面向三維重建的自適應(yīng)步長視頻關(guān)鍵幀提取
2023-09-15 03:34:24鄭義桀陳衛(wèi)衛(wèi)羅健欣潘志松張艷艷孫海迅
軟件導(dǎo)刊 2023年9期
鄭義桀,陳衛(wèi)衛(wèi),羅健欣,潘志松,張艷艷,孫海迅
(陸軍工程大學(xué) 指揮控制工程學(xué)院,江蘇 南京 210007)
0 引言
三維重建是利用二維圖像恢復(fù)三維信息,以獲得更直觀的視覺效果。傳統(tǒng)三維重建主要通過多視角的無序圖像進(jìn)行三維建模,因此對拍攝角度、圖像清晰度要求較嚴(yán)格,且操作流程較復(fù)雜。隨著多媒體信息發(fā)展,視頻已成為信息的主要載體,相較于圖像包含著更多信息,如果能通過視頻進(jìn)行三維重建將更有實際應(yīng)用意義。
由于視頻是連續(xù)圖像幀的集合,基于視頻的三維重建歸根到底還是依賴多視角圖像,但視頻幀存在冗余量大、因相機(jī)抖動而造成圖像模糊等情況,因此需要提取視頻序列關(guān)鍵幀。當(dāng)前,關(guān)鍵幀提取算法可分為基于時間間隔采樣算法[1]、基于幀間差異提取算法[2-4]、基于內(nèi)容聚類提取算法[5-7]、基于光流運動提取算法[8-9]。其中,基于時間間隔采樣算法預(yù)先設(shè)定采樣時間間隔,遍歷所有視頻幀提取關(guān)鍵幀,實現(xiàn)簡單、速度較快、關(guān)鍵幀分布均勻,但在不同時間間隔下的結(jié)果存在較大差異,當(dāng)相機(jī)處于非勻速運動時將造成部分關(guān)鍵幀冗余或缺失;基于幀間差異提取算法取視頻第一幀為關(guān)鍵幀,與之后的圖像幀逐幀比較相似度,當(dāng)相似度小于閾值則提取關(guān)鍵幀,并以新的關(guān)鍵幀尋找下一關(guān)鍵幀,該方法能保留較多原視頻的主要內(nèi)容,但閾值的設(shè)定將直接影響關(guān)鍵幀提取的質(zhì)量且計算量較大;基于內(nèi)容聚類提取算法以圖像間的相似性為度量,依據(jù)不同類間相似性最小、類內(nèi)部相似性最大的原則,將圖像聚類后從每類中選取一幀作為關(guān)鍵幀,雖然該方法圖像冗余度相對較小,但聚類數(shù)目和聚類中心需提前設(shè)定,因此聚類數(shù)目和聚類中心設(shè)定的好壞將直接影響關(guān)鍵幀提取的質(zhì)量且計算量較大;基于光流運動提取算法通過計算圖像光點的運動信息,估計場景中相機(jī)的運動量,將一定時間范圍內(nèi)運動量最小的幀提取為關(guān)鍵幀,該方法需要計算運動量的局部極小值點,計算過程較復(fù)雜且消耗較長。
