基于時間相關性注意力的行為識別
2023-08-16 07:01:56劉寬汪威申紅婷候紅濤郭明鎮羅子江
液晶與顯示 2023年8期
劉寬, 汪威, 申紅婷, 候紅濤, 郭明鎮, 羅子江*
(1.貴州財經大學 信息學院,貴州 貴陽550025;2.北京云跡科技股份有限公司 智能中臺,北京 100089)
1 引言
圖像是信息的載體,通過卷積神經網絡對單張圖片的空間信息進行特征提取,然后進行特征編碼,可以識別圖中包含的物體類別以及空間位置等信息,因而圖像識別是計算機視覺領域的主要研究方向之一。然而單張圖片所包含的信息往往是靜態、非連續的,隨著視頻數據的暴增,視頻中承載著更豐富和動態連續的行為信息,所以行為識別任務成為當前研究的重點。
與圖像識別不同,行為識別不僅要分析目標體的空間信息,還要分析時間維度上的信息,如何更好地提取出時間-空間特征是問題的關鍵。傳統的行為識別方法[1-4]融入大量的手工特征去提取視頻幀之間的關系,雖然取得了不錯的成績但計算成本太高。使用單支卷積神經網絡(Convolutional Neural Networks, CNN)[5-6]可以快速完成行為識別任務,但局限于視頻幀之間的運動信息而表現弱于傳統方法IDT[1]。為了提取運動信息,Simonyan等[7]對視頻數據的空間和時間維度進行建模,并提出雙流CNN進行行為識別。雙流法包含兩個通道,其中空間通道使用單張RGB圖像作為輸入用以提取行為動作信息,時間通道使用多幀相鄰圖像之間的光流作為輸入用以提取行為時序信息,最后將時間和空間信息進行融合從而預測行為類別,并在多個行為數據集上表現優于IDT。雙流法為提取時間和空間特征提供了一個新的思路,但是傳統的雙流網絡大多使用2D卷積作為特征提取器,其缺點在于不能同時學習視頻間的時空特征,因此文獻[8-9]提出使用3D卷積神經網絡同時在時間和空間維度上進行特征提取,有效學習到行為連續性,相較于文獻[7]在UCF101數據集上獲得88%的top-1準確率,I3D[9]帶來10%的性能提升。除此之外,文獻[10-15]旨在找到一種高效提取時空特征的方法,其共同點在于都使用光流作為網絡輸入。然而光流是一種手工設計的表示,這種方法不夠智能,它的提取以及存儲需要消耗大量的時間和空間導致效率不高。雖然Xu等[16]在雙流結構中設計了一條新的分支去預測光流,使得網絡訓練時不用消耗額外的空間去存儲光流從而提高了效率,但是這無疑增加了整個網絡的計算量。文獻[17-20]基于骨骼點特征并結合圖卷積神經網絡執行行為識別任務,該方法未使用到光流數據且網絡輸入為連續視頻幀,但缺點在于不是端到端的訓練。Feichtenhofer等[21]基于3D卷積同時提取時間-空間特征從而舍棄光流作為網絡輸入,并根據雙流法提出了一個新的架構SlowFast。該架構通過FastPath和SlowPath分別從連續的RGB視頻幀中提取不同的狀態信息,隨后進行特征融合。實驗表明,SlowFast在Kinetics-400數據集上強于I3D,top-1提升了7.7%。
