基于YOLOv5的水果品質檢測與分類方法研究
2023-09-15 03:34:32羅家梅
軟件導刊 2023年9期
羅家梅,王 敏,2
(1.贛南師范大學 數學與計算機科學學院;2.江西省數值模擬與仿真技術重點實驗室,江西 贛州 341000)
0 引言
目前,水果產業已經成為我國繼糧食、蔬菜之后的第三大農業種植產業,是國內外市場前景廣闊且具有較強國際競爭力的優勢產業。人工智能技術支持下的水果品質檢測與分類技術對于水果生產、加工、運輸和銷售具有重要意義,尤其是在快節奏的“互聯網+”環境下,水果品質檢測與分類方法的性能和速度直接影響水果產業的經濟效益和市場競爭力。最早的水果品質檢測與分類工作依賴人工,容易受到人的情緒、疲勞程度以及身體狀況等因素影響,而且每個人的分類標準有所差異,從而導致高成本、低效率的弊端。隨后,機械檢測分類方法逐漸替代人工檢測[1],但該方法會對水果造成一定程度的損傷,導致其保質期縮短甚至腐爛,直接影響經濟效益。因此,目前學者們開始嘗試使用以機器視覺和機器學習為代表的人工智能技術研究水果品質檢測與分類方法。傳統智能檢測方法是基于特征設計與分類實現的,特征設計主要是提取顏色[2]、形狀[3]和紋理[4]等特征,經典分類方法包括支持向量機[5]、人工神經網絡[6]、最鄰近分類[7]等。然而這些方案都是通過從大量數據中獲取有用特征并建立有效模型來處理問題,受限于算法自身的局限性,在復雜場景下同時檢測水果品質和種類的魯棒性差,難以滿足實時檢測要求。
基于深度學習的水果檢測方法分為基于候選區域的目標檢測方法和基于回歸的目標檢測方法兩類。基于候選區域的目標檢測方法亦稱為兩階段方法,典型網絡模型包括Fast R-CNN(Fast Region-based Convolutional Neural Network)、Mask-RCNN(Mask Region-based Convolutional Neural Network)等。基于回歸的目標檢測方法也被稱為一階段方法,該類方法能在一個網絡中同時進行回歸和分類操作,減少了計算量并提升了檢測速度,典型網絡模型包括YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)等。融合深度學習技術的水果品質檢測與分類方法較傳統機器學習方法具有一定優勢,但檢測性能和速度仍有提升空間。
1 相關研究
為達到高效、精確且非接觸的檢測目的,自20 世紀70年代起,國內外學者將機器視覺技術應用于水果分類研究中,并取得了一定成果。例如,Zeeshan 等[2]提出使用計算機視覺和支持向量機對18 類水果進行分類,通過提取顏色、紋理和形狀特征創建特征空間,然后結合支持向量分類器進行分類,最終分類準確率達到了87.06%;Yue 等[3]以煙臺蘋果為研究對象構建分類檢測系統,利用Canny 邊緣算法提取蘋果的外輪廓,通過幾何計算提取大小特征,同時采用圓形法提取水果形狀特征,分類準確率達到92.33%,但該方法存在一定的機械損失;艾妮[4]以機器視覺技術為基礎構建水果自動分揀系統,通過提取中心關鍵點的方法對目標水果進行定位,最終該系統對于形狀規則的蘋果和橘子分類準確率可達92%,但對于形狀不規則的水果難以取得良好分類效果;Bekkanti 