基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法綜述
2023-09-18 02:04:24馬玉民錢育蓉周偉航公維軍帕力旦吐爾遜
計(jì)算機(jī)工程與科學(xué) 2023年9期
關(guān)鍵詞:特征
馬玉民,錢育蓉,周偉航,公維軍,帕力旦·吐爾遜
(1.新疆大學(xué)軟件學(xué)院,新疆 烏魯木齊830000;2.新疆維吾爾自治區(qū)信號(hào)檢測(cè)處理重點(diǎn)實(shí)驗(yàn)室,新疆 烏魯木齊 830046;3.新疆大學(xué)軟件工程重點(diǎn)實(shí)驗(yàn)室,新疆 烏魯木齊 830000;4.新疆師范大學(xué),新疆 烏魯木齊 830000)
1 引言
近年來,隨著人工智能[1]的熱潮以及計(jì)算機(jī)視覺領(lǐng)域的不斷進(jìn)步,目標(biāo)跟蹤相關(guān)研究也得到了充分的發(fā)展。截至目前,基于視覺的目標(biāo)跟蹤已廣泛應(yīng)用于視頻監(jiān)控、城市交通以及軍事等領(lǐng)域[2,3]。例如,視頻監(jiān)控通過使用電子輸入設(shè)備捕獲大量視頻數(shù)據(jù)并通過目標(biāo)跟蹤算法監(jiān)控目標(biāo)數(shù)據(jù),從而完成對(duì)目標(biāo)的跟蹤定位,提前預(yù)知目標(biāo)大體走向,避免危險(xiǎn)的發(fā)生。在城市交通領(lǐng)域,通過對(duì)車輛等運(yùn)動(dòng)目標(biāo)的實(shí)時(shí)跟蹤,再對(duì)獲取的數(shù)據(jù)進(jìn)行分析驗(yàn)證,從而判斷是否有異常行為,為監(jiān)管提供了更為有效的手段。在軍事領(lǐng)域,通過無人機(jī)等偵察手段,進(jìn)行航拍目標(biāo)跟蹤,獲取目標(biāo)運(yùn)動(dòng)狀態(tài),并根據(jù)該狀態(tài)做出相應(yīng)戰(zhàn)略措施,其中目標(biāo)跟蹤起到了至關(guān)重要的作用。
雖然目標(biāo)跟蹤算法已經(jīng)得到較為廣泛的應(yīng)用,但由于跟蹤場(chǎng)景種類繁多,環(huán)境復(fù)雜多變,導(dǎo)致目前仍沒有一個(gè)合適的算法可以應(yīng)對(duì)現(xiàn)有的所有情況,目標(biāo)跟蹤仍是一個(gè)具有挑戰(zhàn)的任務(wù)。如圖1所示,目標(biāo)跟蹤一般由5個(gè)部分組成,分別是生成運(yùn)動(dòng)模型、特征提取、觀測(cè)模型評(píng)分、模型更新以及預(yù)測(cè)集成[4,5]。

Figure 1 Main components of target tracking
在給定目標(biāo)輸入以及對(duì)應(yīng)邊界框的情況下,目標(biāo)跟蹤算法仍要克服包括光照變化、尺度變化、形變、運(yùn)動(dòng)模糊、快速運(yùn)動(dòng)、平面內(nèi)旋轉(zhuǎn)、平面外旋轉(zhuǎn)、出視野、背景干擾以及低像素等[6]挑戰(zhàn)。這些挑戰(zhàn)共同決定了目標(biāo)跟蹤是一項(xiàng)極為復(fù)雜的任務(wù),目標(biāo)跟蹤算法不僅要盡可能解決上述挑戰(zhàn)帶來的困難,也要同時(shí)兼顧準(zhǔn)確率和實(shí)時(shí)性。
2 傳統(tǒng)的目標(biāo)跟蹤算法
傳統(tǒng)的目標(biāo)跟蹤算法通常被分為生成式模型方法和判別式模型方法[7],其劃分準(zhǔn)則和依據(jù)為初始目標(biāo)模型采取的建模方式[8]。
2.1 生成式模型方法
生成式模型的初始目標(biāo)模型是在當(dāng)前幀對(duì)目標(biāo)區(qū)域建模,下一幀以相似度的度量為準(zhǔn)則,選擇與目標(biāo)模型最相近的區(qū)域作為預(yù)測(cè)位置,并更新為新的目標(biāo)模型。
Comaniciu等人[9]構(gòu)建目標(biāo)模型的均值漂移(Mean Shift) 向量,該向量始終指向樣本點(diǎn)最密集的區(qū)域并快速收斂,從而實(shí)現(xiàn)目標(biāo)跟蹤。MeanShift算法因計(jì)算簡單、實(shí)時(shí)性好,同時(shí)又能較好地應(yīng)對(duì)遮擋與形變等狀況而得到了廣泛的應(yīng)用和研究。后來Vojir等人[10]使用經(jīng)典顏色直方圖特征在原有的均值漂移算法上增加了尺度估計(jì),提出了ASMS(Adaptive Scale Mean Shift)算法。ASMS解決了由背景混亂導(dǎo)致的尺度擴(kuò)張和相似物體的尺度內(nèi)爆問題,進(jìn)一步提高了算法的適用度。
與均值漂移這一類內(nèi)核方法[11]不同,Nummiaro等人[12]基于貝葉斯估計(jì)理論,提出了粒子濾波算法,該算法對(duì)于非線性系統(tǒng)有著較好的建模能力,從而取得了較好的效果。Zhang等人[13]基于奇異值分解的新型卡爾曼粒子濾波器,使用卡爾曼濾波器來生成復(fù)雜的粒子預(yù)測(cè)分布,改善了原有的濾波效果。次年,他們又通過添加層次采樣,并使用粒子配置中提取的群體智能作指導(dǎo),克服原有的樣本貧化問題,提出了一種基于粒子群智能的粒子濾波算法[14]。
2.2 判別式模型方法
判別式模型方法將當(dāng)前幀分為目標(biāo)區(qū)域和背景區(qū)域2個(gè)部分,運(yùn)用機(jī)器學(xué)習(xí)的方法訓(xùn)練出一個(gè)最優(yōu)判別函數(shù),從而在后續(xù)幀中找到符合判別函數(shù)的最優(yōu)解區(qū)域作為目標(biāo)區(qū)域。
基于相關(guān)濾波思想的跟蹤算法是典型的判別式模型方法[15]。Bolme等人[16]通過高斯函數(shù)標(biāo)識(shí)樣本標(biāo)簽,將建模問題轉(zhuǎn)化為頻域求解,提出了MOSSE(Minimum Output Sum Square Error)算法,極大地提高了跟蹤算法的速度。Henriques等人[17]在相關(guān)濾波的基礎(chǔ)上對(duì)正樣本增加了循環(huán)移位,從而產(chǎn)生了一個(gè)新的樣本集合,利用循環(huán)矩陣的性質(zhì),降低模型復(fù)雜度,提出了CSK(Circulant Structure with Kernels)算法,并在后來使用方向梯度直方圖特征以及高斯核函數(shù)代替灰度特征,提出了KCF(Kernel Correlation Filter)[18]算法。在此基礎(chǔ)上,研究人員又融合了多種特征并兼顧尺度變化,提出了SAMF(Scale Adaptive Multiple Feature)[19]和KCFDP(Kernel Correlation Filter with Detection Proposals)[20]等算法繼續(xù)改進(jìn)KCF,并取得了一定成效。
基于深度學(xué)習(xí)[21]的目標(biāo)跟蹤算法是判別式模型方法的另一主流方法。Wang等人[22]最早將深度學(xué)習(xí)應(yīng)用于目標(biāo)跟蹤領(lǐng)域,但其算法的性能不如當(dāng)時(shí)其他算法的。Nam等人[23]提出了一種基于卷積神經(jīng)網(wǎng)絡(luò)[24]的多域?qū)W習(xí)算法MDNet(Multi-Domain Convolutional Neural Network),該算法將圖像分類任務(wù)中的預(yù)訓(xùn)練模型VGG-M(Visual Geometry Group-M)[25]作為網(wǎng)絡(luò)的初始化模型,利用不同的視頻序列進(jìn)行離線訓(xùn)練,在精度上取得了重大的突破。
將目標(biāo)跟蹤轉(zhuǎn)化為二分類問題可以更好地關(guān)注視頻中目標(biāo)和背景的區(qū)分,所以判別式模型方法普遍優(yōu)于生成式模型方法。但是,即使深度學(xué)習(xí)方法進(jìn)一步提高了判別式模型方法的精度,但其引入了大量的卷積計(jì)算,導(dǎo)致算法的跟蹤速度變慢,很難達(dá)到實(shí)時(shí)跟蹤的目的,這使得判別式模型方法很難兼顧精度與速度。
3 基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法
基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法將跟蹤問題轉(zhuǎn)化為相似度度量問題,并在發(fā)展過程中逐漸從簡單的相似度匹配問題延伸到分類與回歸的綜合問題。與傳統(tǒng)方法相比,孿生網(wǎng)絡(luò)特殊的網(wǎng)絡(luò)結(jié)構(gòu)提高了樣本的利用率,在有限樣本中提取出了更多特征,同時(shí)其結(jié)果在一定程度上保證了精度和速度的平衡,并提高了算法的魯棒性。
3.1 孿生網(wǎng)絡(luò)本質(zhì)和發(fā)展
孿生網(wǎng)絡(luò)結(jié)構(gòu)的根本在于孿生——即基于2個(gè)或多個(gè)人工神經(jīng)網(wǎng)絡(luò)建立的耦合框架。一般同時(shí)接收2幅圖像作為網(wǎng)絡(luò)的輸入,輸出一個(gè)相似度數(shù)值,如圖2所示。狹義的孿生網(wǎng)絡(luò)結(jié)構(gòu)是由2個(gè)結(jié)構(gòu)相同、權(quán)值共享的人工神經(jīng)網(wǎng)絡(luò)組成。廣義的孿生神經(jīng)網(wǎng)絡(luò)可由任意的2個(gè)人工神經(jīng)網(wǎng)絡(luò)拼接而成。本文主要介紹狹義的孿生網(wǎng)絡(luò)。

