二階段手寫漢字骨架提取優(yōu)化
2023-07-21 08:04:36陳泓漢熊顯航
計(jì)算機(jī)技術(shù)與發(fā)展 2023年7期
陳泓漢,王 濤,熊顯航
(1.華南師范大學(xué) 人工智能學(xué)院,廣東 佛山 528200;2.華南師范大學(xué) 計(jì)算機(jī)學(xué)院,廣東 廣州 510631)
0 引 言
圖像細(xì)化是在保持原圖像拓?fù)浣Y(jié)構(gòu)的情況下,抽出圖像的單像素寬度過程[1]。目前細(xì)化算法已廣泛應(yīng)用于運(yùn)動(dòng)檢測[2]、農(nóng)作物[3]、裂縫檢測[4-5]、工業(yè)儀表[6]和漢字研究[7]等場景。
文獻(xiàn)[8]提出基于ZS算法的改進(jìn)方法,通過刪除保留模板得到單像素且毛刺更少骨架。針對(duì)骨架多分叉點(diǎn)未合并問題,文獻(xiàn)[9]引入圓盤對(duì)其進(jìn)行合并,繼而修復(fù)。方法過程清晰,但分叉點(diǎn)會(huì)過度合并。通過骨架輪廓圓盤半徑信息,文獻(xiàn)[10]對(duì)畸變處進(jìn)行修復(fù),該方法過程耗時(shí)較多。文獻(xiàn)[11]提出復(fù)雜區(qū)域檢測法,并根據(jù)筆段方向及曲率進(jìn)行修復(fù)。該方法只適用字體寬度較細(xì)情況。
文中算法借鑒文獻(xiàn)[9-10]中的圓盤概念,考慮漢字方正特性使用矩形進(jìn)行分叉檢測。采用了二階段聚類合并克服文獻(xiàn)[9]以及文獻(xiàn)[11]存在的問題。根據(jù)區(qū)域畸變程度采用不同范圍修復(fù),同時(shí)對(duì)畸變區(qū)域歸類,采用相應(yīng)修復(fù)策略。
1 算法描述
提出的改進(jìn)算法核心優(yōu)化思路可分為兩個(gè)階段。第一階段是為了精準(zhǔn)找到字體畸變待修復(fù)區(qū)域即筆畫的交錯(cuò)處以及拐點(diǎn)處,通過引入字體寬度Wf概念進(jìn)行的二階段合并提高對(duì)不同字體交叉區(qū)域識(shí)別的準(zhǔn)確率;第二階段需要?jiǎng)澐只儏^(qū)域類型并采取相應(yīng)的策略進(jìn)行修復(fù)。
文章在傳統(tǒng)判斷拐點(diǎn)的基礎(chǔ)上,進(jìn)行二次篩選合并得到符合分叉點(diǎn)特征的點(diǎn)。第二階段是根據(jù)畸變區(qū)域信息,清空畸變區(qū)域重新連接分叉點(diǎn),形成更符合該手寫漢字風(fēng)格的骨架連接圖。
1.1 分叉點(diǎn)檢測
目前分叉點(diǎn)檢測方法常見的有角點(diǎn)檢測法[12]和段化法,這兩種方法都是在原始文字圖像上進(jìn)行處理,存在檢測耗時(shí)長以及誤判多等問題。