等[5]提出利用Sobel邊緣檢測和支持向量機對患病水果進行自動檢測,對患病水果和非患病水果的分類準確率達到92%;Huang 等[6]使用人工神經網絡探索土壤和葉片中礦物質養分對枇杷果實品質的影響,同時進行了敏感性分析以確定果實質量,所建立的人工網絡預測模型通過優化礦物元素含量來提高枇杷果實品質;饒劍等[7]設計了一套由成像系統、照明設備、傳送裝置和數據處理中心等組成的類球形水果外形尺寸在線檢測系統,將類球形水果的表面缺陷特征參量作為重要檢測指標,并以此進行分級判定,最終平均識別率達94.4%。然而,以上方法性能依賴于水果表面特征設計和分類方法的選取,存在兩方面問題:一是特征提取需要人工設計,工作量較大;二是同時進行特征提取和分類的傳統機器學習方法對系統性能較高。
近年來,深度學習技術在水果品質檢測與分級分類中的應用越來越廣泛。例如,Mai 等[8]將多分類器融合策略合并到Faster R-CNN 網絡模型中對兩個小型水果數據集進行檢測,使用相關系數衡量分類器的多樣性,并引入一種具有分類器相關性的損失函數訓練區域提議網絡,取得了較好的檢測效果,但由于該方法需要邊界框注釋,檢測效率較低;Liu 等[9]采用R-FCN(Region-based Fully Convolutional Networks)方法識別復雜背景下的水果目標,通過降低提取候選區域的時間提高了檢測速度,但檢測精度存在一定提升空間;王紅君等[10]采用改進YOLOv3 模型檢測復雜環境中的蘋果、桃子、香橙、梨,最終平均精度達到92.27%,檢測速度為45 幀/s;王卓等[11]提出一種以YOLOv4 為基礎的輕量化蘋果實時檢測方法YOLOv4-CA,通過引入深度可分離卷積和坐標注意力機制,在降低網絡計算復雜度的同時提高了抗背景干擾能力,最終平均檢測精度為92.23%,在嵌入式平臺的檢測速度為改進前模型的3倍;涂淑琴等[12]提出基于殘差網絡[13]和特征金字塔網絡(Feature Pyramid Network,FPN)[14]的FasterR-CNN 檢測算法,對無遮擋、遮擋、重疊和有背景4 種情況下的百香果進行自動檢測,最終得到平均檢測精確率為87.98%;黃豪杰等[15]針對自然環境下目標水果檢測率不高和檢測模型泛化性不強等問題,提出一種基于深度學習的SSD 改進模型,其以蘋果、橙子、荔枝作為研究對象,以自然環境為研究背景,得到由SSD 改進的SSD300 和SSD512 模型平均檢測精度分別為83.05%、84.24%。然而,以上研究僅針對類球形水果展開,對非類球形水果品質檢測與分類的研究有待加強。
從以上分析可知,基于傳統深度學習技術的水果檢測方法仍有提升空間。YOLOv5 具有檢測精度較高、速度快和易部署等優勢[16],為此提出基于YOLOv5 目標檢測算法的水果品質檢測與分類方法,以期為為實際農業場景下的水果品質檢測提供新思路。
2 YOLOv5模型