Figure 2 Structure of Siamese network in narrow sense
孿生網(wǎng)絡(luò)的原始過程是將輸入映射為一個(gè)或多個(gè)特征向量,使用2個(gè)向量之間的“距離”來表示輸入之間的差異,也就是相似度數(shù)值。這個(gè)數(shù)值在2個(gè)或多個(gè)輸入相似或?qū)儆谕活悇e時(shí)較小,輸入不相似或不屬于同一類別時(shí)較大。這里相同結(jié)構(gòu)僅代表有相同的參數(shù)和權(quán)重,可以在2個(gè)子網(wǎng)上同時(shí)進(jìn)行更新。
Bromley等人[26]在首次提出孿生網(wǎng)絡(luò)這個(gè)概念時(shí),將其用于簽名驗(yàn)證,并取得了相對(duì)不錯(cuò)的結(jié)果。
Zagoruyko等人[27]研究了如何從圖像數(shù)據(jù)中直接學(xué)習(xí)到一個(gè)普適性的相似度函數(shù)用于圖像匹配,結(jié)果表明孿生網(wǎng)絡(luò)在圖像匹配領(lǐng)域具有較大的優(yōu)勢(shì)。
Melekhov等人[28]提出了一種基于孿生網(wǎng)絡(luò)的全圖像相似度預(yù)測(cè)方法,結(jié)果表明孿生網(wǎng)絡(luò)在圖像比對(duì)任務(wù)中具有較好的可行性和競爭力。
Tao 等人[29]通過使用孿生網(wǎng)絡(luò)學(xué)習(xí)一個(gè)匹配函數(shù),以第1幀做模板,其他幀與第1幀進(jìn)行匹配計(jì)算,選最高分幀作為目標(biāo),提出的SINT(Siamese Instance Search for Tracker)算法首次使用孿生網(wǎng)絡(luò)完成了目標(biāo)跟蹤任務(wù)。
SINT的成果雖然證明了孿生網(wǎng)絡(luò)可以用于目標(biāo)跟蹤領(lǐng)域,但其效果一般而未引起廣泛注意。同年Bertinetto等人[30]提出的SiamFC(Fully-Convolutional Siamese Network)方法,讓研究人員看到了孿生網(wǎng)絡(luò)的潛力與前景。該方法設(shè)計(jì)了一個(gè)端到端的全卷積孿生跟蹤網(wǎng)絡(luò),輸出是標(biāo)量值的得分圖,尺寸取決于候選圖像的大小。其網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示,在跟蹤過程中,以Z作為輸入的模板圖像,X作為輸入的搜索圖像,接著對(duì)2個(gè)輸入分別進(jìn)行φ變換進(jìn)行特征提取。生成的特征圖進(jìn)行互相關(guān)操作,即卷積操作,生成響應(yīng)圖。最后將響應(yīng)圖進(jìn)行雙三次插值生成圖像確定目標(biāo)位置。

Figure 3 Structure of SiamFC
3.2 基于孿生網(wǎng)絡(luò)方法的改進(jìn)
SiamFC在取得具有競爭力的結(jié)果的同時(shí),其在魯棒性和準(zhǔn)確率方面的表現(xiàn)仍有所欠缺,但卻讓研究人員看到了孿生網(wǎng)絡(luò)更多的可能性。截至目前,研究人員改進(jìn)的基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法在準(zhǔn)確率和實(shí)時(shí)性上都已經(jīng)趕超了傳統(tǒng)跟蹤算法和其他基于深度學(xué)習(xí)的算法,本節(jié)將介紹對(duì)應(yīng)的改進(jìn)的孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法。
3.2.1 額外的分支
He等人[31]觀察到圖像分類任務(wù)中的語義特征和相似性匹配任務(wù)中的外觀特征互補(bǔ),在原有的SiamFC的基礎(chǔ)上,增加了語義分支,并在該分支上加上通道注意力模型,該模型將網(wǎng)絡(luò)輸入的特征分為3*3的塊,然后對(duì)每塊進(jìn)行最大池化處理,再通過多層感知機(jī),得到最后每個(gè)通道的權(quán)重值,選擇對(duì)特定跟蹤目標(biāo)影響最大的通道。SASiam(Semantic and Appearance Siamese Network)的2個(gè)分支是分開訓(xùn)練的,只在測(cè)試階段進(jìn)行加權(quán)求和。
如圖4所示,z表示目標(biāo)圖像,X表示搜索區(qū)域圖像。hs(zS,X)與ha(z,X)分別表示雙分支卷積得到的映射結(jié)果,通過加權(quán)求和,得到最終相似度結(jié)果h(zS,X)。SASiam的額外的分支為孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法從傳統(tǒng)的統(tǒng)一計(jì)算處理到之后的分別處理,綜合計(jì)算損失奠定了基礎(chǔ),擴(kuò)寬了研究人員的視野。