傳統(tǒng)關(guān)鍵幀提取算法的主要目的是為了用盡可能少的圖像代表整個視頻,主要應(yīng)用于視頻檢索和分類、目標(biāo)檢測和識別等任務(wù)。然而,三維重建任務(wù)需要在較清晰的圖中提取關(guān)鍵幀,不同關(guān)鍵幀間還需具備較好的重疊度,因此需要改進(jìn)傳統(tǒng)關(guān)鍵幀提取算法,使其適應(yīng)三維重建需求。陳旭等[10-12]采用一種層次化的設(shè)計解決該問題,但此類算法前期依然需要采用時間間隔采樣來降低計算量,難以適應(yīng)相機(jī)運動突變的情況。
為此,本文提出一種自適應(yīng)步長視頻關(guān)鍵幀提取算法。該算法結(jié)合基于多通道直方圖歐式距離[13]的圖像相似性度量算法和基于拉普拉斯梯度函數(shù)[14]的圖像清晰性度量算法,可根據(jù)視頻幀變換率和清晰度變換來實時確定視頻幀采樣步長,并剔除模糊視頻幀。實驗表明,該方法相較于傳統(tǒng)算法,能提升視頻關(guān)鍵幀采樣的效率和質(zhì)量。
1 自適應(yīng)步長視頻關(guān)鍵幀提取算法
本文算法總體流程如圖1 所示,其中C代表清晰度,Cl代表清晰度閾值,S代表兩幅圖像的相似度,Sl、Sh分別代表相似度最低和最高閾值,step代表視頻幀提取步長,K表示提取的關(guān)鍵幀。算法可分為兩個階段:
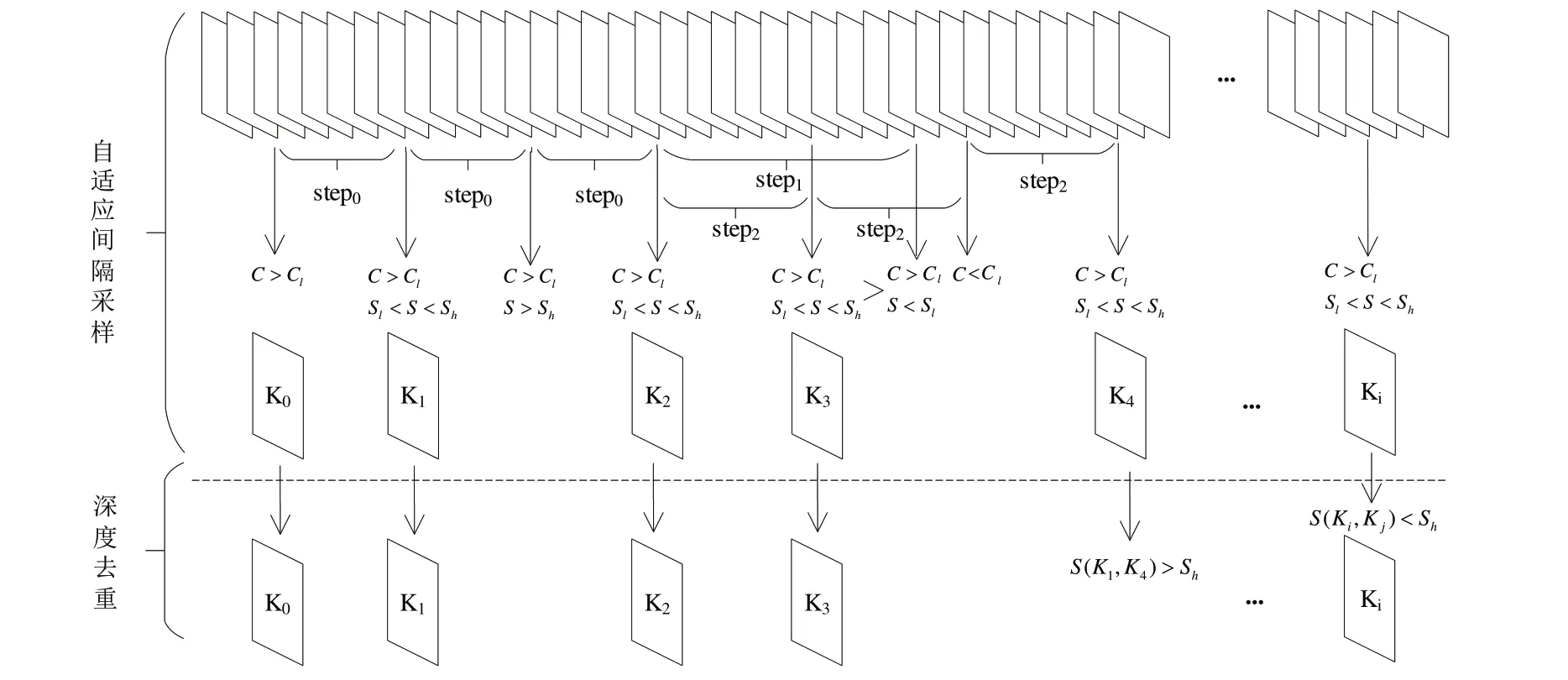
Fig.1 Adaptive step video keyframe extraction process圖1 自適應(yīng)步長視頻關(guān)鍵幀提取流程
(1)自適應(yīng)步長采樣。根據(jù)圖像間的相似度確定視頻幀提取步長,目的是盡可能減少關(guān)鍵幀的提取操作和相似度、清晰度計算過程,以最快速度提取高質(zhì)量的關(guān)鍵幀。算法開始時,假設(shè)相機(jī)勻速運動,按固定步長提取關(guān)鍵幀,一旦發(fā)現(xiàn)圖像相似度增大則需增加步長,反之減小步長;如果圖像清晰度較差則繼續(xù)以原步長向前搜索,最后生成初始關(guān)鍵幀隊列。
(2)深度去重。通過比較非相鄰關(guān)鍵幀間的相似度,剔除相似度過高的關(guān)鍵幀,目的是避免因相機(jī)環(huán)繞物體拍攝而出現(xiàn)的前后場景重合的情況。該階段將自適應(yīng)步長采樣階段生成的初始關(guān)鍵幀隊列的每個關(guān)鍵幀,與非相鄰關(guān)鍵幀進(jìn)行相似度計算,如果高于閾值則去除其中一個關(guān)鍵幀,最終生成關(guān)鍵幀隊列。
其中,自適應(yīng)步長采樣階段主要可分為以下3 個步驟:
步驟1:確定首關(guān)鍵幀。第一個關(guān)鍵幀的要求是清晰度高,為后續(xù)關(guān)鍵幀選取提供參照。從第一幀開始逐幀判斷,滿足清晰度要求即加入關(guān)鍵幀隊列。
步驟2:確定初始步長。從第一關(guān)鍵幀后逐幀判斷,將第一個滿足清晰度和相似度要求的視頻幀加入關(guān)鍵幀隊列,并設(shè)其為參考幀,將兩幀間的幀數(shù)作為初始步長。
步驟3:向前搜索關(guān)鍵幀。按照原步長在參考幀后向前搜索視頻幀,此時有3 種情況:①當(dāng)前幀滿足清晰度、相似度要求時,將該幀加入關(guān)鍵幀隊列并設(shè)為新的參考幀;②當(dāng)前幀滿足清晰度要求但相似度過低時,按照回退折半查找方法向后搜索關(guān)鍵幀;③當(dāng)前幀滿足清晰度要求但相似度過高或清晰度不夠時,按原步長繼續(xù)向前搜索關(guān)鍵幀。
1.1 回退折半查找關(guān)鍵幀算法
當(dāng)前幀相似度過低進(jìn)行回退折半查找時,由于視頻變化存在一定規(guī)律,因此,一旦視頻幀出現(xiàn)模糊幀,則此幀周圍必然存在一定數(shù)量的模糊幀,為了提高效率,如圖2 所示,若發(fā)現(xiàn)中間幀為模糊幀,則以本輪折半查找的最前幀作為關(guān)鍵幀,采用函數(shù)調(diào)用方式實現(xiàn)回退折半查找,如算法1所示。
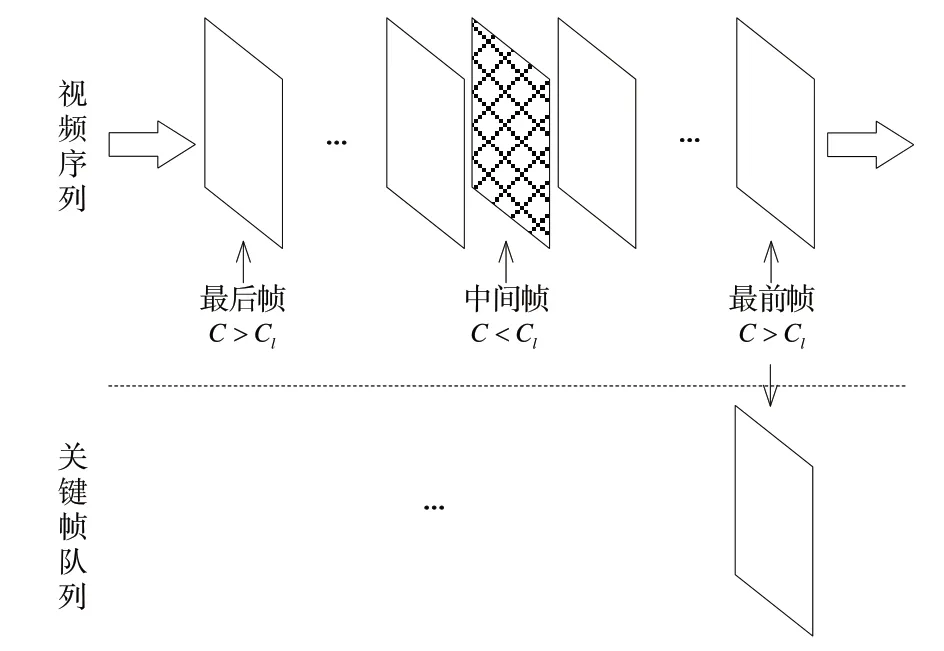
Fig.2 Principle of split-half search for key frames圖2 折半查找法搜索關(guān)鍵幀原理
算法1回退折半查找關(guān)鍵幀算法
1.2 向前搜索關(guān)鍵幀算法
當(dāng)前幀相似度過高繼續(xù)向前搜索關(guān)鍵幀時,同樣采用函數(shù)調(diào)用的方法實現(xiàn)。如果當(dāng)前幀相似度過高或出現(xiàn)模糊的情況,依然以原步長向前搜索;如果當(dāng)前幀相似度過低,則采用回退折半查找方式搜索關(guān)鍵幀,具體流程如算法2所示。
算法2向前搜索關(guān)鍵幀算法
1.3 自適應(yīng)步長視頻關(guān)鍵幀提取算法
然而,回退折半查找法提取的視頻幀并不一定滿足相似度要求,也不能確定相機(jī)運動是否發(fā)生突變。因此,在更新步長時,如果當(dāng)前關(guān)鍵幀與前一關(guān)鍵幀間的幀差與原步長不同,則需要判斷兩個關(guān)鍵幀間相似度是否滿足要求,滿足則更新步長,反之步長保持不變。自適應(yīng)步長關(guān)鍵幀提取流程如算法3所示。
算法3自適應(yīng)步長視頻關(guān)鍵幀提取算法
