基于符號補償的RISC-V處理器乘法器優化
2023-08-03 02:07:50高嘉軒劉鴻瑾張紹林華更新
計算機測量與控制 2023年7期
高嘉軒,劉鴻瑾,施 博,張紹林,華更新
(1.北京控制工程研究所,北京 100190;2.北京軒宇空間科技有限公司,北京 100080)
0 引言
目前嵌入式領域主要應用的處理器為ARM架構處理器,然而該架構經過多年的研究與擴展,其實現逐漸變得復雜。同時,ARM架構需要高昂的授權費,導致應用開發成本增高,不利于進行自主擴展開發。而RISC-V是由加州大學伯克利分校提出的一個開源指令集架構,其特點是開源、簡單、可擴展等,具有良好的內部結構[1]。其高度模塊化的指令集架構可應用于各種需求的處理器設計[2]。出于自主可控的考慮,開源的RISC-V架構將成為處理器開發的新方向。作為一種新興的開源指令集架構,RISC-V已經在學術界和工業界都得到了廣泛的關注[3]。RISC-V生態系統的開源社區為其提供了豐富的對應工具鏈與開源軟件,使研究者們能夠在研究中快速利用RISC-V[4]。基于RISC-V官方指令集手冊,已發布了多款RISC-V處理器[5],比如Rocket Core[6]、SiFive[7]、BOOM Core[8]和LowRISCSoC[5]。
乘法器是處理器的運算核心,其運行速度影響了處理器的運行速度[9]。許多數字信號處理和機器學習應用需要進行大量乘法計算,其表現在很大程度上受到乘法器性能的限制。以卷積神經網絡為例,超過90%的CNN計算為乘法累加計算[10]。因此面對嵌入式領域乘法算力需求較高的應用場景,研究開源指令集架構的RISC-V乘法器算力與功耗優化十分必要。乘法器主要包括三個階段:操作數相乘產生部分積、部分積累加產生兩個結果以及兩個結果相加產生最終結果。目前整型乘法器的算法設計主要有串行累加陣列、Booth編碼和Wallace樹型結構[11]。針對Booth編碼的研究,通過改進后的4位編碼加快了對部分積最低位的獲取,但編碼位數更多,邏輯更為復雜[12]。而縮減基4-Booth編碼位數,則無法對最低位獲取進行優化,浪費了芯片面積[13]。有研究采用了符號擴展,從而減少了資源消耗,但未考慮部分積累加時的壓縮[14]。而針對Wallace樹型結構,有研究表明僅由基本壓縮器構成 Wallace 樹結構,需要經過5級壓縮才能將9個部分積壓縮為2個結果,其運算效率十分低下[15]。文獻[16]對Wallace樹型結構進行了改進,縮短了壓縮延時,解決了蜂鳥E203部分積壓縮延時大的問題,但其未考慮有符號部分積擴展帶來的損失。對壓縮器的研究主要是對其硬件結構進行研究,通過傳輸門結構設計基本壓縮器,節省了壓縮器面積,但不能實現雙軌輸出[17]。而高階壓縮器可以由多個基本壓縮器串聯形成,但關鍵路徑上門數較多,延時較長影響壓縮器性能[18]。