Figure 4 Structure of SASiam
3.2.2 錨設(shè)計(jì)
SASiam雖然將分類和相似性檢測(cè)相結(jié)合,但并沒有對(duì)邊界框進(jìn)行回歸,浪費(fèi)了時(shí)間和空間,但同年的Li 等人[32]受到Faster R-CNN(Faster Regions with Convolutional Neural Network features)[33]的啟發(fā),在提出的SiamRPN(Siamese Region Proposal Network)中引入了RPN模塊來產(chǎn)生候選區(qū)域。如圖5所示,RPN候選區(qū)域由2個(gè)分支組成,一個(gè)是用來區(qū)分目標(biāo)和背景的分類分支,另一個(gè)是微調(diào)候選區(qū)域的回歸分支。其中,x,y,w,h分別表示回歸得到矩形框的中心坐標(biāo)和矩形的長與寬;n表示錨框的數(shù)量;k表示幀數(shù)。RPN通過對(duì)多個(gè)錨框上產(chǎn)生的多種矩形進(jìn)行分類和回歸,得到感興趣的區(qū)域。

Figure 5 Structure of SiamRPN
在分類分支上,模板圖像和檢測(cè)圖像特征先經(jīng)過卷積處理,其中,模板分支的通道數(shù)會(huì)增加到對(duì)應(yīng)錨框數(shù)量的2倍,對(duì)應(yīng)前景和背景信息,并在后續(xù)操作中作為檢測(cè)圖像特征的卷積核,最終返回相應(yīng)錨框數(shù)量的維度為2的分?jǐn)?shù)圖,也就是對(duì)應(yīng)的分類分?jǐn)?shù)。在回歸分支上,類似地,模板分支的通道數(shù)會(huì)增加到4n倍,與分類分支不同,這些通道最終直接返回每個(gè)樣本的位置回歸值。
SiamRPN錨設(shè)計(jì)使得其在回歸方面表現(xiàn)優(yōu)異。但Zhu等人[34]后續(xù)發(fā)現(xiàn),該算法在面對(duì)目標(biāo)短時(shí)間內(nèi)消失(超出視線、全遮擋、翻面等)情況時(shí),即使跟蹤失敗,分類的相似度量依舊可保持較高的分?jǐn)?shù)。因此,在不修改SiamRPN的原有骨干網(wǎng)絡(luò)的情況下,Zhu等人[34]提出了DaSiamRPN(Distractor- aware Siamese Region Proposal Network)。如圖6所示,該算法引入ImageNet Detection[35]和COCO(Microsoft Common Objects inCOntext)[36]數(shù)據(jù)集,并使用數(shù)據(jù)增強(qiáng)技術(shù)增加了3類樣本對(duì):正樣本對(duì)、相同類別和負(fù)樣本對(duì)不同類別的負(fù)樣本對(duì)。

Figure 6 New sample pairs in DaSiamRPN
根據(jù)新增的負(fù)樣本對(duì),DaSiamRPN在原有的相似度量函數(shù)基礎(chǔ)上,添加了負(fù)樣本的影響學(xué)習(xí)。如圖7所示,新的相似度量函數(shù)得到的相似度評(píng)分可以正確反映目標(biāo)丟失現(xiàn)象(評(píng)分降低)。這種正確度量使DaSiamRPN可以較為精確地評(píng)估目標(biāo)丟失,在目標(biāo)丟失后,使用由局部到整體的策略逐步擴(kuò)大搜索區(qū)域,從而在目標(biāo)重現(xiàn)時(shí)可以快速且準(zhǔn)確地重新跟蹤到它。

Figure 7 Detection scores and according overlaps of SiamRPN and DaSiamRPN
3.2.3 骨干網(wǎng)絡(luò)優(yōu)化
淺層的AlexNet[37]骨干網(wǎng)絡(luò)難以從現(xiàn)有的數(shù)據(jù)集中挖掘出更多的知識(shí),研究人員也嘗試使用深度神經(jīng)網(wǎng)絡(luò)替換掉孿生網(wǎng)絡(luò)中的淺層骨干網(wǎng)絡(luò),但大都收效甚微。Zhang 等人[38]通過實(shí)驗(yàn)分析認(rèn)為深層網(wǎng)絡(luò)不會(huì)帶來改進(jìn)的主要原因是:神經(jīng)元感受野的大幅度增加導(dǎo)致特征識(shí)別和定位精度降低;卷積的網(wǎng)絡(luò)填充導(dǎo)致了學(xué)習(xí)時(shí)的位置偏差。并通過定量分析找到了影響深層神經(jīng)網(wǎng)絡(luò)的多個(gè)因素,包括網(wǎng)絡(luò)的深度和寬度、步長、填充、感受野和輸出特征大小。再通過定性分析,認(rèn)為網(wǎng)絡(luò)在填充之后,特征提取時(shí)會(huì)提取到填充的特征;當(dāng)目標(biāo)移動(dòng)至圖像邊界時(shí),不能精確地指示出目標(biāo)的位置。
Zhang等人[38]認(rèn)為適用于孿生網(wǎng)絡(luò)的深層骨干網(wǎng)絡(luò)步長不應(yīng)該相應(yīng)增加,而是保持在4或8即可,感受野的大小應(yīng)為模板圖像的60%~80%。對(duì)于完全卷積的孿生網(wǎng)絡(luò),處理2個(gè)網(wǎng)絡(luò)之間的感知不一致問題是至關(guān)重要的。Zhang等人給出了2種可行的解決方案:一種是刪除網(wǎng)絡(luò)中的多余的填充工作,另一種則直接裁剪受填充影響的特征并最終提出了SiamDW(Deep and Wider Siamese Network)。經(jīng)過裁剪修改的神經(jīng)網(wǎng)絡(luò)有更高的準(zhǔn)確率。
如圖8所示,SiamDW破除了孿生網(wǎng)絡(luò)無法使用深層神經(jīng)網(wǎng)絡(luò)的枷鎖,使孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法可以從原有的圖像中獲取更多的特征信息,也在一定程度上緩解了目標(biāo)跟蹤任務(wù)數(shù)據(jù)集較少而無法得到有效訓(xùn)練的問題。深層知識(shí)為回歸任務(wù)提供了更多有效信息,使算法的性能得到了較大提升。

Figure 8 Accuracy comparison of SiamDW backbone networks
同年,Li等人[39]提出的SiamRPN++中使用了修改后的殘差網(wǎng)絡(luò)[40],與SiamDW類似,為了定位的準(zhǔn)確率,將最后2個(gè)殘差模塊的步長減少到8,并使用了空洞卷積[41]技術(shù)。這樣既增大了感受野,也利用了預(yù)訓(xùn)練參數(shù)。這種修改使最后3個(gè)殘差模塊的分辨率始終一致,所以作者又使用了多層融合技術(shù)。此外,作者還修改了互相關(guān)操作,并將新的互相關(guān)操作命名為深度互相關(guān),如圖9所示,這種改進(jìn)使參數(shù)量大幅下降,同時(shí)也使整體訓(xùn)練變得更為穩(wěn)定,加強(qiáng)了網(wǎng)絡(luò)的整體性。類似地,SiamRPN++的作者也用MoblieNet[42]等網(wǎng)絡(luò)進(jìn)行了相同的改動(dòng)和實(shí)驗(yàn)。

