結合改進注意力機制的YOLO目標檢測算法
2023-07-17 08:51:11李杰
計算機時代 2023年7期
李杰
關鍵詞:YOLO;目標檢測;多尺度卷積;注意力機制
0 引言
自從Hinton 提出利用神經網絡對圖像數據中的高維特征進行自主學習[1]以來,基于深度學習的目標檢測已成為計算機視覺領域中一個重要的研究熱點[2]。目標檢測的方法主要分為雙階段和單階段目標檢測算法。雙階段目標檢測算法,如Fast R-CNN[3]、Faster R-CNN[4]等,都是通過生成預選框再利用神經網絡對候選框進行分類識別。單階段目標檢測算法,如YOLO (you only look once) [5]、YOLO 9000[6]等,將目標檢測問題轉化為回歸問題,由一個無分支的深度卷積網絡實現目標的定位和分類。單階段算法有著較高的檢測速率,但還存在檢測精度不足的問題。
注意力機制是對特征圖進行加權處理[7],旨在突出強調目標信息。Hu[8]等人通過卷積運算學習各通道權重來自適應地重新校準通道特征響應。Woo 等人提出一種混合注意力機制CBAM(convolutional blockattention module)[9],將特征圖沿通道和空間兩個不同的維度順序地進行自適應特征細化。Sun 等人將ShuffleNet 結構引入到YOLOv4 中[10],減少參數量的同時檢測精度和速度方面也有所提升;Fu 等人將CBAM注意力模塊添加到YOLOv4-head 中[11],對小目標、重疊目標具有更好的檢測效果。但上述研究還存在檢測精度不足或是沒有在大型公共數據集上進行綜合性能測試。
為此,本文在YOLOv5s 的基礎上進行了研究和改進。①將多尺度卷積與注意力機制結合,提出一種改進CBAM 注意力機制模塊,增大特征提取模塊的感受野;②將改進CBAM 模塊引入YOLOv5s 網絡中,使用改進后的注意力機制模塊進行特征篩選,提高改進檢測網絡準確率。
1 YOLOv5s 和CBAM 算法
1.1 YOLOv5s 算法
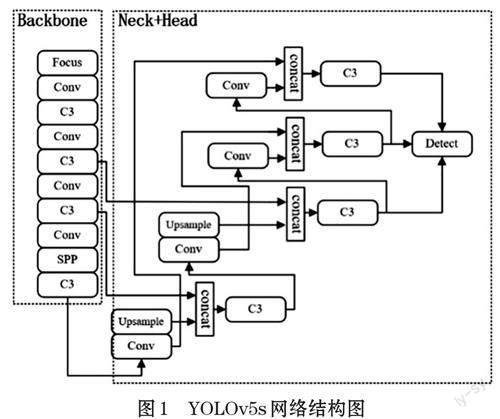
本文在YOLOv5s網絡的基礎上進行改進。YOLOv5s的網絡結構分為主干網絡部分Backbone、特征增強部分Neck 和預測部分Head,如圖1 所示。
網絡主干Backbone 主要由連續卷積模塊Conv 和利用劃分通道的思想構建的C3 模塊。C3 模塊是由1×1 和3×3 卷積構成,包含LeakyReLU 函數激活的BottleneckCSP 結構。主干網絡末端還加入一個特征金字塔池化模塊SPP,使用多尺度的特征融合以獲取更多小目標的有用信息從而提升算法對小目標檢測的精確度。
特征增強Neck 部分采用了FPN[12]+PAN 結合的方式對特征進行融合從而獲得更好的效果。PAN 包含了自上而下和自底向上兩條路徑上的特征融合,這也使網絡獲得更高的性能。
預測部分Head使用的是GIOU_Loss作為Boundingbox 的損失函數,并且在進行非最大值抑制時引入加權因子,在Bounding box 回歸時平衡了正負樣本之間的差距。
1.2 CBAM 算法
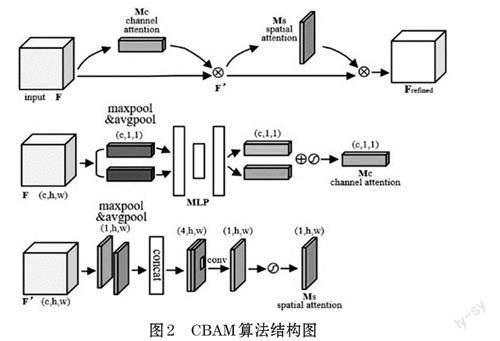
注意力機制是一種能夠讓神經網絡擁有能區分重點區域信息的能力,并對該區域投入更大的權重,突出和加強有用特征,抑制和忽略無關特征。由Woo等人提出的CBAM 算法是一種混合注意力機制。算法結構如圖2 所示。
CBAM 注意力機制可分為兩個順序子模塊:通道注意模塊和空間注意模塊。結構采取串聯形式。Woo等人已經證明將通道注意子模塊放在空間注意子模塊之前會有更好的效果[9],因此本文也使用相同的順序結構。
2 引入多尺度卷積的改進注意力機制
傳統混合域注意力機制CBAM,注意力子模塊會將特征圖直接進行通道域和空間域的全局最大池化和全局平均池化。這樣做法雖然能夠簡便的提取通道域和空間域的權重,但模塊對于特征圖中的信息的利用率低,從而影響檢測網絡的準確性。