文章提出的分叉點(diǎn)檢測處理是細(xì)化后骨架,分為兩階段,一階段主要是篩選出分叉特征點(diǎn),二階段為對(duì)篩選的特征點(diǎn)簇群進(jìn)行聚類合并,從而得到準(zhǔn)確的單分叉點(diǎn)。
定義1 字體寬度Wf:未經(jīng)細(xì)化字體二值圖前景點(diǎn)數(shù)量與細(xì)化后的骨架全景點(diǎn)數(shù)量的比例,稱為字體寬度Wf,計(jì)算過程如式(1)所示:
(1)
其中,N(S)為細(xì)化后骨架圖前景點(diǎn)數(shù),N(0)為原二值圖前景點(diǎn)數(shù)
定義2 向量夾角:局部向量所形成的角度,如aij趨向于1時(shí),表示兩向量為平行關(guān)系,通過余弦相似度可以量化分支的方向關(guān)系,具體計(jì)算過程如式(2)所示:
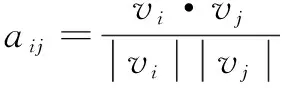
(2)
1.1.1 分叉特征點(diǎn)篩選
得到細(xì)化后的骨架與原圖信息,通過計(jì)算得到該手寫漢字字體寬度Wf,待篩選的特征點(diǎn)為Sd={P0|A(P0)≥3,P0=1},即該點(diǎn)滿足的8-鄰域存在三個(gè)以上的前景點(diǎn)數(shù)。篩選流程如下:
(1)以Wf為范圍對(duì)Sd進(jìn)行分類得到簇群;
(2)從單簇群任選三點(diǎn)形成向量vi、vj;
(3)如aij≠1,加入點(diǎn)集Sdf;
(4)重復(fù)遍歷簇群,得到所有滿足的點(diǎn)。
1.1.2 分叉特征點(diǎn)聚類合并
集合Sdf為特征點(diǎn)簇群,不能有效表示單個(gè)分叉區(qū)域,因此還需進(jìn)行聚類合并[13]。為解決過度合并分叉點(diǎn)以及未能正確合并的問題,文中的聚類合并分兩階段進(jìn)行,一階段篩選區(qū)域畸變程度小的分叉點(diǎn),二階段合并區(qū)域程度畸變大的分叉點(diǎn)。
在進(jìn)行聚類合并前,需要了解二階段聚類合并得到的不僅是分叉點(diǎn),考慮畸變程度不同,待修復(fù)面積也應(yīng)有所區(qū)別,因此引入修復(fù)區(qū)域概念。
定義3 修復(fù)區(qū)域:動(dòng)態(tài)矩形的中心為最優(yōu)分叉點(diǎn)PL,動(dòng)態(tài)邊長為Ldy,未經(jīng)過第二階段聚類合并Ldy為Wf。
一階段聚類合并是為了得到緊密的分叉點(diǎn)簇群。根據(jù)單簇群中坐標(biāo)的x、y均值,得到修復(fù)區(qū)域的PL坐標(biāo),Ldy為字體寬度Wf。此時(shí)細(xì)化得到的骨架畸變較小區(qū)域已被正確識(shí)別,依然存在未能正確合并的情況,因此需要二階段的聚類合并操作。同時(shí)為了防止合并錯(cuò)誤,引入了定義4、5。
