基于遷移模型集成的馬鈴薯葉片病害識別方法
2023-09-11 08:46:17章廣傳李彤何云高泉葉榮錢曄馬自飛
江蘇農業科學 2023年15期
章廣傳 李彤 何云 高泉 葉榮 錢曄 馬自飛
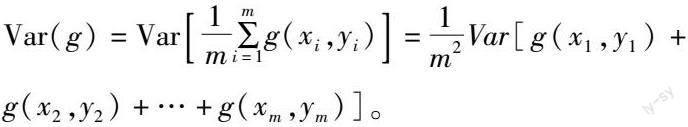
摘要:針對目前馬鈴薯葉片病害識別工作量大、準確率低且主觀性強等熱點問題,提出1種通過ResNet34模型結合不同遷移方式進行集成學習以快速識別馬鈴薯葉片病害圖像的方法。首先,利用多種遷移方式(全部參數遷移、特征提取、微調及全新訓練4種訓練方法),通過調整超參數,使模型快速收斂達到全局最優點。其次,使用混淆矩陣對多種遷移方式的訓練模型結果進行對比分析,微調模型識別準確率達到95.45%。最后,利用集成學習將3種訓練較優的模型進行集成并與微調模型進行對比。通過試驗建立了1個馬鈴薯葉片病害圖像數據集,結果表明,相比現有熱門神經網絡模型,該數據集無論是識別準確率還是識別效率均有顯著提升,通過對比發現,試驗的總體準確率提升了3.68百分點,達到99.13%,遷移學習能夠更快速地收斂,減少訓練時間,并且集成學習能夠大幅提升平均識別準確率。本研究提出的針對馬鈴薯葉片病害的識別方法成本低、精確率高,能更好地應用于日常病害識別中,為植物葉片病害的智能診斷提供借鑒和參考。
關鍵詞:馬鈴薯;病害識別;遷移學習;ResNet;集成學習
中圖分類號:TP183;TP391.41 文獻標志碼:A
文章編號:1002-1302(2023)15-0216-09
基金項目:國家自然科學基金(編號:32101611);云南省重大科技專項(編號:202002AE090010);云南省基礎研究計劃(編號:202101AU070096)。
作者簡介:章廣傳(1998—),男,安徽銅陵人,碩士,主要從事智慧農業研究。E-mail:1535797658@qq.com。
通信作者:李 彤,教授,主要從事智慧農業研究。E-mail:tli@ynu.edu.cn。
利用計算機圖像處理與模式識別技術對農作物的病害進行自動識別是當前研究的熱點。馬鈴薯與小麥、稻谷、玉米、高粱并稱為世界五大作物,中國是世界馬鈴薯總產量最多的國家。馬鈴薯病害發多于葉部,其中早疫病、晚疫病等等會對馬鈴薯的生長造成嚴重影響。目前,在作物病害識別研究中,計算機視覺技術已經發揮了舉足輕重的作用,尤其是對葉部病害的識別。大多數農作物病害的識別是通過傳統機器學習的方法進行的,包括支持向量機模型[1-3]等,但是這種方法的識別率較低、耗時長。卷積神經網絡模型[4-6]由可學習的權重和偏置常量的神經元組成,每個神經元都接收一些輸入,并做一些點積計算,輸出的是每個分類的分數,以及局部連接、池化等具體操作指令,使模型具有一點自我識別能力,從而提升在病害識別中的準確率。目前,卷積神經網絡已經在小麥、煙草及蘋果等病害識別中取得良好效果[7-9]。在實際場景的應用中,病害識別需要考慮許多實際因素,如光照條件、病害種類、病害程度等。直接使用卷積神經網絡訓練,可能會因為數據集過小或不夠多樣化,導致模型的準確率不夠理想[10]。
