基于半監督引導的網絡APT檢測知識圖譜構建
2023-09-15 03:34:22王夢瑤楊婉霞王巧珍
軟件導刊 2023年9期
王夢瑤,楊婉霞,王巧珍,趙 賽,熊 磊
(甘肅農業大學 機電工程學院,甘肅 蘭州,730070)
0 引言
近年來,網絡安全威脅已經發生翻天覆地的變化,運用先進的攻擊方法對某些機構進行持續性、針對性的網絡攻擊,造成高級持續性威脅(Advanced Persistent Threat,APT)已逐漸引起國內外研究者的重視[1]。不同于傳統網絡攻擊手段,APT 的攻擊目標從常見的中斷服務轉為竊取目標知識產權和敏感數據,具有階段性強、持續時間長、攻擊路徑多樣化等特點[2]。例如,BlackEnergy 木馬攻擊的前、中、后期分別使用BlackEnergy、BlackEnergy 2、BlackEnergy 3 逐漸增強的木馬病毒,以郵件、文檔等多種路徑攻擊目標。
2015 年,海蓮花組織對多個不同國家的科研院所、政府、海事機構等重要部門發起APT 攻擊,造成了嚴重的損失[3]。2016 年,APT 28 組織入侵DNC 郵件系統,造成了嚴重的數據泄露。同年,Apple 公司首次披露利用IOS Trident 漏洞進行的APT 攻擊[4]。2018 年底,新加坡遭受了歷史上最嚴重的APT 攻擊,造成包括李顯龍總理在內約150萬人的健康數據被泄露[5]。據360 天眼實驗室發布的《2015 中國高級持續性威脅(APT)研究報告》可知,中國是遭受APT 攻擊的主要受害國,全國多個省市均受到不同程度的攻擊。其中,北京、廣東是重災區,工業、教育、科研領域和政府機構均受到APT 攻擊者的重點關注。
然而,目前仍有大量APT 攻擊未被發現,而他們通常已存在較長時間,入侵了很多主機,在被發現前就已經造成了巨大損失,這說明目前APT 攻擊檢測手段仍然相對滯后,對APT 攻擊的響應能力不足。為此,大量學者對APT的攻擊開展了深入研究,在檢測技術和方法方面已取得不少成果。常見的APT 檢測技術與方法主要包括以下3種:
(1)網絡流量分析。該技術通過Netflow 或DNS 流量規律進行基線學習與分析以發現異常,但樣本獲取與相關性分析的難易程度將影響模型準確度。同時,部分研究人員利用數據挖掘與機器學習方法提取正常、異常的行為特征,對未知流量進行分類以提升異常攻擊檢測率,但無法從根本上解決樣本獲取的難題。
(2)負載分析(沙箱)。該技術首先模擬運行環境,通過捕獲的樣本在虛擬環境運行過程中的行為來提取特征,以顯著提升特征匹配時效性,但目前沙箱逃逸功能已普遍存在于高級樣本中,沙箱效果也大打折扣。
(3)網絡取證。該技術通過抓取大量流量報文或日志,通過對安全日志的行為進行建模,將偏離正常行為視為異常,以此檢測多步攻擊。由于該方法可較好地還原樣本與攻擊過程,在回溯與應急響應方面價值較高,因此廣泛運用于各種新型安全管理系統,但建立完善的攻擊模型是系統的關鍵,因此依然面臨著需要精確分析網絡流量的問題。
鑒于現有方法存在的問題,最新研究提出構建多源異構APT 攻擊大數據知識圖譜,通過APT 事件—組織動態關系模型和時間序列演化模型,解除理想樣本空間和攻擊模型的限制,進而解決APT 攻擊檢測這一難點問題。
