基于全局-局部自注意力網絡的視頻異常檢測方法
2023-09-19 07:41:00楊靜吳成茂周流平
通信學報 2023年8期
楊靜,吳成茂,周流平
(1.廣州鐵路職業技術學院信息工程學院,廣東 廣州 510430;2.菲律賓圣保羅大學,土格加勞 3500;3.西安郵電大學電子工程學院,陜西 西安 710121)
0 引言
視頻異常檢測中的“異常”與“正常”通常是相對立的。一般而言,相比于正常事件,異常事件的類型是不可窮舉的,并且不頻繁發生,難以收集。因此,視頻異常檢測不僅在學術界具有非常重要的研究價值,在工業界也擁有廣闊的應用前景[1-2]。近年來,隨著視頻監控、故障檢測系統、智慧交通及智慧城市等的快速發展,視頻異常檢測變得尤為重要,視頻異常檢測的問題得到了國內外學者的廣泛關注。在視頻異常檢測中由于場景和任務屬性不同,對異常的定義也不盡相同,Saligrama 等[3]對視頻異常檢測進行了較準確的定義:視頻異常可認為是異常外觀或異常運動的屬性,或是在異常位置或時間出現正常外觀或正常運動屬性。在異常檢測中,正常數據一般遵循目標類分布,異常數據則是分布外或難以獲取的樣本。視頻異常檢測的主要任務是檢測出不符合預期規律的罕見樣本或從未發生過的突發性事件,而對于這些事件的劃分并沒有明確的界限和標準。具體而言,根據異常檢測應用場景的不同,異常類型的界定和劃分也會隨之改變,如果用分類的方法解決所有異常事件,則工作量將非常大,難以達到良好的性能。因此,對異常事件的準確檢測面臨各種挑戰,具體表現如下。1) 異常事件的劃分因場景而異[4-5],同一行為在一種任務場景中是正常的,但在另一種任務場景中可能會被判定為異常。2) 異常事件的類型是不可窮舉的,對異常事件進行人工標注的工作量非常巨大。3) 一些正常事件與異常事件非常接近,使其區分具有很大的難度。
隨著深度學習在動作識別[6-8]、跟蹤[9]、軌跡預測[10]、目標檢測[11-13]等領域取得成功,視頻異常檢測得到了大力實踐與發展[14-19]。近幾年關于視頻異常檢測的研究主要集中于無監督學習,即在訓練模型時僅使用正常樣本。首先,通過一分類,進行圖像重建/預測,或使用其他自監督學習方式對正常樣本進行建模;其次,通過識別不同于訓練模型的分布來檢測異常。在異常檢測中,由于異常數據和正常數據分布不均,呈現長尾分布的特點。因此,相比于有監督學習,無監督學習對視頻或圖像的異常檢測更加合理和有效。基于無監督的深度學習方法不僅易于獲取訓練的正常樣本,而且不需要使用真實的異常樣本;無監督的學習范式克服了有監督學習中無法預知異常的問題,因此,擁有更強且有效的特征表達能力。
重構誤差作為模型重構能力的評估指標,已被廣泛應用于異常檢測技術領域[20-22]。重構誤差的基本假設如下:一方面,由于正常樣本更接近正常訓練的數據分布,因此重構誤差較異常樣本會更低;另一方面,對于非正態分布樣本,其假設或預期重構誤差會更高[15]。通常基于自動編碼器的方法使用重構誤差作為識別異常的指標。在傳統方法中,為了在卷積神經網絡中處理視頻序列,將每個圖像幀視為具有灰度通道的2D 圖像[23];然后,將這些灰度幀按照時間順序堆疊在一起,形成一個新的2D圖像,其中第三維度由這些堆疊的灰度幀組成。通過這樣的堆疊方式,模型可以同時對空間和時間信息進行編碼并實現重構。
