購買銀行金融類產品的企業畫像研究
——基于文本分析法
2023-08-19 07:37:32張家普胡佳敏畢以霖李貴鑫
商展經濟 2023年15期
張家普 胡佳敏 畢以霖 李貴鑫
(北京外國語大學國際商學院 北京 100089)
隨著社會經濟的發展,企業財富積累在迅速增長。Wind數據顯示,截至2022年11月,中國非金融企業存款已達74.6萬億元,近10年平均增長率達8.5%。然而,面臨通貨膨脹的巨大壓力,銀行存款利率低于CPI指數及股票市場的高風險,使企業在缺乏合適投資渠道的情況下,必須要確保自身資產保值增值,因此收益好、風險可控的理財產品越來越受到企業的青睞。與此同時,商業銀行加強對企業財富管理需求的關注,短期公司理財產品、公募基金、私募資管計劃等各類理財產品如雨后春筍般在各銀行推出,為企業提供了很多選擇。企業購買銀行的理財產品,于企業而言,可以兼顧收益性和流動性,提高資產配置能力和使用效率;于銀行而言,不僅可以幫助其從中獲取利潤,也是商業銀行在存款業務之外募集資金、獲取客戶的重要方式。因此,銀行對企業客戶財富管理需求的深入把握,從而為企業制定精準營銷策略及差異化服務,將成為銀行提高機構理財產品銷售份額、搶占市場先機的關鍵,而企業客戶畫像的分析,是實現客戶隱性特征顯性化,幫助深入探究客戶需求的有效技術手段。企業畫像模式的提出不僅有利于快速識別出哪些企業有財富管理的需求,幫助其根據產品特點找到目標客戶,提高對公服務效率,還有利于銀行在客戶偏好的渠道上與其進行溝通,實現精準營銷,提升企業客戶在理財需求方面的體驗。
值得注意的是,目前有關用戶畫像的研究多以個人用戶為主,對企業畫像——尤其是金融營銷需求的企業畫像研究相對較少。因此,本文以中國某股份制P銀行為例,獲取2022年7月購買了該商業銀行某個理財產品的企業客戶名稱,通過Python在企查查官網上爬取企業基本信息后,基于圖表的描述性分析、詞頻統計、文本向量化和K均值聚類等方法對該銀行的企業客戶畫像進行分析,以期為銀行對該理財產品的營銷提供啟示。
1 文獻綜述
近年來,用戶畫像的刻畫已經從自然人逐漸過渡到各類實體,在此過程中,企業畫像也得到了學術界和產業界的關注。由于企業畫像的研究經常涉及文本語言等非結構化數據,如提取年報中的標簽信息、分析企業所屬行業或經營范圍、對企業評價分析等,因此越來越多的學者在企業畫像的研究框架中運用了文本分析或自然語言處理等技術。如田娟等(2018)提出構建基于大數據平臺的企業畫像標簽體系模型和建設框架時,對四種企業特征提取方法——Kmeans、LDA、NB、CNN——各自的優缺點進行比較分析。黃曉斌和張明鑫(2020)通過K均值聚類、層次聚類、密度聚類等方法分析企業競爭對手的特征向量,提出一套融合多源數據的企業競爭對手畫像構建模式。曹麗娜等(2022)采用TensorFlow深度學習框架,從質量創新能力、過程質量控制、產品質量水平等維度對中小微企業綜合質量畫像體系進行構建。
