“天鏡”全流程指標計算功能優化
2023-07-21 08:05:24王英杰
計算機技術與發展 2023年7期
徐 達,曾 樂,王英杰
(國家氣象信息中心,北京 100081)
0 引 言
氣象綜合業務實時監控系統—“天鏡”[1]是國家氣象信息中心為建設統一數據環境、整合分散獨立的監視業務建立的通用、綜合、高效的集約化監視平臺。“天鏡”能夠為全國氣象部門在收集、分發、入庫、數據同步各個環節提供實時觀測數據和產品的數據全流程監視服務。目前“天鏡”每小時接收處理氣象業務監視全流程[2]數據記錄達到3千萬條,累計接入的數據資料超過400種,為了使目前的數據全流程監視業務可以更高效地在大數據計算和分布式存儲架構上運行,需要對目前海量監視數據的處理中加大對計算策略和存儲策略的研究力度。
Spark[3]是對海量數據計算處理的重要工具和手段,是基于彈性分布式數據集(RDD)的數據結構,具有數據流模型特點。RDD將數據保留在內存中,且允許用戶程序多次查詢,降低了對磁盤和網絡的開銷,適用于在線計算和迭代計算。“天鏡”系統使用Spark計算全流程數據,并按全國、省、市縣維度的統計指標進行匯聚。氣象資料的接入和監視環節的擴展使得需要計算和處理的監視信息激增,使得Spark運行作業時間變長,這對于滿足時效性要求而言需要縮短計算任務的運行時間,一種方式是從Spark集群框架和配置參數進行修改和優化,另一種方式則是通過對程序代碼進行改動,采用最優的計算策略來提升計算效率。
1 研究環境簡介
1.1 國內外監控系統分析
2017年10月,中國氣象局批復了由國家氣象信息中心牽頭,國家級各業務單位共同參與建設的氣象綜合業務實時監控系統(一期)項目。該項目旨在建立技術先進的監控系統技術框架,實現綜合監視和告警運維核心功能,建立規范的監控信息采集接口,監視范圍橫向覆蓋氣象資料現有數據流程各環節,縱向覆蓋信息系統從網絡及安全、服務器、存儲、中間件、應用軟件運行狀態。氣象綜合業務實時監控系統(一期)計劃2018年底建成后,將完成氣象綜合業務實時監控的基礎框架,建立系統的硬件平臺和技術平臺,從技術上解決了原MCP系統面臨的性能瓶頸問題,建立規范化的監視信息采集接口,實現監視告警的核心功能,實現國家級基于CIMISS數據環境的資料數據流程的收集、分發、解碼入庫、接口服務等環節的監視,以及CMACast衛星廣播系統、部際系統等系統的監視。但是隨著監視信息不斷增長,現有的運行環境在處理計算上會有延遲,尤其是在中國地面分鐘級資料的實時監視上會出現頁面為0的情況[4]。
