基于多樣卷積單元高效人體姿態(tài)估計
2023-08-12 03:39:36吳紅蘭孫有朝
測控技術(shù) 2023年7期
劉 豪, 吳紅蘭, 孫有朝, 喻 賽
(南京航空航天大學 民航學院,江蘇 南京 211106)
人體姿態(tài)估計是計算機視覺中一個基本且具有挑戰(zhàn)性的問題,目的是定位人體關(guān)鍵點,例如手部、膝蓋等部位。它的應用較為廣泛,包括人體動作識別和人機交互等。近些年來,人們通過使用深度卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)取得了顯著的改進。然而這些先進的方法通常使用復雜的網(wǎng)絡結(jié)構(gòu),具有大量的參數(shù)和浮點數(shù)運算次數(shù),這就導致模型推理十分耗時,對設備內(nèi)存的要求很高。筆者研究了在計算資源有限的情況下,開發(fā)兼具準確率和輕量化的人體姿態(tài)估計網(wǎng)絡模型。
隨著CNN的發(fā)展,DeepPose[1]將深度神經(jīng)網(wǎng)絡引入人體姿態(tài)估計算法,將人體姿態(tài)估計看作是一個人體關(guān)鍵點的回歸問題。之后,為了建立人體關(guān)鍵點的空間信息,學者使用CNN預測關(guān)鍵點熱圖成為主流。
SimpleBaseline[2]的網(wǎng)絡模型結(jié)構(gòu)為設計一個簡單的人體姿態(tài)估計網(wǎng)絡提供了方法。基于在ResNet主干網(wǎng)絡上添加的幾個反卷積層,顯示了一個簡單方法的良好性能。這可能是從深度和低分辨率特征圖估計熱圖的最簡單方法。在大型模型中,例如語義分割、人體姿態(tài)估計和目標檢測等位置敏感問題中,HRNet[3]顯示出了強大的能力。為了提取多分辨率的特征信息,HRNet網(wǎng)絡模型通過并行多尺度分辨率特征圖,實現(xiàn)多個特征圖的特征信息融合。由于網(wǎng)絡模型采取保持高分辨率的策略,使得網(wǎng)絡模型具有較高的參數(shù)量和復雜度。Lite-HRNet[4]將ShuffleNet[5]中的高效組卷積模塊應用于HRNet中,大幅度減少了參數(shù)量,同時表現(xiàn)出良好的性能。組卷積[6]是將輸入層的不同特征圖進行分組,然后采用不同的卷積核對各個組進行卷積,降低卷積結(jié)構(gòu)的計算量。DwiseConv(Depthwise Convolution)[7]作為一種比較特殊的組卷積,相對于傳統(tǒng)卷積的優(yōu)點在計算量上有巨大幅度的降低。將通道注意力整合到卷積塊中引起了廣泛的關(guān)注,在性能提升方面表現(xiàn)出了巨大的潛力,其中一個代表性的方法是SENet[8],它學習每個卷積塊的通道注意力,為各種深度CNN體系結(jié)構(gòu)帶來了明顯的性能增益。
