基于BIRCH 算法的配電網設備多源數據融合存儲技術研究
2023-08-19 09:59:50姜英涵
電子設計工程 2023年16期
張 軍,陳 霄,何 育,張 旺,姜英涵
(1.國網江蘇省電力有限公司,江蘇 南京 210000;2.國網江蘇省電力有限公司經濟技術研究院,江蘇 南京 210000;3.國網經濟技術研究院有限公司,北京 100000)
近幾年,全球不可再生能源含量加速減少,加之工業、貿易等多個行業的迅速崛起,導致對電能的需求逐漸攀升[1-2]。為滿足電能需求,我國不斷擴大電網建設規模。而對于電網而言,配電網是關鍵部分之一,其能夠起到輸電網與用戶之間的“橋梁”作用。配電網在輸電網接收電能,通過配電設備將電能合理分配至用戶,其由架空線路、桿塔、電纜、配電電壓器、無功補償器、隔離開關及附屬設施等構成,在電網中承擔著分配電能的關鍵功效。
配電網設備在長期運行過程中會受到電、熱、負荷與自然環境等因素的影響,導致設備出現磨損、腐蝕及老化等現象,進而致使設備性能與可靠性下降。此外,長期在高溫度與高電壓的環境下工作,配電網設備絕緣材料性能也會隨之出現一定程度的變化,導致絕緣性能下降甚至消失。為了保障配電網的順利運行,國內外相關學者對配電網設備數據存儲模型做了研究,并取得了一定的研究成果。文獻[3]提出一種多機構分布式數據存儲網絡設計,其將相同存儲節點的數據集合至一個簡單的網絡模型中,并融合多機構分布式數據存儲網絡,設計該模型的代碼框架,以此得到配電網設備數據存儲模型。文獻[4]提出配電網剩余供電能力實用模型,通過RSC(Residual Supply Capacity)模型改進配電網供電數據模型,并考慮網絡重構,進而提出適用于分段開關的剩余供電能力模型。
上述方法能夠及時對設備運行狀態進行了解,力爭最快速度地維修或更換配電網設備,避免安全事故的發生。但隨著配電網規模的擴大及設備復雜程度的提升,配電網設備數據呈現海量化特性,這就對配電網設備數據存儲提出了更高的要求。智能配電網環境下,設備運行數據量劇增,遠超出傳統配電網設備數據存儲模型的范疇,為此該文提出了一種新的配電網設備數據存儲模型。