1.4 關(guān)鍵幀隊列深度去重算法
在深度去重階段剔除非相鄰關(guān)鍵幀間相似度過高的關(guān)鍵幀,具體流程如算法4所示。
算法4關(guān)鍵幀隊列深度去重算法
2 基于多通道直方圖歐式距離的圖像相似性度量算法
2.1 算法原理
在本文提出的視頻關(guān)鍵幀提取算法中,計算圖像相似度是關(guān)鍵,目前基于直方圖的相似度計算是較為常用的方法。首先進(jìn)行灰度處理,記錄像素灰度值;然后統(tǒng)計每個灰度的次數(shù),生成圖像灰度直方圖;最后通過兩個直方圖的歐式距離代表圖像相似性進(jìn)行灰度處理,雖然能簡化計算,但容易造成誤差,尤其在三維重建中顏色不同將直接影響視角匹配的精確度。為此,本文采用基于多通道直方圖歐式距離計算圖像相似度。首先通過直方圖歐式距離計算R、G、B 通道的相似性,然后計算3 個通道相似性的平均值,并將其作為兩幅圖像的相似性。對于任一顏色通道,兩幀圖像的直方圖分別為H={h1,h2,…,hn}、G={g1,g2,…,gn},該顏色通道相似性可表示為:
式中:n為像素值劃分?jǐn)?shù)量,像素值范圍為[0,255],為了提升比較效果,n取256。兩幅圖像的相似度可表示為:
2.2 相似度閾值
相鄰兩幅圖像相似度需要設(shè)定合理閾值,相似度太高將造成圖像冗余度大、后期三維重建計算量大;相似度太小則會導(dǎo)致圖像匹配困難、三維重建精度不高。為了合理選擇閾值,本文采用文獻(xiàn)[15]的相機(jī)視角選擇方式對每個視頻幀進(jìn)行評分。具體為,針對一段視頻序列,首先選取某個圖像i,計算該圖像與其他圖像j的匹配得分Score(i,j);然后按得分進(jìn)行排序,選取得分最高的10 個圖像。其中,匹配得分的計算方法如式(3)所示。
式中:p為圖像i、j的可視三維點;θij(p)為p與視角i、j的相機(jī)中心連線夾角,計算方法如式(4)所示。
式中:ci、cj分別為視角i、j的相機(jī)中心。
Φ(θ)為分段高斯函數(shù):
式中:θ0為一個確定的基線夾角,越接近該夾角得分越高,本文參照DTU 數(shù)據(jù)集參數(shù)設(shè)置方法,將θ0、σ1、σ2設(shè)置為5、1、10。
本文選取tanks and temples 數(shù)據(jù)集[16]進(jìn)行測試,按照上述方法計算視頻序列中每個圖像與其他圖像的匹配得分并排序。選取得分最高的前10 幀匹配圖像后,計算各個圖像與其他圖像對應(yīng)的10 幀匹配圖像的直方圖相似性,Museum、Panther、Horse、Family 視頻結(jié)果如圖3所示。
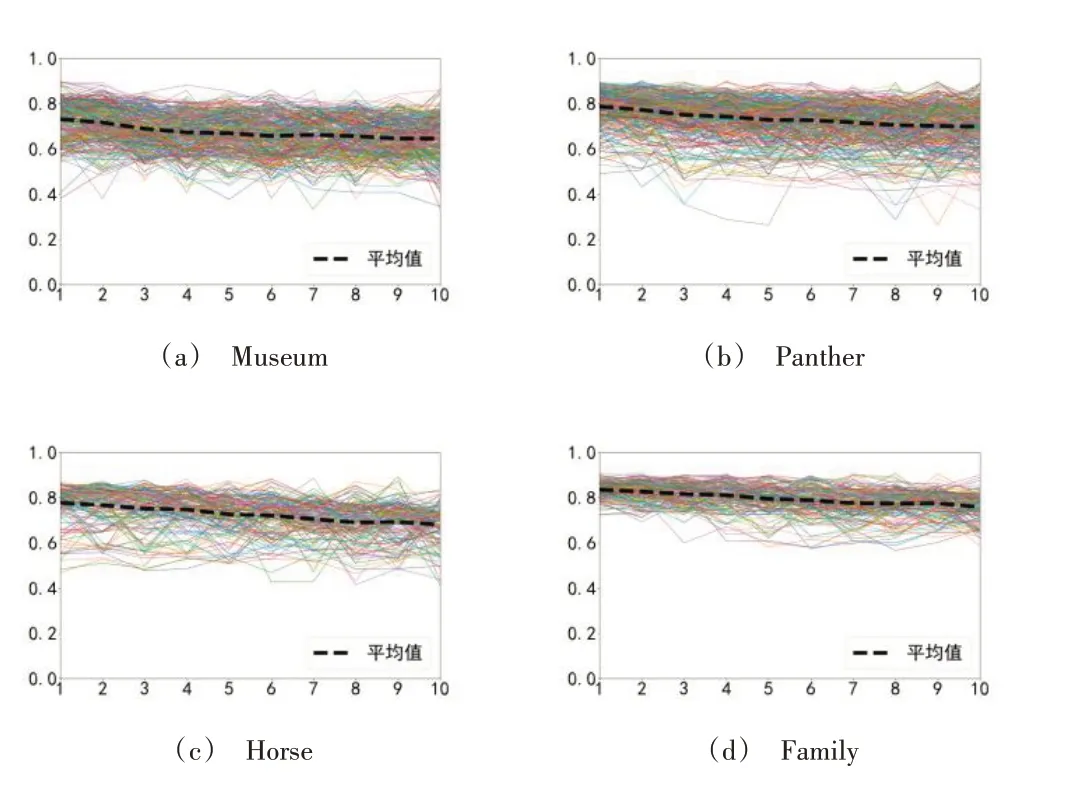