遷移學習是將已有的數據或模型應用在相關卻不同領域的問題中,通過在其他領域中學習到的知識來解決現有領域中數據不足的問題,從而提升學習的效率[11-13]。相關研究結果表明,遷移學習通過提升模型的魯棒性,能夠大幅縮短模型訓練時間。鄭一力等研究發現,將遷移學習應用在Inception-V3等網絡訓練可以很好地識別植物葉片病害[14]。張旭等改進了ShuffleNetV2模型,其對蘋果葉片病害的識別準確率達到98.95%[15]。隨著計算機圖像處理技術的發展,傳統機器學習具有的模型的復雜度高、難以應用于實際等問題越發凸顯,不適合移動設備的開發與應用。本研究基于以上研究,收集網絡上的馬鈴薯葉片病害數據集,將ResNet34、遷移學習與集成學習相結合,改進網絡的識別能力,以期為相關研究人員提供理論基礎與技術支持。
集成學習使用多個學習機來解決同一問題,它通過調用一些簡單的分類算法,以獲得多個不同的基學習機,然后采用某種方式將這些學習機組合成一個集成學習機[16-17]。隨著集成學習研究隊伍的不斷壯大,集成學習技術得到了快速發展,集成學習方法已將其范圍擴大到各個領域,包括醫療保健、金融、保險、汽車、制造、生物信息學、航空航天等[16],使用集成學習的復合分類模型在很大程度上優于單個分類模型,而且通過集成多個分類器模型,可以減少廣義誤差,提高分類性能[18-19]。近年來,對集成學習的理論和集成學習的算法研究在機器學習領域內一直是一個熱點,國際上機器學習界的權威學者Dietterich曾在AI Magazine上將集成學習列為機器學習領域四大研究方向的第1位。
1 材料與方法
1.1 總體框架
為了提高對馬鈴薯葉片病害識別的準確率,本研究提出基于遷移模型的集成學習方法,以期在目標數據集樣本數量少的背景下,在不消耗其他資源的情況下提升模型的識別精度。首先,對訓練樣本數據集進行預處理并劃分數據集,構建圖像識別模型(ResNet34)以訓練樣本數據集。隨后,利用ImageNet數據集訓練ResNet34模型獲取模型權重,將其遷移至本研究搭建的圖像識別模型中,利用不同遷移方式進行訓練,得到不同模型,在測試集上對不同模型進行集成學習(投票法)以提升識別準確率,詳見圖1。
1.2 ResNet34網絡
隨著計算機技術的發展,研究者對圖像分類的要求越來越高,淺層的神經網絡難以滿足圖像分類的需求,優秀的深層網絡模型不斷被人們創造出來。但是,伴隨網絡的加深,出現了梯度消失、梯度爆炸與網絡退化等問題[20]。為了解決上述問題,He等提出,ResNet、ResNext可由一系列殘差塊堆疊而成,并且數量可以達到成百上千層[21]。本試驗選擇的模型為ResNet34,其結構如圖2、表1所示。對于表1中conv_3x、conv_4x、conv_5x對應的一系列殘差結構,第1層殘差結構都是虛線殘差結構,因為這一系列殘差結構的第1層都有調整輸入特征矩陣520的使命(將特征矩陣的高、寬縮減為原來的一半,將深度channel調整成下一層殘差結構所需要的)[20]。
由圖3可見,上述提到的殘差結構主要有2個結構,圖3-a的殘差結構針對層數較少的網絡,如ResNet18、ResNet34等,圖3-b是針對網絡層數較多的網絡,如ResNet101、ResNet152等。
