噪聲作用下的人臉面部情緒表情研究
2023-09-11 08:33:28閆靚周卉婷李爭光
西北工業大學學報 2023年4期
閆靚, 周卉婷, 李爭光
(1.西北工業大學 航海學院, 陜西 西安 710072; 2.浙江科技學院 建筑系, 浙江 杭州 310023)
煩惱是一種消極的復雜情緒[1]。噪聲煩惱度(簡稱:“煩惱度”)包含人對噪聲的體驗、態度和行為,反映了人對噪聲的情緒認知[2]。一直以來,學界多以基于調查或實驗的主觀方法測量煩惱度[3-4],其本質上屬于心理學中的“內省法”[5]。雖然人類有能力借助語言自述情緒狀態,但因“內省法”存在固有缺陷(如回想準確度低、潛在心理活動無法內省、意識到的心理活動未必能盡數精準報告以及存在不愿報告或虛假報告的情況),相關結果常受質疑(如客觀性差、難再現、無法檢驗等等)[6]。此外,噪聲自身屬性(令人討厭的、不需要的聲音)[7]引發的負性情感定向作用(消極暈輪效應)會導致評價結果偏差[4]。加之人類反應的個體差異性、時變性以及情感成分和交感神經系統活動的調節機制等,都使煩惱度的評價與預測深奧莫測,舉步維艱。
了解、認識和評價噪聲引發的情緒效應,對實現精準高效的噪聲控制至關重要。從噪聲刺激下的生理喚醒開始,聽音者對聲環境的需求和愿望在其感受噪聲的過程中經自我比較,形成自我體驗,最終顯現為可觀察的行為(或表情,如面部表情、姿態表情和語調表情)。表情是情緒的外部表現,也是最有效的情緒顯示器[8]。面部表情是最自然的情感表達方式之一[9],能夠實現非侵入方式下的即時觀測,具有可靠指示哺乳動物(包括人類)情緒體驗的潛力。這種潛力不僅具有物種間的普遍性和特異性,還能適應個體差異。面部肌肉豐富細微的變化能夠以“刺激-反應聯結”(stimulus-response [S-R] connection)的形式表征情境中的刺激與個體情緒狀態(類型/程度)之間的關系。