為此,本文采用基于深度學習級聯模型結構的新型APT 知識獲取方法,解決目前在APT 樣本獲取方面存在的問題。首先,通過半監督bootstrap 的知識融合方法自動構建APT 知識圖譜,進而解決多源異構的APT 數據。然后,采用基于BERT(Bidirectional Encoder Representations from Transformers)+BiLSTM+Self-Attention+CRF 的APT 攻擊檢測模型,解決APT 攻擊實體識別方面存在的難點問題,進而精準構建APT 攻擊檢測的知識圖譜。
1 相關研究
經過對APT 攻擊特征的深入分析,研究者發現APT 攻擊檢測的相關算法主要依賴專家領域知識。例如,Alshamrani 等[6]采用白名單方法,通過學習和對系統正常行為進行建模,從而檢測異常行為并發現APT 攻擊。Jedh等[7]利用連續消息序列圖的相似性,通過挖掘未知異常模式來檢測APT。
在基于安全日志的APT 攻擊研究中,大多數算法通過建模APT 攻擊實現檢測[8]。例如,Zou 等[9]建立APT 攻擊模型監控民航通信網,以發現實際攻擊過程中的模式。Milajerd 等[10]構建基于殺傷鏈的攻擊樹模型,關聯分析安全日志后生成攻擊路徑,進而預測下一步攻擊行為。Zimba 等[11]首先采用IP 地址關聯方法進行聚類,然后利用模糊聚類關聯方法構建APT 活動序列集,最后結合對抗時間策略,在較長的時間窗口內分析數據,進而實現在一段時間內檢測多步復雜攻擊,但該方法仍然依賴于專家知識。
APT 知識圖譜呈現了網絡威脅的知識資源及其載體,并對其中的知識及其相互關系進行挖掘、分析、構建和顯示,有助于發現、挖掘多源異構網絡威脅間千絲萬縷的關系數據、隱藏信息,提升網絡攻擊威脅分析的準確性與及時性。因此,近期APT 檢測研究側重于結合最新的知識工程技術構建APT 知識圖譜,運用大數據智能分析方法提升APT 檢測準確率。Xu 等[12]基于知識圖譜提出多領域安全事件關聯性分析方法,利用不同領域中與安全事件內在相關的若干屬性,建立異常事件與攻擊行為間的因果關系。
在網絡安全數據可視化交互技術的研究中,Palantir、Splunk 等外國公司在現有安全可視化的基礎上,提出新的動態語義相關圖分析方法和可視化查詢分析方法,已成為網絡威脅交互分析的新方向。
當前,在知識圖譜構建的研究中,利用深度學習算法設計自動提取、融合知識及實體鏈接算法是研究的熱點[13]。例如,基于深度學習網絡的有監督關系抽取算法、實體鏈接等算法,避免了傳統實體鏈接中手工構建特征的繁瑣過程,取得的性能更優[14]。然而,該方法在理解復雜句子時仍存在許多局限性,需要進一步深入挖掘大規模多源異構數據中的多重關系和事件。由于攻擊者主動引入干擾信息、IDS 等系統錯誤,將造成攻擊事件的知識圖譜存在大量垃圾信息。因此,需要使用一些先進的知識精化算法消除錯誤、驗證一致性,但現有算法僅限于處理簡單靜態事件,對多源異構數據中復雜事件的處理能力有待提高。
