融合YOLO v3與改進ReXNet的手勢識別方法研究
2023-08-03 02:07:18魏小玉焦良葆劉子恒湯博宇
計算機測量與控制 2023年7期
魏小玉,焦良葆,劉子恒,湯博宇,孟 琳
(南京工程學院 人工智能產業技術研究院,南京 211167)
0 引言
智能駕艙系統可顯著提升汽車用戶體驗感,已成為汽車行業發展的重點之一。手勢識別作為一種重要的人機交互方式,在智能駕艙中得到了廣泛的應用。一般來說,手勢識別常采用接觸式和非接觸式兩種檢測方法。基于傳感器的接觸式手勢檢測,因在智能駕艙等應用場景條件有限的情況下,難以實現以最小的駕艙成本達到同樣基于計算機視覺的手勢檢測效果,而且會給用戶帶來不舒適的駕駛體驗,甚至增加駕駛風險。因此在智能駕艙系統設計中采取基于計算機視覺的非接觸式手勢識別方法,用手部關鍵點定位技術進行手勢約束,實現人機交互更符合應用場景。目前研究手勢識別的主流網絡,根據場景需求不同,算法側重也各有不同。
多數的手勢實時檢測方法,研究方式重點在于直接進行手勢的特征提取。而手勢特征提取方法大多采用神經網絡的方式,Di Wu[1]等人提出了一種用于多模態手勢識別的深度動態神經網絡(DDNN,deep dynamic neural networks),能夠同時進行目標姿勢分割和識別,檢測效果良好。于此,在如何提高手勢檢測的整體效果,文獻[2]中提出了一種采用聚合通道特征(ACF,aggregate channel feature)與雙樹復小波變換(DTCWT,dual-tree complex wavelet transform)的手勢識別算法,以求在不同環境下都能夠保持很好的識別精度。除了從選擇不同算法角度,在圖像處理,函數改進等方面作提升也可以達到相同的結果。KeKe Geng[3]等人提出在紅外圖像中采用改進的YOLO v3(you only look once v3)手勢檢測模型網絡,較傳統可見光下的數據呈現方式,可以更好地擬合人體手部姿態并減少噪聲干擾。LYU Shuo[4]等人則是在改進YOLO v3和方差損失函數(SSE,sum of squared error loss)的基礎上,降低Sigmoid對梯度消失的影響,來提高模型檢測精度。在人體手部姿態的小目標定位分類檢測中,手勢特征關鍵點的提取精度至關重要。文獻[5]中采用支持向量機(SVM,support vector machine)的方式對小目標快速計算并分類。