對電網設備數據進行預處理,并引入CMCH(Copies Multiple Consistent Hashing)算法對配電網設備多源數據進行并行關聯處理,實現同類型數據的歸類融合;再通過BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)算法計算各配電網設備并行關聯數據庫的質心;且利用證據理論完成各數據庫代表性信息的組合,從而實現配電網設備多源數據的融合。同時通過Hadoop 分布式平臺構建配電網設備數據存儲模型的整體架構,并利用Hbase 數據管理實現電網數據的關聯融合、管理與查詢。通過海量信息處理降低配電網設備數據存儲的壓力,以滿足現今智能配電網設備數據的存儲需求,且保障配電網及電力系統正常、穩定及可靠地運行,進而為用戶提供更加優質的電能供給。
1 配電網設備數據存儲模型
構建配電網設備數據存儲模型,首先需要搭建配電網設備數據存儲架構。基于Hadoop 分布式平臺及Hbase 數據處理方案對設備數據進行有效的管理;針對設備多源數據,先利用CMCH 算法過濾無用信息,再通過設置組建和標記對多源數據進行關聯輸出,并對多源數據進行融合處理,以此提升配電網設備海量數據的存儲性能。
1.1 配電網設備數據存儲架構搭建
為滿足現今智能配電網設備數據存儲需求,基于Hadoop 分布式平臺搭建配電網設備數據存儲模型架構,如圖1 所示。
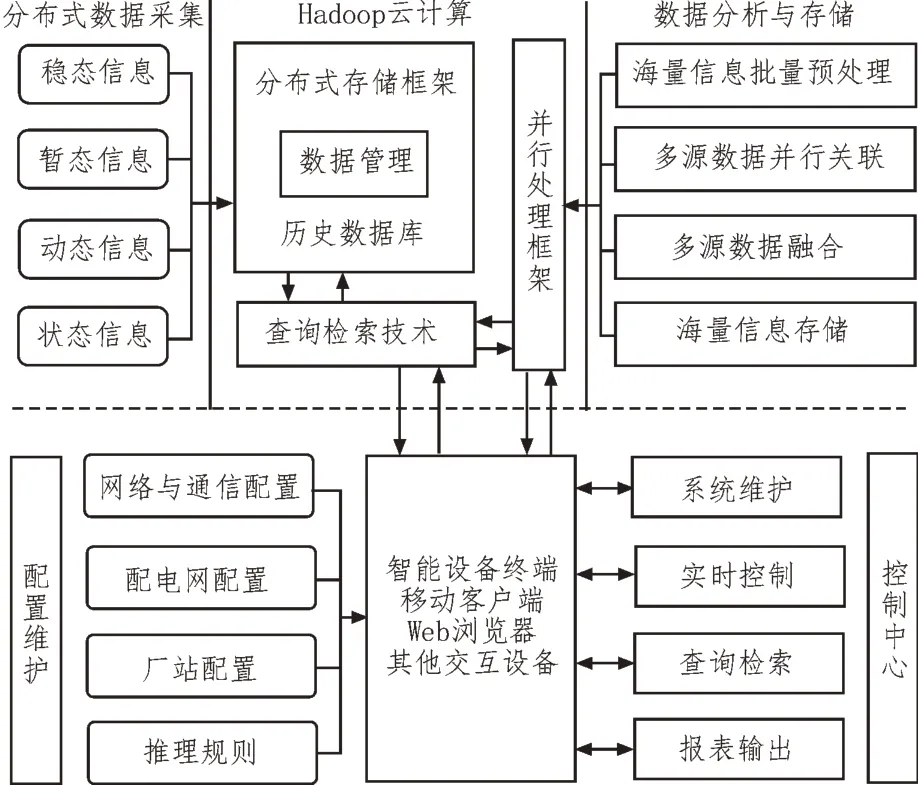
圖1 配電網設備數據存儲模型架構
由圖可知,配電網設備數據存儲模型架構中,利用可擴展采集模塊獲取配電網設備數據,并將全部數據上傳至Hadoop 云計算模塊;再利用Hbase 對設備數據進行有效管理與查詢;同時,通過數據分析與存儲模塊對設備數據進行預處理、并行關聯及融合;最終,對設備數據進行分布式存儲。
1.2 配電網設備海量數據處理
依據上述搭建的配電網設備數據存儲模型架構,獲取配電網設備海量數據[5]。設備數據獲取過程中,受電力干擾、惡劣環境、設備自身脆弱性等多種因素的影響,設備數據中存在海量的干擾、重復數據等。因此,為降低設備數據存儲壓力,需對配電網設備海量數據加以處理。
1.2.1 配電網設備多源數據并行關聯
