RISC-V基礎數學庫性能優化
2023-09-18 02:04:18郭紹忠宋廣輝郝江偉許瑾晨
計算機工程與科學 2023年9期
李 飛,郭紹忠,周 蓓,宋廣輝,郝江偉,許瑾晨
(信息工程大學網絡空間安全學院,河南 鄭州 450001)
1 引言
縱觀計算機發展史,從第1代電子管計算機(1946年~1957年)到第4代大規模、超大規模集成電路計算機(1970年至今),科學計算始終是各代計算機必備的重要功能。高性能基礎數學庫作為科學計算最基礎的軟件庫之一[1],應用廣泛,小到數字游戲、辦公計算、教學分析等,大到海洋遙感、地質勘探、衛星軌道等精密計算科研領域。目前常見的基礎數學庫有GNU的glibc庫[2]、Intel 的 MKL(Math Kernel Library)函數庫[3]和AMD 的 libm 庫[4]等。隨著信息科學技術的發展,計算機體系架構逐漸變得多樣化,不同的體系架構,底層的硬件設計、語言實現、存儲機制也各有差異。為了保證基礎數學庫表現出較高的性能,開發人員都會研發一套契合自身架構的高性能基礎數學庫并基于處理器特性進行底層優化。
近年來,RISC-V 指令集架構ISA(Instruction Set Architecture)作為一種新興的開源精簡 ISA[5],因其可以免費使用和自由設計等特點,受到國內外廠商和研究人員的青睞。相較于x86架構和ARM架構,RISC-V提供了精簡的基礎指令集和擴展指令集,開發者可以基于這2種指令集以及自定義指令集擴展進行精細化的系統研發[6]。由于RISC-V的低功耗性、模塊化設計和可擴展性等優勢,開發人員在此領域取得了許多突破性科研成果,如瑞薩電子集團推出的基于64位RISC-V CPU內核的RZ/Five通用微處理器MPU(MicroProcessor Unit)[7]、中國科學院計算技術研究所的高性能 RISC-V 處理器核“香山”[8]和中國科學院上海微系統與信息技術研究所研發的宇航級高可靠嵌入式RISC-V衛星芯片等[9]。RISC-V作為計算機體系架構走向開放的必然產物,其軟件系統和硬件系統應該都很完善,但目前開發者大都圍繞RISC-V進行硬件開發,導致其軟件生態很薄弱。2022年,首個RISC-V基礎數學庫開源發布(https://gitee.com/mathlib/RV-Libm),這一定程度上促進了RISC-V的軟件生態發展。該數學庫函數皆由RISC-V匯編語言實現,包含17個三角函數、6個雙曲函數、4個指數函數等67個數學函數和2個內部調用函數。
通過對RISC-V基礎數學庫函數進行測試與分析發現,雖然其可以實現正確計算,但是函數中存在大量的訪存指令及冗余指令。部分訪存指令存在如下特征:在一段匯編程序內,如果有將寄存器的值寫入棧空間的操作,在該段程序的結束位置,就會有將該寄存器的值從棧中取出的操作,即中間匯編程序段使用了該寄存器,而使用結束之后又還原了該寄存器值。將需要入棧和出棧的寄存器稱為輔助寄存器。上述訪存指令是為了保證RISC-V函數上下文寄存器依賴關系的正確性,在使用輔助寄存器之前和之后將其原來的值入棧和出棧,可以保存和恢復寄存器現場。通過這種方式實現寄存器的再利用,導致寄存器的利用率不高。而且,由于對內存進行讀寫比對寄存器進行讀寫速度上要慢很多,因此入棧和出棧指令的使用無疑會降低函數的性能。此外,RISC-V基礎數學庫函數中存在一定的冗余指令,尤其是在RISC-V函數的鄰近空間內連續多次出現相同指令操作時,從局部的角度分析這些具有一定關聯性的指令并進行重構,一定程度上可以提升RISC-V的函數性能。
針對上述問題,本文提出了面向RISC-V基礎數學庫的性能優化方法。為了提高優化效率,利用自動插樁技術預先檢測出測試集對應的不同路徑,以路徑為單位進行有針對性的線性優化。基于檢測到的路徑,首先根據隊列式寄存器分配策略將函數中對內存的讀寫優化為對寄存器的讀寫;然后對局部組合功能指令進行重構,盡可能多地刪除冗余指令。實驗結果表明,該方法可以對RISC-V數學函數進行有效的性能優化。
2 相關工作