定義4 延展分支特征點(diǎn):分叉特征點(diǎn)P0可以不經(jīng)過任何其他分叉特征點(diǎn)到達(dá)端點(diǎn)。
定義5 標(biāo)準(zhǔn)T型分叉特征點(diǎn):分叉特征點(diǎn)P0在矩形Ldy為字體寬度Wf局部范圍內(nèi)滿足標(biāo)準(zhǔn)十字以及T型的骨架結(jié)構(gòu)。
在第二階段,距離min Pts為字體寬度Wf,得到待合并點(diǎn)簇Smerge。同時(shí)補(bǔ)充了3個(gè)限制條件防止過度合并,具體如下:
(1)如單簇待合并分叉點(diǎn)數(shù)超過3,任取三點(diǎn)形成aij,aij→1滿足合并條件;
(2)單簇中存在兩個(gè)以及以上延展分支特征點(diǎn),則該簇不滿足合并條件;
(3)單簇中存在一個(gè)或多個(gè)標(biāo)準(zhǔn)T型分叉特征點(diǎn),則該簇不滿足合并條件。
條件1、2主要是防止手寫字體局部筆畫過于密集導(dǎo)致分叉點(diǎn)的誤合并;條件3主要是避免標(biāo)準(zhǔn)的細(xì)化骨架結(jié)構(gòu)被過度合并。三個(gè)限制條件合理保留了傳統(tǒng)細(xì)化算法可準(zhǔn)確細(xì)化的區(qū)域,同時(shí)也避免了局部最優(yōu)分叉點(diǎn)過于密集產(chǎn)生,以至于過度合并丟失了骨架應(yīng)有的細(xì)節(jié)。結(jié)果如圖1所示。
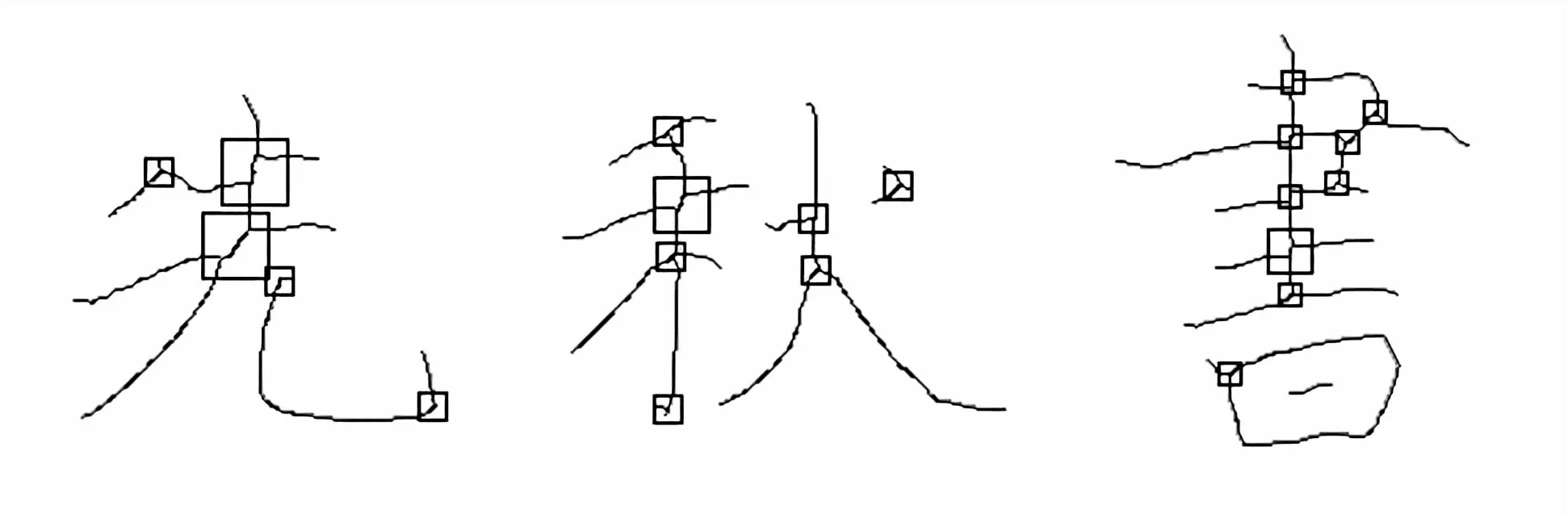
圖1 合并局部最優(yōu)分叉點(diǎn)結(jié)果
經(jīng)過第二階段合并后修復(fù)區(qū)域的邊長Ldy以及中心坐標(biāo)PL,分別為:
Ldy=max(xmax-xmin,ymax-ymin)
(3)
PL=(xmin+Ldy,ymin+Ldy)
(4)
其中,xmin、xmax、ymin、ymax為Smerge中待合并點(diǎn)的修復(fù)區(qū)域中x、y坐標(biāo)的最小和最大值,經(jīng)過二階段得到的待修復(fù)分叉點(diǎn)(PL,Ldy)的集合用Sdy表示。
1.2 分叉點(diǎn)修復(fù)
根據(jù)二階段聚類合并得到的待修復(fù)集合Sdy,分析集合Sdy中(PL,Ldy)形成動(dòng)態(tài)矩形與骨架形成的交界點(diǎn)。同時(shí)依據(jù)漢字筆段形成規(guī)律[14-15],結(jié)合待修復(fù)區(qū)域與骨架相交點(diǎn)信息,將分叉點(diǎn)進(jìn)行歸納分類。
