基于機制、標(biāo)準(zhǔn)和技術(shù)的政府?dāng)?shù)據(jù)治理體系研究
2023-07-25 18:02:57顏家遠宋彥棠劉峻
中國新通信 2023年9期
顏家遠 宋彥棠 劉峻


摘要:數(shù)據(jù)治理使政府治理更智能,本文分析政府?dāng)?shù)據(jù)治理的現(xiàn)狀和存在問題,提出政府?dāng)?shù)據(jù)治理體系,包含體系框架、治理機制、治理標(biāo)準(zhǔn)和治理技術(shù)等內(nèi)容。針對政府?dāng)?shù)據(jù)共享開放難的問題,提出政府?dāng)?shù)據(jù)共享開放的治理機制;針對“有數(shù)無治”,提出綜合人口數(shù)據(jù)庫設(shè)計規(guī)范和數(shù)據(jù)質(zhì)量評價規(guī)范;針對“有數(shù)難治”,提出LSTM-XGBoost融合模型的治理技術(shù)模型。通過實踐,政府?dāng)?shù)據(jù)治理體系在實踐中是可行的。
關(guān)鍵詞:數(shù)據(jù)治理;治理機制;治理標(biāo)準(zhǔn);治理技術(shù);LSTM-XGBoost模型
一、引言
目前,政府?dāng)?shù)據(jù)治理主要集中在技術(shù)治理,文獻[1]對政府?dāng)?shù)據(jù)治理和區(qū)塊鏈技術(shù)的相關(guān)性進行深度分析,探討如何通過區(qū)塊鏈技術(shù)提高政府?dāng)?shù)據(jù)治理需求,并提出基于區(qū)塊鏈的政府?dāng)?shù)據(jù)治理架構(gòu);文獻[2]指出要大力推進數(shù)據(jù)治理技術(shù);文獻[3]研究了人工智能技術(shù)在政府?dāng)?shù)據(jù)模型、數(shù)據(jù)安全和數(shù)據(jù)治理等方面的應(yīng)用,提出人工智能技術(shù)可提高政府?dāng)?shù)據(jù)治理水平;文獻[4]提出基于SSM的政府?dāng)?shù)據(jù)治理聯(lián)盟鏈框架,表明在數(shù)據(jù)安全、數(shù)據(jù)確權(quán)等方面發(fā)揮聯(lián)盟作用,可促進政府?dāng)?shù)據(jù)治理。文獻[5]通過在WSR視域下研究政府?dāng)?shù)據(jù)治理的影響因素,表明物理-事理-人理緯度可影響政府?dāng)?shù)據(jù)治理的成效。以上方法均從技術(shù)角度研究政府?dāng)?shù)據(jù)治理,但當(dāng)政府?dāng)?shù)據(jù)不一、標(biāo)準(zhǔn)不一、機制不一時,最終的政府?dāng)?shù)據(jù)治理效果往往達不到預(yù)期目標(biāo)。因此,政府?dāng)?shù)據(jù)治理亟須豐富治理手段。
政府?dāng)?shù)據(jù)治理面臨“數(shù)據(jù)共享難”“有數(shù)無治、有數(shù)難治”的問題,為破解這些問題,需從“制防、人防、技防”多維度解決[6]。本文首次提出了政府?dāng)?shù)據(jù)治理的框架體系。
二、政府?dāng)?shù)據(jù)治理體系
(一)體系框架
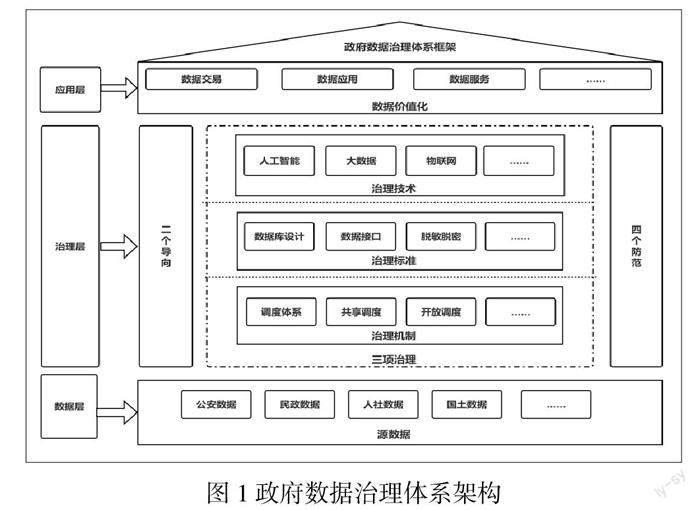
政府?dāng)?shù)據(jù)治理,關(guān)鍵要點就在于挖掘政府?dāng)?shù)據(jù)隱藏的潛在價值,并應(yīng)用于社會經(jīng)濟各方面,進而為社會經(jīng)濟賦能。結(jié)合不同層級、不同地域和不同部門在數(shù)據(jù)共享開放存在的痛點和難點,提出政府?dāng)?shù)據(jù)治理體系框架,包含數(shù)據(jù)層、治理層、應(yīng)用層三個層次,如圖1所示。
1.數(shù)據(jù)層