國外氣象行業的監視系統也是主要圍繞著數據傳輸網絡、數據收集生成、數據質量、觀測設備狀態進行監控,如美國國家海洋和大氣管理局(NOAA)建設了觀測系統監控中心(OSMC)實時監測全球海洋觀測系統的性能[5],歐洲中期天氣預報中心(ECMWF)通過常規觀測告警系統檢測數據可用性和質量問題[6],美國國家環境預報中心(NCEP)的實時數據監測系統(RTDMS)主要監測數據的數量和時效性[7]。國外的數據監視系統是基于傳統的數據資料文件入庫,并對該文件資料進行質量評估后,繪制該類觀測資料的打點時序圖,對資料進行分類監視。ECMWF和NOAA更加側重資料到報后的質量情況,通過設計測試的數值預報模式來校驗到報的觀測資料是否合格,通過地圖打點的方式提供數據服務,并用顏色來區分該類資料的數據質量情況。
1.2 “天鏡”系統
圍繞《全國氣象發展“十三五”規劃》提出的“智慧氣象”發展目標,氣象業務在實施現代化、信息化、集約化、標準化的進程中,都需要監控系統來保障業務的高效穩定運行。但是,各氣象業務的現有監控系統都是獨立開發和運維,監控系統分散且數量龐大,運行維護人力成本高;各監控系統僅監控業務流程中的獨立環節,上下游監控信息無法共享,缺乏對業務全流程的總體監控,出現故障時準確定位故障位置困難、分析故障原因不及時,導致業務監控運維效率低。因此,急需實現對觀測、信息、預報預測、公共服務及政務的全流程、全要素、全過程的一體化監控和運維,以提升氣象業務運行管理的質量和效率。2016年底,按照中國氣象局統一部署,由預報司牽頭組織與協調,觀測司配合,信息中心作為實施技術組組長單位,協同各成員單位上下一心,通力合作,共同推動氣象綜合業務實時監控系統建設,樹立和打造氣象綜合業務監控品牌——“天鏡”[8]。
1.3 氣象全流程指標
氣象全流程監控實現對數據從收集、分發、入庫、數據同步到應用的全流程、全生命周期監控。在收集環節由國內氣象傳輸系統(CTS)收到氣象資料后,經過文件打包處理后,把文件分發給業務系統和用戶。在入庫環節中解碼入庫程序按照氣象要素、時次等條件進行拆解,按照存儲規則錄入不同的數據庫中。為了提供氣象資料查詢服務,需要將解碼后的數據在不同類型庫中進行同步。