而王婧瑤[6]等人則是提出一種基于蒙版區域的卷積神經網絡(Mask R-CNN,Mask Region-based Convolutional Neural Network),與多項式平滑算法(SG,Savitzky-Golay)的手勢關鍵點提取技術且較WANG Sen-bao[7]等提出的手部21關鍵點檢測模型,進一步對數據進行平滑處理,有效的提升了模型檢測精度。而在不輸深度目標檢測網絡的出色表現且兼具方便嵌入小型終端使用,文獻[8]中提出了構建輕量型的手勢實時檢測分類網絡,相較于文獻[9]在深層網絡增加密集連接層來提高復雜環境下的實時檢測效果,有效的減輕了計算量和參數量的問題。
在側重依賴于快速且實時的基礎上,本文同樣采用了輕量型神經網絡的方式進行手部識別檢測。為進一步提高整體的檢測精度,改進了ReXNet輕量型網絡的網絡架構及損失函數。而在考慮提高后續實驗項目的拓展性與可移植性的問題上,采用先進行人體手部識別再進行關鍵點定位檢測的方式,而非直接訓練手部動作分類。實驗結果表明,輕量型網絡模型訓練不會占用太多資源且改進后的網絡有更高的檢測精度,具有很強的實用性研究意義。
1 YOLO v3手部檢測模型
手部識別部分方法采用YOLO v3作為手部特征提取網絡。YOLO v3在YOLO前兩代的基礎上改進缺點,均衡了目標檢測的速度和精度以及重點解決了小物體檢測的問題。本文選用YOLO v3網絡模型對手部特征bounding box的w、h、x、y以及置信度進行訓練。模型損失函數采用均方差(MSE,mean square error)。
YOLO v3算法:
對于手部特征目標實時檢測的應用要求,處理回歸問題的算法模型YOLO v1,自2016年發表的論文You Only Look Once:Unified,Real-Time Object Detection后,算法也正式發布。與經典目標檢測方法相比,深度神經網絡特征提取能力更強,準確率更高。YOLO系列較CNN模型被稱為One-Stage方法,將先生成候選框與再分類回歸兩步同時進行,以此大大降低了計算復雜度,加快了檢測速度。根據Joseph Redmon等發布的YOLO v3算法,在COCO數據集上較YOLO v2 mAP-50的44.0%提高到57.9%,很好的提升了模型識別準確率。