數(shù)據(jù)層是數(shù)據(jù)的來源,政府?dāng)?shù)據(jù)按部門分為公安數(shù)據(jù)、民政數(shù)據(jù)、人社數(shù)據(jù)、環(huán)保數(shù)據(jù)、教育數(shù)據(jù)、國土數(shù)據(jù)等,按可機讀性分為非結(jié)構(gòu)化數(shù)據(jù)、半結(jié)構(gòu)化數(shù)據(jù)、結(jié)構(gòu)化數(shù)據(jù)等,按人的生命周期分為出生數(shù)據(jù)、戶籍?dāng)?shù)據(jù)、社保數(shù)據(jù)、病歷數(shù)據(jù)、教育數(shù)據(jù)、就業(yè)數(shù)據(jù)、不動產(chǎn)數(shù)據(jù)、征信數(shù)據(jù)、死亡數(shù)據(jù)等。
2.治理層
治理層是政府?dāng)?shù)據(jù)治理體系的核心,由“二個導(dǎo)向”“三項治理”“四個防范”組成。
“二個導(dǎo)向”是指目標(biāo)導(dǎo)向、問題導(dǎo)向。政府?dāng)?shù)據(jù)治理應(yīng)堅持目標(biāo)導(dǎo)向,設(shè)定政府?dāng)?shù)據(jù)治理的短期、中期和長期目標(biāo),并通過行動逐步達到目標(biāo);政府?dāng)?shù)據(jù)治理應(yīng)堅持問題導(dǎo)向,針對治理過程中存在的痛點和難點,要“奮勇向前”“知不足而后進”“防患于未然”,不斷解決問題、彌補不足,不斷在新形勢下創(chuàng)新發(fā)展。
“三項治理”是指治理機制、治理標(biāo)準(zhǔn)、治理技術(shù),是政府?dāng)?shù)據(jù)治理的核心內(nèi)容。通過建立政府?dāng)?shù)據(jù)共享開放治理機制,從機制層面解決數(shù)據(jù)共享難的問題。通過健全治理標(biāo)準(zhǔn),規(guī)范數(shù)據(jù)庫設(shè)計、數(shù)據(jù)質(zhì)量評價等標(biāo)準(zhǔn)規(guī)范,確保政府?dāng)?shù)據(jù)治理“有規(guī)可依,有規(guī)可循”。
“四個防范”是指防范決策風(fēng)險、防范管理風(fēng)險、防范技術(shù)風(fēng)險、防范數(shù)據(jù)風(fēng)險。由于主觀和客觀、宏觀和微觀、規(guī)劃與實際等多種不確定因素的影響造成決策不能達到預(yù)期目標(biāo),甚至與預(yù)期目標(biāo)大相徑庭的決策風(fēng)險;由于政府?dāng)?shù)據(jù)治理過程中因信息不對稱、管理不善等因素造成管理風(fēng)險;由于技術(shù)不成熟、技術(shù)不配套、技術(shù)保障不足、技術(shù)創(chuàng)新性和適應(yīng)性無法適應(yīng)新形勢的發(fā)展等因素造成的技術(shù)風(fēng)險;由于數(shù)據(jù)采集、傳輸、存儲、使用等不當(dāng)造成數(shù)據(jù)截取、篡改甚至數(shù)據(jù)泄露或暴露的數(shù)據(jù)風(fēng)險,都需要提前加以防范。
3. 應(yīng)用層
應(yīng)用層是政府?dāng)?shù)據(jù)治理的目標(biāo),政府部門可通過應(yīng)用層開展數(shù)據(jù)交易、數(shù)據(jù)應(yīng)用、數(shù)據(jù)服務(wù)等,大型數(shù)據(jù)應(yīng)用開發(fā)宜采用瀑布型軟件生命周期模型[7]。
圖1 政府?dāng)?shù)據(jù)治理體系架構(gòu)
(二)治理核心內(nèi)容
本文重點就治理機制、治理標(biāo)準(zhǔn)和治理技術(shù)進行探討。
1.治理機制探討
政府?dāng)?shù)據(jù)治理的治理機制中,重點和難點是政府?dāng)?shù)據(jù)共享開放治理機制,提出政府?dāng)?shù)據(jù)共享開放治理機制。