在氣象資料全流程監視設計中需要對收集、分發、入庫、同步環節進行監視。全流程實時指標見表1,計算依賴于節目表信息和總控配置信息,節目表信息用來指定該類氣象資料資料是否為考核資料,總控配置信息主要包含:資料業務時次配置信息、單站的單環節的單時次及時配置信息、統計規則(時次、時次截日、時次截小時、小時、日)、各個環節之間的關聯關系、文件級資料的應收數、檢測告警開始時間、需要告警指標、告警持續時間等相關配置。

表1 全流程實時計算收集環節核心指標
1.4 Spark計算引擎
Spark是一種快速、通用、可擴展的大數據分析引擎,2009年誕生于加州大學伯克利分校AMPLab,2010年開源,2013年6月成為Apache孵化項目。目前Spark生態系統已經發展成為一個包含多個子項目的集合,包含SparkSQL、Spark Streaming、GraphX、MLlib、等子項目。
Spark是基于內存計算的大數據并行計算框架,與Hadoop的MapReduce相比,Spark基于內存的運算速度更快,同時保證了高容錯性和高可伸縮性,Spark實現了高效的DAG執行引擎,從而可以通過內存來高效處理數據流[9-10]。
在“天鏡”中,Spark的體系架構如圖1所示。“天鏡”采用Standlone模式部署Spark集群,通過Zookeeper,一個開源的分布式應用程序協調服務軟件進行集群管理,在Spark集群上創建常駐的SparkSession即常駐的Driver進程用于交互Spark程序,SparkSession中包含開源的ActorSystem,一套開源的用于設計跨處理器和網絡的可擴展彈性系統。服務端的ActorSystem向Zookeeper注冊自身的地址。在外部調度任務模塊的驅動下,將獲取服務端的Actor-System地址,隨機選擇其中一個地址,提交SprakSQL任務,SparkSQL任務提交成功后,會把任務和接收提交的ActorSystem信息注冊到Zookeeper,用于后續查看SparkSQL任務狀態和取消任務。
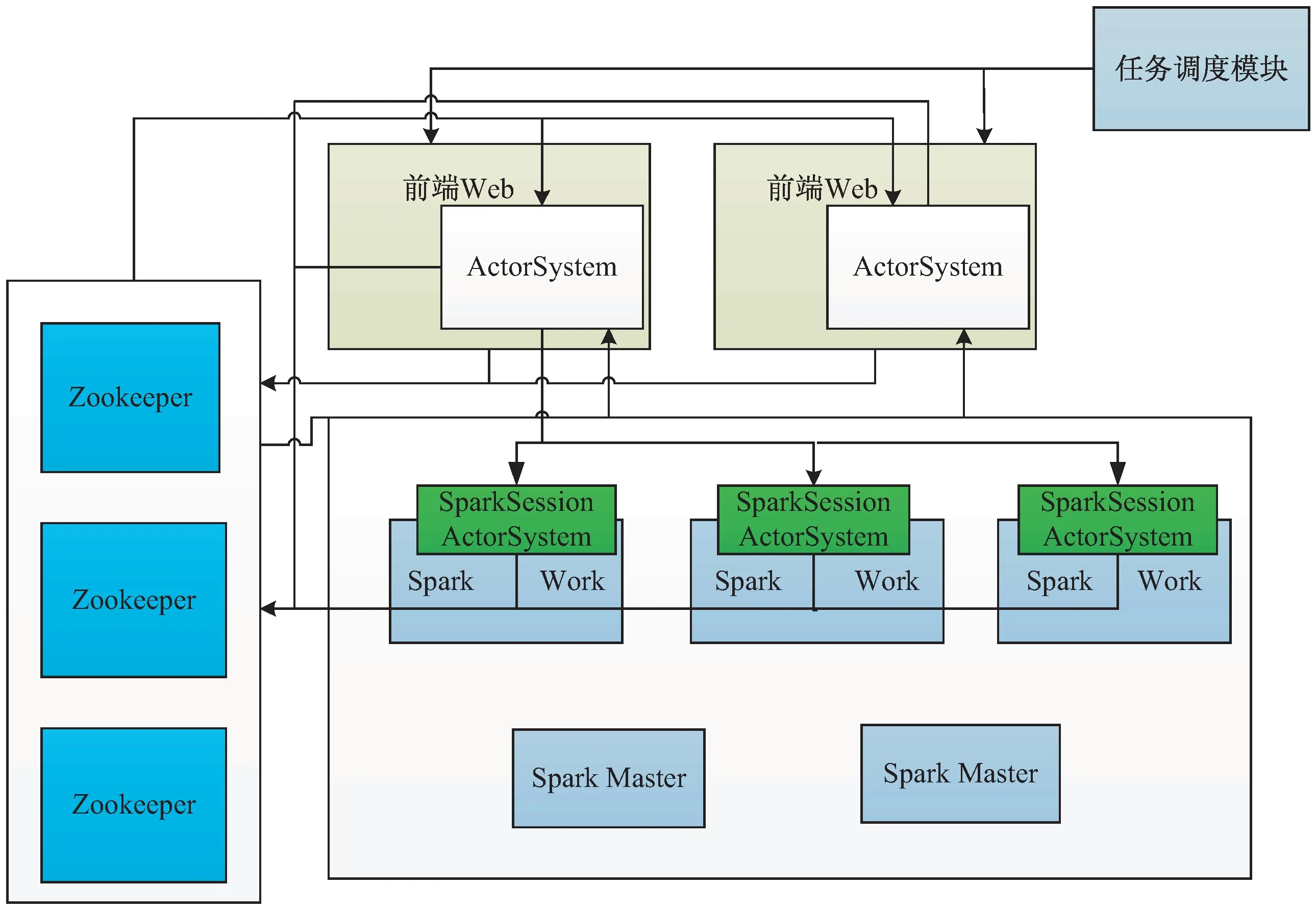
圖1 “天鏡”中Spark的體系架構
2 氣象全流程計算過程
全流程各環節監視信息通過接口網關進入后至高速緩沖通道,一路數據直接入庫進行持久化,一路數據進行標準化構建和數據清洗形成中間結果表(見表2)。