傳統的寄存器分配算法有Chaitin等[10]提出的圖著色算法GCRA(Graph Coloring Register Allocation)和Poletto等[11]提出的線性掃描算法LSRA(Linear Scanning Register Allocation)。圖著色寄存器分配算法是將寄存器分配問題抽象成圖著色問題,通過構造干涉圖對共同邊的不同節點以不同顏色完成著色,直觀地分析2個變量在節點處是否沖突,相互沖突的變量不能同時占用同一寄存器,以此對干涉圖進行構造和化簡,完成寄存器的分配。但是,當此算法運用到大基本塊或者全局范圍時,構成的干涉圖可能過于復雜,增加了寄存器分配的復雜度。線性掃描算法是寄存器分配較快的算法,通過對待分配寄存器的一次性掃描以及將各個變量生命周期的結束時間進行排序,完成寄存器的分配。該算法雖然具有很快的效率,但是僅對待分配的寄存器以及生命周期結束的寄存器進行回收再分配,存在生命周期未結束且下文重新寫入的寄存器和不同路徑中無依賴關系的寄存器利用率低的問題。
2012年,郭正紅等[12]提出層次結構寄存器分配策略,該策略通過判斷是否有可分配的通用寄存器,SIMD寄存器高位和保存寄存器是否空閑來完成寄存器分配。此方法引入SIMD寄存器高位來緩解標量浮點寄存器分配的壓力,但是SIMD寄存器高位和保存寄存器不直接參與分配過程,而是在使用之前和之后進行額外的處理。比如當使用SIMD寄存器高位完成64位浮點計算之后,就需要進行一次數據交換,將其移動到標量浮點寄存器,相比于直接分配通用寄存器,這些交換增加了額外的開銷。而保存寄存器的使用,為了不改變其原本的值,需要將此寄存器的值存進棧空間,當分配使用之后,還需要將原來的值從棧中取出,以恢復寄存器依賴,這些訪存指令的使用會影響函數的性能。
2013年,姜軍等[13]提出了一種局部寄存器分配的優化策略,該策略是在進行全局寄存器分配之前,預估局部寄存器的需求,并根據每條指令的胖點值去分析該位置需要的寄存器個數,在不提高局部寄存器分配復雜度的同時,保證了局部空間內盡可能多地分配到寄存器。此方法需要提前預估需要的局部寄存器個數,并在全局開始時進行預留。但是,在進行寄存器分配時,如果分配的無依賴寄存器個數處于緊張狀態,那么在RISC-V函數優化中很難實現在全局范圍內寄存器的預留。此外,該方法需要對每一條指令進行胖點值賦值和判斷,這會產生不必要的訪存指令,增加了代碼執行的開銷。并且,該方法主要適用于國產CPU SW1600專用編譯器,因此對于RISC-V數學函數的匯編程序優化具有一定的局限性。
3 性能優化方法
RISC-V基礎數學庫包含67個數學函數和2個內部調用函數,盡管在實現時已最大限度地精簡RISC-V函數代碼,但是仍存在寄存器利用率不高、訪存指令過多及存在冗余指令等問題。由于各函數的特性及指令構成不同,具體的優化部分也不盡相同。但總體來說,性能優化方法可以分為3個步驟:函數路徑的自動檢測、隊列式寄存器分配及冗余指令重構,如圖1所示。
3.1 函數路徑的自動檢測
RISC-V數學函數的匯編代碼量大,分支判斷復雜,直接進行優化具有一定的難度。RISC-V函數的分支雖多,但是根據函數的“歸約-逼近-重建”實現算法及數學性質,可以將不同輸入歸約到同一區間內。例如,exp(a+b)=exp(a)+exp(b)和cos(a+2π)=cos(a),可以將輸入值歸約到臨近零點的區間內,結合查表完成近似計算。當輸入為函數的異常值時,例如無窮數、弱規范數等,RISC-V數學函數無法進行計算,則會進入異常處理機制,進而引發異常中斷。將不同輸入進行歸約之后,定義域內不同區間的輸入所經過的路徑大概率是一致的。根據浮點數分布規律,生成可以覆蓋函數定義域內不同區間的測試集。基于該測試集檢測其所經過的路徑、可得到關鍵路徑、次要路徑和其他路徑。由局部到整體地依次對檢測到的路徑進行優化,可以使優化工作更加準確高效。以路徑為單位進行線性優化的優勢是一條路徑內匯編指令的改變不會影響其他路徑的正確計算,而且有助于定位優化后引起精度變化的指令位置。關鍵路徑自動檢測方法通過對函數各分支進行編碼,并將編碼加載進浮點寄存器設計成路徑探針,自動插樁到函數各分支的首行,不同的測試樣本經過路徑探針時,會基于上一個路徑探針中浮點寄存器存儲的編碼計算兩者的和,最后對路徑探針和進行解碼,可得各測試樣本所經過的路徑,其整體流程如圖2所示。