本文沿用傳統混合域注意力機制CBAM 的順序串聯結構,并對其通道注意子模塊和空間注意子模塊進行了改進,構建一種改進CBAM 注意力機制模塊,下面描述每個改進注意力子模塊的細節。
2.1 通道注意子模塊
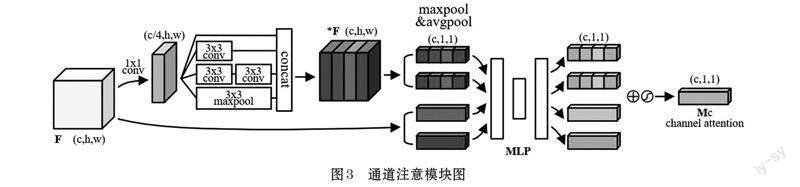
將多尺度卷積引入到注意力機制中,基于便利性也為了減少網絡參數只使用3×3 的卷積,同時結構中保留了一個沒有任何操作的路徑來增加網絡性能。此外,池化操作對于當前卷積網絡的性能提升是必不可少的,因此添加一個并行池化路徑也具有好的效果[14]。為了避免池化層的輸出與卷積層的輸出合并會導致特征圖維度的增加,先使用1×1 卷積來約簡計算,由于有共計四層的輸出,所以將原特征圖的通道數降為原來的1/4。
對于一個輸入特征圖F ∈ Rc × h × w,通道注意子模塊對原特征圖進行兩路并行處理,第一部分進行多尺度卷積操作生成新的特征圖*F ∈ Rc × h × w 再進行最大池化和平均池化,第二部分不進行任何操作直接進行最大池化和平均池化,得到四個的通道注意力向量:{ } Fcmax ,F cavg ,*Fcmax ,*F cavg ∈ Rc × 1 × 1,分別表示平均池化特征和最大池化特征。利用一個共享的多層感知機(multi-layer perceptron, MLP) 學習各通道信息的重要性,最后將四個通道注意力向量逐元素求和來合并再經過Sigmoid 函數激活得到最終的通道注意權重Mc(F)。簡而言之,通道注意力權重計算公式為:
2.2 空間注意子模塊
將通道注意的結果進一步進行空間權重的提取。空間注意子模塊對輸入特征圖F' ∈ Rc × h × w 也進行與通道注意子模塊相同的兩路并行處理,第一部分使用相同的改進多尺度卷積生成新的特征圖*F' ∈ Rc × h × w再沿通道軸應用最大池化和平均池化,第二部分不進行任何操作,直接應用最大池化和平均池化,將得到4個的空間注意力矩陣:{F's }max ,F 'savg ,*F 'smax ,*F 'savg ∈ R1 × h × w,分別表示通道中的平均池化特征和最大池化特征,并將它們連接起來以生成有效的特征描述圖。在特征將通道權重Mc (F)與輸入F進行對應通道的加權,得到通道注意的結果。共享網絡MLP 是帶有一個隱藏層的多層感知器,為了減少參數量,隱藏層的大小設置為R(c/r) × h × w,其中r 是縮減率,本文中r 設為16。這樣兩層卷積在減少卷積參數量的同時也能夠對各個通道上的特征重要程度進行學習。改進通道注意模塊如圖3 所示。
2.3 改進CBAM 注意力模塊
將兩個改進子模塊順序串聯,先用改進通道注意力子模塊校正,然后對結果在進行空間注意力子模塊校正。整個改進注意力過程可以用公式概括為:
相比CBAM 中只對原特征圖進行最大池化和平均池化操作,在改進CBAM 結構中增加了使用卷積、拼接的多尺度卷積運算來生成新的特征圖,兩路運算并行處理。引入多尺度卷積能夠提升運算所得的通道注意權重和空間注意權重的感受野,強調目標信息同時過濾其他冗余信息。
3 結合改進CBAM 的YOLOv5s 算法
在原始YOLOv5s 中,特征增強部分會對特征圖進行反復融合, 并且還會使用多個連續卷積運算。這種做法雖然能夠使不同尺度的特征信息相互結合,但此過程也會產生大量冗余信息,降低網絡的檢測精度。同時對高維特征圖使用多個連續卷積運算,增加網絡運行的參數和計算量,也會影響網絡的檢測性能[13]。
在目標檢測網絡中添加注意力機制,能夠顯著增強特征中的重要信息,對物體檢測有著重要的作用[7]。因此將改進CBAM 引入到YOLOv5s 中。在輸入預測部分進行預測前,使用改進后的注意力模塊對其進行處理以提取到更全面、更重要的目標信息,過濾其他冗余信息,增加檢測網絡的準確率[15]。改進后的YOLOv5s 網絡結構如圖5 所示。
4 實驗結果分析