實踐應用方面,《中國稅務報》2016年就曾報道,大連稅務局等政府部門利用企業經營、誠信、風險和貢獻等大數據信息構建出口企業畫像(王磊,2016)。近年來,Chung等(2021)運用社會網絡分析和文本挖掘等方法進行合作伙伴識別分析,蔡盈芳等(2021)將用戶畫像技術引入涉企政務檔案信息管理中,通過采集企業用戶基本信息、參與政務服務事項、產生或需要的檔案信息、利用政務檔案信息的特征及偏好等,充分了解企業用戶產生和利用政務檔案信息的具體情況;而宋凱和冉從敬(2022)則將企業畫像應用到高校專利推薦過程,依托文本聚類、主題模型、文本相似度計算等技術,構建“專利匹配度”指標,實現向企業進行高校專利的個性化推薦。當前,已有如騰訊云、京東數科、中科聚信等大數據企業面向社會提供企業畫像服務,用于支持相關機構進行企業安全風險評估與監管(黃家娥等,2022)。
縱觀現有文獻,針對企業客戶畫像的技術研究,在理論框架分析上已日臻成熟,并且已經在稅務、專利推薦、檔案管理、風險評估等方面得到了應用,然而這一技術在金融行業的應用研究相對較少。在“互聯網+”的背景下,金融企業必須加快數字化轉型,運用現有的企業畫像技術分析方法實現更好的精準化營銷和決策。因此,本文利用詞頻統計、TFIDF、無監督學習等方法,對銀行的企業客戶畫像進行研究,為銀行針對企業客戶進行理財產品的營銷提供指導意義。
2 實證分析
2.1 數據獲取和預處理
本文獲取某P銀行2022年7月購買該銀行某理財產品的企業客戶相關數據集,內容包括企業名稱及企業購買理財產品時所在的一級分行。該數據集包含216家企業、24家一級分行。基于企業客戶名稱的信息,本文利用Python,從公開的企業信用信息查詢平臺“企查查”上爬取企業的基本信息,包括登記狀態、成立日期、注冊資本(萬元)、納稅人資質、所屬行業、企業類型、人員規模、企業地址、行業標簽、經營范圍等10個字段。
對于爬取結果,做如下預處理。首先,通過觀察發現,變量“登記狀態”的內容均為“存續(在營、開業、在冊)”;變量“納稅人資質”的內容為“一般納稅人”或“增值稅一般納稅人”,兩者沒有顯著差別;變量“企業地址”涉及的地域信息與企業所在的“一級分行”信息基本一致。以上三個變量對企業區分度不大,因此對“登記狀態”“納稅人資質”“企業地址”三個變量進行剔除;其次,將“成立日期”轉換為企業到目前為止的“成立年份”,利于統計分析。進行處理后,每個企業共有8個字段信息可供分析(見表1),其中“行業標簽”變量是對“所屬行業”的進一步補充;企業所在的“一級分行”“成立年份”“注冊資本”“所屬行業”,“企業類型”“人員規模”6個變量屬于數值型或類別型變量,對其做描述性統計分析,針對“行業標簽”“經營范圍”2個文本型變量,運用NLP的詞頻統計、文本向量化處理、K均值聚類等方法進行分析。