YOLO v3算法通過卷積層特征提取網絡,對輸入特征提取輸出檢測結果,得到特定大小的特征圖輸出。算法在3種不同下采樣尺度上進行,通道數為3,檢測結果包括bounding box的中心位置xy,寬高wh,置信度。針對人體手部的小目標檢測,在32倍下采樣呈現的小尺度,大視野上,有更好的預測效果。
手部識別模型采用的MSE Loss常用在回歸任務中,根據公式:
(1)
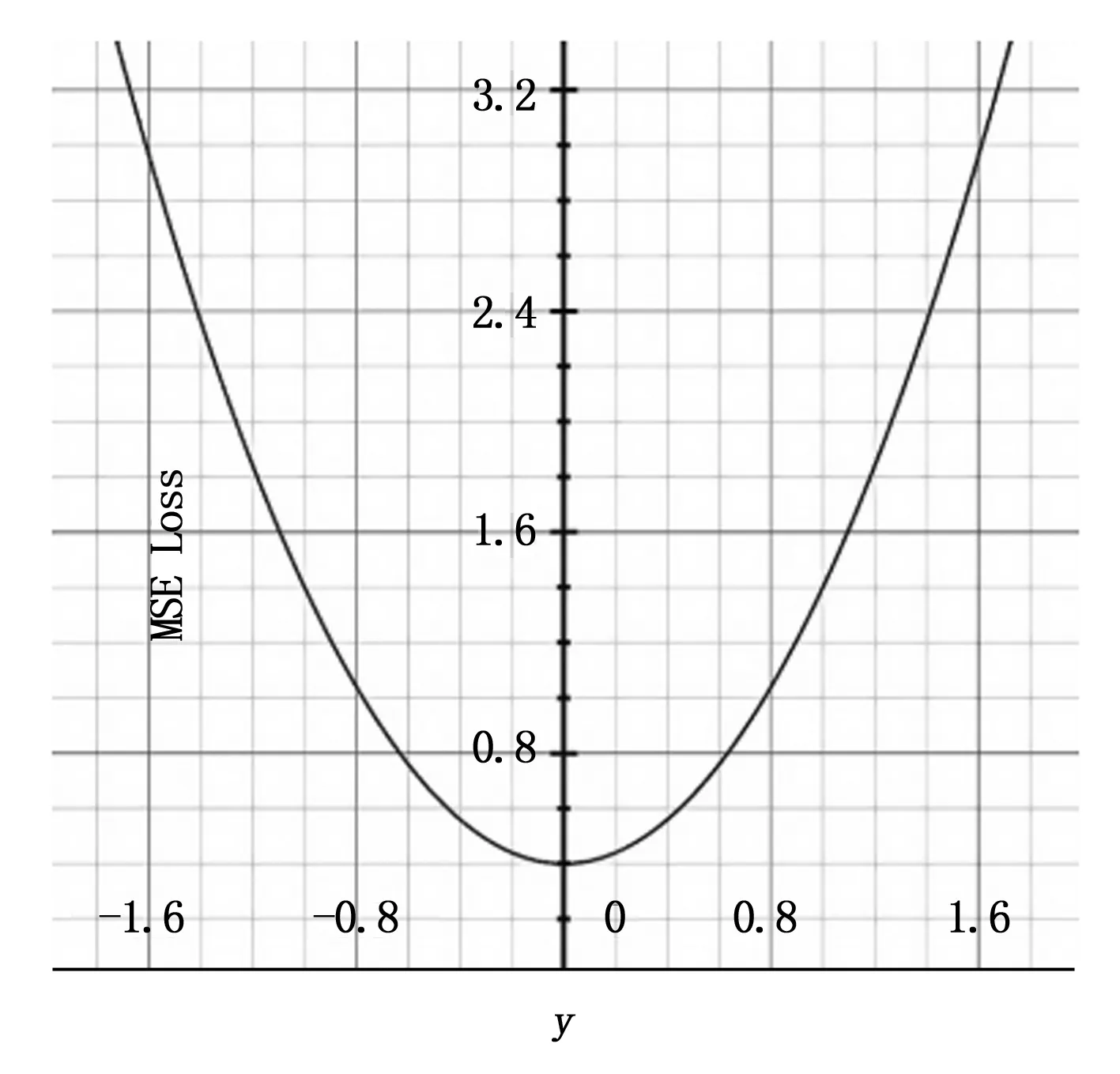
圖1 MSE函數曲線圖
其中,模型誤差包含計算坐標誤差,置信度誤差和分類誤差。置信度公式如下:
(2)
2 改進的ReXNet手部關鍵點檢測模型
手部關鍵點代表的信息本質上不是單個的點的信息,描述的是手部這個固定區域的組合信息,表征不同關鍵點間的確定關系,是對手部物理空間的定位描述。通過點回歸和關系回歸的方式進行手部特征標注。不同于人體大目標檢測手部特征的定位識別,手勢姿態定義類似于人臉特征點檢測和人體姿態估計的骨骼關鍵點檢測,需要在定位出手部關鍵點后通過約束骨骼向量角來定義不同手勢指令。
關鍵點檢測模型采用改進ReXNet網絡結構,改定位損失函數MSE Loss為平滑平均絕對誤差(Huber Loss),并替換ReXNet的卷積層為Ghost Module。在采用輕量型網絡的優點的同時進一步提升ReXNet網絡應用于關鍵點檢測的模型效果。
2.1 ReXNet網絡架構改進
ReXNet網絡的設計初衷是為了解決現有網絡的特征表現瓶頸問題,網絡中間層常出現因對輸入特征的深度壓縮,而導致輸出特征的明顯減少,甚至丟失特征的現象。本文在關鍵點檢測模型上采用改進的ReXNet網絡架構,實現在參數量少的情況下消除表現瓶頸問題,增強21手部骨骼點的局部關注,提升網絡對關鍵點的識別性能及識別準確度。
2.1.1 ReXNet網絡及Ghost Module
ReXNet本身是在MobileNetV2輕量化網絡的基礎上進行改進,以適當的調整有效減輕了現有網絡的特征表現瓶頸問題。其中,倒殘差結構(Inverted Residuals)、線性瓶頸(Linear Bottleneck)以及SENet(Squeeze-and-Excitation Networks)中提出的SE(Squeeze-and-Excitation)模塊三部分是構成輕量化神經網絡MobileNetV2的重要基礎。ReXNet在結合改進的增加網絡通道數,替換激活函數為Swish-1函數以及設計更多擴展層的方式來減輕網絡的特征表現瓶頸問題,形成ReXNet輕量型網絡的基礎模型結構。
