
參數可靠性全局靈敏度高效分析的代理模型法
2023-07-28 10:44:24員婉瑩呂震宙
航空學報 2023年12期
關鍵詞:模型
員婉瑩,呂震宙
1.西北工業大學 重慶科創中心,重慶 400000
2.西北工業大學 航空學院,西安 710072
3.西北工業大學 深圳研究院,深圳 518063
靈敏度分析主要研究的是模型的輸出不確定性是如何分配到輸入不確定性的[1]。常見的靈敏度分析根據所關注的輸出統計量的不同,將其分為基于方差的靈敏度分析[2-3]、基于概率密度函數的靈敏度分析[4-5]以及基于可靠性的靈敏度分析[6-7]。可靠性是在充分考慮不確定性因素基礎上,對結構安全程度進行量化的指標。精確的不確定性概率分布是進行精細化可靠性分析的基礎。結構系統中的不確定性主要分為2 類,即主觀不確定性和客觀不確定性。主觀不確定性主要是認識不足和信息匱乏導致的,客觀不確定性是事物內部的固有隨機性。如疲勞壽命,大量試驗結果表明其服從對數正態分布,但對于缺乏試驗數據的情況,其分布參數將無法準確確定,即具有隨機性,這個隨機性會隨著試驗樣本量的增加而減小。因此,分布參數可靠性全局靈敏度分析[8]也廣受關注,其衡量的是分布參數的不確定性對可靠性的影響,通過分布參數可靠性全局靈敏度分析,識別影響可靠性的重要分布參數,可以通過收集更多對應的基本輸入變量的樣本信息,消除重要分布參數的不確定性,減小分布參數不確定性對可靠性結果的影響。
分布參數可靠性全局靈敏度分析的直接數值模擬法涉及3 層嵌套分析過程,且計算量與不確定性分布參數的維數相關,3 層嵌套分析過程龐大的計算量無法滿足工程中快速靈敏度分析的要求。因此,文獻[8]提出了代理模型的方法,但由于建立的是失效概率函數的代理模型,其計算過程亦是1 個雙層循環過程,且失效概率函數的代理精度會影響分布參數可靠性全局靈敏度分析的準確性。文獻[9]提出了Bayes 公式結合代理模型的方法,該方法僅涉及1 個單層分析過程,將分布參數可靠性全局靈敏度分析等價轉化為樣本狀態(失效或安全)識別問題,且僅需1 組無條件樣本矩陣,但該方法中的抽樣是簡單隨機抽樣,對于小失效概率問題,抽樣樣本規模龐大,龐大的候選樣本池規模會導致代理模型訓練過程極其費時。在文獻[9]的基礎上,本文提出一種分步自適應代理模型結合重要抽樣的單層分析法,該方法通過等概率轉換引入標準正態輔助變量,實現分布參數嵌入功能函數的目的,進而實現分布參數重要抽樣概率密度函數的建立。通過建立低維隨機變量空間中功能函數的Kriging 代理模型,實現高維輔助變量及不確定性分布參數變量近似最優抽樣概率密度函數的建立,及相應重要抽樣樣本點的產生;進一步對構造近似最優抽樣概率密度函數的低維隨機變量空間中功能函數的Kriging 代理模型進行學習,以準確識別重要抽樣樣本點的狀態(失效或安全),高效完成分布參數可靠性全局靈敏度分析。