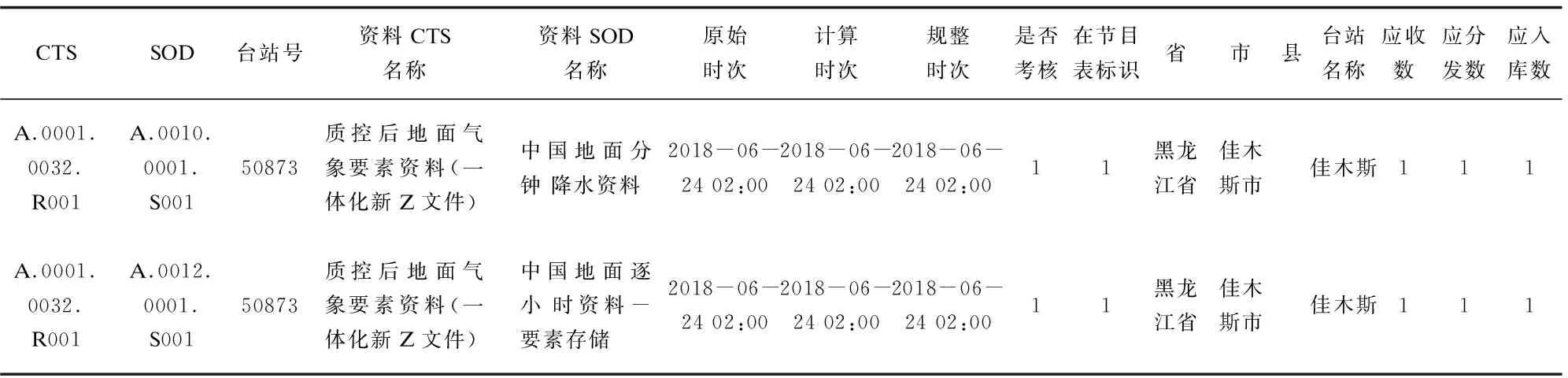
表2 臺站級資料預處理后中間結果表
根據總控配置表的業務頻次(cron表達式[0 0 0/1 * * ? ]、統計規則[時次、時次截小時、時次截日、小時、日])信息計算出業務時次,并生成一個sparkSQL文件存入到HDFS中,提交給spark計算,計算考核指標的SparkSQL語句如下:
1.--考核應收
2.sum(coalesce(CO_CHECK_TD,0))AS CO_CHECK_TD,
3.--考核及時收
4.sum( casewhen CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END) AS CO_CHECK_INTIME_ACTUAL,
5.--考核逾期收
6.sum( casewhen CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) AS CO_CHECK_LATETIME_ACTUAL,
7.--考核實收數
8.(sum( casewhen CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) + sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END)) AS CO_CHECK_ACTUAL,
9.--考核缺收數
10.(sum(coalesce(CO_CHECK_TD,0)) - (sum( casewhen CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) + sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END))) AS CO_CHECK_LOC,
11.--考核及時率
12.(sum( casewhen CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END)/sum(coalesce(CO_CHECK_TD,2147483646))) AS CO_CHECK_INTIME_RATE,
13.--考核到報率