ReXNet模型在對數據的處理方式上同大多數CNN模型一樣,在通過優化算法后,提高了對數據的處理能力,加快了計算效率,有效的節約了計算資源。通過提升網絡模塊數據秩的思路,解決盡可能完全提取圖像特征不壓縮的問題,貫穿輕量型神經網絡的設計始終。ReXNet輕量化網絡的一種關鍵構建塊,深度可分離卷積構成的倒殘差結構,其基本思想是通過分解的卷積運算符來替代完整的卷積算子,使用少量的算子及運算達到相同的計算效果。
倒殘差結構能夠有效的避免當常規卷積核的參數出現較多0時,即卷積核沒有起到特征提取網絡的作用,造成特征信息丟失的問題。利用倒殘差結構能夠很好地獲取到更多的特征數據信息,進而提升模型的訓練效果。倒殘差結構在網絡結構上主要采用了先升維的操作,也就是先進行擴展層的擴充,擴展倍數由擴展因子控制,此時升維卷積層的激活函數為ReLU6,主要目的是為了獲取到更多的特征提取信息。接著再進行深度卷積(DW,Depthwise Convolution)的特征提取工作,此時的特征提取卷積層的激活函數為ReLU6。最后進行降維壓縮的卷積處理,激活函數為線性激活函數。整體的網絡結構呈現兩頭小,中間大的形狀。這也是與殘差結構很不同的一點,兩者呈現的是完全相反的結構,因此稱為倒殘差結構。
在倒殘差結構的降維卷積層中使用線性激活函數,為避免采用了常規的ReLU激活函數后,將高維信息映射到低緯空間中,進行空間維度的轉換時造成的信息丟失。而線性激活函數會降低這種信息損失。在倒殘差結構中,從高維映射到低維的縮減通道數,實現卷積降維的網絡結構稱為線性瓶頸。
可分離卷積分為空間可分離卷積和深度可分離卷積。ReXNet網絡的核心卷積層即基于深度可分離卷積。深度可分離卷積將普通卷積拆分為深度卷積和逐點卷積(PW,pointwise convolution)。深度卷積通過對每一個的輸入通道應用單獨的卷積濾波器來執行輕量級濾波,逐點卷積通過對輸入通道的線性組合構建新特征,實現對特征圖的升維和降維。
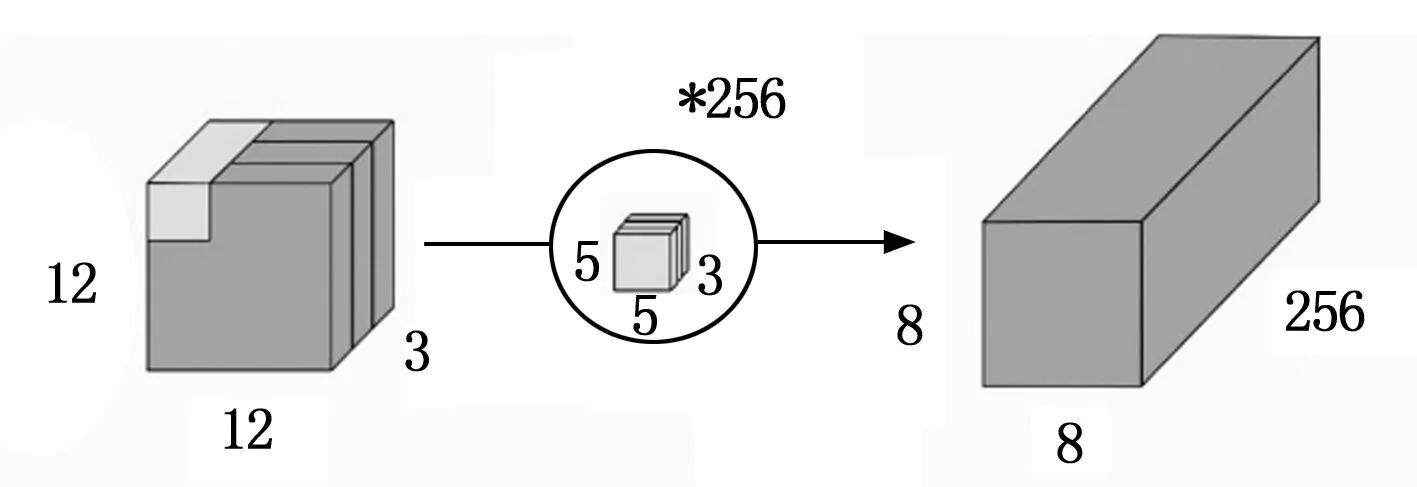
圖2 標準卷積
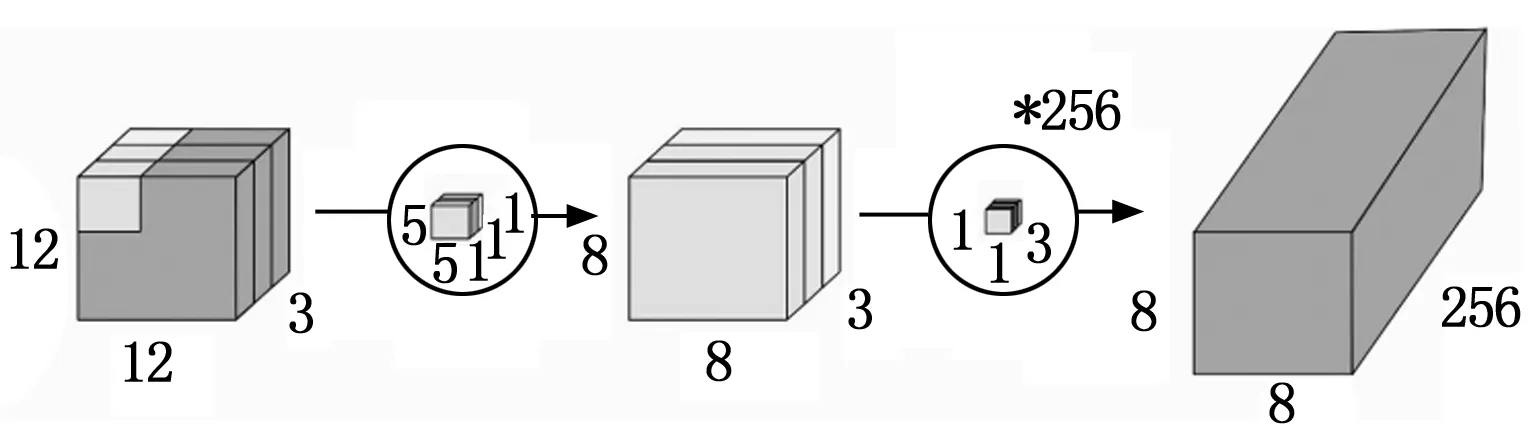
圖3 深度可分離卷積