目前,大多數本體推理算法均基于OWL 語言[15],這種大規模知識推理還處于實驗室原型系統階段,對具有復雜字符關系和事件關系描述的字符—事件知識圖譜的高效推理支持有待進一步研究。Zhang 等[16]針對網絡數據中的多類型實體問題,提出一種基于條件隨機場和實體詞匯匹配相結合的人名實體提取方法,在整個網絡數據集上收集人員姓名,識別正確率、召回率分別為84.5%、87.8%。知識圖譜關系抽取主要為了獲取實體間的關系,以監督方法、半監督方法為主,目前研究成果較為成熟。Yang等[17]將多實例、多標簽的學習機制引入實體關系抽取中,實體和一系列對應的標簽是通過圖模型及其潛變量進行整合,再經過實體訓練進一步獲得關系分類器。Cho 等[18]提出一種基于Bootstrap 算法的半監督學習方法來自動建模實體關系。
綜上所述,知識圖譜的構建技術近年來已取得迅速發展,世界上也出現了許多相關的研究結果,但在提取實體和關系方面仍然存在許多問題尚未解決。為了降低APT事件數據的特征提取和檢測難度,首先通過GitHub 中獲取的14 年數據構建了一個APT 攻擊檢測命名實體識別語料庫;然后在相關研究中命名實體識別關系,在抽取模型Bert+BiLSTM+CRF 學習中加入Self-Attention 模塊,以在原模型基礎上進一步提升識別APT 攻擊檢測實體的準確性;最后研究APT 知識圖構建系統的總體框架,側重于APT 事件知識獲取、知識融合等關鍵技術。
2 APT知識圖譜構建
APT 攻擊事件的知識圖譜是與該事件相關的結構化語義描述。它不僅描述了事件的基本屬性和攻擊特點,還描述組織屬性(包括攻擊者、防御者和受害者組織)。
現有知識圖譜技術主要針對開放領域的大規模網頁、多媒體等非結構化海量數據,構建針對人和熱點事件抽取實體的知識領域可視化映射圖。APT 知識圖譜相較于現有知識圖譜的不同之處在于,從安全專家提取的威脅開源情報數據庫、流量和日志規模數據中構建了一個知識圖譜庫。威脅情報知識庫的主要文檔包括樣本掃描報告、動態分析報告、域名記錄、IP 反查、Whois、組織機構、事件歸屬等,因此數據來源更多樣化和異質化。此外,本文還建立了事件—組織—屬性關系網絡,統一描述攻擊事件的靜態和動態知識,提出了一種構建APT 攻擊事件知識圖譜的方法,包括風險事件知識提取、風險事件知識融合與提煉等。
2.1 APT攻擊的知識圖譜總體框架
APT 知識圖譜的構建是從威脅情報中識別攻擊事件、組織等,并針對某一攻擊事件從中提取事件名稱、攻擊時間、攻擊偏好、技術特征等信息,從而實現對實體屬性的完整勾勒。針對攻擊事件具有許多屬性依賴性的特點(例如攻擊工具與類型間的依賴性等),本文基于威脅情報文本數據集,提出一種深度學習與條件隨機場學習相結合的方法提取實體;針對APT 情報數據多源異構特點,重點研究知識的自適應提取策略,解決目前源異構數據提取方法通用性差、多類型數據提取召回率低的問題。
因此,多源異構威脅情報知識庫中提取的信息結果,必然包含大量冗余信息、沖突信息和互補信息,數據間存在關系扁平、缺乏層次性的問題,必須通過實體消歧和知識融合技術進行知識精細化。傳統實體鏈接方法依賴手動定義實體和實體上下文相關特征,生成候選實體和實體間的特征向量,并通過向量間的相關性獲得實體鏈接結果,這其中存在與數據分布相關的人工定義特征、不同場景下有限的特征泛化能力等問題。
為此,本文利用深度學習對文本中詞和知識庫的實體進行聯合建模,自動學習詞和實體的低維向量表示,并通過向量計算詞和實體的相關性。該方法可減少手工定義特征向量的人力負擔,解決特征向量稀疏的問題,提升知識實體融合模型的泛化能力。根據上述研究思路,由于APT 事件具有較強的知識專業性和數據多源異構性特征,本文設計的APT 事件知識圖譜自動構建整體框架,將APT情報數據、日志數據、流量分析元數據作為構建APT 知識圖譜的原始數據。首先對原始數據進行預處理;然后利用實體抽取技術,從預處理后的語料庫中抽取APT 知識圖譜實體;接下來抽取實體間的關系,構建、融合知識項,以形成APT 知識圖譜庫。APT 知識圖譜的總體框架構建流程如圖1所示。

