大數據技術下煤礦設備狀態Hadoop 平臺設計
2023-07-26 06:38:48胡偉英
山東煤炭科技 2023年6期
胡偉英
(山西焦煤集團霍州煤電集團店坪煤礦,山西 方山 041600)
在店坪煤礦井下設備較多且分布雜亂,收集數據的種類較多且較為離散,將數據集中記錄以及集中處理的難度較大,同時對于數據中心的維護比較困難,容易出現信息孤島問題。為了方便煤礦的數據管理,本文依托大數據技術進行數據管理平臺的設計[1-4],旨在順利完成數據的存儲與管理,同時實現企業化的分布式數據管理。
1 Hadoop 設備運行狀態管理平臺需求分析
1.1 Hadoop 平臺數據源分析
在大數據技術上設備運行狀態管理數據平臺中,數據主要來源如下所示:
1)機電設備的基礎信息。主要是圍繞井下各大系統包括供電、通風、壓風、排水等系統中各個關鍵設備,通過其基礎信息包括型號、額定參數等錄入,管理員可以通過系統對所有設備的基礎信息進行查閱,確保工作的高效進行。
2)設備的運維以及檢修信息。由于井下環境的特殊性,井下很多設備需要進行定期維護與檢修,通過供應商提供的壽命標準,要按期進行零部件的更換,嚴控設備的檢修,保證井下生產的安全。
1.2 Hadoop 平臺需求功能分析
井下設備運行狀態管理平臺是一個集成化的系統,由很多設備管理小部門組合而成。為保證管理平臺的正常運轉,其下的小部門需要在同一個平臺上進行工作的協調,在相同的服務器下進行記錄以及查詢工作,確保值班人員在進行交班前,下一個值班人員能通過平臺數據記錄了解設備的運行狀態與記錄的相符性。為了實現上述功能,數據平臺的功能需求如下:
1)數據在線錄入。首先在進行設備的檢查以及日常維護時,工作人員能夠通過平臺的在線功能,進行在線錄入,主要包括排班信息、設備運行狀態信息、故障信息以及故障排查信息等。
2)數據在線檢索。在平臺中存儲有海量的信息,需要定位查找,難度較大,需要有在線檢索功能,通過查詢,可以直接找到想要的信息。
3)數據導出功能。在線錄入的信息,可以按照時間的排序,實時存儲在Excel 中,通過平臺的導出功能實現數據的下載導出打印,方便查詢等。
除了上述的平臺功能要求,還有一定的非功能性的需求。其中就有數據一致性的要求,確保平臺中數據的準確性以及實時性;海量的存儲空間要求,設備信息以及人員信息較多,對于存儲空間的要求較大,要保證空間足夠;讀寫延遲小,平臺信息更新頻次多、頻率快,對讀寫功能有一定的要求。