配電網設備數據包含設備標識、數據采集時間、環境微氣象數據等,為方便設備數據的存儲與讀取,對設備多源數據實現并行關聯,構建關系數據庫[6]。
基于CMCH 算法并行關聯配電網設備多源數據,具體流程如圖2 所示。

圖2 并行關聯設備多源數據流程
依據圖2 所示流程,以電纜、配電電壓器、無功補償器與隔離開關等設備為例,展示配電網設備海量數據并行關聯流程[7]。配電網設備并行關聯數據庫主要包含設備標識文件表、數據采集時間文件表與環境微氣象數據文件表三部分,具體如表1-3所示。

表1 設備標識文件表
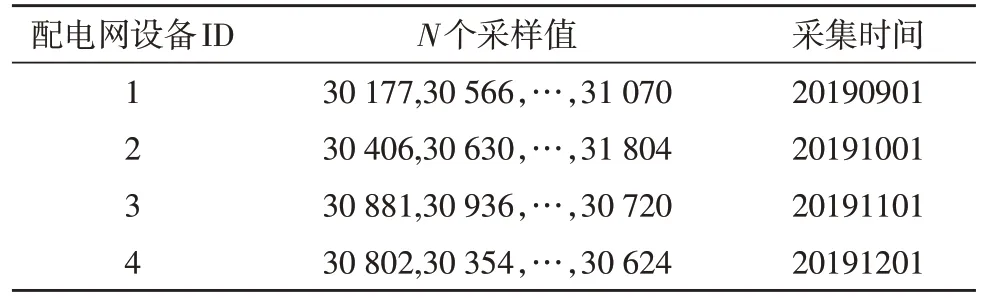
表2 數據采集時間文件表

表3 環境微氣象數據文件表
將上述3 個文件表數據進行并行關聯,以降低設備數據存儲的文件數量,獲得設備數據并行關聯結果如表4 所示。

表4 設備數據并行關聯結果
1.2.2 配電網設備多源數據融合
根據上述配電網設備多源數據并行關聯結果,利用BIRCH 算法對設備多源數據進行融合處理。BIRCH 算法計算出各配電網設備并行關聯數據庫的質心。并以此為代表,利用模糊隸屬度函數對融合目標涉及的質心信息與屬性的基本概率進行賦值,形成各數據庫的代表性信息[8]。最后,利用證據理論完成各數據庫代表性信息的組合,實現配電網設備多源數據的融合[9]。基于BIRCH 算法的配電網設備多源數據融合主要步驟如下。
步驟1:依據采集配電網設備多源數據的特征[10],確定融合目標涉及全部屬性,記為A1,A2,…,An;
步驟2:依據步驟1 確定的融合目標屬性A1,A2,…,An,結合配電網設備多源數據規模及特征來確定BIRCH 算法的分支因子B與閾值T,并設置分支因子與閾值初始值分別為B=10 與T=1;
步驟3:加載上節生成的配電網設備并行關聯數據庫,將其記為C1,C2,…,Cr;
步驟4:計算配電網設備并行關聯數據庫C1,C2,…,Cr的質心信息,記為Q1,Q2,…,Qr;
步驟5:根據實際配電網設備數據存儲需求[11-12],明確辨識框架為Θ:{H1,H2,…,Hk} ;
步驟6:構建模糊模型標記,依據Θ:{H1,H2,…,Hk}的樣本數據,針對樣本數據的某個屬性Ai,確定該屬性下的最小值、最大值及平均值,并以此為基礎構建一個三角形模糊數[13],描述命題Hj,其所對應的隸屬函數為,i=1,2,…,n;j=1,2,…,k。