在ReXNet網絡中間卷積層嵌入SE模塊,以輕微的計算性能損失來提升準確率,在關鍵點檢測模型中有很好的訓練效果。SE模塊作為改進模型注意力機制的常用模塊,其先通過Squeeze操作從每個通道空間的角度進行特征壓縮,再通過Excitation操作為每個特征通道生成獨立權重,最后將每個通道的權重值與原特征圖對應通道進行相乘加權,以此操作達到提升ReXNet網絡通道注意力機制的效果。SE模塊能夠實現從含有大量冗余的信息中獲取所需的重要內容,進而提升模型的整體訓練精度。
Ghost Module的實質是通過減輕模型計算量來進行提升整體的訓練效率。20年華為諾亞方舟實驗室提出的Ghost Net新型神經網絡框架,核心模塊Ghost Module可以移植部署到其他CNN網絡中,實現“即插即用”改進現有網絡,提升實驗效果。Ghost Module操作分為常規卷積過程、Ghost特征圖生成以及恒等映射特征圖的拼接三步,過程如下:
1)先用常規卷積得到本征特征圖;
2)通過φi,jcheap operate操作得到Ghost特征圖,及恒等映射得到本征特征圖;
3)將第二步中的本征特征圖與Ghost特征圖拼接得到輸出結果。
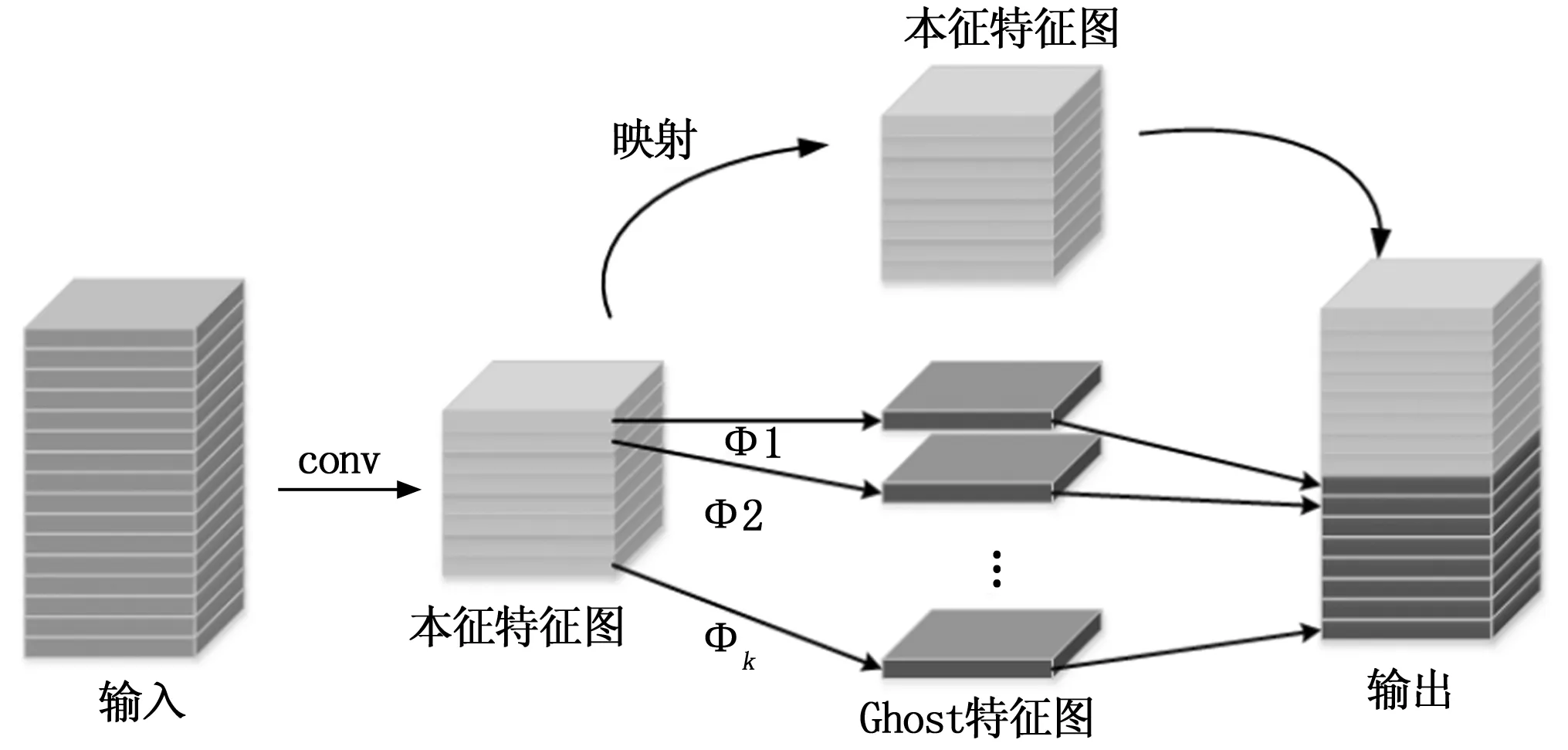
圖4 The Ghost Module
2.1.2 新的ReXNet網絡架構
基于以上,改進操作在結合ReXNet輕量型網絡的模型結構基礎上,在基于減少計算量以及兼具一定的識別準確度的基礎上用Ghost Module模塊對ReXNet進行網絡結構的調整。基于設計的網絡結構的具體實用效果,本文在通過多次實驗改進網絡結構的模型訓練結果下,最后采用替換倒數第二層卷積為Ghost Module。相比較常規卷積,Ghost Module可以大幅度的減小計算量,改進后的網絡結構如圖5所示。
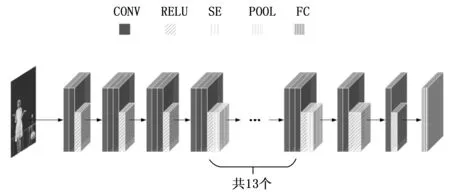
圖5 關鍵點檢測網絡模型結構圖
2.2 損失評價函數改進
在改進ReXNet網絡架構后,模型適配損失函數改MSE Loss為Huber Loss。作為在處理回歸問題中常用的損失函數之一,Huber loss很好的繼承了MSE和MAE的優點,對于離群點抗干擾性強于MSE,Loss下降速度優于MAE,速度接近MSE。在保證模型能夠準確的找到全局最優值的同時還能使其以最快的速度更新模型參數。其中,Huber loss計算公式如下:
(3)
一般采用Lδ(y,f(x))表示,衡量真實值y與預測值f(x)之間的近似程度,一般越小越好。對于Huber loss計算公式中引入的超參數δ,其不同于模型參數,需要在模型訓練中根據數據收斂效果進行認人為調整。當δ趨近于0時,Huber loss會趨近于MAE,當δ趨近于∞時,Huber loss就會趨近于MSE。在實際實驗過程中,因輕量型神經網絡的自身優點,調整優化Huber損失函數參數,提升整體的手部關鍵點檢測精度,并未占用太多時間資源。
3 實驗設計和實驗結果分析
本文以改進ReXNet輕量型網絡,減少模型訓練量提高檢測精度為重點。實驗通過YOLO v3手部檢測與改進的ReXNet手勢關鍵點定位,進而約束手部骨骼點向量角定義的不同手勢后,檢測手勢并判斷,最后達到實時檢測的效果。本文實驗操作流程如圖6所示。
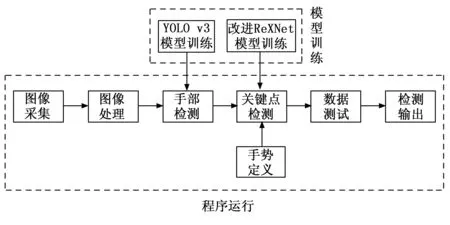
圖6 實驗流程圖
3.1 手部檢測模型訓練
手部識別模型訓練采用TV-Hand以及COCO-Hand的部分數據集,圖像數目為32417。其中,TV-Hand選自ActionThread數據集的部分數據。
ActionThread數據集是由各種電視劇提取的人類動作圖像幀組成,依據其來源于諸多電視劇,采用多角度的攝像機拍攝以及劇集中不同級別的手部遮擋,TV-Hand所用的難易樣本足夠均勻且場景夠多。MS COCO(Microsoft Common Objects in Context)數據集是微軟出資標注的公開數據集,有80個類別超50萬個目標標注,本文采用其中Hand-big部分的數據集并結合TV-hand數據集進行YOLO v3手部識別模型訓練。
模型訓練實驗數據表明,設置epoch為219,學習率為0.001時結果擬合較好。模型保存bounding box的w、h、x、y以及置信度的best loss實驗結果如表1所示。

表1 best loss
如圖7所示,模型訓練各項收斂指標,擬合效果良好。
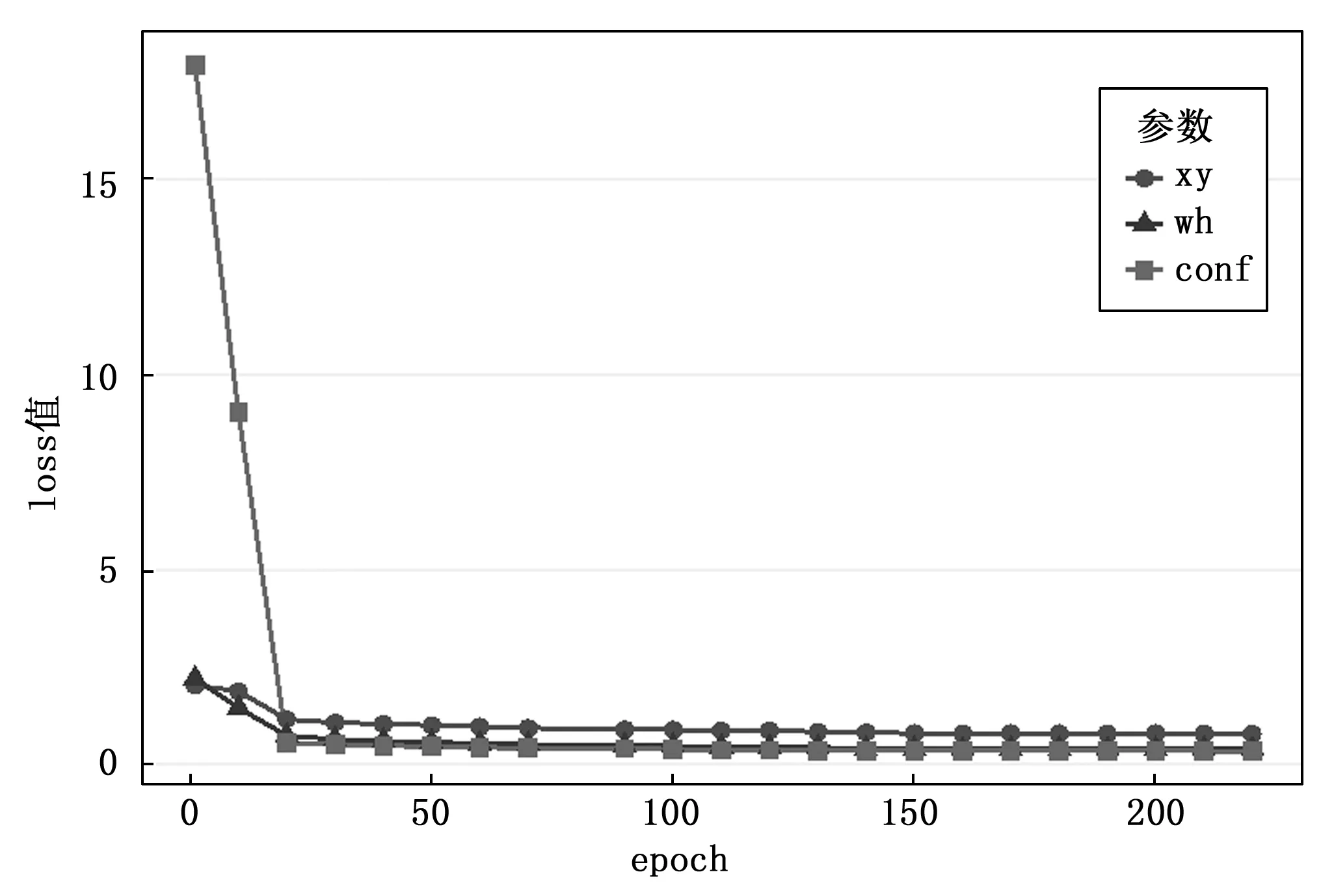
圖7 Loss收斂圖
3.2 關鍵點檢測模型訓練