2 大數據技術下Hadoop 平臺設計
礦井機電信息由三部分組成,包括運行數據、監控數據以及信息文檔。為了將信息簡化,需要對信息進行轉換,將數據統一為XML 文本格式。為確保平臺數據精確集成,平臺需要讀取各個站點的運行信息以及圖紙信息,保證數據管理的有序開展。這樣一來,數據平臺就有實時監控、數據管理以及運行監控等功能。為確保數據平臺快速存儲以及快速處理等功能,需要將站內的各個網絡接口進行連接。目前由于數據平臺越來越完整,搭建的標準也越來越高。數據管理平臺的設計是以Hadoop 平臺為基礎,在最大程度保留原有平臺的基礎上,配備集群部署計算機,同時在目標計算機上搭建虛擬機。通過結合大數據技術,Hadoop 平臺擁有強大的計算能力,同時擁有高容量的存儲能力。圖1 為Hadoop平臺設備運行狀態數據管理平臺總體設計結構圖。
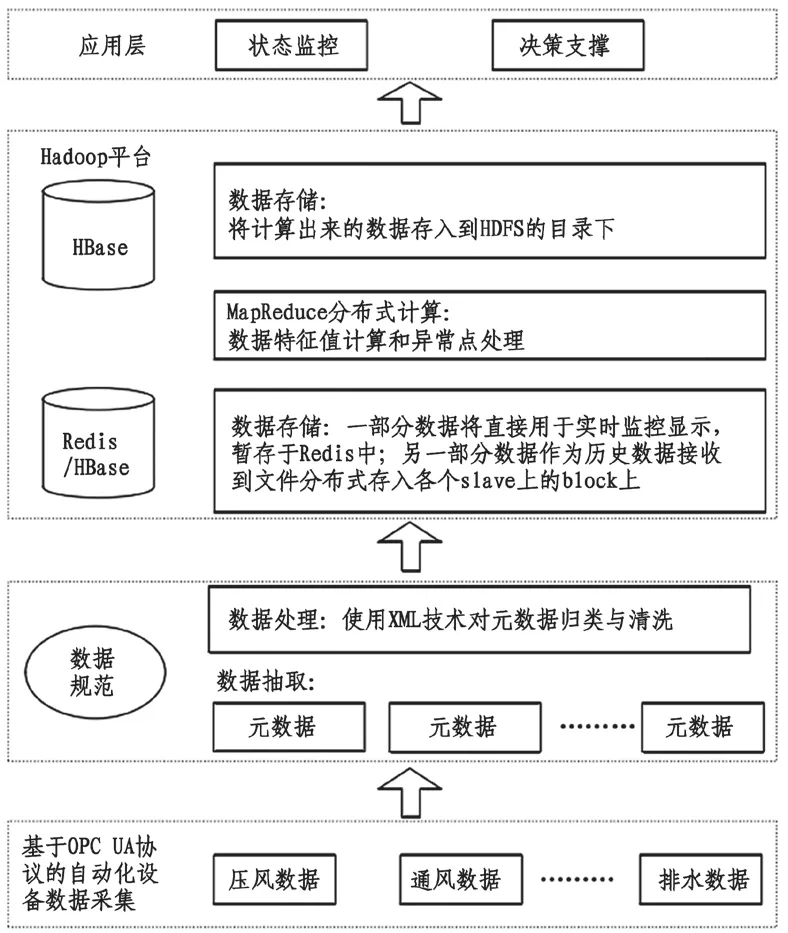
圖1 總體設計結構圖
從圖1 可以看出,Hadoop 數據管理平臺可以分為四大部分,包括數據采集、數據轉換、數據存儲、數據分析。數據采集主要是通過井下各個設備上的傳感器完成信息的采集,包括溫度、濕度、轉速等,再通過PLC 以及以太網組合完成采集數據的上傳工作,將數據傳輸到地面管理中心。數據轉換是將數據通過XML文本格式的媒介進行數據的規范化處理,避免了數據各自孤立的問題存在。數據存儲是將轉換完成的數據進行指定位置的存儲,存儲過程分為兩部分,一部分是通過Redis 將實時數據進行傳輸同時將其暫時儲存在內存中便于上層實時顯示數據;另一部分是將以往數據通過文件系統保存在HBase各節點容器中,方便數據的讀取。在遠程服務器中需要實時顯示各煤礦的信息,也是從Redis 直接調取。平臺的最后工作是數據的分析,同時根據分析結果作出判斷與決策。通過數據分析掌控井下的運轉情況,還可以實現異常數據的排除,同時在大數據技術的基礎上進行數據對比分析、故障診斷等。
3 Hadoop 平臺子系統的設計
3.1 OPC UA 協議基礎數據采集系統設計
為了實現井下的機電設備數據采集驅動標準一致,能夠通過傳感器將反饋的數據進行統一的處理,因此基于OPC UA 協議搭建了每組數據的存儲地址,按照一致的采集協議實現各個設備之間信息的交互,同時也能夠解決現在由于遠程集成系統導致的數據不通的問題。