由于長短期記憶(LSTM,long short term memory)網絡能夠學習數據的長期依賴關系,Medel等[24]利用卷積長短期記憶網絡進行異常檢測,并將該問題定義為重構類型。盡管不是完全的自動編碼器,但他們的方法使用了編碼器-解碼器結構,即給定視頻幀的輸入序列,卷積長短期記憶網絡沿著空間和時間維度提取相關特征;最后,經過解碼器并計算重構誤差。Hasan 等[25]在第三維度通過堆疊視頻幀形成時間立方體,保留必要的時間信息,但這樣保留下來的時間信息非常有限。為了解決這個問題,Zhao 等[26]提出通過3D 卷積保留時間信息,并增加數據來改善樣本密度,進而提高檢測性能。基于以上工作,Gong 等[15]通過實驗測試發現,一些異常事件的重構誤差和正常事件的重構誤差非常接近,主要是因為自動編碼器中卷積神經網絡較強的泛化能力,使接近正常的異常事件也被重構出來。為了解決這個問題,Gong 等[15]引入了一種能夠將編碼特征存儲到內存中的自動編碼器,即編碼器不直接將編碼反饋到解碼器,而是將編碼視為查詢,該查詢預期返回內存中最接近的正常模式,將該模式用于解碼。這樣,在重構異常的情況下,由于內存中只含有正常的內存項,因此其重構誤差會很高。
近年來,注意力模型被廣泛應用于自然語言處理、圖像和語音等領域,神經網絡的可解釋性也被引入無監督的異常檢測中。Liu 等[27]使用了類似grad-CAM(gradient-weighted class activation mapping)[28]的方法將基于梯度的注意力機制推廣到變分自動編碼器(VAE,variational autoencoder)模型。Venkataramanan 等[29]提出了一種帶有注意力引導的卷積對抗變分自動編碼器,利用隱空間變量保留的空間信息進行異常定位,并且根據文獻[27]的思想生成注意力圖,期望在訓練時,注意力圖可覆蓋整個正常區域。Kimura 等[30]利用生成對抗網絡(GAN,generative adversarial network)中判別器的注意力圖來抑制圖像背景造成的異常檢測干擾,有效提升了異常檢測模型的魯棒性。
在數據特征提取的過程中,通常使用卷積來對圖像的高維特征信息進行提取,然而卷積操作無論在時間還是空間上均為局部操作。若要獲取全局的特征關聯性和建立長距離的依賴關系就要構建深層的網絡卷積,隨著網絡深度的增加與卷積塊的增多,網絡訓練的難度增大。因此,單純的卷積操作對圖像的全局信息提取存在一定的局限性。而全局-局部自注意力不僅關注圖像局部特征的關聯性,還關注特征之間長時間的依賴關系。本文擬采用一種編碼器-解碼器結構的U-Net,將RGB 圖像與視頻序列2 種模態信息進行混合編碼以突顯物體的運動變化,兩者共享解碼器,得到的特征圖通過全局-局部注意力網絡處理后再反饋給解碼器,從而進行視頻異常檢測。若解碼得到的圖像與真實圖像差異較大,則表明有異常事件發生,反之則為正常。本文主要工作如下。
1) 采用“雙編碼器-單解碼器”的編解碼混合結構,充分利用原始視頻的多維信息,并通過自注意力模塊實現有效的解碼,從而使模型能夠準確表示和理解視頻數據。