雖然基于雙流的3D CNN在行為識別任務中獲得了良好的性能,但是仍存在不足之處,例如三維卷積操作在特征提取過程中不能區分背景特征和人體動作特征,同時也不能捕獲前后幀之間的相關性,使模型容易受到環境因素的影響,從而降低識別性能。
為解決上述缺陷,本文首先以SlowFast架構為基礎,舍棄光流作為網絡輸入,通過設計不同幀采樣率τ使分支自動采樣,使網絡直接接收視頻而非圖片序列,從而降低額外儲存開銷,加快模型推理速度。其次根據視頻幀之間的時序關系構建時間相關性注意力機制(Time Correlation Attention Mechanism,TCAM),用于降低模型對背景環境變化的敏感性,增強模型對時序信息的建模能力。最后針對SlowFast架構在進行網絡融合過程的不足之處進行改進,使用連續卷積操作進行降維,在保證網絡感受野不變的情況下提取更完整的時序信息并且降低了參數量。分別在UCF101和HMDB51兩個數據集上進行了實驗,結果表明所提方法優于現有的行為識別算法。
2 架構
過去的行為識別架構在建模過程中忽略了動作和行為體狀態變化的速度不同,例如人在握手時,手的變化速度通常比較快,而行為人的其他肢體部分則處于相對靜止狀態。根據這一現象,采用SlowFast分別構建SlowPath與FastPath來進行處理,其中SlowPath分析視頻中的靜態內容,FastPath處理動態信息。架構如圖1所示,3D卷積維度可表示為{C,T,H,W},其中C表示通道數,T是時間維度,即視頻幀的數量;H、W分別表示空間維度的寬和高。網絡架構的輸入是一段完整的視頻數據,因兩條路徑擁有不同的幀采樣率,所以各自的時間維度T不一致,T越大說明分辨率越高,時序性越連續,幀之間的相關性也就越強。故而輸入SlowPath的數據往往不存在相關性,它們大多包含了行為人或物體的顏色、紋理、目標等相對靜態的特征信息,這些信息更復雜、更難以提取,因此需要增加網絡通道數量來獲取更豐富的空間語義信息。FastPath不需要構建太多的網絡通道,因為高分辨率的輸入要求它必須有足夠快的處理速度,因此在架構中將該路徑的通道數設置為SlowPath的β倍。β<1使得網絡更輕量、計算速度更快,其缺陷就是空間細節較少,然而如何在高分辨率的視頻幀中捕獲快速變化的運動信息才是FastPath的目標,這也是本文在設計網絡時重點優化的方向。Slow-Fast通過橫向連接的方式,將FastPath的特征圖進行3D卷積匹配SlowPath特征維度之后,使用concat方式來融合。此外原始框架在使用3D卷積進行橫向連接過程中,其步長設計不合理導致部分幀之間的相關性信息丟失,故設計了一種更高效的連接方式(文中第3.2節)。在架構的末尾,各分支分別執行全局平均池化,然后concat兩個通道的特征執行全連接操作進行類別預測,再使用交叉熵損失函數(Cross Entropy Loss Function,CE Loss)評價預測是否正確,式(1)為損失函數計算公式:
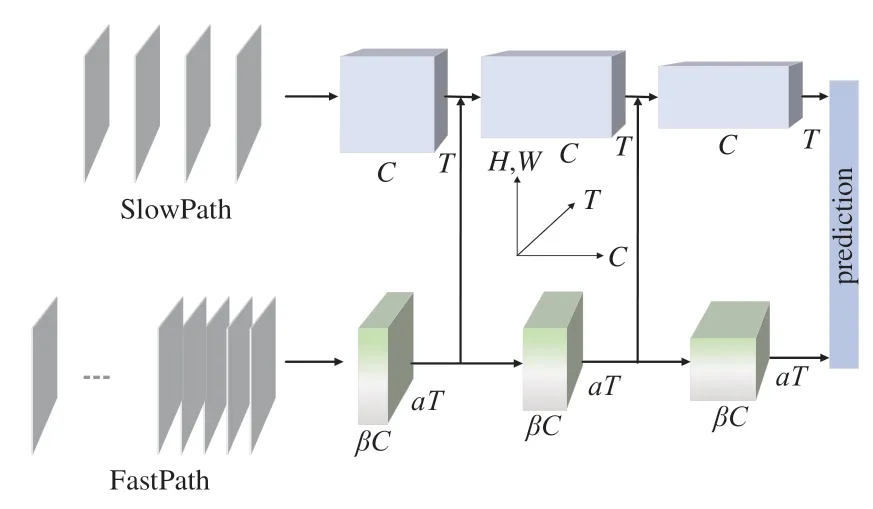