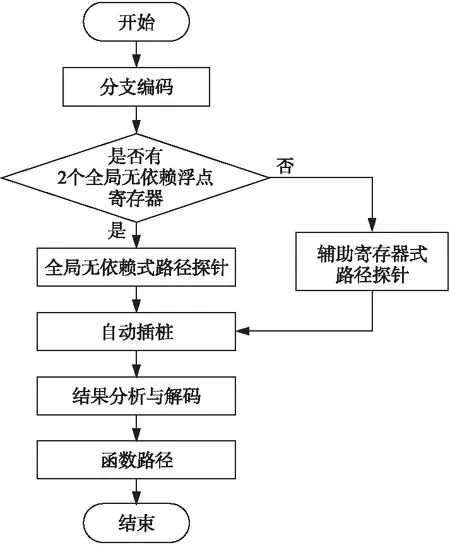
Figure 2 Automatically detection process of function path
3.1.1 分支編碼與路徑探針設計
所謂分支編碼,就是對RISC-V函數的n個分支以十進制序號從1至n進行順序編碼,并將首位為1末尾為n-1個0的二進制字符串與十進制序號進行配對,以這種方式組成二進制字符串,解碼得到的結果具有唯一性。由于RISC-V寄存器通常支持12位的立即數讀寫,所以將二進制字符串轉化為十六進制,以支持更大范圍的序號寫進浮點寄存器,如表1所示。
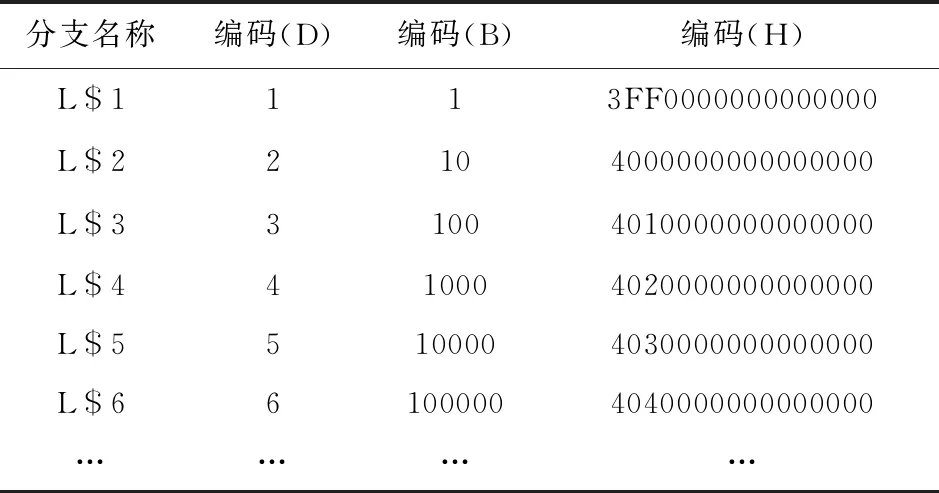
Table 1 Branching code table
路徑探針的作用是以編碼累加的方式記錄測試樣本所跳轉的分支。從起始分支到返回分支,中間涉及的分支順序構成了測試樣本在函數中經過的路徑。為了準確記錄測試樣本跳轉的分支順序,需要將路徑探針插入到每一個分支首行。因為路徑探針插入后測試樣本的路徑易發生改變,所以必須選擇不影響函數原來寄存器依賴關系的寄存器,并結合表1中十六進制編碼對路徑探針進行設計,分為以下2種情況:
(1)當函數有2個以上未使用過的浮點寄存器時,此時這2個浮點寄存器全局無依賴,依此構造全局無依賴式路徑探針GDPP(Global Dependency- free Path Probe)。假設函數中含有2個全局無依賴寄存器ft1和ft2,則GDPP-x的實現如圖3所示。

Figure 3 Global dependency-free path probe
指令說明:li為加載立即數指令;fmv.d.x為整數向雙精度浮點傳送指令;fadd.d為雙精度浮點加指令。GDPP-1插入的位置為函數的第1個分支,GDPP-2對應第2個分支。若測試樣本經過GDPP-1和GDPP-2,則GDPP-2中的第11行目的寄存器ft1的值為2個探針的編碼和。
(2)若函數內沒有2個以上全局無依賴寄存器,則需要借用其他寄存器設計輔助寄存器式路徑探針ARPP(Auxiliary Register Path Probe)。為了不改變探針上下文寄存器的依賴關系,需要在使用輔助寄存器之前和之后將其值入棧和出棧,以保存和恢復寄存器現場。經探針將編碼計算之后,將計算的編碼結果入棧,以便下一個探針從該棧中取出繼續計算,ARPP-x的實現如圖4所示。

Figure 4 Auxiliary register path probe
指令說明:fld為雙精度浮點加載指令,fsd為雙精度浮點保存指令。圖4中,ARPP-2的第10、11行是在使用輔助寄存器fa1和fa2之前將其值先存入棧中保存現場;第12行是將上一個探針的結果從棧中取出,讓當前探針使用;第16行是將當前探針計算得到的結果入棧,以便下一個探針使用;第17、18行為恢復輔助寄存器fa1和fa2的寄存器現場。
此外,由于部分函數中存在循環分支,且循環跳點一般不會在分支的首行,當測試樣本經過循環分支時,對于同一探針結果就有多種不同路徑的可能。如圖 5所示,將數學函數內出現逆向跳轉的情況定義為循環,即在當前分支內發生了向前面分支跳轉的情況。假設L$2為循環分支,如果最終路徑探針的值為110,則經過的分支有2種情況:一種是L$0→L$1→L$2→L$3;另外一種是L$0→L$1→L$2→L$0→L$1→L$2。
對于上述情況,顯然在循環分支內僅在首行插入路徑探針無法正確檢測路徑。因此,需要在循環區域內的分支中插入循環探針。循環探針可以是全局無依賴式路徑探針,也可以是輔助寄存器式路徑探針。由于循環探針的作用是為了記錄在跳點處的循環次數,因此規定循環探針不能重復使用。所謂的循環區域內分支,即如圖5中的L$0、L$1和L$2。最終循環次數等于循環探針的值減1,之所以減1是因為程序順序執行時循環探針的值即為1。例如,如果L$1和L$2分支的循環探針值分別為2,則說明循環執行了1次;如果L$1分支的循環探針值為2,而L$2分支的循環探針為1,則說明循環在L$1分支內結束,以此得到循環次數,進一步得到是循環路徑還是順序執行路徑。