不僅如此,人類觀察者與生俱來的觀察偏見使其總會將注意力集中于被觀察對象的面部區域[10]。這種“精準定位”的能力對實現高效的情緒識別和正確的心理評估十分有利[11]。在噪聲煩惱度研究中,如能將主觀的情緒評估與客觀的面部肌肉運動測量相結合,定會在最大程度上實現煩惱度的準確評價性[12]。
于是,提出2點設想:①是否存在一種典型的面部表情與噪聲引發的煩惱情緒相互對應;②當聽音者出現“煩惱”情緒時,其面部肌肉的運動模式是否與噪聲特性密切相關。若上述2種假設均成立,即可實現以客觀的面部肌肉運動度量不同類型噪聲作用下的聽音者煩惱度,突破現階段研究方法的圈囿,創新噪聲煩惱度評價體系與評估方法。
為此,本文主要開展了以下工作:設計并完成噪聲作用下的聽音者面部表情與生理信號采集實驗,獲得10種類型噪聲作用下、30位不同國籍聽音者的面部視頻影像(時長總計9 360 s)、生理數據(心率值)與自報告煩惱度。隨后,參考面部動作編碼系統(facial action coding system,FACS)確定了噪聲作用下聽音者煩惱情緒的AUs組合表達。同時,創設了集視覺情感符號(emoji表情符號)、明度變化的單色相(灰色)尺度與傳統言語尺度和數字尺度于一體的煩惱度(五級)量表,依托自主開發的移動端應用程序[13](凡響?,Awesound?)借助大規模網絡調查對相關技術方法的有效性進行了驗證。
1 融合聽音者面部表情采集的噪聲煩惱度評價實驗
1.1 實驗準備
1.1.1 聲音的選取
目前,對噪聲的分類方法主要有:按物理特性分類、按機能意義分類、按感覺特征分類、按情感色彩分類[14]。通過對現有國家標準中噪聲分類方法與各類噪聲定義的全面搜集、整理與總結歸納,本文將噪聲的物理特性與機能意義結合,綜合聲音的時、頻域特征與來源,優化現有分類體系并借助網絡資源,分類搜集了368段音頻文件。從中選取了10段極具代表性且囊括噪聲分類體系中所有類別標簽的聲音(經裁剪后時長均為30 s)作為誘發聽音者情緒的聲刺激物(即聲樣本),見表1。實驗過程中,聽音者聆聽噪聲的總時長為300 s,最大等效連續A聲級不大于97 dB(A),符合GBZ/T 189.8-2007《工作場所物理因素測量 第8部分:噪聲》的要求。