關鍵點檢測模型訓練采用開源數據集Large-scale Multiview 3D Hand Pose Dataset及部分網絡手部圖片共49 060個數據樣本。樣本原出項目“handpose x”篩選整理部分圖片合集。實驗針對改進前后的網絡模型,比較了訓練參數的變化。
在統計訓練日志loss值,繪制收斂對比圖后,從圖7可以清晰的看出,模型改進前后都具有很好的擬合結果。但較改進前的模型來說,優化后的模型實驗效果更好。對比兩次訓練控制變量,設置epoch為100,學習率為0.001,batch size為10,參數一致。兩輪模型訓練結束保存最優loss結果如表2所示。
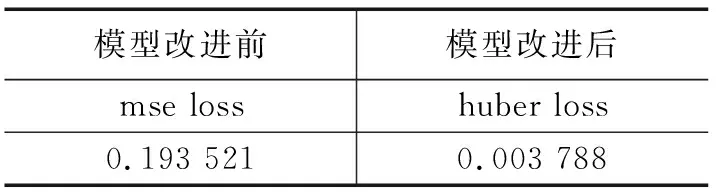
表2 最優loss對比表
如圖8所示,對比改進前后關鍵點檢測模型Loss收斂圖可知,關鍵點損失值整體減小,擬合效果更好。
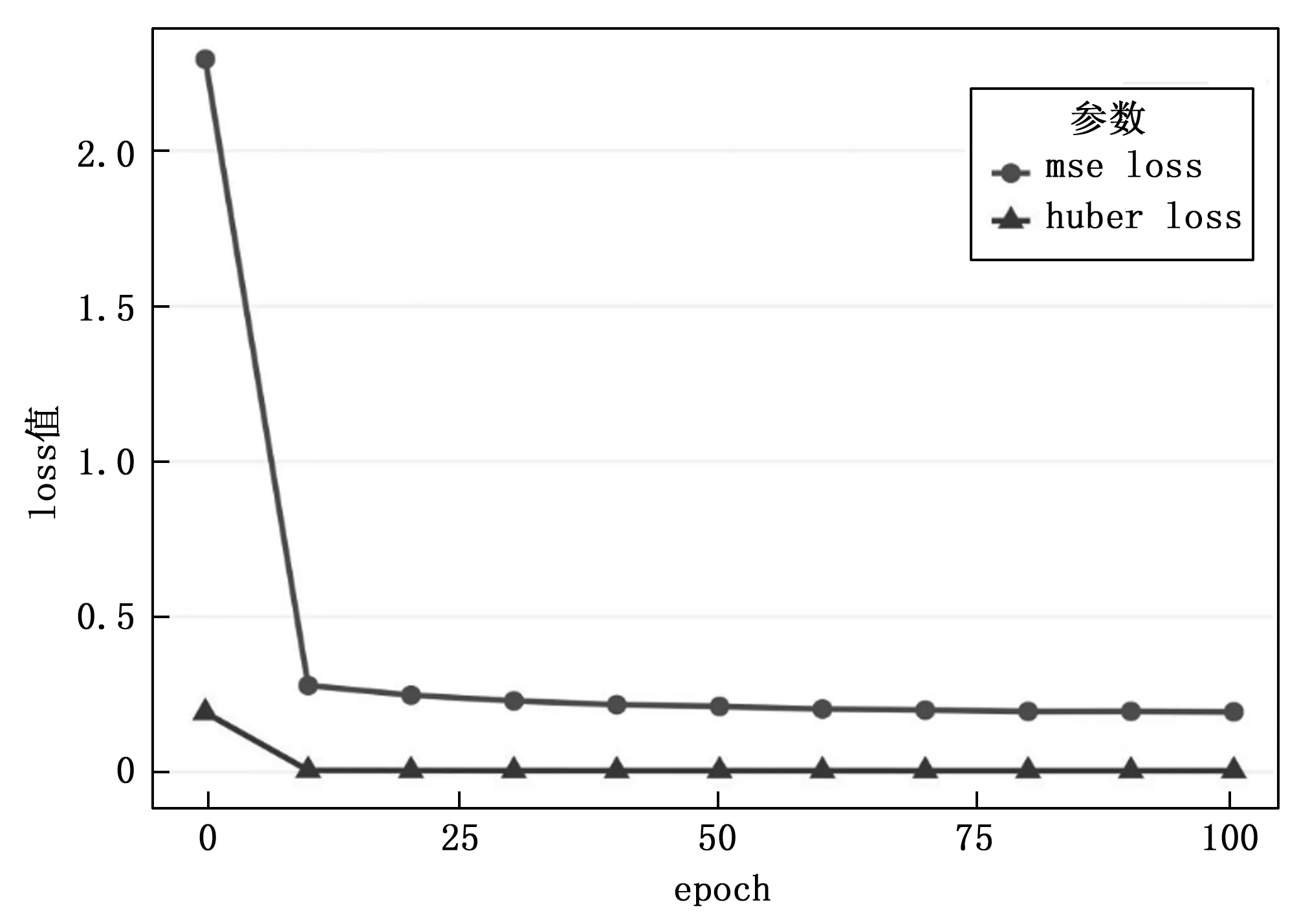
圖8 Loss收斂對比圖
3.3 手勢定義
手勢定義在基于對手部21關鍵點進行檢測確定位置后,將同一順序批次的關鍵點進行連線,標出表示當前手指。最后通過約束骨骼點間連線的二維角度定義不同手勢。
手勢骨骼點向量角度約束如圖9所示,根據設定手指的上下關節夾角經驗閾值,判斷手指的彎曲程度,并定義此時手指為伸直或彎曲。約束不同手指的角度定義手勢,原理簡單,便于操作實現。

圖9 角度約束
本實驗通過角度約束,共定義了5個手勢,分別為one,two,three,four,five,每種手勢由5個手指彎曲角度組合定義。出于實驗驗證角度考慮,實驗手勢含義,由手指固定姿態確定。表3中數值范圍為手指彎曲角度范圍。
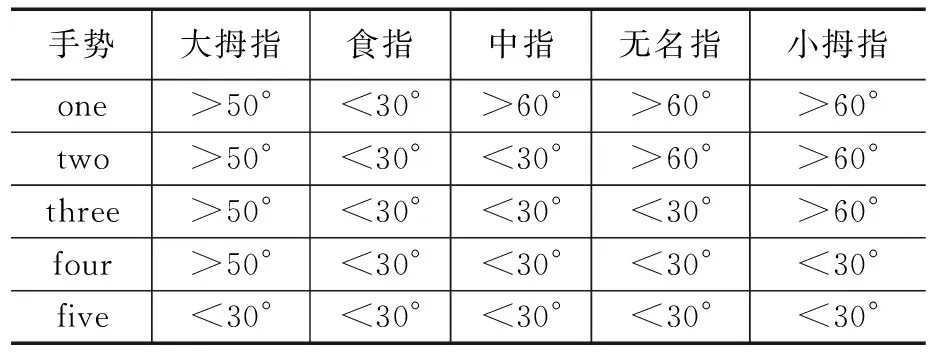
表3 手勢定義
3.4 實驗硬件平臺及數據集設計
實驗使用一塊英偉達GeForce RTX 3090的顯卡服務器,顯存為24 GB,操作系統為32位Linux 5.4,環境搭建Pytorch1.11.0,Python3.7,opencv-python。改進前后的手勢識別方法的測試樣本均為RWTH(RWTH-PHOENIX-Weather multi-signer 2014)公開數據集的2 850張測試樣本。RWTH數據集是一個針對手語識別的數據集,包含各種手勢姿態,應用場景豐富。實驗檢測5種手勢識別具體姿態如圖10所示。
3.5 實驗結果及其分析
