一種基于聚類的門控卷積網絡語聲分離方法*
2023-09-20 06:50:20胡維平吳華楠
應用聲學 2023年5期
羅 宇 胡維平 吳華楠
(廣西師范大學電子工程學院 桂林 541000)
0 引言
語聲分離任務源于雞尾酒會問題[1]。傳統學習方法存在計算復雜度高和區分性訓練困難的問題。與上述相比,深度學習為語聲分離任務提供了快速準確的方法,其高效的建模能力將掩碼推斷視為一個分類問題。在以往的頻域語聲分離中,需要考慮分離語聲的說話人排列問題[2]。因為頻域中將語聲分幀,再進行語聲分離,可能會將一個說話人的語聲幀分離到另一個說話人上,造成網絡分離的語聲信息混亂。深度聚類是最早基于深度學習的語聲分離體系結構,使用經過區別訓練的嵌入,在高維嵌入的特征空間中進行聚類來解決語聲分離輸出排列問題。
說話人聚類的語聲分離可以看作是一種矩陣分解任務,輸入的混合語聲作為輸入矩陣,是若干個輸出矩陣之和,基于此理論來利用掩碼方法。深度聚類訓練目標是理想二值掩碼(Ideal binary mask,IBM),每個時頻單元對應一個源信號,由此可將掩碼估計等同于時頻單元聚類分類的問題。陸續有很多研究人員采取聚類方法來進行說話人分離。Hershey等[3]提出了深度聚類(Deep clustering,DPCL),訓練了一個深層網絡,將對比嵌入向量分配給頻譜圖的每個時頻區域,輸出標簽的匹配轉換為親和力矩陣的匹配,最小化同一人的時頻單元嵌入向量之間的距離,最大化不同人之間的距離,其高度依賴于嵌入形成的低秩成對親和力矩陣。Chen等[4]提出了深度吸引子網絡(Deep attractor network,DANet),通過在混合信號的高維嵌入空間中創建吸引子點,吸引子是由嵌入向量動態計算得到,將每個聲源對應的時頻單元聚集在一起,通過學習聚類中心來對不同的說話人生成不同的掩碼,這樣就可以得到一種可學習的聚類中心,與DPCL 相比更加靈活,得到的結果也更加理想。Luo等[5]提出了獨立說話人的吸引子網絡(Speaker-independent speech separation with deep attractor network,ADANet),利用嵌入空間的一組輔助點(錨定點),使用嵌入和每個吸引子之間的相似性來估計混合物中每個源的掩碼。ADANet 解決了DANet中兩種創建吸引子方法的問題,但是網絡引入一個期望最大化(Expectation maximization,EM)迭代過程,需要對于每一種取法計算錨框和吸引子,因此計算開銷增大。Wang等[6]提出了嵌合體網絡(Chimera),該結構將深度聚類與掩碼推理網絡結合在多目標訓練方案中,提出了多個備選損失函數來訓練深度聚類網絡,在訓練掩碼推理網絡以實現最佳分離時,深度聚類損失可作為正則化項,防止訓練過擬合。