數據采集系統的結構組成如圖2。
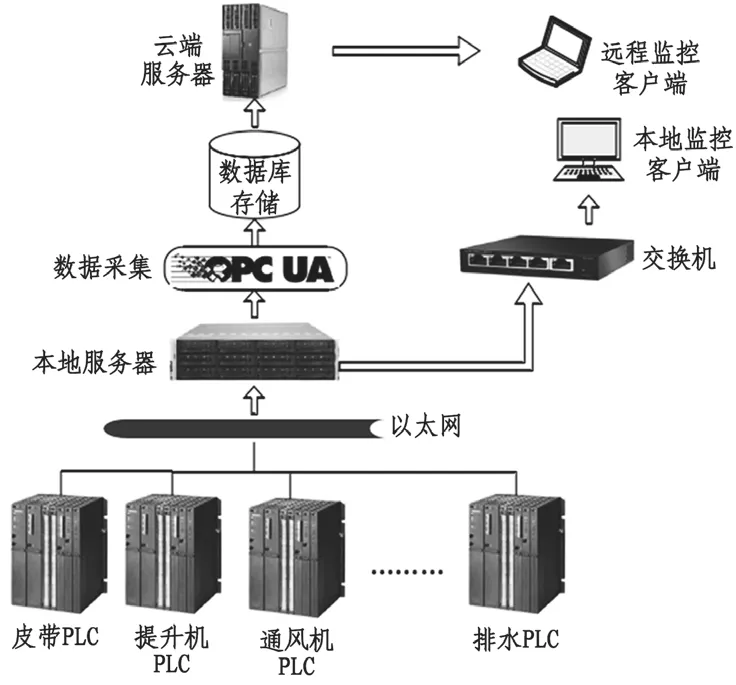
圖2 采集系統結構組成圖
采集系統中本地服務器通過以太網與工業網絡相連接,同時以網絡為路徑,將本地服務器PC 作為客戶端,形成C/S 形式的本地數據采集系統。在對各個設備進行數據采集時,通過多線程的模式,實現同時采集。采集結束后將數據進行解析封裝之后傳遞到相應的地址空間,再上傳到云服務器中,完成數據的存儲,為后續的分析處理做準備。
3.2 MapReduce 特征的數據提取
在Hadoop 平臺中,集群批處理框架被稱為MapReduce,依靠框架本身的分布式計算環境來提供相應的計算模式。其計算模式主要來源于框架的兩大功能,即Map 和Reduce。其代表的是兩種函數,分別是映射函數Mapper 和歸約函數Reducer。在數據處理過程中首先在Map 中進行篩選以及轉換,之后數據會進行Reduce 歸約,完成數據規模收縮,再通過Reducer 聚合功能來獲得最終的結果。圖3為MapReduce 結構圖。
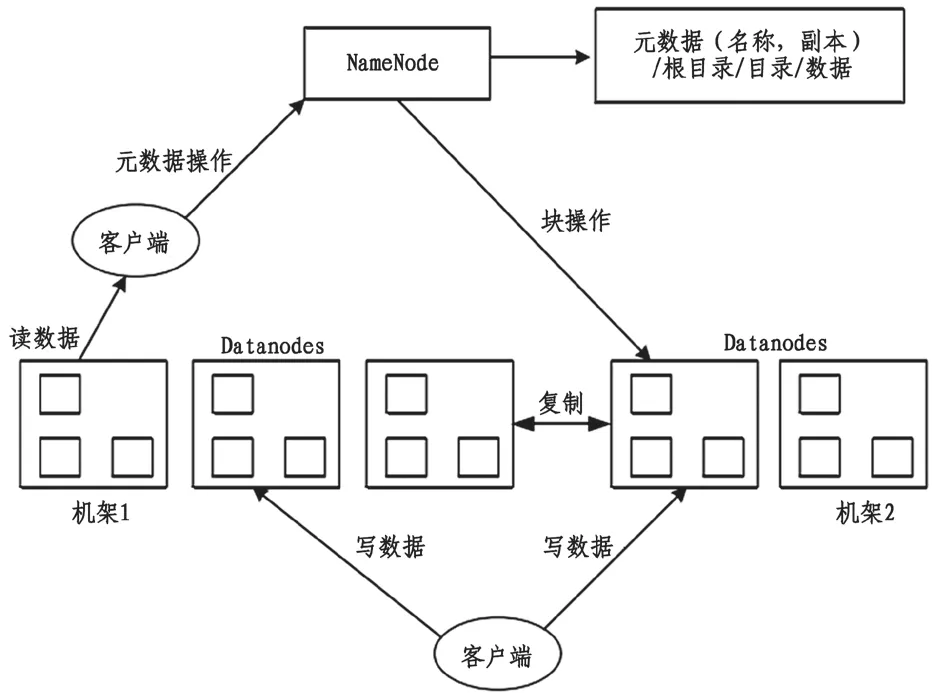
圖3 MapReduce 結構圖
在完成數據采集存儲之后,需要對特征數據完成提取,方便后續的分析。數據提取流程如圖4。
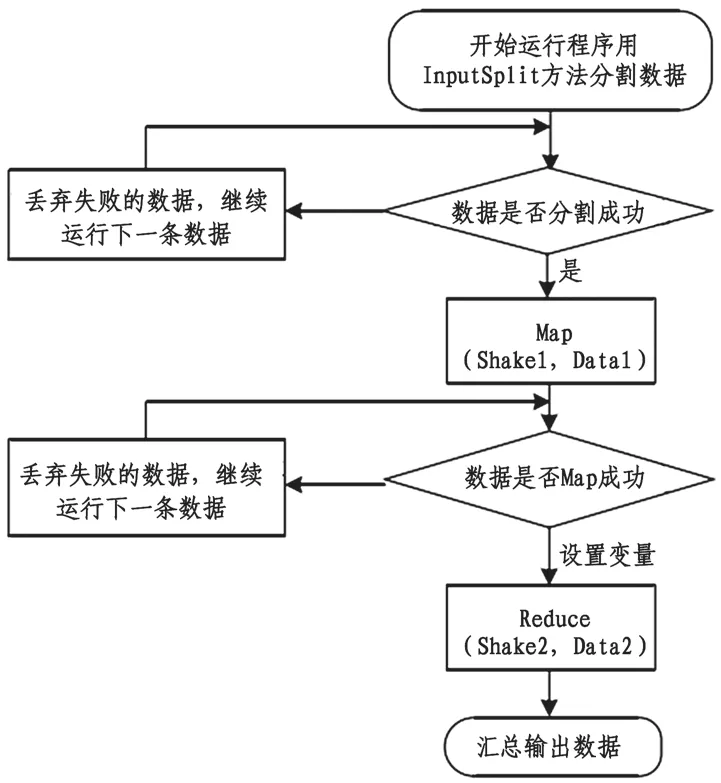
圖4 特征數據提取過程
3.3 Redis 技術下的數據傳輸架構
Redis 技術下的數據傳輸層作為連接采集層與上機監管端之間的橋梁,在Hadoop 平臺下,起著關鍵的作用。Redis 技術具有數據讀寫快、數據緩存持久、交互模式多等特點,可以通過發布以及訂閱兩種模式將數據進行傳輸,實現了數據從客戶端到服務端的傳輸,極大地縮短了數據的傳輸時間。由于其內部的分布式緩存功能,可以將解析的數據暫存在Redis 數據庫中,減小了數據丟失的問題。圖5 為Redis 的兩種模式。
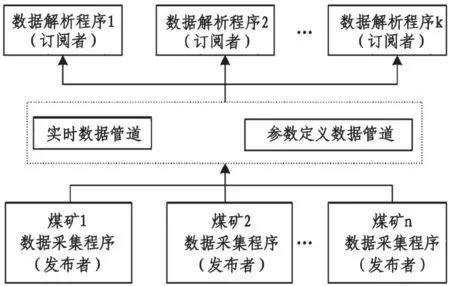
圖5 Redis 發布/訂閱模式
3.4 HBase 技術下的數據存儲