Fig.1 Overall framework construction process of APT knowledge graph圖1 APT知識圖譜的總體框架構建流程
2.2 APT事件實體與關系抽取方式
APT 知識的實體與關系抽取技術是構建APT 知識圖譜的關鍵技術之一,當前主要的知識獲取方式是通過自然語言理解技術獲取文本特征,利用機器學習獲取APT 知識特征。首先利用實體抽取技術從最初的APT 威脅情報等數據中識別APT 知識實體;然后由APT 事件自動關聯APT知識實體;最后利用知識實體間的關系構建APT 知識圖譜。本文基于可識別動態語義的BERT 詞嵌入和具有記憶的BILSTM 設計了神經網絡分層模型,以抽取APT 事件的實體和關系。
面向詞向量的APT 知識獲取方法分層模型在保證召回率基礎上,使得低層網絡能盡可能識別APT 事件的知識實體,為后續提升實體識別準確率奠定基礎。然后,將低級網絡識別結果傳遞給包含注意力機制的高一層網絡BiLSTM-Attention,以再次識別來自低層網絡的信息,并將識別結果傳遞給條件隨機場(CRF)模塊。最后,輸出識別結果中單一合法的實體。
若存在多個APT 事件實體的情況,需要將這些子結果再次傳送至高層網絡(BiLSTM-Attention)中進行識別,通過多層處理APT 威脅情報文本提升APT 知識實體識別的準確率,具體模型結構如圖2所示。
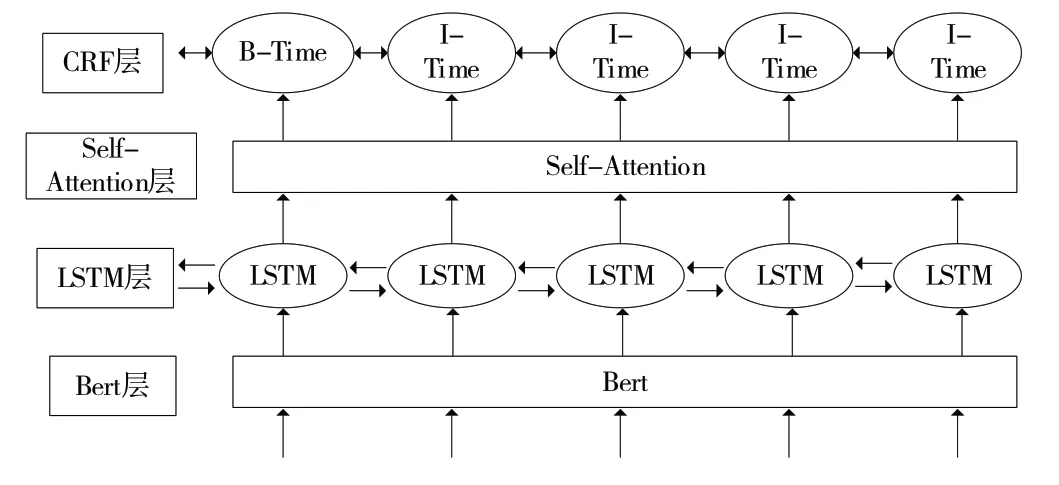
Fig.2 Layered model structure for the extraction of APT knowledge entities圖2 APT知識實體提取的分層模型結構
由圖2 可見,分層模型底層采用BERT 模型結構。BERT 是一個預訓練模型,可根據上下文語義語境編碼動態詞向量。其中,級聯模型的高層網絡是一種包含注意機制的結構,采用雙向Transformer 編碼結構,可直接獲得全局信息;RNN 需要逐漸遞進才能獲取全局信息。因此,本文選用BERT 模型構建分層模型。
同時,為了獲取APT 知識實體的具體信息,需將低層網絡模型的輸出作為高層網絡模型的輸入。BiLSTM 模型通過前向、后向傳播參數獲取上下時刻的信息,因此能更快速、準確地編碼序列。編碼單元的主要組成為Self-Attention 模塊,計算表達式如式(1)所示:
式中:Q、K、V為輸入詞向量矩陣,用輸入向量維數進行表達。
Self-Attention 模塊根據上述關系來調整每個實體的重要性,為每個實體定義一個包含實體本身、實體與其他實體關系的表達方式,因此相較于單個實體向量全局性更高。Transformer 是基于Multihead 模式對模型聚焦能力在不同位置的進一步擴展,增添了Attention 單元的子空間表示,如式(2)、式(3)所示。