本文所提方法極大地提高了樣本的利用率,減縮了Kriging 代理模型的訓練時間。數值算例和工程算例的計算結果表明,在保證計算精度的同時,本文所提方法相對文獻[9]方法極大地減縮了Kriging 代理模型訓練過程中的候選樣本池規模,減少了計算時間。
1 參數可靠性全局靈敏度定義
定義結構功能函數為Y=g(X),其中:Y 為結構或系統的輸出;X=[ X1,X2,…,Xn]為結構的基本隨機輸入變量;n 表示基本隨機輸入變量的個數;X 的聯合概率密度函數為fX(x|θ);θ 為基本隨機輸入變量的分布參數。當基本隨機輸入變量的樣本較少或對其認識有限時,其分布參數亦會存在不確定性,該不確定性可以用區間不確定性描述、模糊不確定性描述或隨機不確定性描述。本文主要研究當分布參數為隨機不確定性變量時,其不確定性對失效概率分散性的影響程度。當分布參數θ 具有不確定性時,結構的失效概率將不再是一個定值,其是分布參數θ的函數,即
式中:PF(θ)為失效概率函數;IFg(x)為失效域指示函數,定義為。
為了衡量不確定性分布參數對失效概率分散性的影響,文獻[9]提出了分布參數可靠性全局靈敏度,其定義式為
式中:E(·)表示期望 算子;θi表示第i 個不 確定性分布參數;θ-i表示除了θi變量之外的其他不確定性分布參數變量的向量。
式(2)表明,直接模擬法求解第i 個不確定性分布參數θi的可靠性全局靈敏度是一個3 層耦合分析過程,最外層是中間層計算結果|Eθ(PF(θ))-Eθ-i(PF(θ)|θi)|關于θi的期望,中間層的求解關鍵是Eθ-i(PF(θ)|θi),其是最內層失效概率函數在θi固定時關于θ-i的期望,最內層是求解不同分布參數取值下的失效概率。3 層法求解分布參數可靠性全局靈敏度指標的真實功能函數調用次數為:m×Nθi×Nθ-i×NX+Nθ×NX,其中:m 表示不確定性分布參數的個數;Nθi表示計算外層期望時θi的樣本個數;Nθ-i表示計算中間層期望時θ-i的樣本個數;NX表示計算內層失效概率抽取的輸入變量X 的樣本個數;Nθ為計算失效概率函數無條件均值Eθ(PF(θ))時抽取的不確定性分布參數θ 的樣本。
為了克服分布參數可靠性全局靈敏度計算的3 層嵌套過程以及計算量與不確定性分布參數維數的相關性,文獻[9]提出了基于Bayes 公式的單層分析法,該方法主要采用了Monte Carlo 簡單隨機抽樣,對于小失效概率問題,需要大量的計算樣本。因此,本文將在單層計算公式的基礎上,研究基于重要抽樣的求解算法,并通過2 步Kriging 代理模型實現近似最優重要抽樣概率密度函數的構造以及重要抽樣樣本狀態(失效或安全)的識別。