在上述模型設計的啟發(fā)下,提出了一個輕量級姿態(tài)估計網(wǎng)絡DU-HRNet(Diverse Unit HRNet)。首先,分析了HRNet模型的基本組成,在HRNet中的高分辨率設計模式的基礎(chǔ)上,設計了DU-HRNet模型結(jié)構(gòu)的不同階段。考慮到CNN的深度、通道數(shù)目對模型的參數(shù)量和計算量的影響。相較于HRNet,重新設置了DU-HRNet模型在不同階段的多分辨率模塊數(shù)目。接著在不同階段多分辨率模塊的分支中使用一系列預定義的卷積單元,該卷積單元使用DwiseConv深度卷積代替常規(guī)的3×3卷積來減少模型參數(shù)量和計算量。為了探索并增強來自不同感受野大小層的多尺度信息,鼓勵卷積層間信息更加多樣化,DU-HRNet允許并行分支中的每一分支擁有不同類型的高效卷積單元。為了改善網(wǎng)絡模型的非線性,以及實現(xiàn)對特征權(quán)重的再分配,使用通道注意單元提升網(wǎng)絡性能。在MS COCO[9]關(guān)鍵點檢測數(shù)據(jù)集和MPII[10]數(shù)據(jù)集上的實驗結(jié)果表明,本文的模型在復雜度較低的條件下具有很強的競爭力。
1 相關(guān)的工作
1.1 人體姿態(tài)估計
自上而下的方法將關(guān)鍵點的檢測過程解釋為兩個階段,即首先從圖像中定位并裁剪所有人形框,然后解決裁剪后的姿態(tài)估計問題。卷積姿態(tài)機(Convolutional Pose Machine,CPM)[11]使用順序化的卷積架構(gòu)來表達空間信息和紋理信息,網(wǎng)絡分為多個階段,每一個階段都有監(jiān)督訓練的部分。Hourglass[12]屬于一種沙漏型的網(wǎng)絡結(jié)構(gòu),該網(wǎng)絡結(jié)構(gòu)能夠使同一個神經(jīng)元感知更多的上下文信息。CPN(Cascaded Pyramid Network)[13]結(jié)構(gòu)利用Mask-RCNN[14]的部分結(jié)構(gòu)檢測人體,之后實現(xiàn)關(guān)鍵點檢測。HRNet通過在整個過程中反復進行信息交換來實現(xiàn)多尺度融合。