此外,基于BILSTM 融合的Attention 機制,能靈活學習APT 實體的上下文語義信息。BiLSTM 模型雖緩解了單向LSTM 造成的前后編碼差異,但無法完美解決時序編碼缺陷的問題,如果僅依賴時序輸出,模型將難以正確識別APT 事件實體任務。因此,融合Attention 機制是為了關注不同上下文片段中涉及的語義及APT 實體間的關系,然后通過這種關系確定相關APT 事件的實體。
在級聯模型中,高層網絡構建部分BiLSTM-Attention僅考慮了上下文信息中的長序列問題,忽視了標簽中的依附關系。因此,在APT 實體識別中存在標簽無法連續出現的問題,APT 的物理邊界仍然存在爭議。由于在標簽決策中,模型無法獨自通過隱藏狀態完成,需要思考標簽間的上下關系來獲取全局中的最佳標簽,但可通過條件隨機場來完成,它可在輸出級別時分離相關性。
因此,級聯模型中高層網絡的輸出結果,將利用更深的CRF 網絡建模標簽序列以糾正錯誤標簽,從而得到更可靠的標簽序列。根據上述知識獲取算法模型,通過Softmax函數進行激活的全連接層計算分類概率,如公式(5)所示。
其中,WT、bT為可訓練參數為第ith個實體類別的概率向量。實體分類任務的損失函數如公式(6)所示。
顯然,這數十頁“神言”不僅是所謂藝術技巧突出,更重要的是它說出了來自彼岸世界的信息,故而與此岸世界的生活景象難以順利對接。 這種觀點與《托爾斯泰和陀思妥耶夫斯基論藝術》中的觀點完全一致,只不過“神言”的數量由七八十頁減少到二十至五十頁罷了。 羅扎諾夫說:
式中:、分別表示第ith個實體的真實類別標簽和實體分類器預測的第ith個實體類別的分布。
2.3 APT知識融合算法
本文提出了一種基于半監督的Bootstrapping 知識融合技術。首先,利用知識提取算法得到由三元組表示的APT知識項;然后,利用知識融合技術構建APT 知識圖譜。由于提取的信息存在高度碎片化、離散化、冗余和模糊現象,因此將未融合的信息碎片視為各自的APT 知識圖譜,利用實體對齊和實體鏈接達到融合多個APT 知識圖譜的目的。
目前,實體對齊問題的方法包括本體匹配與知識實例匹配。其中,本體匹配法主要解決APT 知識實體對齊問題,通常由基本匹配器、文本匹配、結構匹配、知識表示學習等方法組成,根據APT 知識圖譜的現實需要,通過知識圖譜的表示學習技術達到實體對齊目的。
本體匹配方法利用機器學習中的表示學習技術,將圖中實體和關系映射為低維空間向量,利用數學表達式計算實體間的相似度。首先將知識圖譜KGb、KGe映射到低維空間,得到相應的知識表示,分別記為KGb0和KGe0;然后在此基礎上,通過人工標注的實體對齊學習數據集D,即實體對間的對應關系為φ:KGb0?KGe0。知識實體(APT 攻擊關鍵詞和同義詞)的對齊過程如下:
步驟1:選擇種子實體。遍歷、選取待融合的多個知識圖譜KGe中的所有實體ee。
步驟2:預處理種子實體。
步驟3:通過動態索引技術索引屬性。
步驟4:采用精簡過濾方法剔除相似度低的實體,構造對應的實體對(eb,ee),即現有知識圖譜KGb中實體集結合的節點。
步驟5:使相似度較高的實體對分布在多個塊中,并作為候選對齊實體對。
步驟6:通過匹配算法進行評分,例如基于屬性相似度和結構相似度的聚合模型學習方法。
步驟7:根據評分結果進行排名,排名越低的實體對表示兩個實體間對齊程度越高。