Fig.3 Matching image similarity between different video frames圖3 不同視頻幀匹配圖像相似度
圖3 橫軸為匹配圖像序號,縱軸為相似度。由此可見,每個圖像與其匹配圖像的相似度在0.60~0.90,且總體隨得分呈下降趨勢。此外,結(jié)合文獻(xiàn)[10]中指出相鄰圖像相似度應(yīng)低于0.88,因此本文將相似度閾值設(shè)置為0.60~0.88。
3 基于拉普拉斯函數(shù)的清晰性度量算法
3.1 算法原理
由于本文在評價圖像清晰度時無參考圖像,因此可將該問題歸為無參考圖像清晰度評價,采用常用的拉普拉斯(Laplacian)梯度函數(shù)進(jìn)行計算。Laplacian 算子的定義如式(6)所示,圖像清晰度函數(shù)定義如式(7)所示。
式中:G(x,y)為像素點(x,y)處Laplacian 算子卷積。
3.2 清晰度閾值
為確定清晰度閾值,研究tanks and temples 數(shù)據(jù)集中視頻清晰度的變化規(guī)律。首先,對原圖添加3 種不同程度的運動模糊[17];然后比較不同模糊下清晰度值發(fā)生的變化,Horse、Family 的測試結(jié)果如圖4 所示。其中,橫軸表示視頻幀序號,縱軸表示清晰度。
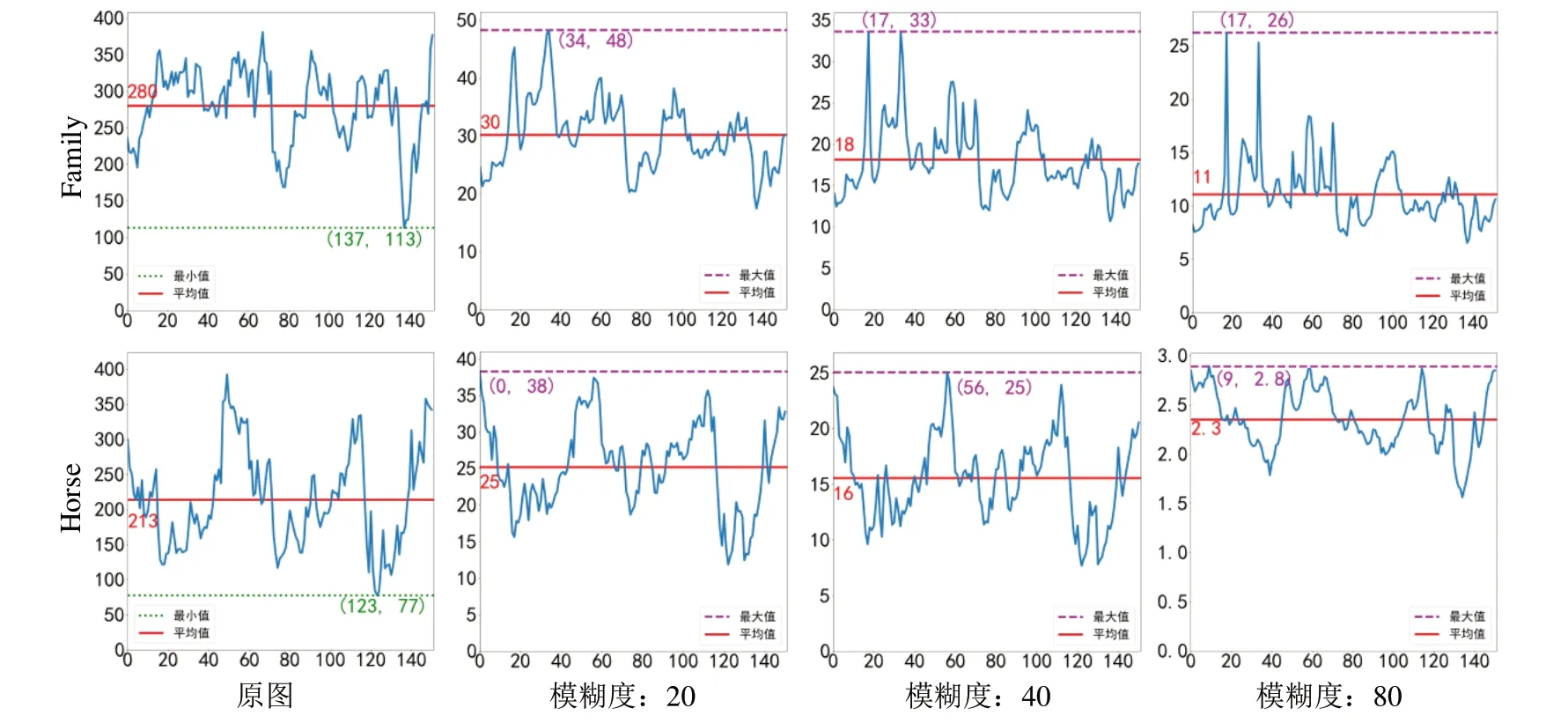
Fig.4 Image sharpness changes after different degrees of blur圖4 不同程度模糊后圖像清晰度變化
由圖4 可見,原圖清晰度均在70 以上,經(jīng)過模糊后清晰度下降明顯,均在50 以下。為了盡量保證圖像質(zhì)量,本文將清晰度閾值設(shè)為70。
4 實驗與結(jié)果分析
4.1 實驗環(huán)境與評價方法
本文編程語言為Python,在Ubuntu18.4 Intel(R)Xeon(R)Gold 5118 CPU 系統(tǒng)上進(jìn)行測試。首先提取視頻關(guān)鍵幀,然后通過MVE[18]進(jìn)行三維重建。MVE 是一個開源、基于傳統(tǒng)方法的三維重建系統(tǒng),從輸入多視角圖片開始,包含了運動重建、稠密重建、網(wǎng)格重建、紋理貼圖整個流程。由于本文主要比較重建效果,因此只采用運動重建、稠密重建這兩個模塊。