為了在不提升處理器功耗的前提下,提高RISC-V乘法器算力,減少進位次數,壓縮延時,本文提出了一種基于符號補償、基4-Booth編碼以及Wallace樹型結構的優化乘法器。由于基4-Booth編碼的系數存在負數,在壓縮時,需要進行符號擴展補齊,負數部分積累加時將產生大量進位以及比特翻轉。針對該問題,本文提出了基于符號補償的基4-Booth編碼,有效壓縮了負數符號擴展時連續比特1,減少了在加法時造成的進位以及比特翻轉,降低了乘法器功耗。傳統Wallace樹型結構由于硬件壓縮器功能簡單,因此其層次過多,關鍵路徑過長,結構不對稱。針對該問題,本文提出了交替使用3-2壓縮器與4-2壓縮器的Wallace樹型結構。改進后的Wallace樹型結構對稱,有效減少了樹型結構的層次,縮短了關鍵路徑的長度,壓縮了累加過程的延遲,降低了乘法指令執行延遲,提高了處理器乘法算力。同時由于壓縮器階數不高,因此對電路復雜度以及延遲未有明顯影響。本文從仿真、綜合以及板級層面對其進行了功能性驗證以及性能評估,測試結果表明,與未改進的PicoRV32相比,使用改進乘法器的PicoRV32在功耗有所降低的情況下,乘法器性能得到了顯著提升。
1 RISC-V指令集架構
作為一種新興指令集架構,RISC-V架構在設計之初總結了傳統指令集的優缺點,避免了傳統指令集的不合理設計。RISC-V指令編碼簡單,并且為擴展指令集預留出了足夠的編碼空間。RISC-V指令主要分為6個類型[19],包括:R型指令:寄存器-寄存器操作;I型指令:短立即數和訪存load操作;S型指令:訪存store操作;B型指令:條件跳轉操作;U型指令:長立即數操作;J型指令:無條件跳轉操作。各個類型指令結構如圖1所示。
其中,opcode為操作碼,表示指令操作。funct3和funct7部分作為opcode的附加字段,和opcode共同決定指令的具體操作。rs1和rs2表示兩個源操作數的寄存器編號,rd表示目的操作數的寄存器編號。該編碼結構位置固定,便于譯碼模塊對指令進行解析。
RISC-V指令集的整數乘法指令共有4條,分別為MUL、MULH、MULHSU、MULHU,均為R型指令。指令具體描述及用法如表1所示。
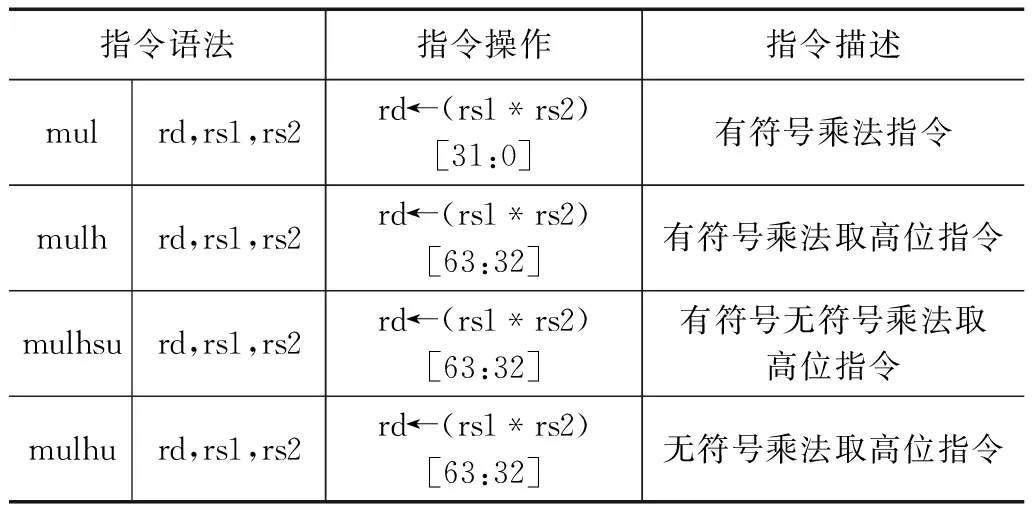
表1 RISC-V乘法指令表
其中MUL指令將源操作數進行符號位擴展,選取計算結果的低32位,MULH指令將源操作數進行符號位擴展,選取計算結果的高32位,MULHSU指令的源操作數rs1為有符號數,rs2為無符號數,指令結果選取計算結果的高32位,MULHU指令將源操作數進行零擴展,選取計算結果的高32位。
2 基4-Booth編碼
