基于SE_ResNeXt-50 的小麥不完善粒分類研究
2023-08-07 09:20:44熊浩添王鵬博劉亞孰蔣玉英
科技創新與應用 2023年22期
熊浩添,王鵬博,劉亞孰,蔣玉英*,王 飛,高 輝
(1.河南工業大學 人工智能與大數據學院,鄭州 450001;2.河南工業大學 信息科學與工程學院,鄭州 450001)
糧食安全是國家安全的戰略基礎,事關全面建成社會主義現代化強國[1],小麥作為我國最重要的農作物之一,保障小麥栽培質量和安全儲藏為我國糧食安全和社會穩定起到了關鍵的作用。其中,小麥不完善粒是指已受損傷但仍有使用價值的小麥粒,包括破損粒、蟲蝕粒、病斑粒(赤霉粒和黑胚粒)、發芽粒和霉變粒等。不完善顆粒的含量是對小麥種子定級及對儲藏小麥定質的關鍵指標。目前小麥質量檢測工作普遍是由專業質檢人員使用目測法[2]或使用小麥色選機[3]等傳統方式進行,傳統的分類檢測方法主觀性強、工作量大、效率低且人力成本較高[4]。因此,實現小麥不完善粒的快速、精準、無損檢測是我國亟待解決的問題。
近年來,國內外研究學者對小麥不完善識別展開了大量的研究。張玉榮等[5]采用Python-OpenCV 圖像處理技術對小麥不完善粒識別研究。于重重等[6]采用CNN 神經網絡,利用高光譜成像技術建立CNN 模型,實現了小麥不完善粒的檢測;曹婷翠等[7]提出一種基于LeNet-5 構建神經網絡的雙面圖像進行識別,準確率達到90%以上。陳文根[8]構建了一種五層卷積的神經網絡深層次挖掘9種不同小麥的信息,準確率達到94%。Saeed 等[9]采用人工神經網絡(ANN)和粒子群優化(PSO)算法相結合的方式對視頻進行處理,實現對小麥粒雜質的識別,準確率達到97%以上。Barbedo 等[10]研究了使用近紅外(NIR)高光譜成像(HSI)檢測小麥籽粒中的芽害,證實了近紅外光譜范圍對檢測小麥籽粒化學變化的有用性。但是這些方法沒有很好地挖掘小麥的不完善粒的深層次特征,檢測精度和檢測目標的多樣性有待提高。
本文以小麥單籽粒為研究對象,通過結合圖像處理技術和SE_ResNeXt-50 網絡的深度學習模型,實現小麥病斑粒、蟲蝕粒、發霉粒的快速、無損、精準檢測與分析,在提升小麥不完善粒分類檢測精度的同時兼顧后期系統成品實用性和可行性,在提升生產工作效率同時,大幅降低了小麥粒在分類篩選階段的損耗率,降低生產成本。
1 材料與實驗設備
1.1 樣本準備