2) 使用多源數據作為輸入,充分利用運動和外觀信息的互補,并綜合考慮不同信息源以全面分析視頻數據,從而更加準確地識別異常行為。
3) 提出一種基于全局-局部自注意力機制的視頻異常檢測方法,通過全局-局部自注意力機制綜合考慮整體和局部的時序相關性,能夠更好地理解視頻序列中不同時間尺度的連續性,并保持局部上下文信息的一致性。
4) 對UCSD Ped2、CUHK Avenue 和ShanghaiTech數據集進行測試,實驗結果表明,本文方法的檢測精度分別達到97.4%、86.8%和73.2%,而且與現有方法相比,本文方法明顯提升了視頻異常檢測的能力和魯棒性,為視頻異常檢測的深入研究和實際應用提供了一定支撐。
1 相關工作
1.1 異常檢測
許多現有工作將異常檢測表述為無監督學習問題,在訓練時使用正常數據,并通過重構或判別的方式描述模型的正態性。其中,重構模型將正常數據作為輸入映射到某個特征空間,再從特征空間將正常數據映射回輸入空間,如自動編碼器(AE,autoencoder)[31]、稀疏字典[32]和生成模型[33]。判別模型表征正態樣本的統計分布并獲得正態實例周圍的決策邊界,例如,馬爾可夫隨機場(MRF,Markov random field)[20]、動態紋理混合(MDT,mixture of dynamic texture)[34]、高斯回歸[35]和一分類問題[36-37]。然而,這些方法對具有復雜分布的高維數據,如圖像、視頻等的檢測效果欠佳。本文擬采用無監督的深度學習方法進行視頻異常檢測。
1.2 注意力機制
在深度學習中,模型的參數越多所含信息量越豐富,表達能力也越強,但這也會導致信息量過大的問題。通過引入注意力機制,可快速高效地篩選出高價值的特征信息,使檢測模型能更準確地聚焦于關鍵信息,避免無用信息對模型的干擾,從而克服信息量過大的問題,并提高模型對任務處理的效率和準確性。Purwanto 等[38]在低分辨率視頻中利用雙向自注意力捕捉長期的時間依賴關系,以此進行視頻動作識別。Zhou 等[39]通過注意力圖來解決異常檢測中前景與背景不平衡的問題,通過對前景和背景賦予不同的權重,使模型更注重前景,并對訓練數據中的背景進行有效抑制來提升異常檢測性能。Hu 等[40]在自動編碼器中引入循環注意力機制,并將其構建為一個循環注意力單元,使模型能夠在新場景中具有快速適應能力。Yang 等[41]通過將Swin Transformer 設計為具有雙向跳躍連接的U 型結構的網絡,并在跨注意力和時序上采用殘差跳躍連接來進一步輔助還原視頻中復雜的靜態和動態運動目標特征。
1.3 基于重構和預測的方法
預測模型的目的是將未來的輸出幀建模為基于過去若干視頻幀的函數,如GAN 生成未來幀。GAN 主要由兩部分組成,一是生成器,模擬原始數據分布;二是判別器,給出來自生成器輸入的概率。基于U-Net 在圖像到圖像轉換方面的出色表現,Luo等[42]利用類似GAN 的生成器-判別器結構,將其作為網絡的生成器來預測未來幀,并通過網絡末端的判別器確定預測幀是否異常。通常假設正常事件是可以預測的,而異常事件則無法預測。Park 等[16]提出了一種在U-Net 結構下,通過編碼器-解碼器間的記憶模塊所記錄的各種正常模式,對未來幀進行預測的方法。