影像檔案多模態檢索模型框架構建
2023-08-10 08:14:02江檳伊房小可
北京檔案 2023年7期
江檳伊 房小可
摘要:數字化轉型為影像檔案的管理提供了機遇和挑戰。針對當前影像檔案檢索存在的問題,該文以影像檔案內容檢索為研究對象,在向量管理技術基礎上構建影像檔案的多模態檢索模型框架。在所構建的框架中,將影像檔案分解為聲音、文本和圖像三種模態,分別形成三類模態向量子空間,之后構建不同向量模型之間的對應關系形成總空間向量,進而通過計算查詢數據與總空間向量的相似性,并通過多模態匹配得到更精準的影像檔案片段。最后,該文以單個視頻的識別過程為例,做“文本-影像”雙模態的模擬實驗,以驗證實現影像檔案多模態檢索的可行性。
關鍵詞:影像檔案 多模態 檢索模型
隨著媒體技術和信息技術的快速發展,影像檔案逐漸成為記錄個人記憶、企業記憶、政府記憶乃至國家記憶和社會記憶的重要載體。[1]提升影像檔案的檢索技術水平,保證其檢索效率,對促進影像檔案的開發利用起著重要作用。目前國內影像檔案的檢索方式主要是通過輸入關鍵詞匹配著錄信息,從而得到相對應的影像檔案,這種文字匹配文字的方式實際上是以單模態檢索為主,以用戶主觀的著錄信息為基礎實現的檢索,有時無法滿足用戶的客觀檢索需求。多模態檢索則是融合不同模態進行的檢索,可通過綜合不同模態間的互補信息達到提高檢索準確率的目的。[2]構建影像檔案的多模態檢索模型,對于從海量影像檔案中快速、準確地找到有價值的檔案數據具有重要意義。
一、實現影像檔案多模態檢索的現實意義
(一)影像檔案多模態檢索是開發影像檔案的重要途徑
要充分發揮影像檔案記錄歷史的功能,需要對影像檔案進行深入開發,提高影像檔案的利用率。一方面,將影像檔案的內容解構成多模態數據,形成多模態數據空間,推動多模態影像檔案資源庫建設;另一方面,在多模態影像檔案資源庫的基礎上,探索數據化影像檔案的檢索方式,如一站式多模態檢索方式等,最終實現影像檔案的高效檢索。
(二)影像檔案多模態檢索將提升影像檔案在檔案學科的影響力
影像檔案具有視覺直觀性強和感覺沖擊性強的特點。檔案工作者常因影像素材收集耗時長、制作難度大等問題,影響整體檔案工作流程。實現影像檔案多模態檢索有利于提高檔案工作者在影像檔案素材收集和制作方面的效率,實現“易找—易用—多找—多用”的連鎖反應。影像檔案與其他類型的檔案相比,整體利用率較低,這與影像檔案自身具有的價值是不相符的。隨著影像檔案利用率的提高,影像檔案在檔案學科中的影響力會擴大,并進一步促進檔案學科與計算機、攝影藝術等學科的融合。[3]
(三)影像檔案多模態檢索能夠延伸影像檔案的文化價值
隨著媒體技術的發展,影像文化作為文化傳播的重要內容正重構人們的審美觀念。與其他類型的檔案相比,影像檔案更具時代性,傳遞的信息更具多樣性。[4]實現多模態檢索會提高影像檔案利用率,借助電視、網絡播放器、短視頻等媒介,形成強大的文化傳播優勢。
二、現階段影像檔案管理面臨的問題
(一)影像檔案整體管理模式有待提升