14.((sum( casewhen CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) + sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END))/sum(coalesce(CO_CHECK_TD,2147483646))) AS CO_CHECK_RATE.
3 氣象全流程計算優化
3.1 運行環境與系統架構
“天鏡”系統部署在36臺IntelX86物理服務器上(見圖2),其中5臺服務器用于部署網關模塊(gateway),數據預處理模塊(standardizer)主要負責接收監視信息的收集和全流程中間結果(指標詳情)的處理,3臺服務器用于部署消息中間件(kafka)集群,用于數據的高速緩存,避免因數據量過大導致后端數據庫寫入壓力過大。18臺服務器部署分布式日志數據庫用于對監視信息的原始指標,中間結果,最終計算指標進行存儲。用于計算的Spark集群(版本2.3.1)[11]部署在5臺CPU 24核,內存256G,3.2TSAS磁盤,操作系統為Centos7.3服務器上。
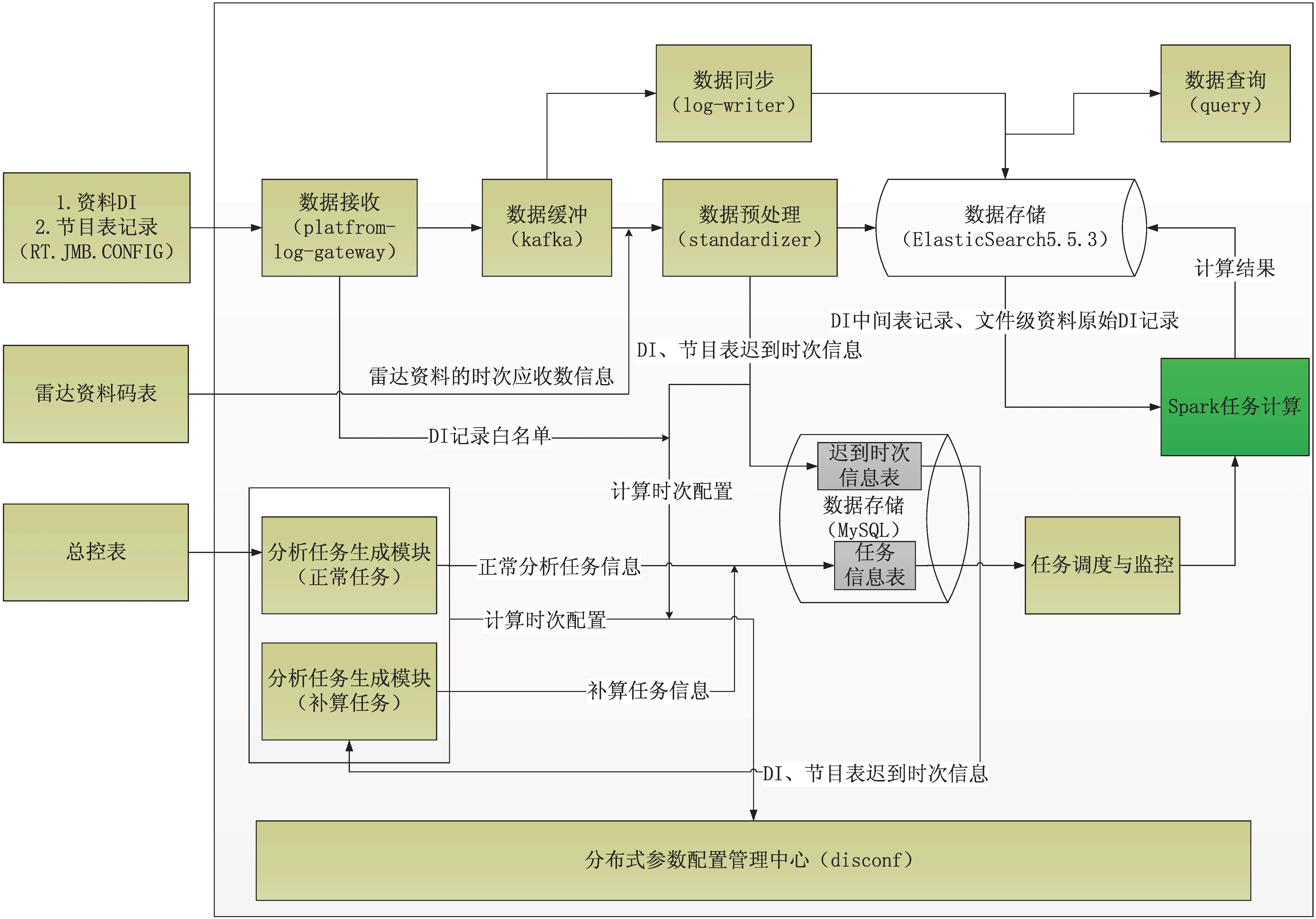
圖2 “天鏡”-氣象數據全流程系統架構
3.2 優化技術原理
基于Spark計算引擎對氣象全流程監視信息進行實時處理,作業調度任務每分鐘執行一次,按照臺站級氣象資料(StationDiStaticJob)和文件級氣象資料(FileDiStaticJob)分為兩個計算任務。隨著接入的氣象資料種類越來越多,每分鐘處理的監視信息也呈幾何級增長,執行的Spark任務的耗時在20分鐘以上,導致氣象全流程監視界面中氣象區域站資料無法及時顯示。與此同時,運維人員發現Spark集群中有個別節點的負載特別高,這種情況是因為數據源單個spark input read數據量過大,或者單個task相對于其他task spark input read較大的情況,導致的讀取數據源明顯不均勻[12]。因此盡量使用可切割的文本存儲,生成盡量多的task進行并行計算,可以從數據源避免傾斜,并從源頭增大并行度[13]。通過觀察Spark任務管理頁面可以看到已完成的計算任務資源使用和耗時情況,如表3所示,正常計算任務需要分配計算資源10核,內存5 GB。