表1 企業基本信息數據集
2.2 變量描述性分析
首先,通過統計各個分行的企業數量觀察企業的地域分布,結果顯示企業數量超過10家的分行主要為北京、南京、寧波、廣州等一線或新一線城市分行,其中北京分行的企業客戶數量最多,企業數量有97家,占比接近45%,以絕對優勢領先于第二、三名分行;其次,從成立年份看,216家企業中成立最久的企業為42年,成立時間不足5年的企業有53家,超過5年但不足10年的企業有51家,兩者合計占比接近50%,可見多數企業成立時間不長。從注冊資本來看,共有210家企業公布了注冊資本,其中注冊資本規模最小為6萬元,最大為1130000萬元,近25%的企業注冊資本不到500萬,資本規模較小,多數企業(約68%)的注冊資本規模在5000萬元以下。從人員規模來看,157家企業公布了人員規模,其中人員規模少于50人的企業數量最多,有95家,占比超過60%,可見絕大多數企業為中小規模。所有企業按照企查查提供的企業類型大致可分為9類,其中企業類型為有限責任公司的數量最多,為191家,占比超過88%。此外,在所有企業中,上市企業僅有1家,國有獨資企業僅有1家,進一步反映出購買理財產品的多為中小企業;最后,215家企業公布了所屬行業,按照企查查提供的企業類型共分為46類,可見購買理財產品的企業行業分布之廣泛。然而,從各行業的企業數量來看,僅有8個行業的企業數量超過5家(見表2),其中科技推廣和應用服務業、商務服務業和批發業的企業數量最多,合計占比超過50%,而餐飲畜牧業、加工制造等行業的企業數量則屈指可數,說明購買理財產品的企業多分布在高新技術產業、高端服務業等第三產業。
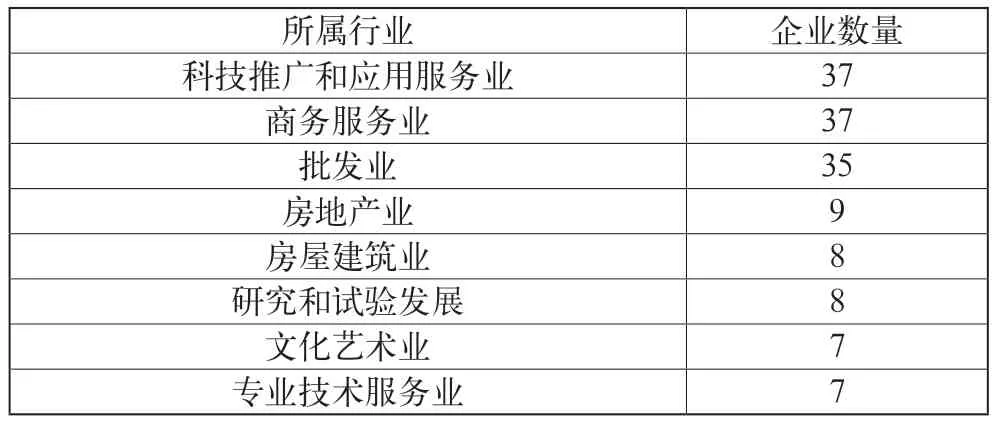
表2 企業所屬行業分布
2.3 詞頻統計
“行業標簽”“經營范圍”這2個文本型變量無法做分類統計,對此本文對這兩個變量做詞頻統計分析并繪制詞云圖,以挖掘出文本中的高頻詞語特征。其中,由于前文分析的“所屬行業”只是對企業所在的一級大類行業進行劃分,劃分顆粒度不夠精細,因此通過爬取的“行業標簽”可對此做進一步補充。
本文在進行詞頻統計前,還需要進行文本預處理。變量“行業標簽”的詞語已經成形,按照符號“#”進行切割即可。變量“經營范圍”屬于長文本,本文使用python的jieba分詞模塊對其進行全模式分詞,分詞之后導入中文停用詞表,去除文本中常見的停用詞。由于采用的是全模式切詞,切出字符長度小于2的詞語體現的語義不夠明顯,因此統計出“經營范圍”詞語長度大于2的詞頻。之后,運用wordcloud模塊分別繪制“行業標簽”和“經營范圍”的詞云圖。