同時,Yu 等[43]受到在語言學習中完形填空形式的啟發,通過時間維度的上下文和模態信息來建立多個模型,分別預測視頻中的視頻幀或視頻流。鑒于在實際場景中異常的復雜性,Liu等[44]提出了一個集成光流重構和視頻幀預測的混合框架來進行視頻異常檢測。首先,在自動編碼器中使用多層級記憶模塊存儲光流重構的正常模式,以便在光流重構誤差較大時準確地識別異常事件。其次,在重構光流條件下,通過條件變分自動編碼器(CVAE,conditional variational autoencoder)捕捉視頻幀和光流之間的高相關性,以便預測未來幀。
在目前主流的異常檢測工作中,對正常數據的特征進行重構是較常用且直觀的方法。Nguyen 等[17]提出了重構和光流預測共享編碼器的網絡模型,雖然模型充分學習了物體外觀和運動信息的對應關系,但由于光流的計算對資源要求高,整個模型的計算成本較高。在無監督深度學習方法中,AE[31]作為異常檢測的常用方法,其對高維數據(如圖像、視頻等)具有很強的建模能力。基于AE 的方法通常假設能夠重構正常樣本,而不能重構異常樣本。但由于AE 的泛化能力過于強大,以至于異常樣本也能被很好地重構,因此為了降低AE 中卷積神經網絡(CNN,convolutional neural network)的泛化能力,Chang 等[45]構建了一種將空間和時間信息解耦為2 個子模塊的自動編碼器結構,兩者同時學習時空特征信息,以提高檢測性能。Le 等[46]提出了一種基于殘差注意力的自動編碼器進行視頻異常檢測,通過在解碼器內引入通道注意力機制對未來幀進行有效預測。由于自動編碼器在重構時,缺少對圖像某些重點區域編碼信息的動態掌握,造成重構時視頻幀內容的上下文信息缺失,進而導致模型性能下降。為了解決上述問題,本文基于預測的方法進行異常檢測,其主要思想是根據先前若干幀的特征變化來預測當前幀,并在測試階段將預測出的當前幀與對應的真實幀進行對比,如果兩者的預測誤差較大,則表明存在異常。這樣既充分考慮了正常樣本的多樣性,又抑制了CNN 強大的泛化能力。
2 視頻異常檢測
2.1 基本原理
本文通過對未來幀的預測進行無監督的視頻異常檢測。受到重構方法的啟發[15-16,47],將預測視為使用之前的若干幀或連續視頻序列來進行未來視頻幀的重構,因此,本文以一種預測的視角對未來幀進行重構,并采用U-Net[48]為基礎網絡框架,進行視頻異常檢測。全局-局部自注意力網絡主要由三部分組成:雙編碼器、全局-局部自注意力模塊、解碼器。整個網絡均采用端到端的方式進行訓練,網絡的整體框架如圖1 所示。在輸入之前,需要進行簡單的數據預處理,即生成與原始圖像相對應的RGB 圖像。首先,輸入t幀的視頻序列和對應的RGB 圖像,經過編碼器編碼后,得到2 個對應的特征圖;然后,將特征圖通過按位相加進行融合,將融合后的特征圖送入全局-局部自注意力模塊進行處理;最后,將處理好的特征圖反饋到解碼器進行解碼,從而進行視頻異常檢測。
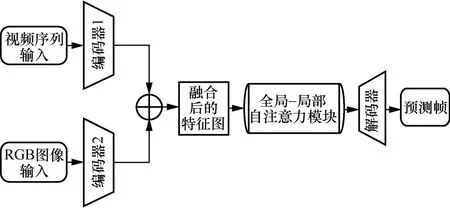
圖1 網絡的整體框架
2.2 雙編碼器-單解碼器結構