1951年,A.D Booth 在其論文“A Signed binary multiplication technique”中提出一種快速乘法算法——Booth算法[20],即為了解決有符號乘法運算中復雜的符號修正問題而提出一種乘法算法,將乘數轉變數據表示形式,使其數據出現盡可能多的0,其編碼原理如式(1)所示。
y=2n-1(-yn-1+yn-2)+2n-2(-yn-2+yn-3)+
2(-y1+y0)+(-y0+y-1)
(1)
式中,y為乘數,n為乘數位數,yn-1為y的n-1位。
從式(1)可以看出,基礎Booth編碼并不能在硬件乘法器電路中起到真正的優化作用,實際部分積個數并未減少。因此在基2-Booth編碼的基礎上提出了改進的Booth編碼,即基4-Booth編碼,進一步減少部分積個數,從而達到減少硬件加法器的目的,其編碼原理如式(2)所示。
y=2n-2(-2yn-1+yn-2+yn-3)+
2n-4(-2yn-3+yn-4+yn-5)+
22(-2y3+y2+y1)+(-2y1+y0+y-1)
(2)
式中,y為乘數,n為乘數位數,yn-1為y的n-1位。
從式(2)可以看出,多項式的項數相較于式1減少了一半,因此通過基4-Booth編碼可以有效減少部分積的個數。
然而基4-Booth編碼的系數存在負數的情況,以2n-2項系數為例,當yn-2=0,yn-3=0且yn-1=1時,該項系數為-2,因此需要考慮負數部分積對壓縮的影響。由于部分積位數不同,在壓縮時,需要進行符號擴展進行補齊,當部分積為負數時,符號位補齊為1,累加時將產生大量進位以及比特翻轉,增加乘法器功耗。
3 Wallace樹型結構
基4-Booth編碼優化了整型乘法中部分積的數量,從而減少累加次數。而為了進一步減少累加操作產生的延遲,1964年,C.S.Wallace提出的一種高效快速的加法樹結構,被后人稱為Wallace樹[21],其核心思想為將每3個加數分為一組,壓縮至2個加數,即計算結果與進位,循環往復,最終得到累加結果,其結構如圖2所示。
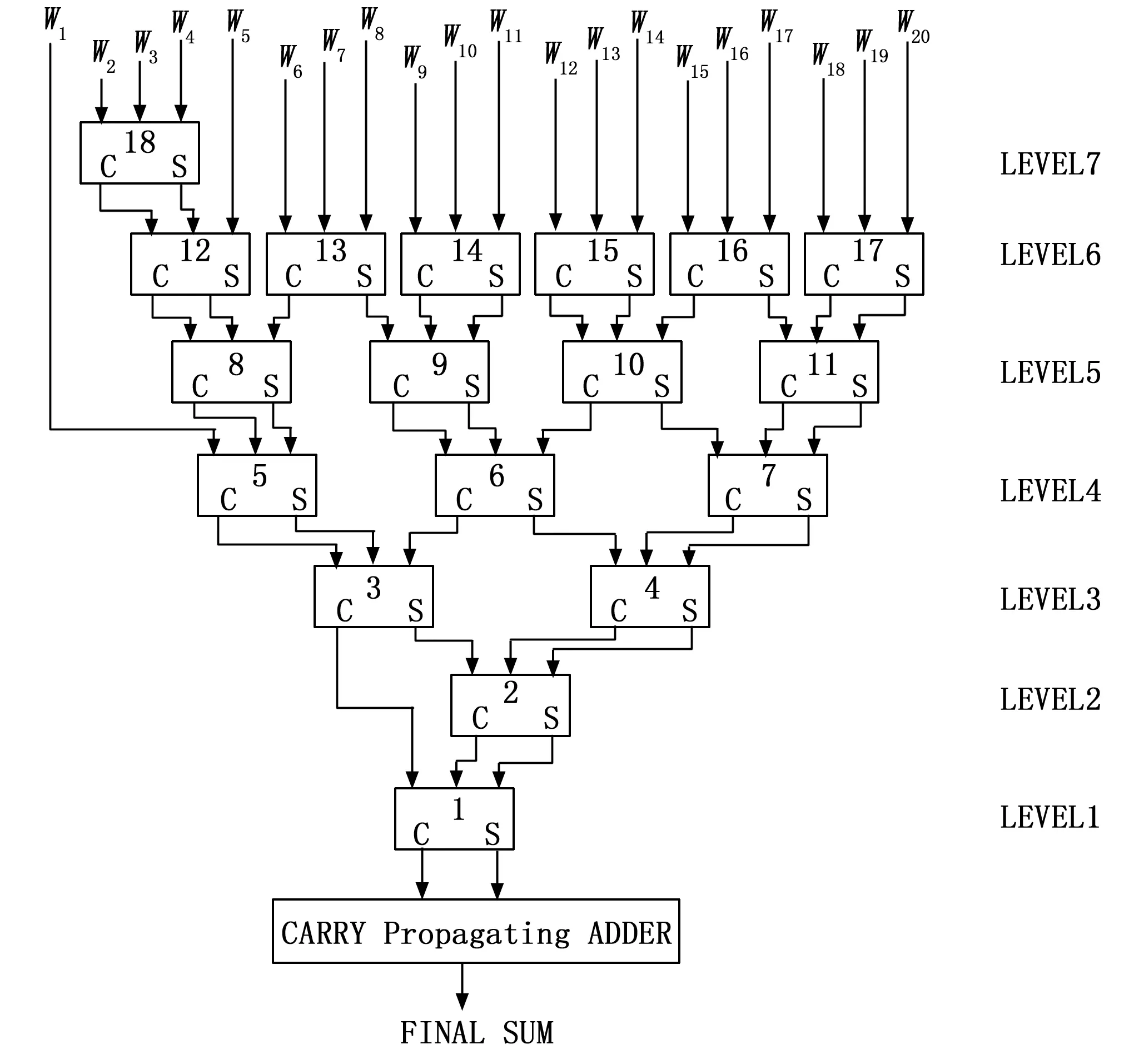
圖2 Wallace樹型結構圖
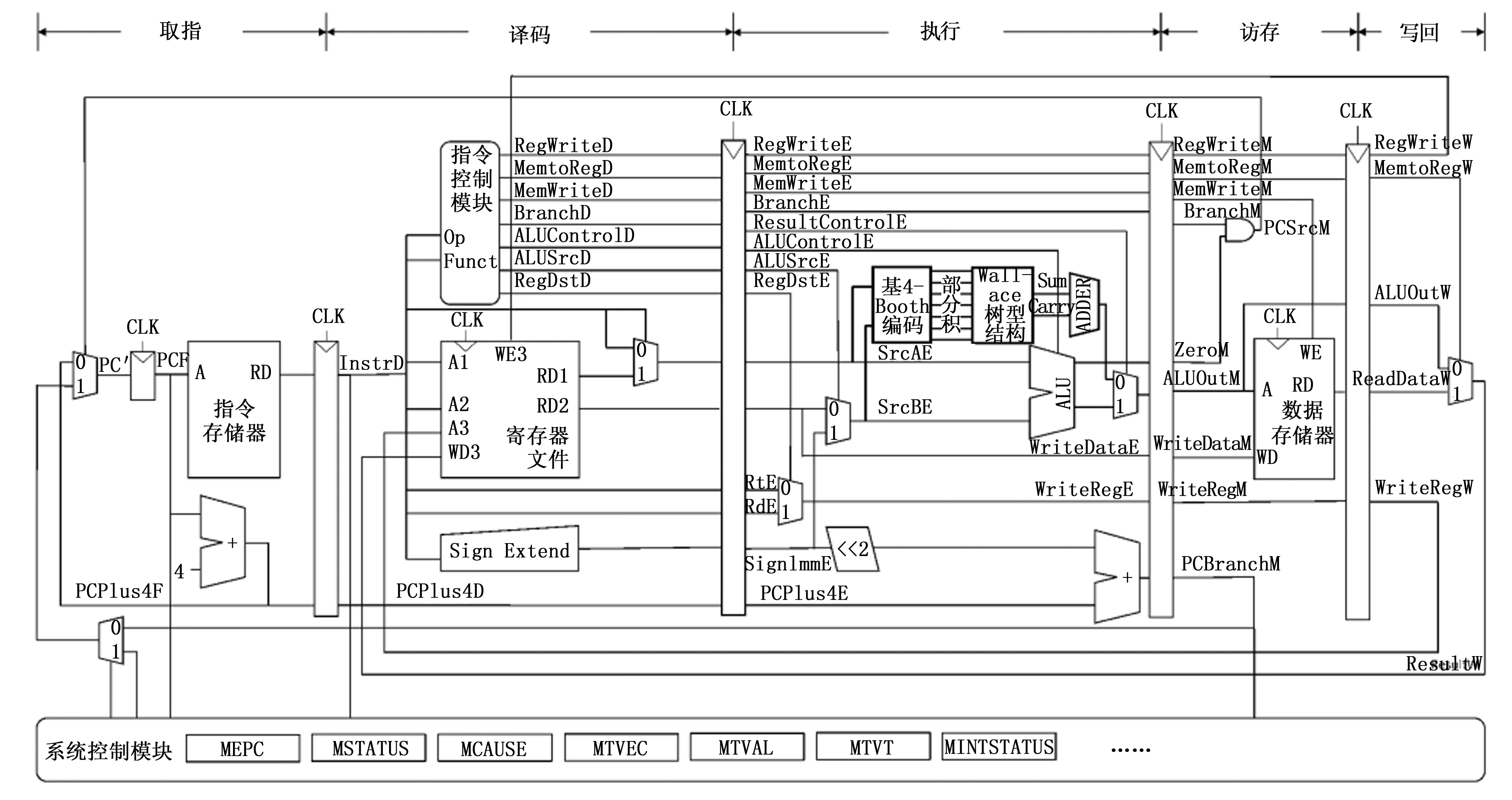
圖3 RISC-V處理器結構圖
Wallace樹型結構提高了累加操作的執行并發性,通過樹型結構提高了硬件壓縮器的復用性,縮短了關鍵路徑的長度,有效地縮短了累加操作的執行時間。
然而傳統Wallace樹型結構由于硬件壓縮器功能簡單,其層次依舊過多,并且對于32位數據計算,其結構不對稱,增加了電路的復雜度,消耗了更多布線資源。不規則的布局布線結構,增大了關鍵路徑的時延。隨著硬件壓縮器的不斷發展,Wallace樹型結構可通過使用高階壓縮器實現進一步優化。而階數過高的壓縮器,例如7-3壓縮器、6-3壓縮器存在電路設計復雜、硬件占用資源多、功耗高以及面積大等問題,因此面對嵌入式領域對低功耗的需求,需要在控制乘法器功耗以及面積的情況下,優化Wallace樹型結構,從而提高乘法器算力。