為了更好地進(jìn)行分析,歸納出定義6~11五種類型的畸變區(qū)域?qū)?yīng)后續(xù)修復(fù)策略。
定義6 交界點(diǎn)可延展性:如延展Wf的距離,得不到骨架上的點(diǎn)則認(rèn)為不可延展。
定義7 四通區(qū)域類型:交界點(diǎn)集數(shù)為4,各點(diǎn)滿足交界點(diǎn)集四邊界有且僅有一點(diǎn)。
定義8 三通區(qū)域類型:分叉點(diǎn)交界點(diǎn)集數(shù)為3,其中四邊界各有且僅有一點(diǎn),且各邊界點(diǎn)都具有可延展性。
定義9 毛刺區(qū)域類型:分叉點(diǎn)交界點(diǎn)集數(shù)為3,其中四邊界各有且僅有一點(diǎn),同時(shí)僅存在一邊界點(diǎn)具有不可延展性。
定義10 拐角區(qū)域類型:交界點(diǎn)集中個(gè)數(shù)為2,其中四邊界各有且僅有一點(diǎn),兩邊界為相鄰關(guān)系。
定義11 多通區(qū)域類型:四邊界存在任意一邊界存在兩個(gè)及以上的交界點(diǎn)。
待修復(fù)分叉點(diǎn)類型如圖2所示。

圖2 待修復(fù)分叉點(diǎn)類型
圖3為交叉區(qū)域類型歸類流程,具體描述如下:
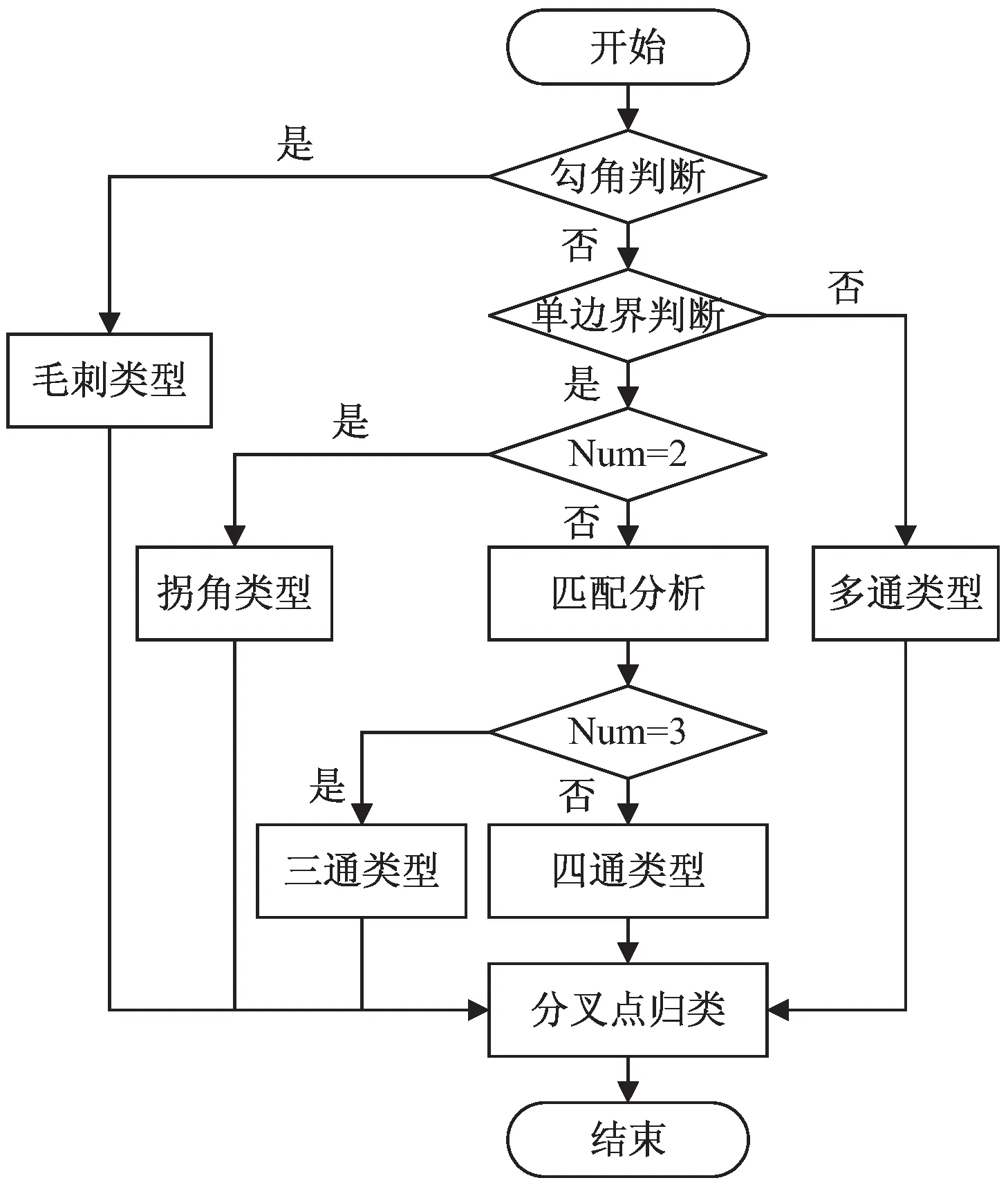
圖3 交叉區(qū)域類型歸類流程
(1)遍歷集合Sfix中的元素點(diǎn),如該區(qū)域滿足毛刺區(qū)域類型定義,則可直接歸類;
(2)單邊界判斷,如該點(diǎn)四邊界點(diǎn)集存在任意邊界,存在兩個(gè)及以上的分支,歸類為多通區(qū)域類型;
(3)根據(jù)交界點(diǎn)集Num進(jìn)行分類,如Num為2,歸類為拐角區(qū)域類型;
(4)匹配分析為根據(jù)分支局部斜率找到于與走勢相近的分支,如圖2中四通區(qū)域類型,南北分支的局部斜率aij→1,則可將南北分之判定為匹配關(guān)系;
(5)得到匹配關(guān)系后,根據(jù)當(dāng)前交界點(diǎn)集Num為3歸類為三通區(qū)域類型,否則為四通區(qū)域類型。
通過上述交叉區(qū)域類型歸類流程,可得到相應(yīng)區(qū)域類型,接下來需要根據(jù)相應(yīng)的區(qū)域類型展開修復(fù)工作。
四通區(qū)域類型修復(fù)策略根據(jù)得到的匹配關(guān)系集合,處理流程如下:
(1)將兩相匹配的邊界點(diǎn)按照局部斜率進(jìn)行延展;
(2)存在未處理的點(diǎn),計(jì)算兩點(diǎn)到PL與匹配點(diǎn)相交的直線距離,取最小距離方案將未處理點(diǎn)與之相連。
由圖4可看出,常見的四通區(qū)域類型根據(jù)分支匹配進(jìn)行準(zhǔn)確修復(fù),修復(fù)后區(qū)域走勢自然,也很好地解決了筆畫錯(cuò)誤粘貼問題。