1.3 超參數
1.3.1 batch size batch_size指1次訓練所抓取的數據樣本數量,其大小影響訓練速度、模型優化[22],其最大的好處在于使中央處理器(CPU)或圖形處理器(GPU)滿載運行,提高了訓練的速度,其次是使得梯度下降的方向更加準確。梯度方差的公式如下:
式中:m為batch_size設置的大小,本研究后續一律使用m代替,增大m可以使得梯度方差減小,使梯度更加準確,而減小m會使梯度變化波動大,網絡不容易收斂;g()為訓練集上學得模型在x上的預測輸出;x為測試樣本;y為x的真實標記。
1.3.2 學習率 在卷積神經網絡每次迭代時,更新參數都會存在一定的誤差。學習率是深度學習中的重要超參數,合適的學習率可以使損失函數在較短時間內收斂到局部最小值[23]。當學習率設置過小時,損失函數的變化速度就會變慢,會大大增加網絡的收斂復雜度,如果損失函數曲線離理論最優點較遠,會增加網絡達到極值的時間,并且很容易被困在局部最小值附近或者鞍點。當學習率設置遠超閾值時,損失函數可能會直接跳過全局最優點,網絡永遠無法達到理想狀態。
1.4 遷移學習
遷移學習的過程如圖4所示。遷移學習可以加快網絡模型的學習進度,減少模型的收斂進度。利用遷移學習可以將在ImageNet中訓練好的模型的權重參數遷移到預訓練模型中,實現對馬鈴薯葉片病害的有效識別。遷移方式有特征提取、全部參數遷移及部分遷移3種。
1.4.1 特征提取 特征提取指在原模型中,除了全連接層外的全部參數都不更新,將原全連接層更換為隨機權重的新的全連接層,并且只更新全連接層的參數。
1.4.2 全部參數遷移 全部參數遷移又稱模型遷移,源域模型和目標域模型共享模型參數,也就是將之前在源域中通過大量數據訓練好的模型參數直接應用在目標域的模型上進行預測。基于模型的遷移學習方法比較直接,該方法的優點是可以充分利用模型之間存在的相似性,缺點是模型參數不易收斂。
1.4.3 微調 使用預訓練網絡初始化網絡,用新數據訓練部分卷積層。微調的大致過程如下:在預先訓練過的網絡上添加新的隨機初始化層,預先訓練的網絡參數也會被更新,但會使用較小的學習率以防止預先訓練好的參數發生較大變化。常用的方法是固定底層的參數、調整一些頂層或具體層的參數。微調的好處是能夠減少訓練參數的數量,有助于克服過擬合。
1.5 集成學習
集成學習是一種機器學習的方法,多個學習器被集中到一起來訓練、解決同一個問題,與普通機器學習方法(試圖從訓練數據中學習一個模型)不同,集成學習可以從訓練數據中的多個模型集成其優點,可使識別準確率得到提高。目前廣泛使用的集成學習方法有Bagging法[19,24]、Boosting法[24-26]。集成學習中的投票法是選擇若干模型作為基礎學習器,用這些基礎學習器分別識別樣本,通過識別結果進行投票,根據少數服從多數的原則,通過多個模型的集成降低方差,從而提高模型的魯棒性。