4 乘法器優化設計
本文設計的乘法器用于單發射順序執行五級流水線RISC-V處理器32×32位有符號整數乘法運算,主要模塊包括:通過改進的基4-Booth編碼產生部分積,通過改進的Wallace樹型結構對部分積進行壓縮。RISC-V處理器結構圖以及乘法器的結構圖如圖3所示。
在處理器五級流水線結構中,乘法器位于執行階段,譯碼模塊從指令中解析出被乘數與乘數,通過改進的基4-Booth編碼產生部分積,部分積陣列通過Wallace樹型結構計算出累加結果和進位兩個數據,最后通過加法器計算出最終結果,通過多選器根據指令功能選取對應的結果位。
本文對基4-Booth編碼進行改進,將補碼計算以及符號位擴展與基4-Booth編碼相結合,減少符號位擴展對壓縮效率的影響。對Wallace樹型結構進行改進,加入4-2壓縮器,使改進的Wallace樹型結構對稱,減少其層次數量,縮短關鍵路徑長度。部分積陣列經過改進后的Wallace樹型結構,產生兩個結果,通過全加器得到乘法計算結果。
4.1 改進的基4-Booth編碼
基4-Booth編碼減少了部分積的數量,其中存在負數部分積,而當部分積為負數時,符號位補齊為1,累加時將產生大量進位以及比特翻轉,增加乘法器功耗。針對該符號位問題,有研究提出了一種有效的符號補償方式[22],有效減少了符號位擴展以及補碼引起的功率消耗。采用符號位直接擴展時,以8位數據snXXXXXXX為例,其中sn表示符號位,將其擴展為16位數據,其結果為sn sn sn sn sn sn sn sn snXXXXXXX。而使用該符號補償方式,可對其進行等價邏輯變換,如式(3)所示:
snsnsnsnsnsnsnsnsnXXXXXXX=
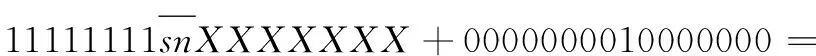
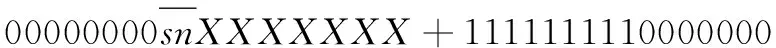
(3)
從式(3)可以得出,由于符號位擴展部分為連續相同的數據,因此根據二進制計算特點,可將符號擴展變換為只與符號位及固定值有關的運算,而固定值可提前根據部分積數量以及位數進行計算,其計算結果可在部分積累加前通過編碼實現。因此本文通過將該符號補償方式、補碼計算與基4-Booth編碼相結合,形成改進后的基4-Booth編碼,擴展方式如圖4所示。
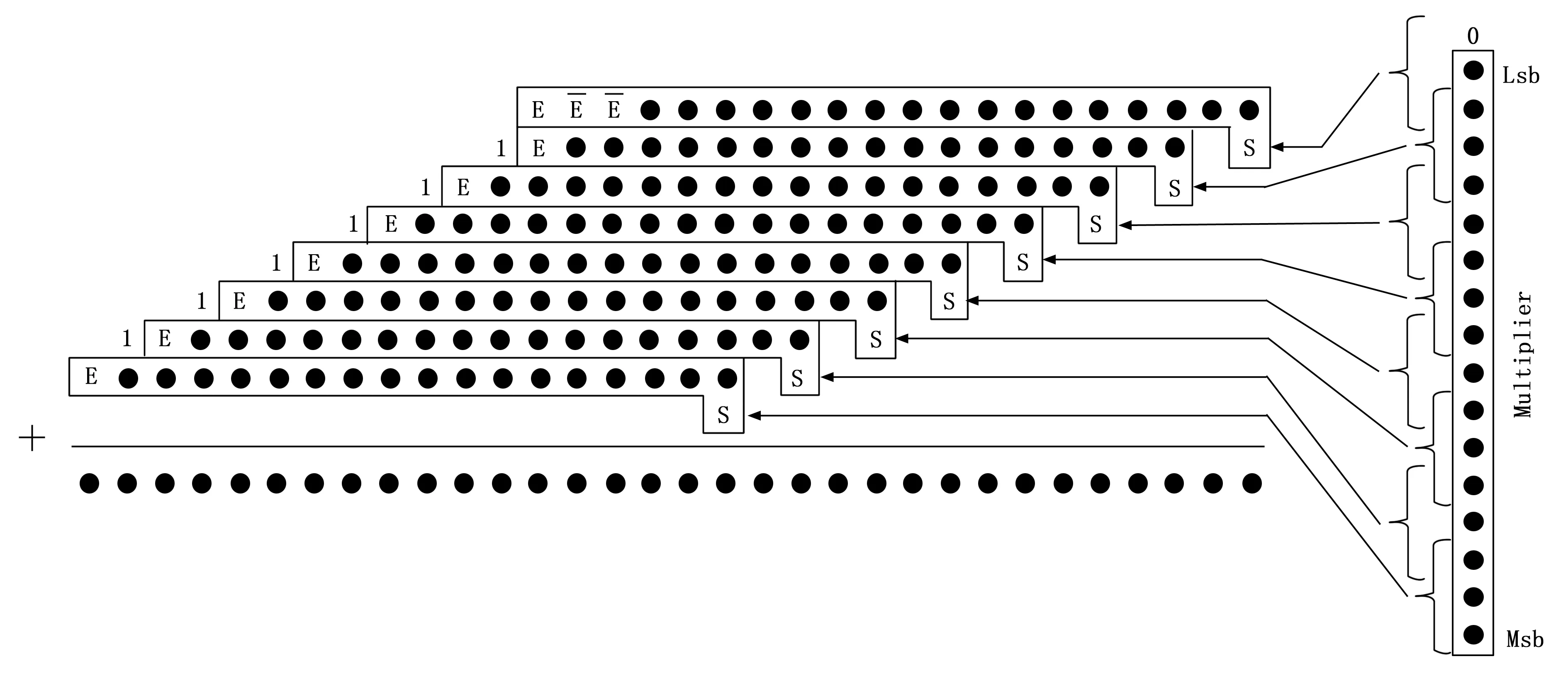
圖4 改進符號擴展圖
本文在基4-Booth編碼的基礎上,加入對符號補償以及補碼的編碼,從而將上述符號補償方式與基4-Booth編碼相結合,減少部分積壓縮的功率消耗。本文采用如表2所示的編碼。