自下而上的方法直接預測所有關(guān)鍵點,然后將關(guān)鍵點組合為人的姿態(tài)。OpenPose[15]網(wǎng)絡框架分為兩支路,一路使用熱力圖進行關(guān)節(jié)點預測,同時另一路用于關(guān)節(jié)點分組,兩支路進行聯(lián)合學習和預測。Newell等[16]使用堆疊沙漏網(wǎng)絡進行熱圖關(guān)鍵點預測和分組。分組方法是通過關(guān)聯(lián)嵌入完成的。HigherHRNet[17]使用了HRNet網(wǎng)絡主干結(jié)構(gòu),在末端使用高分辨率特征圖,提高了準確率和模型的運算復雜度。
1.2 高效卷積單元
在輕量級網(wǎng)絡中,可分離卷積和組卷積的使用越來越廣泛。MobileNetV2[18]為了獲得更多特征先使用了1×1的卷積核進行升維,然后用3×3的空間卷積核,最后再用1×1卷積核進行降維。Osokin[19]在OpenPose[20]的基礎(chǔ)上通過使用部分MobileNetV2結(jié)構(gòu)修改主干網(wǎng)絡進行輕量化改進,使得整體網(wǎng)絡能在Intel的CPU上達到實時的運行。
1.3 權(quán)重信息分配
注意力模塊通過卷積特征的學習實現(xiàn)對特征通道信息重新分配權(quán)重。SENet[8]模塊主要通過全局平均池化方法來建模特征通道之間關(guān)系。CBAM[21]在此基礎(chǔ)上考慮了通道關(guān)系和空間關(guān)系,并單獨生成注意力圖。ECANet[22]基于SENet提出了一種不降維度的局部跨信道交互策略。CoordAttention[23]網(wǎng)絡在捕捉特征圖通道之間關(guān)系的前提下,有效地將空間方向的信息保存在注意力圖中。Liu等[24]提出了極化自注意力機制,用于解決像素級的回歸任務。
2 DU-HRNet
首先,回顧原始的HRNet的網(wǎng)絡架構(gòu);然后,基于HRNet網(wǎng)絡模型為基礎(chǔ)架構(gòu),通過分析把擁有不同卷積內(nèi)核高效卷積單元應用于HRNet不同階段。在網(wǎng)絡不同階段的相同分辨率的并行分支中使用5×5和3×3卷積內(nèi)核的單元,增強來自不同感受野大小層的多尺度信息,在保證網(wǎng)絡模型性能的同時,達到輕量型網(wǎng)絡模型的目的。
2.1 HRNet
如圖1所示,HRNet在第1階段從一個高分辨率的主干開始,逐漸添加一個高到低分辨率的分支作為新階段。多分辨率分支是并行連接的,主體由4個階段組成,在每個階段,跨分辨率的信息都會反復交換。HRNet網(wǎng)絡模型主要包含4個階段,階段1特征圖分辨率為輸入原圖1/4,該階段包含4個殘差連接卷積單元,其中每個單元由Bottleneck[3]組成。然后經(jīng)過一個3×3的卷積,將特征圖的通道數(shù)降低至C。階段2、階段3和階段4分別包含1、4和3個多分辨率卷積模塊。該多分辨率卷積模塊的分支特征圖分辨率從高到底分別為輸入圖的1/4、1/8、1/16、1/32,其中4種分辨率分支通道數(shù)目分別為C、2C、4C和8C。每個分辨率分支具有4個Basicblock[3]殘差單元,該單元由2個3×3殘差連接卷積組成。在文本中,設置模型通道數(shù)目C為32。