本文提出的雙編碼器結構能夠很好地對輸入圖像中的外觀和運動信息同時進行學習,并共享一個解碼器。本文采用U-Net 結構,為了避免梯度消失和信息不平衡,U-Net 在高層和低層語義信息之間加入跳躍連接。在原來U-Net 框架的基礎上,本文將網絡深度從4 層增加到5 層。此外,受ResNet 結構的啟發,本文在模型的主干網絡中使用殘差模塊來代替U-Net 中的標準卷積模塊,但檢測效果較差,其原因有兩點:其一是U-Net 整體規模較小,網絡沒有達到一定深度,使殘差模塊沒有發揮應有的作用;其二,模型訓練數據不足,使殘差模塊得不到充分的訓練。
給定編碼器t幀視頻序列xclips={I1,I2,…,It},得到大小為H×W×C的編碼特征圖M,其中,H、W和C分別表示特征的高、寬和通道數。
其中,θ為編碼器fe(·) 的參數。M經過全局-局部自注意力模塊得到特征圖M′,并將其反饋到解碼器進行解碼,即
其中,α為解碼器fd(·) 的參數。
預測未來幀的損失函數Lpre和RGB 損失函數LRGB可分別用L2 損失函數表示為
2.3 全局-局部自注意力模塊
根據視頻分析和視頻理解中注意力機制的相關運行原理[21,49-50],本文利用全局-局部自注意力模塊捕捉時間維度的全局和局部依賴性。膨脹卷積通常應用于空間維度,其主要作用是在同等分辨率的條件下,通過增大卷積的感受野來獲得更多的特征信息。本文使用膨脹金字塔卷積,來捕捉視頻片段在時間維度上的多尺度依賴性,從而進一步提高視頻異常檢測性能,全局-局部自注意力框架如圖2所示。
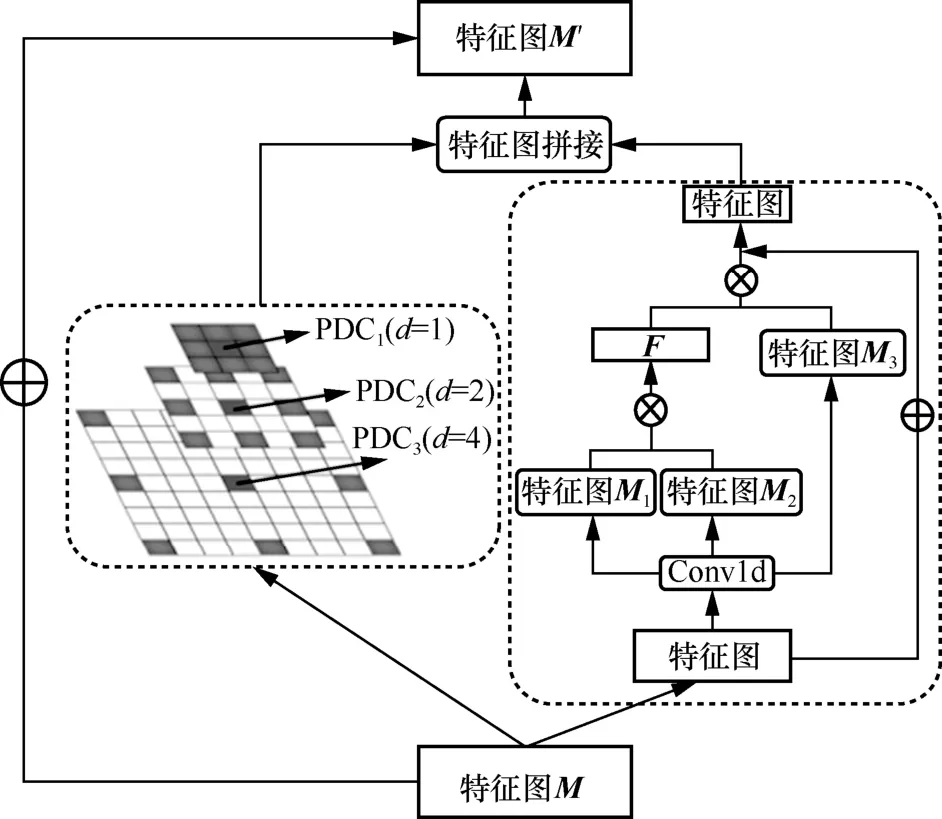
圖2 全局-局部自注意力框架
局部自注意力模塊從編碼器中得到編碼特征圖M={m1,m2,…,mi,mC},然后對M進行卷積操作,在局部自注意力部分主要有三層膨脹卷積操作,即 {PDC1,PDC2,PDC3},其對應的膨脹因子d分別為{1,2,4}。其數學形式為
其中,Dl表示第l層的卷積操作,mi為特征表達。
全局時序依賴主要通過一個自注意力模塊實現,其性能已在視頻理解、圖像分類、目標檢測等多個下游任務中得到驗證。通過全局自注意力的作用,將距離相對較遠的特征像素點建立一種依賴關系,使全局的特征關聯性更加緊密。首先,對特征圖M進行1×1卷積處理,得到3 個尺寸和特征相同的特征圖Mc(c∈{1,2,3}),將特征圖M1和M2的轉置進行運算,得到時空關系映射矩陣F,即F=(M1)(M2)T,Fij表示在位置i和位置j的關聯程度,其數值大小代表了關聯性的緊密程度,然后將F與M3進行卷積操作,得到F′=Conv1×1(FM3),將F′與原始特征圖M通過跳躍連接相加得到FSA,其中FSA=F′+M。
2.4 損失函數
為了最小化預測幀和真實幀之間的差異,本文使用了強度、梯度和時序圖像差異作為約束。強度約束比較兩幀之間每個像素的值,保證RGB 空間的像素值在整個畫面中是相似的。梯度約束比較兩幅圖像相同位置像素值的梯度,并對生成的幀進行銳化。其梯度損失函數為
其中,i和j表示像素值的索引位置。在設計梯度損失函數的過程中,本文使用L1損失函數作為梯度損失,通常情況下能夠得到清晰的圖像,并且在訓練過程中能夠更好地被優化。
對于整個網絡模型而言,其整體的損失函數為
其中,λ、μ、ν為超參數。
2.5 異常得分