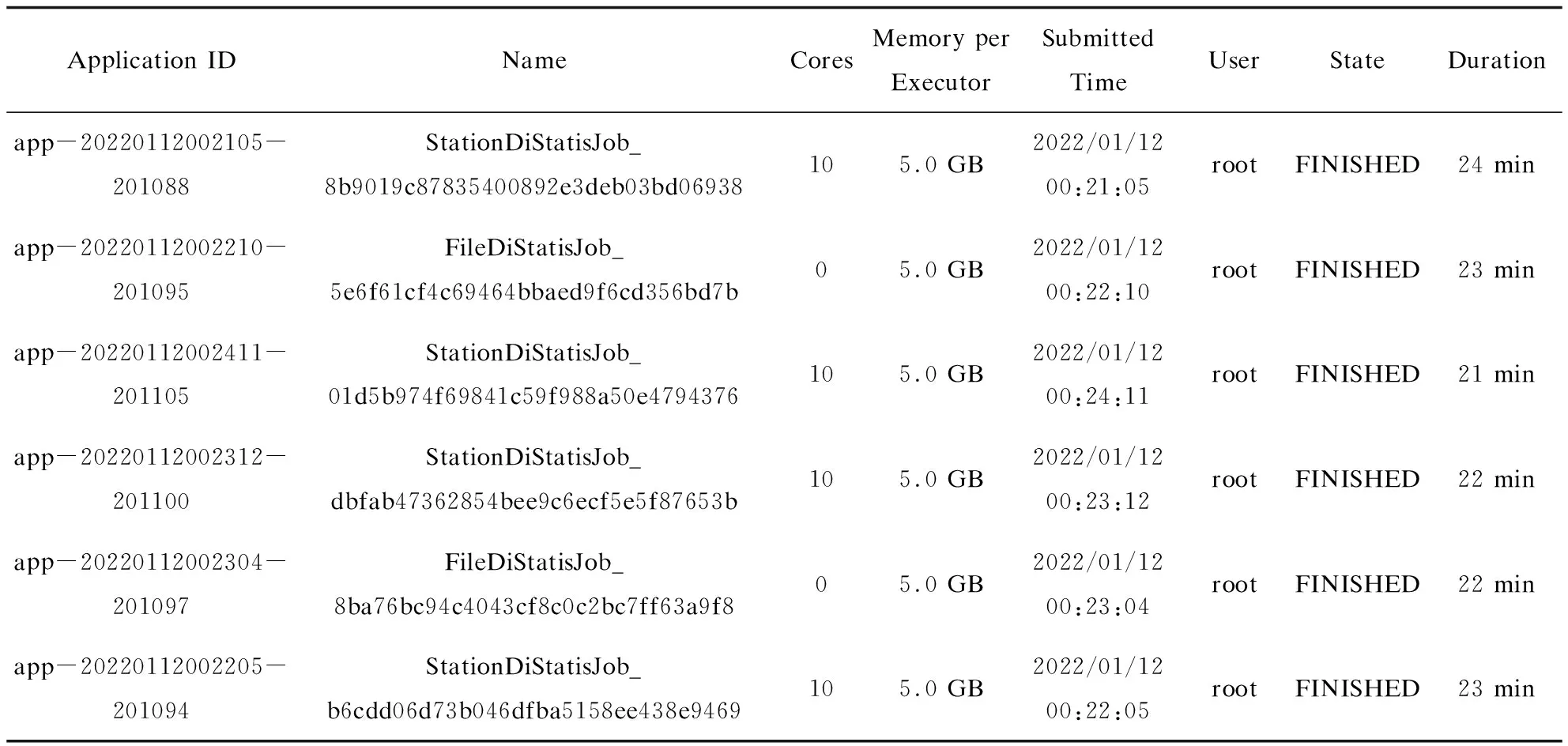
表3 優化前Spark任務運行監視結果
3.3 Spark任務優化過程
進行Spark計算任務的優化的目的,是為了充分利用硬件本身的性能,最大限度地提升Spark中Executor的執行效率[14-17]。依據氣象全流程監視界面資料展示情況,拆分為地面資料、海洋資料、高空資料、輻射資料、農業與生態資料、大氣成分、雷達數據、衛星數據、氣象服務產品、數值預報產品共10類資料,每類資料又分為考核資料和非考核資料。相較于優化前,雖然增加了SparkSQL模板的復雜度,但是提升了氣象考核資料的計算效率,該文以傳輸環節考核資料為例,新增的SparkSQL模板如下:
1.base.sql.co.checks=sum( casewhen CHECK = '1' then coalesce(CO_TD,0) ELSE 0 END) AS CO_CHECK_TD, sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END) AS CO_CHECK_INTIME_ACTUAL, sum( case when CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) AS CO_CHECK_LATETIME_ACTUAL, (sum( case when CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) + sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END)) AS CO_CHECK_ACTUAL, (sum( case when CHECK = '1' then coalesce(CO_TD,0) ELSE 0 END) - (sum( case when CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) + sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END))) AS