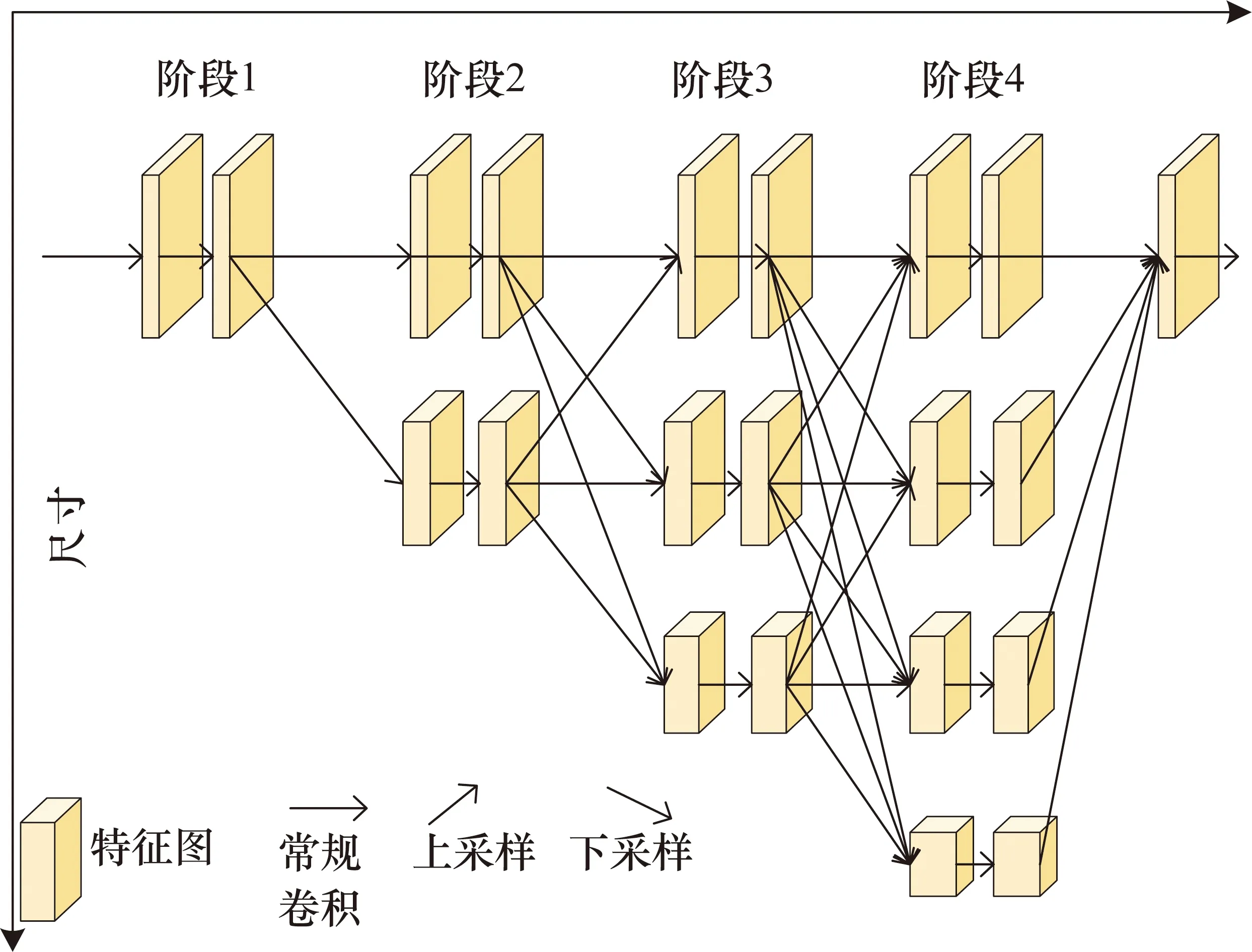
圖1 原始的HRNet網(wǎng)絡模型
2.2 多樣化卷積單元
保持圖片高分辨率方法對于解決位置敏感的視覺問題很重要。DU-HRNet模型繼承了HRNet模型原有的架構(gòu)。為了探索并增強來自不同感受野大小層的多尺度信息,鼓勵卷積層間信息更加多樣化,允許模型并行分支中的每一分支擁有不同類型的高效卷積單元。
主干網(wǎng)絡的深度對模型的精度是有重要影響的。重新設計了HRNet的階段2~階段4,得到每個階段的不同卷積單元流,如圖2所示。圖2中的實線框展示了DU-HRNet模型在階段2和階段3多分辨率分支中的信息交流方式。與HRNet不同之處,模型在每一階段中設置2個多分辨率模塊。其中每個多分辨率模塊的分支設計成一系列預定義的卷積單元,保持每一分支分辨率不變的情況下,調(diào)整卷積核尺寸,使得在最終融合的特征中充分利用有效信息。為了平衡網(wǎng)絡的深度和準確率,設計了分支中的卷積單元個數(shù)為6。圖2中的虛線框內(nèi)詳細地展示了各個預定義的卷積單元的信息流向。
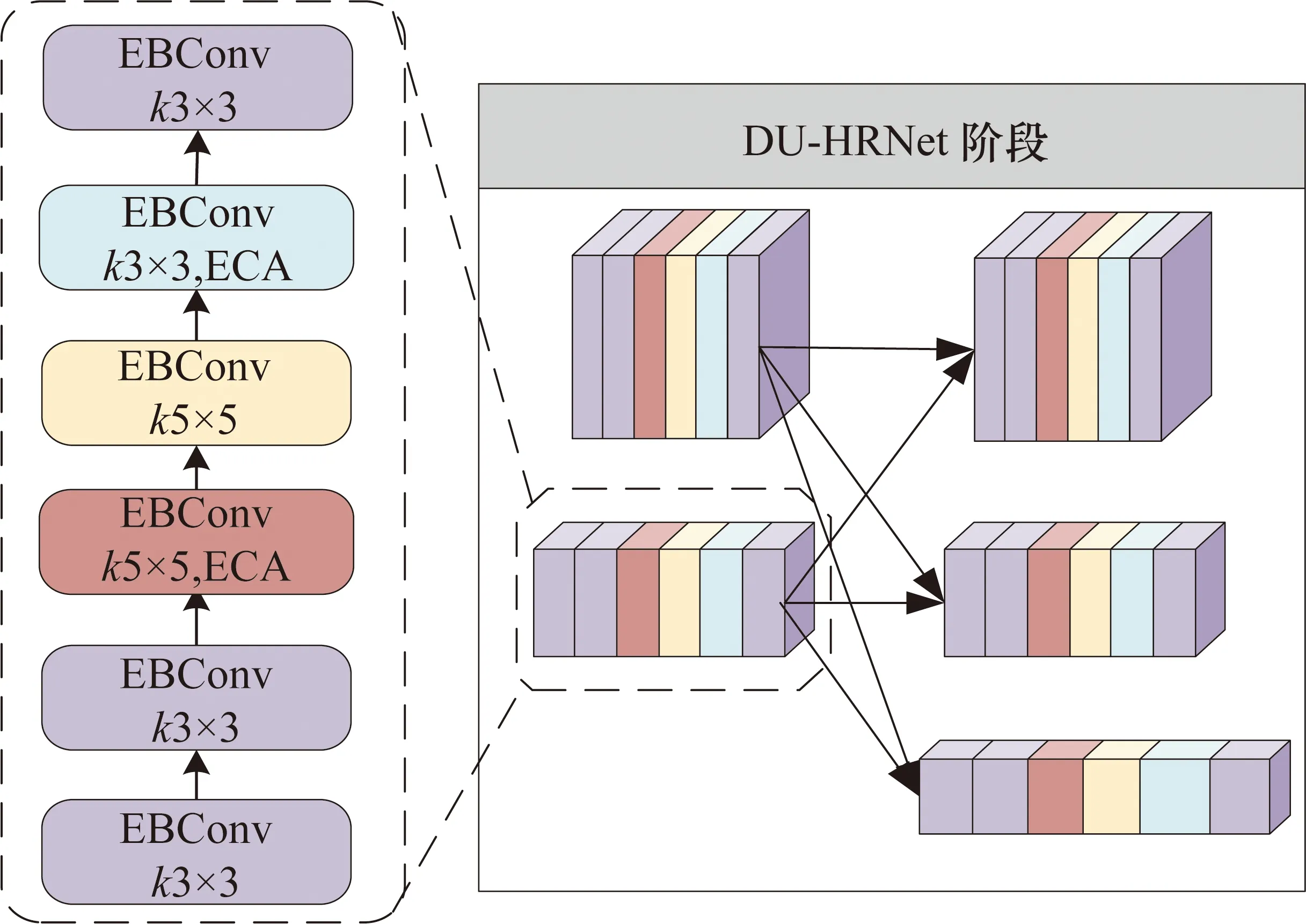
圖2 DU-HRNet的分支結(jié)構(gòu)
同一階段每一分支不同類型的卷積單元詳細結(jié)構(gòu),如圖3所示。包含了以下幾層單元:EBConv(Efficient Block)結(jié)構(gòu),首先第1層為卷積核1×1的卷積層,中間層為一個卷積核3×3或5×5 DwiseConv卷積,圖3(c)和圖3(d)在此基礎(chǔ)上使用一個即插即用的ECANet通道注意單元,最后使用了一個卷積核1×1的卷積層和一個殘差連接,將輸入直接加到輸出上。
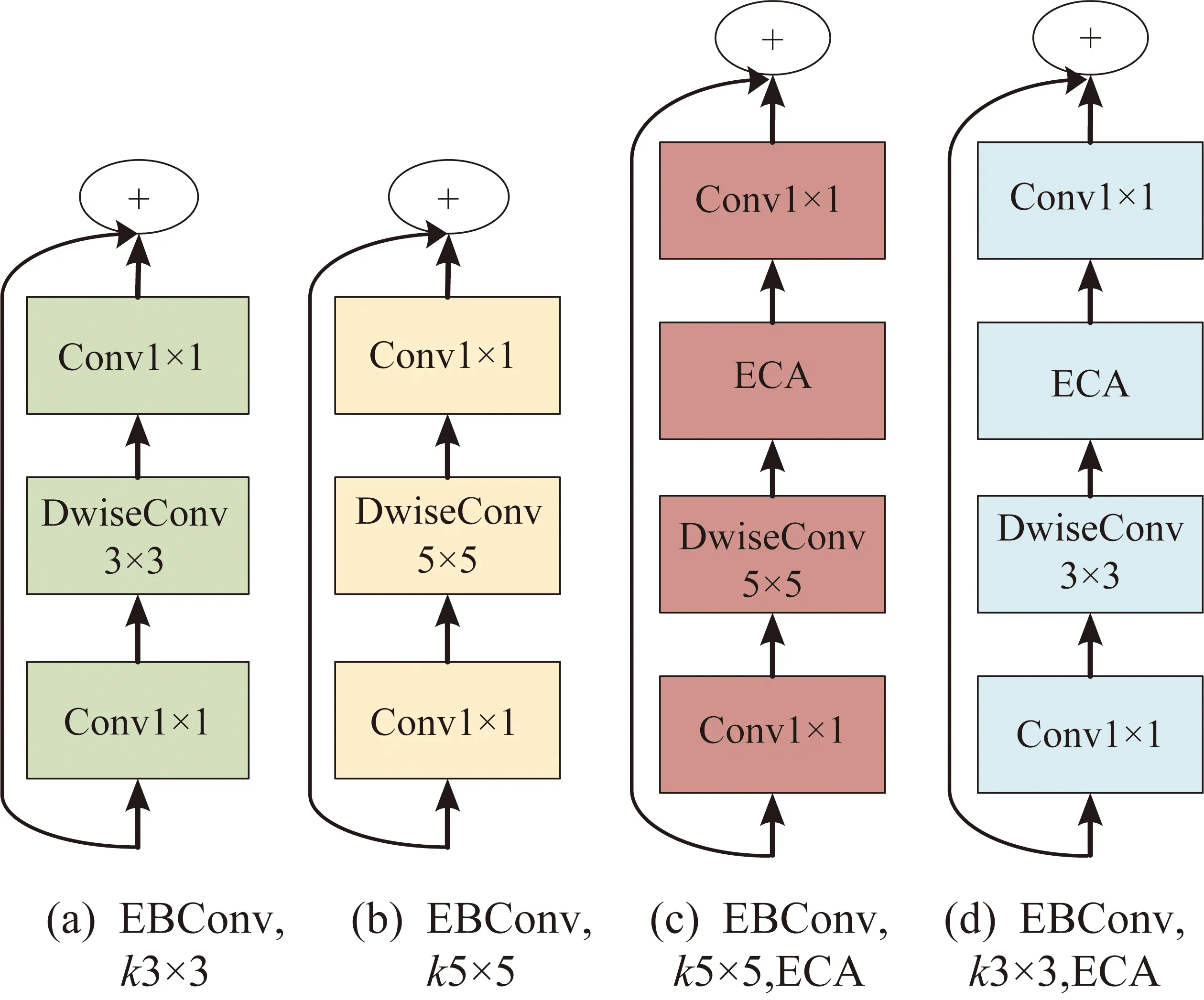
圖3 多樣化高效卷積單元
2.2.1 準確率與實時性的平衡
在網(wǎng)絡模型中使用大的深度內(nèi)核進行輕量化改進是有效的。大多數(shù)網(wǎng)絡架構(gòu)通常會多次重復3×3卷積核大小的卷積結(jié)構(gòu)。人們普遍認為,大的內(nèi)核卷積在計算資源上是昂貴的,因為卷積內(nèi)核大小與模型的參數(shù)量以及運行速度有著密切的聯(lián)系。然而通過應用深度可分離卷積,可以很好地克服這個缺點,假設內(nèi)核都經(jīng)過了合理的優(yōu)化。因此為了獲得更多特征,多樣的卷積單元包含較多的5×5深度卷積內(nèi)核。在形式上,給定一個輸入形狀(H,W,C)和輸出形狀(H,W,O),深度可分離卷積5×5和3×3內(nèi)核的乘法相加的計算代價分別為