政府?dāng)?shù)據(jù)按照共享屬性分為無條件共享、有條件共享和不予共享三種類型;政府?dāng)?shù)據(jù)按照開放屬性分為無條件開放、有條件開放和不予開放三種類型,政府?dāng)?shù)據(jù)調(diào)度體系如下所示:
(1)共享數(shù)據(jù)調(diào)度
無條件共享的政府?dāng)?shù)據(jù),數(shù)據(jù)使用部門通過政府?dāng)?shù)據(jù)共享平臺直接獲取[8];有條件共享的政府?dāng)?shù)據(jù),數(shù)據(jù)使用部門在政府?dāng)?shù)據(jù)共享平臺上提交申請后,按照以下流程調(diào)度:
數(shù)據(jù)提供部門為本級行政主管部門的,本級大數(shù)據(jù)主管部門在規(guī)定時間內(nèi)完成初審。初審未通過的,駁回申請;初審?fù)ㄟ^的,轉(zhuǎn)至數(shù)據(jù)提供部門在規(guī)定時間內(nèi)審核和授權(quán)。
數(shù)據(jù)提供部門為上級(或下級)行政主管部門的,由數(shù)據(jù)使用部門所在層級的大數(shù)據(jù)主管部門在規(guī)定時間內(nèi)完成初審。初審未通過的,駁回申請;初審?fù)ㄟ^的,逐級轉(zhuǎn)至數(shù)據(jù)提供部門所在層級大數(shù)據(jù)主管部門進行復(fù)審。復(fù)審未通過的,駁回申請;復(fù)審?fù)ㄟ^的,轉(zhuǎn)至數(shù)據(jù)提供部門在規(guī)定時間內(nèi)審核和授權(quán)。
數(shù)據(jù)提供部門審核不通過的,數(shù)據(jù)使用部門有權(quán)提起申訴;數(shù)據(jù)使用部門提起申訴的,由數(shù)據(jù)提供部門和數(shù)據(jù)使用部門共有的上級大數(shù)據(jù)主管部門協(xié)調(diào)處理。數(shù)據(jù)提供部門授權(quán)給數(shù)據(jù)使用部門使用政府?dāng)?shù)據(jù)后,數(shù)據(jù)使用部門應(yīng)在規(guī)定時間內(nèi)將政府?dāng)?shù)據(jù)應(yīng)用成效報大數(shù)據(jù)主管部門備案登記。
(2)開放數(shù)據(jù)調(diào)度
無條件開放的政府?dāng)?shù)據(jù),申請人(自然人、法人和非法人組織)通過政府?dāng)?shù)據(jù)開放平臺直接獲取[9]。依申請開放數(shù)據(jù),按照以下流程進行調(diào)度:
依申請開放的政府?dāng)?shù)據(jù),申請人通過政府?dāng)?shù)據(jù)開放平臺提交數(shù)據(jù)開放申請,并填寫數(shù)據(jù)名稱、數(shù)據(jù)需求類型、數(shù)據(jù)描述、所屬領(lǐng)域、數(shù)據(jù)格式、數(shù)據(jù)用途及其他相關(guān)信息。
申請人在政府?dāng)?shù)據(jù)開放平臺上提交申請后,數(shù)據(jù)提供部門應(yīng)在規(guī)定時間內(nèi)完成審核。審核通過的,數(shù)據(jù)提供部門在規(guī)定時間內(nèi)開放所需數(shù)據(jù);審核未通過的,數(shù)據(jù)提供部門必須提供不予開放的依據(jù)或理由。
政府?dāng)?shù)據(jù)開放應(yīng)當(dāng)遵守《保守國家秘密法》《政府信息公開條例》等有關(guān)規(guī)定。數(shù)據(jù)提供部門不同意提供依申請開放的政府?dāng)?shù)據(jù),申請人確需使用的,由數(shù)據(jù)提供部門所在層級的大數(shù)據(jù)主管部門協(xié)調(diào)處理。數(shù)據(jù)提供部門同意提供依申請開放的政府?dāng)?shù)據(jù)后,數(shù)據(jù)提供部門應(yīng)將開放的數(shù)據(jù)情況提交同級大數(shù)據(jù)主管部門備案登記。