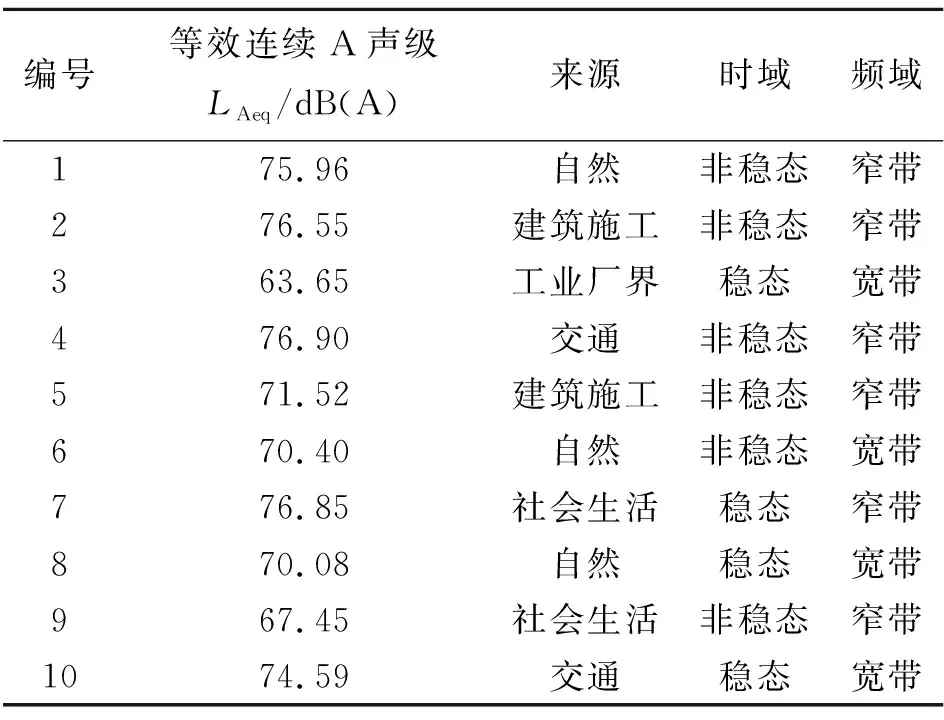
表1 各聲樣本參數及分類
1.1.2 問卷設計
相比文字和數字,色彩和圖形會帶給人更加直觀的認知體驗與情緒共鳴[15]。本研究嘗試將色彩融入傳統的煩惱度評價(描述詞+數字)量表,創新問卷形式。具體做法如下:①調查適于表征“煩惱”情緒的色彩量表:a)探尋刻畫煩惱情緒的單色色相;b)在a)的基礎上,構建“以明度變化表示感受程度”的評價量表。②實施在線調查,驗證新量表的有效性。調查發現:77.69%的被調查者傾向于以“明度變化的單色相尺度”衡量煩惱情緒的(程度)變化;40.9%的被調查者認為“灰色”能夠更好地映射“煩惱”情緒。據此,決定以深淺不同的灰色構建噪聲煩惱度評價量表。
1.2 實驗實施
1.2.1 實驗流程
本研究及相關實驗程序由上海精神衛生中心倫理委員會批準(批件號:2021-53),符合NMPA/GCP和《赫爾辛基宣言》。實驗招募13~52歲之間、聽力正常的聽音者共30人(男17人,女13人;平均年齡27.5歲)。其中,中國籍25人,外籍5人。實驗前,所有聽音者均簽署了實驗告知書,明確告知其有權在身體不適時隨時暫停或退出實驗且本人同意研究者使用其個人肖像。實驗中,聽音者先佩戴耳機聆聽純音樂(1 min),熟悉環境,平復心情,實驗員開啟攝像機并記錄心率。隨后,隨機依次播放10段聲樣本(兩樣本間設置1 min靜默時間,以便填寫問卷),待10段聲樣本全部播放完畢,結束視頻錄制和心率采集,回收問卷,結束實驗(見圖1)。
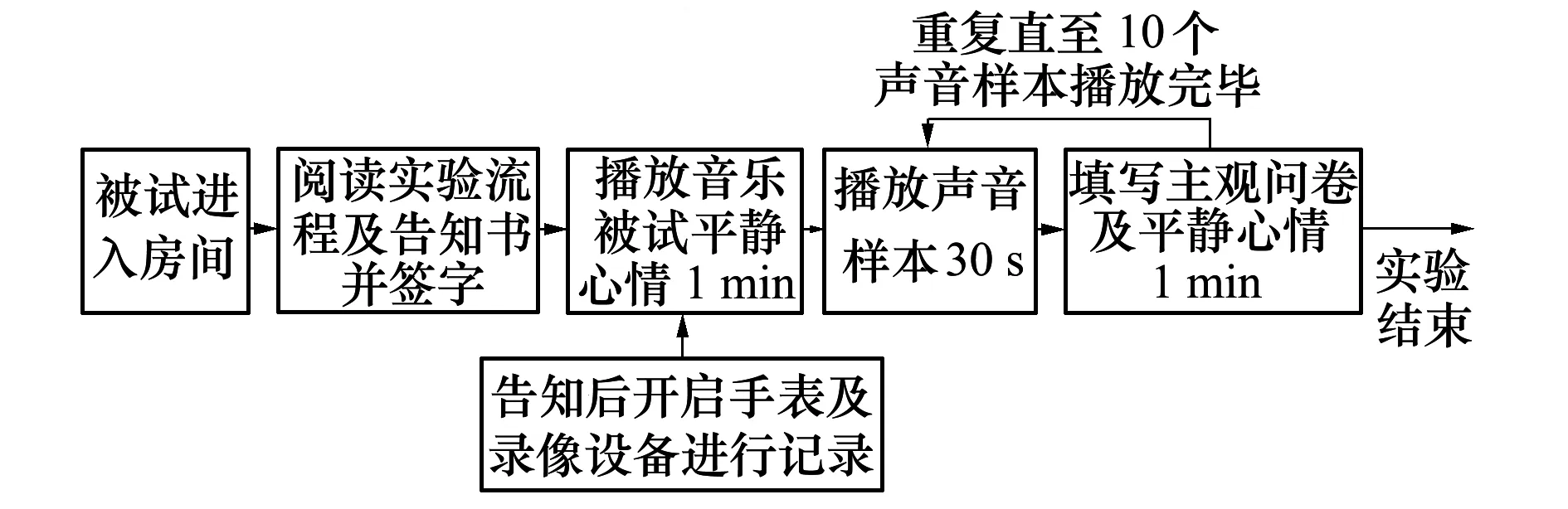
圖1 實驗流程圖
