周圍最近鄰的一個或幾個樣本來對待測樣本進行分類,根據計算出來的歐氏距離大小對樣本進行遞增排序,距離越小相似度越高。統計K個最近的鄰居樣本點分別屬于每個類別的個數,采用投票法和少數服從多數的原則,將K個鄰居樣本點里出現頻率最高的類別,作為該樣本點的預測類別。適合蘋果二分類中類域交叉重疊較多的樣本。
BP神經網絡是一種按照誤差逆傳播算法訓練的多層前饋網絡[18],能學習和存貯大量的輸入—輸出模式映射關系,其核心是使用梯度下降法,通過反向傳播不斷調整神經網絡的權值和閾值,從而最小化網絡的誤差平方和。BP神經網絡由輸入層、隱藏層和輸出層構成,在此結構中信號向前傳播,誤差向后傳播。利用BP神經網絡進行訓練時,樣本數據分為訓練集和測試集,訓練集用于發現和預測樣本數據和分類之間的關系,測試集用于評估關系強度。圖6是1層隱藏層的神經網絡結構。數學表達式為:
式中,f為非線性單元,即模型中的sgn(·)函數;(ω11,b11)和(ω12,b12)分別為輸入層連接到2個隱藏層節點的權重參數向量;(ω1,b2)為隱藏層到輸出層的參數;h=(h1,h2)為隱藏層輸出。
1.4 基于Stacking的融合算法模型研究
集成學習是建立在統計學習理論基礎上的多算法融合的機器學習方法[19],可以克服單一模型識別準確率呈邊際效用遞減趨勢的缺點。多模型融合時既要考慮每個基學習器的識別能力,也要考慮各學習器組合的效果。算法模型差異度較大時能夠最大程度體現不同算法的優勢。本文采用Person相關系數對各個模型的誤差差異度進行計算[20],以此分析不同的基學習器之間的關聯程度,二維向量的Person相關系數計算方法如下:
基于此研究,本文在對樣本二分類的基礎上提出了一種基于Stacking框架的算法融合方法,研究單一機器學習和集成學習在蘋果氣味樣本二分類上的適用性。原理如圖7所示。
基于Stacking框架的蘋果二分類方法流程如圖8所示。按照5折交叉驗證思想將初始訓練集分成5個訓練子集記作S1、S2...S5,其中S1、S2、S3、S4用來訓練第1層分類模型,S5用來測試第1層分類模型;每個訓練子集均做1次測試集;初始化1個測試集預測結果矩陣,將第1層預測的結果放在該矩陣中作為第2層模型的輸入,最后輸出結果矩陣,即測試集上的分類結果。
2 結果與分析
2.1 單一分類算法的超參選擇與關聯度分析
為優化算法模型,首先對各個基學習器冗余信息進行篩選[21]。本文的特征信息為傳感器采集的電壓峰值數據,對于不同的算法傳感器陣列輸入的特征貢獻度也不同。各個基學習器的特征貢獻度如圖9所示。系數既可以為正,也可以為負。正數表示預測類別1的特征,負數表示預測類別0的特征。由圖9可知,傳感器0、5和7對LDA算法的貢獻度較大,在訓練模型時5號傳感器TGS2602應占比最重,0號TGS2603和7號TGS2602次之。LR、BP神經網絡和KNN算法的貢獻度同理。
LDA算法通過拉格朗日乘子法對輸入的數據集進行特征值提取,使用hθ(x)=θ0+θ1 x1+θ2 x2+…+θ8 x8的8輸入模型對其進行θ值計算。多次訓練后得到θ1~θ8的值分別為2.076 949 46e-03、2.125 127 04e-04、-9.578 842 53e-05、-6.149 024 72e-04、-2.866 366 30e-04、-3.594 670 69e-03、-2.464 231 56e-04、2.270 187 30e-03,截距θ0的值約為-2.71。‘花牛和‘阿克蘇的氣味與傳感器電壓值的3D關系如圖10所示,藍色o代表‘花牛,紅色x代表‘阿克蘇。
LR模型采用準確率(Accuracy),召回率(Recall)和精確率(Precision)3項指標來評價分類結果。本次分類用到的數據共171組,從中隨機選擇120組作訓練集,51組數據作測試集。其中正確率、召回率和準確率的值見表2。