圖1 SlowFast架構Fig.1 SlowFast architecture
其中:C代表類別數,pi為真實類別,qi為預測概率。在對C中的第j個類別進行預測時,若i=j,則pi=1,i≠j,pi=0,因此當i=j時,qi越大,CE就越小,表明模型預測錯誤率越低。
3 網絡設計
如圖2所示,t-1時刻行為人A做出踢球的動作從而導致t時刻足球改變運動狀態。正是由于足球的運動狀態發生改變,而使得行為人在t+1時刻作出了撲球動作,因此行為發生的動作之間是具有相關性的,行為識別任務中不僅要建立動作之間的時序關系還需要構建相關性。
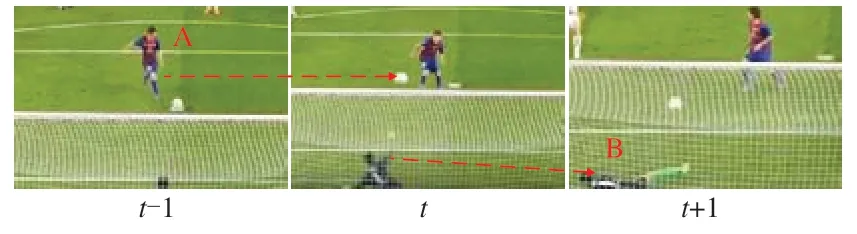
圖2 動作相關性示例Fig.2 Example of action correlatio
3.1 時間相關性注意力機制
時間相關性注意力機制由兩部分組成:相關性注意力機制、時間注意力機制。
3.1.1 相關性注意力機制
相關性注意力機制旨在找到視頻幀之間的相互依賴關系,受文獻[22]提出的三維時空注意力機制的啟發,設計相關性注意力如圖3所示。首先輸入形狀為{2C,T,H,W}的特征矩陣X,分別進行3次卷積核為{1,1,1}的三維卷積操作進行降維,得到維度為{C,T,H,W}的矩陣Matrix_1、Matrix_2、Matrix_3,隨后將Matrix_1、Matrix_2分別Reshape成{T,CHW}和{CHW,T}的特征圖Map_1、Map_2。圖3中“Δ”被定義為一種利用矩陣相乘進行特征圖融合的操作。不同于傳統的矩陣乘法計算方式,它采用余弦相似性來獲取相鄰特征圖之間的相關性關系,公式(2)給出了推導過程:
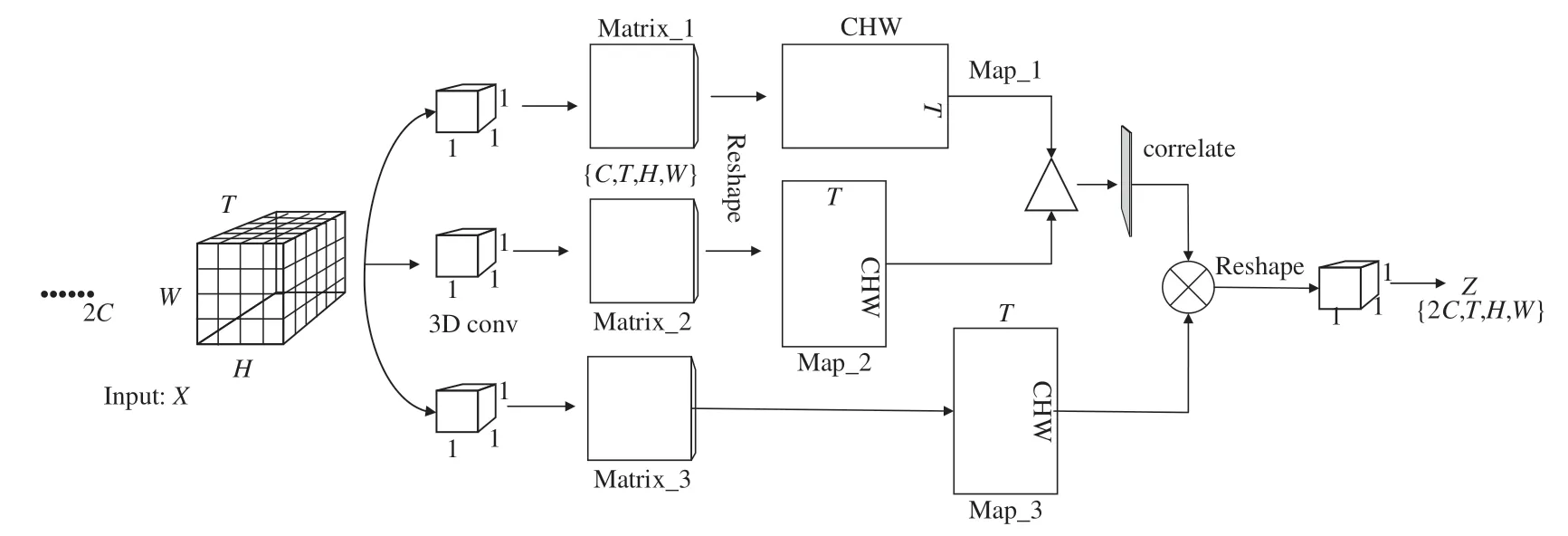
圖3 相關性注意力機制Fig.3 Correlative attention mechanism
式中:Ti表示特征矩陣在時間維度上第i張特征圖經過Reshape后的特征向量,Tix表示特征向量Ti的第x個特征值,其中{x|0≤x<C}。cos<Ti,Tj>越接近1表明特征圖之間越相關,接近0則不相關性越強。相關性注意力機制可總結為公式(3)~(5),Map_1、2經過“Δ”得到T×T的相關性特征圖M,隨后利用該圖的特征值計算每幀的相關性權重,計算方式見公式(4)。將得到的權重向量δ經過Sigmoid函數進行歸一化后,通過Fscale(·,·)操作將歸一化后的權重加權到每幀的特征上。
其中:Reshape(·)表示變換矩陣維度函數,Conv(·)為3D 卷積操作。
利用相關性注意力機制使卷積神經網不僅提取到行為時序特征,還建模了幀之間的依賴關系。然而在長視頻序列中存在著許多不包含任何有效信息的序列,這些序列需要被忽略或者賦予其較低的權重讓它變得不重要,通過構建時間注意力機制來實現這一目標。
3.1.2 時間注意力機制
圖像處理任務常使用SENet[23]來建模通道之間的關系,以此矯正通道特征從而提升神經網絡的表征能力。而在視頻處理任務中更關注于時間維度之間的關系,傳統的SENet不能提取該特征,因此將SENet進行移植,構建時間注意力機制,結構如圖4所示。