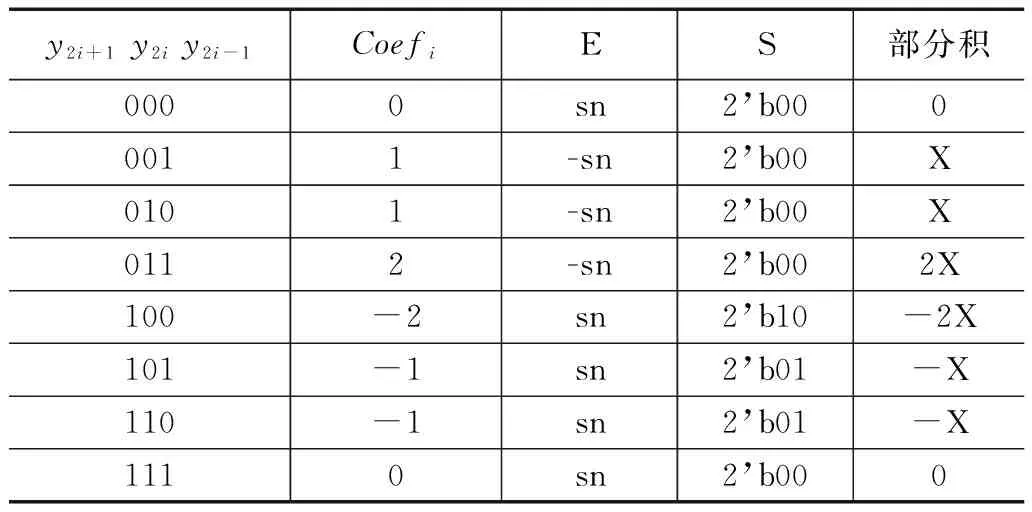
表2 改進的基4-Booth編碼表
表中y2i+1y2iy2i-1代表乘數的第2i+1、2i和2i-1位,對于32位處理器,i的范圍為0到16;Coefi代表第i個部分積系數;E代表乘上系數后的符號位,sn代表被乘數的符號位;S代表補碼加1操作產生的中間值,本級的中間值拼接至下一級部分積,在壓縮過程中實現補碼計算。改進的基4-Booth編碼電路圖如圖5所示。
其中:Y_2i+1、Y_2i和Y_2i-1代表y2i+1y2iy2i-1,即乘數的第2i+1、2i和2i-1位,sign代表Coefi的符號,coef1代表Coefi[1],coef0代表Coefi[0],E代表被乘數符號位的系數,S1代表中間值S[1],S0代表中間值S[0]。
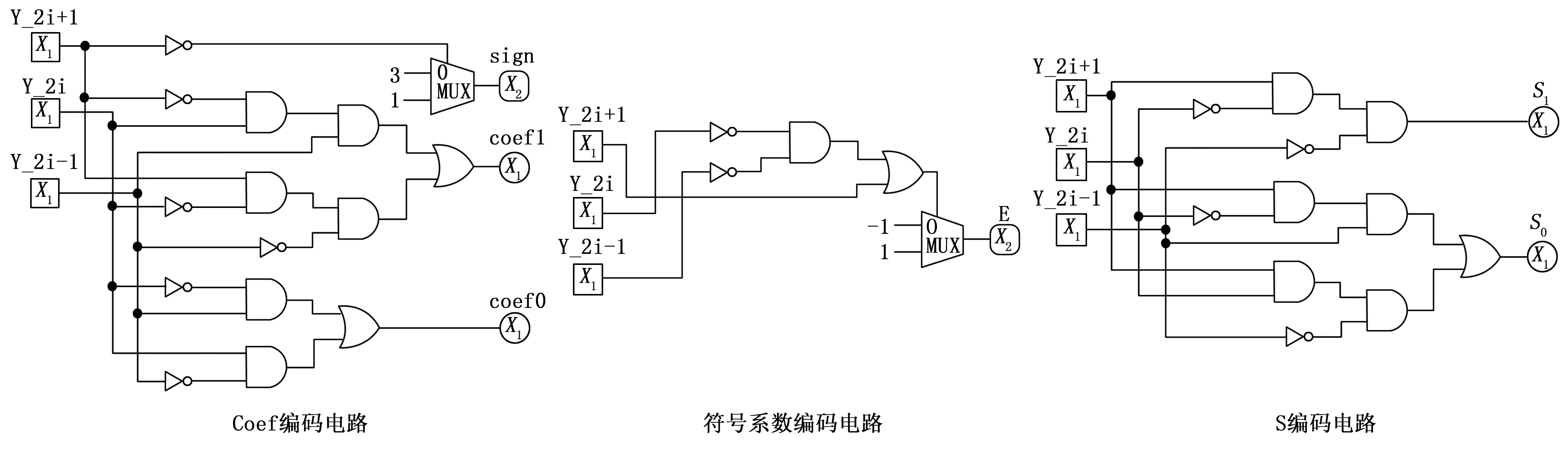
圖5 改進基4-Booth編碼電路圖
從圖5可以看出,改進的Booth編碼通過與門、或門、非門以及二選一多選器實現,經過4個門的時間延遲即可得出編碼結果。
根據Coefi的編碼結果,分別對被乘數進行相應操作。對于系數為負數的部分積,對被乘數進行按位取反,對于系數絕對值為2的部分積,對被乘數進行左移1位操作。將乘以系數的部分積與編碼后的符號位以及中間值進行拼接,形成改進后的部分積,該部分積陣列輸入Wallace樹型結構進行累加計算。
采用基于符號補償的基4-Booth編碼,不需要擴展全部符號位,減少了由于擴展大量連續的1,在加法時造成的進位以及翻轉,降低了乘法器功耗。
4.2 改進的Wallace樹型結構
基礎的Wallace樹型結構采用3-2壓縮器,通過樹型結構有效提高累加操作的并行性,同時從硬件設計角度,增加了加法器的復用性,減少了硬件加法器的數量。為了更好地配合32位處理器的運算需求,在不提高處理器功耗的情況下,盡可能減少Wallace樹型結構的層次,提出了一種交替使用3-2壓縮器與4-2壓縮器的Wallace樹型結構,改進后的Wallace樹型結構示意圖如圖6所示。
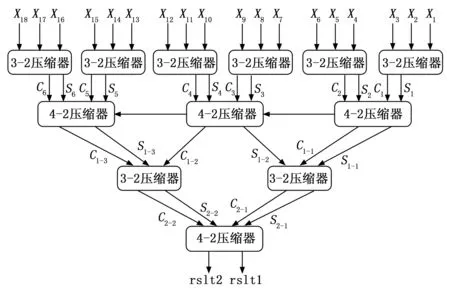
圖6 改進的Wallace樹型結構圖
由于使用符號補償方式,32位操作數將產生17個部分積,因此為了使Wallace樹型結構對稱,將32位乘法運算經過符號擴展,產生18個部分積,18個部分積經過3-2壓縮器產生12個操作數,再經過4-2壓縮器產生6個操作數,6個操作數經過3-2壓縮器產生4個操作數,在經過4-2壓縮器產生最終的2個結果。
其中3-2壓縮器的邏輯表達式如式(4)~(5)所示:
S0=X0⊕X1⊕X2
(4)
C1=X0X1+X0X2+X1X2
(5)