K-近鄰算法中的K值表示選擇K個最近的鄰居進行參考。K值較小時間模型的復雜度高,包容度也高,模型訓練誤差小,泛化能力弱;K值較大時模型復雜程度低,模型訓練誤差大,泛化能力強。本文中K值和模型精確度如圖11所示。由圖11可以看出,K值取1時,模型的精確度最高。本文僅對2種蘋果進行分類,故K值取1時,模型擬合能力較強,此時決策只根據最近鄰的訓練樣本給出結果,當訓練種類過多,訓練中包含噪聲樣本時,K值取3會獲得更佳的擬合效果。
BP神經網絡采用正確率、召回率和F1共3項指標來評價分類結果的好壞,其中F1=2×正確率×召回率/確率+召回率 用于綜合反映整體的指標。對試驗數據進行處理,第1列為標簽列,將‘花牛種類標記為“0”,‘阿克蘇種類標記為“1”,訓練集和測試集的比例為7∶3,迭代次數設置為2 000次,訓練后的結果如表3所示。
使用5折交叉驗證的網格搜索法觀測不同超參數在各模型上的預測效果,從而確定各模型的最優超參數組合。各單算法模型的超參數及模型準確率如表4所示,單個模型算法結果如圖12所示。
2.2 基于Stacking框架的融合算法分析
Stacking多模型融合算法[24]需要在不同的數據空間角度和數據結構角度來觀測數據,故第1層模型要選擇差異度較大的模型作為基學習器。為選取最佳的基模型組合,首先對各個基學習器進行單獨預測,綜合比較單模型誤差,采用二維向量的Person系數計算相關性指標,各單模型算法的誤差相關性如圖13所示,顏色越深表示相關度越高。
由圖13可知,由于各算法學習能力較強,各個模型之間的誤差相關性普遍較高,可以選擇以上4種模型進行融合集成學習。為避免過擬合的情況,第2層選擇結構簡單且泛化能力強的LR模型作為元學習器。最終得到結果矩陣和測試集之間分類的準確率為97.14%。為進一步驗證Stacking集成模型中基學習器對識別能力的影響,表5總結了不同基學習器組合的識別結果。結果表明,使用不同的基學習器對識別結果影響較大,使用相關性小的基學習器會使Stacking模型識別能力更加優異。
3 討論與結論
以上研究表明,蘋果種類與氣味可以通過人工嗅覺系統建立聯系。基于LDA、LR、KNN和BP神經網絡4種單一分類算法對‘花牛和‘阿克蘇進行分類其準確率分別為86.83%、85.33%、91.26%、85.00%;基于Stacking框架的二分類融合算法考慮到各基學習器之間的關聯度,不同的基學習器融合后的效果各不相同,當基學習器為LDA、LR、KNN、BP,第2層模型為LR時融合模型的準確率最高,此時基于Stacking框架的融合模型的分類準確率為97.14%。其他3個單一模型融合后的分類效果則不如KNN單一模型,故在算法融合時需要考慮各個模型之間的協同作用,才能有效地解決單一模型泛化能力弱的問題。以上研究表明,基于多傳感器人工嗅覺系統及機器學習模型的蘋果種類識別系統可對蘋果分類作出有效判斷,可為受主觀因素影響的感官評價提供客觀參考,提高蘋果種類判斷的準確性。本研究提出的人工嗅覺系統有效地避免了檢測過程中對水果樣本的破壞,大幅度降低了檢測成本和品種識別的難度。雖然本研究目前局限于二分類的判別,但當需要分類的蘋果種類增加時,依然可以選擇多傳感器和機器學習組合的模式進行分類。
參考文獻:
[1] MOSTAFA S, WANG Y, ZENG W, et al. Floral scents and fruit aromas: functions, compositions, biosynthesis, and regulation[J]. Frontiers in Plant Science, 2022, 13: 860157.