在理想情況下,投票法的預測效果應優于任何一個基模型的預測效果。但是,投票法也有其局限性,即它對于所有模型的處理都是一樣的,也就是所有模型的權重對于最后結果的影響都一樣大。如果某個模型在特定的表現情況下很好,而在其他情況下的表現很差,這是使用投票法時需要考慮的一個問題。集成學習的訓練策略如圖5所示。
圖5中,投票機制是絕對多數投票法,以每次批量加載到網絡中的樣本為例,通過統計3個預測模型對病害圖像xi的預測結果y1i、y2i、y3i并進行投票,投票法可表示為:
式中:H(x)為投票結果;i表示第i個樣本;k表示第k個模型;Reject表示投票失敗;yki表示第k個預測模型對第i個樣本的預測結果。
2 結果與分析
2.1 試驗環境
本試驗采用Pytorch作為小麥病害識別中模型搭建、訓練的平臺,試驗地點為云南省作物生產與智慧農業重點實驗室,試驗時間為2022年5—11月。試驗模型在GPU環境下訓練,試驗的軟件、硬件配置如表2所示。
2.2 數據來源
本試驗以健康馬鈴薯葉片和4種病害馬鈴薯葉片(發生馬鈴薯早疫病的一般類別葉片、發生馬鈴薯早疫病較嚴重的葉片、發生馬鈴薯晚疫病的一般類別葉片和發生馬鈴薯晚疫病較嚴重的葉片)作為試驗對象。試驗數據來自AI Challenger 2018競賽的數據集,選取其中的馬鈴薯類別作為本試驗對象,共2 840幅,如圖6所示。
2.3 數據增強與數據預處理
由于試驗中馬鈴薯葉片的病害數據集圖片有限且分布不均,因此選擇數據增強的方法擴大數據集,以增強原數據集中存儲的病害圖像的多樣性,從而增強模型的泛化能力。數據增強技術包含多種變換方法,包括顏色的數據增強(色彩飽和度、對比度與亮度)、鏡像變換等。試驗通過使用Python中的PTL模塊對所有試驗數據圖像進行水平翻轉,以增強模型的魯棒性及適應性。同時,針對數據集中的某些病害進行垂直翻轉,以達到各類數據樣本相對平衡。數據增強后的所有樣本共計5 158幅。
為了使模型訓練更有效率,將5 158幅葉片病害圖像統一調整為224像素×224像素大小,并用0、1、2、3、4作為數據集標簽分別代表健康馬鈴薯葉片、發生早疫病的一般馬鈴薯葉片、嚴重發生早疫病的馬鈴薯葉片、發生馬鈴薯晚疫病的一般葉片與嚴重發生馬鈴薯晚疫病的葉片。依據數據增強后的圖像劃分數據集,按照8 ∶2的比例劃分數據集,將數據集分為訓練集和驗證集,再將訓練集按9 ∶1劃分成訓練集與測試集數據增強后的圖像數量,如圖7所示。
2.4 超參數的性能評估
2.4.1 m對模型性能的影響 本環節探討不同m值(batch_size)對模型識別準確率的影響。將m設置為4的倍數,分別測試當m=16、32、64時對模型準確率的影響。從圖8可以看出,當m=32時,訓練效果最為平滑,效果最好。
2.4.2 學習率對模型性能的影響 本試驗對3種不同的初始學習率進行測試訓練,如圖9所示,分別設置初始學習率為0.01、0.001、0.000 1、0.000 01,在同樣的m值下測試試驗結果。當初始學習率設置為0.01時,訓練測試效果不是很理想;當初始學習率設置為0.001時,準確率繼續提升;當初始學習率設置為0.000 1時,準確率仍在提升,達到85%;當初始學習率設置為0.000 01時,模型準確率變低,模型收斂慢。因此 選擇初始學習率為0.000 1作為試驗的默認準確率。