步驟7:針對屬性Ai,計算每個配電網設備并行關聯數據庫的平均方差,以此為基礎,將實際采集設備數據擴展為能夠表示的三角模糊數,從而獲取觀測函數,記為gAi(x);
步驟8:計算采集設備數據與模糊模型標記間的似然度,即觀測函數gAi(x)與模糊模型標記曲線相交部分縱坐標最大值,記為
步驟10:針對步驟4 得到的質心信息,基于選定的屬性A1,A2,…,An,重復步驟6-9,生成每個質心信息所對應的n條證據;
步驟11:依據證據理論組合公式,并融合步驟10 獲得的n條證據,構成反映配電網設備并行關聯數據庫Ci對融合目標支持程度的合成證據cmj(Hj);
步驟12:計算cmj(Hj)的權重數值,計算公式為:
步驟13:依據證據理論組合公式與權重數據,融合處理步驟11 合成證據cmj(Hj),獲取最終配電網設備多源數據融合結果。
對基于BIRCH 算法的配電網設備多源數據融合方法進行算法計算代價分析,算法時間復雜度O(n)的計算公式為:
式中,ni為算法迭代總次數,為每次迭代中基本操作執行次數。由此得到算法計算代價分析,如圖3 所示。

圖3 算法計算代價分析
由圖可知,隨著迭代次數的增加,時間復雜度數值增長的趨勢也逐步變大。這表明算法基本操作所執行的次數較多,可行性較好。
1.3 配電網設備數據存儲
以上述獲取配電網設備海量數據處理結果為基礎,在Hadoop 分布式平臺上采用一致性哈希算法(consistent Hashing)來存儲配電網設備數據,并實現其數據存儲模型的運行。
一致性哈希算法的基本思想為:依據數據關聯性,應用該算法將關聯數據映射并存儲在相同節點上,進而實現設備數據的存儲[14]。此種設備數據存儲模型在數據查詢時,極大地減少了Map 節點與Reduce 節點間的通信開銷,從而提升了模型的整體存儲性能。
基于一致性哈希算法[15]的配電網設備數據存儲流程描述如下:
步驟1:加載配電網設備海量數據融合結果,通過配置文件定義數據副本數量;
步驟2:計算Hadoop 分布式平臺各個數據節點的哈希值,并依據規則將其配置到一個0~232的哈希環區間上,再應用MD5 散列算法(Message Digest Algorithm 5)形成128 bit 散列值,并選取其中的32 bit作為哈希值;