在最初假設不變的情況下,即模型能夠很好地預測正常事件,本文使用預測幀與真實幀I之間的差異來進行異常預測。均方差(MSE,mean square error)是一種衡量預測圖像質量的較常用的方法,其主要思想是通過計算RGB 圖像空間中所有像素的預測值與其真實值之間的歐氏距離。Mathieu 等[51]證實峰值信噪比(PSNR,peak signal to noise ratio)能夠很好地對圖像質量進行評估,計算式為
其中,maxi表示圖像的最大像素值,表示真實圖像與預測圖像的像素之間的均方差。PSNR 越高表明該視頻幀是正常的可能性就越大,在計算完每幀的PSNR 之后,將這些數值歸一化到[0,1]內,并計算每個視頻幀的異常分數為
3 實驗結果與分析
本節使用3 個公開的異常檢測數據集測試所提方法以及不同模塊的功能,包括UCSD 行人數據集[34]、CUHK Avenue 數據集[52]和ShanghaiTech數據集[53],并對實驗結果進行定性和定量分析,以便驗證本文方法的有效性。
3.1 數據集
1) UCSD 行人數據集
UCSD 行人數據集由Mahadevan 等[34]創建,包含2 個子數據集UCSD Ped1 和UCSD Ped2,該數據集主要通過學校中固定在較高位置的攝像機俯瞰拍攝獲得,且人行道的行人密度是由稀疏到稠密不斷變化的。UCSD Ped1 中主要包含34 個訓練視頻和36 個測試視頻,其分辨率為238 像素×158 像素。UCSD Ped2 主要包含16 個訓練視頻和12 個測試視頻,其分辨率為360 像素×240 像素。
2) CUHK Avenue 數據集(簡稱Avenue數據集)
CUHK Avenue 數據集[52]采集于香港中文大學(CUHK)校園,數據集中人物的尺寸會因為攝像機的位置和角度而改變。其中共有47 個異常事件,主要是行人的異常動作及拋物、異常的奔跑等。該數據集包含16 個訓練視頻和21 個測試視頻,共30 652 幀(包括15 328 個訓練幀和15 324 個測試幀)。
3) ShanghaiTech 數據集
ShanghaiTech 數據集[53]是根據已有數據集的固有缺陷所提出的,即缺乏場景和視角的多樣性。數據集包含了437 個校園監控視頻,在13 個復雜光照條件的應用場景中有130 個異常視頻,由于數據集提出的最初設定是用于無監督學習,因此,異常事件均包含于測試集中。
3.2 評價指標與實驗設置
本節實驗使用視頻異常檢測中最常用的評估指標,即接受者操作特征(ROC,receiver operating characteristic)曲線、曲線下面積(AUC,area under curve)和等錯誤率(EER,equal error rate)。AUC不關注具體的正負樣本得分,只關注整體結果,因此,它能夠有效避免在閾值選擇過程中因經驗設定而產生的主觀性,特別適合于正負樣本不均衡任務的性能評估。EER 是錯誤接受率(FAR,false acceptance rate)和錯誤拒絕率(FRR,false rejection rate)相等時的錯誤率,也是ROC 曲線與對角線的交點。模型性能越好,AUC 越高,EER 則相反。根據文獻[15,44,47]的實驗要求,本文實驗使用NVIDIA GeForce RTX 3090 GPU 進行端到端的訓練和測試,網絡模型使用Pytorch 深度學習框架實現,并使用Adam 隨機梯度下降來進行參數優化,學習率為1×10-4,使用AUC 對檢測模型的性能進行判別。