2.5 特征圖的可視化
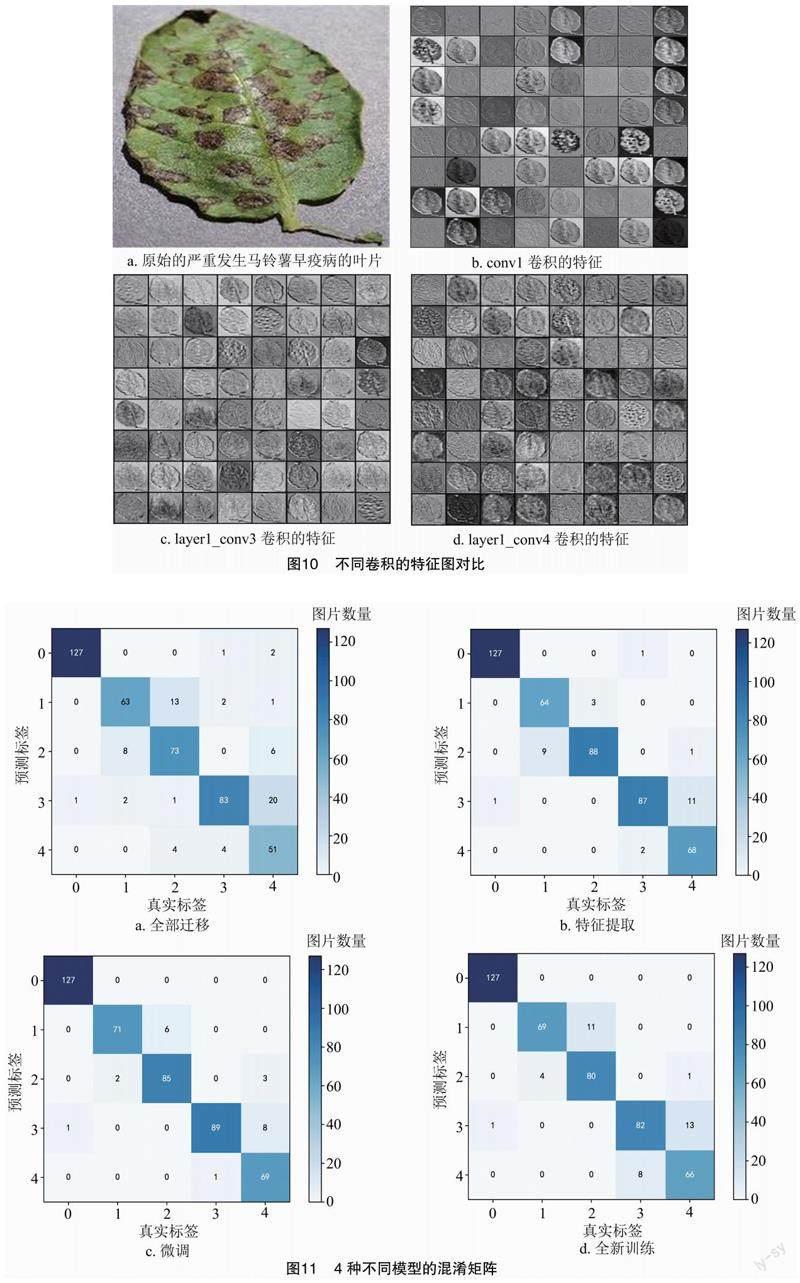
對ResNet34網絡模型卷積塊進行特征可視化,以方便觀察該模型的卷積過程及理解模型識別病害的總過程。從卷積塊的淺層到深層進行選擇性的可視化。分別選取網絡的conv1層卷積、layer1_conv3卷積、layer1_conv4卷積進行對比,從圖10可以看出,特征圖在第1次卷積時可以清楚地看到葉片的病害信息。隨著卷積層數的增加,對葉片的信息也越來越模糊,可以解釋為卷積神經網絡淺層卷積層的特征提取更多的是對紋理和一些細節信息進行提取,而深層卷積層的特征提取更多的是對抽象特征信息進行提取。
2.6 遷移學習方法的性能評估
圖11是ResNet34訓練模型與不同遷移學習方式的混淆矩陣的對比結果,混淆矩陣橫軸0、1、2、3、4分別代表真實類別的馬鈴薯健康葉片、發生早疫病的一般馬鈴薯葉片、嚴重發生馬鈴薯早疫病的葉片、發生馬鈴薯晚疫病的一般葉片與嚴重發生馬鈴薯晚疫病的葉片。縱軸0、1、2、3、4分別代表模型預測類別的馬鈴薯健康葉片、發生早疫病的一般馬鈴薯葉片、嚴重發生馬鈴薯早疫病的葉片、發生馬鈴薯晚疫病的一般葉片與嚴重發生馬鈴薯晚疫病的葉片。當模型預測類別與真實類別一一對應時,即混淆矩陣的藍色程度越深時,意味著模型的預測效果越好。利用混淆矩陣比較容易判別模型的預測結果與真實結果之間的誤差。根據混淆矩陣判斷微調模型在識別嚴重發生馬鈴薯早疫病、發生馬鈴薯早疫病的一般情況和發生馬鈴薯晚疫病的一般情況時效果較好,全新訓練模型在識別嚴重發生馬鈴薯晚疫病時的效果較好。分析可知,微調模型的總體識別效果較好。
本次微調試驗將ResNet34網絡的前6個層凍結,然后對后面的卷積層及全連接層進行重新訓練。由于底層網絡收集的都是圖像的曲線、邊緣等一系列普遍特征,一般的卷積神經網絡的底層網絡收集的信息都是相通的,因此保持這些權重不變,對后面部分網絡進行重新訓練,使其更為關注馬鈴薯病害數據集的一些特有特征,直到凍結所有卷積層,本試驗的目的便是為了找到準確率最高的微調方法。
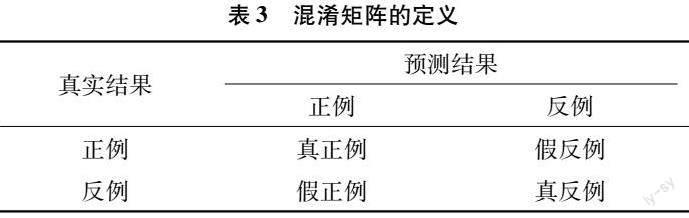
本試驗主要研究3種遷移方式(全部遷移、特征提取和微調)與全新訓練隊模型準確率、模型的精確率、模型的召回率、模型的特異率及迭代1次的時間,將這5個參數進行對比,選擇比較好的3個模型進行集成學習。其中,微調模型的識別效果最好,在整體準確率上,微調模型的準確率比全部遷移模型高1.51百分點,比特征提取模型高9.52百分點,比全新訓練模型高3.68百分點,精確率、召回率與特異率也有明顯的提升。每次迭代的時間也有大幅減少(除了與特征提取模型相比),特征提取凍結了除了全連接層之外的全部網絡的權重,能夠減少模型對預訓練的卷積層的重新學習的過程,因此每次迭代的時間最短,而全部遷移模型、全新訓練的模型都是每次更新卷積層的權重,所以每次迭代時間最長。微調模型只凍結前6個層,對后面的卷積層和全連接層的權重進行重新訓練,因此每次迭代的時間相比較于全新訓練、全部遷移會變短。采用準確率作為模型結果的主要評價指標,對模型進行進一步改進,采用精確率(P)、召回率(R)和特異度(S)作為模型進一步分析的評價指標,每個指標均由混淆矩陣計算得到,詳見表3。