YOLO 是一種廣泛應用于工業[17-18]、交通[19-21]、醫療[22]和農業[23-25]等領域的目標檢測網絡模型,其于2016年由Joseph Redmon 等[26]首次提出,隨后相繼提出YOLOv2、YOLOv3[27]、YOLOv4[28]、YOLOv5[12]版本。YOLOv5在YOLOv4 的基礎上進行了參數優化調整,檢測速度有所提升。例如YOLOv5 在Tesla P100 加速器上可實現140 幀/s 的快速檢測,能夠滿足工業生產線實時檢測要求。按照模型大小不同,YOLOv5 推出了s、m、l和x4 個不同網絡深度和寬度的網絡模型,其中YOLOv5s 網絡是YOLOv5 系列中深度最小、特征圖寬度最小的模型。為滿足水果表面質量檢測速度要求,本文采用計算速度最快的YOLOv5s模型。
如圖1所示,YOLOv5s算法網絡模型主要分為輸入端、骨干端、頸部端、頭部端4 個模塊。輸入端的主要功能是對輸入圖像進行預處理,包括Mosaic 數據增強、自適應錨框計算、自適應圖像縮放3 個模塊,其中Mosaic 數據增強以4 張圖像為輸入,通過隨機縮放、隨機裁剪、隨機排布的方式進行拼接;自適應錨框計算對訓練輸出中的預測框與真實框進行距離計算,通過反向迭代達到更新網絡參數的目的;自適應圖像縮放則利用等比縮放或黑邊填充方法得到統一圖像,從而提高目標檢測速度。骨干端由 Focus、Conv、BottleneckCSPn、空間金字塔池化(Spatial Pyramid Pooling,SPP)等模塊組成,其是網絡的主干部分。該模塊采用Focus 結構對圖片進行切片操作,將其切分為4 張互補的圖片,最后進行卷積運算。BottleneckCSPn 由3個卷積層和N 個Bottleneck 模塊Concat 組成,如果帶有False 參數則未使用Bottleneck 模塊,而是采用Conv+BN+Leaky_Relu+Conv,其中Bottleneck 先是1×1 的卷積層,再是3×3 的卷積層,最后通過殘差結構與初始輸入相加,主要目的是減少參數數量,從而減少計算量,且在降維之后可以更加有效、直觀地進行數據訓練和特征提取。在特征生成部分則沿用之前的SPP 結構,主要作用是增加特征的多樣性,防止過擬合現象出現,同時加快網絡收斂速度。頸部端網絡采用路徑聚合網絡(Path-Aggregation Network,PANet)進行特征融合,即在FPN 自頂向下的基礎上添加一個自底向上的信息流通路徑,有利于提高特征提取能力。頭部端輸出端采用GIOU 函數作為邊界框的損失函數,在目標檢測后處理過程中使用非極大值抑制(Non Maximum Suppression,NMS)對多目標框進行篩選,增強了多目標和遮擋目標的檢測能力。
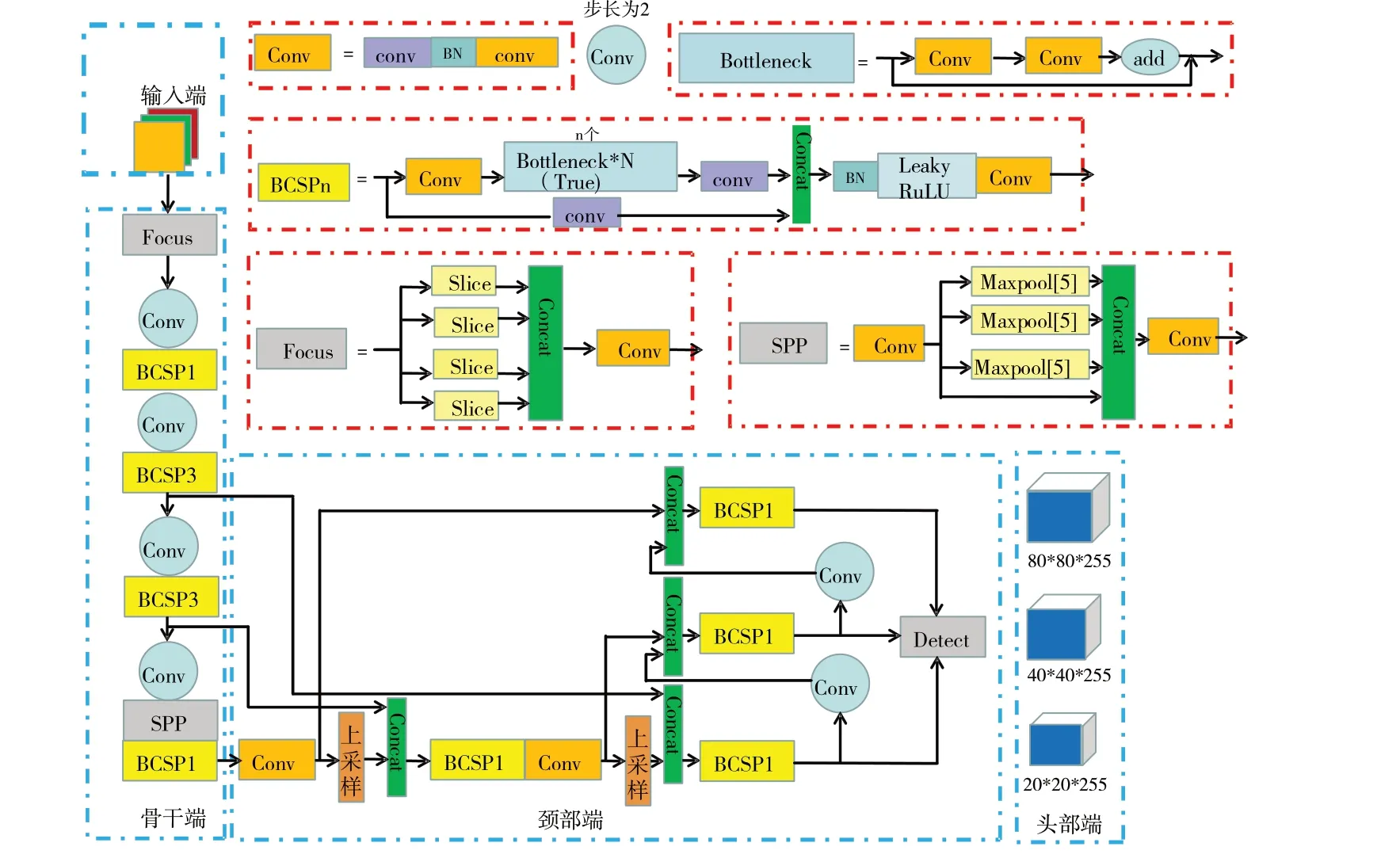
Fig.1 Network structure of YOLOv5s圖1 YOLOv5s網絡結構
3 數據集構建
通過現場拍攝和網絡爬蟲方法進行圖像采集,為保證分類效果,照片覆蓋4 類不同品質、不同形狀和紋理的水果。數據集具體構建步驟為:
(1)數據采集。實驗數據集由網絡數據和現場數據兩部分組成,其中網絡數據由爬蟲工具從互聯網獲取的蘋果、橘子、香蕉和梨4 種果實形狀不同的水果圖像組成;現場數據則由相機或手機在果園和超市等地點拍攝得到。需要注意的是,現場圖像數據是在不同光照條件、角度和背景環境拍攝得到的,因此最后需從數據集中剔除像素不清晰以及果實存在嚴重遮擋的圖像。