(3)調(diào)度保障機制
健全運轉(zhuǎn)機制。建立覆蓋國家、省級、市級、縣級的統(tǒng)一政府?dāng)?shù)據(jù)共享和開放平臺;形成“數(shù)據(jù)使用部門提需求、數(shù)據(jù)歸集部門做響應(yīng)、大數(shù)據(jù)主管部門保流轉(zhuǎn)”的運轉(zhuǎn)機制。
健全歸集權(quán)機制。加快推進政府部門內(nèi)部業(yè)務(wù)系統(tǒng)整合,形成“大系統(tǒng)、大平臺、大數(shù)據(jù)”,實現(xiàn)一個部門一個系統(tǒng),一個部門一套數(shù)據(jù)。同時,按照“誰歸集、誰維護”的原則,各級政府部門依法履職所獲取和產(chǎn)生的政府?dāng)?shù)據(jù)擁有歸集管理的權(quán)利和義務(wù),強化數(shù)據(jù)維護,使得數(shù)據(jù)更加準(zhǔn)確、更加完整、更加有效、更加可用。
健全使用權(quán)機制。各級政府部門對數(shù)據(jù)擁有使用權(quán),按照“誰使用,誰負(fù)責(zé)”的原則,各級政府部門依法依規(guī)對政府?dāng)?shù)據(jù)享有使用權(quán)利和確保安全的義務(wù)。
健全管理機制。政府?dāng)?shù)據(jù)歸政府所有,可委托大數(shù)據(jù)主管部門管理。按照“誰管理、誰統(tǒng)籌”的原則,各級大數(shù)據(jù)主管部門擁有對該區(qū)域各部門數(shù)據(jù)的統(tǒng)籌管理權(quán),確保數(shù)據(jù)共享和開放高效進行。
建立仲裁機制。數(shù)據(jù)提供部門不同意提供有條件共享(或依申請開放)的數(shù)據(jù)時,可由數(shù)據(jù)使用部門和數(shù)據(jù)提供部門共有的上級大數(shù)據(jù)主管部門協(xié)調(diào)處理,協(xié)調(diào)處理無法解決問題時,可通過建立解決爭議的仲裁機制,解決數(shù)據(jù)共享開放過程中的爭議問題。
2.治理標(biāo)準(zhǔn)探討
政府?dāng)?shù)據(jù)治理過程中,由于政府的部門不同、服務(wù)廠商不一,導(dǎo)致承載政府?dāng)?shù)據(jù)的業(yè)務(wù)系統(tǒng)數(shù)據(jù)庫設(shè)計不規(guī)范、字段命名不一,造成數(shù)據(jù)質(zhì)量參差不齊,但是各行各業(yè)為了破解這一問題,亟需統(tǒng)一標(biāo)準(zhǔn),實現(xiàn)口徑統(tǒng)一。
(1)綜合人口庫設(shè)計規(guī)范探討。
提出綜合人口數(shù)據(jù)庫設(shè)計規(guī)范,在已出臺標(biāo)準(zhǔn)的基礎(chǔ)上,對人的全生命周期各項活動及產(chǎn)生的數(shù)據(jù)進行綜合分析和整合利用的數(shù)據(jù)標(biāo)準(zhǔn),將各個政府部門的人口相關(guān)的數(shù)據(jù)進行梳理、分析、融合,形成人從出生到死亡全生命周期的信息分類,為匯聚、融合各行業(yè)、各領(lǐng)域涉及人口相關(guān)數(shù)據(jù)提供一套切實可行、符合實際的綜合人口數(shù)據(jù)庫標(biāo)準(zhǔn),助推數(shù)據(jù)資源“聚”“通”“用”。規(guī)范涵蓋了人從出生到死亡的數(shù)據(jù)集,設(shè)計出具備數(shù)據(jù)關(guān)聯(lián)的業(yè)務(wù)表模型,數(shù)據(jù)關(guān)聯(lián)分析比較容易,工作量少,便于開展政府?dāng)?shù)據(jù)治理。