Figure 9 Differences between deep-wise cross-correlation method and traditional cross-correlation method
3.2.4 無錨設(shè)計(jì)
Li等人[43]認(rèn)為,以SiamRPN為首的RPN頭需要對(duì)錨框選擇做出仔細(xì)調(diào)整,這個(gè)工作費(fèi)時(shí)費(fèi)力,于是提出了一種利用無錨的級(jí)聯(lián)KPN(Keypoint Prediction Network)特征融合頭實(shí)現(xiàn)的算法,并命名為SiamKPN。如圖10所示,SiamKPN使用的KPN模塊包括3個(gè)3×3的卷積和1個(gè)5×5的深度互相關(guān)模塊,并將返回的結(jié)果經(jīng)過2次卷積得到熱圖,該熱圖有5個(gè)通道,其中1個(gè)通道用于估計(jì)目標(biāo)的中心點(diǎn),2個(gè)用于解決步長導(dǎo)致的離散誤差,另外2個(gè)則用于估算目標(biāo)大小。SiamKPN在使用3層級(jí)聯(lián)的同時(shí),縮小了標(biāo)簽熱圖的方差,沿著級(jí)聯(lián)方向逐漸細(xì)化,加強(qiáng)了特征信號(hào)的監(jiān)督強(qiáng)度。這種修改使得目標(biāo)中線點(diǎn)周圍的區(qū)域特征更加突出,前后景差異更加明顯,從而更容易區(qū)分目標(biāo)與類似的干擾項(xiàng)。

Figure 10 Structure of SiamKPN
類似地,Chen等人[44]認(rèn)為使用錨框的多尺度設(shè)計(jì)來估計(jì)目標(biāo)大小,雖然使精確度有顯著提高,但這種啟發(fā)式設(shè)計(jì)也引入了大量的參數(shù),增加了計(jì)算復(fù)雜度。于是在之后設(shè)計(jì)了無錨跟蹤器SiamBAN(Siamese Box Adaptive Network),它直接預(yù)測(cè)了相關(guān)特征映射上每個(gè)空間位置的前景與背景類別評(píng)分和一個(gè)4D向量。與傳統(tǒng)的回歸方法不同,該4D向量描述了從邊框的4個(gè)側(cè)面到搜索區(qū)域?qū)?yīng)的特征位置中心點(diǎn)的相對(duì)偏移。如圖11所示,一個(gè)骨干網(wǎng)絡(luò)中有多個(gè)特征融合頭處理單元用于進(jìn)行自適應(yīng)邊框預(yù)測(cè)。與SiamRPN++類似,這些處理單元也使用模板分支的卷積結(jié)果,與檢測(cè)分支深度互相關(guān)得到對(duì)應(yīng)層的互相關(guān)特征圖。最后將各個(gè)卷積層的特征圖進(jìn)行融合,得到最后的互相關(guān)結(jié)果。SiamBAN的無錨框設(shè)計(jì)在不損失精度的情況下,將輸出所需要的變量數(shù)減少到有錨框設(shè)計(jì)的1/5,極大地提高了訓(xùn)練與跟蹤的速度。

Figure 11 Structure of SiamBAN
Xu等人[45]受到質(zhì)量評(píng)估[46,47]的啟發(fā),在卷積模塊后的分類分支中增加了質(zhì)量評(píng)估分支,提出了SiamFC++。質(zhì)量評(píng)估分支對(duì)遠(yuǎn)離中心點(diǎn)的位置進(jìn)行約束,使距離中心點(diǎn)近的像素點(diǎn)評(píng)分高,遠(yuǎn)離中心點(diǎn)的像素點(diǎn)評(píng)分低,如圖12所示,質(zhì)量評(píng)估分支最終與原分類分支結(jié)果點(diǎn)乘,得到分類分支結(jié)果。最后與回歸分支使用argmax函數(shù)結(jié)合。

Figure 12 Processing of SiamFC++ convolution results
綜合SiamBAN和SiamFC++的優(yōu)勢(shì),Guo等人[48]提出了SiamCAR(Siamese fully Convolutional classification And Regression),為了抑制過大的位移導(dǎo)致的精確度下降,在SiamBAN的基礎(chǔ)上增加了類似SiamFC++的質(zhì)量評(píng)估分支,從而使網(wǎng)絡(luò)在跟蹤時(shí)更精確地獲取到目標(biāo)的中心點(diǎn)。并且,SiamCAR修改了SiamBAN互相關(guān)特征圖的融合方式,將原來的相加取平均值修改為拼接后降維的方法,通過訓(xùn)練修改權(quán)重,找到最佳的融合方法。
3.2.5 Transformer方法
相關(guān)性在孿生網(wǎng)絡(luò)跟蹤領(lǐng)域起著關(guān)鍵作用,但該操作實(shí)際上是一個(gè)局部線性匹配的過程,易丟失語義信息,繼而陷入局部最優(yōu)。Chen等人[49]受Transformer[50]啟發(fā),提出了基于注意力的特征融合網(wǎng)絡(luò)TransT(Transformer Tracking)。TransT設(shè)計(jì)了一種獨(dú)特的特征融合層,先使用自注意力ECA(Efficient Channel Attention)模塊分別增強(qiáng)來自模板分支和搜索分支的特征信息,再使用交叉注意力CFA(Cross Feature Augment)模塊同時(shí)接收各分支自身和另一個(gè)分支的特征,并通過多頭交叉注意力進(jìn)行特征融合。如圖13所示,TransT將孿生網(wǎng)絡(luò)提取的特征經(jīng)過降維后,輸入由4個(gè)獨(dú)特的特征融合層疊加的融合層,再使用一個(gè)額外的交叉注意力融合2個(gè)分支的特征。在預(yù)測(cè)結(jié)果時(shí),使用無錨方法直接預(yù)測(cè)標(biāo)準(zhǔn)化坐標(biāo),從而使整體的跟蹤框架更加簡潔。

Figure 13 Structure of TransT
與TransT多個(gè)特征融合層疊加不同,Zhao等人[51]提出了TrTr(visual Tracking with Transformer)算法。如圖14所示,該算法設(shè)計(jì)的特征融合網(wǎng)絡(luò)中,先分別使用自注意力模塊增強(qiáng)模板分支和搜索分支的特征信息,之后,模板分支經(jīng)過一個(gè)額外的前饋網(wǎng)絡(luò)FPN(Feature Pyramid Network)后,直接與搜索分支的特征使用交叉注意力進(jìn)行特征融合。