(2)數據標注。使用LabelImg 軟件對圖像數據進行標注,并以PascalVOC 格式保存為XML 文件,文件名與圖像名保持一致。圖2給出了蘋果的標注示例。

Fig.2 Apple annotation example圖2 蘋果標注示例
(3)數據分割。通過上述兩個步驟得到2 190 張圖像,按照8∶1∶1的比例將其劃分為訓練集、驗證集和測試集。
4 實驗方法
4.1 實驗環境與參數設置
實驗計算機配有i7-7820X CPU、Geforce GTX 1080 Ti顯卡和128 GB 內存,操作系統為Windows Server 2019,采用PyTorch 1.10 深度學習框架。實驗使用隨機梯度下降(Stochastic Gradient Descent,SGD)[29]優化器訓練網絡,修改目標種類參數nc(number of classes)為8,同時分別命名為apple、damaged_apple、orange、damaged_orange、pear、damaged_pear、banana、damaged_banana。數據集配置文件ab.yaml 中設置好數據集路徑,輸入圖像尺寸為900×900,迭代次數(epochs)為300,批處理大小(batch size)為8,動量因子為 0.937,權重衰減系數為0.000 5。選用自動錨點檢測,采用Mosaic 數據增強策略,初始學習率為0.001。
4.2 評價指標
使用精確率(Precision)和召回率(Recall)作為水果分類評價指標,表示為:
式中:TP為被判為正類的正類(正確檢測),FP為被判為正類的負類(錯誤檢測),FN為被判為負類的正類。使用IoU 設為0.5 時的平均精度均值(mAP_0.5)、同IoU 閾值(從0.5 到0.95,步長0.05)的平均mAP(mAP_0.5:0.95)、精確率、召回率作為模型評價指標。平均精度(AP)表示 Precision-Recall 曲線下面積,對該圖片每一類的平均精度求均值即得mAP,計算公式為:
式中:N 為該圖片不同類別的總和。
5 實驗結果與分析
5.1 網絡模型訓練結果
在以上參數環境下進行模型訓練,對訓練結果進行可視化繪圖,模型精確率、召回率、mAP_0.5、mAP_0.5:0.95如圖3 所示。可以看出,當迭代次數小于200 時,精確率、召回率、mAP_0.5 和mAP_0.5:0.95 均隨迭代次數的增加快速上升。當迭代次數大于200 時,各項性能指標逐漸趨向平穩,模型精確率和召回率均穩定在90%以上,平均精度均值為95.3%,模型在訓練階段性能較為理想。
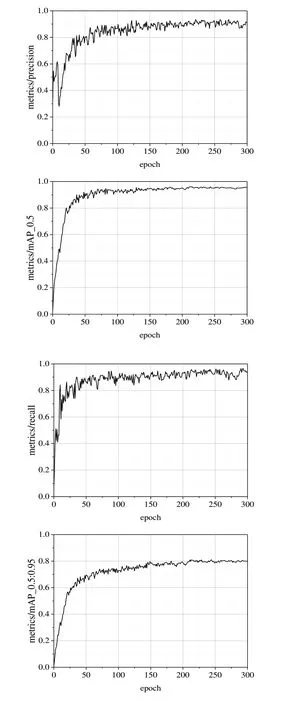
Fig.3 Model training results圖3 模型訓練結果
5.2 性能比較