4.1 數據集和網絡訓練
為驗證本文所提出的結合改進注意力機制的YOLOv5s 目標檢測網絡的性能, 在PASCAL VOC 數據集上進行了訓練和驗證。在本實驗中,將圖片轉換為長寬512 大小作為網絡輸入,選取VOC 2012 訓練驗證集及VOC 2007 訓練驗證集作為訓練數據,將VOC 2007 訓練驗證集部分數據作為驗證集。
本文在TeslaV100 上進行訓練和測試模型。操作系統是Ubuntu18.04,開發語言是Python,框架是PyTorch,訓練采用了Amd 優化器進行參數優化。在訓練時使用遷移學習加載預訓練模型。訓練網絡時,網絡輸入大小為512×512 彩色圖像,batch_size 為64,初始學習率為0.0032,迭代總批次為200,權重衰減設置為0.00012. 學習率采用余弦退火衰減來保證模型更好的收斂。
4.2 結果與對比
將訓練后的網絡在PASCAL VOC 測試集上進行測試,在IOU 閾值為0.5 的情況下,繪制了召回率-精確度曲線圖,如圖6 所示。橫坐標Recall 表示召回率,縱坐標Precision 表示精度。改進后的模型對各個類別均有一定的檢測精度,并對數據集中所有類別的平均準確率(mAP)達到了76.1%。
4.2.1 改進前后結果對比
為對比改進后的檢測網絡的檢測效果。分別對YOLOv5s、YOLOv5s+CBAM、YOLOv5s+改進CBAM三種模型在PASCAL VOC 測試集上的平均準確率mAP 和其他性能指標進行了測試。如表1 所示,其中加粗數值為三種模型中表現最優值。
實驗結果表明在兩種IOU閾值下,本文的YOLOv5s+改進CBAM 模型相較于其他兩種模型在平均準確率方面均有所提升。當IOU 閾值為0.5 時,本文方法相較于原始YOLOv5s 模型的mAP 上升了0.9%,相較于YOLOv5s+CBAM 模型的mAP 上升了0.3%。當IOU閾值在區間[0.5:0.95]時,本文方法較另外兩種模型分別提高了1.1%、0.4%。在檢測精度方面,YOLOv5s+改進CBAM 模型精度為78.4%,為最優值。在召回率方面較其他兩種模型低,但F1-score 均較其他兩種模型分別提高了1.2%、0.9%。
為了更直觀的發現改進網絡檢測能力的提升,實驗進一步獲取了改進前后的可視化測試結果,如圖7所示。
對比原始YOLOv5s 模型和本文的YOLOv5s+改進CBAM 模型,改進后的模型在復雜場景下能夠檢測出更多目標。對于圖中未遮擋的目標,改進后的模型能有更高的置信度。盡管有遮擋部分的目標較原始YOLOv5s 模型識別置信度有所下降,但改進后的模型仍然能成功檢測出這些目標,也進一步證明了改進后的模型有更好的檢測性能。
4.2.2 不同檢測算法對比
本文將改進后的網絡與近年來其他目標檢測網絡進行比較,結果如表2 所示,表中加粗數值為表現最優值。
以ResNet-152 為骨干的PS-DK 網絡,由于使用了足夠大且深的骨干網絡,其檢測準確率達到了79.5%,改進后的網絡的準確率較之低了3.4%,但改進后的網絡參數量更少,僅為PS-DK 網絡參數的1/10。另外對于一些輕量化網絡,如EEEA-Net-C2 網絡,盡管參數量有所增加,但在檢測準確率方面較之提高了4.4%。結果表明改進后的檢測網絡在與近年來其他先進的目標檢測網絡對比中,也表現出較好的性能。
5 結束語
本文提出了一種改進注意力機制模型,并將其引入到YOLOv5s 目標檢測網絡中,提高檢測網絡的準確率。提出改進CBAM 結構,引入多尺度卷積增加特征感受野提升算法性能的效果。YOLOv5s 目標檢測網絡在輸入預測部分前使用改進注意力機制模塊,提高網絡檢測的準確率。改進后的網絡在VOC 數據集上的準確率達到了76.1%,較原網絡整體準確率提升了0.9%,F1-score 也獲得了1.2% 的提升,同時在近年來的目標檢測網絡中表現出不錯的性能。接下來還將繼續優化網絡結構,同時研究如何提升對有遮擋的目標的檢測效果。