準確率(A):準確率指模型能夠正確識別所有樣本中正確樣本的比例,公式如下:
A=真正例+真反例真正例+假反例+假正例+真反例×100%。
精確率(P):精確率指某類預測正確的樣本中真實正確樣本的比例,公式如下:
P=真正例真正例+假正例×100%。
召回率(R):召回率指某類正確樣本中的被正確預測的樣本所占比例,公式如下:
R=真正例真正例+假反例×100%。
特異度(S):特異度指某類反例的樣本中被預測為反例樣本所占比例,公式如下:
S=真反例真反例+假正例×100%。
2.7 集成學習對模型的提升
從表4中對4種不同模型的效果對比可以看出,全部遷移、微調與全新訓練的模型訓練效果較好,因此選擇這3種模型進行下一步的集成學習。由于微調模型的識別準確率最高,因此將3種模型集成學習后的效果與微調模型進行對比。
本次集成學習主要通過全部遷移、全新訓練、微調3種模型完成,首先將3種模型的預測結果分別導入3個不同的列表(list_a、list_b與list_c)中,再分別對列表中的類別進行投票,選擇最終類別,得到投票預測準確的圖片數量,繪制混淆矩陣,混淆矩陣如圖12所示。在微調模型的基礎上進一步提高預測準確率,對比結果如表5所示。
馬鈴薯健康葉片經過集成學習硬投票,沒有將微調識別錯誤的樣本投票為正確的樣本,發生早疫病的一般馬鈴薯葉片經過集成學習硬投票,將微調識別錯誤的2個樣本全部轉化為正確樣本,嚴重發生馬鈴薯早疫病的葉片經過集成學習硬投票,將微調識別錯誤的6個樣本全部轉化為正確樣本,發生馬鈴薯晚疫病的一般葉片經過集成學習硬投票,沒有將微調識別的錯誤樣本投票為正確的樣本,嚴重發生馬鈴薯晚疫病的葉片經過集成學習硬投票,將微調識別錯誤的11個樣本中的9個轉化為正確樣本。集成學習的總體準確率較微調模型提高了3.68百分點,較全新訓練模型提高了7.36百分點。
3 結論
針對馬鈴薯葉片樣本量少且背景復雜的病害圖像,本研究提出了一種在ImageNet上完成預訓練的ResNet34網絡,通過遷移學習、集成學習的方法對馬鈴薯葉片病害進行了分類試驗,并就m、學習率、學習方法等因素對模型性能的影響進行了對比分析,得到如下結論:ResNet34網絡可以自動從原始數據中提取馬鈴薯葉片的病害特征,平均識別準確率達到91.77%;對于全新訓練而言,遷移學習可以充分利用在大型數據集上學習到的知識,可以大幅縮短模型訓練時間,約減少3/5。在同一學習率下,集成學習的平均識別準確率相比全新訓練提高了7.36百分點;集成學習將不同遷移方式得到的模型進行集成,最終結果優于任何一種遷移方式得到的模型,相比微調模型,平均識別準確率提高了3.68百分點。
參考文獻:
[1]魏麗冉,岳 峻,李振波,等. 基于核函數支持向量機的植物葉部病害多分類檢測方法[J]. 農業機械學報,2017,48(增刊1):166-171.
[2]張云龍,袁 浩,張晴晴,等. 基于顏色特征和差直方圖的蘋果葉部病害識別方法[J]. 江蘇農業科學,2017,45(14):171-174.