步驟3:依據配電網設備數據采集時間屬性、關聯數據屬性計算設備數據的哈希值,并將其依次映射到哈希環上;
步驟4:依據步驟2-3 獲取的數據節點及數據哈希值確定設備數據的存儲位置,并按照逆時針方向將設備數據映射至最小距離的數據節點上;
步驟5:若設備數據存儲節點出現失效或異常等現象,此時需將失效或異常數據節點上的設備數據進行重新映射與分布,直至設備數據全部存儲結束。
基于上述過程,構建配電網設備數據存儲模型,如圖4 所示。
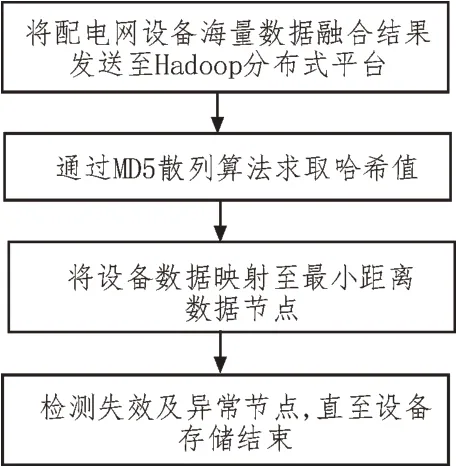
圖4 配電網設備數據存儲模型
通過上述過程實現了配電網設備數據存儲模型的運行,為配電網設備故障預防提供了精準的數據支撐,且保證了配電網穩定運行[16]。
2 實驗結果與分析
為證實構建模型與傳統模型的性能差異,采用Matlab 軟件設計仿真對比實驗,具體實驗過程如下。
2.1 Hadoop分布式平臺搭建
仿真實驗Hadoop 分布式平臺包含一個主控節點,19 個數據節點,共計20 個節點的集群。其中,主控節點與數據節點配置相同,具體配置數據如表5所示。

表5 主控節點與數據節點配置表
依據表5 數據搭建Hadoop 分布式平臺,示意圖如圖5 所示。

圖5 Hadoop分布式平臺示意圖
2.2 實驗數據集準備
為驗證構建模型的存儲性能,選取了不同大小的實驗數據集,其規格如表6 所示。
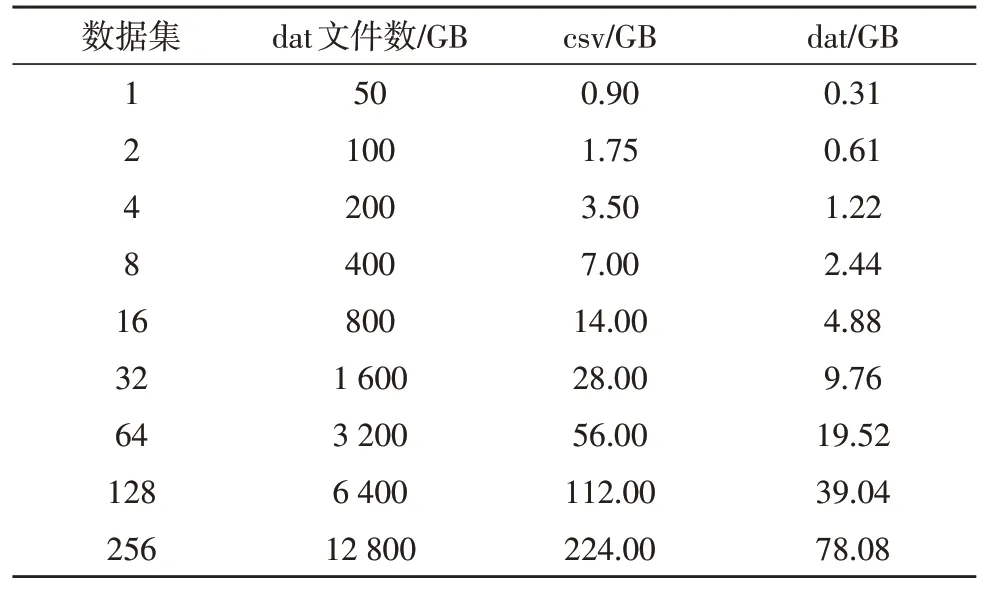
表6 實驗數據集
如表4 所示,csv 表示的是文本格式文件;dat 表示的是二進制文件。
2.3 數據分析
依據上述所搭建的Hadoop 分布式平臺,選取實驗數據集并進行仿真對比實驗。通過數據上傳速率與數據壓縮比來反映模型性能,實驗結果分析過程如下[17]。
2.3.1 數據上傳速率分析
通過仿真實驗獲取數據的上傳速率,如表7所示。
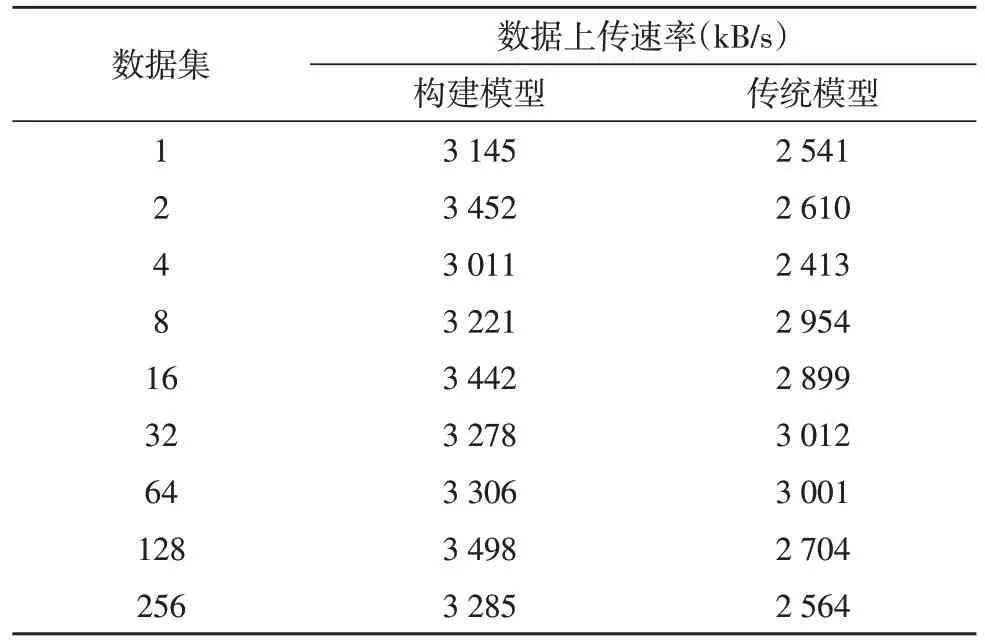
表7 數據上傳速率數據表