CO_CHECK_LOC,(sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END)/coalesce(sum( case when CHECK = '1' then coalesce(CO_TD,0) ELSE 0 END), 2147483646)) AS CO_CHECK_INTIME_RATE,((sum( case when CHECK = '1' then coalesce(CO_LATETIME_ACTUAL,0) ELSE 0 END) + sum( case when CHECK = '1' then coalesce(CO_INTIME_ACTUAL,0) ELSE 0 END))/coalesce(sum( case when CHECK = '1' then coalesce(CO_TD,0) ELSE 0 END), 2147483646)) AS CO_CHECK_RATE
在向Spark進行任務提交時,客戶端處理程序需要將氣象資料按照上述分類進行拆解,核心代碼如下:
1.…
2.for (TabMcmConfig config : tabOminCmCcSubsystem Allconfigs) {
3.// 1、資料編碼
4.String ctsCode = config.getcCtsCode();
5.String sodCode = config.getcSodCode();
6.//資料大類
7.String dataClass = config.getDataClass();
8.String ctsSodCode = ctsCode.concat(":").concat(sodCode);
9.//文件級還是站點級
10.String dataSourceType = config.getcDataSource();
11.if ("1".equals(dataSourceType)) {
12.if(!fileDiComputeEnabled) {
13.continue;
14.}
15.dataSourceType = "file";
16.}else {
17.dataSourceType = "station";
18.}
19.…