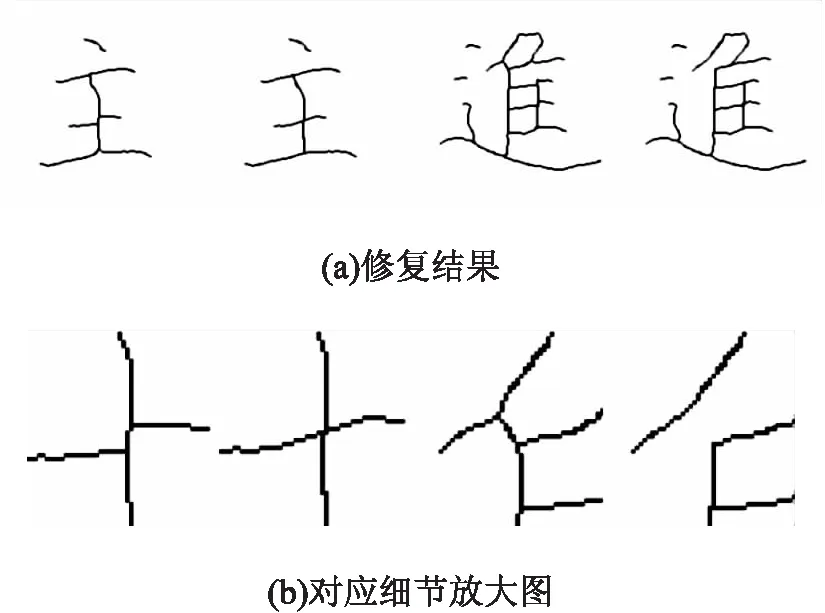
圖4 四通區(qū)域類型修復(fù)
三通區(qū)域類型修復(fù)策略處理流程如下:
(1)如存在匹配關(guān)系集合,則將匹配的邊界點(diǎn)按局部斜率延展相連;
(2)未處理的點(diǎn)按該點(diǎn)的局部斜率進(jìn)行延展,連接到匹配分支形成的直線上;
(3)如不存在匹配關(guān)系,則將待修復(fù)點(diǎn)集都連接到PL上。
如圖5所示,骨架交錯(cuò)區(qū)域發(fā)生畸變,此處的筆畫走勢顯得抖動(dòng),不符合實(shí)際字體的特點(diǎn)。通過局部斜率將筆畫延展相交在一起,正確還原了筆畫趨勢。

圖5 三通區(qū)域類型修復(fù)
拐角區(qū)域類型處存在毛刺問題并沒形成單獨(dú)分支,產(chǎn)生的毛刺是因?yàn)榧?xì)化發(fā)生輕量畸變。因此對(duì)該區(qū)域進(jìn)行局部斜率重連,因此采取的拐點(diǎn)區(qū)域類型修復(fù)策略為:
(1)將各交界點(diǎn)按照局部斜率延展,得到相交點(diǎn);
(2)交界點(diǎn)連接到相交點(diǎn)上。
經(jīng)過拐點(diǎn)修復(fù)策略后的骨架效果如圖6所示,其產(chǎn)生的毛刺都被有效處理,局部筆畫抖動(dòng)基本消失。

圖6 拐角區(qū)域類型修復(fù)
毛刺區(qū)域類型因存在邊界點(diǎn)具有不可延展性導(dǎo)致該區(qū)域存在較大的毛刺,相關(guān)結(jié)果如圖7所示,毛刺區(qū)域類型修復(fù)策略的處理流程如下:
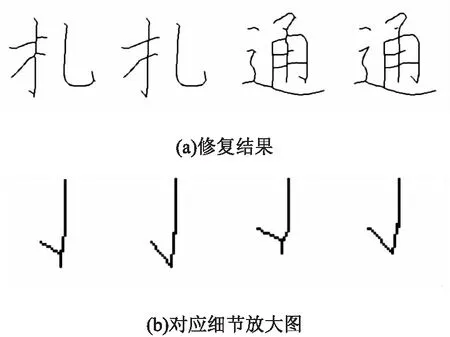
圖7 毛刺區(qū)域類型修復(fù)
(1)得到未能延展的交界點(diǎn)Pex;
(2)清除Pex到端點(diǎn)間的前景點(diǎn);
(3)將其余的交界點(diǎn)按局部斜率延展相交。
漢字結(jié)構(gòu)產(chǎn)生多通區(qū)域類型都是多筆畫的聚集點(diǎn),對(duì)多通策略的處理流程如下:
(1)通過修復(fù)信息Sdy得到分叉點(diǎn)PL;
(2)將交界點(diǎn)連接到分叉點(diǎn)PL上。
由于不同筆畫在這個(gè)分叉點(diǎn)匯集,筆畫的斜率以及粗細(xì)導(dǎo)致細(xì)化算法在此處是必然發(fā)生畸變的,修復(fù)策略將不同的分支邊界點(diǎn)連接到二階段合并得到的最優(yōu)分叉點(diǎn)上,效果如圖8所示。
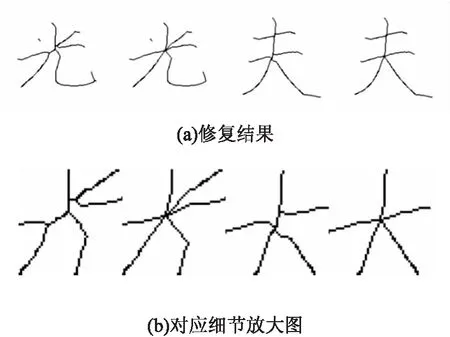
圖8 多通區(qū)域類型修復(fù)