小麥不完善粒樣品的培養和數據采集均在河南工業大學糧食信息處理和控制教育部重點實驗室完成。其中,小麥完善粒樣本是在河南興隆國家糧食儲備庫自行購買。將一部分完善粒樣本按照GB 1351—2008《小麥》國家標準培養了病斑粒、蟲蝕粒、發霉粒等3 類不完善粒。蟲蝕粒:將完整的小麥粒放入有玉米象蟲的培養皿中;發霉、病斑粒:在特定濕度和溫度下的培養箱中培育而成。
1.2 圖像數據采集系統
實驗采用河南工業大學糧食信息處理和控制教育部重點實驗室糧食信息智能技術及系統團隊的圖像數據采集系統。該圖像數據采集系統由海康威視高清工業相機、MVS 多視圖密集重建算法、小型電磁振動臺、密胺材質黑色托盤構成,數據采集系統及拍攝設備如圖1 所示,系統具體參數見參考文獻[11]。

圖1 數據采集系統
1.3 開發環境
開發環境由硬件環境和實驗平臺2 部分組成。
硬件環境:處理器為AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz,圖像處理器為NVIDIA GeForce GTX 1660ti。
實驗平臺:Windows 10 操作系統上的飛槳Paddlep-Paddle 1.8.0 深度學習框架,運行環境為GPU Tesla V100 Video Mem 32GB,python 3.7。
2 圖像采集與預處理
2.1 圖像采集
圖像采集時,使用MV-CE100-30GC 工業相機,結合電磁振動臺,頻率50 Hz,垂直振動,促使麥粒均勻分布,同時采用不反光密胺材質的黑色托盤,增加小麥籽粒與背景的對比度,避免因背景在拍攝過程中對小麥圖像造成干擾,結合配套的MVS 多視圖密集重建算法來獲取小麥圖像。同時,為解決小麥籽粒上下重疊或邊緣粘連等問題,將黑色托盤做了改進,在托盤的固定位置留出數個小麥籽粒大小小坑,通過結合托盤下的電磁振動臺,可以使小麥粒均勻分布,利于采集到的小麥圖像清晰、有效。使用MVS 獲取小麥圖像如圖2 所示,小麥單籽粒形態、顏色、輪廓等特征信息完整、清晰呈現。
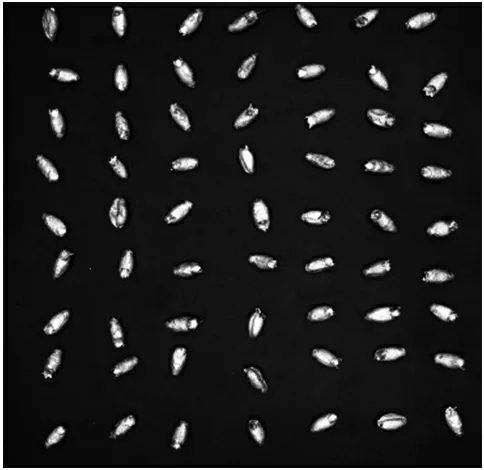
圖2 小麥原始圖像
2.2 圖像預處理