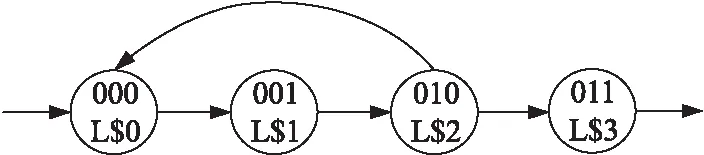
Figure 5 Loop branch jump
3.1.2 自動插樁與解碼
RISC-V數學函數的分支跳轉復雜,無法直接判斷輸入所經過的路徑,且測試集規模龐大,如果通過查看控制跳轉寄存器的值去分析所有測試樣本經過的路徑,人工方式幾乎難以完成。為了準確快速地得到測試集所涉及的RISC-V函數中的所有路徑,本文實現了一個自動檢測方法。首先,將3.1.1節設計的路徑探針自動插樁到各分支的首行,在返回分支中將其對應路徑探針的累加和存入RISC-V浮點輸出寄存器fa0中。然后,通過調用待優化函數對測試樣本進行自動測試,并將浮點寄存器fa0的結果輸出到文件,此時文件中的結果為表1中分支對應的十六進制編碼和。最后,對結果進行解碼,即可得測試樣本所經過的路徑,其中經過的測試樣本數最多的路徑為關鍵路徑。
路徑探針的自動插樁實現過程為:獲取RISC-V數學函數匯編程序每行的第1個連續字符串,若識別到的字符串非RISC-V指令集架構的匯編助記符,說明該字符為分支名稱,則在該字符下插入路徑探針。代碼實現如算法1所示。
算法1路徑探針自動插入
輸入:每行第1個連續字符串。
輸出:插樁后RISC-V數學函數程序。
1.for(i=0;i≤line;i++) {
2.get_str(S);
3.if(get_str(S)==‘’‖get_str(S)==‘ ’ ) {
4. continue;}
5.else{
6.while(strcmp(get_str(S),RV_mn)!=0) {
7.mv_down(i+P_l(GDPP-xor ARPP-x));
8.inster(GDPP-xor ARPP-x,i);
9. }
10. }
11.}
算法1中,第6行判斷非空字符串是否為RISC-V助記符,第7行表示將函數匯編程序從i行開始下移一個探針大小行,第8行將GDPP-x或者ARPP-x插入到匯編程序的第i行。
根據3.1.1節表1中各分支對應的二進制編碼方式,可以發現不同分支的二進制和具有唯一性。通過將結果文件中路徑探針的十六進制編碼和轉化為二進制,再將二進制中的1進行順序轉置,則轉置后1的位置序號即為分支的十進制編碼,由此可得測試樣本所經過的路徑。
3.2 隊列式寄存器分配策略
根據RISC-V基礎數學庫函數的實現特性,函數中有較多以指令組合的方式完成計算功能的程序段。為了使組合方法具有通用性,函數源碼中利用了輔助寄存器以固定格式進行組合,因此輔助寄存器會被寫入新的變量值,這就導致輔助寄存器原來的值被覆蓋,進而造成下文寄存器的依賴錯誤。因此,在函數源碼中使用輔助寄存器之前需要將原來的值存入棧空間,待組合功能完成之后,再從棧中取出,以這樣的方式去保存和恢復輔助寄存器對下文的依賴。如圖6所示,以Code#1中RISC-V的lg函數中部分程序段為例,對該程序段分析可知,實際完成的功能是復制ft0浮點寄存器的〈63:52〉位的值和fa0浮點寄存器〈51:0〉位的值,組合成一個新的雙精度浮點數存入目的寄存器fs1中。然而,RISC-V中沒有直接實現此功能的匯編指令,因此只能以Code#1中組合的方式實現。根據RISC-V指令集特性及指令組合方法,需要借助整數寄存器s8、s9、s10、s11完成Code#1中的功能。Code#1中復制ft0的〈63:52〉位是通過將ft0寄存器的值移動到整數寄存器s8(第5行),然后將由〈63:52〉位全為1和〈51:0〉位全為0格式的十六進制數加載進整數寄存器s9(第6行),s8和s9經過邏輯與操作形成新的值存入s8(第7行)。fa0寄存器〈51:0〉位的復制以同樣的方式進行操作并存入s9整數寄存器(第8~10行)。最后s8和s9進行邏輯或操作得到最終值,并將其存入浮點寄存器fs1(第11、12行)。