Figure 14 Transformer structure of TrTr
TrTr的特征融合網(wǎng)絡(luò)的設(shè)計(jì)更接近傳統(tǒng)的Transformer,對(duì)注意力使用和特征圖處理的探討相較TransT略有不足,但其使用了額外的在線學(xué)習(xí)方法,提高了跟蹤的準(zhǔn)確率。
受到DETR(DEtection TRansformer)[52]啟發(fā),Yan等人[53]提出了STARK算法,不僅將原Transformer的編碼器層和解碼器層分別疊加6次,還使用角點(diǎn)概率分布設(shè)計(jì)了獨(dú)特的預(yù)測(cè)頭。如圖15所示,該預(yù)測(cè)頭首先從編碼器中獲取搜索分支的特征,計(jì)算與解碼器的輸出嵌入之間的相似程度;再使用該相似度的得分與搜索分支的特征相乘以突出重要特征;最后使用一個(gè)簡單的全卷積網(wǎng)絡(luò)完成對(duì)角點(diǎn)的預(yù)測(cè)。不僅如此,STARK考慮到目標(biāo)物體的外觀可能會(huì)隨時(shí)間發(fā)生顯著變化,對(duì)算法進(jìn)行進(jìn)一步優(yōu)化,如圖16所示。首先,在輸入端引入中間幀采樣,以提供額外的其他時(shí)間信息。其次,添加了一個(gè)額外的得分預(yù)測(cè)頭過濾掉目標(biāo)完全遮擋或移除視線等不可靠幀覆蓋動(dòng)態(tài)模板。最后,將訓(xùn)練過程分為2個(gè)階段,分別關(guān)注定位和分類任務(wù),防止聯(lián)合學(xué)習(xí)導(dǎo)致2個(gè)任務(wù)的解決方案都不理想。
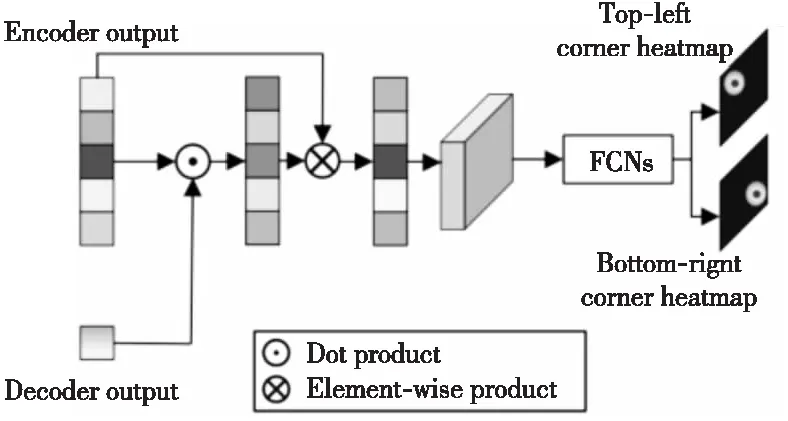
Figure 15 Structure of STARK’s box prediction head
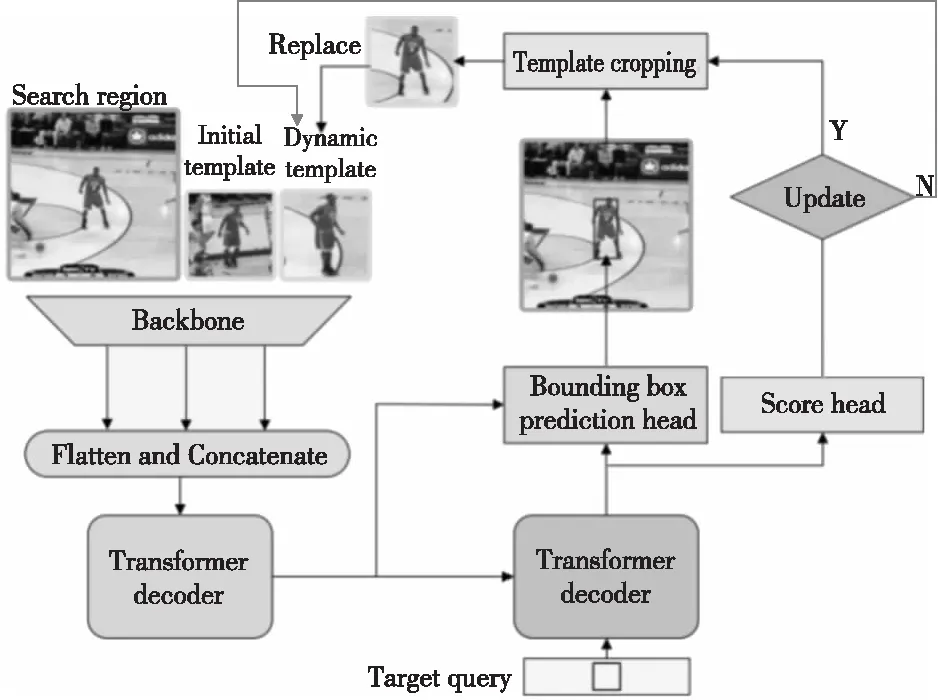
Figure 16 Framework of spatio-temporal tracking
與殘差網(wǎng)絡(luò)相比,Swin-Transformer[54]可以提供更緊湊的特征表示和更豐富的語義信息,Lin等人[55]以此為骨干網(wǎng)絡(luò),設(shè)計(jì)并提出了SwinTrack算法。如圖17所示,得益于骨干網(wǎng)絡(luò)的更換,SwinTrack可以接收多模態(tài)的數(shù)據(jù)作為輸入,從而使用基于連接的融合方法代替基于交叉注意的融合方法,降低了運(yùn)算的復(fù)雜度。不僅如此,在預(yù)測(cè)分類時(shí)引入目標(biāo)候選包圍框與真實(shí)目標(biāo)標(biāo)注的交并比得分,使分類分支的預(yù)測(cè)更加準(zhǔn)確。