2 參數可靠性全局靈敏度求解的單層Monte Carlo 法
首先,根據等概率轉換[10-11]建立標準正態變量與任意隨機變量及其分布參數的關系,即
式中:ui表示標準正態變量;θXi表示Xi變量的分布參數;Φ(·)為標準正態變量的累積分布函數;FXi(·)為Xi變量的累積分布函數。
根據式(3)可以得到隨機變量Xi與其分布參數θXi及ui之間的關系,即
將式(4)代入功能函數Y=g(X)中,得到式(5)所示的等效功能函數為
式中:等效功能函數中隨機變量的維數為n+m;n 為標準正態輔助變量的個數;m 為不確定性分布參數的個數。
基于等效功能函數gG(u,θ)可得Eθ(PF(θ))和Eθ-i(PF(θ)|θi)的等價計算式如式(6)及式(7)所示:
式 中:失 效 域F 的定義為F={u,θ:gG(u,θ)≤0}; IFG(u,θ) 為 失 效 域 指 示 函 數,定 義 為為n 個相互獨立的標準正態變量的聯合概率密度函數;fθ(θ)為不確定性分布參數的聯合概率密度函數;P{·}為概率算子。
根據Bayes 公式可建立P{F|θi}與P{F}的關系,即
求解式(9)的關鍵是計算P{F}和fθi(θi|F),根據Monte Carlo模擬法(Monte Carlo Simulation, MCS)抽取變量u和θ的樣本得到Su,θ樣本矩陣,即
式中:NMCS表示MCS 樣本規模,將樣本矩陣Su,θ中樣本代入等效功能函數中得到P{F}的估計式為
fθi(θi|F)可以根據Su,θ中的失效樣本結合概率密度函數估計方法[12-14]求解,無需額外功能函數的計算。因此,基于Bayes 公式的單層樣本法的計算量為NMCS,其與不確定性分布參數的維數無關,由于P{F}的求解也即識別樣本矩陣Su,θ中樣本的狀態(失效或安全),因此文獻[9]亦將自適應Kriging 代理模型嵌入基于Bayes 公式的單層樣本法中進一步降低功能函數的調用次數。但對于小失效概率問題,大規模的樣本矩陣Su,θ會使得Kriging 代理模型自適應學習過程較為耗時,因此,本文將提出基于重要抽樣的單層計算法。
3 所提方法
3. 1 參數可靠性全局靈敏度求解的單層重要抽樣法
式(9)的 計算關鍵是估計P{F}及fθi(θi|F),本節將介紹如何利用重要抽樣法計算P{F}及fθi(θi|F)。首 先,引 入 重 要 抽 樣 概 率 密 度 函 數hu,θ(u,θ),根 據 重 要 抽 樣 法 可 得P{F}的 計 算式為