C3×3=H×W×C×(9+O)
C5×5=H×W×C×(25+O)
2C3×3>C5×5ifO>7
(1)
由式(1)可知,當輸出的深度O>7時,2個3×3卷積核比1個5×5卷積核消耗更多的計算資源。為了兼顧模型的準確率和實時性,經(jīng)過實驗,平衡了模型中3×3卷積核和5×5卷積核的數(shù)量。
2.2.2 ECANet的嵌入
由于SENet單元成功應用于ResNet[25]中,本文使用了一個通道注意單元ECANet來改善網(wǎng)絡模型的非線性。SENet在通道Excitation(Fex)[8]的操作為給定一個輸入Z(Z∈R1×1×C)經(jīng)過Excitation變換參數(shù)矩陣W得到輸出S(S∈R1×1×C),即由式(2)可得:
S=Fex(Z,W)=σ(w2δ(w1z))
(2)
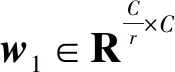
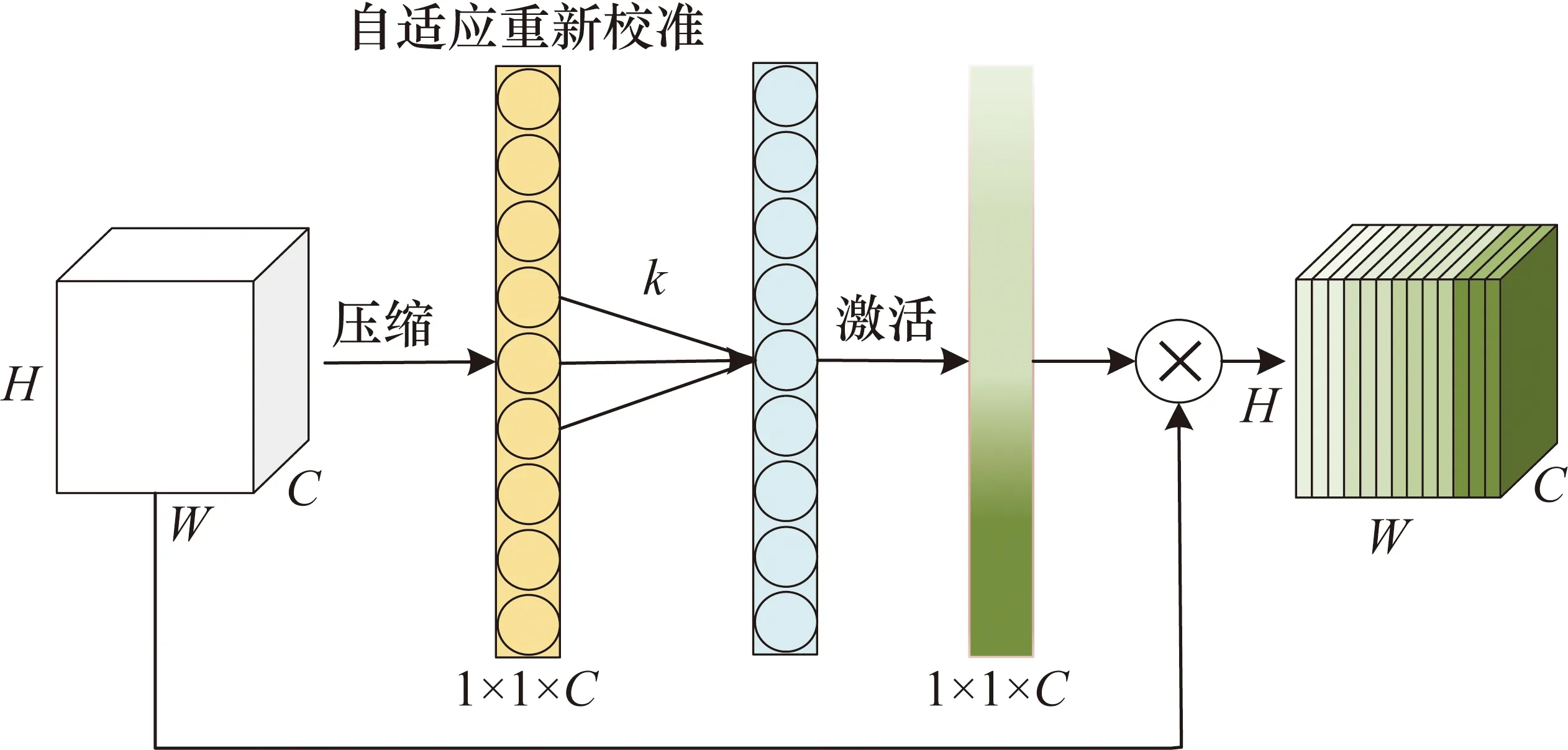
圖4 ECANet跨通道交互圖
(3)
式中:k為卷積核大小;C為輸入的通道數(shù)。k由式(4)計算得出。
(4)
式中:C為輸入的通道數(shù);|·|odd為最近的奇數(shù)。在DwiseConv卷積層之后,1×1卷積層之前插入一個通道注意單元ECANet,如圖3(c)和圖3(d)所示。該單元可以有效地改善原始卷積層的整體非線性,完成跨通道之間的信息交互,使輸出特征和輸入特征更加不同。
3 數(shù)據(jù)集模型驗證
3.1 MS COCO關(guān)鍵點檢測數(shù)據(jù)集
MS COCO數(shù)據(jù)集有超過20萬張圖像和25萬個人體實例,有17個關(guān)鍵點。模型是在train2017數(shù)據(jù)集上訓練的,在val2017(包括5千張圖像)和test-dev2017(包括2萬張圖像)上驗證的。
3.1.1 評估標準
在MS COCO上采用關(guān)鍵點相似度(Object Keypoint Similarity,OKS)的平均精度均值(mAP)度量,OKS定義了不同人體姿態(tài)之間的相似性。使用mAP定義在OKS=0.50,0.55,…,0.95時,10個閾值之間所有預測關(guān)鍵點平均精度。具體實現(xiàn)方法為
(5)
式中:j為每個關(guān)節(jié)點的類型;dj為檢測到的關(guān)鍵點與其對應的標注值之間的歐氏距離;vj為標注值的可見性標簽;s為結(jié)果的比例。