式中,S0為第0個3-2壓縮器的壓縮結果,C1為第0個3-2壓縮器的進位結果,X0、X1和X2為3-2壓縮器的3個輸入操作數。
其1位電路示意圖如圖7所示。
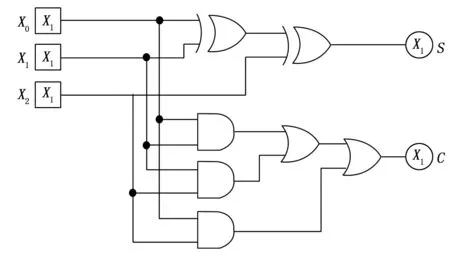
圖7 3-2壓縮器1位電路圖
從圖7可以看出,3-2壓縮器僅使用與門、或門和或非門構成,經過3個門的時間延遲即可得出結果。
4-2壓縮器,又稱5-3計數器,包括5個輸入和3個輸出,輸入和輸出分別包括一個進位。傳統的4-2壓縮器是由兩個串行連接的3-2壓縮器組成,而改進后的4-2壓縮器可以通過異或門和2-1的多選器構成,改進后的4-2壓縮器的邏輯表達式如下所示:
Cout=X0X1+X0X2+X1X2
Xor=X0⊕X1⊕X2⊕X3
S0=Xor⊕Cin
式中,S0為第0個4-2壓縮器的壓縮結果,C1為第0個4-2壓縮器的進位結果,Cout為同級4-2壓縮器的進位結果,X0、X1、X2和X3為4-2壓縮器的4個輸入操作數。
由于Cout的邏輯表達式與Cin無關,所以4-2壓縮器之間雖有信號連接,但不會形成行波進位鏈,4-2壓縮器之間依舊是并行的,其結構示意圖如圖8所示。

圖8 4-2壓縮器結構圖

圖9 乘法指令波形圖
采用3-2壓縮器和4-2壓縮器交替的Wallace樹型結構對稱,減少了布局布線資源,有效減少了樹型結構的層次,縮短了關鍵路徑的長度,壓縮了累加過程的延遲。同時,使用的3-2壓縮器和4-2壓縮器電路簡單,電路最大延時短,未造成處理器功耗以及面積大幅提高。
5 實驗結果與分析
本文的實驗環境如表3所示。

表3 實驗環境表
采用Verilog語言對設計的32位乘法器進行實現,并嵌入到PicoRV32中,通過匯編語言對乘法器進行功能仿真,將結果與Spike仿真結果進行對比驗證乘法器功能的正確性。
圖9為乘法器執行乘法指令的仿真波形,其結果與Spike仿真的結果一致。
從圖9可以看出,通過MUL指令計算32’habcde與32’habcde相乘,其計算結果為32’h4caed084,與預期結果相符。通過如下所示代碼,對其余指令以及邊界值進行驗證。
.global MUL
MUL:
li x3, 0x80000000
li x4, 0x7fffffff
li x10, 0xabcde
mul x5, x0, x3
bne x5, x0, __fail
mul x5, x0, x0
bne x5, x0, __fail
mul x5, x0, x4
bne x5, x0, __fail
mul x5, x4, x4
li x6, 0x1
bne x5, x6, __fail
mul x5, x4, x0
bne x5, x0, __fail
mul x5, x4, x3
li x6, 0x80000000
bne x5, x6, __fail