我國部分檔案管理機構還沒有形成影像檔案管理的統一規范,普遍存在以下問題:一是影像檔案存儲的格式還未統一。影像檔案部門都有專用的錄像設備,設備不統一會導致影像清晰度和存儲格式不同,進而使得后續影像檔案的電子化管理變得困難。二是檔案工作者缺乏對影像檔案的科學管理意識,難以實現影像資料的高質量歸檔。檔案工作者需要將不同存儲格式的影像檔案轉化成相同的存儲格式,并按照統一規則進行有序化管理。三是影像檔案的描述語言存在較大范圍的不一致。這里影像檔案的描述語言是指對影像檔案的主題、主體、時長等進行描述的語言。目前各檔案部門對影像檔案的描述語言格式要求沒有統一的標準,亟須確定影像檔案的描述語言以提升影像檔案的檢索效率。
(二)影像檔案著錄、標引和檢索技術水平落后
學者張美芳曾提出我國檔案編目著錄工作結構層次過于簡單的共性問題。[5]影像檔案形式特殊,主要以聲音和錄像呈現,其檢索結果的精準與否取決于著錄是否精確。影像檔案著錄、標引和檢索技術水平直接影響著影像檔案的利用效率。我國影像檔案檢索多為單模態檢索,檔案編目工作還停留于文字層編目,主要基于描述文本導出檢索結果。此外,一些檔案工作者不會對影像檔案內容進行機器識別和存儲,這給后期檔案利用帶來了許多困難。
與國內相比,國外對于影像檔案的著錄標引技術研究更加深入,主要集中于基于內容識別的影像著錄和多模態檢索。學者龐美詩蒂(R.M.Bommisetty)[6]在2022年4月提出了多模態檢索技術,即在存儲階段,提取數據庫視頻的關鍵幀并生成算法ICTSLIC,應用ICTSLIC生成的超像素表示數據庫視頻;在查詢階段,對查詢幀進行ICTSLIC超像素分割,同樣用超像素表示查詢幀;最后通過計算查詢與存儲的歐氏距離進行匹配,檢索出與查詢幀相似的視頻,這極大提升了影像檔案的檢索效率。2022年8月18日,國家檔案局發布了上一年度全國檔案主管部門和檔案館基本情況摘要,我國錄音磁帶、錄像磁帶、影片檔案達到109.2萬盤。[7]面對海量的影像檔案,各級檔案部門僅依靠人力進行編目不切合實際,有必要探索基于內容的影像識別和多模態檢索技術,通過機器學習提升影像檔案的檢索利用效率。
三、構建影像檔案多模態檢索模型
我國影像檔案現有的檢索方式多采用關鍵詞式的單模態檢索,這就需要實現檢索文本關鍵詞與被檢索影像檔案內容的高度匹配,檢索程度受限。針對當前問題,本文提出影像檔案聲音、文本、圖像的多模態檢索模型,此模型可通過匹配不同模態間的數據信息達到更高的檢索效率。主要思路是將影像分解為不同模態的數據,進而構建表示同一語義的不同模態數據所對應的向量模型,之后構建不同向量模型之間的對應關系形成總空間向量,通過多模態匹配得到更精準的影像檔案片段。
(一)構建影像檔案多模態檢索模型框架
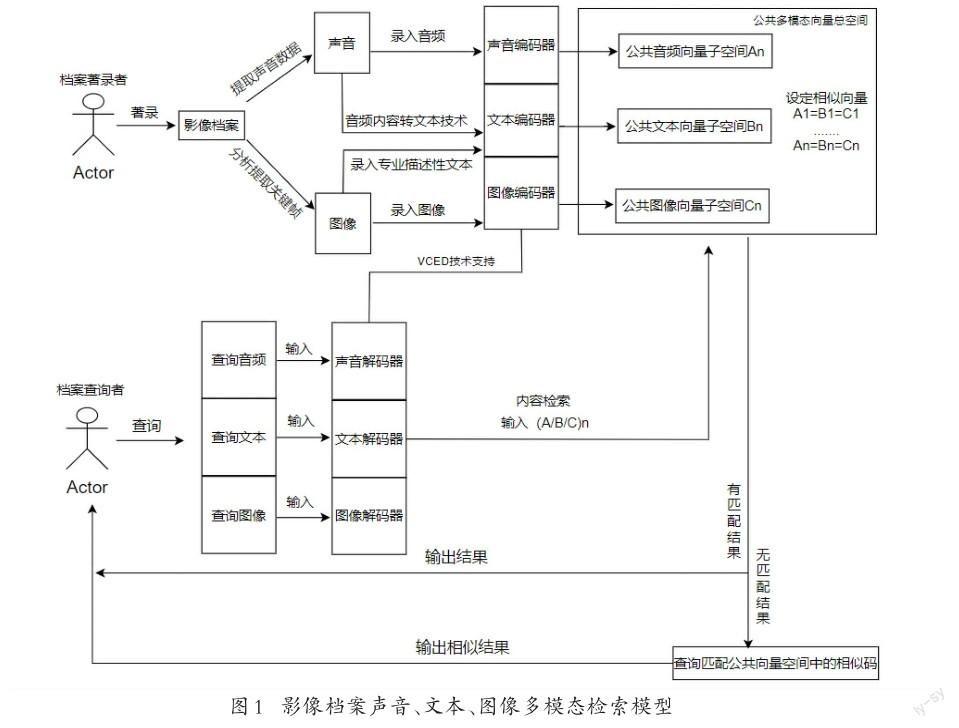