時域卷積網絡(ConvTasNet)是一種全卷積聲頻分離網絡,在序列建模和聲頻處理任務中展現了優越的性能[8]。本文利用ConvTasNet 的時域卷積網絡(Temporal convolutional networks,TCN)結構,設計了基于聚類的門控卷積網絡(Gate-conv cluster)框架,編解碼器分別是一維卷積和一維轉置卷積,在分離網絡中,用堆疊的門控卷積(Gateconv)來提取語聲信號的深層次特征;同時在特征空間中搭建聚類模塊,對長時語聲特征進行映射分離。聚類定義的損失函數是負尺度不變信源噪聲比(-SISNR),對目標語聲信號進行端到端訓練。該框架很好地解決了傳統聚類方法無法做到端到端訓練和時域卷積網絡語聲建模中短時依賴的問題。
1 模型設計及方法介紹
語聲分離是指從給定的混合語聲信號中提取所有重疊的信號源[9]。對于給定的線性混合單通道信號y[t],單通道語聲分離提取所有C個說話人的源信號為Xc[t],c為說話人索引。
1.1 Gate-conv cluster
Gate-conv cluster 是 在convtasnet 的tcn 結構[7-8,10]上提出的編碼器-解碼器框架,編碼器是一維卷積,并行編碼計算混合語聲的時域特征;然后將其送入一維非線性Gate-conv堆疊的嵌入網絡中,在高維度的特征空間中進行聚類,估計出目標語聲的掩蔽值;后利用編碼后的混合語聲與估計出來的掩蔽值做點乘,最后通過一維轉置卷積重構得到純凈的語聲信號。圖1 顯示了搭建的Gate-conv cluster框架以及gate-conv結構。
1.2 編碼器
其中,Yconv是混合信號y[t]的時域特征表示,ReLU(·) 是用于確保非負輸出的元素整流線性單元;Conv1D(·)是由可學習權重參數的1*1卷積核。
1.3 Gate-conv
分離網絡由門控卷積網絡和嵌入空間中的聚類組成。受Chimera 聚類集群框架[6]啟發,語聲經過深度神經網絡,結合門控支路提取的非線性信息對于在聚類空間中時頻單元生成掩碼具有更好的性能。Gate-conv在ConvTasNet中一維卷積塊1-D-conv中增加了非線性門控卷積支路[8,11],每個一維卷積模塊增加兩個Sigmoid 門,一個對應于一維卷積模塊中的第一個1*1 卷積層即1*1_conv,另一個對應于從深度可分離卷積depthwise_conv到輸出1*1_conv 的所有層,depthwise_conv 中的卷積層是大小為K的卷積核。
Gate-conv 結構塊中,門控卷積塊的不同顏色表示不同的膨脹因子,特征映射首先通過一個通道數為256 的1*1_conv 塊,然后是8 個剩余的通道數為512 的Gate-conv塊,膨脹率為1,2,···,128,重復4 次;其中Gate-conv 中卷積核大小為3,步長stride為1。其中在每兩個卷積操作之間添加激活函數和歸一化,經過depthwise_conv 后的1*1_conv的Output 作為下一個門控卷積塊的輸入;剩下的1*1_conv 塊的跳躍連接總和作為Gate-conv 結構塊的輸出[8]。
1.4 嵌入空間中的聚類