mul x5, x4, x10
li x6, 0xfff54322
bne x5, x6, __fail
mul x5, x3, x3
li x6, 0x0
bne x5, x6, __fail
mul x5, x3, x0
bne x5, x0, __fail
mul x5, x3, x4
li x6, 0x80000000
bne x6, x5, __fail
mul x5, x3, x10
li x6, 0x0
bne x6, x5, __fail
mul x5, x10, x10
li x6, 0x4caed084
bne x6, x5, __fail
上述代碼對32位操作數的最大正值0x7fffffff、最小負值0x80000000、中間值0xabcde以及0進行乘法計算,通過對乘法器計算結果的判斷,進行程序跳轉,從而測試指令執行結果是否正確。當指令結果正確,即符合預期時,程序順序執行,仿真成功結束。當指令結果不正確時,程序跳轉至__fail,表示程序執行錯誤,仿真錯誤結束。其余3條乘法指令與MUL指令測試程序相同。如圖10所示,測試結果為仿真成功結束,表明指令執行結果正確,即設計的乘法器功能正確。
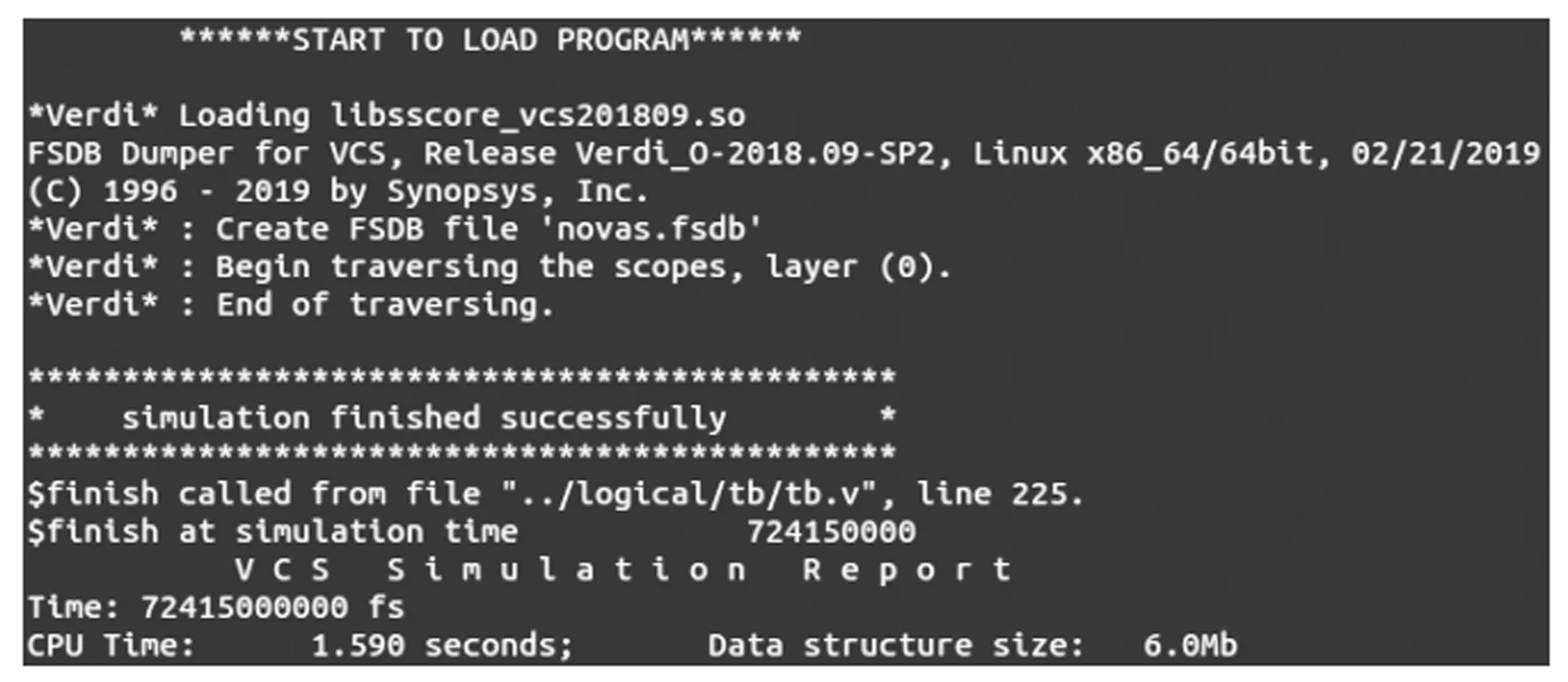
圖10 乘法指令測試結果圖
通過圖9波形圖,本文的乘法器接收到乘法指令,第一個時鐘周期計算累加結果以及進位,第二個時鐘周期兩者相加得出最終結果,因此乘法所需時鐘周期為2個時鐘周期。為了更加直觀地體現本文乘法器的性能,將優化后的乘法器與PicoRV32乘法器以及文獻[16]進行了性能對比,結果如表4所示。

表4 乘法器時鐘周期數對比表
從表4可以看出,與文獻[16]相比,本文的乘法器執行乘法運算花費的時鐘周期數相同。而相較于PicoRV32乘法器,本文改進后的乘法器大幅減少了乘法計算所花費的時鐘周期數,乘法指令執行時間縮短了88.2%,減少了乘法指令的執行延遲,提高了處理器的算力。
本文使用Synopsys公司的Design Compiler軟件,基于smic40nm工藝庫,對乘法器進行了綜合,對其面積進行了評估,結果如表5所示。

表5 乘法器面積對比表
從表5可以看出,由于擴展了基4-Booth編碼以及使用了4-2壓縮器,本文乘法器相較于PicoRV32原乘法器在面積上增加了13.3%。而與文獻[16]乘法器相比,本文乘法器在面積上優于文獻[16],減少了10.6%。從表4可以得出,本文乘法器與文獻[16]乘法器執行乘法指令時鐘周期數相同,因此本文設計優化的乘法器優于文獻[16]。
Dhrystone可對處理器的整型運算性能進行測量。因此本文通過運行測量處理器運算能力的基準程序之一的Dhrystone,在板級對帶有本文乘法器的RISC-V處理器進行了進一步性能與功耗測試,其性能與PicoRV32對比如表6所示。