Figure 17 Structure of SwinTrack
3.2.6 其他改進(jìn)方法
Voigtlaender等人[56]設(shè)計(jì)了一種將Faster R-CNN中的RCNN模塊級(jí)聯(lián)3次的重檢測(cè)頭,以得到更精確的特征圖相似評(píng)分,并提出了SiamR-CNN。如圖18所示,該算法先使用孿生網(wǎng)絡(luò)進(jìn)行特征提取后,將第1幀的特征中的目標(biāo)區(qū)域特征與當(dāng)前幀經(jīng)RPN網(wǎng)絡(luò)得到的候選區(qū)域特征結(jié)合,使用重檢測(cè)頭回歸計(jì)算這些候選區(qū)域與目標(biāo)區(qū)域的相似度的得分。再使用其中得分較高的結(jié)果,與上一幀以相似方法得到的區(qū)域特征排列組合,再使用重檢測(cè)頭回歸計(jì)算。繼而完成了當(dāng)前幀與第1幀、當(dāng)前幀與上一幀的關(guān)聯(lián),得到了更精確的回歸邊框。
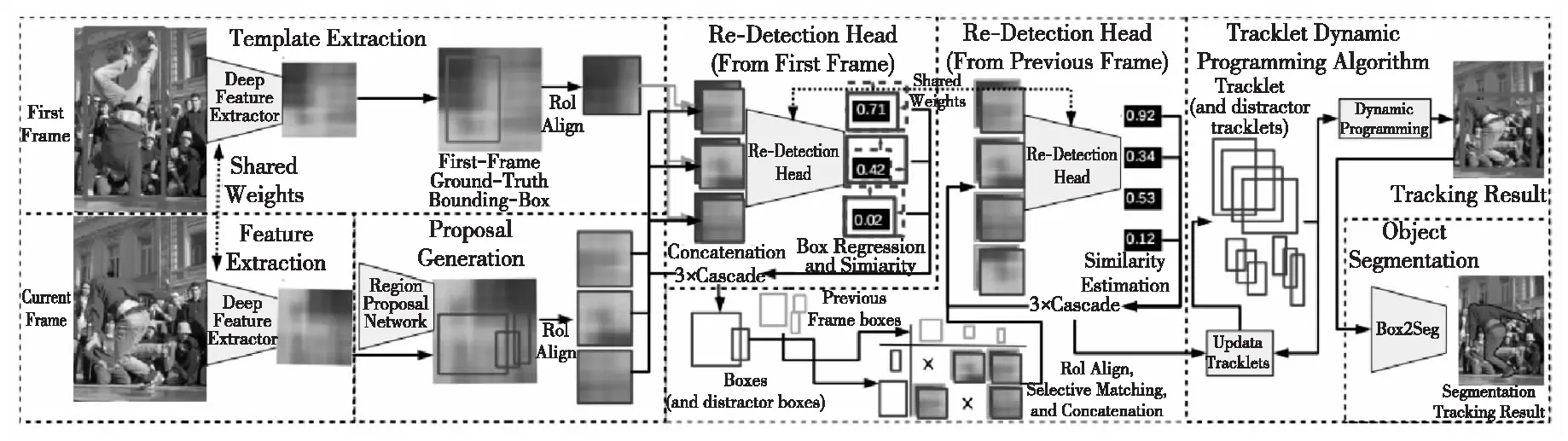
Figure 18 Structure of SiamR-CNN
在跟蹤過程中,SiamR-CNN對(duì)所有可能的結(jié)果都進(jìn)行檢測(cè),并隨著新目標(biāo)的出現(xiàn)產(chǎn)生新的跟蹤軌跡,這些軌跡與真實(shí)的軌跡動(dòng)態(tài)關(guān)聯(lián),得到正確的跟蹤結(jié)果。這些方法的融合極大地提高了跟蹤的精度,但復(fù)雜的計(jì)算導(dǎo)致網(wǎng)絡(luò)的實(shí)時(shí)性有待提高。
SiamKPN等無錨框設(shè)計(jì)擺脫了復(fù)雜的超參數(shù)調(diào)整,但與SiamRPN等跟蹤方法一樣,仍將固定比例的裁剪區(qū)域作為模板特征,這種方法可能會(huì)引入很多的背景信息,或者丟失大量的前景信息,特別是當(dāng)模板目標(biāo)的寬高比發(fā)生了急劇的變化時(shí)尤為突出。
Guo等人[58]在設(shè)計(jì)SiamCAR后繼續(xù)探索其他模塊與孿生網(wǎng)絡(luò)結(jié)合的可能性,利用注意力機(jī)制聚合相鄰節(jié)點(diǎn)的特征,構(gòu)建了適合孿生網(wǎng)絡(luò)的圖形注意力模塊[57],如圖19所示。作者根據(jù)該模塊設(shè)計(jì)了SiamGAT(Siamese Graph Attention Tracking)算法[58]。

Figure 19 Graph attention module of SiamGAT
SiamGAT將模板幀中標(biāo)記的邊框投影到特征圖上,從而得到一個(gè)感興趣的區(qū)域,并僅使用這個(gè)區(qū)域的像素作為模板特征,這些像素作為模板子圖的節(jié)點(diǎn)GT。而在搜索幀中,所有的像素都被當(dāng)作搜索子圖的節(jié)點(diǎn)GS。GT中的所有節(jié)點(diǎn)ht被aij賦予注意力后與GS中某個(gè)節(jié)點(diǎn)hs進(jìn)行聚合表達(dá),再將該聚合表達(dá)與原節(jié)點(diǎn)hs組合起來得到更強(qiáng)的特征表達(dá)。W為每次線性變換所使用的矩陣。這2幅子圖作為圖形注意力模塊的輸入,最終重構(gòu)出每個(gè)搜索節(jié)點(diǎn)的表示。最后,SiamGAT使用SiamCAR中的分類與回歸的特征融合頭處理網(wǎng)絡(luò)。2個(gè)分支共享圖形注意力模塊的輸出結(jié)果,并最終得到跟蹤結(jié)果。