如圖1所示,圖左側為影像檔案工作人員著錄流程。工作人員首先需要將影像檔案進行著錄并存入系統,系統會通過自動語音識別技術(ASR)提取出影像檔案中的聲音數據以及被轉化的聲音內容文本數據,同時通過關鍵幀提取技術提取影像檔案關鍵幀的圖像數據,并在此基礎上錄入圖像數據的專業描述文本。最終,影像檔案會形成音頻、文字和圖像三種數據,并通過聲音編碼器、文本編碼器和圖片編碼器編碼,分別進入線上的音頻、文本和圖像三種模態的公共子空間。這三類子空間共同形成了公共多模態向量總空間。
在公共多模態向量總空間中,我們規定公共音頻向量子空間內編碼向量為An,公共文本向量子空間內編碼向量為Bn,公共圖像向量子空間內編碼向量為Cn,并在總空間中設定A1音頻向量綁定B1文本向量和C1圖像向量,A2音頻向量綁定B2文本向量和C2圖像向量,依此類推。右側是影像檔案查詢者的檢索流程,如圖1所示,影像檔案查詢者可上傳一段音頻、描述文本、圖片,存儲系統會通過解碼器得出相應的向量編碼,再將向量編碼與公共多模態總空間中的各子空間向量編碼進行對比,得到匹配編碼后的查詢結果。如果存儲系統在各向量子空間中沒有找到與之匹配的編碼,則會自動查詢并匹配相似向量編碼,再輸出查詢結果。影像檔案存儲系統運行時需要將各種模態的數據進行編碼和解碼,在此過程中主要運用了Video ClipExtractionByDescription(VCED)技術。
(二)模擬實驗
前文所提到的影像檔案多模態檢索模型實質上是以影像檔案資源庫為對象,針對海量影像進行檢索的概念模型。在檢索過程中,系統需要采用自動語音識別、關鍵幀提取、VCED文本自動提取影像等技術對每個視頻進行逐一編碼、解碼,并與查詢者輸入的查詢數據相匹配,最后將所匹配的各類模態數據匯總后一并輸出給查詢者。本文以系統中單個視頻的識別過程為例,做“文本-影像”雙模態的模擬實驗,以驗證實現影像檔案多模態檢索的可行性。實驗過程如下所述。
1.利用Python搭建JINA開源環境。在開源過程中,我們需要運用3.9版本Python,依次安裝包含Python3.9、Pip、Docker、Rust、FFmpeg、Clip.git等6個軟件包。其中最重要的是Clip.git,這是由OpenAI提出的一種多模態預訓練算法,連接文本與圖像兩種模態。
2.關鍵幀抽取。這個過程將用戶的輸入內容分為兩個部分:一個是用戶輸入的視頻,另一個是用戶輸入的文本。輸入視頻需要先通過FFmpeg運行,再通過Clip進行關鍵幀圖像抽取,形成N個片段。輸入文本則直接通過Clip進行文本抽取描述,并與視頻模態內容相匹配。
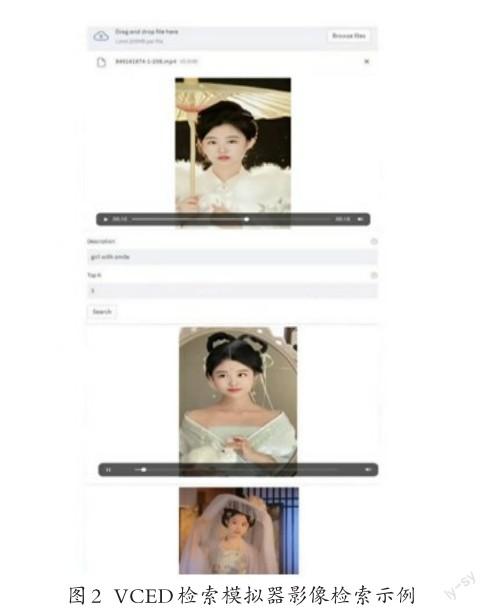
3.運用VCED技術構建影像檔案跨模態檢索模型。VCED技術基于MLOPS框架JINA與CLIP模型搭建,通過前后端分離模式的多模態檢索,實現通過文字描述自動識別視頻中相符合的片段。如VCED影像檢索模擬器的界面所示,在Browse files按鈕部分,我們可以上傳需要檢索的影像數據,在Description欄目可以輸入描述文本,在Top N欄目可以輸入數字n,這代表系統需要輸出n段與描述文本相符的影像數據。