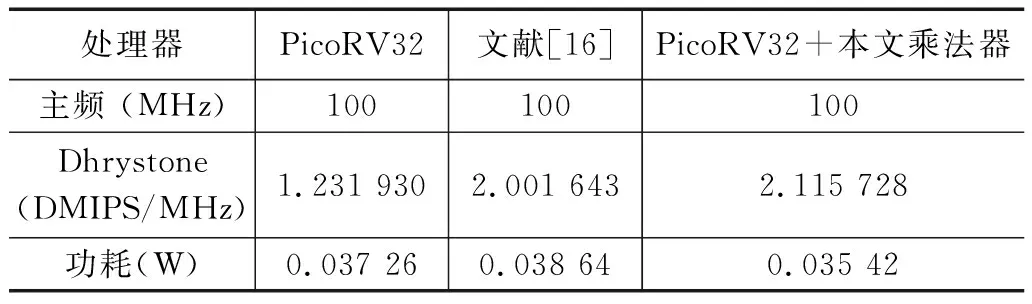
表6 處理器性能對比表
從表6可以看出,與PicoRV32相比,本文設計的乘法器在算力方面提高了71.7%,而處理器算力提高的同時,處理器功耗降低了4.9%。文獻[16]提升了處理器算力,但處理器功耗也有所提高,而本文的乘法器與其相比,算力有所提高,功耗有所降低,提高了處理器的能耗比。
6 結束語
本文通過對RISC-V架構中整數乘法指令的研究以及乘法器的研究,提出了基于符號補償的基4-Booth編碼以及使用3-2壓縮器和4-2壓縮的改進Wallace樹型結構,設計實現了改進后的RISC-V處理器乘法器。通過RISC-V匯編語言對改進后的乘法器進行功能仿真,驗證了其功能正確性。使用Design Compiler軟件對乘法器面積進行了綜合,與處理器原乘法器以及已有工作進行了對比分析。通過板級測試,對處理器算力以及功耗進行了評估,并與原處理器以及已有工作進行了對比分析。結果表明,本文改進的乘法器功能正確,執行整型乘法指令所花費的時鐘周期為2,相較于PicoRV32乘法器,縮短了88.2%。Dhrystone分數為2.115 728 DMIPS/MHz,功耗為0.035 42 W,相較于未改進的PicoRV32,性能提高了71.7%,功耗降低了4.9%,在功耗有少許降低的情況下,大幅提高了處理器性能,提高了處理器計算速度。與已有研究工作相比,本文改進的乘法器在執行乘法指令時鐘周期數相同的情況下,面積與功耗均優于已有工作,適用于嵌入式領域對處理器面積、功耗以及算力有較高需求的應用場景。本文的乘法器確實在縮短整型乘法執行時間方面有一定效果,但在功耗方面優化并不明顯,同時由于增加了符號擴展編碼,乘法器面積有所增加,未來的改進方向為:
1)優化編碼設計,盡可能降低編碼邏輯復雜度;
2)考慮乘法器的低功耗優化。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
哲學評論(2021年2期)2021-08-22 01:53:34
幼兒園(2021年6期)2021-07-28 07:42:14
小學生學習指導(低年級)(2019年11期)2019-11-25 07:31:48
中華詩詞(2019年7期)2019-11-25 01:43:04
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
小學生導刊(2017年13期)2017-06-15 20:29:38
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
天津科技大學學報(2015年4期)2015-04-16 04:55:11