[2] 鮮義坤, 楊楠, 孔凌, 等. 圈養大熊貓所食蘋果和胡蘿卜的氣味特點與香氣成分研究[J]. 飼料博覽, 2020(6): 1-9, 19.
[3] 何馥嫻, 蒙慶華, 唐柳, 等. 高光譜成像技術在水果品質檢測中的研究進展[J]. 果樹學報, 2021, 38(9): 1590-1599.
[4] 凡建. 基于近紅外光譜傳感器的便攜式食品檢測器的設計與實現[D]. 南京: 南京郵電大學, 2019.
[5] 乜蘭春, 孫建設, 陳華君, 等. 蘋果不同品種果實香氣物質研究[J]. 中國農業科學, 2006, 39(3): 641-646.
[6] 楊艷菊, 黃成鈞. 人工神經網絡的蘋果氣體識別算法研究[J]. 銅陵學院學報, 2010, 9(2): 76-78.
[7] 郭清乾, 馬劉正, 孫海峰, 等. 電化學傳感器水果成熟度檢測技術的研究[J]. 河南農業大學學報, 2017, 51(6): 839-844.
[8] 張艷麗. 靜寧縣4種紅富士蘋果香氣物質成分及含量檢測與分析[J]. 安徽農業科學, 2019, 47(12): 207-209, 214.
[9] BAIETTO M, WILSON A D. Electronic-nose applications for fruit identification, ripeness and quality grading[J]. Sensors, 2015, 15(1): 899-931.
[10] VALENTE J, ALMEIDA R, KOOISTRA L. A compre-hensive study of the potential application of flying ethylene-sensitive sensors for ripeness detection in apple orchards[J]. Sensors, 2019, 19(2): 372.
[11] HAN J K, KANG M G, JEONG J, et al. Artificial olfactory neuron for an in-sensor neuromorphic nose[J]. Advanced Science, 2022, 9(18): e2106017.
[12] 王辰, 粟勇, 吳濤, 等. 一種傳感器陣列的封閉氣路設計方法及封閉氣路: CN202111579090.0[P]. 2022-04-01.
[13] 宋婷婷. 基于MOS氣體傳感器陣列的混合氣體檢測方法研究[D]. 哈爾濱: 哈爾濱理工大學, 2022.
[14] 謝曉錚, 夏炎. 電子鼻的核心——氣體傳感器的研究與應用[J]. 大學化學, 2021, 36(9): 2012045.
[15] 付榮榮, 李朋, 劉沖, 等. 基于線性判別分析的決策融合腦電意識動態分類[J]. 計量學報, 2022, 43(5): 688-695.
[16] 王正存, 肖中俊, 嚴志國. 邏輯回歸分類識別優化研究[J]. 齊魯工業大學學報, 2019, 33(5): 47-51.
[17] XING W C, BEI Y L. Medical health big data classification based on KNN classification algorithm[J]. IEEE Access, 2020, 8: 28808-28819.
[18] 吳貴軍, 范鵬生, 陳浩辰, 等. 基于深度學習的數據分類預測及應用[J]. 無線互聯科技, 2022, 19(8): 126-127.
[19] 史佳琪, 張建華. 基于多模型融合Stacking集成學習方式的負荷預測方法[J]. 中國電機工程學報, 2019, 39(14): 4032-4041.
[20] 張露康, 王海蓉, 古可言, 等. 基于Pearson相關性分析的交通樞紐站客運量預測模型分析研究[J]. 黑龍江交通科技, 2023, 46(3): 137-139.
[21] 劉培江. 基于Relief-F學習算法的煙葉近紅外光譜特征貢獻度分析[J]. 科學技術創新, 2022(25): 49-53.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