在門控卷積網絡后端搭建了聚類框架,經過門控卷積網絡的混合聲音的特征單元,被投射到一個高維空間[12]。特征單元在和不同源分配生成的吸引子距離計算上,任意兩點的距離都可能極為相近,導致難以將其區分出來;同時高維數據集的簇可能存在于不同的維度集合里。所以確定一定維數的特征空間很有必要,特征空間使用嵌入尺寸參數embed_size為σ的深度神經網絡實現。為了將每個嵌入的特征單元分配給混合特征矩陣中的不同說話人,沿著時間追蹤嵌入空間中說話人的質心,其中來自不同聲源的質心被稱為吸引子點At(i,σ,τ),i是說話人的源分配,σ是特征空間維度,τ是時間步長,該吸引子點用于確定當前說話人的特征向量分配。
與去年的調查相比,其他變化僅有CPA報道的AB Smithers北方木制品公司倒閉。這家工廠在我們去年的名單中僅顯示9.7萬m3的年產能。
吸引子的位置在每個時間步都會更新。首先,吸引子的先前位置用于確定當前特征單元的說話人分配。然后通過聚類操作,基于先前吸引子的加權平均值和說話人分配定義的當前特征向量中心更新吸引子[13]。
其中分離模型U(·),在特征空間中,屬于同一源的所有嵌入的特征單元表示會互相吸引[14]。嵌入特征空間中的特征單元和每個吸引子之間的距離(通常表示為點積)決定了該特征單元的源分配,然后使用該分配為每個說話人定義一個掩碼,該掩碼乘以經過一維卷積編碼器后的混合源語聲的時域特征表示來恢復該源。圖2 顯示了嵌入空間中聚類來恢復源信號的操作。
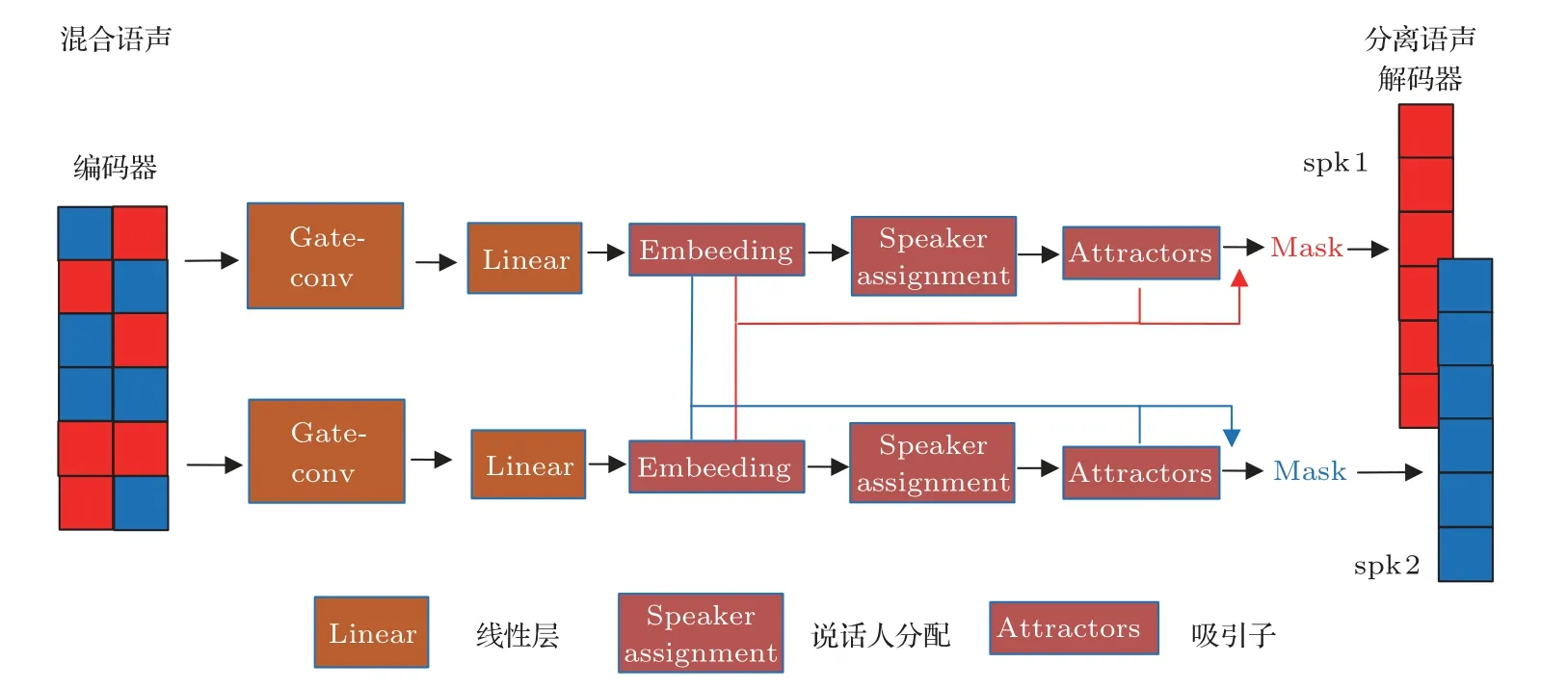
圖2 嵌入空間中聚類分離源信號示意圖Fig.2 Schematic diagram of clustering separated source signals in the embedding space
其中,U(·)是由分離網絡參數σ定義的掩碼估計模型。
在基于掩蔽Mask 的解決方案中[15-16],根據式(4)推導出恢復源信號Xc的特征向量由估計掩碼與混合信號經過編碼器后的Yconv點乘得到。
其中,t和k分別是時間步長和特征向量索引,而Yconv通過混合信號y[t]經過一維卷積編碼的潛在特征表示;是為說話人c通過聚類生成的掩碼;⊙是元素乘法運算。
1.5 解碼器
2 訓練目標
本文以尺度不變信噪比為訓練目標[8]。網絡訓練目標函數是標準信號重建誤差,這使得在訓練和測試階段都可以進行端到端操作。
3 實驗結果及分析
3.1 數據集設置
實驗采用的原始語聲數據集來自WSJ0 語料庫[8]。利用該語料庫創建雙說話人混合數據集WSJ0-2mix:首先從WSJ0 語料庫中si_tr_s 文件夾中隨機選擇兩個說話者的語聲,并以-5~5 dB之間隨機選擇的信噪比(Signal to noise ratio,SNR)進行混合,建成包括49 名男性和51 名女性說話人、總量為30 h的訓練集。此外,10 h驗證集和5 h測試集來自WSJ0 的si_dt_05 文件夾和si_et_05 文件夾的16 個說話人的言語(與訓練集不同)。最后,經過8 kHz降采樣,得到精度為16 bit的20000條語聲訓練集、5000 條語聲驗證集、3000 條語聲數據測試集[3]。
3.2 參數設置
該網絡的編碼器與解碼器即一維卷積,卷積核大小均為20,網絡在4 s長的片段上進行訓練。初始學習速率設置為1×10-3,如果在連續3 個時期內驗證集的準確性沒有提高,學習率將減半,優化器使用Adam進行訓練[17]。