1.2.2 面部表情采集
將煩惱度研究中慣用的聽音實驗與心理學研究中的行為觀察相結合,在聽音者完成聽音評價任務的同時錄制其聽音過程中的面部表情變化。
參考中國情緒圖片系統[16]制作方法,以SNOY EX280攝像機錄制聽音者在整個聽音過程中的面部表情。攝像機位于聽音者正前方4.5 m處,鏡頭高度與其面部持平。聽音者座位上方天花板安裝4盞補光燈(其中2盞置于聽音者正上方,另外2盞分置于聽音者左右側斜上方),以提供高強度的穩定照明(見圖2)。錄制視頻分辨率1 920×1 080,幀率25 frame/s。

圖2 實驗現場
聽音室(11.2 m×7 m×2.8 m)四周及頂部均鋪設吸聲材料,本底噪聲符合NC20(《Criteria for Evaluation Room Noise》)[17]。室內溫度21~30℃,濕度適宜,布局布置參考 GB/T 13868-1992《感官分析:建立感官分析實驗室一般導則》。實驗中,聲樣本經Artemis軟件和雙耳耳機均衡器(HEADlab-compatible binaural headphone equalizers labP2)調制后,由動圈式高保真立體聲頭戴式耳機(SENNHEISER HD600)回放給聽音者。
為了驗證Ekman等人提出的:人在不同情緒狀態下會呈現出可觀測的生理反應[18](如憤怒與恐懼時心率提升);實驗中使用HUAWEI-B5手環同步采集聽音者心率(采樣頻率1次/30 s),用以探索聽音情緒的產生和變化與心率波動之間的關系。
2 實驗結果與分析
2.1 聽音者自報告煩惱度分析
定義3種參數,分析聽音者依據圖1量表判定并報告的個人煩惱等級(描述詞):
1) 平均煩惱度Am:首先,依據以下規則對聽音者個人判定并報告的煩惱等級進行賦值:“一點也不”(not at all)賦分值“0”,“輕微”(a little)賦分值“1”,“中度”(moderate)賦分值“2”,“非常”(very)賦分值“3”,“極度”(extremely)賦分值“4”;計算(全部聽音者對)10個聲樣本的個人煩惱度平均值,獲得每個聲樣本的Am。