3.1.2 實驗配置
實驗配置:Ubuntu 20.04系統(tǒng),2塊GeForce RTX 3090顯卡,PyTorch 1.8.2深度學習框架。訓練時將COCO數(shù)據(jù)集中的圖像固定到384像素×288像素或者256像素×192像素尺寸大小。實驗采用Adam作為網(wǎng)絡訓練時的優(yōu)化器,初始學習率設置為1e-3;在第180輪時學習率衰減到1e-4;在第200輪時,學習率衰減到1e-5;模型總共訓練230輪。每個GPU的批量為64。在訓練過程中使用圖像旋轉(zhuǎn)和水平翻轉(zhuǎn)方法增強數(shù)據(jù)。
3.1.3 實驗結(jié)果分析
在COCO val2017進行驗證,得出該方法和其他先進的方法的結(jié)果如表1所示(AR 為檢測結(jié)果的平均召回率)。預訓練為是否使用在ImageNet上訓練權(quán)重,參數(shù)量和GFLOPs是針對姿態(tài)估計網(wǎng)絡計算的。實驗結(jié)果表明,DU-HRNet模型在較少的參數(shù)量和運算復雜度的條件下仍然取得了較好的性能。該模型,從256像素×192像素尺寸開始訓練,達到71.1 mAP分數(shù),超過其他輕量級方法。同樣地,以下模型的對比采取了統(tǒng)一的輸入尺寸。

表1 模型在COCO val2017上的性能比較
在復雜的網(wǎng)絡模型上,與SimpleBaseline模型進行對比,當網(wǎng)絡模型參數(shù)量為22.3%,GFLOPs為29.2%的條件下,mAP分數(shù)上提高了0.7精度分數(shù);與HRNetV1模型相比,該網(wǎng)絡模型參數(shù)量下降了73.3%,GFLOPs下降了62.5%,在mAP分數(shù)僅降低了2.3精度分數(shù)。相較于CPN,該網(wǎng)絡模型在預測的平均準確率提升了2.5精度分數(shù)。在輕量化的網(wǎng)絡模型上,與網(wǎng)絡模型Lite-HRNet-18和Lite-HRNet-30相比,該網(wǎng)絡模型雖然參數(shù)量分別提升了6.5×106和5.8×106,但是在模型性能方面分別提升了9.7%和5.8%,同時所有的性能指標均優(yōu)于Lite-HRNet-18模型和Lite-HRNet-30模型。相較于MobileNetV2、ShuffleNetV2、DY-ReLU,該網(wǎng)絡模型預測的平均準確率分別提升了10.1%、18.7%、4.4%。