2 實(shí)驗(yàn)結(jié)果與分析
通過實(shí)驗(yàn)驗(yàn)證文中算法的有效性。實(shí)驗(yàn)環(huán)境如下:操作系統(tǒng)為windows10,處理器為英特爾7700k,16G運(yùn)行內(nèi)存,使用跨平臺(tái)計(jì)算機(jī)視覺OpenCV。使用顏真卿的楷書作品《多寶塔碑》、田英章《弟子規(guī)》以及《九成宮醴泉銘》共967個(gè)楷書字體作為實(shí)驗(yàn)數(shù)據(jù)。
2.1 交叉點(diǎn)檢測算法對(duì)比
在使用細(xì)化算法得到骨架后,首先通過計(jì)算原圖像有效點(diǎn)與骨架有效點(diǎn)比例得到Wf后,根據(jù)提出的交叉點(diǎn)檢測算法得到待修復(fù)集合Sdy,為更好量化不同分叉點(diǎn)檢測算法的性能,提出相關(guān)定義12~16。
定義12 人工標(biāo)注分叉點(diǎn)Pmark:對(duì)實(shí)驗(yàn)數(shù)據(jù)的原圖進(jìn)行人工處理,標(biāo)記所有分叉區(qū)域的中心位置點(diǎn)作為Pmark。
定義13 分叉點(diǎn)檢測準(zhǔn)確率BRR:如單Pmark有且僅被Sdy集合中(PL,Ldy)形成的動(dòng)態(tài)矩形覆蓋,則認(rèn)為該被正確識(shí)別。分叉點(diǎn)檢測準(zhǔn)確率BRR等于被正確識(shí)別的分叉點(diǎn)數(shù)占人工標(biāo)注分叉點(diǎn)數(shù)的比率。
定義14 過度合并分叉點(diǎn)率ORR:Sdy集合中(PL,Ldy)形成的動(dòng)態(tài)矩形覆蓋兩個(gè)及以上Pmark,則認(rèn)為存在過度合并的情況。ORR等同于過度合并的Pmark與人工標(biāo)注分叉點(diǎn)數(shù)的比率。
定義15 未合并分叉點(diǎn)率URR:Sdy集合中存在兩個(gè)及以上(PL,Ldy)形成動(dòng)態(tài)矩形覆蓋單Pmark,則認(rèn)為Sdy集合存在未能正確合并情況。URR等同于未合并的(PL,Ldy)數(shù)與人工標(biāo)注分叉點(diǎn)數(shù)的比率。
定義16 錯(cuò)誤檢測率ER:Sdy集合中存在(PL,Ldy)形成動(dòng)態(tài)矩形未能覆蓋任何Pmark。ER等同于未能覆蓋任何Pmark的(PL,Ldy)數(shù)與人工標(biāo)注分叉點(diǎn)數(shù)的比率。
圖9為文中交叉點(diǎn)檢測算法與最大圓盤法[9]以及復(fù)雜區(qū)域檢測算法[11]的對(duì)比實(shí)驗(yàn)結(jié)果。從左到右依次書寫字體原圖,最大圓盤法過程分析圖,最大圓盤法結(jié)果,復(fù)雜區(qū)域檢測算法結(jié)果以及文中算法得出的交叉點(diǎn)結(jié)果。