Figure 20 Special process of SE-SiamFC
4 實(shí)驗(yàn)對(duì)比
本文使用OTB2015[6]、VOT2018[60]與LaSOT(Large-scale Single Object Tracking)[61]作為上述所有基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法的測(cè)試數(shù)據(jù)集,通過算法間的對(duì)比直觀地展示它們的跟蹤性能。
4.1 OTB2015
Wu等人[6]在前人研究的基礎(chǔ)上提出了目標(biāo)跟蹤基準(zhǔn)OTB2013,并在后續(xù)的研究中,將最初的50個(gè)視頻序列拓展到100個(gè),即如今的OTB2015測(cè)試數(shù)據(jù)集,也稱OTB100。OTB2015包含灰度圖像和彩色圖像,數(shù)據(jù)集完全公開,而且涉及了目標(biāo)跟蹤領(lǐng)域大部分復(fù)雜情況的挑戰(zhàn),從而能更加準(zhǔn)確地判斷目標(biāo)跟蹤算法面對(duì)現(xiàn)實(shí)生活中各種情況的能力。基于該測(cè)試集主要通過2個(gè)指標(biāo)評(píng)價(jià)目標(biāo)跟蹤算法:
(1)成功率Successrate。將每個(gè)視頻跟蹤算法估計(jì)的跟蹤框內(nèi)的像素點(diǎn)個(gè)數(shù)與人工標(biāo)注的跟蹤框內(nèi)的像素點(diǎn)個(gè)數(shù)的交集與并集的比值定義為重合率得分。給定重疊率閾值,當(dāng)某一幀算法得到的重疊率得分大于該閾值時(shí),視該幀為成功幀。總成功幀數(shù)占所有幀數(shù)的比值即為當(dāng)前閾值下的成功率。閾值由0到1,可擬合出成功率的曲線。
(2)準(zhǔn)確率Precision。計(jì)算每個(gè)視頻跟蹤算法估計(jì)的跟蹤框中心點(diǎn)與人工標(biāo)注的跟蹤框中心點(diǎn)的距離。給定距離閾值,準(zhǔn)確率為2個(gè)中心點(diǎn)距離小于給定閾值幀數(shù)占總幀數(shù)的百分比。根據(jù)不同的距離閾值,可擬合出準(zhǔn)確率的曲線。
各算法在OTB2015上的測(cè)試結(jié)果如圖21所示。
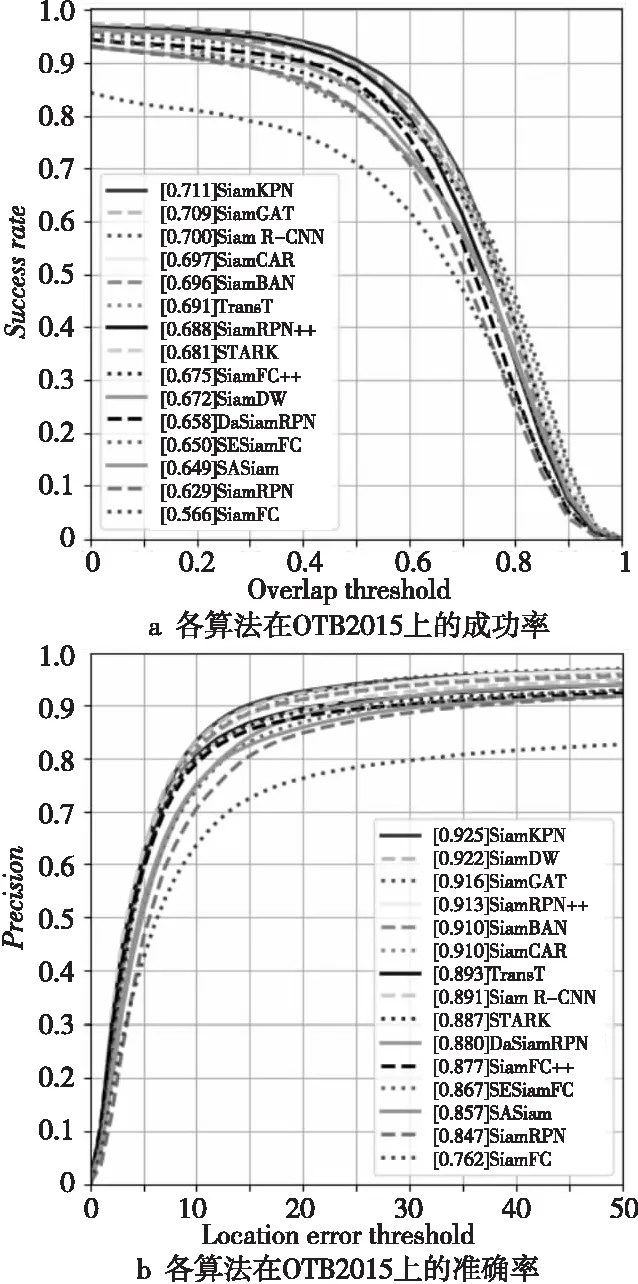
Figure 21 Comparison of success rates and precision rate of each algorithm on OTB2015
4.2 VOT2018
VOT競賽作為目標(biāo)跟蹤領(lǐng)域最具權(quán)威和影響力的測(cè)評(píng)平臺(tái),由伯明翰大學(xué)、盧布爾雅那大學(xué)、布拉格捷克技術(shù)大學(xué)和奧地利科技學(xué)院聯(lián)合創(chuàng)辦,旨在評(píng)測(cè)在復(fù)雜場(chǎng)景中單目標(biāo)跟蹤算法的性能。該競賽使用的數(shù)據(jù)集由公開測(cè)試集與隱藏測(cè)試集組成,測(cè)試序列涵蓋遮擋、光照變化、快速運(yùn)動(dòng)和尺度變化等影響因素。評(píng)測(cè)集逐年進(jìn)行更新,不斷加入更具挑戰(zhàn)性的序列,因此被視為視覺目標(biāo)跟蹤領(lǐng)域最難的競賽。其中,VOT2018由于其特有的反映算法實(shí)時(shí)性的評(píng)價(jià)指標(biāo)而廣泛用于測(cè)試算法的性能。
與OTB2015包含25%灰度序列不同,VOT2018是全彩色序列,且VOT序列的分辨率更高,評(píng)價(jià)指標(biāo)更為完善。基于VOT2018的評(píng)價(jià)指標(biāo)主要有以下3個(gè):
(1)平均重疊期望EAO(Expected Average Overlap):是對(duì)每個(gè)跟蹤器在一個(gè)短時(shí)圖像序列上的非重置重疊的期望值,是VOT評(píng)估跟蹤算法的最重要的指標(biāo)。
(2)準(zhǔn)確率(Accuracy):是指跟蹤器在單個(gè)測(cè)試序列上的平均重疊率(2個(gè)矩形框的交集部分除以并集部分)。
(3)魯棒性(Robustness):是指在單個(gè)測(cè)試序列上跟蹤器跟蹤失敗次數(shù)所占比例,默認(rèn)重疊率為0時(shí)跟蹤失敗。
各算法在VOT2018上的測(cè)試結(jié)果如表1所示。

Table 1 Test results of each algorithm on VOT2018
4.3 LaSOT
為了給目標(biāo)跟蹤任務(wù)提供一個(gè)大規(guī)模的訓(xùn)練數(shù)據(jù)與專業(yè)且質(zhì)量高的評(píng)估基準(zhǔn),Fan等人構(gòu)建了LaSOT數(shù)據(jù)集。與其他數(shù)據(jù)集相比,LaSOT提供了70種目標(biāo)類別,每一種又包含20個(gè)序列,即共有1 400個(gè)視頻。這些視頻平均每個(gè)長達(dá)2 512幀,最低不少于1 000幀。同時(shí),LaSOT提供了豐富的可視化邊框注釋和自然語言規(guī)范,共計(jì)352萬個(gè)高質(zhì)量人工標(biāo)注的包圍框。各算法在LaSOT上的測(cè)試結(jié)果如表2所示。實(shí)際測(cè)試過程中,將每種類別的4個(gè)序列用于測(cè)試,即共280個(gè)序列,總計(jì)69萬幀。與OTB2015相比,LaSOT不僅提供了評(píng)價(jià)指標(biāo)成功率Successrate,還提供了標(biāo)準(zhǔn)化準(zhǔn)確率NormalizedPrecision作為更準(zhǔn)確體現(xiàn)精度的評(píng)價(jià)標(biāo)準(zhǔn)。標(biāo)準(zhǔn)化準(zhǔn)確率在準(zhǔn)確率中心點(diǎn)距離的基礎(chǔ)上額外增加了目標(biāo)大小考量,以降低因準(zhǔn)確率對(duì)圖像分辨率和目標(biāo)大小過于敏感導(dǎo)致的效果不佳。

Table 2 Test results of each algorithm on LaSOT
5 問題與展望
從實(shí)驗(yàn)對(duì)比結(jié)果來看,SiamKPN、SwinTrack與SiamFC++等無錨設(shè)計(jì)的算法表現(xiàn)良好,能夠在保持高準(zhǔn)確率和高實(shí)時(shí)性的情況下應(yīng)對(duì)光照變化、尺度變化和平面內(nèi)變化等挑戰(zhàn)。但是,在梳理這些算法的結(jié)果時(shí),本文也發(fā)現(xiàn)了一些普遍問題。下面主要討論目前孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法仍需突破的瓶頸,以及未來的研究趨勢(shì)。
5.1 存在的問題
雖然在近幾年基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法得到了飛速發(fā)展,但目標(biāo)跟蹤任務(wù)本就復(fù)雜,本文對(duì)上述所有算法的結(jié)果進(jìn)行對(duì)比評(píng)估,總結(jié)出以下孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法仍待解決的問題與瓶頸。
5.1.1 網(wǎng)絡(luò)結(jié)構(gòu)復(fù)雜
目前,孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法雖在一定程度上解決了傳統(tǒng)跟蹤算法數(shù)據(jù)量少、泛化能力較差的問題,但網(wǎng)絡(luò)本身設(shè)計(jì)復(fù)雜,尤其是近幾年深層神經(jīng)網(wǎng)絡(luò)的引入,這一問題愈加突出。隨著時(shí)間推移,更多大規(guī)模目標(biāo)跟蹤數(shù)據(jù)集的提出可以為孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法提供更大幫助,但如何優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu),使數(shù)據(jù)得到充分利用的同時(shí)仍能保證回歸速度、訓(xùn)練速度與實(shí)時(shí)性是基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法亟需解決的難題。
5.1.2 特殊遮擋
孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法在面對(duì)瞬時(shí)遮擋和部分遮擋等問題時(shí),能夠快速重新找回目標(biāo)并繼續(xù)跟蹤。但是,面對(duì)如圖22所示的長時(shí)間遮擋以及頻繁遮擋等特殊的遮擋問題時(shí),孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法準(zhǔn)確率較低,甚至可能出現(xiàn)目標(biāo)丟失的情況。未來目標(biāo)跟蹤任務(wù)會(huì)越來越復(fù)雜,上述的特殊遮擋情況更是屢見不鮮,能否準(zhǔn)確找回復(fù)雜情況下被遮擋的目標(biāo)是孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法的重要問題。