綜合人口數(shù)據(jù)庫由21類數(shù)據(jù)共107個數(shù)據(jù)庫表組成,包括身份識別信息、基本信息、生育信息、教育信息、就業(yè)信息、職業(yè)資格信息、醫(yī)療健康信息、社會保險信息、公積金信息、納稅信息、消費收入信息,社會關(guān)系信息、資產(chǎn)信息等,記錄了人從出生到死亡的主要信息,數(shù)據(jù)庫表設(shè)計由字段名稱、字段編碼、數(shù)據(jù)類型、長度、精度、是否主鍵、是否可空、值域、備注共9項組成。
(2)數(shù)據(jù)質(zhì)量評價規(guī)范。
政府?dāng)?shù)據(jù)一般來源于各個政府部門的應(yīng)用系統(tǒng),但因系統(tǒng)建設(shè)的標(biāo)準(zhǔn)不統(tǒng)一,或者數(shù)據(jù)采集規(guī)則存在缺陷,導(dǎo)致產(chǎn)生了大量的問題數(shù)據(jù),嚴(yán)重影響數(shù)據(jù)的使用。國家和一些地方出臺了數(shù)據(jù)質(zhì)量的評價標(biāo)準(zhǔn),如,國家2018年出臺了《GB/T 36344-2018信息技術(shù)數(shù)據(jù)質(zhì)量評價指標(biāo)》,明確了規(guī)范性、完整性、準(zhǔn)確性、一致性、時效性、可訪問性共6個數(shù)據(jù)評價指標(biāo),但針對每個表、每個部門的數(shù)據(jù)質(zhì)量,未提出評價方法。又如,貴州2021年出臺了《DB52/T 1540.4-2021政務(wù)數(shù)據(jù)—第4部分:數(shù)據(jù)質(zhì)量評估規(guī)范》,該規(guī)范較為宏觀,通過該規(guī)范難以對每個部門、每個表的數(shù)據(jù)質(zhì)量進行精細(xì)化評估,難以精準(zhǔn)識別問題數(shù)據(jù),難以輸出數(shù)據(jù)質(zhì)量評價報告。
提出數(shù)據(jù)質(zhì)量評價規(guī)范,可對每個部門、每個表的數(shù)據(jù)質(zhì)量進行精細(xì)化評估,輸出可執(zhí)行的質(zhì)量評價報告,有利于部門整改問題數(shù)據(jù)。數(shù)據(jù)質(zhì)量評價流程包括確定業(yè)務(wù)目標(biāo)和要求、剖析評價數(shù)據(jù)、明確數(shù)據(jù)評價指標(biāo)、設(shè)計質(zhì)量校驗規(guī)則、配置質(zhì)量校驗規(guī)則、評價數(shù)據(jù)質(zhì)量并輸出報告、整改問題數(shù)據(jù),設(shè)計完整性、一致性、準(zhǔn)確性、合理性、唯一性、及時性共6項評價指標(biāo)和字段完整性校驗、空值校驗、記錄數(shù)據(jù)校驗、參照校驗-雙向校驗、一致性校驗、值域校驗、格式校驗、參照校驗-單向校驗、邏輯校驗、波動性校驗、關(guān)系校驗、重復(fù)校驗、記錄數(shù)校驗共12項質(zhì)量校驗規(guī)則。
數(shù)據(jù)質(zhì)量評價包括規(guī)則級得分、表級得分和部門級得分。其中:
(1)表級得分均遵循下列計算公式進行計算得出:
(1)
式中:X為表級得分,Si、Wi分別第i個規(guī)則的得分和權(quán)重,Wsum為總權(quán)重,n為規(guī)則總數(shù)。
(2)部門級得分均遵循下列計算公式進行計算得出:
(2)
式中:Y為部門級得分,Xi為第i個表的得分,n為表的總數(shù)。
3.治理技術(shù)探討
以技術(shù)提升政府?dāng)?shù)據(jù)治理能力應(yīng)堅持“四變”,即變“模糊治理”為“精準(zhǔn)治理”,變“線下治理”為“線上線下融合治理”,變“一元主導(dǎo)”為“多元共治”,變“碎片化治理”為“整體性治理”,為更好地實現(xiàn)“四變”,提升政府?dāng)?shù)據(jù)治理能力,人工智能的相關(guān)算法模型在政府?dāng)?shù)據(jù)治理的過程中發(fā)揮著舉足輕重的作用。