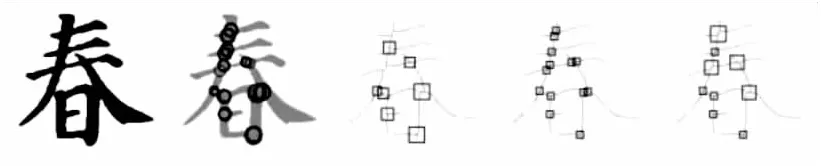
圖9 不同交叉點(diǎn)檢測算法結(jié)果對(duì)比
從對(duì)比結(jié)果可以看出,最大圓盤法[9]存在過度合并的問題,導(dǎo)致最終在分叉點(diǎn)密集區(qū)域,多分叉點(diǎn)被錯(cuò)誤識(shí)別成單分叉點(diǎn)。復(fù)雜區(qū)域檢測算法[11]對(duì)畸變程度較大的區(qū)域進(jìn)行未正確識(shí)別合并,從而導(dǎo)致單分叉點(diǎn)檢測成兩個(gè)或以上的分叉點(diǎn)。文中提出的二階段檢測法正確識(shí)別到分叉點(diǎn),同時(shí)對(duì)畸變區(qū)域范圍也作出更準(zhǔn)確動(dòng)態(tài)調(diào)整。
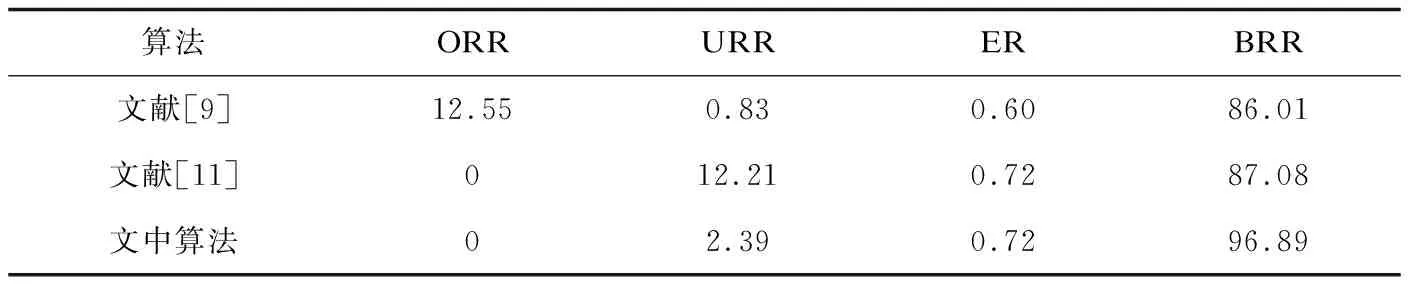
表1 分叉點(diǎn)檢測算法準(zhǔn)確率 %
2.2 骨架修復(fù)對(duì)比
實(shí)驗(yàn)中,絕大部分骨架畸變區(qū)域都被二階段檢測算法很好地識(shí)別檢測到。受文獻(xiàn)[16]中相似度計(jì)算方法以及文獻(xiàn)[17]提出的骨架特征不變量描述接合點(diǎn)啟發(fā),此處將人工標(biāo)注正確的骨架與經(jīng)優(yōu)化算法得到的骨架進(jìn)行重合度比較,作為衡量不同細(xì)化算法的性能指標(biāo)。表2中的數(shù)據(jù)是指識(shí)別到的分叉區(qū)域按照修復(fù)類型進(jìn)行修復(fù),未修復(fù)導(dǎo)致的原因是不滿足文章提出的修復(fù)類型,導(dǎo)致不能找到相應(yīng)的修復(fù)策略,可以看出通過二階段檢測出的分叉區(qū)域都能很好歸類成修復(fù)類型,并采取了相應(yīng)的修復(fù)。修復(fù)效果對(duì)比如圖10所示。

表2 細(xì)化實(shí)驗(yàn)效果統(tǒng)計(jì)

圖10 不同骨架提取算法結(jié)果
定義17 策略覆蓋率SCR:待修復(fù)集合Sfix歸類成區(qū)域類型的成功率,策略覆蓋率SCR等同于歸類區(qū)域類型個(gè)數(shù)占人工標(biāo)注分叉區(qū)域數(shù)量的比率。
定義18 骨架提取準(zhǔn)確率ERR[11]:對(duì)畸變區(qū)域進(jìn)行人工標(biāo)注骨架,ERR等同于重合骨架點(diǎn)數(shù)占標(biāo)注骨架總點(diǎn)數(shù)比率,若所提骨架與標(biāo)準(zhǔn)骨架一致,則所有骨架點(diǎn)應(yīng)重合。