Figure 22 Long time occlusion problem and frequent occlusion problem
5.1.3 回歸困難
SiamRPN的提出讓后續(xù)孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法將跟蹤任務(wù)劃分成分類與回歸2個(gè)子任務(wù)。在實(shí)際訓(xùn)練過程中,算法已經(jīng)可以準(zhǔn)確區(qū)分目標(biāo)的前景與背景。但是,孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法主流的回歸指標(biāo)IoU(Intersection over Union)[46],在面對(duì)完全不重合的目標(biāo)與完全重合卻比例變化的的目標(biāo)情況時(shí),無法正確表達(dá)損失下降的方向,導(dǎo)致回歸損失無法繼續(xù)降低,成為孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法參數(shù)更新時(shí)的瓶頸。
5.1.4 局限于平面特征
孿生網(wǎng)絡(luò)的本質(zhì)仍是2幅圖像的特征匹配問題,當(dāng)跟蹤物體在平面內(nèi)不發(fā)生劇烈變化時(shí),孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法確實(shí)能夠發(fā)揮較好的性能優(yōu)勢(shì)。但是,當(dāng)物體發(fā)生快速翻轉(zhuǎn)、翻折等立體維度的變化時(shí),該類算法并沒有高效的應(yīng)對(duì)方法。如圖23所示,現(xiàn)實(shí)生活中,目標(biāo)跟蹤任務(wù)并不只有平面內(nèi)的簡單跟蹤,能否正確認(rèn)識(shí)到自身以及周圍環(huán)境的立體維度的信息,這也是孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法需要面對(duì)的一個(gè)難題。

Figure 23 Object flipping problem and folding problem
5.2 孿生網(wǎng)絡(luò)目標(biāo)跟蹤的展望
上節(jié)總結(jié)了孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法面臨的瓶頸,這些瓶頸帶來難題的同時(shí),也引導(dǎo)著研究人員研究的方向。下面討論可能會(huì)成為今后研究熱點(diǎn)的幾個(gè)問題。
5.2.1 優(yōu)化骨干網(wǎng)絡(luò)
雖然SiamDW討論了卷積神經(jīng)網(wǎng)絡(luò)深度對(duì)孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法的影響,但影響骨干網(wǎng)絡(luò)性能的因素并不只有網(wǎng)絡(luò)深度。網(wǎng)絡(luò)的卷積方法(高波卷積[62]和動(dòng)態(tài)卷積[63]等)、使用注意力機(jī)制(SE(Squeeze and Excitation networks)[64]、CBAM(Convolutional Block Attention Module)[65]和CA(Coordinate Attention)[66]等)以及引入其他額外模塊,都已被證明可以提升視覺圖像領(lǐng)域算法的性能。孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法由于其本質(zhì)是2個(gè)或多個(gè)人工神經(jīng)網(wǎng)絡(luò)組合的耦合框架,優(yōu)化骨干網(wǎng)絡(luò)對(duì)于提升算法準(zhǔn)確率與實(shí)時(shí)性事半功倍。
5.2.2 困難樣本挖掘
DaSiamRPN證明了額外的訓(xùn)練樣本有助于提升算法的整體性能,而針對(duì)特殊遮擋等復(fù)雜的目標(biāo)跟蹤任務(wù),孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法需要對(duì)困難樣本進(jìn)行額外的訓(xùn)練來改善網(wǎng)絡(luò)參數(shù)。類似目標(biāo)檢測(cè)領(lǐng)域中提出的OHEM(Online Hard Example Mining)[67]在線學(xué)習(xí)算法,訓(xùn)練時(shí)選擇困難樣本進(jìn)行迭代,代替簡單的采樣,可以有效提高孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法在面對(duì)復(fù)雜挑戰(zhàn)時(shí)的魯棒性。
5.2.3 優(yōu)化評(píng)價(jià)指標(biāo)
近年來,GIoU(Generalized Intersection over Union)[68]、DIoU(Distance Intersection over Union)[69]以及CIoU(Complete Intersection over Union)[70]的相繼提出,彌補(bǔ)了傳統(tǒng)IoU算法在部分情況下參數(shù)更新困難的問題(如圖24所示)。將更有助于梯度下降的指標(biāo)引入到孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法中可以有效降低回歸損失。同時(shí),SESiamFC也證明了其他的相似度量函數(shù)也可以有效應(yīng)用到孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法中,并提高算法的準(zhǔn)確率。
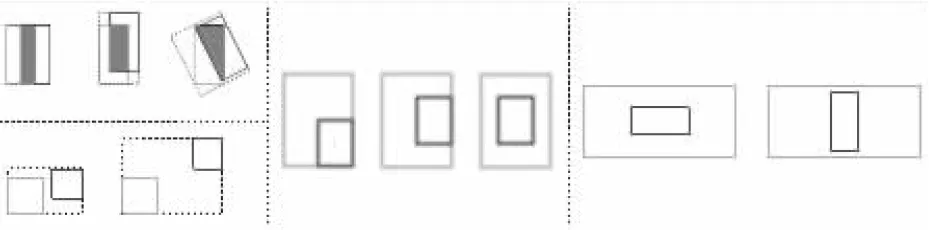
Figure 24 Regression problems that IoU method cannot solve
5.2.4 目標(biāo)立體建模
3D立體建模已經(jīng)廣泛應(yīng)用到目標(biāo)檢測(cè)[71]和目標(biāo)識(shí)別[72]任務(wù)中。將孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法的平面特征輸入修改為空間特征輸入,從而使網(wǎng)絡(luò)學(xué)習(xí)到目標(biāo)和周圍環(huán)境的立體空間知識(shí),提高網(wǎng)絡(luò)對(duì)發(fā)生劇烈形變和平面外翻轉(zhuǎn)的目標(biāo)前后景的識(shí)別能力,這種方法還有很大的拓展空間。
6 結(jié)束語
基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法是目標(biāo)跟蹤領(lǐng)域的研究熱點(diǎn)。隨著目標(biāo)跟蹤算法的不斷發(fā)展,該方向也逐漸受到研究人員更為廣泛的關(guān)注。本文首先介紹了目標(biāo)跟蹤的現(xiàn)狀以及孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法的本質(zhì)與由來,并討論了多種以孿生網(wǎng)絡(luò)為基礎(chǔ)的目標(biāo)跟蹤算法以及它們的特點(diǎn)與優(yōu)勢(shì)。通過使用近年主流且具有說服力目標(biāo)跟蹤數(shù)據(jù)集作為測(cè)試標(biāo)準(zhǔn),對(duì)比了所有介紹的基于孿生網(wǎng)絡(luò)目標(biāo)跟蹤算法的性能差異。根據(jù)實(shí)驗(yàn)結(jié)果,討論了當(dāng)前基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法的瓶頸并分析了日后的發(fā)展趨勢(shì)。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2022年3期)2022-04-26 14:04:16
數(shù)學(xué)年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學(xué)學(xué)報(bào)(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(xué)(2019年8期)2019-11-25 01:38:14
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:38