在政府?dāng)?shù)據(jù)治理過程中,一些政府?dāng)?shù)據(jù)對時間的預(yù)測性要求較高,比如,通過氣溫的歷史數(shù)據(jù),結(jié)合相對濕度、風(fēng)速風(fēng)向、日照等歷史數(shù)據(jù),預(yù)測某一地區(qū)的最高氣溫,分析最高氣溫變化趨勢,進而分析城市是否宜居,為招商引資和政府決策提供參考。
文章以某地最高氣溫預(yù)測為例,通過LSTM-XGBoost融合模型為切入點,探討政府?dāng)?shù)據(jù)治理技術(shù)。
(1)基于LSTM-XGBoost融合模型的政府?dāng)?shù)據(jù)治理
LSTM模型。長短時記憶網(wǎng)絡(luò)(Long Short Term Memory Network, LSTM)內(nèi)部結(jié)構(gòu)包含遺忘門、輸入門和輸出門,在訓(xùn)練過程中,LSTM根據(jù)其內(nèi)部結(jié)構(gòu),可以有效避免梯度爆炸、梯度消失等問題[10]。
每個Sigmoid 層產(chǎn)生的數(shù)字在0 和1 的范圍內(nèi)。每個LSTM 通過3 種類型的門來控制每個單元的狀態(tài):遺忘門決定了上一時刻的單元狀態(tài)有多少保存到當(dāng)前時刻,輸入門決定了當(dāng)前時刻網(wǎng)絡(luò)的輸入有多少保存到單元狀態(tài),輸出門控制單元狀態(tài)有多少輸出到LSTM 的當(dāng)前輸出值,每一步的狀態(tài)更新滿足以下的步驟[11]:
ft=Sigmod(Wxfxt+Whfxt-1+bf) ? ? ? ? ? ? ? ? ? ? ? (1)
it=Sigmod(Wxixt+Whixt-1+bi) ? ? ? ? ? ? ? ? ? ? ?(2)
ot=Sigmod(Wxoxt+Whoxt-1+bo) ? ? ? ? ? ? ? ? ? ? ? (3)
ct~=Sigmod(Wxoxt+Whoxt-1+bo) ? ? ? ? ? ? ? ? ? ? ? (4)
ct=ft·ct-1+it·ct~ ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (5)
ht=tan(ot·ct) ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(6)
其中,bi、f、c和Wi、f、c分別是偏置和權(quán)重。
XGBoost模型。極限梯度提升樹(eXtreme Gradient Boosting,XGBoost)是一個優(yōu)化算法,該算法基于Boosting框架,XGBoost是梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)的優(yōu)化和拓展。在政府?dāng)?shù)據(jù)治理過程中,XGBoost模型通過不斷迭代,生成一棵樹擬合前一棵樹的殘差,隨著迭代次數(shù)的增多,精度不斷提高[12]。
LSTM-XGBoost融合模型。LSTM模型和XGBoost模型的原理相差很大,其任意一種方法都適用于政府?dāng)?shù)據(jù)治理中的最高氣溫預(yù)測,本文使用LSTM-XGBoost融合模型進行社保資金支出金額的預(yù)測,模型結(jié)構(gòu)如圖2。