式中:Eh(·)表示在重要抽樣概率密度函數抽樣下的期望算子。式(12)的估計通過hu,θ(u,θ)抽取變量u 和θ 的樣本,得到對應的樣本矩陣為
式中:NIS表示重要抽樣樣本規模。
通過功能函數判斷重要樣本的失效域指示函數值進而得到P{F}的估計值,即
3.2 節將詳細介紹如何采用分步自適應更新的Kriging 代理模型構造重要抽樣概率密度函數以及如何準確預測各個重要樣本的失效域指示函數值。
通過引入Metropolis-Hastings 準則[15-16],可以 將樣 本 矩 陣 中 服 從hu,θ(u,θ|F)的 樣 本 轉換 為 服 從fu,θ(u,θ|F)的 樣 本,進 而 通 過Edgeworth 級數[14]得到fθi(θi|F),實 現重復利用中樣本信息得到各個不確定性分布參數的可靠性全局靈敏度,具體執行過程如下。
第2步 定義初始化樣本z(k)=,其中k=1。
第3步 計算接受概率并確定z(k+1)。根據Metropolis-Hastings 準 則[15-16],接 受 概 率 的 定義為
式中:π(·)是目標分布;p(·)是建議分布。在本文中 目 標 分 布 是 fu,θ(u,θ|F),建 議 分 布 是hu,θ(u,θ|F)。fu,θ(u,θ|F)和hu,θ(u,θ|F)又 可 分別表示為
式中:P { F }=∫ fu,θ(u,θ)IFG(u,θ)dudθ;Ph {F}=∫hu,θ(u,θ)IFG(u,θ)dudθ。
根 據 式(16)構 建 服 從hu,θ(u,θ|F)的 樣 本d(k+1)={uhF(k+1),θhF(k+1)}向z(k+1)轉化的接受概率為
根據式(19)的判據,可以得到z(k+1),即
式中:random [0,1]表示[0,1]區間均勻分布的隨機數。
根據以上流程即可得到服從fu,θ(u,θ|F)的樣 本,將 樣 本 放 入 矩 陣中,即
式 中:H3(·)、H4(·) 和H6(·) 是3 階、4 階、6 階Chebychev-Hermit 多項式。
綜上,可以通過重復利用重要抽樣樣本點得到各個不確定性分布參數的可靠性全局靈敏度指標。重要抽樣法中的關鍵是如何高效地構造最優抽樣概率密度函數和準確識別重要抽樣樣本的失效或安全狀態。3.2 節將建立通過低維自適應Kriging 代理模型構建高維重要抽樣概率密度函數的方法以及如何在構建高維重要抽樣概率密度函數的低維Kriging 代理模型的基礎上通過繼續自學習實現重要抽樣樣本安全或失效狀態的識別。
3. 2 自適應代理模型結合單層重要抽樣法
3.2.1 基于代理模型的近似最優抽樣概率密度函數
重要抽樣概率密度函數hu,θ(u,θ)的最優形式為