4.模擬運行。如圖2所示,首先上傳一段任意的視頻,在文本描述欄目輸入“girl with smile”的描述詞,在段落數欄目中輸入數字“3”,點擊檢索會得到相應的3段與描述詞相符的影像數據結果。
上述實驗是以單個視頻的關鍵幀抽取為例做的“文本-影像”雙模態的模擬實驗,即通過輸入文本可得到視頻中某個相關的視頻片段。該模擬實驗說明本文提出的方法可以運用于影像檔案多模態檢索中,側面反映了影像檔案多模態檢索的可行性。
四、結語
信息技術的高速發展為影像檔案數字化發展奠定了堅實基礎,影像檔案的多模態檢索是一個新的研究方向。本文針對當前影像檔案檢索中存在的問題,將多模態檢索的理念和技術引入影像檔案檢索中,一方面通過研究探索影像檔案多模態檢索的可行性,另一方面希望借此進一步推動影像檔案的開發利用。但由于技術局限,該研究實驗階段只能從單個視頻中檢索到對應片段,無法達到從海量視頻集成的數據庫中檢索到相應片段的效果。后續我們將進一步開展技術與影像檔案相結合的研究,為影像檔案開發利用貢獻綿薄之力。
*本文為北京市屬高等學校優秀青年人才培育計劃項目(The Project of Cultivation for Young Top-motch Talents of Bei? jingMunicipalInstitutions)“多源數據驅動的北京公共數字文化智慧服務研究”(項目編號:BPHR202203216)的研究成果之一。
注釋及參考文獻:
[1]章燕華,王力平.數字化轉型背景下的檔案信息化發展戰略:英國探索、經驗與啟示[J].檔案學通訊,2021(4):28-35.
[2]歐衛華,劉彬,周永輝,等.跨模態檢索研究綜述[J].貴州師范大學學報(自然科學版),2018,36(2):114-120.
[3]楊峰.新媒體語境下影像檔案開發與利用的案例分析與展望[J].檔案管理,2022,257(4):94-95.
[4]徐園園,李娜.移動短視頻時代城市影像檔案建設[J].中國檔案,2022,583(5):70-71.
[5]張美芳.面向音視頻檔案保存與利用的分類編目研究[J].檔案學通訊,2018(1):93-95.
[6]BOMMISETTY R M, KHARE A, KHARE M, et al. Content-based video retrieval using integration of curve? let transform and simple linear iterative clustering[J].Interna? tional Journalof Image&Graphics,2022,22(2):1-24.
[7]中華人民共和國國家檔案局.2021年度全國檔案主管部門和檔案館基本情況摘要(二)[EB/OL].(2022-08-18)[2023-03-16].https://www.saac.gov.cn/daj/zhdt/202208/ b9e2f459b5b1452d8ae83d7f78f51769.shtml.
作者單位:北京聯合大學應用文理學院