Figure 6 Combination implementation of copy instruction
從圖6 Code#1的第8~11行發現,整數寄存器s10、s11、s9、s8的值進行了額外的更新,這是為了不改變下文寄存器對這些寄存器的依賴,在使用這些寄存器之前和之后,需要保存和恢復寄存器現場,即第1~4行和第13、14行。這些訪存指令無疑會影響函數的性能,如果使用不影響下文依賴的寄存器代替s8~s11寄存器,則就不需要入棧和出棧,函數性能也會有一定的提升。
隊列式寄存器分配策略就是在RISC-V函數路徑中,根據待優化位置和寄存器的依賴復雜度構成3種不同優先級的寄存器隊列。3種寄存器隊列都是由可以代替輔助寄存器而不改變原依賴關系的寄存器構成,因此隊列式寄存器的分配不需要入棧和出棧,從而減少訪存指令數,寄存器分配優先級依次為第1隊列、第2隊列和第3隊列。
第1隊列為全局無依賴寄存器,此類寄存器是RISC-V數學函數從未使用的寄存器,也可以是其他路徑與優化路徑無交集分支內的寄存器。對這類寄存器進行再分配不會影響任何路徑的寄存器依賴,并且適用于程序中任一位置優化,但是這類寄存器一般數量較少。當第1隊列寄存器數量不能滿足需求時,則需要借助第2隊列寄存器完成分配。第2隊列寄存器為下文先被更新的寄存器,當在優化位置的下文有寄存器A作為目的寄存器出現時,將其分配至優化位置代替輔助寄存器,不會對依賴寄存器A的下文程序產生影響。此隊列更適合路徑的前部分程序優化,因為對前部分進行優化時,后部分寄存器可以作為目的寄存器的數量更多。第3隊列寄存器為程序周期已結束的寄存器,如果寄存器A在程序中是最后一次出現,則代表該寄存器的程序周期已結束。當對程序周期已結束寄存器的下文程序進行優化時,則可以對寄存器A進行再分配,將其用作優化所需的寄存器,同樣不會影響函數的正確計算。第3隊列寄存器更適合路徑的后部分程序優化,因為此時前部分程序周期已結束的寄存器數量更多。第2隊列和第3隊列根據不同優化位置以不同的規則對寄存器進行判斷,所以這2個隊列的寄存器是動態變化的。以圖6 Code#1為例,根據隊列式寄存器分配策略找到4個寄存器代替輔助寄存器s8~s11,優化流程如圖7所示。

Figure 7 Optimization process of queue register allocation strategy
圖7中子圖1為lg函數中的代碼段,為了減少訪存指令數,首先在此位置全局搜索符合第1隊列全局無依賴的寄存器,僅有寄存器a2。以a2寄存器代替子圖1中的輔助寄存器s8,得到子圖2。經過子圖6發現,子圖2中仍有輔助寄存器存在,此時第1隊列已經無寄存器可分配,根據隊列式寄存器分配策略需要搜索符合第2隊列的寄存器。由子圖7發現,第137行和第138行有寄存器a3和a4可以作為目的寄存器,則可以將子圖2中的輔助寄存器s9和s10替換為a3和a4,得到子圖3,且不影響第138行之后其他寄存器對a3和a4的依賴。經過子圖8判斷,子圖3中仍有輔助寄存器s11未被替換,若繼續向下搜索符合第2隊列的寄存器,會增加搜索復雜度,更好的方法是向上搜索符合第3隊列的寄存器。根據子圖9顯示,該代碼段的上文第112行有寄存器a7的程序周期已結束,則以a7代替s11得到子圖4。通過再判斷發現,該程序段已沒有輔助寄存器,即可以刪除Code#1中第1~4行和第13~16行的訪存指令,完成寄存器分配。

Figure 8 Analysis of program segment function

Figure 9 Analysis of redundant instruction
3.3 冗余指令重構