由于P { F }是個待求量,因此,文獻[17]提出了基于Kriging 代理模型的近似最優重要抽樣概率密度函數構造方法,即
式中:概率分類函數π(u,θ)表示根據當前Kriging 代理模型gG(K)(u,θ)得到樣本點{u,θ }處預測值gG(K)(u,θ)≤0 的概率,定義為π(u,θ)=P { gG(K)(u,θ)≤0}=
式 中:μgG(K)(u,θ) 表 示 Kriging 代 理 模 型gG(K)(u,θ)的均 值[18-19];σgG(K)(u,θ)表 示Kriging代理模型gG(K)(u,θ)的標準差[18-19]。
從式(27)中可以看出,為了構造概率分類函數π(u,θ),需要建立n+m 維的Kriging 代理模型,相對建立真實功能函數的n 維代理模型g(K)(X),gG(K)(u,θ)的建立增加了代理模型的維度。因此,基于等概率轉換,本文提出利用n 維Kriging 代理模型g(K)(X)來構造n+m 維概率分類函數的方法,進而產生u 和θ 的重要樣本,具體推導如下。
式中:X=[ X1,X2,…,Xn];;μg(K)(X)表示Kriging 代理模型g(K)(X)的均值;σg(K)(X)表示Kriging代理模型g(K)(X)的標準差。
通過式(28)的等式關系,可以通過構造g(K)(X)結合等概率轉換得到變量{u,θ }的概率分類函數。具體流程如下:
第1 步 構造功能函數的初始Kriging 代理模型,將功能函數g(X)在該階段的Kriging 代理模型記為。首先由u 和θ 的概率密度函數fU(u)及fθ(θ)產生變量{u,θ }的少量樣本點,并將其放入矩陣中,即
根據式(4)的轉換關系可得到對應的X 空間的樣本點,即
第2 步 基于π(u,θ),利用簡單拒絕抽樣法[21]抽取變量{u,θ }的重要抽樣樣本。具體過程如下:
第2. 1 步 令q=1;并通過u 和θ 的概率密度函數fU(u)和fθ(θ)產生變量{u,θ }的N 個樣本,計算這N 個樣本的概率分類函數值,從而確定簡單拒絕抽樣中的常數 c,即 c=,其中π(u(i),θ(i))通過式(28)確定。
第2. 2 步 通過變量u 和θ 的概率密度函數 fU(u) 和 fθ(θ) 產 生 變 量{u,θ } 的 樣 本{u(q),θ(q)}。
第2. 3 步 產生標準均勻分布變量的樣本p(q)。
第2. 4 步 當p(q)-cπ(u(q),θ(q))≤0 接受 樣本{u(q),θ(q)},將 樣 本{u(q),θ(q)}放入重要抽 樣 樣本矩陣的第q 行,并執行第2.5 步;否則,返回第2.2 步。
第2. 5 步 當q=NIS時結束簡單拒接抽樣過程,輸出重要抽樣樣本矩陣;否則,令q=q+1,并返回第2.2 步。