為了便于深度學習網絡對小麥不完善粒特征提取,將MVS 獲取到的小麥不完善粒原始圖像進行分割。根據黑色托盤上固定的放置小麥籽粒的點位,使用Python 坐標分割的方法將大圖分割為小麥單籽粒圖像。數據清洗時,使用圖像降噪法、插值法對不可信的圖片數據以及缺失值和異常值進行處理,增強樣本的區分度,提升模型精度。為增加樣本數據量,采用線下圖像擴充和實時擴充的概率圖像增強操作,模型訓練前對數據樣本進行強制縮放圖片(通過PIL 圖像庫中resize 方法),增加隨機旋轉角度(取numpy 庫中randint 方法范圍在-14~15,再放入PIL 庫中rotate 方法),調整亮度、對比度、飽和度、色度等處理,得到由1 800 張圖片組成的小麥不完善粒數據集。數據集共計4類,分別為完善粒、病斑粒、蟲蝕粒、發霉粒,見表1。隨機抽取每類小麥粒中的90%的小麥單籽粒圖片作為訓練集,其余10%的圖片為測試集,即訓練集為1 620 張小麥單籽粒圖像,測試集為180 張小麥單籽粒圖像。

表1 小麥不完善粒數據集 張
3 分類方法
3.1 殘差網絡
為了解決當卷積網絡到達一定深度時就會出現訓練錯誤不降反增的問題,本文引入了殘差網絡。殘差學習是殘差網絡的方式方法,其由數個stack layers 組成的擬合底層映射稱為H(x),x 表示第一層的輸入信息。通過實驗發現有多個非線性層可以逼近復雜函數(1)并逐漸接近殘差函數(3)。因此,期望讓stack layers 近似趨向于殘差函數而不是H(x)。
基于殘差學習的概念函數,殘差網絡是在普通網絡的基礎上插入了一個快捷連接,當維度增加時,可以直接使用身份快捷鍵公式(1),為增加維度填充額外的零項且并不引入額外的參數,從而達到修正升維降維的錯誤。殘差網絡由一系列殘差塊組成,一個殘差塊可以用公式表示為(1),網絡的一層通常可以看做(2),而殘差網絡的殘差塊也可以表示為(3)
在單位映射中,公式(4)便是觀測值,而H(x)是預測值,F(x)便對應著殘差。
3.2 分組卷積
3.2.1 分組卷積的流程
分組卷積稀疏卷積的一個特殊用法。實驗的訓練環節中包括2 個階段:第一階段是壓縮階段,先通過稀疏性誘導的正則化重復訓練網絡進行固定次數的迭代,再通過剪枝權值較低的不必要濾波器。第二階段是優化階段,通過對濾波器效果擇優,對其進行分組固定處理。在實驗過程中,要確保被剪枝的過濾器來自同一個分組并且共享相同的稀疏模式。
3.2.2 正則化器的選擇
為了減少權重剪枝對精度的負面效果,實驗引入組級稀疏性,在同組下的卷積濾波器使用相同的輸入特征子集來進行凝聚[12]。在實驗訓練過程中使用Group-Lasso正則化方法將FG 列的所有元素推到零,平方根中的項被該列中最大的元素所控制,從而產生了所要達到的組級稀疏性[13]。以下為Group-Lasso 正則化器