步驟8:采用基于圖相似性傳播的引導程序迭代對齊方法,選擇與種子實體置信度高的匹配實體對達到實體對齊,進而有效整合APT 知識。
3 實驗與結果分析
3.1 實驗環境
本文實驗環境為:Intel(R)Core(TM)i7-8750H CPU @ 2.20 GHz,GPU NVIDIA GTX 1050Ti,磁盤大小為2 TB。實驗開發語言為Python,編譯器為Pycharm,采用Tensorflow 深度學習開發平臺。
3.2 測試數據語料庫
本文使用數據來自Github,整理了2006-2020 年不同來源的APT 事件報告。其中,APT 事件報告數據的大小約16.4 GB,APT 相關實體約9 200個,如表1所示。

Table 1 Data set表1 數據集
由表1 可知,APT 報告多為非結構化數據,部分報告僅包含了攻擊過程中的詳細描述及攻擊活動造成的影響,并未包含實驗中所需事件信息樣本。因此,基于上述數據特征,有必要處理APT 事件的樣本數據。首先人工提取實驗所需相關事件樣本,然后將提取的事件信息樣本進行序列標注,最后將處理后的數據作為實驗主要數據,進一步構建APT 知識圖譜語料庫。
語料庫中包括APT 攻擊組織、攻擊類型、攻擊時間、攻擊事件和攻擊目的等實驗所需事件信息樣本信息。例如,The Dropping Elephant 事件是由于東南亞和南海問題,針對美國在內各國政府和公司發起的攻擊行為。在準確提取APT 事件特征前,需對文本進行序列標注,以更好地提升模型訓練性能。序列標注中最關鍵的步驟是為數據賦予標簽,通常會使用簡單的英文字母為詞語賦予標簽,常用數據集標注方法包括BIO、BIOES、IOB 等。本文使用目前最流行的BIO 標注方法進行標注,該方法首先使用YEDDA 工具對預處理后的APT 攻擊事件文本語料庫進行手動標注,然后編寫Python 腳本處理標注后的數據,得到基于BIO 注釋的APT 事件文本數據序列。
針對APT 事件特征,對文本的實體定義了攻擊組織(Organization)、攻擊目的(Purpose)、攻擊目標(Target)、攻擊類型(Type)、攻擊工具(Tool)、攻擊媒介(Medium)、攻擊事件(Event)、攻擊時間(Time)8 種類型。其中,8 個實體類別的元素標注中B-XX 表示實體開始,I-XX 表示實體中間或結尾,O 表示定義實體之外的實體。通過BIO 標記方法定義每個實體類別的標簽,得到滿足詞向量生成層的輸入語料庫標準,最后將語料庫中訓練集、測試集及驗證集按照6∶2∶2的比例進行劃分。
3.3 模型性能分析
本文模型輸入數據為APT 威脅情報、事件報告等文本數據,通過神經網絡的分層模型抽取文本數據的實體和關系,從而構造三元組知識條目,目的是從輸入文本的非結構化數據中提取APT 的基本屬性,例如攻擊特點、攻擊工具等。APT 組織為與事件相關的黑客組織和檢測組織,例如國家、實體組織、黑客組織等。APT 知識實體關系包括事件關聯關系,例如APT 攻擊工具的更新或攻擊類別的延伸。同時,模型還提取APT 事件行為屬性、組合流量特征和攻擊場景特征信息。為模型性能評估,本文選擇準確率、召回率和F1 評估實體關系抽取算法的性能,模型參數設置如表2所示。

Table 2 Main parameters of knowledge extraction algorithm model表2 知識提取算法模型主要參數