3.3 方法比較
本節將所提方法與基于手工特征的方法以及基于深度學習的方法進行比較,對比方法如下。1) 基于手工特征的方法:MPPCA[20]、MDT[34]、DFAD[54]。2) 基于深度學習的預測方法:Conv AE[30]、ConvLSTM-AE[55]、TSC[53]、MNAD[16]、IPR[47]等。表1 列出了不同方法的AUC,對比方法的性能均是從其對應文獻中獲得的。
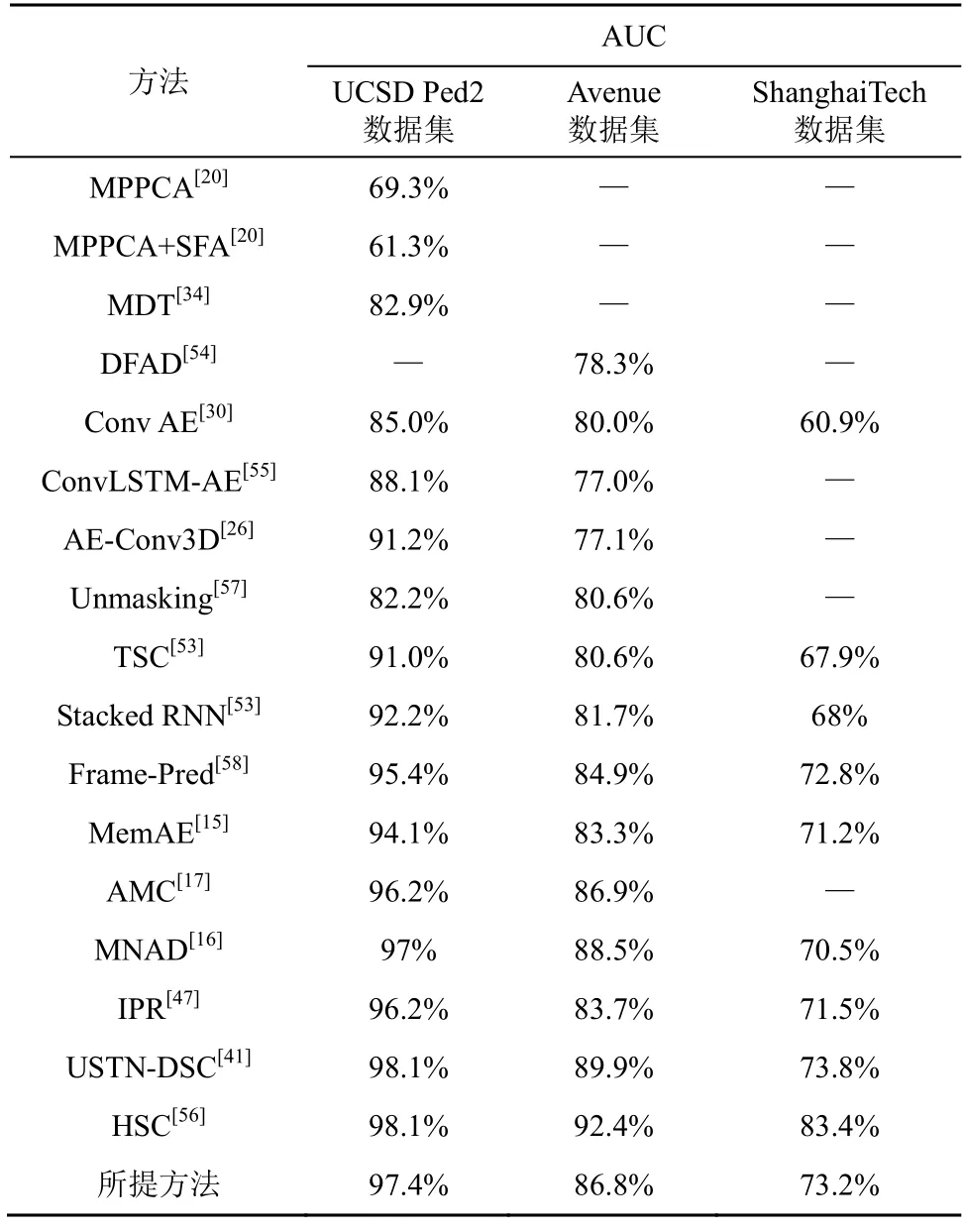
表1 不同方法的AUC
從表1 可知,所提方法的異常檢測精度優于大多數對比方法,在 USCD Ped2、Avenue 和ShanghaiTech 數據集上的AUC 分別為97.4%、86.8%、73.2%,主要得益于其對編碼器的特征分別進行了全局和局部的細節處理,使模型性能有了很大的提升。與IPR[47]相比,本文方法在3 個數據集上的AUC 均高出1%~3%,雖然IPR 中使用的網絡結構也基于編碼器-解碼器結構,但缺少對物體外觀和運動特征等信息的處理;同樣地,MNAD[16]也沒有對物體外觀和運動信息進行有效處理,而本文方法中加入了RGB 圖像的輸入,用來增強視頻序列的上下文信息,RGB 圖像的信息量與光流特征大體相當,但會節省存儲空間并加快學習速度,MNAD 中增加了記憶項,存儲了豐富的正常事件的原型,使模型在Avenue 數據集上的性能比本文方法高1.7%,由此可見,原型學習對無監督視頻異常檢測任務的研究提供了新的思路,對后續研究有一定的推動作用。與文獻[42]相比,本文不僅在模型中加入了運動、外觀和上下文信息的相關處理,也在基礎網絡上增加了網絡的深度,使網絡的整體性能有所提升。本文方法與USTN-DSC[41]都采用了注意力機制,但在AUC 方面,USTN-DSC 表現出較好的性能,這主要是因為USTN-DSC 使用了目前最先進的視頻處理架構Swin Transformer,并在時序和注意力中融入了殘差連接,能夠更好地傳遞和利用信息,使其性能有了較大提升;此外,HSC[56]采用了一種全新的思路,即引入場景感知的概念進行異常檢測,并取得了令人滿意的效果,這為解決視頻異常檢測問題提供了另一種思路和方法。綜上分析,在視頻異常檢測上,本文構建的全局-局部自注意力網絡有效性得到了驗證。
3.4 消融實驗分析
本文對模型中所涉及的主要模型組件進行了定量分析,模型組件在UCSD Ped2 和Avenue 數據集上性能對比如表2 所示。增加全局注意力模塊后AUC 僅有小幅提升,在UCSD Ped2 上AUC 提升了0.7%,主要是因為將數據降維編碼后,數據的高維特征丟失較多,使全局特征處理受限;而在局部注意力中,現有的編碼特征將信息處理的重點放在了細節處理上,使模型性能明顯提升,在UCSD Ped2 上性能提升了1.6%。實驗結果表明,將全局-局部自注意力模塊加入模型后在UCSD Ped2 上的檢測效果達到最優,為97.4%。