3.2.3 冷凝因子及過程
訓練后,去除修剪后的權值,并將稀疏模型轉換成具有規則連接模式的網絡,可有效提高設備的計算能力,因此,引入一個索引層來實現特性選擇和重排操作。索引層輸出中的卷積濾波器被重新安排,以適應常規組卷積的現有(和高度優化的)實現。在訓練過程中,1×1 卷積是一個學習的群卷積(L-CONV),而在測試過程中,在索引層的幫助下,則變成了一個標準的群卷積(G-CONV)。
3.3 Squeeze-and-Excitation
Squeeze-and-Excitation 是一個計算結構模塊,其可以嵌入到X∈RH’×W’×C’映射到特征映射U∈RH×W×C的卷積操作中。設Ftr為一個卷積操作,并用V=[v1,v2,...,vC]來表示學習到的濾波器核集合,其中vC指的是第C 個濾波器的參數[14]。然后可以將輸出寫為U=[u1,u2,...,uC]
運用到ResNeXt-50 網絡中,通過顯著改變信道的相互依賴關系來增強卷積特征學習,從而提高網絡對信息特征的敏感度。Squeeze-and-Excitation 模塊可以為網絡提供全局信息的訪問,通過Squeeze(擠壓)和Excitation(激勵)2 個步驟重新校準濾波器響應。SE_ResNeXt-50 模塊如圖3 所示。
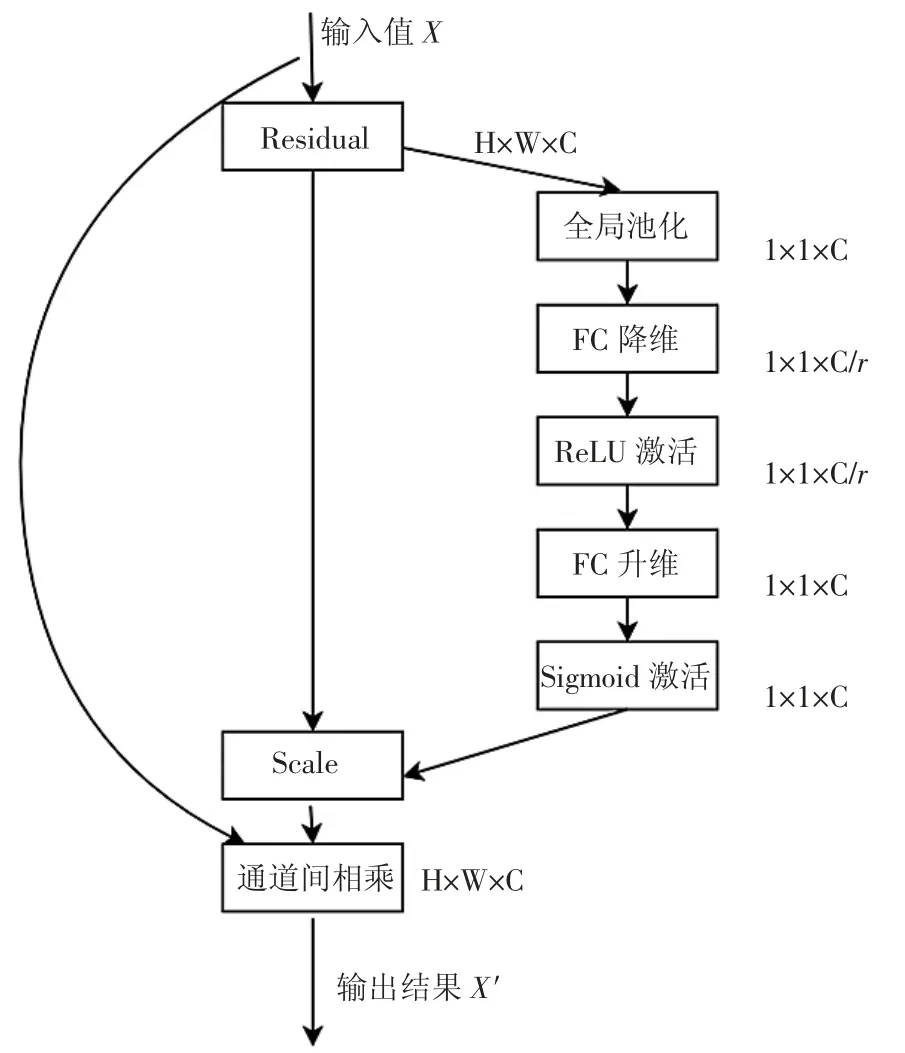
圖3 SE_ResNeXt-50 模塊
3.3.1 Squeeze——全局信息嵌入
Squeeze 通過使用全局平均池生成的基于信道的統計信息將全局空間信息壓縮到信道描述符中,進而解決不同特征信道間存在不同的局部特征學習域的問題,提升網絡對不同信息特征權重的感知。Z∈RC是通過將輸出U 縮小到空間維H×W。即通過Squeeze 操作,將輸入量H×W×C,壓縮為1×1×C 的結果輸出。Z 的第C 個元素可以通過以下方法計算
3.3.2 Excitation——自適應重新校準
為了充分利用Squeeze 操作中聚合的全局信息,在后續進行Excitation 操作。在自適應重新校準階段,Excitation 模塊能夠學習通道間的非線性相互作用和非互斥關系,使多個通道被強調,即通過此過程學習網絡中各支路的權重,將各個通道進行打分,作用到原輸入網絡信息中。非線性激活函數如下所示