[3]劉 媛,馮 全.葡萄病害的計算機識別方法[J]. 中國農機化學報,2017,38(4):99-104.
[4]郭小燕,于帥卿,沈航馳,等. 基于全局特征提取的農作物病害識別模型[J]. 農業機械學報,2022,53(12):301-307,379.
[5]孟 亮,郭小燕,杜佳舉,等. 一種輕量級CNN農作物病害圖像識別模型[J]. 江蘇農業學報,2021,37(5):1143-1150.
[6]曾偉輝,李 淼,李 增,等. 基于高階殘差和參數共享反饋卷積神經網絡的農作物病害識別[J]. 電子學報,2019,47(9):1979-1986.
[7]張紅濤,朱 洋,譚 聯,等. 基于FA-SVM技術的煙草早期病害識別[J]. 河南農業科學,2020,49(8):156-161.
[8]張 航,程 清,武英潔,等. 一種基于卷積神經網絡的小麥病害識別方法[J]. 山東農業科學,2018,50(3):137-141.
[9]孫 俊,譚文軍,毛罕平,等. 基于改進卷積神經網絡的多種植物葉片病害識別[J]. 農業工程學報,2017,33(19):209-215.
[10]劉玉耀,彭瓊尹. 基于卷積神經網絡和遷移學習的甌柑病蟲害識別研究[J]. 熱帶農業科學,2022,42(9):64-70.
[11]杜甜甜,南新元,黃家興,等. 改進RegNet識別多種農作物病害受害程度[J]. 農業工程學報,2022,38(15):150-158.
[12]李 好,邱衛根,張立臣.改進ShuffleNet V2的輕量級農作物病害識別方法[J]. 計算機工程與應用,2022,58(12):260-268.
[13]孫 俊,朱偉棟,羅元秋,等. 基于改進MobileNet-V2的田間農作物葉片病害識別[J]. 農業工程學報,2021,37(22):161-169.
[14]鄭一力,鐘剛亮,王 強,等. 基于多特征降維的植物葉片識別方法[J]. 農業機械學報,2017,48(3):30-37.
[15]張 旭,周云成,劉忠穎,等. 基于改進ShuffleNetV2模型的蘋果葉部病害識別及應用[J]. 沈陽農業大學學報,2022,53(1):110-118.
[16]張春霞,張講社. 選擇性集成學習算法綜述[J]. 計算機學報,2011,34(8):1399-1410.
[17]楊融澤,柳 毅. 面向異常數據流的多分類器選擇集成方法[J]. 計算機工程與應用,2018,54(2):107-113.
[18]Tian Y,Zhao C J,Lu S L,et al. SVM-based multiple classifier system for recognition of wheat leaf diseases[C]//2012 World Automation Congress.Puerto Vallarta Mexico,2012.
[19]車翔玖,于英杰,劉全樂. 增強Bagging集成學習及多目標檢測算法[J]. 吉林大學學報(工學版),2022,52(12):2916-2923.
[20]郭玥秀,楊 偉,劉 琦,等. 殘差網絡研究綜述[J]. 計算機應用研究,2020,37(5):1292-1297.
[21]He K M,Zhang X Y,Ren S Q,et al. Deep residual learning for image recognition[C]//Computer vision and pattern recognition.IEEE,2016.
[22]張忠林,余 煒,閆光輝,等. 基于ACNNC模型的中文分詞方法[J]. 中文信息學報,2022,36(8):12-19,28.
[23]王東方,汪 軍. 基于遷移學習和殘差網絡的農作物病害分類[J]. 農業工程學報,2021,37(4):199-207.
[24]Takemura A,Shimizu A,Hamamoto K. Discrimination of breast tumors in ultrasonic images by classifier ensemble trained with AdaBoost[J]. Electronics & Communications in Japan,2011,94(9):18-29.
[25]金松林,來純曉,鄭 穎,等. 基于特征選擇和CNN+Bi-RNN模型的小麥抗寒性識別方法[J]. 江蘇農業科學,2022,50(10):201-207.
[26]李 凱,崔麗娟. 集成學習算法的差異性及性能比較[J]. 計算機工程,2008(6):35-37.