將本文算法與時間間隔采樣算法[1]、幀間差異提取算法[19]、K-means 聚類提取算法[5]和光流運動提取算法[8]進(jìn)行比較,根據(jù)關(guān)鍵幀提取時間、關(guān)鍵幀數(shù)量、關(guān)鍵幀質(zhì)量和三維重建質(zhì)量分析各算法特點。具體的,關(guān)鍵幀質(zhì)量包括有無模糊關(guān)鍵幀或相似度過高的關(guān)鍵幀;圖像相似度過高定義為兩幅圖像間基于多通道直方圖歐式距離>0.88;圖像模糊定義為圖像的拉普拉斯梯度函數(shù)值<70;三維重建質(zhì)量主要用來比較重建的三維點云與真實物體的相似程度,可分為點云精確度和完整度。其中,精確度通過重建的三維點云與真實物體點云的距離來衡量,表示重建點的精度;完整度表示物體表面被重建的完整程度,一般以兩者間的平均值作為最終點云質(zhì)量的評價指標(biāo)。
本文采用DTU 數(shù)據(jù)集評價計算方法,假設(shè)基準(zhǔn)三維點云中空間點gi,重建點云距離gi最近的三維點ri的歐氏距離為di,具體精確度計算方式為:
式中:|R|表示重建點云中參與評價的點云數(shù)量,重建點云精度越高,精確度值A(chǔ)cc越小。
完整度計算方式為:
式中,|G|表示基準(zhǔn)三維點云的空間點個數(shù),重建點云的完整度越高,完整度值Comp越小。
整體度為兩者平均值:
4.2 實驗數(shù)據(jù)
通常情況下,以tanks and temples 數(shù)據(jù)集中的視頻Caterpillar 片段作為數(shù)據(jù)集進(jìn)行實驗,但該視頻均為高清視頻且相機(jī)勻速運動,因此本文參考文獻(xiàn)[20]的方法制作了一段虛擬視頻Visual Car,并且虛擬視頻通過人工控制相機(jī)運動,可方便、有效的評估視頻幀提取算法。其中,Caterpillar 是高清勻速視頻、Visual Car 是變速且包含模糊幀的視頻。
本文利用Unity3D 引擎搭建了一個虛擬場景,設(shè)置相機(jī)勻速、加速和減速運動并增加抖動情況,因此該視頻包含了變速和模糊情況,可有效檢測算法在不同情況下的性能。圖5 展示了兩段視頻中的部分視頻幀,具體參數(shù)如表1 所示。為了比較點云重建質(zhì)量,采用tanks and temples 數(shù)據(jù)集給出的Caterpillar 基準(zhǔn)點云,Visual Car 的基準(zhǔn)點云需手動制作。首先通過Unity3D 生成多視角圖像和視角相機(jī)參數(shù),然后通過深度學(xué)習(xí)多視角網(wǎng)絡(luò)PatchMatchNet[21]生成三維點云,如圖6所示。

Table 1 Video data parameters表1 視頻數(shù)據(jù)參數(shù)

Fig.5 Video part video frame圖5 視頻部分視頻幀

Fig.6 Datum point cloud圖6 基準(zhǔn)點云