RISC-V基礎數學庫中函數數量多、代碼量大、算法實現復雜,如果逐個分析所有函數的所有單指令操作,不僅需要很大的時間成本和人工成本,并且還容易忽略指令之間的關聯性。根據RISC-V組合指令的特性,一段組合指令完成的功能是確定的。如果從局部的角度分析程序段實現的功能,就可以將單指令正確性擴大為程序段正確性,即只要保證在一定的局部空間內對程序段進行重構,不改變下文程序的依賴,則RISC-V數學函數的功能依然保持正確。以RISC-V讀取浮點控制寄存器的值并存入雙精度浮點寄存器和雙精度浮點先取負再乘加功能為例進行詳細介紹,如圖8所示。第1~4行完成的功能是讀取浮點控制寄存器的值并存入浮點寄存器ft4中。由于RISC-V中沒有直接實現該功能的指令,因此先通過frcsr指令將浮點控制寄存器的值讀入整數寄存器s8,再使用fmv.d.x指令將整數寄存器的值移動到浮點寄存器,其中整數寄存器s8為輔助寄存器。第5~7行實現的是雙精度浮點先取負再乘加,然而RISC-V中僅有雙精度浮點乘加指令fmadd.d,因此在計算乘加之前,需要先利用fneg.d指令將相乘寄存器中的一個寄存器值取負,待乘加計算結束之后,再還原該寄存器值。
在RISC-V函數中需要重復完成此類功能時,在函數程序中仍然會以相同的方式組合為RISC-V程序段,因此導致產生冗余指令。圖9為RISC-V函數fmod中重復實現上述功能的相鄰程序段,根據圖8該類功能的組合實現,圖9第773~776行和第798~800行分別對應圖8中第1~4行和第5~7行實現的功能。
圖9中,第775和779行fmv.d.x指令是將整數寄存器s8的值移動至浮點寄存器ft4和ft5,在這2個指令之間的ld、sd、frcsr指令的功能是將原來s8的值出棧、入棧、讀浮點控制寄存器的值放入s8。由于這2行之間浮點控制寄存器的值沒有發生改變,因此第774行寄存器s8的值可以運用到第779行。從局部角度分析,第778行再次讀取浮點控制寄存器的值并將其寫入寄存器s8為多余操作,第776和777行出棧結束后再入棧也毫無意義,因此第776,777,778行為冗余指令,可以優化為圖10中子圖1的第773~777行。同樣的原理分析#RISC-V_fmod中的第800和801行,連續地使用fneg.d指令將浮點寄存器fs10的值還原之后再取負,那么其依然為第798行fs10的值,因此這2行為冗余指令,經優化可得到圖10中子圖1的第798~801行。

Figure 10 Redundant instruction optimization
根據3.2節隊列式寄存器分配策略,RISC-V的fmod函數程序的此位置有符合第3隊列的整數寄存器a5可以進行再分配,代替圖10中子圖1整數寄存器s8。此外,也有符合第1隊列的浮點寄存器ft3,可以將子圖1中第798行浮點寄存器fs10的值取負之后存入ft3浮點寄存器,從而取消第801行浮點寄存器fs10的值還原操作,最終將圖9代碼段優化為圖10子圖2代碼段。
4 實驗及結果分析
為了驗證本文方法的有效性,使用遵循RVV-0.10規范的指令功能模擬器Spike[14]及RISC-V的gcc工具鏈[15]進行各項測試。測試項分別為:精度測試、函數路徑自動檢測方法測試、隊列式寄存器分配和冗余指令優化方法的效果對比測試及所有RISC-V函數優化前后的性能變化測試。
4.1 精度測試
為了測試優化后的函數精度是否發生變化,在優化之前和之后分別對RISC-V基礎數學庫函數進行了精度測試。測試集由隨機生成的函數定義域內的5×1010個雙精度浮點數據構成。精度測試是通過與高精度MPFR[16]數學庫函數計算相對誤差(relativeULP)實現,計算過程如式(1)所示:
relativeULP=
(1)
在相同測試樣本下,Expression(x)RISC-V代表RISC-V數學函數計算得到的結果,Expression(x)mpfr代表此函數在MPFR上計算得到的結果,ulp(x)mpfr代表MPFR函數計算得到結果的ULP(Unit in the Last Place)值。經測試,67個數學函數中有58個函數相對誤差處于(0,1] ULP,9個函數處于[1,2] ULP,其中最大相對誤差1.90 ULP是由反誤差函數erfc產生的。測試結果表明,優化之后RISC-V基礎數學庫函數精度與優化之前的保持一致。
4.2 函數路徑自動檢測方法測試