此段代碼通過獲取總控配置后對每類氣象資料進行分類,分類后生成的計算任務與生成的SparkSQL模板匹配,從而完成計算任務拆解,單個SparkSQL只計算一類考核資料或者一類非考核資料。
3.4 全流程計算結果正確性驗證及性能優化分析
該文采用自動化測試的方法,由于對程序代碼結構進行了修改和微調,因此需要對優化后的全流程指標計算結果正確性進行驗證。正確性可以根據監視頁面中資料的統計指標和系統告警進行判斷,如圖3所示,可以通過查看Spark作業任務日志進行驗證,如表4所示。該文展示的全流程監視界面與優化前資料監視統計指標計算結果一致,并且中國地面分鐘降水數據在一級界面中可以顯示正常。優化后單個計算任務的計算時間控制2分鐘以內。
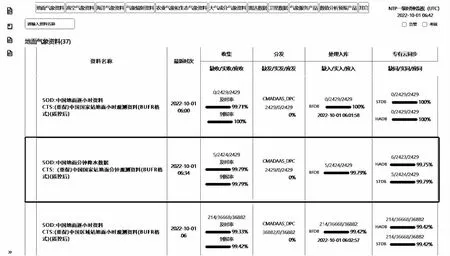
圖3 氣象綜合業務實時監控系統—“天鏡”全流程監視界面
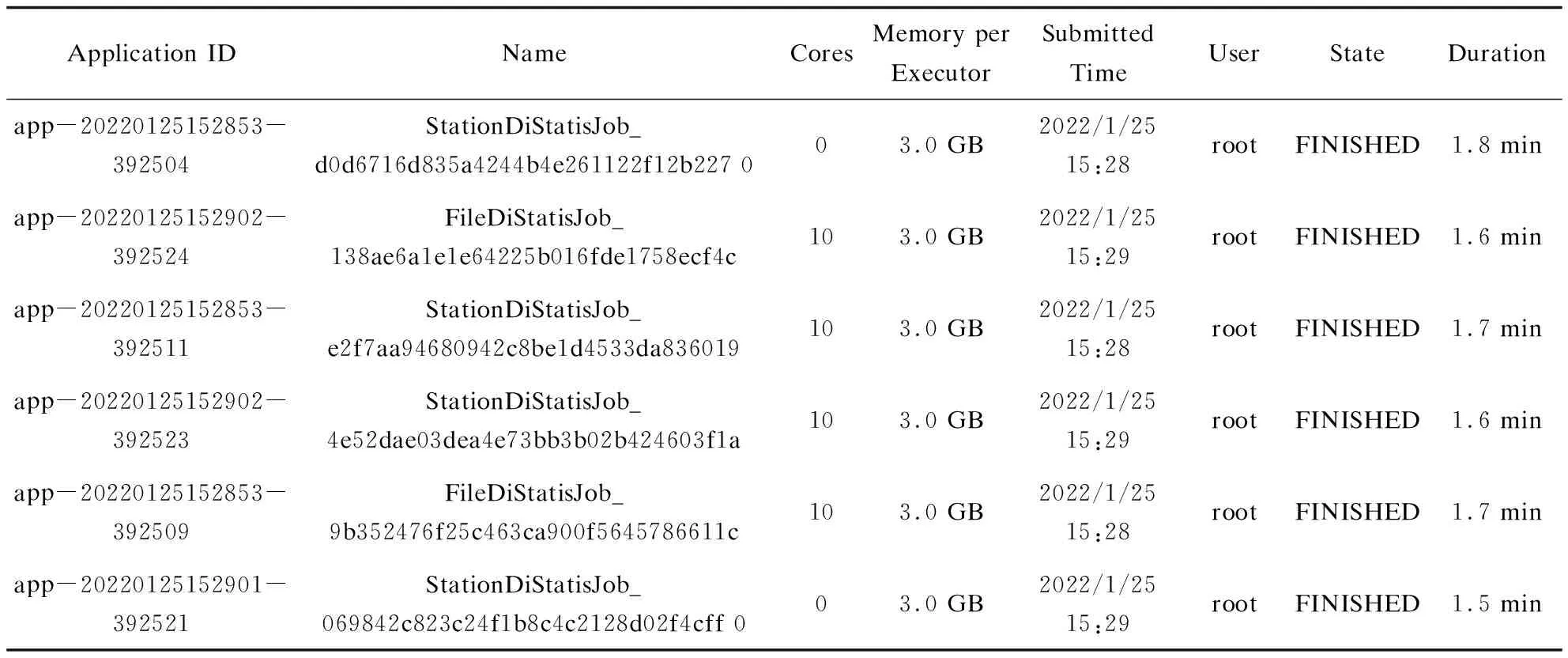
表4 優化后Spark任務運行監視結果
4 結束語
通過拆分計算任務,生成盡可能多的task增加Spark計算并行度,成功將氣象全流程計算框架優化并業務運行,如表5所示,獲得了10倍的加速效果,提高了程序的運行效率。但是“天鏡”系統在處理大數據計算時還是有瓶頸,原因是地面區域站氣象資料會產生大量重復數據,要能夠高效處理海量的監視數據,除了對計算任務拆分,還需要對計算任務設置優先級,針對核心資料優先分配計算資源計算,這就需要業務人員對資料的監視等級進行配置,同時要熟悉Spark資源分配機制,在此基礎上來做系統優化,能夠較好地提升優化效果。
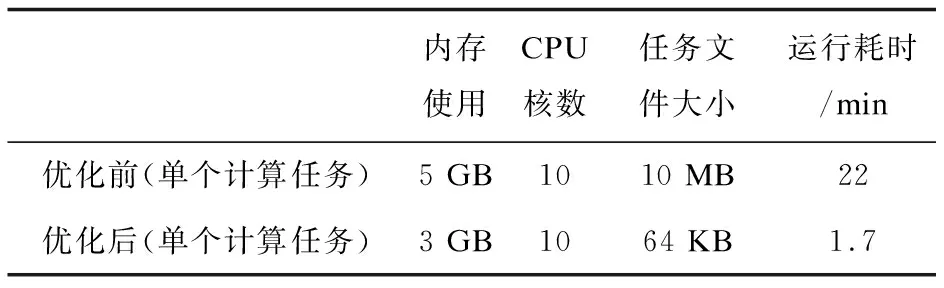
表5 “天鏡”全流程Spark計算任務優化前后運行時間
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
童話世界(2020年10期)2020-06-15 11:53:22
裝備制造技術(2019年12期)2019-12-25 03:06:46
當代陜西(2019年9期)2019-05-20 09:47:40
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
影劇新作(2017年4期)2017-03-22 05:47:21
中國衛生(2016年2期)2016-11-12 13:22:24