第3步 更新訓練樣本集。對重要抽樣樣本進行K-means 聚類分析以覆蓋所有可能的失效區域,得到K 個形心
第4 步 判斷代理模型的收斂性。由交叉驗證法[22]計算修正因子αcorr的留一法估計值,的計 算式為
式中:NT表示訓練樣本集T 中訓練樣本個數;;IFg(x(i))=表示除去訓練樣本集T 中第i 個訓練樣本后構建的Kriging 代理模型所建立的概率分類函數。當概率分類函數精確近似失效域指示函數時,留一法交叉驗證誤差應為1,此時需要較多的更新訓練樣本點來更新Kriging代理模型,文獻[17]提出了以下折中的停止準則,即當收斂條件滿足,輸出當前重要抽樣樣本矩陣,若收斂條件0.1 <不 滿足,返 回第2 步。
3.2.2 重要抽樣樣本失效域指示函數值預測的自適應代理模型法
式中:xh(i)表示樣本矩陣中的第i 個樣本;表示Kriging 代理模型的均值;表示Kriging 代理模型的標準差;Φ(-U(x))表示樣本點x 狀態(失效或安全)被誤判的概率。誤判概率越大的點越需將其加入訓練樣本集中,因此更新訓練樣本點可根據式(33)選出,即
4 案例分析
4. 1 數值算例
數值算例的功能函數為
式中:輸入變量X1,X2和X3均服從正態分布,即Xi~N(μi,1)(i=1,2,3);μi為Xi的均值,其具有不確定性,均服從均值為4,標準差為1 的正態分布。
表1 為數值算例的分布參數可靠性全局靈敏度分析結果。從表1 的計算結果可以看出,本文所提方法和文獻[9]所提方法的計算精度和穩健性隨著候選樣本池的增加而增加,且隨著樣本池的增加,2 個方法的計算精度逐漸收斂于雙層MCS 采用大樣本計算的結果。在基本相同的計算精度和穩健性下,重要抽樣樣本池的規模是1 000,而文獻[9]方法的候選樣本池規模是524 288,本文所提方法相對文獻[9]中方法降低了99.81% 的樣本池規模,降低了78.31%的計算時間。
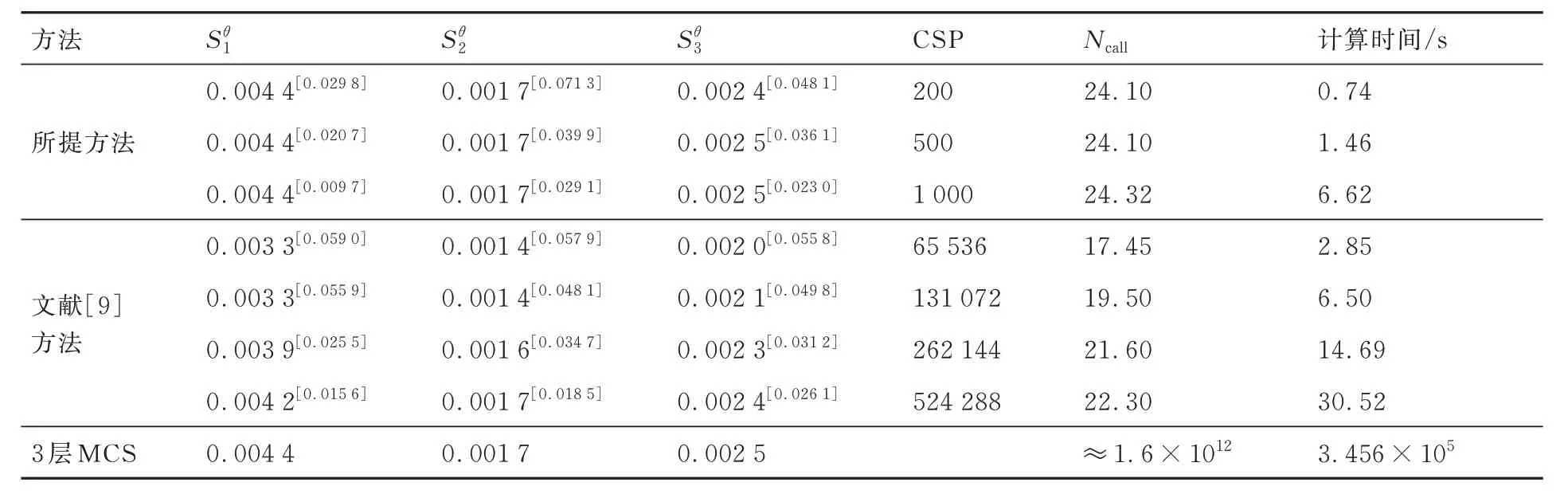
表1 數值算例的分布參數可靠性全局靈敏度分析結果Table 1 Results of parameter global reliability sensitivity indices of numerical example
4. 2 導彈彈翼