3.3.1 Batch_size值因素
參數Batch_size 值決定下降方向,在合理范圍內增大Batch_size 值既能提升內存利用率、矩陣乘法的并行化效率,還會增加下降方向的準確性。例如,BIGRU+CRF 模型的Batch_size 值不同,樣本數量會對模型性能產生一定影響。
本文將Batch_size 值設定為8 和16 進行比較實驗,具體數據如表3 所示。由此可見,當樣本數量小于樣本1 時(樣本數量為300 個),Batch_size=8 的模型性能更優;當樣本數量增大到樣本2 時(樣本數量為440 個),Batch_size=16 的模型性能更優;當樣本數量為樣本3 時(樣本數量為715 個),Batch_size=16 的模型性能更優。綜上,模型在Batch_size=16 時性能最佳,因此設置Batch_size=16 進行后續實驗。
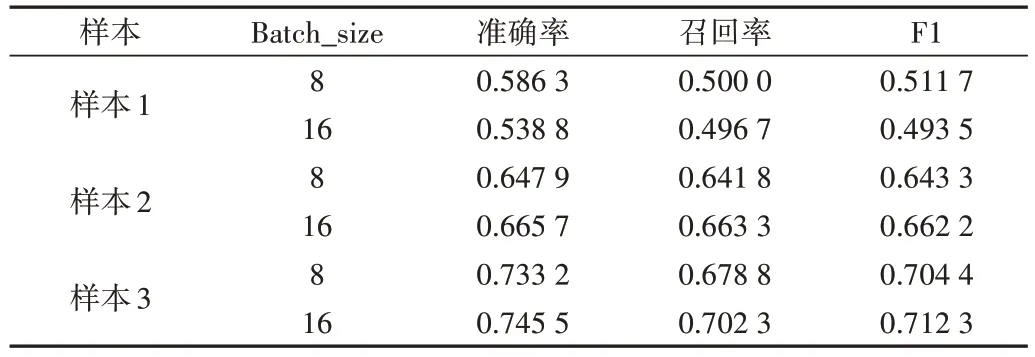
Table 3 Effect of Batch_size on model BIGRU+CRF表3 Batch_size對模型BIGRU+CRF的影響
3.3.2 數據集因素
GRU 為LSTM 的簡化版本,擅長執行長期記憶任務,既能解決長期依賴問題,還可通過保留有效信息提取APT 威脅情報文本的APT 知識實體特征。BIGRU 的前向、后向傳播過程類似雙向長短期記憶神經網絡,但性能受限于樣本數量,即保持其他參數不變,當樣本數量較少時,BIGRU 模型性能優于BILSTM,但在樣本數量較多時,BILSTM 模型性能優于BIGRU。
由圖4 可見,在Batch_size=16 時,當樣本數量小于樣本1 時,BIGRU+CRF 模型的準確率高于BILSTM+CRF 模型;當樣本數量增加為樣本2 時,BIGRU 的性能不及BILSTM;當樣本數量為樣本3 時,BILSTM+CRF 模型和BIGRU+CRF 模型性能均有所提升,但BILSTM 性能仍舊優于BIGRU。綜上,若數據量較少時應使用BIGRU,當樣本數量較大時應選用BILSTM 模型。
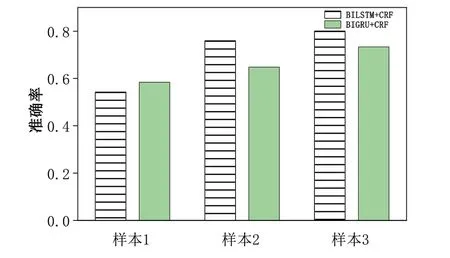
Fig.4 Impact of different datasets on model performance圖4 不同數據集對模型性能造成的影響
根據上述結論,在后續實驗中選取對模型性能最優的樣本數量(樣本3)為實驗數據。其中,樣本1 數量為300個,樣本2數量為440個,樣本3數量為715個。
3.4 模型性能比較
基于上述實驗的數據集和算法,為了進一步驗證Bert+BiLSTM+Self-Attention+CRF 模型在實體識別的優越性,將其與BiLSTM+CRF、BiGRU+CRF、Bert+CRF、Bert+Bi-GRU+CRF 和Bert+BiLSTM+CRF 模型進行比較,結果如表4所示。同時,從Bert+BiLSTM+Self-Attention+CRF 算法模型中分別增加、去除或替換不同的模塊進行消融實驗,以驗證知識抽取模型中不同模塊各自的優勢。
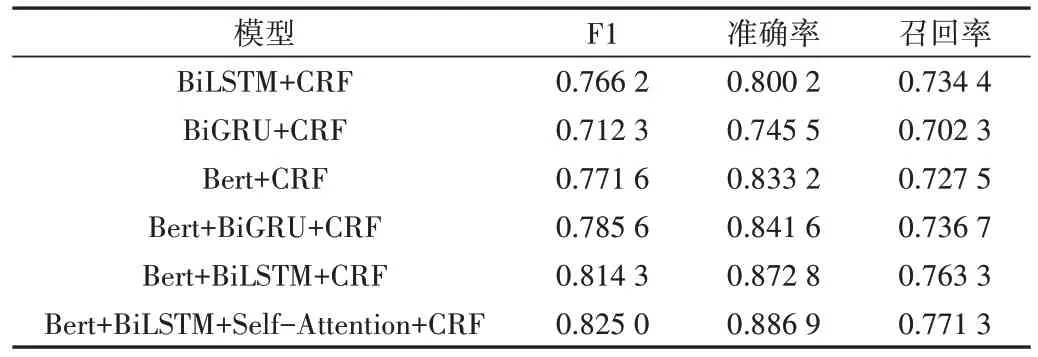