2) 易感煩惱率Psensitive:某聲樣本的煩惱等級為“中度及以上(包括“中度”、“非常”或“極其”)”的結果占全部評價數據量的百分比;當Psensitive>50%時,即可判定該聲樣本“易致人煩惱”。
3) 煩惱度A:根據“易感煩惱率”判定:當50%≤Psensitive<75%,對應聲樣本的煩惱度為“高”;當Psensitive≥75%,對應聲樣本的煩惱度為“極高”;此外,聲樣本的煩惱度為“低”。據此,獲得全部聲樣本的相關評價數據,見表2。
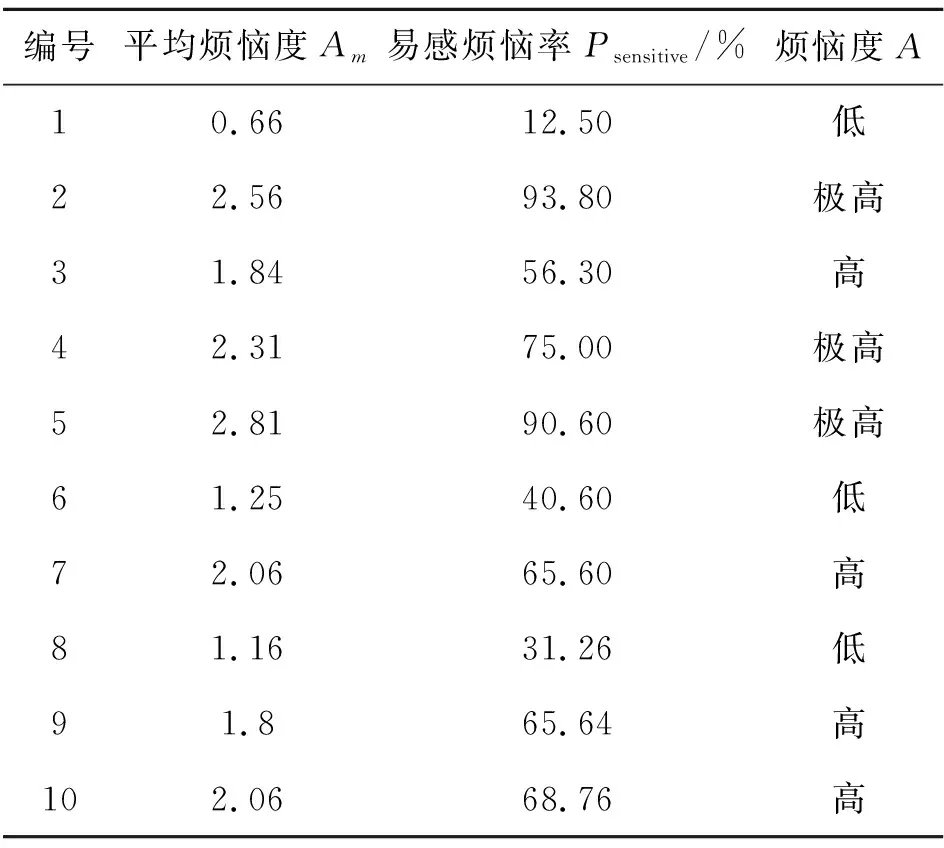
表2 聲樣本煩惱度分析結果
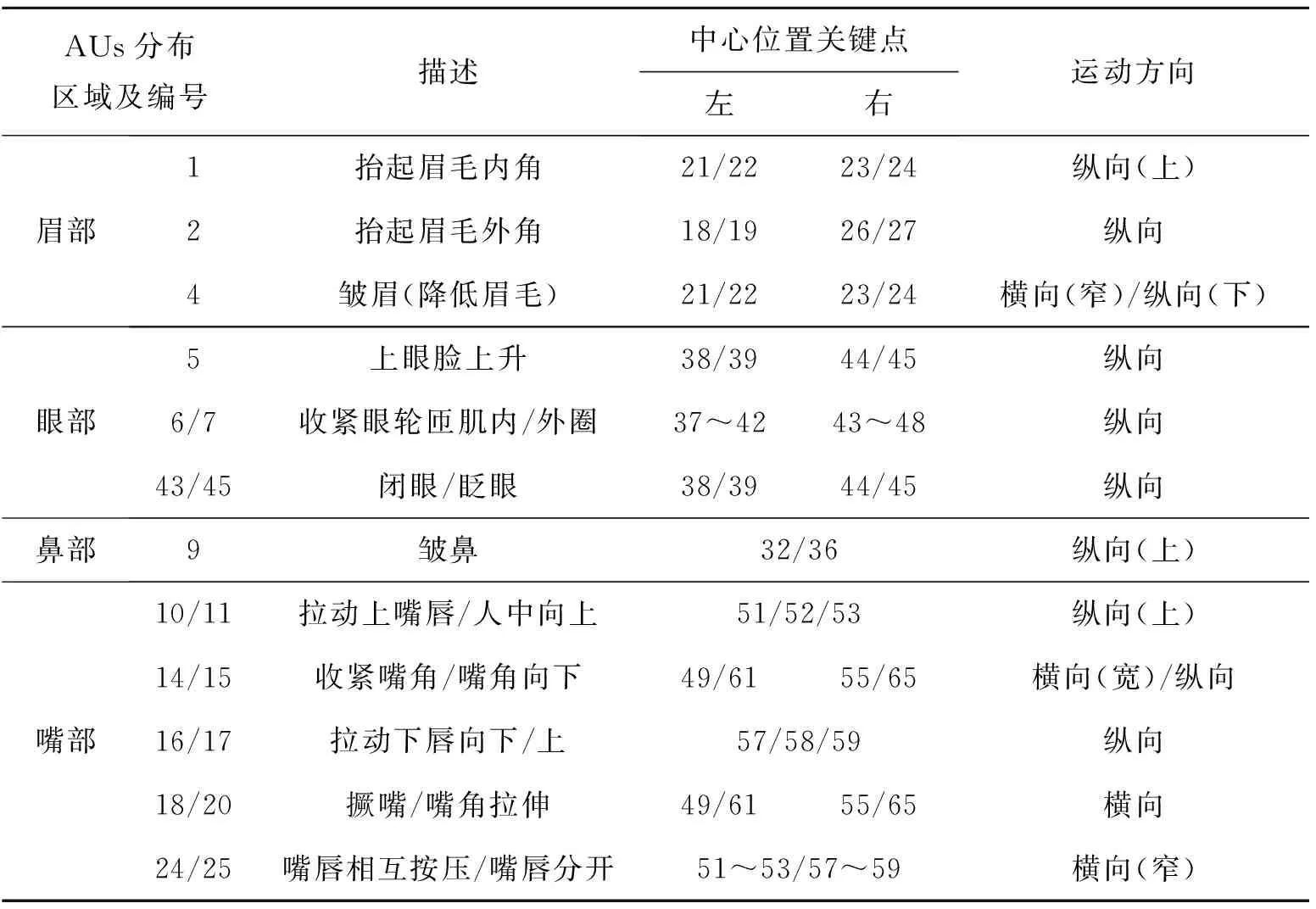
表3 與煩惱相關AUs及其中心點與關鍵點對應關系
2.2 聽音者面部情緒表情分析
在探究與“煩惱”情緒相關的面部表情之前,首先,將人臉面部分為眉部、眼部、鼻部、嘴部及外輪廓。結合FACS中對AUs的描述,選擇眉部:抬起眉毛內角(AU1)、抬起眉毛外角(AU2)、降低眉毛(AU4),眼部:上眼瞼上升(AU5)、眼輪匝肌內/外圈收緊(AU6及AU7)、眨眼(AU43)、閉眼(AU45),鼻部:皺鼻(AU9),嘴部:拉動人中/嘴唇向上(AU10及AU11)、收緊嘴角(AU14)、拉動嘴角向下(AU15)、拉動下唇向下(AU16)、推動下唇向上(AU17)、撅嘴(AU18)、嘴角拉伸(AU20)、抿嘴(AU24)、嘴唇分開(AU25)的運動進行統計及分析。具體分析步驟如下:
1) 首先,對所采集到的300段視頻進行圖像配準,以消除頭部偏轉導致的無關抖動。采用dlib庫中訓練好的人臉關鍵點模型進行面部關鍵點提取,獲得人臉輪廓0~17號關鍵點,眉部18~27號關鍵點,鼻部28~36號關鍵點,眼睛37~48號關鍵點,嘴部49~68號關鍵點(見圖3)。