式中:δ 指ReLU 函數。為了減低模型復雜度的同時更好的提升模型的泛化能力,首先通過一個降維比為R 的FC降維層做通道壓縮,提高了模型的計算效率,然后通過ReLU 函數,之后在FC 升維層中將之前壓縮的通道升維,最后通過Sigmoid 函數得到輸出結果s,再將輸出結果與原始輸入進行通道相乘后得到經過Squeeze-and-Excitation 模塊處理后的模型通道信息
4 結果與分析
4.1 優化器選擇
為了獲取模型訓練和模型輸出的網絡參數的最優解,本文選用的優化器為自適應矩估計(Adam)。郝天軒等[15]實驗表明,不同的優化器也對模型的優劣有著巨大的影響。在大量的數據測試下,Adam 優化器呈現的效果最佳且Loss 下降速度最快,其繼承了RMSprop 優化器的優點,而RMSprop 優化器繼承了Momentum 優化器的優點,Monmentum 優化器在優化方面增加了動量原則故其也是SGD 的升級版,SGD 則是最原始效果最普通的加速器。各個優化器的對比圖如圖4 所示(其中Loss 表示誤差),所以在大量數據驗證后,發現Adam 優化器是最適合SE_ResNeXt-50 的小麥不完善粒分類模型的優化器。
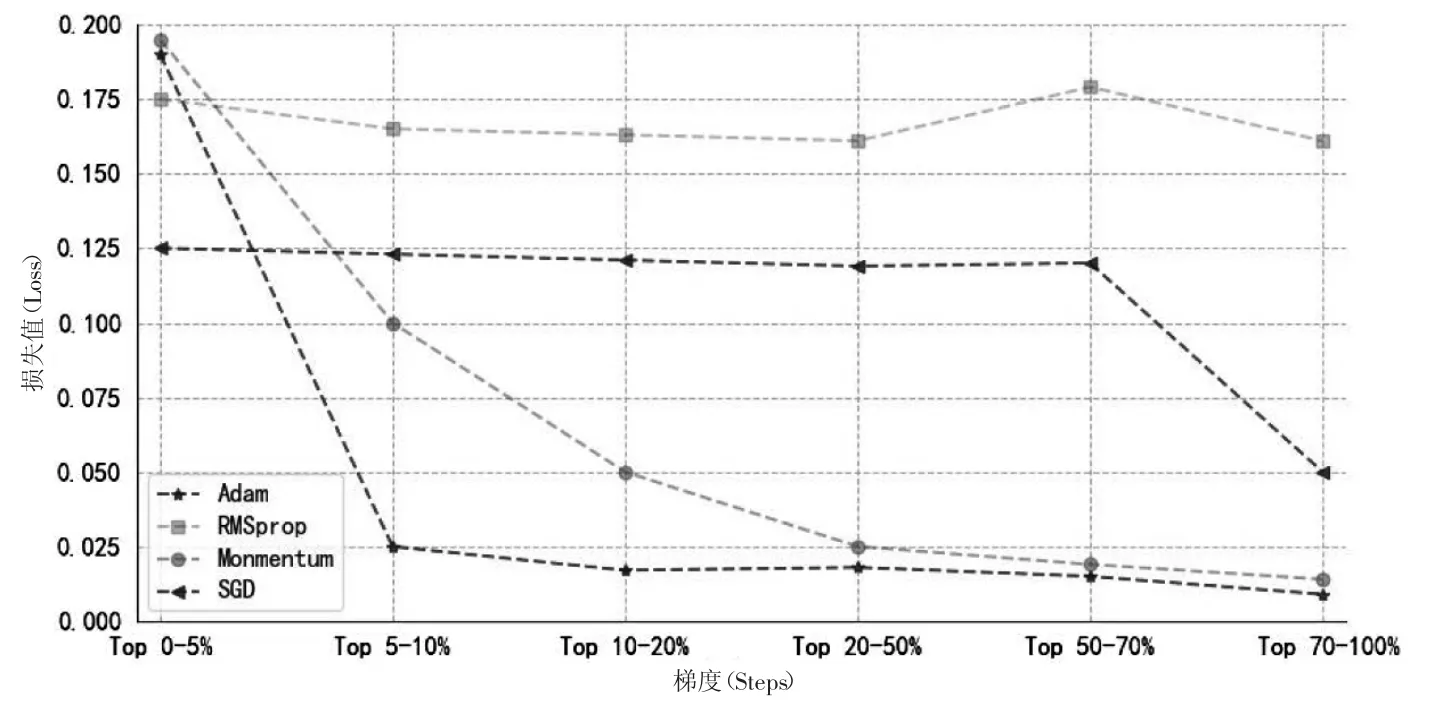
圖4 優化器對比
4.2 模型驗證
為驗證模型的實用性,在得到模型的基礎網絡結構后,使用SE_ResNeXt50 網絡框架訓練模型[16]。按90%和10%的比例將數據集分為訓練集和測試集,經過多次迭代訓練后通過測試集對模型精度進行測試,根據返還的測試結果不斷調整梯度下降算法的超參數(Epoch 和Batch_size)、不斷優化數據集、選用合適的優化器。通過對Epoch 和Batch_size 的調整,可以控制模型內部參數更新之前控制的樣本數量和訓練全部數據集的次數,選擇合適的梯度下降算法的超參數(Epoch 為15,Batch_size 為20),可以讓梯度下降達到最優收斂;通過對數據集總量的調整同時結合提前終止訓練、正則化、剪枝等策略,簡化模型的深度,避免過擬合的發生。同時,最大限度地提高模型的測試精度;通過選取合適的優化器,使影響模型訓練和模型輸出的網絡參數逼近或達到最優值,從而最小化損失函數。最終模型平均測試精度達到95%以上,測試結果如圖5 所示。