4.3 實驗結(jié)果
本文調(diào)整時間間隔采樣算法的時間間隔、K-means 聚類提取算法的類間距和光流運動提取算法的光流變化閾值等參數(shù),使3 種算法生成的關(guān)鍵幀數(shù)量與本文算法基本相同,并將幀間差異提取算法的幀間差異閾值與本文算法中相鄰圖像相似性閾值設(shè)置一致。
表2 展示了各算法提取Caterpillar 關(guān)鍵幀的結(jié)果,圖7為重建的點云效果。由此可知,時間間隔采樣算法耗時最少,但由于該算法不比較幀之間的變化,容易存在高相似幀情況,重建效果一般;幀間差異提取算法需比較每兩幀間的差異,用時最長,不具備高相似幀,重建結(jié)果相對較好;K-means 聚類提取算法用時較長,存在高相似幀,重建結(jié)果最差;光流運動提取算法需提取圖像光流信息并比較光流變化,耗時最長且重建點云完整性較差;本文算法耗時雖然為時間間隔采樣算法的3 倍,但僅為幀間差異提取算法的1/13.5、K-means 聚類提取算法的1/9.1、光流運動提取算法的1/15,且不存在高相似幀,重建質(zhì)量最優(yōu)。
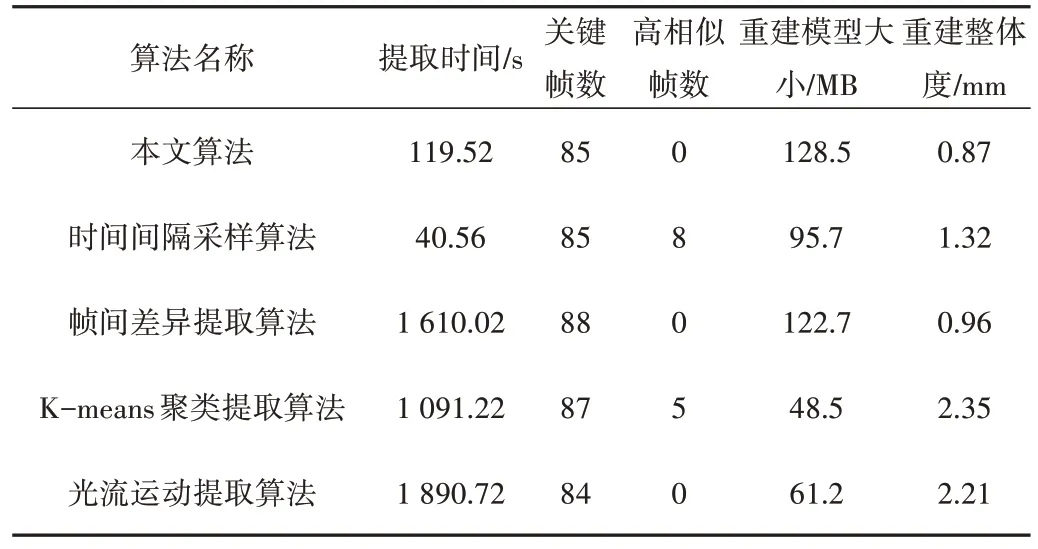
Table 2 Comparison of Caterpillar key frame extraction results表2 Caterpillar關(guān)鍵幀提取結(jié)果比較

Fig.7 Comparison of reconstruction effect of different algorithms in Caterpillar圖7 不同算法在Caterpillar的重建效果比較
表3 展示了各算法提取Visual Car 關(guān)鍵幀的結(jié)果,圖8為重建的點云效果。由此可知,時間間隔采樣算法雖然耗時最短,但不存在高相似幀和模糊幀的識別能力,重建點云質(zhì)量較差;幀間差異提取算法可剔除高相似幀,但提取時間最長且包含大量模糊幀,因此重建點云質(zhì)量較差;Kmeans 聚類提取算法耗時長,包含高相似幀和模糊幀,重建點云完整性不高,存在較多雜點;光流運動提取算法用時最長,存在較多高相似幀和模糊幀,重建點云質(zhì)量一般;本文算法用時雖然相較于時間間隔采樣算法耗時更長,但僅為幀間差異提取算法的1/5.19、K-means 聚類提取算法的1/4.29、光流運動提取算法的1/5.56,且不存在高相似幀和模糊幀,重建點云質(zhì)量最優(yōu)。
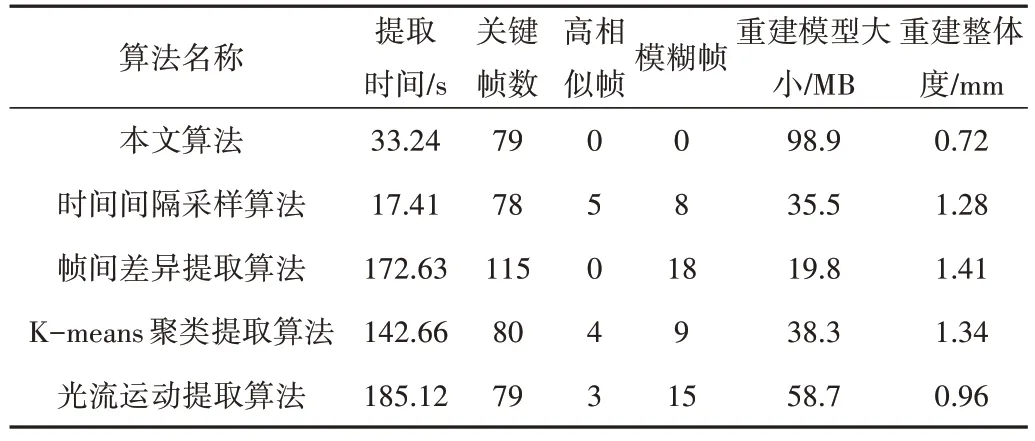