彈翼和舵面是產生氣動升力和法向力(垂直導彈縱軸方向)的重要部件,用以克服重力和實現導彈的機動飛行,保證導彈具有良好的操縱性和穩定性。舵面是指在氣流中利用偏轉而產生導彈平衡力和控制力來操縱導彈飛行的氣動翼面,又稱操縱面。按功能可分為升降舵、方向舵和副翼;按作用介質可分為空氣舵,燃氣舵;按照結構和部位安排分為全動舵、位于翼面后緣的舵、翼尖舵、陀螺舵和擾流片。圖1 為某型導彈舵面結構的示意圖,其由5 條桁條、6 條翼肋、蒙皮以及作用于和彈體相連接的固定端所組成。各個部件的材料均為某鈦合金材料,材料的彈性模量為E,泊松比為ν。翼肋與桁條的厚度均為trs,蒙皮的厚度為tsk。在導彈的飛行過程中,舵面的作用主要用于調節和穩定飛行姿態,其所承受的載荷主要為氣動載荷,大小為P,垂直作用于上蒙皮。以舵面結構在承受氣動載荷情況下的變形不超過δc=8 mm 為門限值,建立該舵面結構的功能函數為
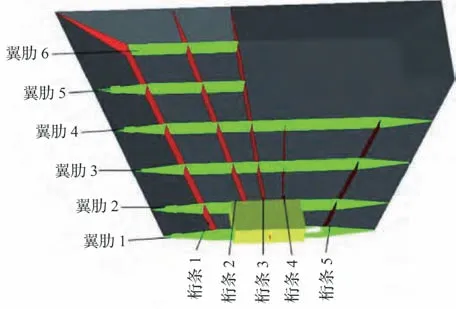
圖1 某型導彈舵面結構示意圖Fig. 1 Missile wing structure
式中:max(δ)為結構在承受氣動載荷情況下的最大變形,其通過有限元分析得到,確定性有限元分析結果如圖2 所示。舵面結構材料的彈性模量、泊松比、桁條、翼肋、蒙皮的厚度以及所承受的氣動載荷是相互獨立的正態分布隨機變量,輸入隨機變量的均值具有不確定性,分別服從正態分布且相互獨立。輸入隨機變量及其均值的分布參數如表2 及表3 所示。

圖2 某型導彈舵面結構有限元模型Fig. 2 Finite element model of missile wing structure

表2 隨機變量的分布類型及分布參數Table 2 Distribution types and distribution parameters of variables
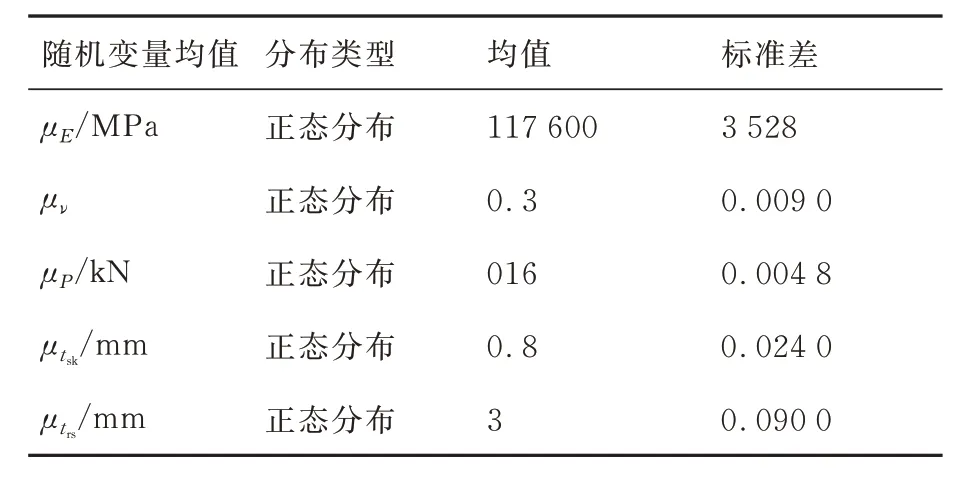
表3 隨機變量均值的分布類型及分布參數Table 3 Distribution types and distribution parameters of means of variables
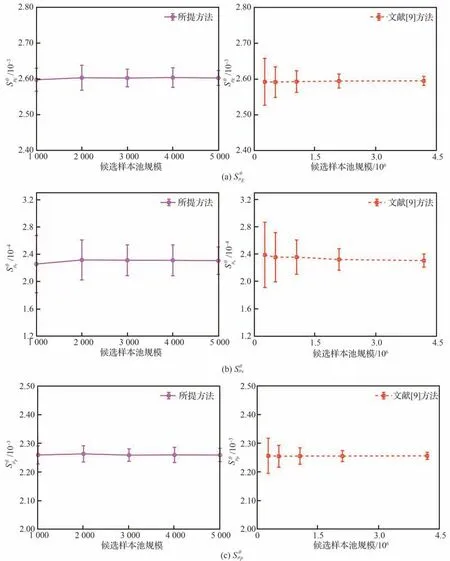
圖3為不同樣本池規模下各個變量分布參數可靠性全局靈敏度分析結果的收斂圖,從圖3 中可以看出,隨著樣本池規模的增加本文所提方法的計算穩健性不斷提高,且計算結果逐步收斂于大樣本容量下文獻[9]方法的計算結果,且本文所提方法在樣本池規模為5 000 時的計算結果與文獻[9]方法在2 097 152 樣本池規模下的計算結果的精度和穩健性基本一致。表4 為不同樣本池規模下,2 種方法所需的功能函數調用次數和選擇更新訓練樣本點的時間,從表4 的結果中可以看出,在計算精度和穩健性基本一致的情況下,本文所提方法與文獻[9]所提方法所需的功能函數調用次數相同,但本文所提方法由于采用重要抽樣,提高了樣本的抽樣效率,降低了候選樣本池規模,從而降低了在候選樣本池迭代選擇更新訓練樣本點的時間。