RISC-V基礎數學庫函數類型多樣,本文基于此方法對cotd、fma、cos、erf、exp、pow、lgamma、log2、erfc、lround共10個典型函數進行測試,檢測其不同路徑及樣本通過率。由于不同函數檢測到的路徑數量不同,所以本文測試以各函數的關鍵路徑為例進行統計與分析。
為了保證測試的有效性,本文按照 IEEE-754 浮點數分布的全浮點域指數分布測試集的生成方法[17],在函數定義域內生成 5×106個雙精度浮點測試樣本,最大限度地保證覆蓋函數的所有路徑,以確保基于關鍵路徑優化時不影響其他路徑的正確計算,結果如表2所示。
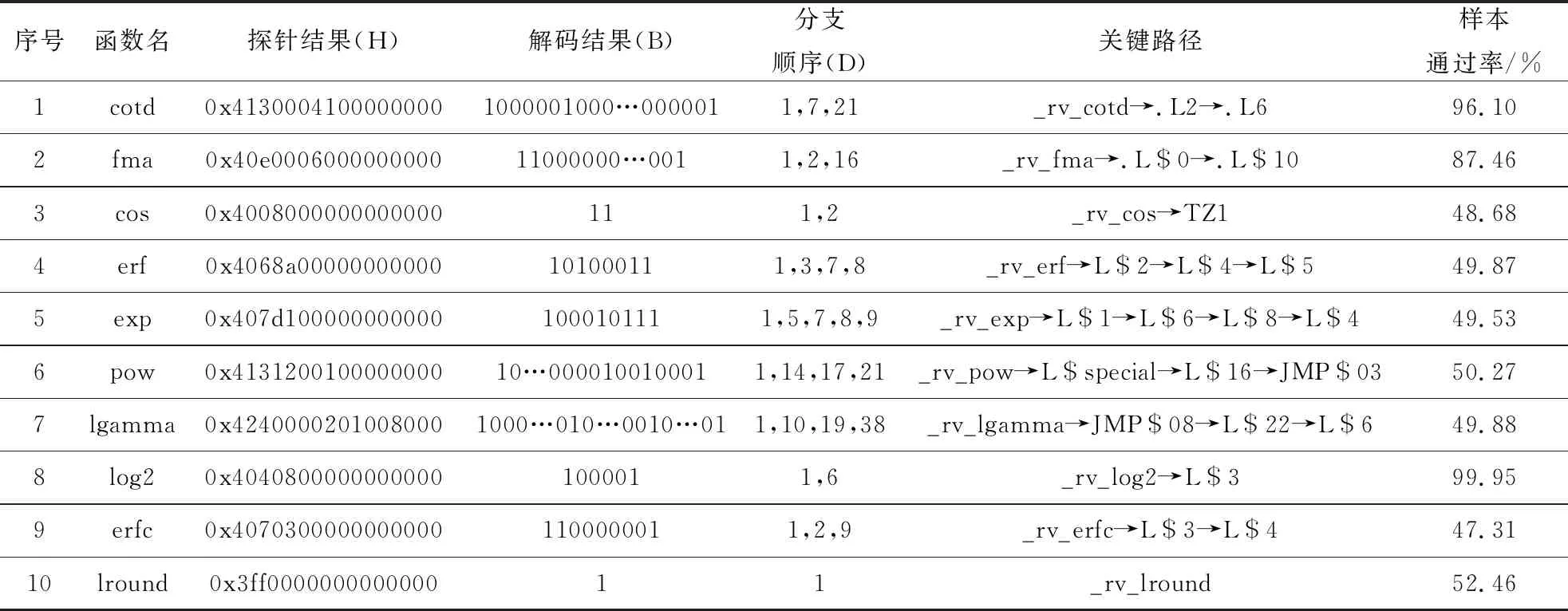
Table 2 Results of critical paths automatic detection
經測試,此方法可以快速得到所有測試樣本的準確路徑。個別函數的測試樣本絕大部分會經過同一路徑完成計算。例如,cotd函數的_rv_cotd→ .L2→.L6路徑樣本通過率為96.10%;lb函數的_rv_lb→L$3路徑樣本通過率為99.95%。而大部分函數的關鍵路徑樣本通過率大約占總測試集的一半。例如,erf、exp、lgamma和lround函數在關鍵路徑的樣本通過率分別為49.87%,49.53%,49.88%和52.46%。由于函數程序由各分支代碼段組成,不同分支之間的跳轉構成了不同路徑,因此,樣本通過率占比較高的路徑復雜度對函數性能表現會起到主要作用,依次通過檢測到的路徑對函數進行性能優化,不僅降低了程序分析的難度而且提高了優化效率。
4.3 2種優化方法的性能測試
本文3.2節和3.3節分別對影響函數性能的不同部分以不同的方法進行了優化。為分析兩者的優化效果,以不同類型的典型函數sin、acos、cbrt、scalb、fmod、pow、lgamma、lb、erfc、ldexp為例,分別對以隊列式寄存器分配優化后的函數以及進行冗余指令優化后的函數進行性能測試與分析。
性能測試通過獲取隨機生成函數定義域內的1 000個測試樣本的平均時鐘周期實現。為了確保得到的平均時鐘周期的準確性,首先對函數進行預熱,以此減低外部環境對測試產生的影響。預熱代碼如下:
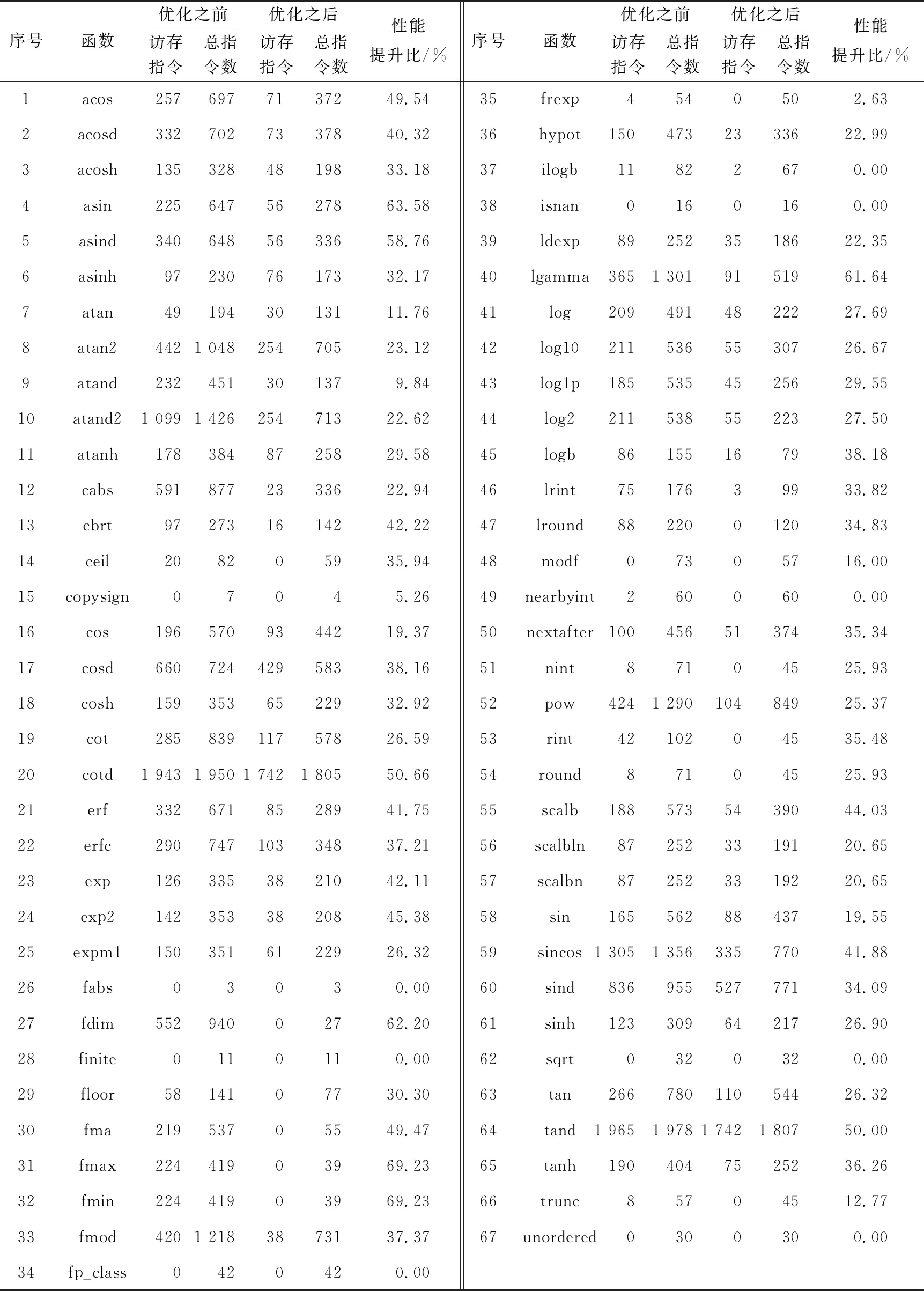
for(inti=0;i arry[i]=(float)rand() / ((float)RAND_MAX+1)*((1)-(0))+(0);} for(inti=0;i<10;i++){//sin函數預熱 _rv_sin(arry[i]);} 各函數的平均時鐘周期通過式(2)計算: (2) 其中,cycleij表示樣本xj第i次測試得到的時鐘周期數,m表示每個測試樣本的測試次數,n表示測試樣本的個數。在本文中m取10,n取1 000,性能測試結果如圖11所示。 Figure 11 Performance changes of two optimization methods 關于2種優化方法需要說明的是,隊列式寄存器分配方法和冗余指令優化是依次遞進對函數進行優化,即在使用隊列式寄存器分配方法對函數進行優化之后,再對函數進行冗余指令重構。從圖11的測試結果可知,隊列式寄存器分配方法和冗余指令優化對函數的性能有不同程度的提升。其中,隊列式寄存器分配方法普遍對函數性能提升顯著,如acosh、cbrt、lgamma函數性能由223,225,537個時鐘周期提升至176,151,295個時鐘周期,提升比分別為21.08%,32.89%,45.07%。這是由于在此類函數中存在較多的入棧和出棧操作,因此經該方法優化后得到了較高的性能提升。冗余指令優化根據函數自身指令冗余程度的不同有不同的性能提升,即指令冗余程度較高的函數經該方法優化后性能提升更明顯。例如,lgamma函數性能由295個時鐘周期提升至206個時鐘周期,提升比為30.17%。而冗余指令程度較低的函數性能提升不明顯,如lb函數僅提升1個時鐘周期。 RISC-V基礎數學庫共有69個函數,其中有2個為內部調用函數。