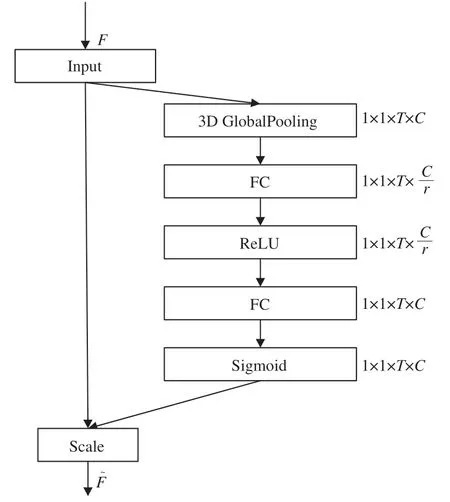
圖4 時間注意力機制Fig.4 Temporal attention mechanism
對于輸入u∈RC×T×W×H經過兩條分支:SE通道和不做任何處理的快通道。其中SE通道分兩步,首先是壓縮(Squeeze),然后進行膨脹(Excitation)。Squeeze采用3D全局平局池化的方式,壓縮每個時間維度的特征作為該維度的描述子,然后對每個時間維度里面的特征值求均值,得到2D時間注意力特征圖At∈R1×1×T×C。Excitation用來捕捉時間維度之間的重要性,首先通過兩個全連接層學習到每個時間維度的權重,激活函數依次選擇ReLU和Sigmoid,然后輸出特征圖,圖中每個元素對應時間維度的權重,輸入特征矩陣u的每個時間維度最后會乘上對應的權重,因此無用維度會被忽略。時間注意力機制可總結為公式(6)~(8):
其中:ut(i,j)表示輸入特征矩陣在時間維度t里面第i行j列的特征值,H、W分別表示特征圖的寬和高,Wiz對應全連接操作,σ(·)、δ(·)分別對應Sigmoid和ReLU激活函數,Fscale(·,·)為矩陣乘法操作。
將相關性注意力機制與時間注意力機制進行融合可以使網絡同時注意到行為之間的時間相關性,其網絡結構如圖5所示,⊕表示通道拼接操作。
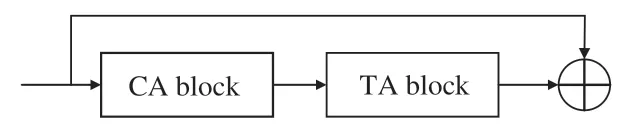
圖5 時間相關性注意力機制Fig.5 Time-dependent attention mechanism
3.2 優化橫向連接
行為類別判斷需要同時了解該行為的動態信息以及靜態信息。為此,模型將來自FastPath的特征信息通過橫向連接送入到SlowPath進行信息融合,由于兩條路徑產生的特征圖維度不一致,因此在融合之前需要先進行特征匹配。從圖1可知,SlowPath的特征圖維度為{T,S2,C},FastPath為{ɑT,S2,βC},S2表示特征圖的H×W。SlowFast利用核大小為5×12,步長等于ɑ×12的濾波器對FastPath的特征圖進行3D卷積之后送入SlowPath,然后利用concat操作實現數據的拼接。然而當ɑ>8時,由于濾波器在時間維度上的步長過大,會導致相鄰幀之間的相關性丟失,因而使用3×12的卷積核,通過3×12的步長進行兩次3D卷積來代替,在保證信息完整的同時降低了網絡參數量,數學推導見公式(9)~(11)。橫向連接過程中通道的輸入數量為βC,輸出數量為2βC,公式(9)是網絡參數量的計算公式,其中kernelsize表示卷積核尺寸,indim、outdim分別表示網絡通道的輸入和輸出數量,由此可計算出進行2次卷積核大小為3×12的卷積操作需要的參數量為7(βC)2,比1次5×12的參數量要減少30%。
3.3 網絡結構
結合時間相關性注意力機制設計時間相關性殘差塊Res_TCAM,如圖6所示。將TCAM放置該結構的最后位置,其目的在于使注意力機制每次都能對深層特征進行操作,抑制無用背景信息,增強特征表達能力。