根據(jù)表2數(shù)據(jù)可以得出,未能修復(fù)區(qū)域主要是因?yàn)榉植鎱^(qū)域得不到歸類的區(qū)域類型。從SCR可知,對(duì)于區(qū)域類型歸類已經(jīng)很好覆蓋不同筆畫交錯(cuò)形成的畸變區(qū)域,文獻(xiàn)[11]提出的骨架提取準(zhǔn)確率可以很好地作為修復(fù)效果量化指標(biāo)。為進(jìn)一步量化區(qū)域修復(fù)的效果,通過對(duì)比標(biāo)注骨架與文中的修復(fù)策略得到的優(yōu)化區(qū)域骨架重合比率,驗(yàn)證文中算法的有效性。提出的優(yōu)化算法在二階段聚類合并因?yàn)橄拗茥l件判斷過程,導(dǎo)致算法的時(shí)間會(huì)增多,而文獻(xiàn)[9]在計(jì)算最大圓盤方面消耗以及計(jì)算圓盤與骨架交點(diǎn)的計(jì)算時(shí)間花銷占重較大。
文獻(xiàn)[9]方法根據(jù)最大圓盤獲取到中心點(diǎn)進(jìn)行連接,對(duì)于拐角處的修復(fù)有著不錯(cuò)效果,由于沒有三通以及四通分叉區(qū)域筆畫走勢延伸等分析,修復(fù)方面效果不足。因此可得出文章提出的優(yōu)化算法更高效可行。
3 結(jié)束語
文章提出的交叉點(diǎn)檢測算法更合理適用字體寬度Wf以及動(dòng)態(tài)矩形概念識(shí)別分叉點(diǎn),經(jīng)實(shí)驗(yàn)驗(yàn)證可更準(zhǔn)確識(shí)別分叉區(qū)域。通過提出的修復(fù)策略可覆蓋絕大部分字體畸變的區(qū)域,修復(fù)后的骨架更能反映出手寫漢字的特征,筆畫會(huì)更為順暢且交叉以及拐角區(qū)域的筆畫走勢更為自然。提出的優(yōu)化算法是基于細(xì)化后骨架結(jié)果進(jìn)行修復(fù),不針對(duì)具體細(xì)化算法畸變問題,可適用范圍更廣。
二階段優(yōu)化算法適用于較為規(guī)則的手寫漢字,對(duì)于筆畫走勢靈活或是筆畫相對(duì)潦草的草書等風(fēng)格字體,該算法修復(fù)效果不足。因此后續(xù)工作會(huì)針對(duì)走勢更靈活、潦草的草書[18]進(jìn)行相應(yīng)研究以及骨架提取優(yōu)化。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
山東青年(2016年1期)2016-02-28 14:25:25
電測與儀表(2015年5期)2015-04-09 11:30:52
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
公務(wù)員文萃(2013年5期)2013-03-11 16:08:37