用測試樣本分別對改進前后的手勢識別方法進行測試,改進后的手勢識別方法在模型訓練及準確度方面都有很大提升,訓練識別率均可達100%。根據定義的5種不同手勢,采用2 850張測試樣本進行測試,測試識別率對比結果如表4所示。5種手勢的平均識別準確率由改進前的93.56%提升至96.18%,整體識別準確率提升了2.62%。實驗改進使得手勢“two”,“three”識別準確率低于其他手勢,主要原因在于測試樣本的個人生活習慣不一致。大拇指與無名指和小拇指的擺放位置,與約束條件不匹配導致,存在相互誤判,手勢“two”誤判為“three”,手勢“three”誤判為“two”。手勢“one”,“four”,“five”在日常使用中通常較為規范,展示角度范圍幅度不大,鏡頭識別誤判率較低。
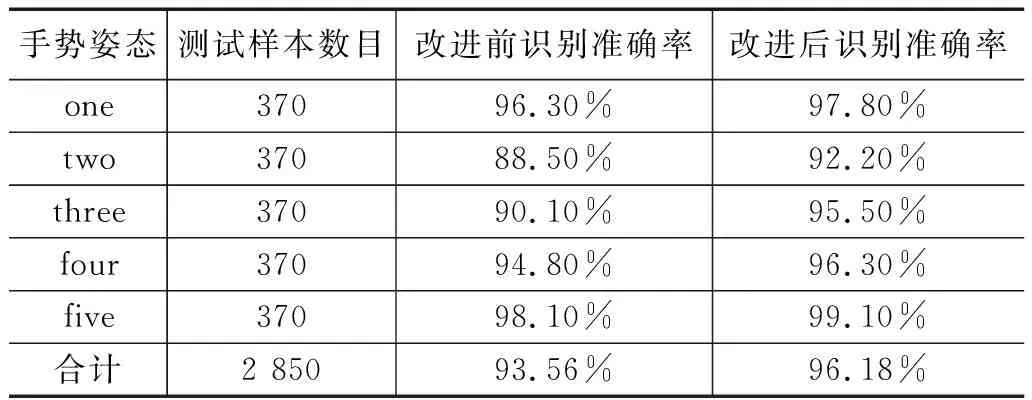
表4 測試集識別準確率對比
4 程序運行
實驗運行程序調用OpenCV函數庫,數據讀入可使用本地圖片,視頻或采用硬件攝像頭實時信息抓取。在經過手部識別模型檢測圖片,bounding box標注手部特征并進行1.1倍外擴,盡可能保證手部信息全在標定框內后,在進行圖片分割。進而在改進手部關鍵點模型進行檢測后,通過判斷是否滿足手勢約束條件,顯示設定手勢,否則不顯示既定手勢。最后輸出分類結果,檢測畫面還原鏡頭捕獲比例,顯示實時檢測畫面。
以外置攝像頭檢測為例,如圖10所示,判斷顯示檢測約定的5種手勢。準確度高。
5 結束語
輕量型神經網絡常被用于移動端或者嵌入式設備中。本文在應用于智能駕艙的人機交互手勢識別中,提出了一種基于改進輕量型神經網絡的手勢識別方法。基于YOLO v3與改進ReXNet為基礎框架,融合Ghost Module模塊,有效的提高了手勢識別效果,在測試樣本的識別結果中表現良好,測試整體精度可達96.18%。雖然有兩個手勢的識別準確率相較其他手勢略低,但在實時檢測中,不甚有太大影響,且改進后的算法對識別精度有很大提升,模型訓練不會占用太多資源,這也是輕量型神經網絡的優點之一。綜上總結,本文改進的手勢識別方法,可以實現高精度的手勢實時交互檢測,在智能駕艙等應用場景中,都能夠得到很好的發展,有很強的現實工程意義。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國衛生(2014年2期)2014-11-12 13:00:16