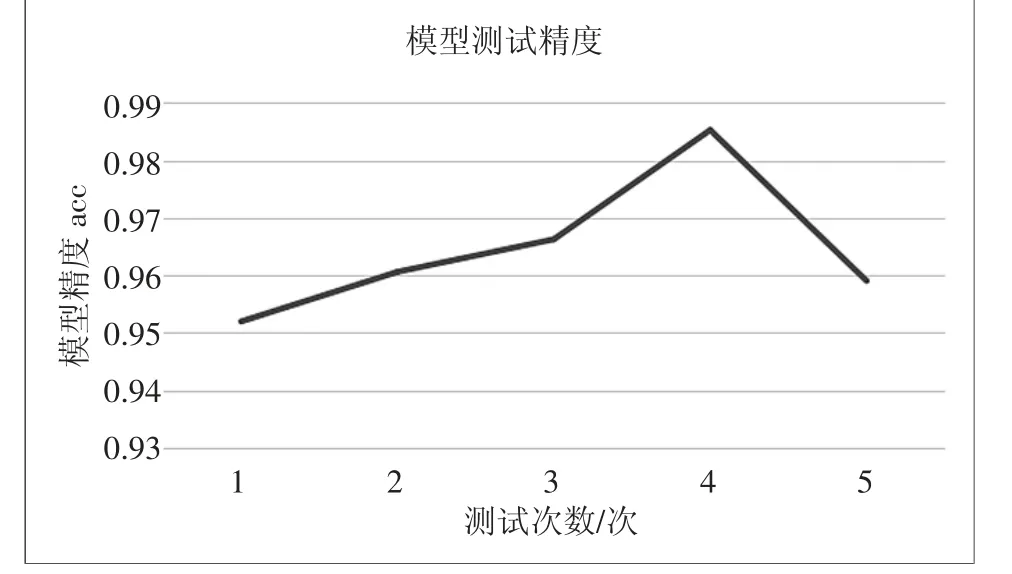
圖5 模型精度
4.3 系統驗證
為驗證模型的真實性和實用性,結合海康威視高清工業相機試驗裝置開發了一款小麥不完善粒分類檢測系統進行實驗驗證。基于SE_ResNeXt-50 的小麥不完善粒快速檢測系統可以根據用戶上傳發霉、蟲蝕、病斑單籽粒圖片快速將圖片數據發送給在AI Studio 上部署的SE_ResNeXt-50 小麥不完善粒分類模型,將模型的預測數據快速準確的返還給用戶。系統界面如圖6 所示。隨機選取154 粒小麥不完善粒樣本進行檢測。

圖6 系統檢測界面
根據測試結果,在154 粒小麥不完善粒測試樣本中,檢測正確的樣本數為146 粒,系統識別精度達到96.10%,小麥不完善粒分類混淆矩陣如圖7 所示。由混淆矩陣可知,66 粒發霉粒樣本中,4 粒被誤判為蟲蝕粒;42粒病斑粒樣本中,2 粒被判斷為蟲蝕粒;46 粒蟲蝕粒樣本則全部判斷正確。較好地解決了在小麥不完善粒分類領域將蟲蝕、病斑、發霉粒因小麥籽粒表面的黑斑類似而導致的分類不準確等問題。表明小麥不完善粒檢測系統能夠大幅度提升檢測效率,降低檢測成本,有極強的實用價值和推廣性。同時也表明改進的SE_ResNeXt-50 網絡結構能夠較好地實現小麥蟲蝕粒、發霉粒、病斑粒的分類。
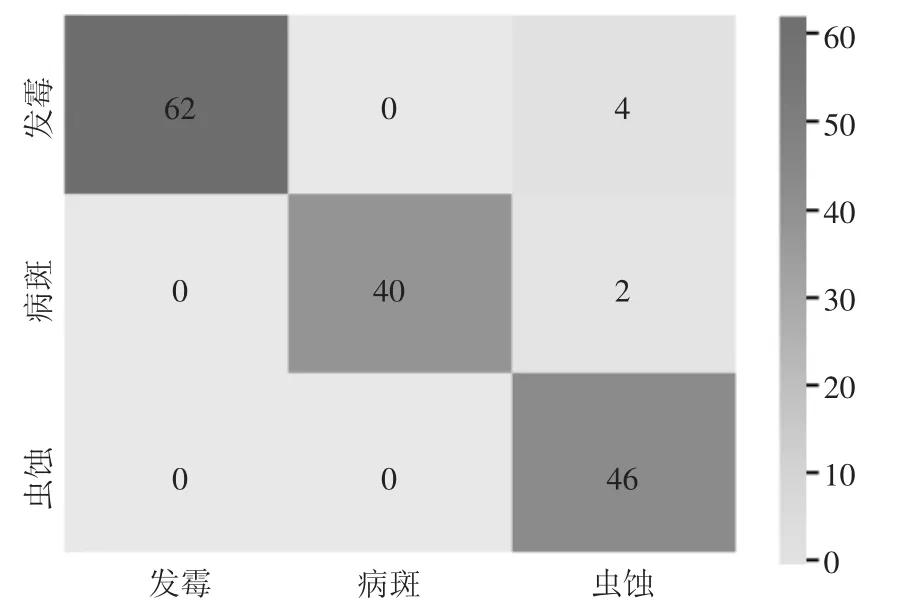
圖7 混淆矩陣
5 結論
本文在使用ResNeXt-50 卷積神經網絡的基礎上,通過引入Squeeze-and-Excitation 計算結構模塊改進原有的網絡結構,提出了一種SE_ResNeXt-50 小麥不完善粒分類模型,實現了小麥病斑粒、蟲蝕粒、發霉粒的快速、精準、無損分類檢測。結果表明,改進后的SE_ResNeXt-50 網絡通過改進模型通道間的相互依賴關系來增強卷積特征學習,提高了神經網絡對信息特征的敏感度,從而大幅提升了模型的收斂度和計算效率。為驗證模型的真實性和實用性,結合海康威視高清工業相機試驗裝置開發了一款小麥不完善粒分類檢測系統進行實驗驗證。經測試,系統識別精度達到96.10%。可滿足日常生產生活中對小麥不完善粒分類檢測需求,提升生產效率,減少小麥粒在分類篩選階段的損耗率,降低生產成本。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