為分析RISC-V基礎數學庫的整體性能變化,本節使用4.3節測試方法對優化前后的67個RISC-V函數進行性能測試(addtc 函數和cvttqc 函數屬于內部調用函數,不進行性能測試)。由于Spike是功能模擬器,測試的時鐘周期數和實際時鐘周期數會有微小差異,但是優化前后的函數性能測試都是基于Spike進行的,即在環境變量保持一致性的條件下,計算性能提升比具有更準確的參考價值,并使用式(3)所示的方式計算整體性能平均提升比: (3) 其中,AOPIR為整體性能平均提升比,f為函數的總個數,Si為第i個函數優化前的時鐘周期,Oi為第i個函數優化后的時鐘周期。性能測試結果如圖12所示,邏輯實現較復雜的函數性能提升更明顯,如tand、sincos、scalb、cotd、acos等函數,性能分別由232,437,134,229和109個時鐘周期優化為116,254,75,113和55個時鐘周期,性能提升比分別為50.00%,41.88%,44.03%,50.66%和49.54%;實現較簡單的函數性能提升較少,如atan、trunc、frexp、modf等函數,性能分別由51,47,38和50個時鐘周期優化為45,41,37和42個時鐘周期,性能提升分別為11.76%,12.77%,2.63%和16.00%;而對于邏輯簡單的數值處理函數,其本身沒有優化空間,此類函數性能沒有提升,如unordered、nearbyint、fp_class、fabs等函數。 Figure 12 Performance of RISC-V basic math library before and after optimization 為進一步分析本文優化方法對函數的性能提升與指令的關系,分別對優化前后函數中的訪存指令數和總指令數進行統計,并給出各函數的性能提升比,其結果如表3所示。優化之后函數的訪存指令數以及總指令數相較優化前的都有不同程度的減少。根據表3各函數的性能提升比結果發現,性能提升比與訪存指令減少數總體呈正相關。然而部分函數相較于其他函數雖然訪存指令減少得更多,但是性能提升卻小于其他函數的。如cotd函數的訪存指令數由1 943優化為1 742,共優化掉201條訪存指令,性能提升比為50.66%;然而erf函數訪存指令數由332優化為85,共減少247條訪存指令,性能提升比為41.75%。在erf函數的訪存指令減少數多于cotd函數的情況下,其性能提升比卻小于cotd函數的,這是由于erf函數的訪存指令減少數并沒有集中在關鍵路徑中,而隨機生成的測試集主要通過關鍵路徑,因此獲取的時鐘周期數會大于訪存指令集中在關鍵路徑中的函數的時鐘周期數,即性能提升比會小于此類函數的。 Table 3 Number of instructions before and after RISC-V basic math library optimization 本文根據RISC-V基礎數學庫函數的匯編程序實現特性,提出了性能優化方法。該方法主要分為函數路徑自動檢測、隊列式寄存器分配以及冗余指令重構。實驗結果表明,在精度保持不變的情況下,基于上述方法,67個RISC-V數學函數由平均144個時鐘周期優化為85個時鐘周期,性能平均提升了29.61%,驗證了性能優化方法的有效性。依據科學的測試方法對函數完成測試,并對結果做了較詳細的分析,得到的數據具有一定的參考價值。目前優化后的高性能RISC-V基礎數學庫源碼已開源發布在https://gitee.com/mathlib/RV-Libm。當前工作主要在功能模擬環境中進行,待RISC-V相關條件具備的時候,可以將其部署在硬件環境下。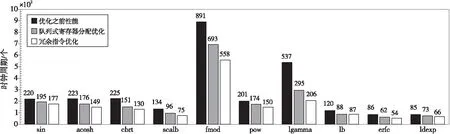
4.4 RISC-V基礎數學庫性能測試
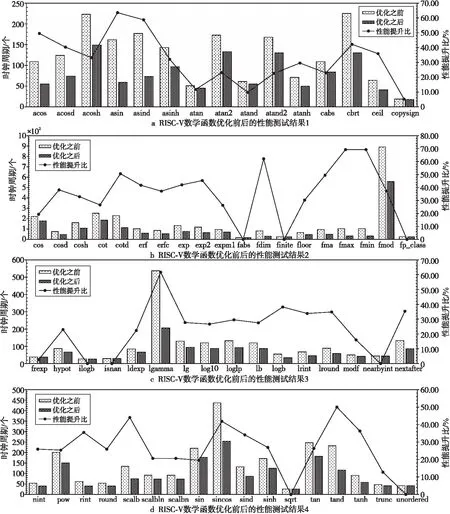
5 結束語
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
現代企業(2015年2期)2015-02-28 18:45:09