圖1基于詞頻統計做出的詞云圖。數據顯示,出現頻次排名前三的為“科學研究和技術服務業”“批發和零售業”“制造業”,此外,“租賃和商務服務業”“商務服務業”“科技推廣和應用服務業”等服務業詞語出現頻次也較高。

圖1 企業行業標簽詞云圖
圖2 是詞頻統計制作的詞云圖。數據顯示,出現頻次排名靠前的詞語除了“進出口”外,“計算機”“機械設備”“電子產品”“化工產品”等和工業相關的詞語出現的頻率較高,與“技術開發”“技術咨詢”“技術轉讓”等高新技術服務業相關的詞頻排名也很靠前。

圖2 企業經營范圍詞云圖
2.4 文本向量化和K均值聚類
對“行業標簽”和“經營范圍”的高頻詞分析只能對企業客戶所在的行業得到初步了解,但無法確定企業所在的行業主要有哪些,因此本文運用無監督學習——K均值聚類法分別對“行業標簽”和“經營范圍”進行聚類分析,以找出購買理財產品的企業的主要行業。
由于K均值模型的輸入必須是數值型向量類型,需把每條由詞語組成的句子轉換成一個數值型向量,所以本文使用TF-IDF算法對文檔進行向量化。TF-IDF(李春梅,2015)在信息檢索、文本挖掘等場景中是常用的加權技術,用以評估一字詞對于一個文件集或一份文件對于一個語料庫的重要程度。字詞重要性與其在文件中出現的次數成正比增加,但同時會隨著其在語料庫中出現的頻率成反比下降。本文使用Sklearn模塊的TF-IDF算法把所有文本數據轉換為詞頻矩陣,作為K均值模型的輸入,并將TF-IDF的最大特征值設為20000。
K均值聚類是一種自上而下(top-down)的聚類方法,須預先確定樣本中的聚類數目,即K的具體取值,比如根據經驗或試錯。在對“行業標簽”進行K-means聚類時,分別測試當K等于3、4、5類的結果,對比發現,當K=4時,“行業標簽”的聚類結果區分更為清晰,因此將K設定為4,結果如圖3和表3所示。
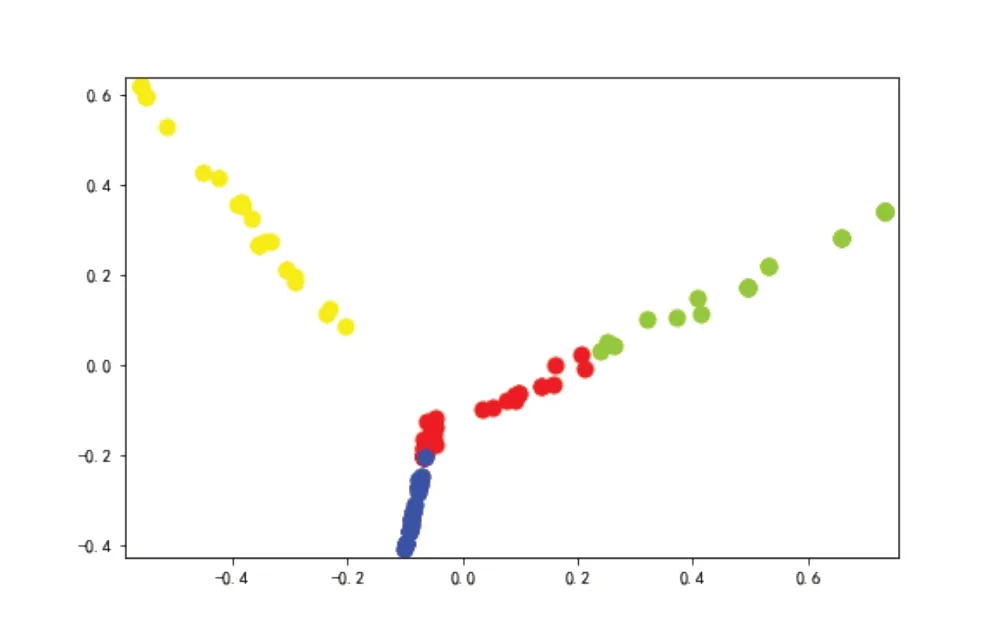
圖3 企業行業標簽聚類結果圖

表3 企業行業標簽聚類分析結果
從表3可以看出,P銀行購買理財產品的企業主要集中于以下四類行業:第一類以文體娛行業為主;第二類主要為批發和零售業;第三類主要為科學研究和技術服務業;第四類主要為現代商務服務業,包括組織管理服務、投資管理服務等。
企業“經營范圍”的K-means聚類結果如圖4所示。由于多數企業的“經營范圍”登記內容較多,因此從圖4可以看出,對“經營范圍”的聚類劃分并沒有“行業標簽”那么明確,但結論與基于“行業標簽”聚類分析的結果一致,即企業經營范圍同樣集中在“文體娛樂”“批發零售”“科學研究和技術服務”“租賃和商貿服務”這四類行業。受篇幅限制,聚類劃分結果不再展示。