選 擇YOLOv3、YOLOv3-spp、YOLOv3-tiny 和YOLOv4-tiny 4 種網絡模型作為比較模型,與本文模型在相同計算機環境下的同一個數據集中進行實驗,結果如表1 所示。可以看出,本文提出的YOLOv5s 方案平均檢測精度值達到95.3%,與YOLOv3、YOLOv3-spp、YOLOv3-tiny 和YOLOv4-tiny 相比分別提高了3.7%、0.2%、13.1%和8.73%。YOLOv5s 在damaged_apple、damaged_orange、pear 和damaged_banana 4 個類別上的表現最優;YOLOv3-spp 在apple、orange 和banana 3 個類別上的表現最優,YOLOv3 在damaged_pear 類別上的表現最優。這是由于YOLOv3 和YOLOv3-spp 兩個網絡模型使用了更大的特征提取模塊,而YOLOv5s是一個輕量化網絡模型。

Table 1 Training results comparison of different models表1 不同模型實驗結果比較(%)
表2 給出了相同計算環境下不同模型的訓練時間、推理時間和大小,可以看出YOLOv5s 模型的訓練時間、推理時間和網絡參數大小均明顯優于其他模型。綜上所述,YOLOv5s 模型的平均檢測精度和檢測速度均有較大優勢,滿足實時檢測需求。
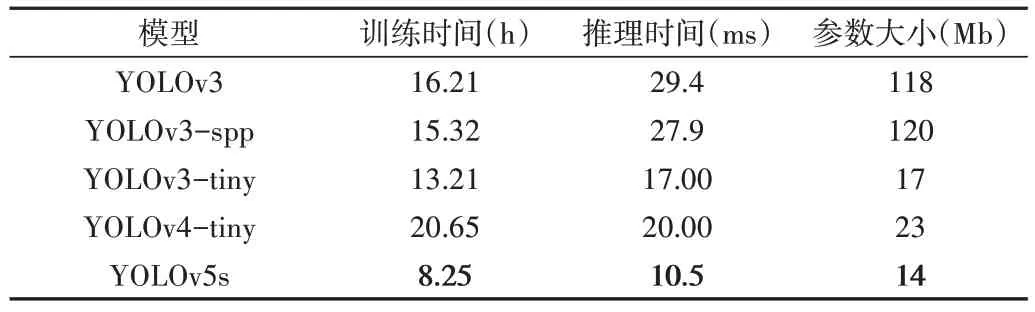
Table 2 Comparison of training time,inference time,and size of each model表2 各模型訓練時間、推理時間和大小比較
5.3 測試結果
分別使用訓練好的YOLOv5s 和YOLOv3、YOLOv3-spp、YOLOv3-tiny、YOLOv4-tiny 網絡模型對非訓練水果圖像進行測試,輸出結果包括水果種類、好壞、邊界框及相應的置信度,部分測試結果如圖4 所示。可以看出,YOLOv5s模型對所有水果圖像的檢測置信度均高于0.9,平均檢測時間為10.5 ms。雖然YOLOv3 和YOLOv3-spp 測試結果的置信度大多比YOLOv5 高,但其推理時間分別為29.4 ms 和27.9 ms,是YOLOv5s檢測時間的2.5倍以上,難以滿足實時檢測需求。YOLOv3-tiny 和YOLOv4-tiny 是輕量化后的網絡模型,由于其定位精度較差以及容易出現漏檢、誤檢情況,檢測置信度較低,其中YOLOv3-tiny 對banana 和damaged_banana 檢測的置信度均低于0.5。
6 結語
本文針對傳統深度學習技術對水果種類與品質檢測精確度和速度有待提高的問題,提出基于輕量級模型YOLOv5s 的目標檢測算法,同時自行構建了4 種不同類型水果的數據集。實驗結果表明,YOLOv5s 在檢測性能、訓練時間、推理時間和網絡參數大小等方面均優于傳統檢測方法,可以對不同品種的水果進行準確識別與定位,且具有占用內存小、推理時間短的特點,有望將其部署到智能終端,從而實現水果的實時在線檢測。未來將繼續完善不同類型水果的檢測數據集,并優化網絡結構以進一步提高水果分類準確率及品質檢測精度。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