經(jīng)氣象部門授權(quán)后,得到近10年的歷史氣象數(shù)據(jù),按照6:2:2的比例將樣本分為訓(xùn)練數(shù)據(jù)(Train Data)、驗證數(shù)據(jù)(Validation Data)、測試數(shù)據(jù)(Test Data);首先進行數(shù)據(jù)預(yù)處理與特征選擇,得到一些關(guān)鍵特征參數(shù)(如氣溫、風(fēng)速、風(fēng)向、日照等)作為LSTM-XGBoost融合模型的輸入特征集,特征參數(shù)對應(yīng)時刻的下一時刻最高氣溫作為輸出;重要性排前的特征中分別隨機選取60% 的特征輸入XGBoost1與LSTM 進行訓(xùn)練,得到氣溫預(yù)測值Z1與Z2(由于特征選取的隨機性,且模型結(jié)構(gòu)存在差異,兩個模型預(yù)測結(jié)果相關(guān)性較低,從而提升了最終的融合結(jié)果精度);再將Z1和Z2輸入XGBoost2 得到不同氣溫預(yù)測值情況下的權(quán)重W1、W2,最后計算社保金預(yù)測結(jié)果Z[13]。
(2)基于LSTM-XGBoost模型的氣溫預(yù)測流程。首先將構(gòu)建好的訓(xùn)練集輸入 LSTM-XGBoost模型進行訓(xùn)練,然后通過同樣的特征選擇方式將氣溫測試數(shù)據(jù)(Test Data)輸入模型對下一時刻的氣溫進行預(yù)測,預(yù)測流程如圖3。
三、政府?dāng)?shù)據(jù)治理分析
政府?dāng)?shù)據(jù)治理的成效主要取決于共享數(shù)據(jù)量級、數(shù)據(jù)授權(quán)時間、完整準(zhǔn)確數(shù)據(jù)集占比、數(shù)據(jù)質(zhì)量評分等方面,數(shù)據(jù)共享集越多、完整準(zhǔn)確數(shù)據(jù)集占比越大、數(shù)據(jù)質(zhì)量評分越高、數(shù)據(jù)授權(quán)時間越少,在實踐中表明數(shù)據(jù)治理成效越好[14-15]。
以A市2018年和2021年的25個市級黨政部門的政府?dāng)?shù)據(jù)共享情況進行分析:A市2018年的數(shù)據(jù)共享方式主要靠傳遞申請函、授權(quán)函、拷貝數(shù)據(jù)等方式,也未構(gòu)建政府?dāng)?shù)據(jù)整理體系,2019年建立治理機制后,數(shù)據(jù)治理成效大幅提升。從共享數(shù)據(jù)集的數(shù)量來看,2018年可共享的政府?dāng)?shù)據(jù)集有100項,2021年為280項,平均每年(2019-2021年)提高了90%。從共享數(shù)據(jù)集授權(quán)時間來看,2018年成功共享數(shù)據(jù)集的平均授權(quán)時間為360小時,2021年為168小時,平均每年(2019-2021年)降低了26.7%。從數(shù)據(jù)質(zhì)量上來看,2018年可共享的100項數(shù)據(jù)集中,相對完整、準(zhǔn)確的數(shù)據(jù)集僅有40項,占比40%;2021年可共享的280項數(shù)據(jù)集中,相對完整、準(zhǔn)確的數(shù)據(jù)集有265項,占比95%,較2018年平均每年(2019-2021年)提高27.5個百分點。從數(shù)據(jù)質(zhì)量評分來看,按照數(shù)據(jù)質(zhì)量評價規(guī)范,2018年的數(shù)據(jù)質(zhì)量評價得分為65分,2021年的數(shù)據(jù)質(zhì)量評價得分為83分,數(shù)據(jù)質(zhì)量評分平均每年(2019-2021年)提高了14%。
影響政府?dāng)?shù)據(jù)治理成效因素中,共享數(shù)據(jù)量、完整準(zhǔn)確數(shù)據(jù)集占比、數(shù)據(jù)質(zhì)量評分均逐年上升,數(shù)據(jù)授權(quán)時間逐年減少,分析出政府?dāng)?shù)據(jù)治理成效逐年提升。
四、結(jié)束語