通過信號失真比改善(Signal distortion ratio improvement,SDRi)[18]和尺度不變信噪比改善(Scale invariant SNR improvement,SI-SNRi)[8]來評價該方法,其中指標數值越大表明語聲分離性能越好。
3.3 雙支路非線性門控卷積的驗證分析
為了驗證雙支路非線性門控卷積對于TCN 結構的改進作用,在后端均不添加聚類操作的情況下,Gate-conv 和ConvTasNet,在WSJ0-2mix 數據集下,使用相同實驗設置,分別使用Gate-conv和使用ConvTasNet 的1-D-conv 再進行聚類后端分離,運行50個epoch,實驗結果如表1所示。
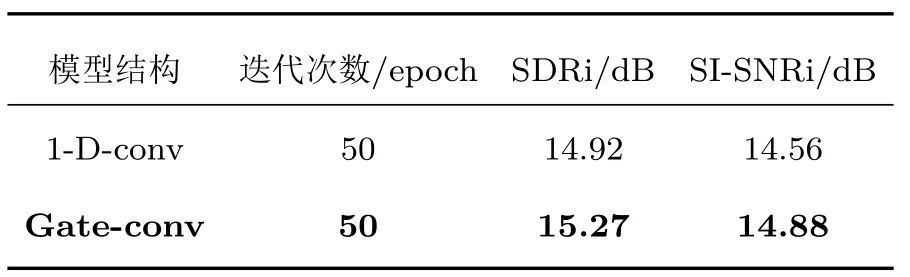
表1 使用非線性雙支路門控卷積與一維卷積的分離結果對比Table 1 Comparison of separation results using nonlinear bipartite gated convolution with one-dimensional convolution
從表1 可以看出,在基線原有ConvTasNet 中1-D-conv 上增加雙支路非線性門控激活后的Gateconv,分離結果均有不同程度的提升,其中SDRi 提升了0.35 dB,SI-SNRi 提升0.32 dB。由此可得出,非線性雙支路門控卷積提高了卷積網絡的非線性表達能力,在序列建模工作控制更多的信息流,能夠有效地提取語聲信號的深層次特征,對于語聲分離效果有著一定的改善。
3.4 高維聚類和不做聚類直接估計mask 方法的驗證分析
基于Gate-conv,在WSJ0-2mix數據集下,使用相同實驗設置,分別進行高維空間聚類(Gate-conv cluster)和不做聚類(Gate-conv)直接估計mask 分離,運行50個epoch,實驗結果如表2所示。

表2 高維空間聚類和不做聚類方法的分離結果對比Table 2 Comparison of separation results between high-dimensional spatial clustering and no clustering methods
從表2 可以看出,在Gate-conv 后端進行聚類(Gate-conv cluster),其中SDRi提升了1.03 dB,SISNRi 提升1.01 dB。經過實驗研究發現,Gate-conv cluster 在高維空間中聚類,通過說話人分配和吸引子進一步使網絡訓練每個說話人更長時間序列的特征向量表示,克服了ConvTasNet 語聲建模的短時依賴性問題,進一步提高了語聲分離的性能。
3.5 最優嵌入空間維數研究
在門控卷積網絡后端使用嵌入尺寸參數embed_size為σ的深度神經網絡生成高維度的特征空間,在WSJ0-2mix數據集下,使用相同實驗設置,運行50 個epoch 進行分離,進行最優嵌入空間維數的研究,實驗結果如表3所示。
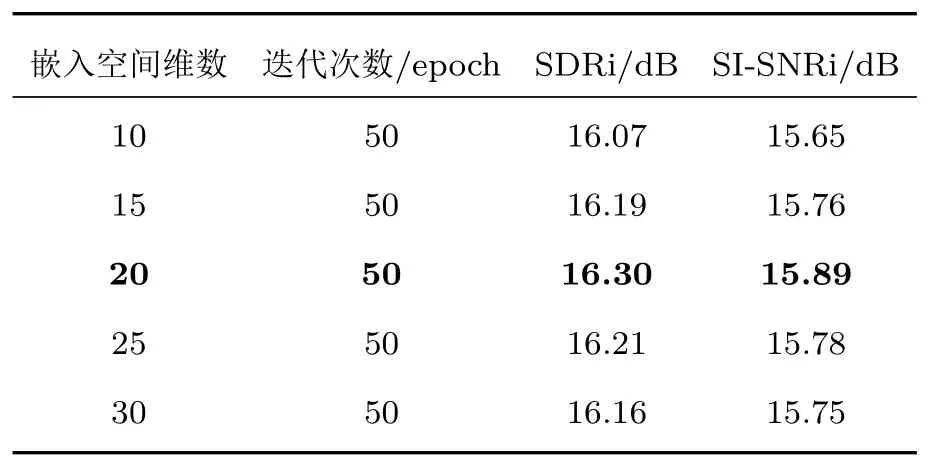