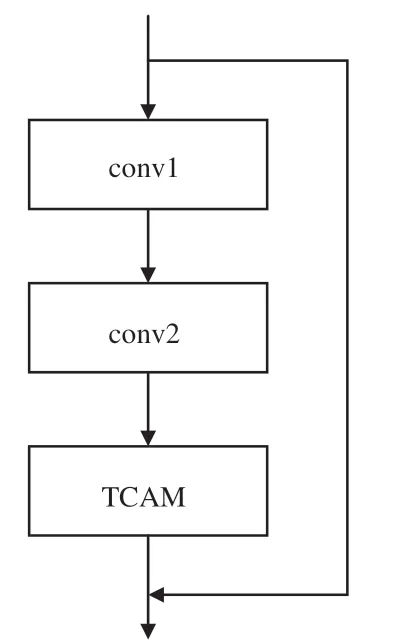
圖6 殘差塊Res_TCAMFig.6 Risidual block of Res_TCAM
表1給出了網絡結構參數,該網絡在ResNet50的基礎上,使用Res_TCAM替換傳統的殘差塊結構。然而TCAM的加入會增加網絡的計算量,表1中使用T×S2來表示時間和空間維度,步長用{時間步長,空間步長2}表示,同樣卷積核尺寸也采用{時間卷積核,空間卷積核2}表示。網絡中為了保證行為在時間上的連續性,不使用時間池化也不使用時間步長的卷積操作,直至分類之前使用全局平均池化。Res_TCAM在部分塊中先后使用3×12、1×32的卷積核,這樣可以在增強時間和空間維度上感受野的同時,減少參數量。
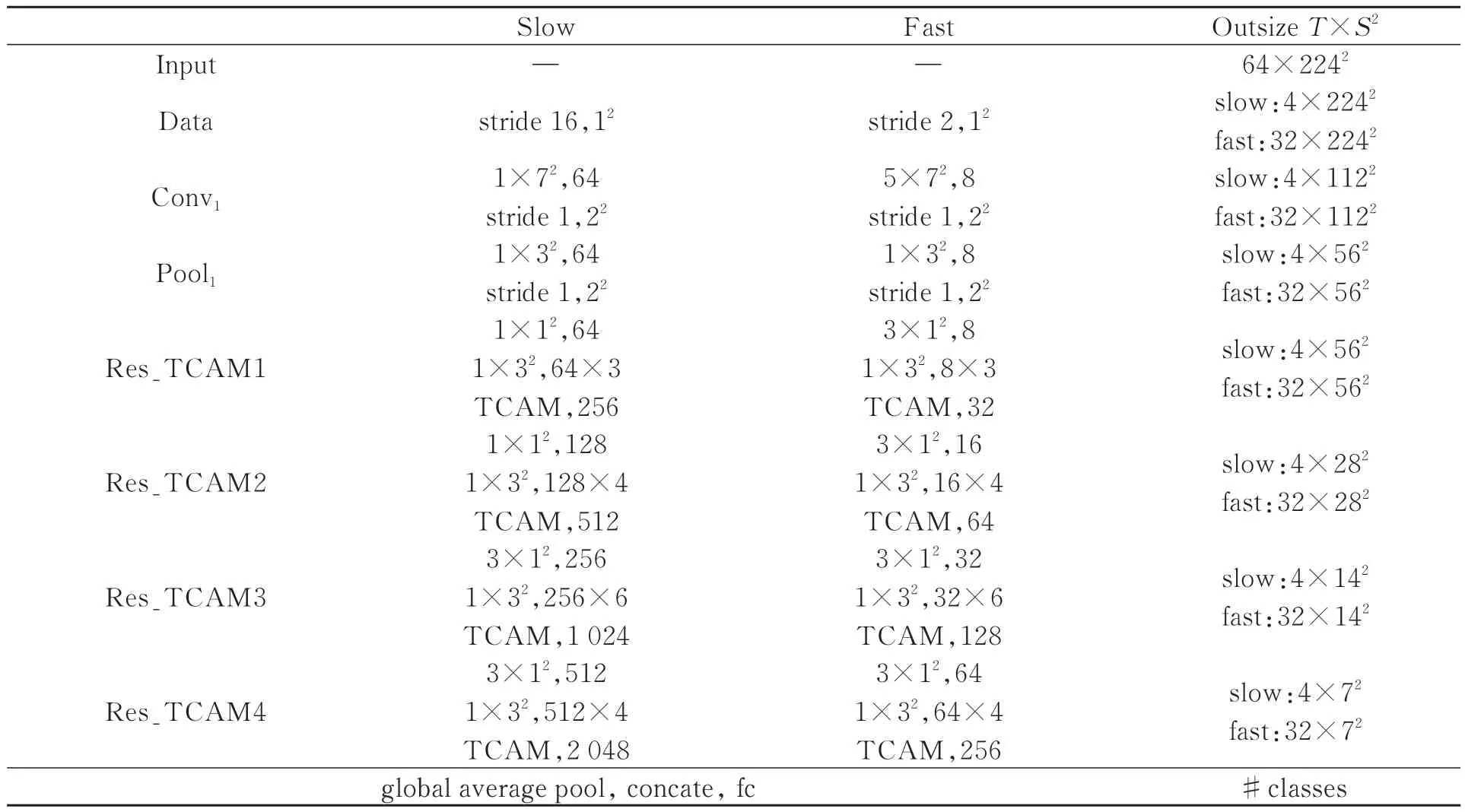
表1 網絡結構參數Tab.1 Parameters of network structure
4 實驗
實驗運行環境基于Ubuntu18.0.4操作系統,CPU是Intel Core i5-10500,使用單張型號為GeForce GTX TITAN X的GPU進行訓練,訓練網絡使用Python3.6,基于Pytorch框架搭建。
4.1 數據集介紹
UCF101[24]是目前行為識別任務中最常用的數據集之一,它來源于YouTube,數據集中包含了總時長約27 h的13 320個視頻,收集了不同行為人在不同環境下的101個行為類別。這些類別可劃分為5類:人與物體交互、單純的肢體動作、人與人交互、演奏樂器和體育運動。HMDB51[25]提供的數據大多來源于YouTube等網絡視頻庫,數據集包含6 849段樣本共51類,類別主要包括:一般面部動作、面部操作與對象操作、一般的身體動作、與對象交互動作和人體動作。
4.2 實驗訓練過程
4.2.1 模型評價標準
為使實驗結果與其他模型進行公平比較,采用通用的評價標準top-1 acc進行評價,公式(12)是計算公式。式中假設測試集樣本數量為n,模型預測某個樣本的類別為而該樣本的實際類別是時,函數F(·)返回1,否則返回0。因此top-1越接近1,模型預測準確率越高。
4.2.2 自動幀采樣方式
不同行為發生的動作頻率不同。為了提高模型的通用性以及減少數據采樣冗余,節省設備的存儲開銷,對UCF101的視頻數據進行分析,分別提取各個類別中所有視頻的平均值、最大值以及最小值。從圖7可以分析出,多數行為平均發生時間在300幀以下,最短時間大多在50~100幀,因此在設計視頻幀提取算法過程中以300為分界線,每個視頻最多提取300幀數據,單個視頻提取到的有效幀數少于γ幀時被丟掉。算法1對自動幀采樣進行了描述。
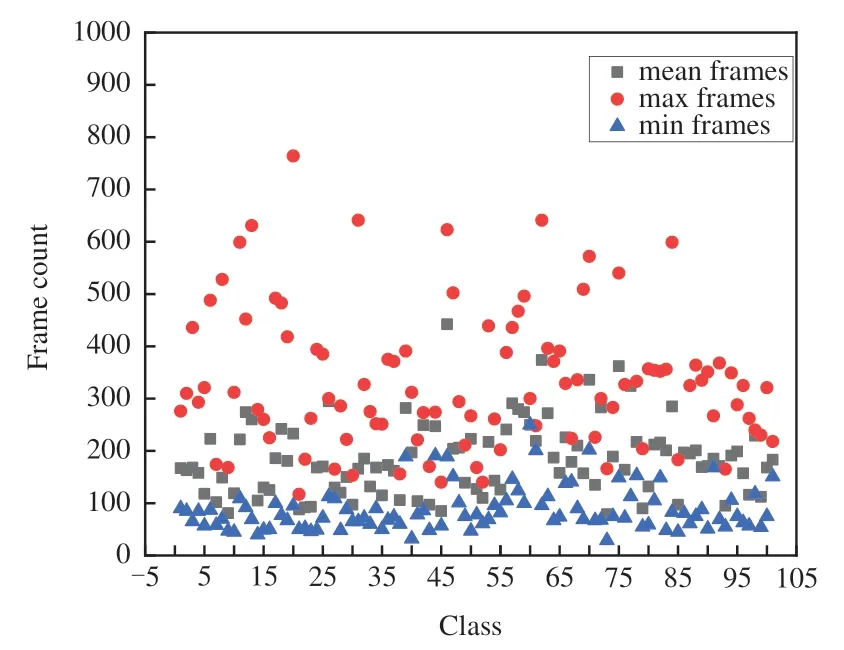
圖7 UCF101視頻幀數量統計圖Fig.7 Statistics of the number of UCF101 video frames