在計算精度和穩健性基本一致的情況下,本文所提方法相對文獻[9]方法降低了91.05%的Kriging 代理訓練過程中選擇更新訓練樣本點的時間。2 種方法得到的分布參數可靠性全局靈敏度排序一致,如圖4 所示,分布參數可靠性全局靈敏度排序為:μE>μP>μtsk>μtrs>μν。因此,可以通過獲取更多彈性模量E 的數據,提高對彈性模量E 統計規律的認識,進而最大程度地降低失效概率的分散性。
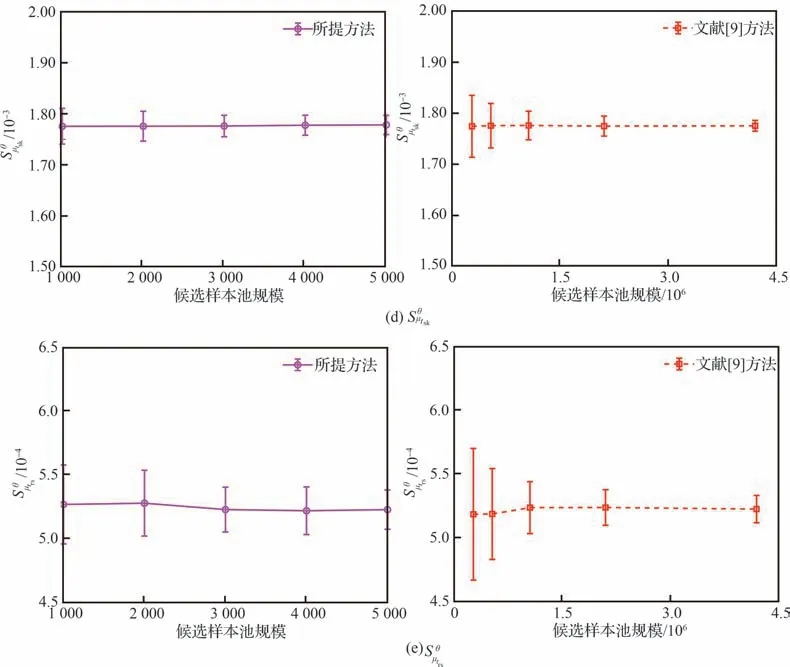
圖3 分布參數可靠性全局靈敏度計算結果隨候選樣本池規模變化的收斂圖Fig. 3 Convergence plot of parameter reliability sensitivity indices with changes in the size of the candidate sample pool
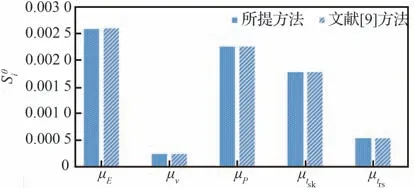
圖4 分布參數可靠性全局靈敏度排序圖Fig. 4 Importance rank of parameter global reliability sensitivity indices
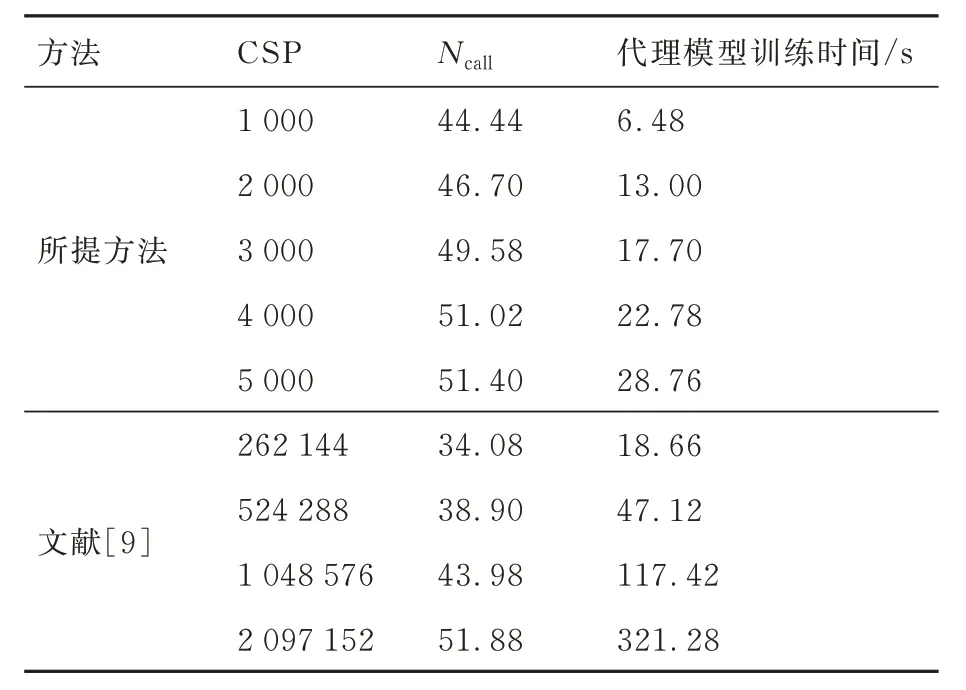
表4 所提方法與文獻[9]方法不同樣本池規模的計算量Table 4 Computational cost of proposed method and method in Ref.[9] with different sizes of candidate sampling pool
5 結 論
1)本文通過等概率轉換,構建了包含不確定性分布參數的等效功能函數,為建立分布參數可靠性全局靈敏度分析的重要抽樣法建立基礎。
2)本文提出了分布參數可靠性全局靈敏度分析的分步自適應代理模型的單層重要抽樣法,實現了利用原始空間功能函數代理模型構建輔助變量與不確定性分布參數的重要抽樣概率密度函數,并通過進一步更新構造最優重要抽樣概率密度函數的原始空間功能函數,實現輔助變量與分布參數重要樣本狀態的準確識別,完成參數可靠性全局靈敏度分析。
3)該方法僅需1 組無條件重要抽樣樣本即可實現各個不確定性分布參數可靠性全局靈敏度分析。
4)算例分析結果表明,本文所提方法相對文獻[9]中方法節省了>70%的代理模型訓練時間,說明了本文所提方法的高效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