為提高政府?dāng)?shù)據(jù)治理效能,提出治理機制、治理標(biāo)準(zhǔn)和治理技術(shù)為核心的政府?dāng)?shù)據(jù)治理體系,實踐表明,通過治理機制、治理標(biāo)準(zhǔn)和治理技術(shù),提高了政府?dāng)?shù)據(jù)治理水平,可破解政府?dāng)?shù)據(jù)互聯(lián)互通難、信息共享難、業(yè)務(wù)協(xié)同難和數(shù)據(jù)治理不高等問題。
顏家遠 廣西大學(xué) 計算機與電子信息學(xué)院 ? 黔南州大數(shù)據(jù)發(fā)展管理局
宋彥棠 黔南州氣象局
劉峻廣西大學(xué) 計算機與電子信息學(xué)院
參 ?考 ?文 ?獻
[1] 段月嵐. 基于區(qū)塊鏈技術(shù)的政府?dāng)?shù)據(jù)治理研究[D].中國礦業(yè)大學(xué),2021.
[2] 邢春曉.大力推進數(shù)據(jù)治理技術(shù)與系統(tǒng)的學(xué)術(shù)研究[J].計算機科學(xué),2021,48(09):3-4.
[3] 江錫強.人工智能技術(shù)在政府?dāng)?shù)據(jù)治理中的應(yīng)用[J].計算機產(chǎn)品與流通,2020(06):128.
[4] 王常玨,段堯清,朱澤.基于SSM的政府?dāng)?shù)據(jù)治理聯(lián)盟鏈框架構(gòu)建[J/OL].情報科學(xué):1-18[2022-09-05].
[5] 李鋒,柳浩.WSR視域下政府?dāng)?shù)據(jù)治理影響因素與路徑研究[J].河海大學(xué)學(xué)報(哲學(xué)社會科學(xué)版),2021,23(06):44-53+110.
[6] 顏家遠.“一平臺一基地一學(xué)院”網(wǎng)絡(luò)安全監(jiān)管體系研究[J].數(shù)字通信世界,2021(08):34-35+43.
7[] 顏家遠,劉峻.瀑布型軟件生命周期模型的案例實踐研究[J].數(shù)字通信世界,2022(01):26-28+31.
[8] 王淼.“大數(shù)據(jù)+網(wǎng)格化”模式中的公共數(shù)據(jù)治理問題研究—以突發(fā)公共衛(wèi)生事件防控為視角[J].電子政務(wù),2021(01):101-109.
[9] 張珺.政府?dāng)?shù)據(jù)開放的法制路徑[J].研究生法學(xué),2019(02).
[10] Luo Junling,Zhang Zhongliang,F(xiàn)u Yao,Rao Feng. Time series prediction of COVID-19 transmission in America using LSTM and XGBoost algorithms.[J]. Results in physics,2021,27.
[11] 馮晨,陳志德.基于XGBoost和LSTM加權(quán)組合模型在銷售預(yù)測的應(yīng)用[J].計算機系統(tǒng)應(yīng)用,2019,28(10):226-232.
[12] 陳振宇,劉金波,等.基于LSTM與XGBoost組合模型的超短期電力負(fù)荷預(yù)測[J].電網(wǎng)技術(shù),2020,44(02):614-620.
[13] 滕偉,黃乙珂,等.基于XGBoost與LSTM的風(fēng)力發(fā)電機繞組溫度預(yù)測[J].中國電力,2021,54(06):95-103.
[14] 郭少青,謝明. 以數(shù)據(jù)治理為中心推進數(shù)字政府建設(shè)[N]. 中國社會科學(xué)報,2022-06-15(007).
[15] 高志華.數(shù)據(jù)治理背景下政府?dāng)?shù)據(jù)開放共享研究[J].行政科學(xué)論壇,2021,8(07):29-33.