首先根據輸入獲取原視頻幀的數量,按照幀采樣率r(每隔r幀采一次)計算單個視頻能夠被采樣的幀數,如果該視頻幀數超過300幀,則隨機從300到frame_count之間取值,并設為結束采樣索引(end_idx),開始采樣索引(start_idx)為end_idx-300,否則令start_idx=0,end_idx=frame_count-1,然后進行幀采樣,對采樣后的數據緩存容器進行處理,若容器的緩存幀數量少于有效視頻幀采樣數量γ則丟棄,否則從DataBuffer中順序抽取γ幀數據作為網絡的輸入。
4.2.3 模型訓練細節
為使網絡的訓練過程是端到端,不需要預先提取視頻幀,因此在網絡訓練時通過自動幀采樣算法進行處理成γ幀224×224的圖片序列。實驗中參照文獻[21]的實驗結果,選擇γ=64,然后設置SlowPath的幀采樣率為16,FastPath為2。訓練時設置的批處理大小為48,初始化學習率為10-2,采用隨機梯度下降策略,動量為0.9,學習率優化器是Adam。最終模型在迭代100 Epochs時停止訓練。圖8是一個訓練實例,訓練數據集選擇UCF101,骨干網絡為ResNet50,僅在Fast-Path添加TCAM。模型在迭代了40個Epochs后,top-1 acc在97%上下浮動,在結束訓練時最高達到98.16%,損失下降到0.06(±0.01)。
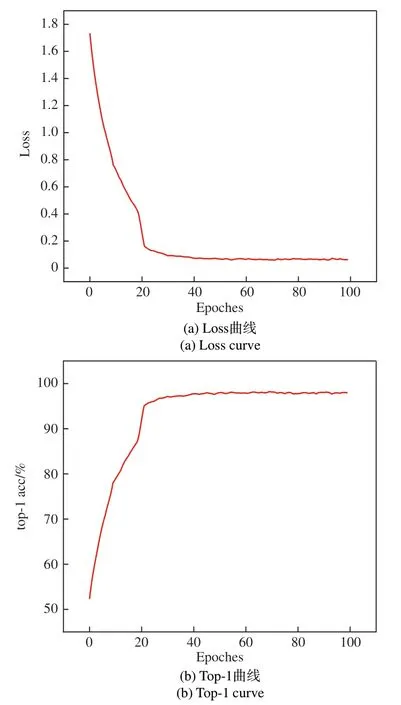
圖8 UCF101上的訓練結果Fig.8 Training results on UCF101
4.3 消融實驗
4.3.1γ對模型的影響
在對原視頻進行處理過程中,通過設置γ值來獲取網絡輸入圖片序列的幀數。在幀采樣率r一致時,γ越大表明輸入的時間跨度越長,網絡所獲取的信息越豐富,與之而來便是冗余信息的增加,因此選擇合適的γ對模型的性能影響很大。在實驗中固定SlowPath與FastPath的采樣率為16和2,速度比α=8,骨干網絡選擇ResNet50,不進行預訓練。從表2的結果可以看出,當γ從64增加到128時,SlowFast的top-1準確率增加了1.87%,SlowFast+TCAM增加了0.96%,然而它們的GFlops分別增加了2倍。此外當γ=64時,SlowFast+TCAM相比原模型的top-1增加了2.47%,而GFlops僅增加0.75。
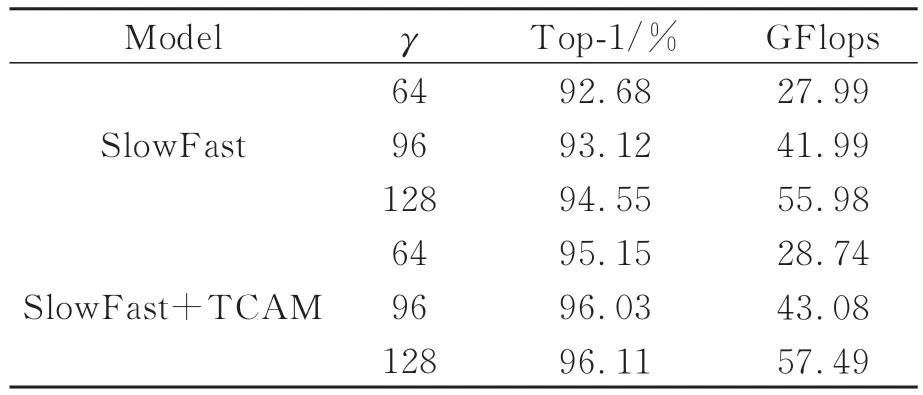
表2 γ對模型的影響Tab.2 Effect of γ on the model
4.3.2 不同幀采樣率對模型的影響
固定γ=64,α=8,同樣以ResNet50作為骨干網絡添加TCAM,探究SlowPath與FastPath在不同幀采樣率下對模型性能的影響。表3中T表示SlowPath采樣的幀數,τ為幀采樣率,通過速度比α可以推出FastPath的采樣幀數為αT,采樣率為τ/α。分析表3可以得出兩個結果:(1)增加幀采樣率τ可以提升模型的精度,然而由于Slow-Path在時間通道上的分辨率增加,使得模型的GFlops成倍增長,這將減慢模型的推理速度;(2)對比表2的實驗結果,SlowFast在添加TCAM后,即使將τ降低1倍,top-1仍然比原模型提高0.21%,而每秒10億次的浮點運算數(GFlops)約為原模型的50%。