Table 3 Comparison of extraction results of Visual Car key frames表3 Visual Car關(guān)鍵幀提取結(jié)果比較
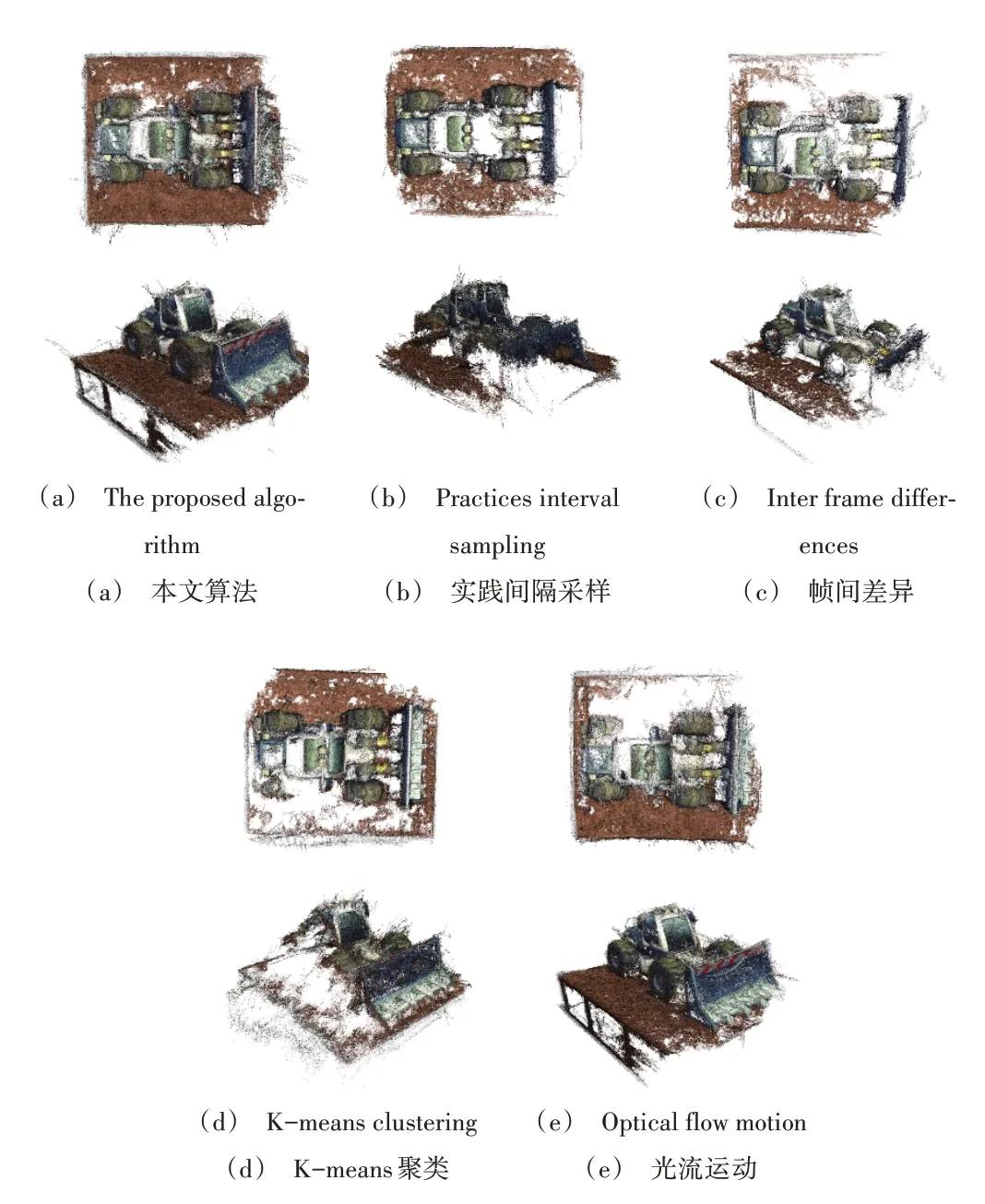
Fig.8 Comparison of reconstruction effect of different algorithms in Visual Car圖8 不同算法在Visual Car的重建效果比較
綜上所述,時間間隔采樣算法需提前調(diào)整時間間隔,K-means 聚類提取算法需提前設(shè)置類間距,光流運動提取算法需提前設(shè)置光流變化閾值,因此難以適應(yīng)動態(tài)變化的視頻,且不具備高相似幀和模糊幀的識別能力。本文算法在高清勻速視頻或變速模糊視頻下,在提取關(guān)鍵幀時相較于現(xiàn)有方法存在一定優(yōu)勢。
此外,幀間差異提取算法計算量過大,且不具備模糊幀識別能力。本文算法通過設(shè)置步長可減少視頻幀間的比較計算用時,通過清晰度判斷剔除模糊幀、幀間差異的變化以動態(tài)改變步長,既保證了關(guān)鍵幀間具有較好的視角變化,又能快速確定下一關(guān)鍵幀的位置。
為了進(jìn)一步比較算法的通用性,本文通過相機(jī)隨機(jī)拍攝了3 個物體的視頻,分別采用上述5 種算法提取關(guān)鍵幀,并采用MVE 進(jìn)行三維重建,重建點云效果如圖9 所示。由此可見,雖然本文提出的關(guān)鍵幀提取算法無法保證點云重建效果總為最優(yōu),但算法魯棒性較強(qiáng),重建的點云質(zhì)量普遍較高。
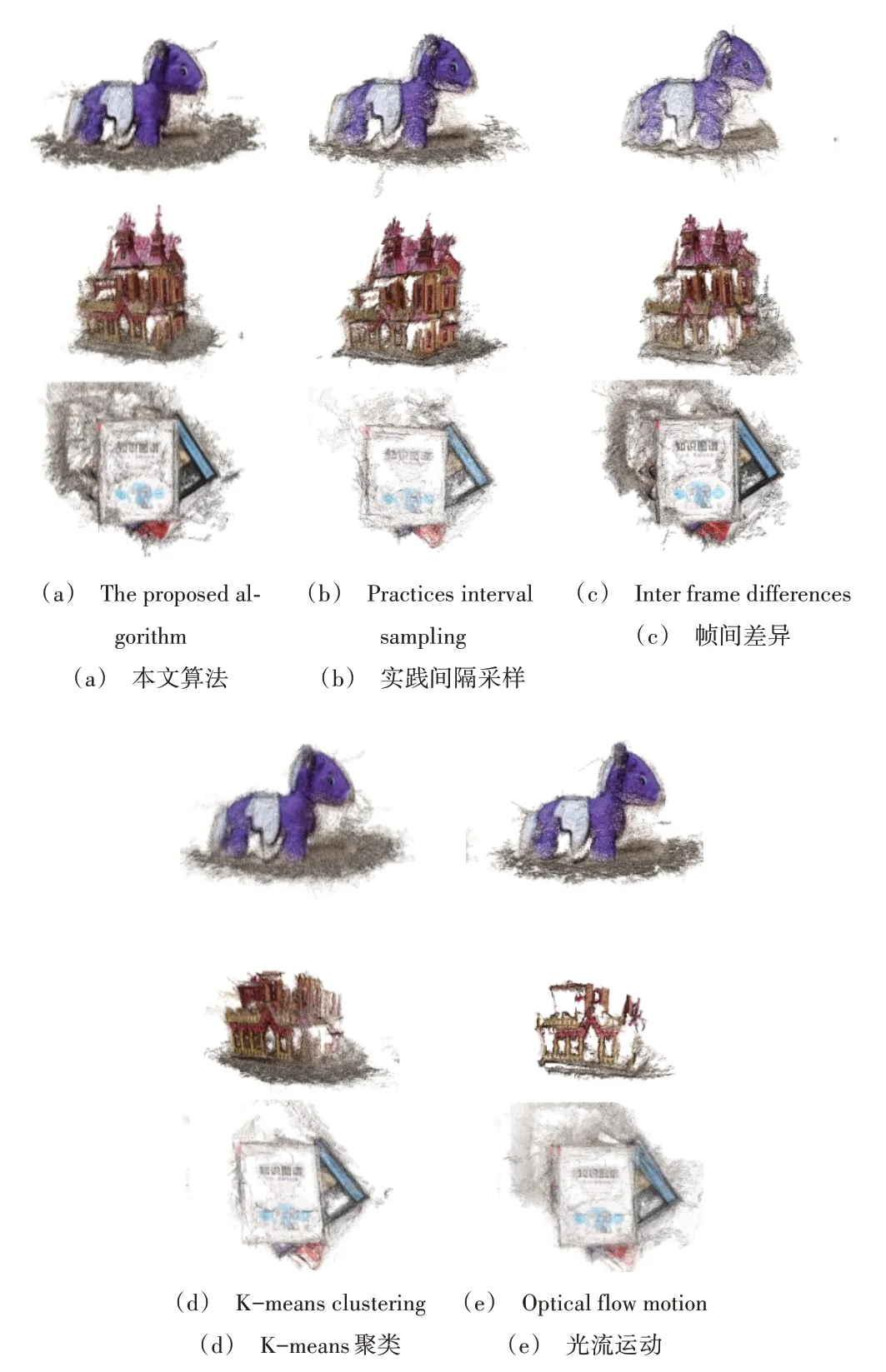
Fig.9 Comparison of reconstruction effect of objects taken by camera圖9 相機(jī)拍攝物體重建效果比較
5 結(jié)語
本文基于多通道直方圖歐氏距離的圖像相似性與拉普拉斯梯度函數(shù)的圖像清晰度計算方式,提出一種面向三維重建的自適應(yīng)步長視頻關(guān)鍵幀提取算法。根據(jù)視頻幀的變化快慢、清晰度,以實時確定視頻幀采樣步長、去除模糊視頻幀。
實驗結(jié)果表明,該算法相較于多種傳統(tǒng)算法能提升視頻關(guān)鍵幀采樣的效率和質(zhì)量,三維重建效果最優(yōu),但提取的視頻關(guān)鍵幀數(shù)量仍然較多。下一步,將重點研究關(guān)鍵幀數(shù)量與三維重建效果的關(guān)系,以改進(jìn)關(guān)鍵幀提取算法,進(jìn)一步提升視頻關(guān)鍵幀提取的效率和質(zhì)量。