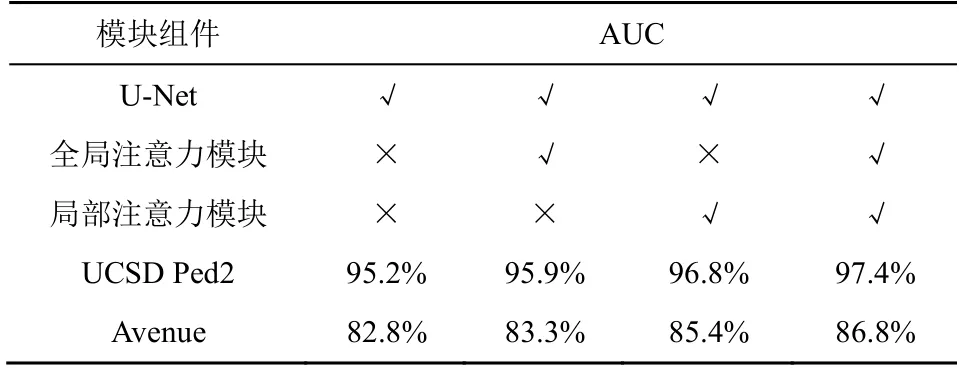
表2 模型組件在UCSD Ped2和Avenue數據集上性能對比
本文在其他實驗組件不變的情況下,對模型架構的基礎組件在UCSD Ped2 數據集上進行了測試和性能分析,具體如表3 所示。通過加深基礎主干網絡的深度,使網絡的非線性表達能力更好,能夠學習更復雜的特征變換,從而更好地擬合復雜的特征輸入,主干網絡的加深使模型檢測性能提升了0.3%。與經典的單編碼器-單解碼器相比,本文采用的雙編碼器模式通過加入相比于光流更輕量化的RGB 圖像,將原本單個模態的特征信息轉變為2 種模態信息的有效融合作為輸入信息,從而對特征提取起到了增強作用,尤其是對運動信息的加強,使模型性能相較于單編碼器結構提升了0.8%。

表3 模型架構基礎組件性能對比
3.5 可視化分析
本文分別將模型在UCSD Ped2 和Avenue 數據集上的測試結果進行了可視化分析。圖3 展示了在UCSD Ped2 數據集上正常幀和異常幀的檢測結果,其中具有異常行為的目標物體已用方框進行了標注,圖3 中的可視化結果主要為了突出顯示異常事件發生的位置,將可視化后的原始彩色圖轉換為黑白圖后,正常幀與異常幀的差別非常明顯。在正常幀情況下,沒有異常發生,此時的異常分值曲線圖處于較高位置,對應于圖像時,其色彩過度較平緩,被檢測物體間的色彩差異大致相同,如圖3(a)所示,在人行橫道上的正常情況為正常行走的路人;當有異常發生時,發生異常的位置會顯示高異常色彩,如圖3(b)所示,方框標注處為高異常,即有人在人行橫道上騎自行車和玩滑板。圖4 展示了Avenue數據集測試視頻的異常得分。當行人正常行走時,異常得分處于較高位置,而有人向空中拋擲雜物時,則被判定為一個異常事件,此時異常得分會急劇降低,且異常行為越突出,異常得分越低,這表明本文中的模型能夠有效檢測到異常事件的發生。

圖3 UCSD Ped2 數據集上正常幀和異常幀的檢測結果
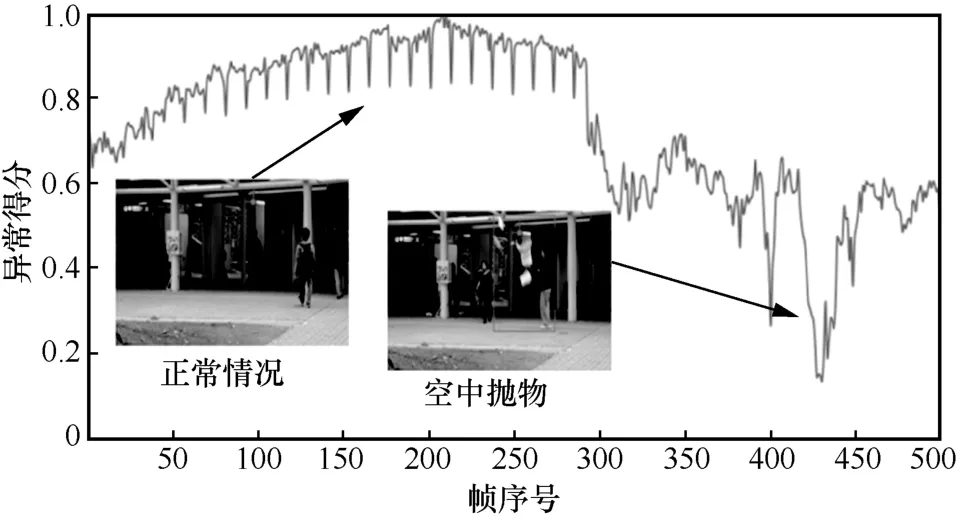
圖4 Avenue 數據集測試視頻的異常得分
4 結束語
本文提出了一種基于全局-局部自注意力網絡的視頻異常檢測方法。該方法采用無監督學習方式,通過加深U-Net 的網絡深度、添加多尺度局部注意力模塊和全局自注意力模塊,以及在數據輸入時添加RGB 圖像,增強了模型對視頻序列中物體運動、外觀等信息的處理能力和魯棒性。實驗結果表明,本文方法在不同應用場景的數據集上具有一定的泛化性和有效性。
CNN 方法通過多層疊加來獲得全局信息,但隨著疊加層數的增多信息量有所衰減,而Transformer中的自注意力機制克服了上述缺陷,使模型具有更強的表達能力,這將是本文未來的研究方向之一。在無監督的方法中,模型的訓練通常建立在正常數據集上,如果將已知的異常類型作為重要的先驗知識加入模型的訓練,則對模型的魯棒性和檢測效果有較大提升。因此,如何將已知的異常類型作為先驗知識融入模型的訓練將會是本文下一步研究的重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