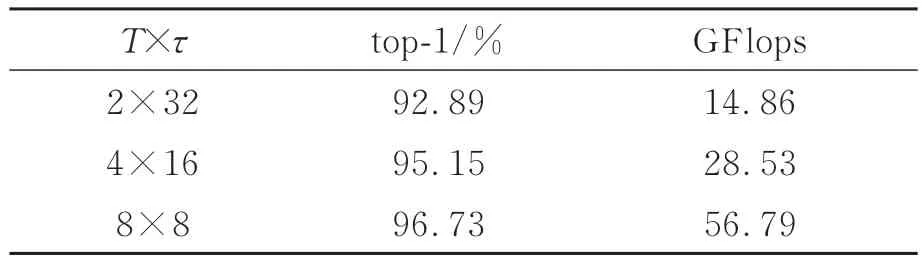
表3 不同幀采樣率對模型的影響Tab.3 Effects of different frame sampling rates on the model
4.3.3 TCAM與橫向連接對模型的影響
表4給出了所提方法和SlowFast在不同分支添加時間相關性注意力機制(TCAM),以及改進橫向連接(Lateral)方法在UCF101上的實驗結果。Backbone選擇ResNet50,不進行預訓練。SlowFast(b+)為比較基準,Slow Only與Fast Only分別僅在SlowPath與FastPath添加變量。為比較優化后的橫向連接方式對行為識別準確率的影響,將lateral作為變量。從表4可以看出,模型使用lateral(Ours)比使用lateral的識別精度高1.11%。為探究TCAM在不同路徑上的效果進行了3次實驗,實驗發現僅FastPath添加TCAM時的識別精度比基準高3.15%,表現最好。
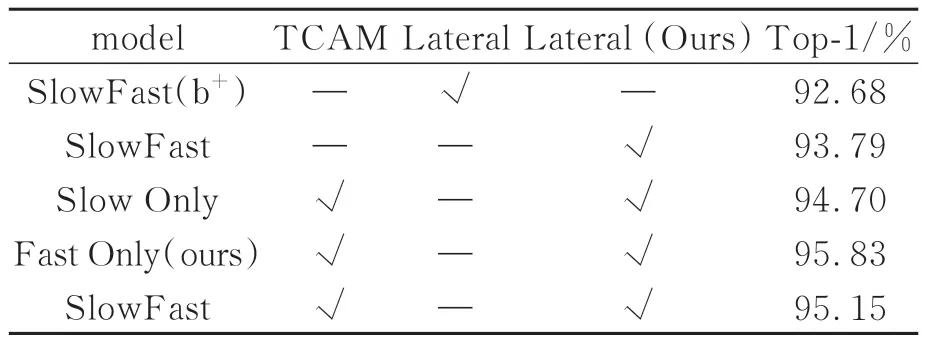
表4 時間相關性注意力與橫向連接對實驗結果的影響Tab.4 Effects of time-dependent attention and lateral connectivity on experimental results
4.4 與其他方法的比較
為判斷所提方法在行為識別任務中是否具有先進性,分別與baseline、no-attention、attention這3種類型中的優秀算法進行了比較。其中baseline表示行為識別領域的基準,no-attention表示網絡中沒有加入注意力機制,attention表示網絡中加入注意力機制。從表5的比較結果可以看出:(1)所提方法比IDT、Two-stream和C3D這3個基準模型的識別精度都有所提升。對比最好的基準模型Two-stream,TCAM在UCF101數據集上提升18.16%,HMDB51上提升了22.9%。分析原因可以得出,光流只能在一定程度上彌補2D卷積不能同時提取外觀和運動信息的缺陷。(2)從數據上可以粗略得出,不帶注意機制的模型在兩個數據集上的表現同樣良好,然而進行仔細分析可以發現兩方面的差異,一方面TCAM(Kinetics)在UCF101和HMDB51上的錯誤率相較于Twostream-I3D (ImageNet+Kinetics)分別降低了8%和8.29%;另一方面Two-stream-I3D通過ImageNet+Kinetics預訓練前后在UCF101上的精度相差4.6%,在HMDB51上更是相差14.3%,而TCAM僅在Kinetics上進行預訓練前后得出的結果分別比Two-stream-I3D預訓練前后的差異性降低了49.34%和56.64%。