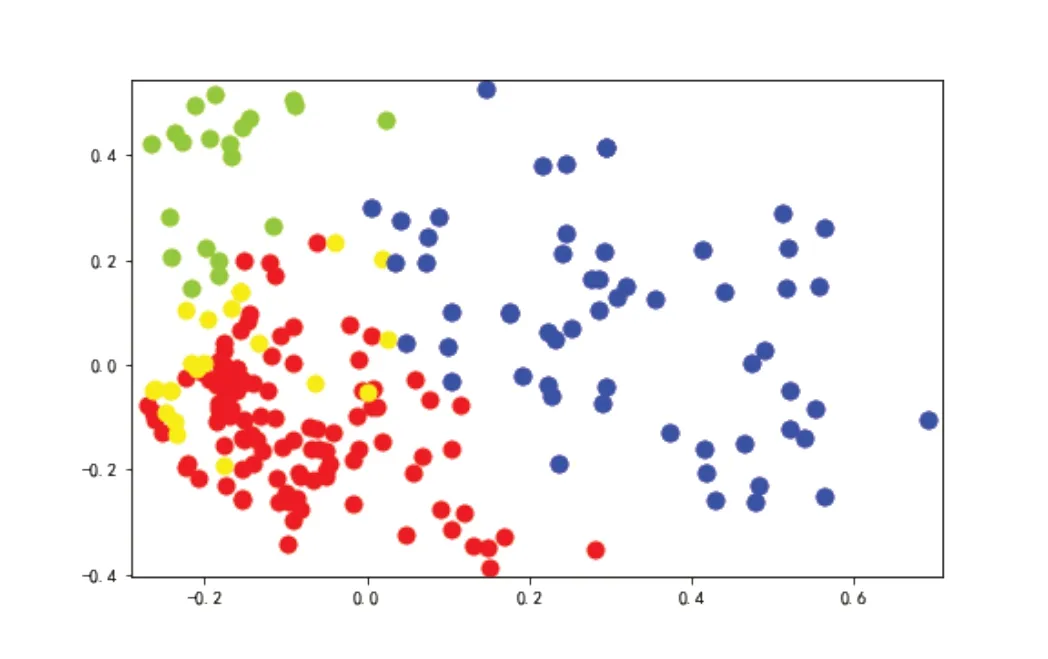
圖4 企業經營范圍聚類結果圖
2.5 企業畫像總結
本文基于以上對216家企業基本信息的描述性分析、詞頻統計分析、K均值聚類分析等,可以初步總結出P銀行2022年7月購買其理財產品的企業客戶畫像:企業主要集中于一線或新一線城市,以北京居多;大多數企業成立時間為10年左右或不足10年,注冊資本規模多在5000萬以下,人員規模多數少于50人,企業類型以有限責任公司居多,多數為非上市、非國有的獨資中小企業;所屬行業主要集中于文體娛樂業、批發和零售業、科學研究和技術服務業、現代商務服務業等第三產業,經營范圍既包括與“計算機”“機械設備”“電子產品”“化工產品”等工業相關的內容,也有與“技術開發”“技術咨詢”“技術轉讓”等高新技術服務業相關的內容。
3 結語
本文以某股份制P銀行為例,獲取2022年7月購買了該商業銀行某個理財產品的企業客戶名稱,通過Python在企查查官網上爬取企業的基本信息后,基于描述性分析、文本分析和K均值聚類等方法對該銀行的企業客戶畫像進行分析,總結發現:購買該理財產品的企業主要集中于一線或新一線城市,以北京居多;大多數企業成立時間為10年左右或不足10年,注冊資本規模多數在5000萬以下,人員規模多數少于50人,企業類型以有限責任公司居多,多數為非上市、非國有獨資的中小企業;所屬行業主要集中于文體娛樂業、批發和零售業、科學研究和技術服務業、現代商務服務業等第三產業,經營范圍既包括與“計算機”“機械設備”“電子產品”“化工產品”等工業相關的內容,也有與“技術開發”“技術咨詢”“技術轉讓”等高新技術服務業相關的內容。銀行在進行產品營銷時,可通過以上總結的企業特征,尋找或挖掘出企業客戶潛在的理財需求。
本文涉及的企業基本為未上市的中小企業,多數企業甚至沒有官方網站,因此只能在“企查查”等公開的信息登記網站上爬取企業的基本信息。如果能從銀行獲得更多維企業相關的數據,如企業在該銀行登記的財務數據、該企業歷史存貸款數據、企業歷史購買理財產品的數據、企業理財需求的偏好數據等,對企業畫像的研究也將更加全面豐富,從而幫助銀行更快、更高效地判斷出哪些企業有購買該理財產品的可能性。
猜你喜歡
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
云南畫報(2020年9期)2020-10-27 02:03:26
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