表3 不同嵌入空間維數的分離結果對比Table 3 Comparison of separation results for different embedding space dimensions
從表3 可以看出,在進行驗證不同嵌入空間維數時,隨著嵌入空間維數的增加有助于提高網絡分離性能,但當維數增加到一定值時,網絡分離效果顯著下降;當σ為20時,SDRi和SI-SNRi達到最佳,分別為16.30 dB和15.89 dB。實驗研究表明了在不同維度嵌入空間的接近度會影響不同源信號特征單元聚類的性能[19],同時也證明了在最優維度特征空間中Gate-conv cluster框架能夠在語聲分離任務中表現得更好。
3.6 與不同聚類方法和基線ConvTasNet 的研究比較
通過以上實驗驗證分析研究,Gate-conv cluster 在運行100 個epoch 后,與不同聚類方法和基線ConvTasNet 在同一數據集wsj0-2mix 下進行說話人分離的研究比較,實驗結果如表4所示。
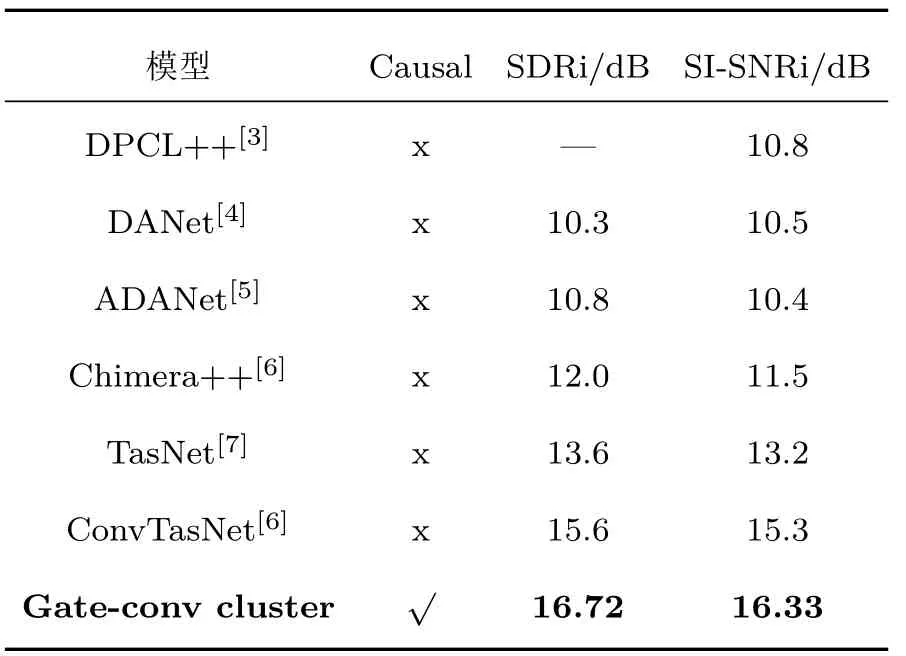
表4 與不同聚類方法和基線ConvTasNet 的分離結果對比Table 4 Comparison of separation results of different clustering methods and baseline ConvTasNet
從表4 所示,在時域上,Gate-conv cluster 與ConvTasNet 的TCN 結構的基線[8]相比,在因果任務中實現了端到端訓練,SDRi和SI-SNRi分別能提高1.12 dB 和1.03 dB;與之前聚類操作的網絡架構相比,性能明顯優之前無語聲建模的聚類框架,其中SDRi 和SI-SNRi 分別達到16.72 dB 和16.33 dB的效果。實驗證明了本文提出Gate-conv cluster,通過堆疊的門控卷積對語聲進行深層次的建模,然后在最優維度的空間中,聚類對映射的特征單元進行表示和劃分,為恢復不同信號源提供了一個長期的說話者表示信息,能夠進一步提高語聲分離性能。
4 結論
本文介紹了在時域上用于單通道語聲分離任務的Gate-conv cluster,首先將使用改進的堆疊雙支路非線性門控卷積對編碼后的語聲進行建模,然后通過實驗研究了最優嵌入空間的維數,在高維特征空間中進行聚類,追蹤不同源信號的長時特征表示;同時網絡訓練使用了基于目標語聲的尺度不變信噪比作為損失函數,實現端到端信號分離。實驗結果表明,與基線ConvTasNet 和以往傳統聚類分離的方法相比,Gate-conv cluster 框架具有更好的分離性能。
由于時域卷積更關注語聲的局部信息,因此,下一階段工作將使網絡能夠學習全局說話人信息,提高語聲分離模型的魯棒性。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2019年3期)2019-02-01 06:12:26
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