通過以上兩個方面的分析可以得出,所提出的時間相關性注意力機制不僅可以降低模型在行為識別任務中的錯誤率,還能提升魯棒性。(3)與AR3D進行比較,TCAM不經過預訓練的模型在兩個數據集上的識別精度均高于它。STA-LSTM是基于長短時記憶網絡設計的時空注意力機制,它在HMDB51上的精度顯著低于UCF101,說明HMDB51的訓練集和測試集分布差異較大,對模型的魯棒性能要求更高。而不經過預訓練的TCAM在該數據集上的精度要比STA-LSTM在ImageNet上進行預訓練的模型精度高16.7%,充分說明TCAM的魯棒性強于STA-LSTM。可見,所提方法在現有行為識別任務的算法中無論是識別精度和模型魯棒性均為最優,證明所提方法是具有先進性的。
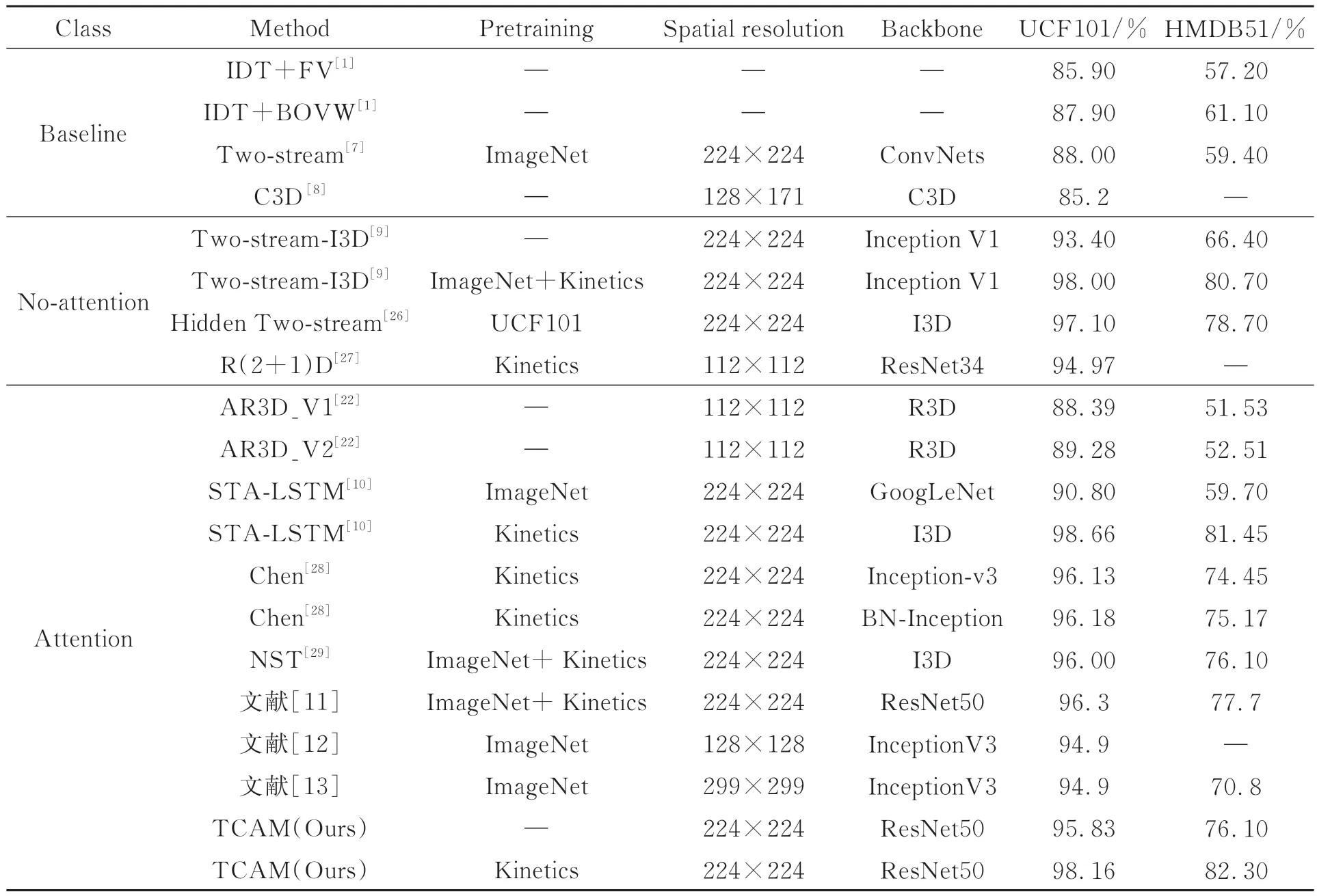
表5 TCAM與其他方法的識別精度的比較Tab.5 Comparison of recognition accuracy of TCAM with other methods
4.5 混淆矩陣
圖9給出了UCF101和HMDB51數據集上的實驗結果,通過混淆矩陣來展示。用i來對應類別序號。當模型預測標簽predi與真實標簽actuali一致時,在矩陣[i,i]位置進行計數,數值越高表明模型預測準確的次數越多,表現為該位置混淆點的顏色越深。從圖中可以看出,模型對于每一類別的預測準確率,準確率越高,矩陣對角線顏色越深。從圖9(a)可以看出,模型在UCF101數據集上的表現較優。圖9(b)中除矩陣對角線外,在其他地方出現了顏色較淺的混淆點,表明模型在對應類別上的準率較低,出現誤判,這也符合模型在HMDB51數據集上82.30%的top-1 acc的情況。

圖9 混淆矩陣Fig.9 Confusion matrix
5 結論
本文提出了一種基于時間相關性注意力機制的行為識別網絡,通過SlowFast框架設計快慢兩條路徑分別對行為的靜態信息和動態信息進行建模,使用時間相關性注意力機制來提取特征之間的依賴關系并且抑制無用的特征信息,利用卷積核更小、步長更連續的3D卷積替代原有連接方式,在實現精度提升的同時減少模型參數量。最后在UCF101和HMDB51數據集上進行實驗驗證,TCAM的識別精度分別為98.16%和82.3%,比基準Two-Strean高18.16%和22.9%。相比于I3D和STA-LSTM,TCAM表現出了更強的魯棒性,這也證明了所提方法的有效性。此外,還通過混淆矩陣展示了TCAM在兩個數據集上的預測結果,矩陣混淆點的分布情況再一次證明了所提方法的優越性。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中國衛生(2015年9期)2015-11-10 03:11:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
河南科技(2014年23期)2014-02-27 14:19:15