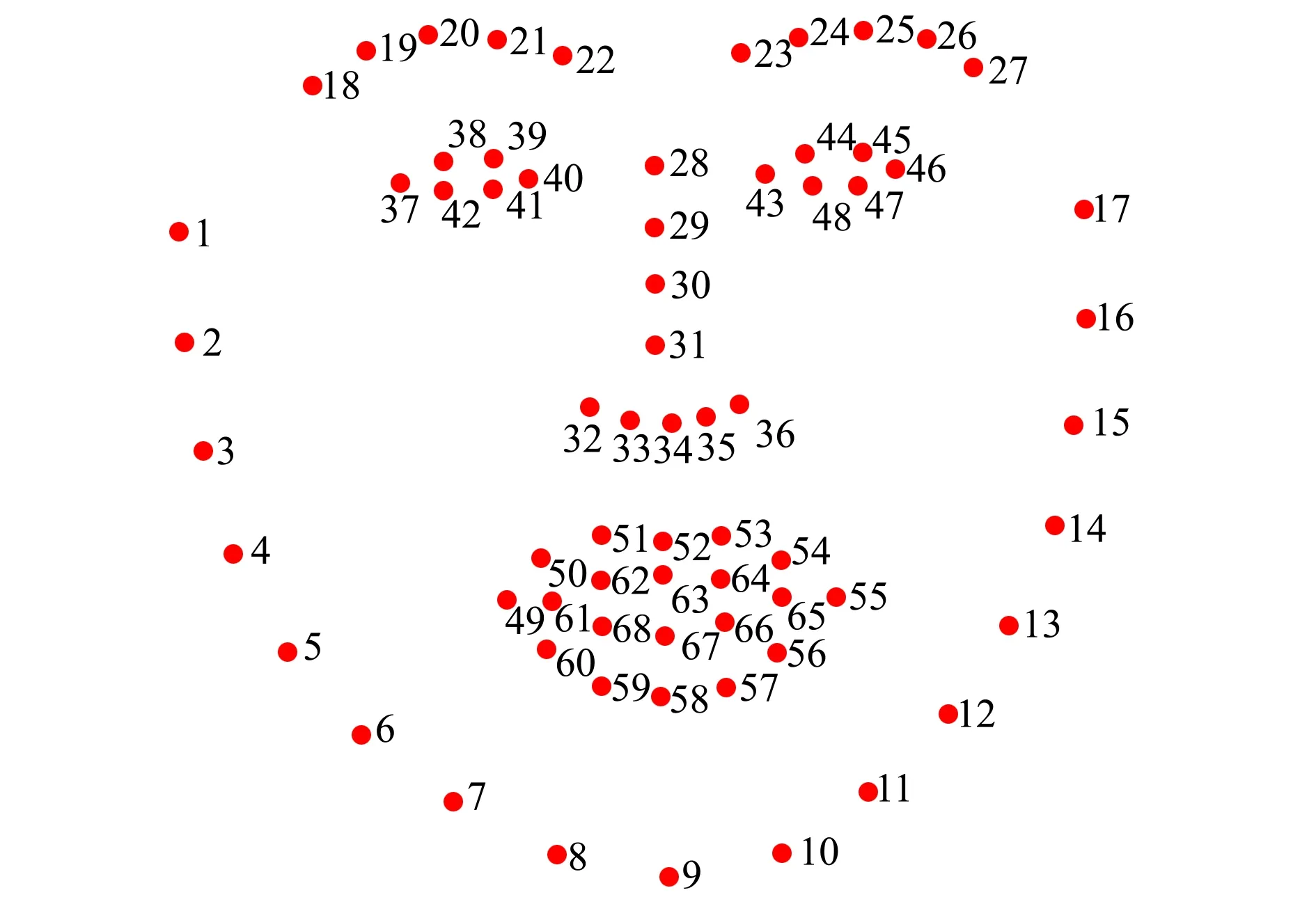
圖3 人臉面部圖像處理中的關鍵點
2) 根據既有研究[19-20]對AUs 的區域劃分(見圖4),確定其中心點與上述68個面部關鍵點間的對應關系,并對關鍵點的運動趨勢進行了人工標注(見第3節)。
3) 接著,根據面部關鍵點的位置變化,輔以人工觀察,判定并標注與煩惱情緒密切相關的面部AUs。
4) 最后,統計每段視頻中各AUs運動的次數。
3 煩惱情緒面部表情關鍵特征提取與有效性驗證
現有面部情緒分析理論與計算方法均未涉及復雜情緒面部特征的描述與表征。煩惱是一種典型的復雜情緒。為了尋找“易感煩惱”噪聲作用下聽音者面部情緒表情的顯著特征,構建基于FACS的煩惱情緒面部AUs組合。分析30位聽音者在聆聽“高”與“極高”煩惱度聲樣本(共7個)時的面部影像(時長總計為6 300 s),具體做法如下:對面部變化區域進行劃分并對其中涉及面部AUs的關鍵點進行運動狀態變化的時間統計分析,完成關鍵表情特征的揀選、分類與重組。
研究發現:聽音者面部表情可分為習慣性面部表情及情緒引發的面部表情兩類。前者為聽音者在平靜狀態及整個聽音過程中均出現的面部表情,包含張嘴(AU25),快速眨眼(AU45)等。習慣性面部表情具有顯著的個體性差異性。而情緒引發的面部肌肉運動在聽音者自報告不同煩惱度時,面部表情呈現明顯可分的等級變化(見圖5)。可見,利用聽音者面部情緒表情的變化模式(即面部肌肉的具體的運動方式和幅度)評價噪聲煩惱度是可行的。統計30位聽音者在不同ANOYI等級的聲樣本影響下各面部AUs的平均運動頻次(見圖6),發現眉部的AU1、AU2、AU4,眼部的AU6和AU7和嘴部的AU14及AU20隨著聲樣本的ANOYI上升呈現出增長的趨勢,由此推測,上述AUs對解釋煩惱情緒具有普適性。結合FACS中用AUs對各類基本情緒的描述方法,將煩惱情緒下的面部運動定義為由眉毛內角(AU1)及外角(AU2)、降低眉毛(AU4)、眼眶收緊(AU6和AU7)、收緊嘴角(AU14)和嘴角拉伸(AU20)共同描述。