從表7 中可以看出,構建模型數據上傳速率范圍為3 011~3 498 kB/s,傳統模型數據上傳速率范圍為2 413~3 012 kB/s。通過對比發現,構建模型的數據上傳速率遠高于傳統模型。
2.3.2 數據壓縮比分析
通過仿真實驗獲取壓縮比數據,如表8 所示。
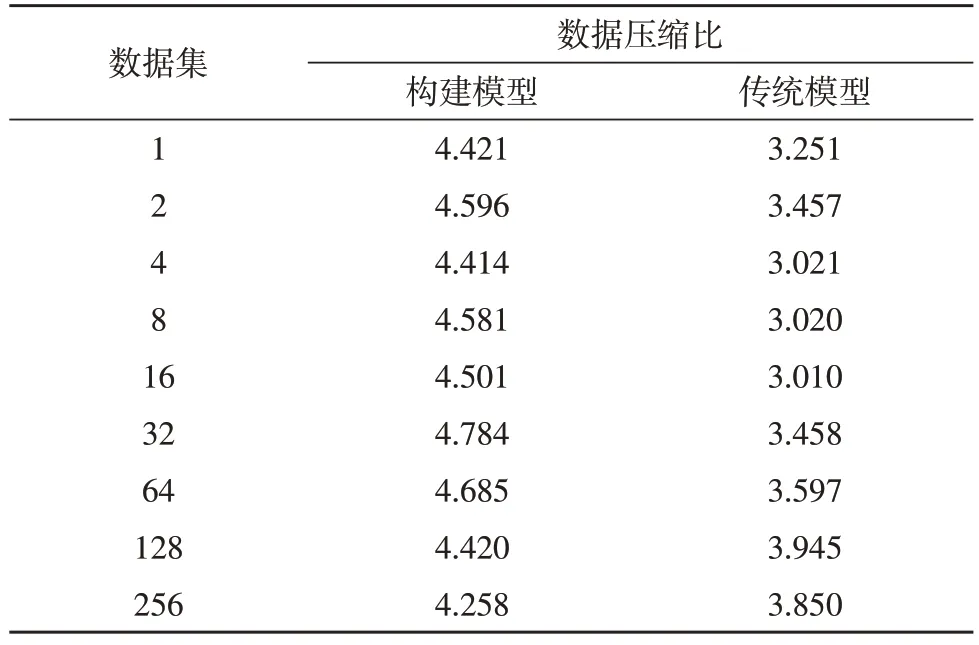
表8 數據壓縮比數據表
如表8 中數據顯示,構建模型數據壓縮比范圍為4.258~4.784,傳統模型數據壓縮比范圍為3.010~3.945。通過對比發現,構建模型的數據壓縮比遠高于傳統模型。上述實驗結果表明,與傳統模型相比,該文構建模型的數據上傳速率較高、數據壓縮比更大,驗證了該模型設備數據存儲性能更優。
2.4 實例驗證
選取某省市內8家供電公司管轄的配電網,來對基于海量信息處理的配電網設備數據存儲模型進行實證研究。統計選取2019年10-12月8家供電公司的電力數據共1 000 MB,包括正常運行信息500 MB、停電檢修信息300 MB 及裝置故障信息200 MB,對1 000 MB 電力數據進行分類整理,得到數據存儲結果如表9 所示[18]。

表9 數據存儲結果
分析表9 可知,采用所構建的模型對電力數據的分類結果與實際數據一致,而傳統模型的數據分類結果與實際值差別較大。通過實證分析可知,所設計模型的數據分類存儲效果較好,能夠實現配電網設備數據的準確存儲。
3 結束語
為提升智能配電網設備數據的存儲效率及安全性,此研究構建配電網設備數據存儲模型,并將海量信息處理引入至該存儲模型中,實現數據的安全存儲。實驗結果表明,應用所設計的模型后,極大地提升了模型的數據上傳速率與數據壓縮比,節省了海量的存儲空間,并有效提升了電網數據的存儲性能,從而為配電網設備數據存儲提供了新的手段支撐。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
當代陜西(2021年17期)2021-11-06 03:21:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
電測與儀表(2016年5期)2016-04-22 01:14:14
河南電力(2016年5期)2016-02-06 02:11:24