圖6 為HBase 技術下數據存儲流程圖。在整個過程中,首先通過OPC 服務器來獲取設備的實時狀態數據,將數據進行XML 文檔格式的轉換,后到達用戶界面終端對設備數據進行操作。一旦數據中心收到終端查詢指令后,平臺內Yarn 實物調動引擎將會對指派的任務進行分解。對于實時類數據存儲,會根據業務規則完成數據的計算,將計算結果歸納到存儲區內,再按照多個數據完成節點來進行數據存儲;對于文檔類文件,將會根據屬性自動識別為標準格式進行存儲。根據數據節點完成的緩存,將會按照Yam 指令程序分解任務進行逐一完成:首先實時數據到達緩存區,按照時間的先后順序對數據進行接收排序;隨后數據到達計算區,Yarn 實物引擎會通過發出的調度指令接收下發的歷史數據集,將數據存儲在實時數據緩存區內;緊接著對HBase 數據庫進行容量檢測,若發現資源充足,將會被立即送到數據庫中,若空間不足,會將其暫存在Redis 中,待資源充足后再進行傳輸。
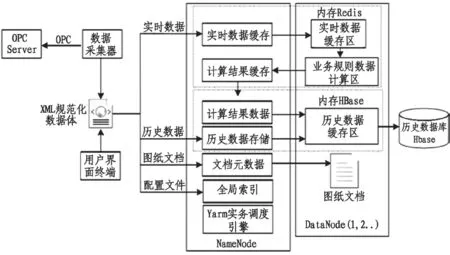
圖6 HBase 技術下數據存儲流程圖
4 結論
本文以數據監測平臺為研究對象,為了解決目前出現的數據雜亂難集中、難處理、難維護、難流通等的問題,以大數據技術為依托,對設備狀態Hadoop 平臺進行設計,再分別對Hadoop 平臺4 大組成系統進行設計,分別是數據采集、數據提取、數據傳輸以及數據存儲,成功將難集中、難處理、信息孤島等問題解決,實現海量數據的有序化存儲,為數字化礦山注入自己的一份力量。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
中國特種設備安全(2022年6期)2022-09-20 02:52:28
電子制作(2018年11期)2018-08-04 03:26:08
中國科技論壇(2017年7期)2017-07-25 08:49:53
中華手工(2017年2期)2017-06-06 23:00:31
工業設計(2016年12期)2016-04-16 02:52:00
中外會展(2014年4期)2014-11-27 07:46:46
消費者報道(2014年7期)2014-07-31 11:23:57
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
中國中醫藥現代遠程教育(2014年16期)2014-03-01 04:28:54