Table 4 Model performance comparison表 4 模型性能對比
由表4 可見,Bert 模塊能顯著提升算法性能,原因為Bert 層采用了Masked LM、Next Sentence Predictio 兩種方法分別捕捉詞語和句子級別的representation,模型在Bert 層捕獲全局上下文信息并對數據進行預處理,體現了Bert 層在捕獲全局上下文信息方面的有效性。由Bert+CRF、Bert+BiLSTM+CRF 模型可知,去除BiLSTM 層后知識獲取算法的準確率有所降低,因為通過堆疊的LSTM 層生成的上下文字符表示難以較好地建模上下文間的依賴關系。此外,由Bert+BiLSTM+CRF、Bert+BiLSTM+Self-Attention+CRF 模型可知,加入注意力機制后能提升模型的知識提取性能,原因為注意力機制的記憶網絡可將上下文感知信息整合到神經模型中,以幫助神經模型準確識別稀有實體和上下文相關實體。
實驗表明,Bert+BiLSTM+Self-Attention+CRF 模型在驗證集上的結果最優,F1 值可達82.50%,證實了Bert+BiLSTM+Self-Attention+CRF 模型中各功能模塊的有效性。本文還研究了模型F1、準確率及召回率隨epoch 值增加發生的變化,如圖5所示。
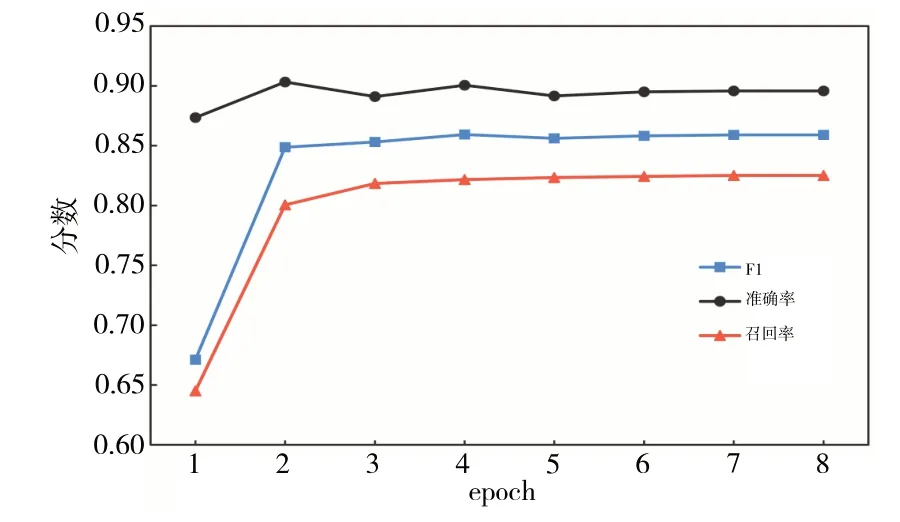
Fig.5 Trend of Bert+BiLSTM+Self Attention+CRF model changing with epoch圖5 Bert+BiLSTM+Self-Attention+CRF 模型隨epoch變化的趨勢
由圖5 可見,在第6 個epoch 值后,本文模型的F1、準確率及召回率均趨于穩定,說明此時模型參數基本為最優值,證實了Bert+BiLSTM+Self-Attention+CRF 模型在知識識別算法穩定性中具有較好的性能。
4 結語
本文研究了構建知識圖譜檢測APT 的關鍵技術,包括知識提取和融合,根據攻擊事件的諸多屬性和APT 情報數據的多源異質性,提出一種深度學習與條件隨機場學習相結合的知識提取方法,重點解決了知識的自適應抽取問題,提升了知識抽取的召回率。
同時,針對APT 情報數據冗余信息較多、信息沖突顯著的特點。首先,通過實體消歧、知識融合技術精細化知識;然后,利用深度學習對文本的詞、知識庫的實體進行聯合建模,以自動學習詞和實體的低維向量表示;最后,通過向量計算獲得詞和實體的相關性,以減少人工定義特征向量的開銷,解決特征向量稀疏的問題,提升知識實體融合模型的泛化能力。
本文在不同樣本數量、Batch_size 值的實驗參數下,與其他模型進行比較測試的結果表明,Bert+BiLSTM+Self-Attention+CRF 模型在準確率、召回率、F1 值等方面表現更優。然而,本次實驗均在同一個數據集下進行,后續將考慮利用更全面的APT 事件數據,以研究不同數據集對實驗結果造成的影響。
此外,為了進一步提升APT 檢測的準確率,考慮在現有模型基礎上進行改良,構建更大、更完整的APT 知識圖譜,加強知識圖譜在網絡安全防護中的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