在COCO test-dev2017上的性能比較如表2所示。參數(shù)量和GFLOPs是針對姿態(tài)估計網(wǎng)絡計算得出的。與輕量網(wǎng)絡模型比較,結(jié)果表明本文的DU-HRNet達到71.8%mAP分數(shù),超過其他輕量級方法;與復雜網(wǎng)絡模型比較,DU-HRNet模型性能優(yōu)于Mask-RCNN、G-RMI。盡管和一些大型網(wǎng)絡存在性能差距,但是DU-HRNet的GFLOPs和參數(shù)要低很多。
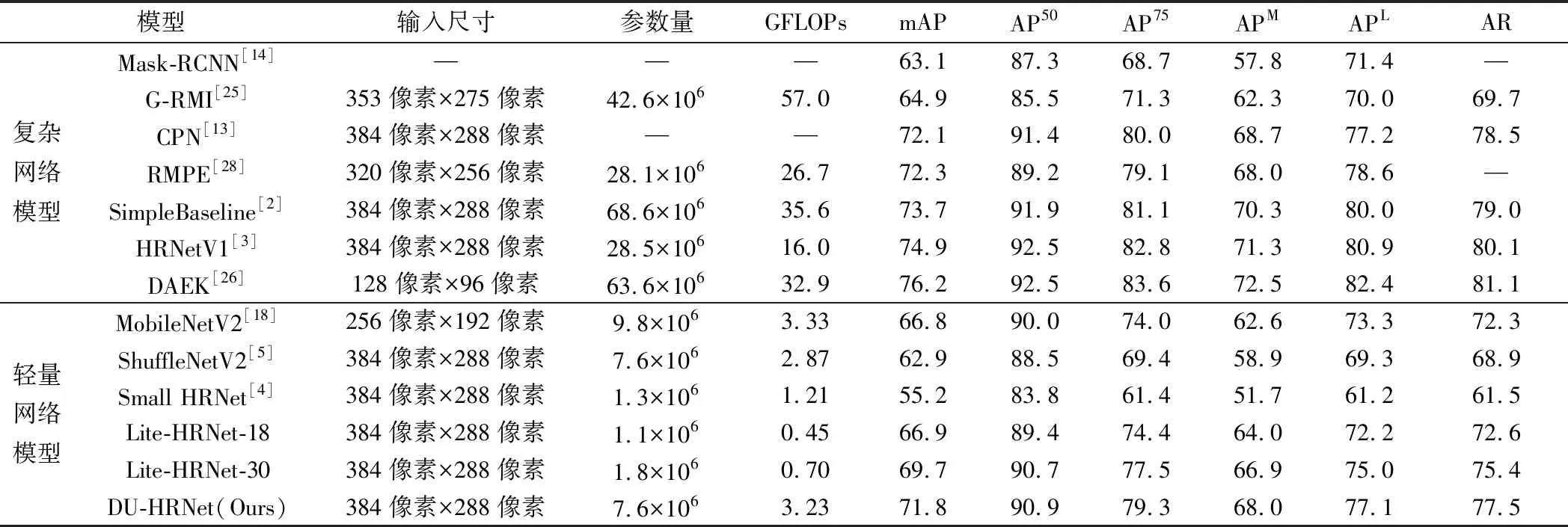
表2 在COCO test-dev2017上的性能比較
3.2 MPII 數(shù)據(jù)集
MPII人體姿勢數(shù)據(jù)集擁有大約2萬5千張來自真實世界各地姿態(tài)標注圖像。
3.2.1 評估標準
對于MPII數(shù)據(jù)集,使用標準度量PCKH@0.5(正確關(guān)鍵點的頭部歸一化概率分數(shù))來評估網(wǎng)絡性能。
3.2.2 訓練細節(jié)
實驗配置:Ubuntu 20.04系統(tǒng),2塊GeForce RTX 3090顯卡,PyTorch 1.8.2深度學習框架。在MPII數(shù)據(jù)集進行訓練時,統(tǒng)一將裁剪后的圖像縮放到固定的256像素×256像素大小,采用Adam作為網(wǎng)絡訓練時的優(yōu)化器,設置初始學習率為1e-3;在第170輪時學習率衰減至1e-4;在第220輪時,學習率衰減至1e-5;當網(wǎng)絡訓練230輪時候,學習率衰減為0。每個GPU的最小批量為48。在訓練過程使用圖像旋轉(zhuǎn)和水平翻轉(zhuǎn)方法增強數(shù)據(jù)。
3.2.3 實驗分析
在MPII驗證集上進行驗證,模型的輸入尺寸為256像素×256像素。報告了該網(wǎng)絡和其他輕量級網(wǎng)絡的結(jié)果,如表3所示。該模型比MobileNetV2、MobileNetV3、ShuffleNetV2更低的參數(shù)量下,實現(xiàn)了更好的準確性。與網(wǎng)絡模型Lite-HRNet-18和Lite-HRNet-30網(wǎng)絡模型相比,該網(wǎng)絡模型雖然分別高出了6.5×106與5.8×106參數(shù)量,但是在模型性能方面分別提升了2.1和1.2精度分數(shù)。其中,所有的輕量型網(wǎng)絡中取得了最高的性能。
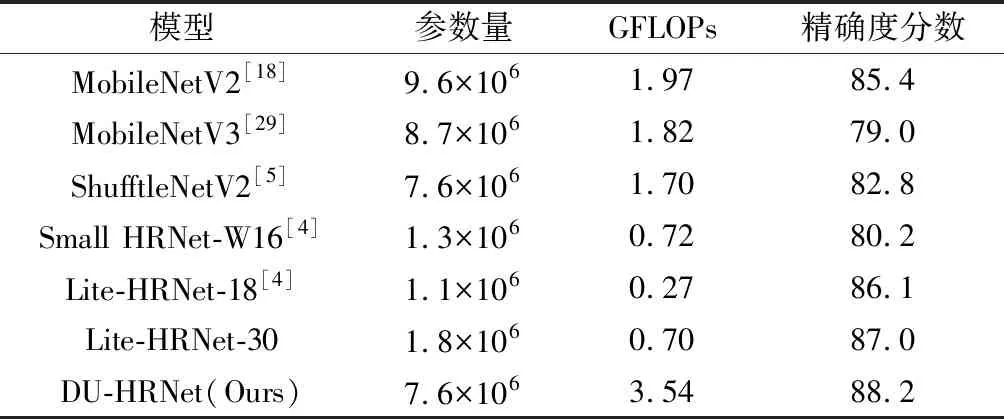
表3 在MPII驗證集上的性能比較
3.3 消融實驗