圖5 煩惱度程度尺度條對應面部情緒表情尺度
4 結 論
本研究踐行了跨領域融合創新,獲取了一個分析噪聲刺激作用下聽音者自然流露的面部情緒表情的數據集。其中,包括了30名聽音者在聆聽10段具有不同時頻特征聲樣本時的面部視頻及其對每段聲樣本的自報告煩惱度;以此為基礎,借助面部表情識別技術并配合人工標注,對發生運動的面部區域(以面部關鍵點的多少表征)及運動程度(以面部關鍵點運動頻率)進行分析統計,尋找與聽音(煩惱)情緒緊密相關的面部AUs。本實驗是對噪聲煩惱度研究的理論創新與方法變革的初步探索與大膽嘗試,期望能夠克服領域研究中大量主觀因素對研究結論客觀性的影響。誠然,面部情緒表情模型的正確構建和運動模式的精準識別,必須以全面、詳盡、充分的數據收集和分析為基礎。本文相關工作的完成,旨在促進建立集噪聲特性、聽音者生理數據、面部表情變化與自報告煩惱度于一體的研究型數據集和深入開展后續工作。為了實現合理嚴謹、科學可靠、靈活便捷、普適性強的噪聲煩惱度評估,避免傳統描述性評估技術流程繁瑣、成本密集、耗時耗力的弊端,提高研究的信度和效度,盡量減少使用模棱兩可的主觀感受描述詞與未經設計的心理反應量表,采用行為心理學的觀點和方法,通過直接觀摩、記錄、分析聽音者在聲刺激作用下的面部表情反應,闡釋其情緒狀態,用“看到的”而非“想到的”,評價“感覺”,預測“反應”,解釋“情緒”,從實際出發開展包括煩惱度在內的一切噪聲作用下的情緒效應研究。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商業評論(2014年6期)2015-02-28 04:44:25