為了探究4種多樣化卷積單元的數(shù)量對參數(shù)量和精度有何影響,本文分別使用了不同數(shù)量和不同類型的卷積單元進行實驗驗證。考慮到模型的參數(shù)量和復雜度,在保證網(wǎng)絡深度相同的條件下,實驗中模型被另外設計為4種典型類別,分別為DU-HRNet-T、DU-HRNet-S、DU-HRNet-B、DU-HRNet-M。其中網(wǎng)絡階段2、階段3、階段4分支層間單元的信流向由上到下。DU-HRNet與其他4種類型具體細節(jié)比較,如表4所示。使用多樣化卷積單元和通道注意力機制提升網(wǎng)絡模型精度的策略是有效的。DU-HRNet比DU-HRNet-S多使用了2層5×5卷積內(nèi)核,準確率提升2.0分數(shù)。DU-HRNet比DU-HRNet-B多使用了1層5×5卷積內(nèi)核,準確率提升了0.9分數(shù)。對比DU-HRNet-S和DU-HRNet-T兩種模型,在參數(shù)量相差不多的條件下,局部嵌入ECANet提升了0.4的精度分數(shù)。對比DU-HRNet與DU-HRNet-M,模型使用ECANet,增加少量的參數(shù)量的條件下,提升0.5精度分數(shù)。

表4 消融實驗模型在val2017上的比較,(模型輸入尺寸256像素×192像素)
3.4 人體姿態(tài)模型效果可視化
從模型對單人、多人預測效果的正面、背面進行了可視化,如圖5所示。模型表達出了良好的可視化性能。

圖5 模型的可視化效果圖
4 結(jié)束語
提出兼具準確率和輕量化的人體姿態(tài)估計網(wǎng)絡模型DU-HRNet。為了探索并增強來自不同感受野大小層的多尺度信息,鼓勵卷積層間信息更加多樣化,模型允許并行分支中的每一分支擁有不同類型的高效卷積單元。通過實驗驗證了文章方法的有效性。和其他的方法相比,本文的方法可以在MS COCO數(shù)據(jù)集上取得優(yōu)秀的結(jié)果,此方法能對開發(fā)輕量級模型有所幫助。后續(xù)的工作聚焦于多樣感受野的可解釋問題,為姿態(tài)估計提供明確的證據(jù)。同時,以期該方法能夠帶給輕量級人體姿態(tài)估計領(lǐng)域更多的啟發(fā)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·中考版(2022年12期)2022-02-16 07:36:56
今日農(nóng)業(yè)(2021年8期)2021-11-28 05:07:50
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
河南畜牧獸醫(yī)(2016年24期)2016-11-29 01:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛(wèi)生(2014年2期)2014-11-12 13:00:16
語文知識(2014年7期)2014-02-28 22:00:26
